基于数据挖掘的电力自动化系统运行数据中台资源检索技术研究
2023-06-14张旭东谢民黄建平王政
张旭东 谢民 黄建平 王政


摘要:目前,电网包含了大量多源信息数据。想要对其数据信息进行高效、准确的检索并非易事。为了解决这一问题,经过查阅文献资料,分析实际电力运行系统的数据特点及多源数据库样本,引入了基于互信息和并行计算理论的优化式决策树算法,并在此基础上构建了决策树模型,最后设置仿真实验以各种系统数据库为样例对模型进行模拟验证。结果发现基于互信息和并行计算的优化式决策树算法对于大型数据库可以实现迅速、精确、有效的多源数据检索目的,同时还可以完成对实时数据的有效处理。该算法按照代表性特征集合直接对数据库的原始数据进行挖掘,并根据索引信息量大小进行排序。以改进的决策树算法为核心技术的数据挖掘方法具有较高的精度,对于电网的多源数据信息能够较好的实现挖掘,不但能避免数据重复现象,而且可以满足工程的决策要求,为提高电网数据的高效挖掘提供了可靠的技术支撑。
关键词:数据挖掘;电力运行系统;互信息;决策树;仿真实验
中图分类号:S816.2文献标志码:A文章编号:1001-2443(2023)02-0119-07
引言
目前,随着智能电网的持续开发,电网运维产生的数据量呈指数级扩大,电力行业开始进入大数据时代[1]。电力大数据不仅包含了大数据的广义特征,即数据量大、数据类别多、数据发展速度快、数据价值密度低,还承载着能源行业的独特标志,包括大量多维时空数据、相关数据和实时响应数据[2]。另外,这些电力数据分别集成在贯通调度管理系统、生产管理系统、地理信息系统、用电信息管理系统等不同的信息管理系统中。并且,不同的管理平台之间的数据互不兼容,它们之间包括很多重叠数据[3]。另一方面,这些多源数据也具有互补关系,包括多种多样的电力运行信息。因此,如何利用现有信息管理系统的信息,迅速、精确地检索所需信息,是构建配电网多维数据融合管理系统的基础和关键[4]。
现阶段,电力物联网发展正处于泛化的特殊时期,因此,对于电网多源数据的检索就需要更加准确、高效以及采用独特的开发方法。也就是说,现有的信息检索方法大多与电网数据特征不相匹配,所以找到适应电网数据特点的信息检索方法就显得尤为关键[5]。例如,基于电网事故信息并且采取分类以及回归算法的检索方式的提出[6];以电力数据维数特征为背景,给出以流形排序为基础的电网数据信息检索方式[7];针对电网数据组成结构繁杂的特点,提出的一种以B+树和倒排索引相结合的多模块索引结构[8];根据海量电网状态监测数据管理平台的架构体系和作用,设计的一种基于Map Reduce的海量数据检索方式[9];利用模糊特征聚类方法对电力数据实施划分,提取特征向量,然后采取云计算手段完成分布式检索[10]。然而,决策树算法作为一种适用于数据分类和检索的手段,不仅可以提高检索的精准度,也能实现信息检索速度的加快。现阶段,常用的决策树核心算法为ID3(Iterative Dichotomiser 3)算法,该算法利用信息熵来对分类进行判断,并且对系统的有序程度进行衡量,以此来完成区分任务。ID3算法不但能够在样本划分时以信息最大属性为选取依据,而且还可以对算法的速度以及精度进一步加强[11]。另外,除了ID3算法,其它常用的决策树算法还包括C4.5(Classification 4.5)、Sprint、PUBLIC(Pruning and Building Integrated in Classification)等算法[12],这些算法都是以ID3算法为基础优化形成的,所以对于更多的实际问题都能够进行针对性的处理。
