基于锚框稀疏图像金字塔的MTCNN人脸检测方法
2023-06-20李丽平许营坤王嘉航
李丽平,许营坤,王嘉航
(1.浙江商业职业技术学院 财会金融学院,浙江 杭州 310053;2.浙江工业大学 计算机科学与技术学院,浙江 杭州 310023)
人脸检测是一种基于人工智能(AI)的计算机技术,其作用是在数字图像中查找和识别人脸。该技术不仅作为面部跟踪、面部分析和面部识别等应用程序的第一步发挥着关键作用,而且在人证比对、安防、娱乐和社交网络等领域起到重要作用,同时在手机、数码相机等电子产品中可以使用该技术,检测并定位人脸。该技术支持姿势、表情、位置、方向、夜晚和肤色等复杂环境,从正面和侧面等多个角度检测人脸的位置。在人脸识别过程中,人脸检测是整个人脸识别算法的第一步。
1 人脸检测算法
人脸检测算法的输入是一幅图像,输出是若干个包含人脸的矩形框坐标(x,y,w,h)。早期人脸检测算法采用模板匹配,即用人脸的模板图像匹配待检测的图像的各个位置,匹配内容是提取的特征,根据特征判断该位置是否存在人脸。经过早期后,机器学习算法被用于该问题,包括神经网络、支持向量机等。其中,Rowley等[1-2]提出的多层感知器模型人脸检测和Viola等[3]提出的VJ算法具有代表性,这些方法虽然在人脸检测领域早中期的意义重大,但是随着卷积神经网络CNN的提出及广泛应用,CNN在人脸检测技术上有了很大的突破,在准确度上明显超越之前的AdaBoost框架。Hand等[4]总结了近年来基于深度学习的人脸检测发展历程。Zhan等[5]在2016年ECCV会议上提出了一种基于级联架构的多任务卷积神经网络MTCNN,其可以同时完成人脸检测和人脸对齐任务。在工程实践上,MTCNN是一种检测速度和准确率均较高的算法,应用范围较广。研究发现:在MTCNN三层级联网络结构中,P-Net不仅耗时最多,约占75%,而且图片越大,耗时越长,其次是R-Net耗时较多。另外发现噪点比较多的夜间图像,由于噪点多的问题,导致P-Net误检率高。吴纪芸等[6]通过整合不同网络模型,改进了多任务卷积神经网络,通过动态修改Minsize值,提出了一种改进的MTCNN人脸检测算法。改进后的算法减少了图像金字塔中图片生成的数量,达到优化网络的目的。贾小硕等[7]在MTCNN基础上设计了MT-Siam网络,引用了SiameseNet并设计轻量化的Siam相似度判断因子,提升复杂背景下人脸检测效率。薛晨等[8]采用Retinex理论对图像进行增强,提高MTCNN在不同光照场景下的人脸检测精度。
