基于深度学习的计算全息显示进展
2023-06-13刘珂瑄吴佳琛何泽浩曹良才
刘珂瑄,吴佳琛,何泽浩,曹良才
(清华大学 精密仪器系 精密测试技术及仪器国家重点实验室,北京 100084)
1 引 言
显示技术的发展始终是消费升级和生活方式革新的重要推力,带来了显著的经济效益,引起了社会的高度关注。近年来,元宇宙概念的兴起再次将三维显示技术带入了大众的视野。当前,三维显示技术主要包含双目视觉显示、体三维显示、光场显示以及计算全息显示等解决方案[1-2]。相较于其他的三维显示技术,计算全息(Computer-generated Holography,CGH)可以提供更为精确的深度信息,从源头上避免了易引起视疲劳的辐辏调焦矛盾,且具有光路简单、结构紧凑的优势,全息重建像也因具有强烈的真实感而被称为“光学等价物”。近年来,在元宇宙通信[3]、AR/VR 显示[4]、车载抬头显示[5]等方向,基于计算全息显示技术的实现方案应运而生。
计算全息基于衍射光学理论,首先对调制器件到目标三维光场的物理衍射传播过程建立了精确的正向可微数学模型,再通过求解该正向数学模型所对应的高维病态逆问题获取用于光场物理重建的计算全息图。所以,计算全息的显示质量极大程度地受限于正向数学模型的准确性和逆向求解算法的可靠性。
硅基液晶(Liquid Crystal on Silicon,LCoS)相位型空间光调制器(Spatial Light Modulator,SLM)因其光学效率高、无孪生像的优势,成为了目前主流的计算全息调制器件。LCoS 作为一种相位型、离散采样和有限像素尺寸的器件,其相位全息图(Phase-only Hologram,POH)的生成逆问题具有病态性。如何基于正向衍射数学模型求解满足器件限制的相位全息图是计算全息领域的重要研究方向。
常用的相位全息图生成算法可分为复振幅编码方案和迭代方案两类。复振幅编码方案通过一次衍射计算得到SLM 平面的复振幅分布,再利用不同的编码方式将其转化为相位全息图。具体的编码方式包含双相位编码[6]和误差扩散编码[7-8]等。复振幅编码方案理论完备性高,光学重建结果普遍具有高质量、无散斑噪声的优势。但是双相位编码需要针对不同目标场景手动调节最优的滤波强度以获得无位移噪声的三维显示,误差扩散编码也需要手动选取合适的均匀振幅值来消除编码过程中引入的团状噪声,均无法实现相位全息图的实时生成。迭代方案则是将相位全息图的生成问题转化为最优化问题直接求解,包含Gerchberg-Saxton(GS)算法[9-10]、Wirtinger 算法[11]、非凸优化算法[12]、随机梯度下降(Stochastic Gradient Descent,SGD)算法[13]等。