现有的电力系统数据检索技术大部分是通过对海量数据库的直接检索来完成用户的查询要求,这种方式显然存在花费时间长且准确度较低等问题。另外,大部分检索方法的适用范围较局限,比如只适用于文本数据和Web数据,但对存在多源数据的电力系统数据库进行检索时,就显得不太适用。因此,为了解决上述问题,首先将决策树算法引入到电力运行系统中,其次利用互信息理论对决策树算法进行优化,以此设计出电力系统检索模型,最后设置仿真实验对算法以及检索模型效果进行验证。希望此方法能够提高电力系统的信息检索能力,从而方便相关工程人员使用。
1 材料与方法
1.1 改进的决策树信息检索算法
1.1.1 决策树算法 决策树算法是一种逼近离散函数值的方法。它是一种典型的分类方法,首先对数据进行处理,利用归纳算法生成可读的规则和决策树,然后使用决策对新数据进行分析。本质上决策树算法是通过一系列规则对数据进行分類的过程[13]。
因为决策树算法是通过构造决策树来发现数据中蕴涵的分类规则,所以,如何构造精度高、规模小的决策树就是决策树算法的核心内容。决策树构造可以分两步进行。第一步,决策树的生成:由训练样本集生成决策树的过程。一般情况下,训练样本数据集是有一定综合程度的,用于数据分析处理的数据集。第二步,决策树的剪枝:决策树的剪枝是对上一阶段生成的决策树进行检验、校正的过程,主要是用新的样本数据集(称为测试数据集)中的数据校验决策树生成过程中产生的初步规则,将那些影响准确性的分枝剪除。
1.1.2 基于互信息的决策树算法 互信息是计算语言学模型分析的常用方法,它度量两个对象之间的相互性。在过滤问题中用于度量特征对于主题的区分度。互信息的定义与交叉熵近似。互信息本来是信息论中的一个概念,用于表示信息之间的关系,是两个随机变量统计相关性的测度,使用互信息理论进行特征抽取是基于如下假设:在某个特定类别出现频率高,但在其它类别出现频率比较低的词条与该类的互信息比较大。通常用互信息作为特征词和类别之间的测度,如果特征词属于该类的话,它们的互信息量最大。由于该方法不需要对特征词和类别之间关系的性质作任何假设,因此非常适合于文本分类的特征和类别的配准工作[14]。
互信息可定义为:
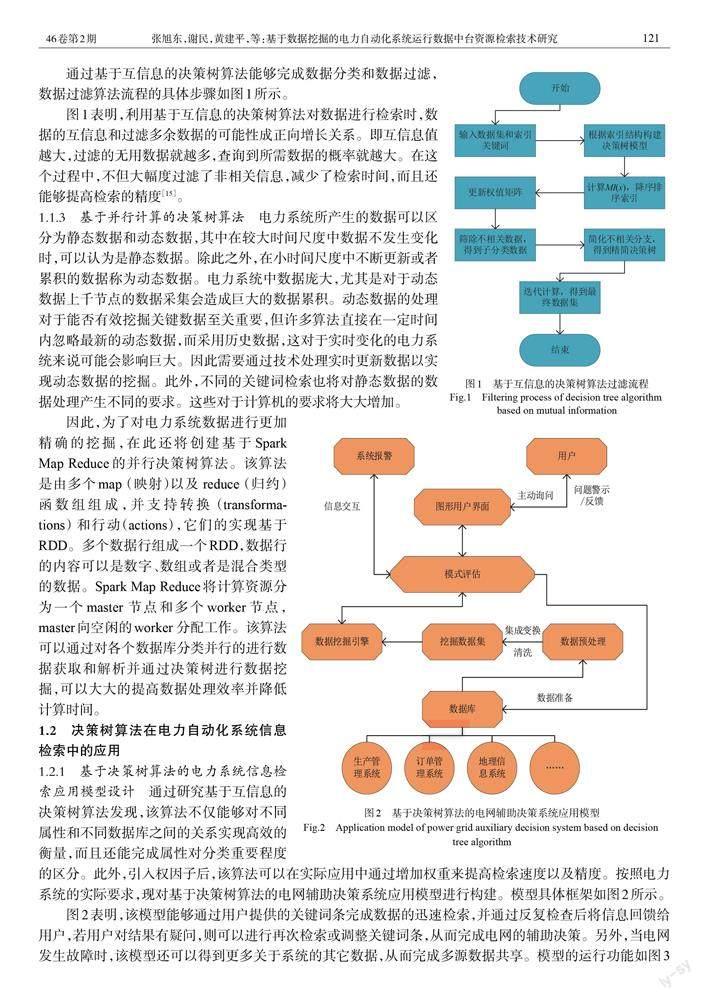
通过基于互信息的决策树算法能够完成数据分类和数据过滤,数据过滤算法流程的具体步骤如图1所示。
图1表明,利用基于互信息的决策树算法对数据进行检索时,数据的互信息和过滤多余数据的可能性成正向增长关系。即互信息值越大,过滤的无用数据就越多,查询到所需数据的概率就越大。在这个过程中,不但大幅度过滤了非相关信息,减少了检索时间,而且还能够提高检索的精度[15]。
1.1.3 基于并行计算的决策树算法 电力系统所产生的数据可以区分为静态数据和动态数据,其中在较大时间尺度中数据不发生变化时,可以认为是静态数据。除此之外,在小时间尺度中不断更新或者累积的数据称为动态数据。电力系统中数据庞大,尤其是对于动态数据上千节点的数据采集会造成巨大的数据累积。动态数据的处理对于能否有效挖掘关键数据至关重要,但许多算法直接在一定时间内忽略最新的动态数据,而采用历史数据,这对于实时变化的电力系统来说可能会影响巨大。因此需要通过技术处理实时更新数据以实现动态数据的挖掘。此外,不同的关键词检索也将对静态数据的数据处理产生不同的要求。这些对于计算机的要求将大大增加。
