企业数据联邦学习的收益分享机制研究
2023-06-15张潇扬窦一凡张成洪黄丽华
张潇扬, 窦一凡, 张成洪, 黄丽华
(复旦大学 管理学院,上海 200433)
1 引言
数据作为最具时代特征的生产要素,逐渐成为我国深化发展数字经济、推动企业和社会治理数字化转型的核心引擎。企业推进数字化转型,走向数据智能驱动的运营需要多模态多来源的数据为创新提供原料[1,2]。然而,“数据孤岛”已成为当下束缚企业进一步探索数据价值,社会进一步推动数字经济发展的“卡脖子”问题。推进数据要素流通,促进企业间的数据融合使用和协同创新[3],已成为释放数据的战略基础资源作用[4]的不二之举。
以联邦学习为代表的隐私计算方式已成为推动数据流通的重要的技术解决方案。传统的机器学习方法往往需要依赖于数据资源的跨组织聚合以形成数字产品,但面临着严峻的隐私保护、安全与合规挑战[5]。相较而言,联邦学习是一种既联合多方又不共享各方数据资源的分布式学习框架,在保障数据隐私保护、安全及合法合规的基础上,实现数据共享,共同建模[5-7]。
然而,技术的逐渐完善并未带来应用的广泛普及,以及数据要素流通的繁荣。我国在数据市场的早期探索中发现了包括交易成本问题[8]、数据价值评估问题[9]等诸多问题。其中作为数据治理体系的重要组成部分[10],激励企业参与的收益分享机制设计已成为推进数据要素流通的重要问题,也是联邦学习中的重要研究问题[5,11-13]。目前已有一些文献提出了联邦学习中可能的收益分享机制,包括平等收益分享机制、个体收益分享机制与边际收益(损失)分享机制[14-17]等。在此基础上,Zhang等[18]讨论了上述机制如何激励具有相同数据量的数据提供方参与联邦数据投入的问题。然而,在实践中,具有相同数据量的参与者的情形有限,更多的情形是来自不同行业、拥有不同规模数据的企业参与联邦学习的应用探索。比如,百度点石联邦学习平台作为联邦学习的发起者,支持政府部门的政务数据、银行机构等不同行业的参与者一起进行联邦学习的应用探索。其中政府部门、银行机构等均拥有高质量的数据,但是数据规模和数据内容均不同。可见,联邦学习的主要挑战之一是如何激励拥有不同规模的异质数据的参与者参与联邦学习[18],但目前仍没有关于异质数据提供方在不同收益分享机制下如何进行是否参与联邦学习的决策方面的相关讨论。
针对上述问题,本文从经济学的视角提出了一个完全信息下的静态模型来考察联邦学习各方的参与激励。具体而言,本文基于上海富数科技公司正在开展的联邦学习应用的一个实际案例来研究在不同收益分享机制下异质数据提供方如何进行联邦决策,以及联邦如何达成的问题,其中数据提供方处于不同的行业,数据规模存在差异。本文的目标是分析联邦学习平台该如何设计最优的收益分享机制,以吸引异质数据提供方加入联邦。本文的发现弥补了联邦学习相关文献的空白,并且对于数据要素流通实践具有指导意义。
2 文献综述
联邦学习的概念最早由谷歌公司提出,其主要思想是基于分布在多个设备上的数据集构建机器学习模型,并防止数据泄漏[19,20]。之后,Yang等[5]将联邦学习定义为所有保护隐私的去中心化协作的机器学习技术。传统机器学习方法直接将数据于本地聚合并建模,而联邦学习的核心思想是在多个数据源共同参与模型训练时不需要进行数据资源的跨域流通,而是通过交互模型中间参数进行模型联合训练,以实现数据隐私保护和数据共享分析的平衡,达到“数据不动算法动”的数据应用模式[5-7,11]。在隐私保护的同时,联邦学习并没有牺牲模型的准确度,诸如SecureBoost[21],CORK[22]等算法能达到与将数据聚合的集中式非隐私保护方法相同的准确度,即无损联邦学习(lossless federatedlearning)。梁锋等[11]提出了目前联邦学习存在的主要问题,包括客户端资源受限问题(如计算、通信资源)、客户端在线率低、贡献与回报不平问题等。其中前两种问题已有多种技术解决方案,如节省服务端的计算成本的联邦矩阵分解算法(federatedMF)[23]、通过本地多次迭代训练来降低通信成本等[24]。本文的研究旨在利用激励机制设计来解决贡献与回报不平等问题。
