基于企业画像的水泥产业大数据平台设计与实现
2023-06-21宋登科


摘 要:基于水泥产业发展需求、行业特点和发展中产生的海量数据,设计并实现了水泥产业大数据平台。从数据架构、应用架构和物理架构三个方面构建平台的总体架构,并结合机器学习相关算法对企业进行画像,多维度挖掘企业信息。该平台可提供产业大数据可视化、产业地图、企业全息画像和政策精准匹配四大核心功能,为水泥产业信息化、智能化转型升级提供极富价值的参考,是大数据建设的重要应用示范。
关键词:水泥产业;大数据平台;企业全息画像;政策精准匹配
中图分类号:TP311 文献标识码:A 文章编号:2096-4706(2023)09-0111-04
Abstract: The cement industry big data platform is designed and implemented based on the development demand, industry characteristics and massive data generated in the development of the cement industry. Build the overall architecture of the platform from three aspects of data architecture, application architecture and physical architecture, and combine machine learning related algorithms to visualize enterprises and mine enterprise information in multiple dimensions. The platform can provide four core functions of industrial big data visualization, industrial map, enterprise hologram and policy precise matching, which provides valuable reference for the informatization and intelligent transformation and upgrading of the cement industry, and is an important application demonstration of big data construction.
Keywords: cement industry; big data platform; enterprise hologram; policy precise matching
0 引 言
党的二十大报告中强调要建设现代化产业体系,推动制造业高端化、智能化、绿色化发展。在推动我国水泥工业加速转型升级方面,互联网、大数据、云计算、人工智能等先进技术是重要的技术支撑。大数据平台的相关建设案例有华夏幸福产业大数据平台、上海市产业地图、苏州市“政策通”、合肥市庐阳区产业政策申报平台等,满足不同产业的业务需求。本文利用安徽海螺水泥产业跨平台、跨行业、跨地区的多源异构数据[1],结合机器学习算法挖掘产业数据,以企业画像[2]为核心,设计并实现了具有多种核心功能的水泥产业大数据平台,实现水泥产业管理网络化和平台化,为水泥产业的未来发展提质增效。