笔者研究在MTCNN人脸检测算法的基础上,提高检测速度和检测精度。针对MTCNN三层级联网络结构中P-Net和R-Net耗时较多的问题,提出一种改进的基于锚框稀疏图像金字塔的MTCNN人脸检测方法,采用锚框的思路增加生成框的密度,减少图像金字塔层数,构建基于锚框的稀疏图像金字塔,从而提高P-Net检测速度;采用深度可分离卷积的思路来改进R-Net网络结构,去掉池化层,修改前2个卷积层的步幅,修改第3个卷积层为可分离卷积,降低R-Net模型的参数计算量,进而提高R-Net检测速度。同时,在P-Net检测前进行一次中值滤波,减少图像噪点,降低P-Net误检率。在Windows和Android平台,使用CPU处理器,采用单线程方式进行对比实验测试。实验结果表明:改进的MTCNN在检测精度略提升的情况下,在Windows和Android平台的检测速度均提升一倍,应用价值较高。
2 MTCNN
MTCNN主要分4个步骤:生成图像金字塔,进行3个逐级递进的级联网络P-Net、R-Net和O-Net训练。
2.1 生成图像金字塔
原始图像缩放成不同的尺度,生成图像金字塔,将缩放后的图像输送入P-Net、R-Net和O-Net 3个子网络中进行训练,目的是可以检测到不同尺寸的人脸,从而实现多尺度目标检测。
2.2 P网络(P-Net)
P-Net是一个人脸区域的候选网络。网络的输入设置为12×2×3的图像。经过3层卷积层后,确定12×12图像中的人脸,并且给出人脸框和人脸关键点信息,利用非极大值抑制算法(Non-maximum suppression,NMS)校准边框,去除多余边框。
网络输出有两部分。第一部分输出向量大小为1×1×2,即两个值,判断图像中的人脸。第二部分显示了框的确切位置,一般被称为框回归。P-Net导入的12×12的图像块对应的人脸并非全部为正方形。如:12×12的图像偏左或偏右,这时需要计算当前框所在位置相对于完美人脸框位置的偏移,偏移大小为1×1×4。第三部分给出面部的5个关键点位置。5个关键点分别对应鼻子、左眼、右眼、左嘴巴和右嘴巴的位置。每个关键点用两维来表示,因此,输出是大小为1×1×10的向量。
2.3 R网络(R-Net)
R-Net用于否决P-Net生成大部分错误的检测框,该方法应用了检测框回归和NMS合并的检测框。将P-Net候选框对应原图并截取,同时,将截取图像缩放到24×24×3,作为R-Net的输入,网络的输出与P-Net相同。
由网络结构可知:R-Net网络的结构与P-Net网络不同,增加了一个全连接层从而微处理图像的细节化,过滤重复且不符合要求的候选框,并且利用NMS进行候选框合并处理。
2.4 O网络(O-Net)
