基于大数据平台的推荐系统研究与实现
2023-06-21谷广兵顾佩佩
谷广兵 顾佩佩

摘 要:个性化推荐系统作为人工智能一个落地场景,在社交平台、电商、生活服务等领域有着广泛的应用。为了把优选的商品提供给有需要的客户,对用户行为进行数据采集、数据清洗与存储、用户物品推荐建模、模型评估等内容进行了研究。数据采集通过客户端页面埋点技术来记录用户浏览、点击、关注等行为以及页面停留时长等数据,通过flume、kafka、hive、spark等大数据相关组件与技术完成数据采集、ETL相关操作,将用户评分表、物物余弦相似度等数据通过ALS、item-based组合召回技术,以及LR排序技术生成TOP-N推荐列表,最终经过AB测试,完成最优迭代方案版本选取。
关键词:推荐系统;大数据技术;召回;排序;ALS
中图分类号:TP391.3;TP311.1 文献标识码:A 文章编号:2096-4706(2023)01-0026-04
Research and Implementation of Recommendation System Based on Big Data Platform
GU Guangbing1, GU Peipei2
(1.Jiaxing Vocational & Technical College, Jiaxing 314036, China; 2.Lishui Bureau of Agriculture and Rural Affairs, Lishui 323000, China)
Abstract: As a landing scenario of artificial intelligence, personalized recommendation system is widely used in social platforms, E-commerce, life services and other fields. In order to provide the preferred products to the customers in need, the data collection, data cleaning and storage, user item recommendation modeling, model evaluation and other contents of user behavior are studied. Data collection records user browsing, clicking, following and other behaviors, as well as page dwell time and other data through the embedded point technology on the client page. Data collection and ETL related operations are completed through flume, kafka, hive, spark and other big data related components and technologies. Data such as user scoring table and cosine similarity of objects are generated into TOP-N recommendation list through the combined recall technology of ALS and item-based, as well as LR sorting technology, and finally tested by AB, complete the selection of the optimal iteration scheme version.
Keywords: recommendation system; big data technology; recall; sort; ALS
0 引 言
推薦系统是解决大规模用户场景下的大量信息的精确发送问题,通过离线和实时收集用户行为数据,建立用户行为模型,进行个性化推荐,并且不断评估推荐成效。推荐系统在社会诸多领域均有应用,推荐系统让软件更懂用户,提升用户的智能化体验[1]。
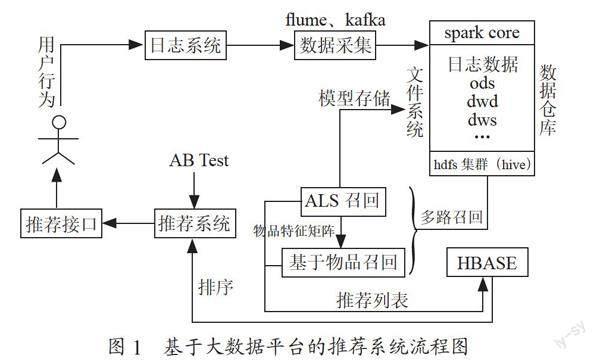
在本项目研究过程中,将用户client端请求日志数据做为flume组件的source层,hdfs作为sink层完成数仓ODS层的构建,使用sparksql技术将用户行为特征值清洗,构建用户行为评分矩阵表,使用召回、排序算法进行模型训练并存储,最终借助于AB测试台完成项目的方案选取,总流程如图1所示。
1 数据源
数据源是推荐系统中最为关键的元素,因为算法都是公开的,而数据呈现隐秘性和私有性。对于推荐系统而言,数据又分为用户数据和物品数据。本文主要针对用户数据中的用户行为数据进行研究,该部分数据主要指的是购买、收藏、浏览、关注等显式反馈数据和页面停留时长、跳转连接(refer)、点击等隐式反馈数据。
为了获取上述用户行为数据,本研究采用目前业内普遍选用的数据埋点技术进行收集。埋点技术在电商类领域运用较为成熟,它方便企业产品经理、运营部门统计分析复杂的用户数据从而进行相关经营决策。目前行业内有神策分析等第三方统计平台,虽能够针对PV、UV数据指标进行统计,但缺乏定制化。本研究采取的是通过代码埋点的方式以定制化的方式完成用户行为数据采集。
埋点行为发生在客户端,可以是Web端、也可以是H5、APP、wxapp等终端。当用户发生浏览行为或者点击行为时候,通过客户端脚本Javascript程序发送head请求,将用户行为数据以json的格式封装在请求头中,如图2所示。在实际应用中,将客户端页面部署在nginx服务器上,继而客户端行为触发http请求,并将所携带埋点对应数据将写入nginx日志文件中[2]。