1 平台功能及目标
水泥制成的砂浆或混凝土是国民经济发展的重要基础原料,广泛应用于土木建筑、交通、水利、电力、化工、国防等工程建设。在海螺水泥的带动和引领下,水泥产业完成了技术结构调整,处于创新提升超越引领阶段。此阶段水泥产业的目标是淘汰落后设备,推动供给侧改革,进一步向信息化和智能化转型升级。水泥产业具有自身特点,其销售情况受季节变化、国家政策的影响明显,因此相关人员在制定水泥生产计划时要分析市场需求,同时及时研究国家经济政策的走向,避免盲目决策[3]。市场手段与行政手段相互配合是水泥行业供给侧改革的核心路径,通过构建水泥产业大数据平台,加速释放数据潜力,作为连接宏观决策和微观数据的工具在水泥行业上游原料和下游需求产业链中发挥重要作用。本文设计的水泥产业大数据平台主要实现了以下四个核心功能:
1)通过集中整合和管理如产业规划、区域布局、水泥生产园区、水泥项目等产业相关数据,全方位构建水泥产业数据的指标体系,结合常用的分析模型和方法,进行统计图表可视化表达水泥产业数据相关指标。
2)基于水泥企业所在地区的二维地图,将水泥企业、生产园区、水泥项目等主体的分布情况予以呈现,通过点击地图上企业、园区等主体的符号化图标,可跳转到该主体的详情查看页面。
3)对所获取的海量水泥企业数据进行分析处理,建立企业标签体系,深度挖掘企业和个人、企业、项目、产业间的关系链路,建立关系图谱,结合业务需求建立企业的全息画像,用户可对企业不同维度信息进行查询。
4)梳理整合政府发布政策和企业需求,运用机器学习算法对海螺旗下300多家子公司以及上下游产业链相关企业和国家经濟政策进行匹配,智能化将政策推送给企业,同时企业也能在政策查询模块获取匹配的政策推荐,实现政策精准匹配。
建立起这样一个集汇总、整合、展示和分析于一体的水泥产业大数据平台,一方面可充分利用产业大数据资源,充分挖掘数据价值并进行信息化展示;另一方面可通过机器学习相关算法满足水泥企业的相关需求,为产业智能化发展提供助力。
2 平台架构
水泥产业大数据平台总体架构主要包括三部分,分别是平台服务层(IaaS、PaaS)、数据服务层(DaaS)和应用服务层(SaaS),如图1所示。
平台服务层包括IaaS平台管理和PaaS平台管理两个部分。IaaS平台管理主要提供基于云服务的计算服务、存储服务、网络服务。PaaS平台管理主要进行数据的获取和处理,并提供通用中间件服务及大数据中间件服务,通用中间件服务包括MySql、Redis、数据可视化工具,大数据中间件服务的实现主要基于Hadoop分布式系统框架。数据服务层主要是应用机器学习和人工智能技术,实现水泥产业指标统计分析、企业和政策标签构建等功能。应用服务层在数据服务层的基础上,围绕企业画像实现产业大数据可视化、产业地图、企业全息画像和政策精准匹配四大核心功能。
2.1 数据架构
数据架构负责组织获取到的大量数据,以满足应用系统不同的数据需求,是建立灵活有效大数据平台的重要基础。水泥产业大数据平台建设九大数据区,分别为:缓冲区、贴源区、基础区、标签区、主题区、应用区、历史数据备份区、非结构化区以及索引区,如图2所示。
2.2 应用架构
应用架构主要分为四个部分,分别是数据源、数据仓库、数据应用和门户,如图3所示。
数据源负责数据的接入,采集政务和水泥数据;数据仓库负责整合结构化、半结构化和非结构化数据,统一格式收入产业主题库;数据应用针对水泥企业需求实现相应功能;门户负责应用和信息的集成展示,是产业大数据平台的用户入口。