O-Net更进一步筛选检测框,与R-Net的处理方法一致,将上一层的输出候选框的人脸区域缩放到48×48×3作为O-Net的输入,网络的输出是一样的,包括N个边界框的坐标信息,score以及关键点位置。由网络结构可知:这一层比R-Net层多一个卷积层,因此可以得到更加精细的处理结果。
从P-Net到R-Net再到O-Net,输入到网络的图像越来越大,卷积层的通道数也越来越多,网络的深度(层数)也越来越深,因此检测人脸的准确率也越来越高。在检测之前,需要通过中值滤波进行降噪处理。中值滤波是处理中心像素点的邻域,其处理方式不能线性表达式表示。某个像素点的滤波结果就是用滤波器包围的图像区域中像素的灰度值的中值来替代该像素的值。计算式为
f(x,y)=median(x,y)∈sxy{g(x,y)}
(1)
式中:f(x,y)为滤波输出;sxy{.}为以(x,y)为中心的滤波窗口中的所有坐标点;g(x,y)为坐标点(x,y)处的灰度值;median(.)为中值滤波处理。通过上述处理,减少图像噪点,从而降低P-Net误检率。
在完成滤波处理后,进行MTCNN训练过程,该过程包含3个任务,分别是人脸和非人脸的分类、人脸检测框的回归以及面部关键点的定位。
首先,人脸和非人脸的分类任务,使用交叉熵损失函数,计算式为
(2)

然后,检测框回归的任务,采用欧几里得损失函数,计算式为
(3)

最后,人脸关键点定位的任务,采用欧几里得损失函数,计算式为
(4)

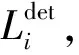
(5)
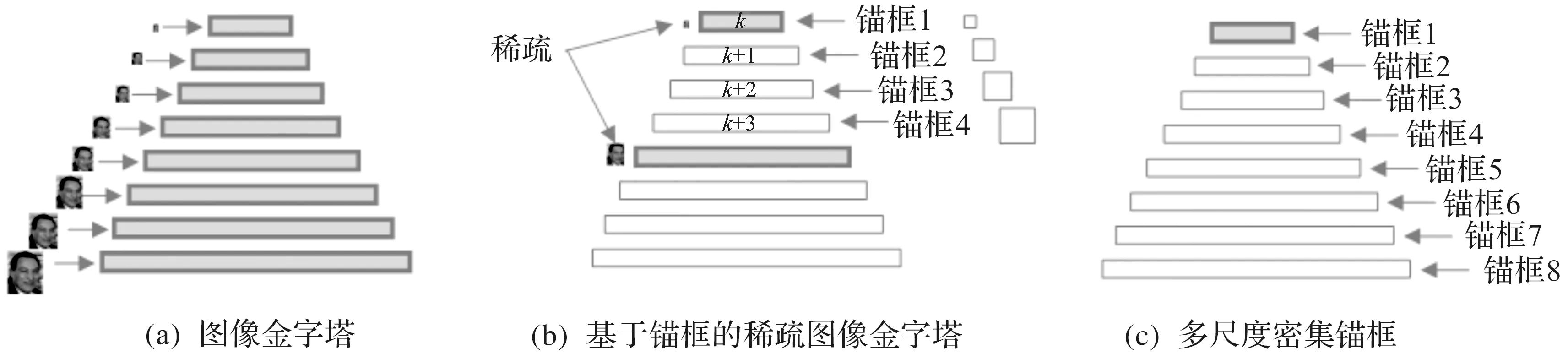
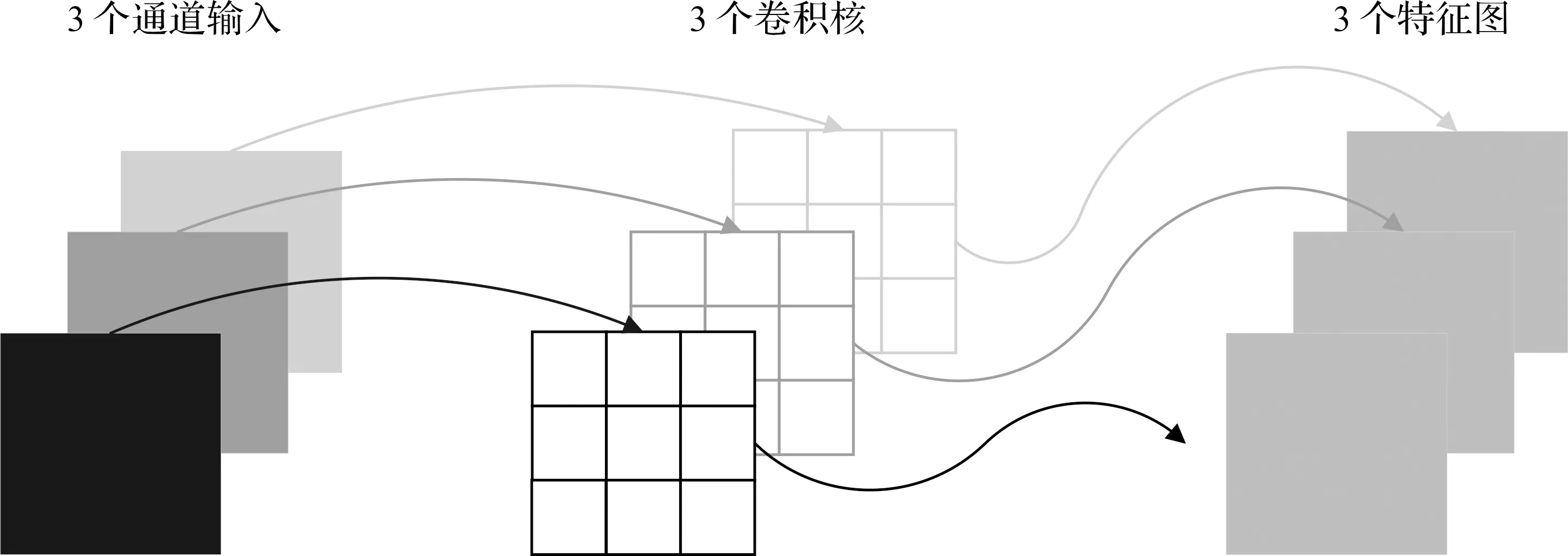
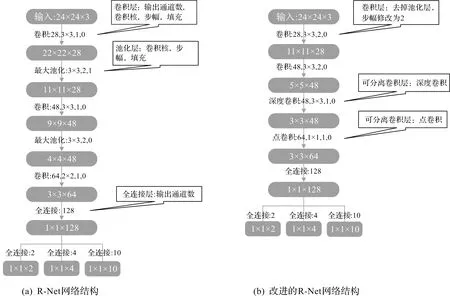
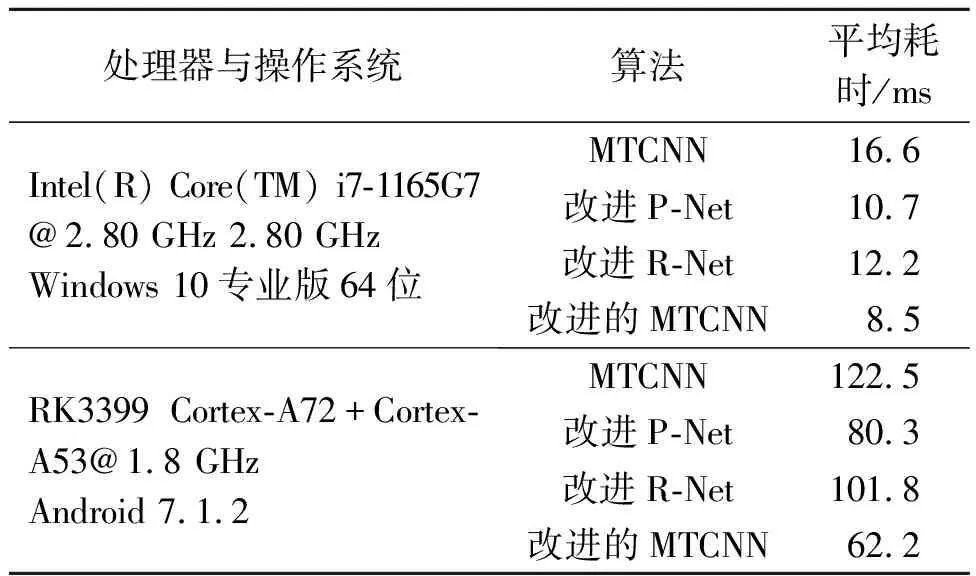
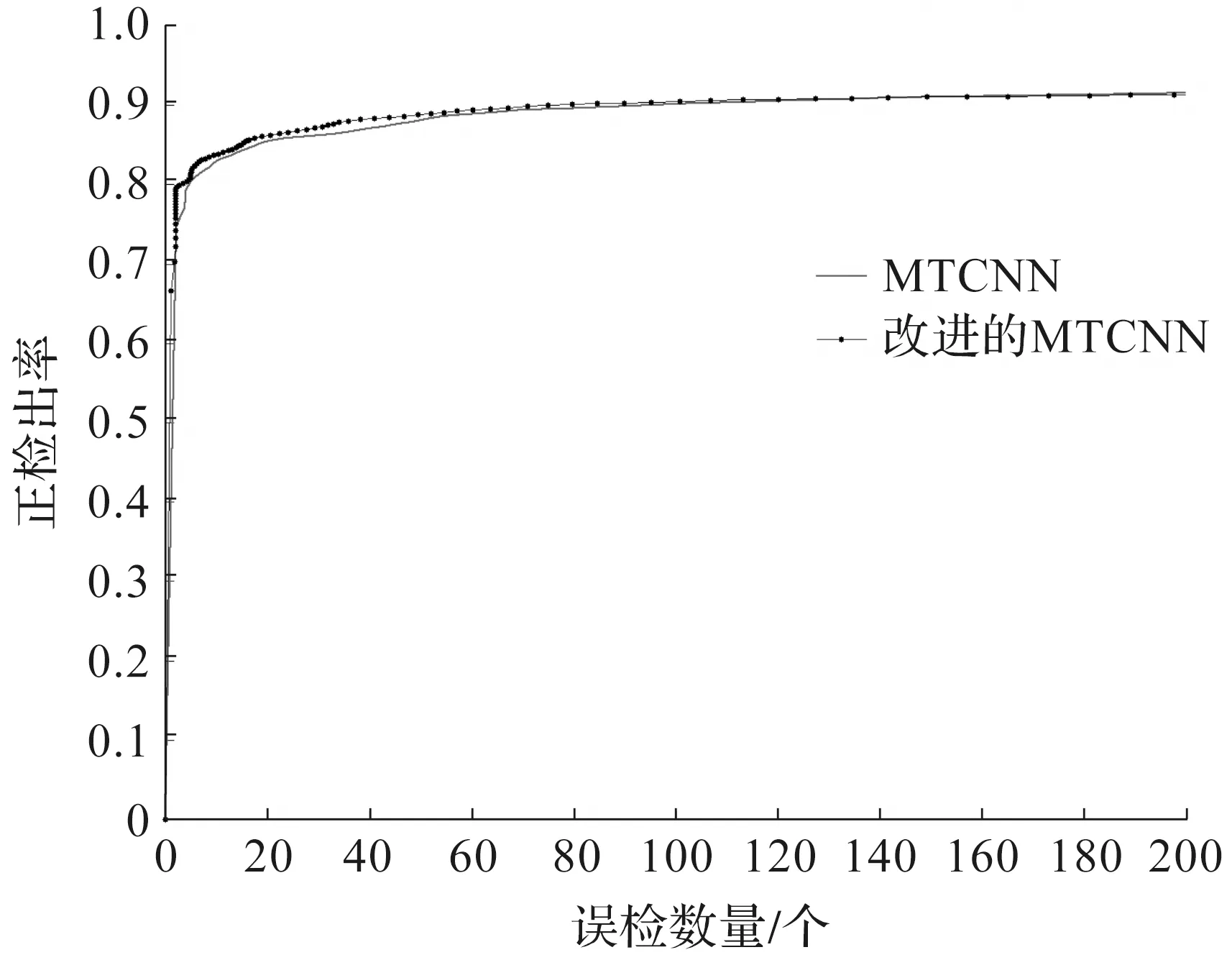
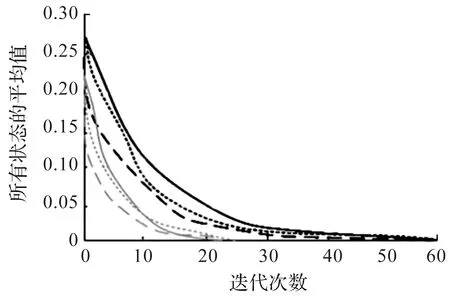
同时,提出一种在线的困难样本挖掘方法,降低了人工选择样本的难度和工作量。该方法记特征距离D的对角线元素为d1={dii}i=1,2,…,n;非对角线元素为d2={dij}i,j=1,2,…,n。在每步迭代过程中消除冗余的负样本,该方法得到的特征距离D是对称矩阵。为避免样本重复,仅挑选D的上半角矩阵参与训练:d0={dij}i,j=1,2,…,ni 因为P-Net网络是通过单尺度(12×12)图像训练,所以想要识别各种尺度的人脸,需要应用图像金字塔技术。