迭代方案得到的数值解收敛性较好,但通常伴有散斑噪声问题,需要在显示质量和计算速度间进行权衡。所以复振幅编码方案和迭代方案均无法同时兼顾显示质量和计算速度,限制了计算全息技术的实际商业应用。如何实现高质量且高速的相位全息图生成是目前计算全息三维显示面临的核心问题之一。
近年来,深度学习技术及其相关应用呈现出了爆炸式的发展趋势,深蓝、AlphaGo、ChatGPT等产品的问世一次次刷新着人类对于人工智能的想象。深度学习技术具有强大的数据处理、特征提取和非线性预测能力且可利用不断增多的训练数据持续提升自身性能,其飞跃式的发展对光学领域产生了深远的影响,带来了诸多革命性的成果[14-16],也为计算全息技术的发展提供了一条新的技术路径。早在1998 年,基于神经网络的相位全息图生成算法便已被提出[17]。但受限于当时计算机的软硬件性能,只得到了小尺寸、低质量的初步结果。随着卷积神经网络的提出和GPU 的商用普及,基于深度学习的计算全息技术也迎来了高速发展,高质量且高速的相位全息图生成问题也正在被逐步解决。
本文综述了近年来基于深度学习的相位全息解决方案,根据网络训练过程中约束条件的不同分为数据驱动深度学习和模型驱动深度学习两类。介绍并比较了各类方案的优势与不足,展望了基于深度学习的计算全息技术在实际应用中面临的挑战与未来发展方向。
2 数据驱动深度学习
2.1 网络框架及训练原理
基于数据驱动深度学习的相位全息图生成算法网络框架如图1 所示。在训练开始前,利用复振幅编码方案或迭代方案生成与图像数据集相对应的相位全息图数据集,用以充当真值。神经网络根据输入的图像数据集输出预测的相位全息图结果。预测结果和真值间的差异用损失函数表示。常见的损失函数包含均方误差(Mean Square Error,MSE)、负皮尔逊相关系数(Negative Pearson Correlation Coefficient,NPCC)和感知损失(Perceptual loss)[18]等。神经网络根据链式法则将计算得到的损失函数反向传播用以更新自身参数,学习图像数据集与相位全息图数据集间的映射关系。得益于GPU 的并行运算和神经网络学习输入输出间高维非线性关联的强大能力,训练后的神经网络可以针对图像数据集外的输入项快速预测出相应的相位全息图输出项,实现质量与速度的兼顾。因为网络只是单纯地学习两数据集间的映射关系,故被称作数据驱动深度学习。数据驱动深度学习的训练过程被视作黑箱,所以数据集对其训练结果起到了决定性的作用。