当下,联邦学习激励机制设计问题得到了广泛关注。目前已有大量文献提出相应解决方案,可以划分为贡献度驱动[17]、信誉值驱动[25,26]与资源分配驱动[27-30]的激励机制设计三类[13]。贡献度驱动激励机制关注如何吸引更多的数据量与更高数据质量。如Yu等[16]综合考虑贡献、模型成本、模型遗憾与模型时间遗憾等因素,提出了联邦激励方案(federatedlearningincentive,FLI)。该方案能够在保证公平的同时,激励提供大量高质量数据的数据所有者。在信誉值驱动方面,urRehman等[26]提出了一个基于区块链的信誉系统。通过智能合约,该系统能够聚合、计算和记录联邦学习中每个参与者的声誉,从而激励参与者良性行为。但该方法面临评分机制不够客观,缺乏质量分析等问题。对此,Kang等[25]提出了一个基于契约理论的激励机制。该机制利用声誉衡量可靠性和可信赖性,激励拥有高质量数据的高声誉设备参与学习。资源分配驱动激励机制关注如何在异构客户端之间进行资源配置问题[27-30],包括计算资源配置与通信资源配置。如Zhan和Zhang[29]实现了模型训练时间与参数服务器支付之间的最优权衡,Pandey等[28]通过构建效率成本模型,在模型参数交换过程中考虑传播效率。
本文关注以数据量作为贡献度的激励机制设计问题,主要参考了平等收益分享机制、个体收益分享机制、边际收益/损失分享机制[14-17]。平等收益分享机制(egalitarianprofitsharing)是一种收益平摊的方法,其不足之处在于会导致“搭便车”现象,即不同贡献度的数据提供方获得相同的收益,这会迫使高贡献度数据提供方不愿意参与联邦学习[14,15]。个体收益分享机制(individualprofit sharing)的核心思想是通过衡量只有该参与者参加到活动中时产生的收益[14]来分配给每个参与者。边际收益分享机制(marginalgainprofitsharing)和边际损失分享机制(marginallossprofitsharing)分别衡量参与者加入和离开联邦时整体联邦学习绩效价值的改变[15],来对参与者进行收益分配。从以上分享机制出发,Zhang等[18]检验了一个连接同质数据提供者的平台该如何选择最优的激励机制以实现利润最大化。然而,联邦学习的主要挑战之一是如何激励拥有大量数据的客户在其本地数据集上训练算法[18],本文的模型考虑了异质数据提供者在不同的激励机制下会如何进行数据联邦加入决策。
3 研究模型的构建
3.1 一个实践案例
上海富数科技有限公司(https://www.fudata.cn/,以下简称富数科技)成立于2016年,是我国目前隐私安全计算的领跑者,专注于联邦学习、多方安全计算、匿踪查询等加密计算领域。该公司2021年入选福布斯中国企业科技50强,自主研发的隐私计算产品Avatar平台与商业应用落地处于市场领先地位,是我国首批获得银行卡检测中心、中国信通院、中国公安部的权威认证的公司,落地场景覆盖金融、政务、运营商、电力等各个数据相关领域。
有一个典型的应用场景是基于非金融数据的增信评估。消费信贷的征信评估往往以二代征信数据以及贷款申请信息为主要评估基础,而非金融数据有很强的预测性,但并未大规模应用于信用评估中。如何合规合法地引入外部非金融数据为银行征信赋能是一个非常重要的联邦学习的需求应用。