2.3 物理架构
物理架构实现内网和外网分开,内外网之间通过数据交换平台交换数据。内网部署大数据集群用于数据的计算和分析,相关数据库用于结构化和非结构化数据的存储;外网部署虚拟机用于Web应用服务、业务数据库和前置机数据库存储服务,其具体结构如图4所示。
3 关键技术
水泥产业大数据平台设计的功能,以企业画像为技术核心,采用机器学习领域相关算法得以实现,主要分为标签生成技术、协同过滤技术和地图构建技术。
3.1 标签生成技术
水泥企业数据具有来源不同、类型不同的特点。类别类型的数据,直接提取类别数据作为企业标签,表示企业的基本信息。原因描述类的数据,利用数据处理工具Pandas、Numpy等进行统计归类分析生成标签。对于企业很多无法通过简单统计分析获取的隐含特征,采用机器学习相关算法建立模型获取标签[4],主要采用多项式朴素贝叶斯(MNB)分类器和支持向量机(SVM)的方式,对企业数据文本进行分类从而实现对企业隐含特征的挖掘。
多项式分布公式为:
其中,P(X = xi | Y=c)表示c类别下第i个属性上取值为xi的条件 概率,是c类别下第i个属性上取值为xi的样本数,|Dc|表示c类别的样本数,Ni表示第i个属性可能的取值数,λ表示平滑系数,为防止训练数据中出现过的词未包含在测试集中导致0概率的出现,取λ=1称为拉普拉斯平滑。技术上通过调整sklearn中的MultinomialNB参数实现。
标准的硬边界线性SVM在约束条件设为样本点到决策边界的距离大于等于1的情况下,转化为一个等价的二次凸优化问题进行求解:
对企业未显式说明的特征视为目标进行分类,挖掘出企业的隐含特征并为其加上标签。技术上通过调整sklearn中的LinearSVC参数实现。
3.2 协同过滤技术
通过标签生成构建企业全息画像之后,采用基于邻域的算法来构建推荐系统[5],实现政策的精准匹配。根据企业和政策特征,计算企业和政策匹配度,以此构建企业-政策矩阵和政策-企业矩阵,主要采用两个基于邻域的算法。
3.2.1 基于企业的协同过滤推荐(User-Based)
给定一个企业,寻找未被该企业浏览的政策(政策-企业矩阵中的值为0),计算与该企业相似的企业偏好政策的分数,并按照从高到低的顺序进行排序,返回前N个政策进行推荐。
3.2.2 基于政策的协同过滤推荐(Item-Based)
给定一个政策,寻找未浏览该政策的企业(企业-政策矩阵中的值为0),计算与该政策相似的政策被企业偏好的分数,并按照从高到低的顺序进行排序,返回前N个企业进行推荐。企业相似度和政策相似度采用余弦相似度公式来表示:
结果的值代表了企业和企业、政策和政策向量之间夹角的大小,夹角越小,余弦相似度越大,说明两者之间的相似度越大。
针对上述两个算法泛化能力弱和具有头部效应的问题,采用基于模型的协同过滤推荐(Model-Based)进行优化,这里采用基于矩阵分解的潜在语义模型。潜在语义模型通过隐含特征联系企业匹配的政策,基于企业特征找出潜在政策主题,然后对政策进行自动聚类,划分给对应企业,通过分解共现矩阵得到含有隐向量的企业矩阵Q和政策矩阵P,这样就能得到企业u对政策i的偏好分数:
按照从高到低的顺序排序之后将前N个未推荐给企业的政策推荐给该企业。
3.3 地图构建技术