首先将原图等比缩放(12/minsize);然后按缩放因子factor(如0.709)用上一次的缩放结果不断缩放,直至最短边小于或等于12。每种尺度的图像均需要输入模型。采用图像金字塔,在不同分辨率下检测不同尺寸的目标,该方法主要缺点是增加了计算量,主要原因是生成的“金字塔”层数越多,P-Net计算耗时越多。 因此,针对上述问题,采用多尺度密集锚框检测不同尺度的目标,从而减少图像金字塔层数。该方法在SSD,YOLO系列等优秀的目标检测模型中得到了广泛应用。 通过遍历输入图像的像素框,选出正确的目标框,并调整位置和大小,完成目标检测任务。如图1所示,以一个锚点为中心,生成3种尺寸的正方形的框(灰色、黑色、灰色中的正方形框),对每个正方形框生成2种扩展尺度的框(每种颜色的另外2个长方形),共生成9个锚框。 图1 锚框示意图 锚框的尺寸和长宽比的设计难度大,常见的设计方式有以下3种:1)人为经验选取;2)k-means聚类;3)作为超参数进行学习。YOLOv3算法[9]中锚框的长宽比是通过分析COCO数据集中对象长宽比,使用k-means估算得到的。YOLOv5算法[10]中锚框的长宽比是一个超参数,可以在模型的配置文件中配置。 采用锚框的思路,增加生成框密度,减少检测金字塔层数,生成基于锚框的稀疏图像金字塔,从而提高检测速度,改进对照图如图2所示。选用APN24来替代P-Net,APN24网络结构体如图3所示。 图2 图像金字塔改进对照图 图3 APN24网络结构 该网络的输入为一个24×24×3图像,网络输出的第一部分用于判断图像中是否存在人脸。输出向量大小为1×1×2×k,即2k个值,其中k表示锚框数量。网络输出的第二部分是人脸框位置偏移量,偏移量采用Fast-RCNN的方式,即中心点偏移值和宽高对数偏移值,输出向量大小为1×1×4×k,即4k个值,其中k表示锚框数量。 深度可分离卷积方法[11-13]在MobileNet系列中得到了深入的应用。深度可分离卷积由深度卷积和逐点卷积两个部分组成。深度卷积的一个卷积核负责一个通道,一个通道只由一个卷积核进行卷积,具体情况如图4所示。逐点卷积的操作与常规卷积操作相似,其卷积核大小为1×1×M,其中M是前一层的通道数,具体情况如图5所示。 图4 深度卷积示意图 图5 逐点卷积示意图 假设存在这样一个场景,上一层有一个5×5大小,3个通道的特征图,需要通过卷积操作,输出4个通道的特征图,并且尺寸大小前后一致。对比常规卷积和可分离卷积的参数量和计算量的差异,具体情况如表1所示。 起初只是要求将打乱顺序的有丝分裂各个时期的细胞进行排序,这样的设计可以考查学生对细胞有丝分裂各个时期特点的掌握程度;之后增加对细胞中染色体、染色单体和D N A分子的数目变化这一重点内容,在游戏的过程中,这对学生具有足够的挑战性。