富数科技基于其联邦学习引擎,可以对来自电信运营商、银联、航信数据以及其他数据资源等不同企业的千万级数据、几千个维度,通过多方数据源进行联合建模,并通过持牌个人征信公司进行输出,为银行的消费信贷提供合规有效的行业赋能,如图1所示。

图1 联邦学习的应用场景:非金融数据的增信评估
3.2 基本模型
基于图1所示,我们考虑联邦发起方作为中心节点,连接异质数据的参与者构成的数据联邦网络。该网络联邦发起方是为联邦学习提供基础设施服务的富数科技,提供服务平台的同时也提供联邦学习算法。我们假设该富数科技(联邦发起方)是收支平衡的,即不参与提供数据与收益分享,将联邦学习取得的收益分享给各数据提供方。
数据提供方的数据存在异质性。简便起见,我们考虑两类异质的企业,即拥有数据分别为dA(如电信运营商)和dB(如银联。不失一般性,我们将dA标准化为1)的A类企业和B类企业,对应企业数量为NA和NB。该网络中每个数据提供方为策略性(strategic)的,在观测到公开信息(数据量)后,他们能够推测其他数据提供方的决策,并选择是否加入联邦。假定同类企业面临着相同的权衡,因此会做出相同的联邦决策。我们记i类企业的联邦决策为si={0,1},i∈{A,B}。
选择加入数据联邦(即si=1)的数据提供者能够通过联邦学习实现数据的跨组织协作。这类似于传统机器学习中直接将数据聚合为总训练集,对应总数据量我们用常替代弹性生产函数(CES productionfunction)衡量数据联邦总产出g(d)为
其中δ∈(0,1)表示联邦学习效率,k∈[0,1]表示算法利用数据的能力。一方面,随着训练数据的增加,模型的精确度更加难以提高[18],即算法的精确度关于数据量规模报酬递减,我们利用k∈(0,1)来表示该特征。另一方面,如 SecureBoost[21],CORK[22]等无损联邦学习的算法能达到与将数据聚合的集中式非隐私保护方法相同的准确度,因此考虑无损联邦学习的场景,即δ=1。
此外,数据提供方加入联邦需要支付成本,如企业数据加工成本以及在联邦计算过程中产生的计算、硬件设施及通信成本。我们考虑线性成本函数形式如下
其中c表示固定边际成本。
3.3 收益分享机制
正如2.1节中的讨论,我们考虑三种收益分享机制,即平等收益分享机制、个体收益分享机制与边际效用分享机制。在三种机制下,参与方i从联邦总收益R中获得的收益ri为
其中vi表示参与方i的贡献度,表示所有加入联邦的企业贡献度之和。在不同机制下,参与方的贡献度衡量方式不同,对此我们说明如下。
(1)平等收益分享机制:沿用Yang等[14],Gollapudi等[15]中关于平等分配的讨论,数据联邦的产出平均分配给所有参与方,即各参与方拥有相同的贡献度
(2)个体收益分享机制:沿用Yang等[14]中个体收益分享方法,参与方的贡献度衡量为其单独形成联邦时产生的收益,即
(3)边际效用分享机制:边际效用分享机制综合了Gollapudi等[15]中边际收益/损失分享机制,其中两种方法的衡量都是基于序贯的。在静态的模型中,我们将以上两种机制统一为边际效用分享机制,该机制将参与方的贡献度衡量为其加入/离开时产生的边际效用/损失,即
3.4 企业效用与决策
综上,我们考虑数据提供方i(i∈{A,B})的权衡。简便起见,我们记数据提供方i在平等分享机制、个体收益分享机制、边际效用分享机制的效用分别为UEiM,UIiM,UMiM。可见,若全部数据提供方选择加入联邦时,数据提供方i(i∈{A,B})加入联邦的收益为