因此,为了对电力系统数据进行更加精确的挖掘,在此还将创建基于Spark Map Reduce的并行决策树算法。该算法是由多个map (映射)以及 reduce (归约) 函数组组成,并支持转换 (transformations) 和行动(actions),它们的实现基于RDD。多个数据行组成一个RDD,数据行的内容可以是数字、数组或者是混合类型的数据。Spark Map Reduce將计算资源分为一个master 节点和多个worker节点,master向空闲的worker 分配工作。该算法可以通过对各个数据库分类并行的进行数据获取和解析并通过决策树进行数据挖掘,可以大大的提高数据处理效率并降低计算时间。
1.2 决策树算法在电力自动化系统信息检索中的应用
1.2.1 基于决策树算法的电力系统信息检索应用模型设计 通过研究基于互信息的决策树算法发现,该算法不仅能够对不同属性和不同数据库之间的关系实现高效的衡量,而且还能完成属性对分类重要程度的区分。此外,引入权因子后,该算法可以在实际应用中通过增加权重来提高检索速度以及精度。按照电力系统的实际要求,现对基于决策树算法的电网辅助决策系统应用模型进行构建。模型具体框架如图2所示。
图2表明,该模型能够通过用户提供的关键词条完成数据的迅速检索,并通过反复检查后将信息回馈给用户,若用户对结果有疑问,则可以进行再次检索或调整关键词条,从而完成电网的辅助决策。另外,当电网发生故障时,该模型还可以得到更多关于系统的其它数据,从而完成多源数据共享。模型的运行功能如图3所示。
(1) 数据处理:通过处理缺失数据和问题数据来达到提高数据质量的目的。此外,在数据处理的过程中,数据集成会把多源数据组合为整体数据集,数据的转变能够将数据进行规范化处理以此得到更贴切实际的呈现方式。
(2) 数据挖掘:数据挖掘工作包含实时性和精确度等重要特点。而针对数据的实时性,可利用Boosting手段,通过把新数据引入到决策树中,以此产生决策树集合,从而加大数据挖掘的深度。
(3) 模式评估:针对挖掘的数据是否有效,需要对其进行验证以及评价。第一步是将数据与数据库不断对比,以此确定数据的精度。
(4) 用户交互:在此功能下,用户能够自主进行数据检索,建立数据要求。
(5) 系统主动问询:在该系统中,用户不但可以自主查询数据,并且系统还设置了系统接口。
1.2.2 仿真实验 为了验证基于互信息和并行计算的决策树算法的模型的实用性,首先利用实验室环境来搭建仿真平台,其次通过提出的检索模型对生产管理系统数据库Oracle、地理信息系统数据库ArcSDE(Spatial Database Engine)以及监控和数据采集系统数据库SCADA(Supervisory Control And Data Acquisition)进行数据检索,最后记录检索所花费的时间以及分类结果。
2 结果与分析
2.1 改进决策树算法的性能
2.1.1 改进前后的决策树算法的信息检索性能 将改进的决策树算法与传统的ID3算法进行比较后得到的结果如图4所示。