在游戏设计过程中也不应该将太多的知识点包含进来,因为这样将会使游戏的难度过大。 表1 常规卷积和可分离卷积的参数量和计算量的差异 常规卷积的参数量:3×3×3×4=108;计算量:3×3×3×4×5×5=2 700 FLOPs。可分离卷积的参数量:3×3×3+1×1×3×4=41;计算量:3×3×3×5×5+1×1×3×4×5×5=975 FLOPs。相同大小的输入,同样相同大小的输出,可分离卷积的参数量是常规卷积的约1/3,计算量是常规卷积约1/3。采用可分离卷积改造R-Net网络结构,去掉池化层,将前两个卷积层的步幅修改为2,第3个卷积层修改为可分离卷积层,网络结构的改进情况如图6所示。 图6 R-Net网络结构改进对照图 对比R-Net网络结构和改进的R-Net网络结构的参数量和计算量的差异,具体情况如表2所示。改进的R-Net网络结构的计算量约为原来的1/3,从而提高R-Net检测速度。 表2 R-Net和改进的R-Net的参数量和计算量的差异 从WIDER Face数据集随机裁剪获取正样本、负样本和部分样本,从CelebA数据集随机裁剪获取关键点人脸,用于模型训练。FDDB数据集用于模型测试。 1)WIDER Face数据集是人脸检测基准数据集。该数据集的图像来源为WIDER数据集,从数据集随机挑选32 203张图像并进行人脸标注,总共标注了393 703个人脸数据。同时,每张人脸均附带详细信息,包括模糊程度、遮挡、表情、光照和姿态等。这些人脸在遮挡、妆容、姿势、尺度、表情和光照上均存在较大的差异。在数据集中方面,根据事件场景的类型分为了61类。对于每个事件类别,随机选择40%,10%,50%的数据分别作为训练、验证和测试集。 2)CelebA数据库是CelebFacesattribute的缩写,是一个大规模的人脸属性数据集,拥有超过200 000张人脸图像,每张图像有40个属性标注,该数据集中的图像覆盖了大部分的姿势变化和杂乱的背景。该数据集可用作人脸关键点定位、人脸属性检测和人脸识别等计算机视觉任务的训练和测试集。 3)FDDB数据集被广泛用于人脸检测方法评价,其是最具权威的人脸检测评测平台之一。图像大部分是名人在自然环境下拍摄的图像。该数据共有5 171张人脸图像,包含彩色图像和灰度图像。图像的人脸采用椭圆标注。这些人脸以各种状态出现,包括罕见姿势、低分辨率、遮挡和失焦情况。 训练环境:操作系统采用的是Ubuntu 18.04,编程语言采用的是Python3.6,深度学习框架为Tensorflow-GPU 1.15.0,GPU加速工具为CUDA 10.0。