2 数据仓库与数据清洗
2.1 数据采集
当用户发生点击、浏览、收藏等用户行为时,通过埋点技术,系统将用该部分数据记录在nginx web服务器的日志文件access.log中。通过flume组件,将用户行为数据采集到hadoop集群中的HDFS中,本研究中,采取两个节点的flume组件,完成数据采集[3]。相关节点以及对应的source、channel、sink层如图3所示。
2.2 数仓建设
本研究中,通过建设三层数据仓库,最终生成用户评分矩阵表,三层数据仓库分别为ODS层,存储用户原始行为数据;DWD层,将用户原始行为进行归一后按权重、时间衰减进行计算后存储;DWS层,将用户行为评分进行Sigmoid标准化生成用户物品评分矩阵。这三层数仓的建设采用hive组件完成,在数仓建表过程中,采用hive外部分区表,分别以年、月、日、时做为分区字段,采用sparksql技术进行数据的清洗、聚合等操作[4]。三层数仓建设如表1所示。
3 系统建模
3.1 基于系统过滤的召回与排序
一般推薦系统主要分为召回、排序两阶段,召回是对数据进行初步筛选,得到候选集,也就是初始推荐列表;排序则采用排序模型对召回生成的候选集打分排序,最终生成针对某一用户的推荐列表,本文采用的是基于协同过滤的召回、排序算法[5,6]。
3.2 召回阶段
召回要使用不同的方法、从不同的角度筛选出候选集、满足推荐商品的多样性以及保证候选集和用户的匹配度。本研究采用ALS算法与基于物品的协同过滤这种混合式的召回算法生成候选集。
3.2.1 ALS算法实现
基于数仓建设中的DWS层生成的用户物品评分表,采用spark中所提供的sparkcore,spark MLlib技术完成ALS模型的训练。具体参数如表2所示。
在创建ALS模型过程中,设置最大迭代次数maxIter=10,通过rank(取值20,30),reg(取值0.1,0.05),alpha(取值2.0,3.0)三个参数共8种全排列组合训练模型,经过对比rmse值获取最优模型[7,8],用此模型获得的召回结果,存储到HBASE中。
3.2.2 基于物品的协同过滤
采用上述ALS算法获取物品特征矩阵(model.itemFactors),通过余弦相似度计算,得到物品相似度矩阵。用户物品打分矩阵(dws_user_item_rating)与该物品相似度矩阵相乘,得出用户物品推荐列表,表格式如图4所示。
3.2.3 候选集的存储
上述采用ALS算法与基于物品的协同过滤,在具体业务场景中,通过设置定时计划任务来完成对前一天采集到的数据进行计算。在研究中我们设置0:30进行ALS算法数据计算,1:30实现基于物品协同过滤的数据计算。ALS与基于物品的协同过滤生成的候选集,以时间戳、用户id组合做为rowkey,recall作为列簇,分别以两种召回策略作为列名:als,item2item。将召回的结果存储在HBASE的history_rs_recall表中,如图5所示。最终将两种召回策略的结果集取交集,即可获得推荐列表。
3.3 排序
通过上述召回步骤,已经生了一个候选集或者称之为推荐列表。但是用户在实际浏览商品过程中,兴趣度仅仅停留在前几页商品列表网页。基于此,需要对召回阶段生成的候选集做一个排序,排序依据用户对候选集对应商品点击率的高低,从而筛选出用户可能点击概率高的商品推荐给用户。本文采取基于逻辑回归(LR)的排序方法,实现步骤具体如表3所示。
4 AB测试
AB测试是,在产品正式迭代发版之前,为同一个目标制定两个或者两个以上可行方案,在保证流量(用户)的控制特征不同,而其他特征相同的前提下,将流量(用户)分为多组,不同组流量(用户)会看到不同的推荐方案,根据用户的真实行为数据反馈,统计不同分组方案得到的业务数据,如留存率、点击率、转化率等,从而确定最优推荐迭代版本,如图6所示。本文基于spring boot+vue搭建了AB测试管理平台,主要有三个功能组成:“配置管理模块”用于管理每个ab需求;“实时分流”模块,根据用户性别、设备等用户信息进行分流;“实时效果分析统计”将分流后程序点击、浏览以echarts图的形式进行展示,如图7所示。
5 结 论
推荐系统是人工智能领域一个重要的研究方向,有着巨大的应用价值。本文以电商领域用户行为原始日志数据作为数据源,通过数据清洗构建用户物品打分矩阵,通过召回与排序构建了基于用户的物品推荐列表,通过搭建AB实现管理平台,进行AB实验实现推荐系统的择优迭代。随着基于内容的推荐系统、基于深度学习的推荐系统以及实时推荐系统研究,推荐系统将会更加广泛应用在社会其他领域并造福于社会。
参考文献:
[1] 顾军林,刘玮玮,陈冠宇.基于Hadoop平台的岗位推荐系统设计 [J].现代电子技术,2019,42(20):123-127.
[2] 秦道祥,路阳,张荠月,等.基于Spark技术的日志分析平台设计与应用 [J].中国教育信息化,2021(19):50-54.
[3] 李柯.基于Flume、Kafka的日志采集系统分析研究 [J].电子技术与软件工程,2022(10):255-258.
[4] 程志强.关于大数据时代的数据仓库建设研究 [J].长江信息通信,2022,35(7):156-158.
[5] 李盼颖.基于协同过滤的个性化推荐算法 [D].张家口:河北建筑工程学院,2022.
[6] 崔丽莎.基于用户特征和项目类型兴趣的协同过滤推荐算法研究 [D].郑州:河南财经政法大学,2022.
[7] 文雅.基于大数据的用户个性化推荐策略研究 [D]. 北京:北京邮电大学,2021.
[8] 周晶,刘丹,李慧超,等.考虑用户兴趣的个性化协同过滤推荐方法 [J].微型电脑应用,2022,38(8):74-78.
作者简介:谷广兵(1986—),男,汉族,河南舞阳人,专任教师,讲师,硕士,研究方向:大数据技术与应用。
收稿日期:2022-10-24