数据提供方i选择加入联邦(si=1)当且仅当Uξi≥Ui0,其中ξ表示不同的分享机制,Ui0表示数据提供方i的外部选择,我们不妨设为0,即Ui0=0。以上条件表明,只有加入联邦后根据不同分享机制所获得总利润的收益分成不小于该数据提供方加入联邦所需要的成本(如数据处理成本、协调成本等),数据提供方才会选择加入联邦(si=1)。否则,数据提供方选择不加入联邦(si=0),不会参与为由发起方提供的算法提供数据。
为了更好地阐述模型的合理性,我们还需要对以下几点进行说明。首先,上述模式是静态模型中的自由数据联邦,假设数据提供方在加入联邦后取得一次性收益并支付成本。现实中,数据联邦中往往是动态并且多次学习的。上述模型可以认为是将多次学习的收益或多周期的收益支付等过程一并计算到一次性收益中,这没有牺牲一般性。其次,我们认为联邦学习模型结果是竞争性的,即假设联邦学习模型只能由发起方(或数据联邦)利用,而各数据参与方并不能独立地使用该模型,该假设在很多联邦学习场景是成立的。最后,我们没有在产出中考虑数据(或算法)的不确定性。加入不确定性与参与方预期可能出现难以找到均衡或者多均衡解的情况,我们将其放到未来工作中。
4 分析结果
基于上述讨论,首先,我们检查在参与方数据存在异质性的情况下会如何进行加入联邦的决策。我们定义联邦决策可行域为数据提供方愿意加入联邦的条件,结合我们在3.4节中的讨论,数据提供方i选择加入联邦(si=1)当且仅当Uξi≥Ui0(=0)。进一步,我们定义联邦决策边界为数据提供方选择加入联邦的最低条件(下界),即数据提供方i的联邦决策边界为Uξi=0。其次,我们检查数据联邦会如何形成。我们定义联邦形成可行域为联邦能够形成的条件。具体来说,由于数据提供方的策略性,即便数据提供方i选择加入联邦,但数据提供方j选择不加入,联邦依然不能形成。因此,联邦形成需要所有数据提供方收益为正,即对任意数据提供方i,有Uξi≥Ui0(=0)。同样的,我们定义联邦形成边界是所有数据提供方都选择加入联邦时的最低条件(下界)。在此基础上,我们对比不同机制对于数据提供方异质性的兼容能力。最后,我们采用数值试验的形式对以上部分进行补充。
4.1 分析结论
我们首先讨论联邦决策边界,可以得到命题1。
命题1当数据存在异质性时(即dA≠dB),在三种机制下数据提供方联邦决策边界均不同。
证明在三种机制下UA=0与UB=0有且仅有一组解,即dB=dA。
不妨假设dB≥dA(=1),考虑数据提供方的决策边界Uξi=0,A类企业与B类企业决策交点的必要条件是整个联邦收支平衡,即
将(5)式带入(6)式可以解出交点的必要条件是
在三种收益分享机制下,(7)式带入UξA=0与UξB=0,可以分别得到
(1)平等收益分享机制
(2)个体收益分享机制
(3)边际效用分享机制
对于平等收益分享机制与个体收益分享机制,易知解的必要条件为dB=dA。
对于边际效用分享机制,易知dB=dA时等式(10-1)和(10-2)同时成立。我们证明,当dB>dA时,有
若(11)式成立,则(10-1)式和(10-2)式不同时成立,即证。
实际上,(11)式等价于
对(12)式左右同时除以dkB+1,并记dA/dB为x∈(0,1),记NAx+NB为y∈(1,+∞),整理为
可证左式关于x=0与x=1的极限均为0,并且为凸函数(convex,二阶导恒为正),因此成立。
命题1告诉我们,当权衡数据联邦的收益成本时,数据存在异质性的方可能有不同的决策。如图2所示,在三种不同的分享机制下,A类企业(实线)与B类企业(虚线)的联邦决策边界均仅有一个交点,即两者数据相同时(即图2中交点位于dB=dA时)。当数据存在异质性时,数据提供方联邦决策边界不同。

图2 企业联邦决策与联邦形成(NA=NB=1,c=0.7)