硬件配置主要包括CPU为2张Intel Xeon Silver 4210@2.20 GHz,GPU为2张NVDIA GeForce RTX 2080 Ti@11 GB,RAM为64 GB。 网络模型:改进的MTCNN由APN24、修改后的R-Net和O-Net3级网络结构组成,训练多个任务(人脸/非人脸分类、包围盒回归、人脸关键点位置)的人脸框检测和关键点检测算法。选用APN24来替代P-Net,采用锚框思路增加生成框密度,减少图像金字塔层数,构造基于锚框的稀疏图像金字塔,锚框数选用n=4。对R-Net的卷积层进行深度可分离卷积改造,去掉池化层,将前2个卷积层的步幅修改为2,第3个卷积层修改为可分离卷积;从而减少参数量和计算量,用于提高R-Net检测速度。O-Net网络结构保持不变。 由于网络级联,在训练时按照APN24、修改后R-Net和O-Net的顺序进行训练。因此,前面网络性能对后面的网络产生影响。在每个网络训练前都会生成训练样本,由前面网络生成第2个和第3个网络训练样本。为了提高算法精度,网络使用在线挖掘困难样本策略进行训练。即每个mini-batch所有样本损失值的前70%的样本loss值用于计算后向传播。 APN24采用和P-Net一样截取图像切片的方式进行训练,因为使用了多锚框思想,每个图像切片需要为每一个锚框都分配一个label值和一组回归值。笔者项目中锚框数n=4,因此每个图像切片有n(4+1)=20个标签数据(和YOLO相似)。 为了使样本采样充分且分布均匀,获得真实人脸对应不同尺寸锚框的样本,正样本和部分样本的采样方式:1)在真实人脸框附近获取IOU>0.5的随机选框;2)将选框中心固定,尺寸缩放scale^i(i=0,1,2,3)倍,获得裁切框;3)计算裁切框对应的各个锚框,并计算其与真实人脸框的IOU;4)将裁切框缩放至24×24并保存图像和标签;循环式(1~4),生成正样本和部分样本。 负样本的采样包括两部分:一是在原图中随机尺度随机位置切片;二是仿照正样本和部分样本的方式在真实人脸附近选取随机选框,其作用是采集到真实人脸附近的困难负样本。 当生成APN24训练样本数据时,回归值特征采用Fast-RCNN的方式,即输出中心点偏移值和宽高对数偏移值,正样本、部分样本、负样本的IOU阈值分别设置为0.5,0.3,0.2;当生成R-Net和O-Net样本数据时,采用传统MTCNN的方式,即输出边界偏移值,正样本、部分样本、负样本的IOU阈值分别设置为0.65,0.4,0.3。 