水泥产业地图功能模块基于主流的GIS软件进行地图符号化,通过GIS软件平台提供各类空间数据服务,将所获取的高精度矢量數据通过空间数据库引擎导入关系型数据库。利用图像解译方法将需要提取的地物(如水泥企业、生产园区、水泥项目等主体)进行实体提取,构成高精度高完整度的矢量格式数据,基于这些数据,利用ArcGIS软件[6]进行数字线画图(Digital Line Graphic, DLG)生成,将这些实体在地图上进行符号化渲染。
同时采用Apriori算法挖掘主体之间的关联规则,在地图上用户点击该主体能获得其他相关主体的信息。Apriori算法首先获取主体X和Y之间的支持度,支持度表示主体X和Y同时出现在数据集中的概率:
Support(X→Y )=P(X ∩Y )=P(XY )
在计算主体X出现的情况下,主体Y出现的概率称为置信度:
Confidence(X→Y )=P(Y | X )
在满足最小支持度的组合中,生成满足最小置信度的关联规则,提取出相关主体作为目标主体的关联主体进行展示。
4 平台展示
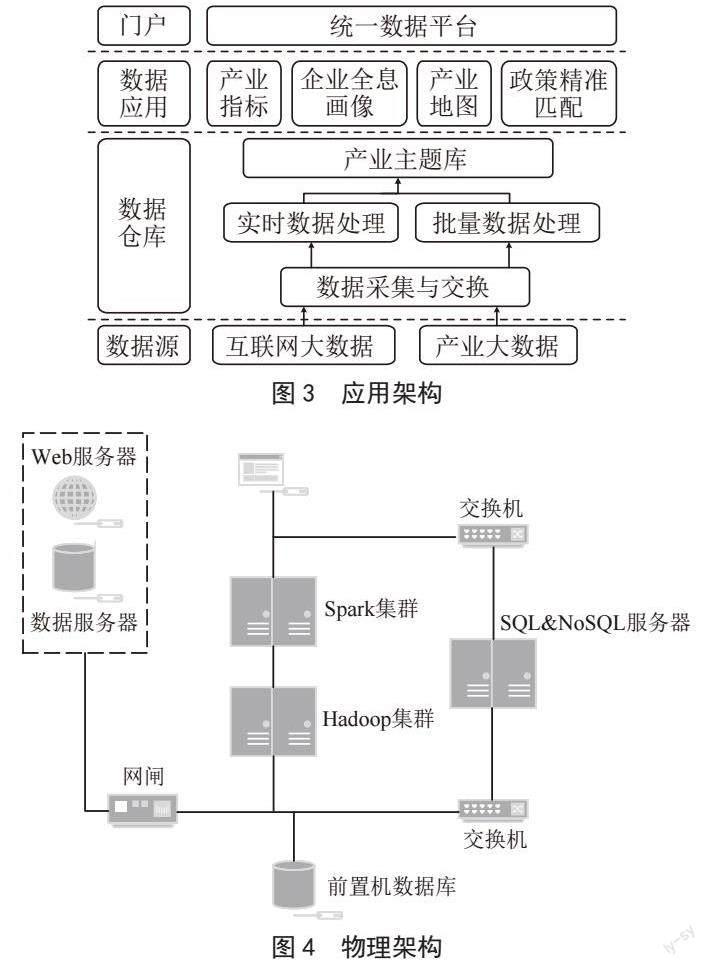
在地图上点击相关主体的符号化图标,可以进入该主体的详细信息界面,展示主体的特征信息。如图5所示,点击进入安徽海螺水泥某厂信息页,展示水泥生产企业的特征信息(主要是水泥生产的能效能耗)。实时呈现企业特征信息,一旦出现不合理数据时能够及时发现并采取相应对策,提升管理效率。
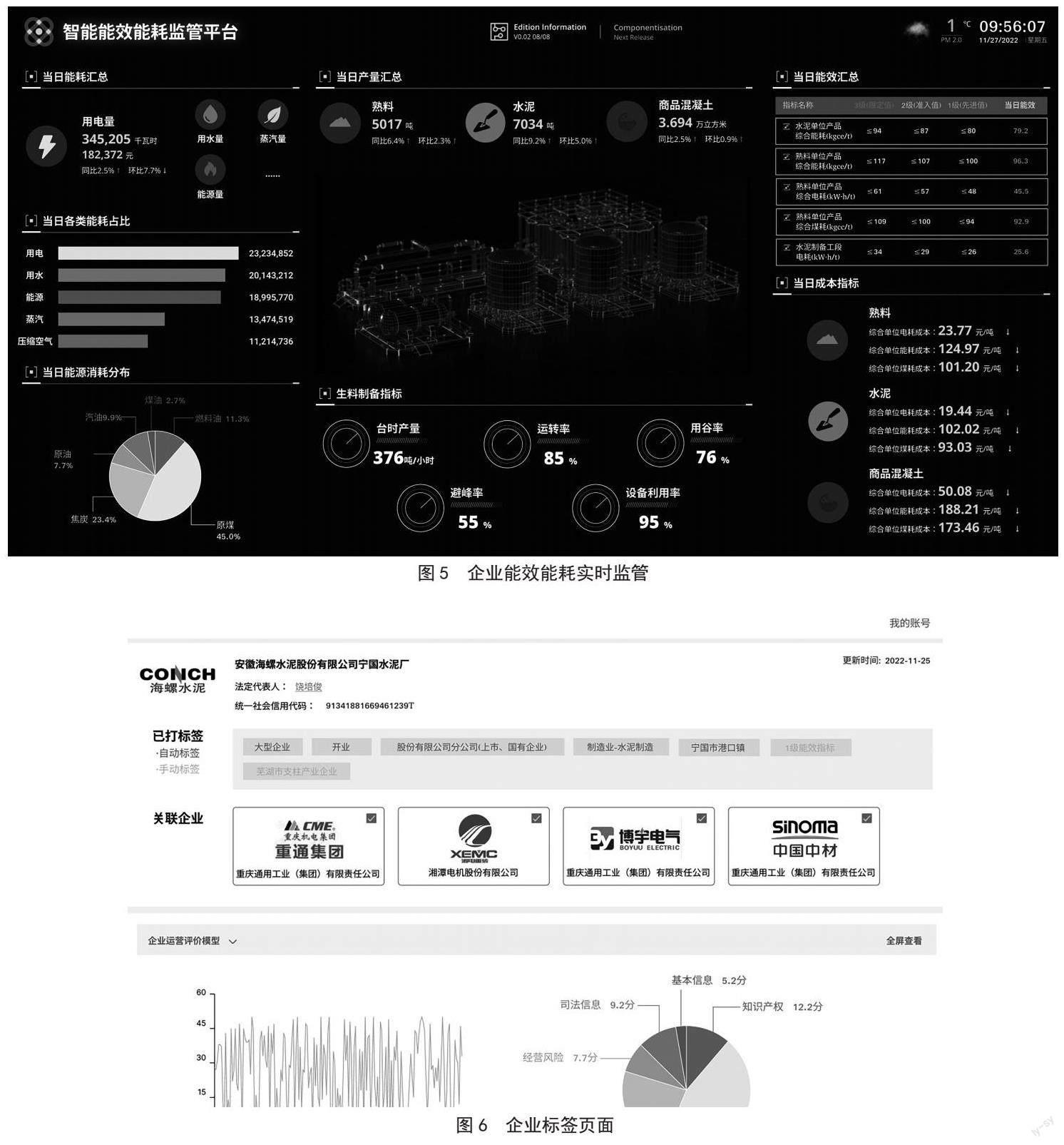
同時点击企业能够进入企业画像页面,如图6所示。通过直接获取的和计算生成的相关标签,全方位展示企业信息,如基本信息、司法信息、经营风险、知识产权等。同时展示通过关联规则挖掘出的与企业关联度较高的关联企业,以及运营评价相关模型,为未来发展提供决策参考。
5 结 论
为持续推进水泥产业信息化、智能化建设的步伐,进一步推进水泥行业创新提升超越引领发展,基于安徽海螺水泥和互联网相关数据,设计并实现一种水泥产业大数据平台,结合现有的主流机器学习技术,以企业画像为核心,实现了产业大数据可视化、产业地图、企业全息画像、政策精准匹配四大核心功能模块,同步升级当前政策大数据库、企业和水泥产业大数据库以及配套业务功能及流程,取得了良好的经济效益和社会效益,为以物质生产、物质服务为主的经济发展模式向以信息生产、信息服务为主的经济发展模式转变提供重要支持。
参考文献:
[1] 林瑀,陈日成,金涛.面向复杂信息系统的多源异构数据融合技术 [J].中国测试,2020,46(7):1-7+23.
[2] 陈钢,佘祥荣,秦加奇,等.面向精准政务服务的自然人全息画像 [J].电子技术与软件工程,2021(15):209-210.
[3] 张媛媛.信息化建设在水泥行业中的应用与研究 [J].四川水泥,2018(6):2.
[4] ACCENTS J.Feature-driven label generation for congestion detection in smart cities under big data [EB/OL].[2022-11-10].https://www.accentsjournals.org/paperInfo.php?journalPaperId=1390.
[5] 褚宏林.协同过滤推荐算法研究分析 [J].福建电脑,2021,37(6):51-54.
[6] 齐志飞,姚奕.面向ArcGIS个人地理数据库的矢量几何数据解码 [J].电脑编程技巧与维护,2022(10):92-96.
作者简介:宋登科(1980—),男,汉族,湖南株洲人,工程师,硕士,研究方向:大数据与人工智能。