图4表明,改进的决策树算法和传统的ID3算法在对不同数据集进行数据挖掘时,其算法的性能存在差异。对于生产管理系统数据集,ID3算法下的数据挖掘精度为99.59%,改进决策树算法在人工常量设置为1和灵活值时的数据挖掘精度分别为99.67%和99.72%;对于地理信息系统数据集,ID3算法下的数据挖掘精度为90.02%,改进决策树算法在人工常量设置为1和灵活值时的数据挖掘精度分别为93.92%和94.27%;对于监控和数据采集系统数据集,ID3算法下的数据挖掘精度为94.61%,改进决策树算法在人工常量设置为1和灵活值时的数据挖掘精度分别为95.85%和96.12%。由此说明,改进的决策树算法对于数据集的数据挖掘更加精确。
2.1.2 基于决策树算法的信息检索方法的实际应用效果 为进一步验证基于决策树算法的信息检索性能,选取 500 kV 变电站作为测试试点,实验数据共 96.2 MB。其中包含一次设备信息6万余条,天气数据20 MB。通过准确率和召回率证明变电站设备信息决策树算法的检索效果,并同时与传统的关键词检索方法进行比较,得到的结果如表1所示。
表1表明,基于互信息和并行计算的决策树检索方法在准确率和召回率两个指标上整体高于传统的关键词检索方法。在信息检索条件为3时,指标相差最大。以上数据表明,基于互信息和并行计算的决策树检索系统能够满足日常检索需求,它可以快速有效的检索设备信息,能减少错误操作,提高智能变电站的安全性。
2.2 電力系统信息检索应用模型效果
2.2.1 生产管理系统数据库检索分类结果 利用基于改进决策树算法的电力系统信息检索应用模型对生产管理系统数据库的数据进行检索分类,得到的结果如图5所示。
图5表明,利用该检索模型对生产管理系统数据库进行数据分类,当分类器中数据量为20、15、12、10、3时,模型挖掘出的可用数据量分别为1、3、5、5、2。以上说明该检索模型对于数据集的挖掘分类具有一定效果。
2.2.2 不同数据库数据检索所花费的时间 利用提出的检索模型对生产管理、地理信息以及监控和数据采集三种系统数据库的数据进行检索,并不断提高数据量级别,检索花费时间如图6所示。
图6表明,对于不同的检索条数,该模型检索所花费的时间不同。当检索条数分别为0.8万、1.6万、12万、32万、63万、130万时,该模型检索所花费的时间分别为0.04s、0.07s、0.61s、2.12s、4.17s、7.82s。以上结果表明,随着检索条数的不断增加,该模型检索所花费的平均时间越来越小。这充分说明了基于互信息决策树的分类方法的适用性。
3 结论与讨论
目前,将电力系统中的海量数据进行高效提取从而更好的辅助工程人员决策是一项关键问题。通过研究发现,现阶段的信息检索技术存在单一性、数据不完整性等诸多局限性。针对数据库信息的特点,研究所做工作以及得到的结论如下:(1) 设计了一种基于互信息的决策树算法,利用互信息对索引信息量进行判断,从而对多源数据关键词实现快速检索,并尝试将并行计算加入到决策树算法当中,实现多种电网系统数据的精确挖掘;(2) 以基于互信息的决策树算法为基础,对电力系统应用的电网辅助决策系统模型进行了搭建,此模型可以实现对当前电网信息的快速检索以辅助用户决策;(3) 基于互信息和并行计算的决策树检索方法在准确率和召回率两个指标上整体高于传统的关键词检索方法。
不足之处在于设计的信息检索方法在实际的电力系统中的应用较少,后续将针对实际应用进行研究,旨在进一步提高电网数据的挖掘能力和效果。
参考文献
[1] 赵海波. 电力行业大数据研究综述[J]. 电工电能新技术, 2020, 39(12):11.