当APN24和R-Net训练时,正样本、部分样本、负样本的数据比例为1∶1∶3;当O-Net训练时,正样本、部分样本、负样本的数据比例为1∶1∶1,其原因是R-Net检测出的候选框中负样本比例较低。 测试环境:前向推理框架使用OpenCVDNN模块。Windows平台:Windows 10操作系统,处理器为Intel(R)Core(TM)i7-1165G7@2.80 GHz 2.80 GHz,编译工具为Visual studio 2015;Android平台:Android 7操作系统,处理器为RK3399双核Cortex-A72及四核Cortex-A53@1.8 GHz,编译工具为Android Studio。用C++语言开发。 采用FDDB数据集对MTCNN和改进的MTCNN在Windows和Android平台使用CPU处理器,采用单线程方式进行算法对比测试,测试结果如图7和表3所示。由测试结果可以看出:改进的MTCNN在检测精度得到了提升的情况下,检测速度提升幅度较大。 表3 MTCNN和改进的MTCNN在单线程情况下的速度对比测试结果 图7 MTCNN和改进的MTCNN精度对比测试结果 为了进一步分析设计方法的性能,验证设计方法的收敛性,改进算法前后的对比结果如图8所示。图8中:深色实线为MTCNN算法滤波处理收敛性曲线;深色段虚线为MTCNN算法整体收敛性;深色点虚线为MTCNN算法的卷积层收敛性曲线;浅色曲线为改进的MTCNN算法曲线,其对应的收敛性曲线与MTCNN算法一致。由图8可知:MTCNN算法改进前,所有状态在50次迭代时达到收敛。改进的MTCNN算法在25次迭代时达到了收敛效果,算法的滤波处理收敛性在20次迭代时达到了收敛状态,其他处理过程在25次时达到收敛状态。两种方法相比,改进后比改进前迭代降低了25次,因此,测试结果表明改进的MTCNN的人脸检测方法有效提高了算法的收敛性。 图8 MTCNN和改进的MTCNN收敛性对比测试结果 为了提高人脸检测效果和检测速度等,提出了基于锚框稀疏图像金字塔的MTCNN人脸检测方法。该方法引入锚框思路,构建基于锚框的稀疏图像金字塔,采用深度可分离卷积的思路改进R-Net网络结构,实现人脸检测。通过实验分析可知:改进方法的人脸检测耗时最低平均值仅为8.5 ms,在迭代25次时达到收敛状态。因此,测验结果验证了笔者算法框架的合理性。在未来的研究中,将进一步对网络结构进行优化,使用更多的数据集对网络模型进行训练,提高人脸的检测能力和检测效率。
3 改进MTCNN
3.1 基于锚框的稀疏图像金字塔


3.2 深度可分离卷积


4 实验结果
4.1 训练和测试数据集
4.2 网络模型训练
4.3 测试结果
5 结 论