从图2中可见,异质性数据提供方的决策在不同机制下存在差异。由此,我们进一步探索联邦形成边界,得到命题2。
命题2当数据存在异质性时(即dA≠dB),在三种机制下联邦达成边界有差异,具体来说:
(1)在平等收益分享机制与个体收益分享机制中,若拥有数据量较大的数据提供方愿意加入,则数据量较小的数据提供方一定愿意加入,联邦形成边界与数据量大的数据提供方联邦决策边界相同。
(2)在边际效用分享机制中,若拥有数据量较小的数据提供方愿意加入,则数据量较大的数据提供方一定愿意加入,联邦达成边界与数据量小的数据提供方联邦决策边界相同。
证明不妨设dB>dA=1,我们分别证明:
(1)在平等收益分享机制与个体收益分享机制中,若UB>0,则UA>0。
由(5)式,在平等收益分享机制中,UEAM>UEBM,易知若UEBM>0,则UEAM>0。在个体收益分享机制中,UIBM>0等价于
而cd1B-k>cd1A-k,则有
这等价于UIMA>0,即证。
(2)在边际效用分享机制中,若UA>0,则UB>0。
由(5)式,在边际效用分享机制中,UMMA>0等价于
同命题1中的证明,我们有
因此有
整理即为UMMB>0。
命题2告诉我们,不同的收益分享机制会给拥有异质性数据的参与方带来不同的权衡。如图2所示,在三种机制下,数据提供方都倾向于在算法能力较强时(即k更大时)选择加入联邦,这是由于算法能力的提高能够把“蛋糕”做大,带来更高的总收益。然而,数据提供方还需要关注“蛋糕”的分配问题,即收益分享机制。在平等收益分享机制与个体收益分享机制中,数据量更大的数据提供方更难加入联邦,而边际效用分享机制则相反。这意味着,在“蛋糕”的分配上,平等收益分享机制与个体收益分享机制更倾向于小数据提供方,而边际效用分享机制更倾向于大数据提供方。
与传统机器学习相比,联邦学习对计算与通信提出了更高的要求。目前已有诸多文献提出了技术解决方案[23,24]。若企业通过该类方法降低边际成本c(如图3所示,边际成本由图2中0.7降为0.6),结合(5)式,联邦成本下降导致企业更可能加入联邦(体现在联邦决策边界下移),联邦也因此更容易形成(体现在联邦形成边界下移)。由此,我们得到推论1如下。

图3 企业联邦决策与联邦形成(NA=NB=1,c=0.6)
推论1当加入联邦成本降低时,企业更可能加入联邦,联邦更容易达成。
在实践中,企业在边际成本上可能存在差异。结合命题2与推论1,若数据量较小企业面临更高的边际成本,如拥有较差的计算、通信资源,或者较低的数据质量,则应当在机制设计上倾向于小企业,如选择个体收益分享机制。反之,若数据量较大企业面临更高的边际成本,则应考虑采用边际效用分享机制。
若平台希望通过补贴的方式来促进联邦的达成以实现社会最优,我们可以得到推论2如下。
推论2当数据存在异质性时(即dA≠dB),在三种机制下,社会最优的联邦发起方(或平台)的补贴策略不同。具体来说,对于平等收益分享机制与个体收益分享机制,应当补贴数据量较大的数据提供方;对于边际效用分享机制,应当补贴数据量较小的数据提供方。
在分析了三种机制下的参与方的联邦决策与联邦达成的基础上进一步讨论联邦中参与方数据的异质性问题。假设dB>dA=1,并且使用dB/dA∈(1,+∞)来衡量企业数据的异质性,并假设dB/dA越大则表明企业数据的异质性越强。我们首先对比平等收益分享机制与个体收益分享机制对于数据异质性的兼容能力,得到命题3如下。
命题3当数据存在异质性时(即dA≠dB),个体收益分享机制比平等收益分享机制更容易兼容异质性数据提供方。
证明对于任意dB满足UEAM>0,UEBM>0,则其一定满足UIMA>0,UIMB>0。