[2] 吴雷. 能源互联网下电力大数据的特征及应用分析[J]. 科技创新导报, 2021, 18(8):3.
[3] 彭冰月, 张宸, 于翔,等. 基于数据系统的电力杆塔共享运营策略探析[J]. 机电信息, 2021(23):2.
[4] ZHANG Y, CONG W, LI G, et al. Single-ended MMC-MTDC line protection based on dual-frequency amplitude ratio of traveling wave[J]. Electric Power Systems Research, 2020, 189(3):106808.
[5] DING Z, WANG J, CHENG Y. A long short-term memory network-based intrusion detection method for power grid middle platform[J]. Journal of Physics: Conference Series, 2021, 1815(1):012007.
[6] 费宏运, 杨阳. 基于保信系统的电网事故智能分析与决策[J]. 光源与照明, 2021(12):2.
[7] SHI Z, SUN T, WU D, et al. Research on the integration technology of power engineering design materials based on fuzzy retrieval[J]. IOP Conference Series: Earth and Environmental Science, 2021, 632(4):042030.
[8] GAO L C, YAO L M, YANG Z W, et al. Research on hybrid index method of double-layer B+ tree for power big data considering knowledge graph[J]. Journal of Physics: Conference Series, 2021, 1771(1):012004.
[9] 宋辰萱, 孔祥文. MongoDB与Hadoop MapReduce的海量非结构化数据处理方案[J]. 电子技术与软件工程, 2021(2):2.
[10] FADELELMOULA A A. Exploiting cloud computing and web services to achieve data consistency, availability, and partition tolerance in the large-scale pervasive systems[J]. International Journal of Interactive Mobile Technologies (iJIM), 2021, 15(15):74.
[11] QIANG G, SUN L, HUANG Q. ID3 algorithm and its improved algorithm in agricultural planting decision[J]. IOP Conference Series Earth and Environmental Science, 2020, 474:032025.
[12] LIU Q, XIA X. Construction of classification model of academic library websites in Jiangsu based on decision tree algorithm and link analysis method[J]. Open Access Library Journal, 2022, 9(1):9.
[13] 韩成成, 增思涛, 林强,等. 基于决策树的流数据分类算法综述[J]. 西北民族大学学报(自然科学版), 2020, 41(2):11.
[14] 王雅辉, 钱宇华, 刘郭庆. 基于模糊优势互补互信息的有序决策树算法[J]. 计算机应用, 2021, 41(10):8.
[15] ZHAO Y. Research on personal credit evaluation of internet finance based on blockchain and decision tree algorithm[J]. EURASIP Journal on Wireless Communications and Networking, 2020, 2020(1):1-12.
Research on Station Resource Retrieval Technology in Operation Data of Power Automation System Based on Data Mining
ZHANG Xu-dong, XIE Min, HUANG Jian-ping, WANG Zheng
(State Grid Zhejiang Electric Power CO.,LTD. , Hangzhou 310007,China)
Abstract: At present, the power grid contains a large number of multi-source information data. It is not easy to retrieve its data information efficiently and accurately. In order to solve this problem, after consulting the literature, analyzing the data characteristics of the actual power operation system and multi-source database samples, an optimized decision tree algorithm based on mutual information and parallel computing theory is introduced, and a decision tree model is built on this basis. Finally, simulation experiments are set to verify the model with various system databases as examples. The results show that the optimized decision tree algorithm based on mutual information and parallel computing can achieve fast, accurate and effective multi-source data retrieval for large databases, and can also effectively process real-time data. The algorithm directly mines the original data of the database according to the representative feature set, and sorts according to the size of the index information. The data mining method with the improved decision tree algorithm as the core technology has a high precision. It can better realize the mining of the multi-source data information of the power grid. It can not only avoid data duplication, but also meet the decision-making requirements of the project, providing a reliable technical support for improving the efficient mining of power grid data.
Key words: data mining; power operation system; mutual information; decision tree; simulation experiment
(責任编辑:马乃玉)