根据命题2,在平等收益分享机制与个体收益分享机制中,若UB>0,则UA>0。因此,我们只需要证明对于任意dB满足UEBM>0,则其一定满足UIBM>0。实际上,对于dB>dA=1,由(5)式易知UIBM>UEBM,因此成立。
由命题2可知,平等收益分享机制与个体收益分享机制的联邦达成边界均为数据量较大的参与方的联邦决策边界。由此我们绘制个体收益分享机制与平等收益分享机制下联邦可行域如图4所示,其中黑色虚线与灰色虚线分别代表个体收益分享机制与平等分享机制下的联邦形成边界。可以看出,平等收益分享机制下联邦可行域始终是个体收益分享机制的子集。因此,当k一定时,个体收益分享机制能够允许异质性更强的数据提供方加入联邦。
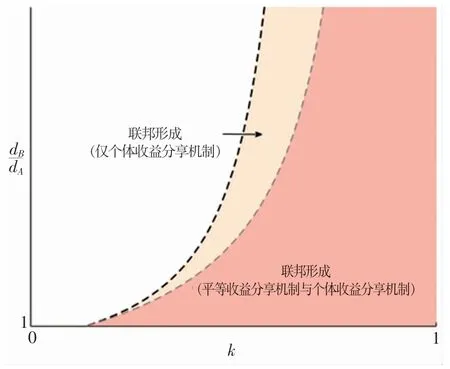
图4 个体收益分享机制与平等收益分享机制比较——联邦可行域(NA=NB=2,c=0.3)
4.2 数值观察
接下来,我们采用数值解对以上讨论进行补充。由命题2可知,不同于平等收益分享机制,边际效用分享机制的联邦形成边界为数据量较小的数据提供方的联邦决策边界。我们绘制边际效用分享机制与平等收益分享机制下联邦的可行域如图5所示,其中黑色实线与灰色虚线分别代表边际效用分享机制与平等收益分享机制下的联邦形成边界。从图5中可以发现,当联邦成本较小时,平等收益分享机制与边际效用分享机制的联邦形成边界有交点(即图5a中灰色虚线与黑色实线存在交点),而当联邦成本较大时(如图5b),平等收益分享机制联邦可行域是边际效用分享机制联邦可行域的子集。因此,可以得出观察1。

图5 边际效用分享机制与平等收益分享机制比较——联邦可行域(NA=NB=1)
观察1当数据存在异质性时(即dA≠dB),若数据成本较大,则边际效用分享机制比平等收益分享机制更容易兼容异质性数据提供方。
最后,我们考虑算法能力如何影响联邦关于数据提供方异质性的兼容能力。以个体收益分享机制为例,如图6所示,随着算法利用数据能力的提高,联邦能够兼容异质性更强的数据提供方(即图6中虚线变“高”)。因此,可以得出观察2。

图6 数据提供方异质性与算法能力(以个体收益分享机制为例)(NA=NB=2,c=0.5)
观察2当数据存在异质性时(即dA≠dB),在三种机制下联邦可兼容数据提供方的异质性关于算法利用数据能力(即k)均呈单调递增。
5 研究结论与启示
本文从联邦学习的应用实践出发,讨论了异质数据提供方在不同的收益分享机制下会如何进行联邦决策的问题。研究发现,在平等收益分享机制与个体收益分享机制中,数据量较大的数据提供方更难加入数据联邦,这表明两种机制的分配更偏向小数据提供方。而边际效用分享机制则相反。进一步,本文检验了平台该如何设计最优的收益分享机制,以吸引异质数据提供方加入联邦。研究发现,个体收益分享机制与边际效用分享机制能够兼容异质性更强的数据提供方。这表示这两种机制更能够吸引数据量大的数据提供方加入联邦学习以共同建模。
在实践上,本文的研究对基于联邦学习的数据要素流通给出了管理学的见解。首先,异质数据提供方的激励机制设计应结合考虑数据提供方的数据规模与算法能力。当潜在联邦网络中企业数据异质性较强时,只有当算法能力较强时联邦才有可能达成,即利用算法能够创造更多的产出。反之,若算法不能够带来更高的价值,则联邦学习仅在企业数据异质性较弱时才可以达成。另外,若联邦边际成本降低,则联邦网络更容易达成。其次,就联邦学习平台而言,选择个体收益分享机制与边际效用分享机制能够激励数据规模大的数据提供方加入联邦当中。另外,若平台希望通过补贴策略来激励数据提供方参与数据联邦,则应该在采用个体收益分享机制时补贴数据量较大的数据提供方,在采用边际效用分享机制时补贴数据量较小的数据提供方。