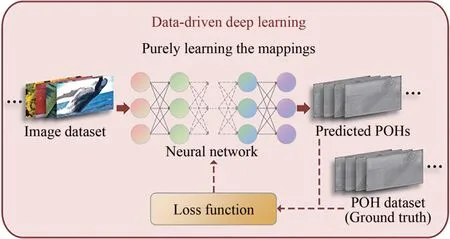
图1 基于数据驱动深度学习的相位全息图生成算法网络框架及训练原理Fig.1 Network framework and training principle of POH generation algorithms based on data-driven deep learning
2.2 基于数据驱动深度学习的相位全息图生成算法
2018 年,日本Horisaki 等人率先利用数据驱动深度学习实现了相位全息图的生成[19]。该神经网络结构如图2 所示,它使用的U 型残差神经网络(Residual U-Net)是目前计算光学相关工作中最为广泛应用的网络结构[20-21]。为简化数据集的生成过程,相位全息图数据集由振幅均一的随机相位分布充当,相应的图像数据集则由相位全息图数据集利用一次正向传播模型计算直接得到,如图3(a)所示。虽然最终的训练结果受限于数据集的选择,在应用于真实图像的相位全息图生成任务时泛化性较差,但该工作首次证明了利用深度学习进行相位全息图生成的可行性,并将相位全息图的生成时间缩短到了毫秒量级,为后续的研究工作奠定了基础。
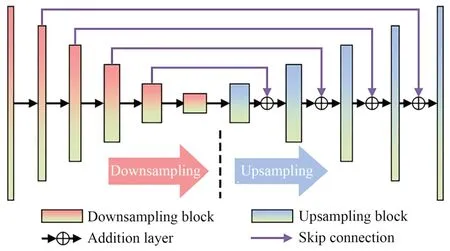
图2 U 型残差神经网络Fig.2 Residual U-Net architecture
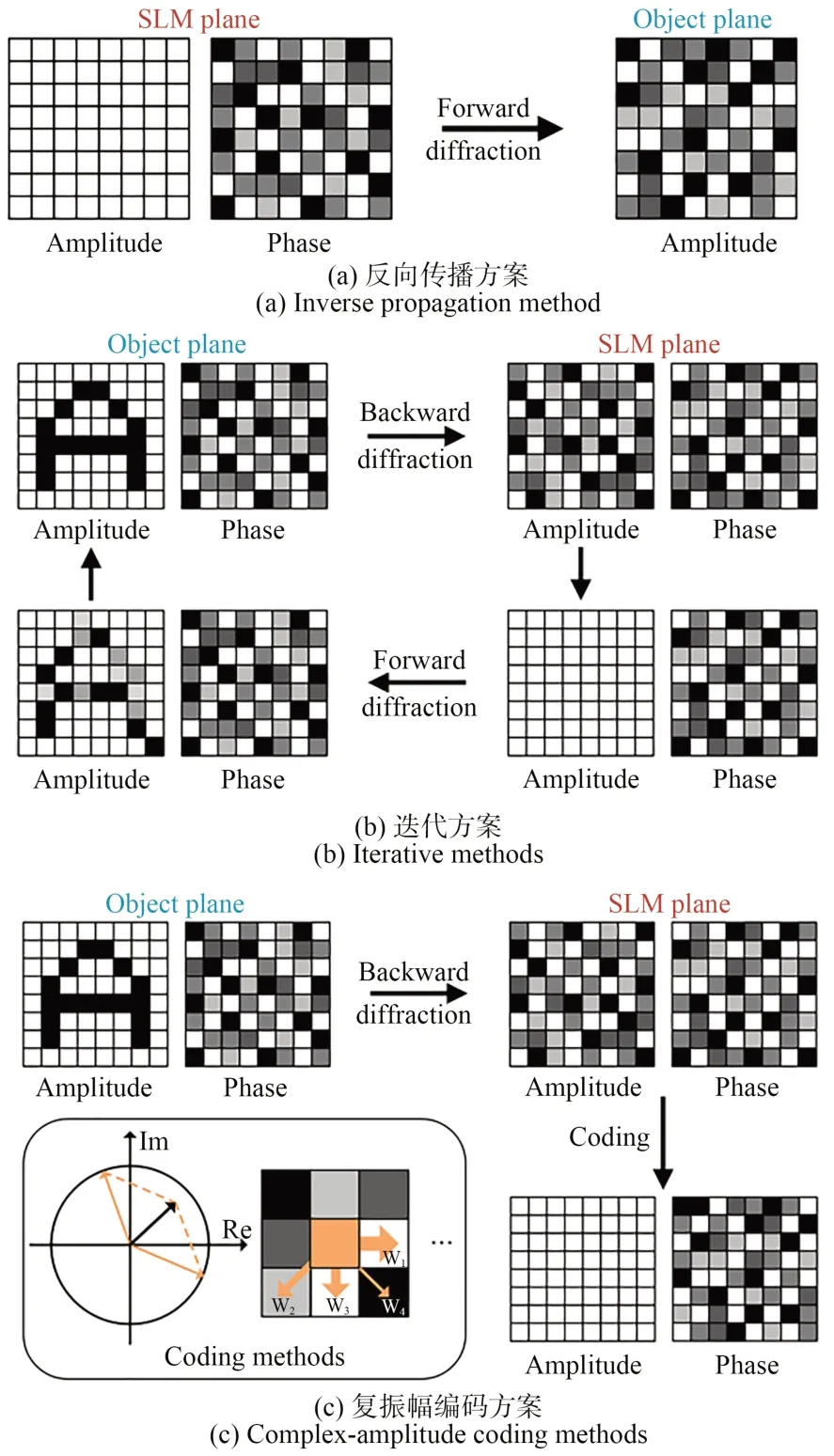
图3 相位全息图数据集的多种生成方案Fig.3 Different generation methods of POH datasets
2020 年,韩国Lee 等人在上述工作的基础上对网络训练所需的数据集进行了优化[22]。利用10 000 张随机分布、大小不一的圆点图像充当图像数据集,利用如图3(b)所示的GS 迭代算法生成相应的全息图数据集,从而显著提升了网络预测全息图的质量。光学重建质量与GS 迭代算法相近,但也伴有GS 算法中常见的散斑噪声问题。
2021 年,麻省理工学院的Shi 等人提出的TensorHolo 网络在智能手机上实现了2K 全息图的实时生成[23]。其中的图像数据集由三维随机场景生成器产生的4 000 张RGB-D 图充当。相应的全息图数据集为利用点源法得到的SLM 平面复振幅分布。训练后网络预测的复振幅分布利用双相位编码法转化为相位全息图,上载至SLM 实现光学重建,如图3(c)所示。由于双相位编码法理论基础完善,产生的相位全息图无散斑噪声问题且质量较高,所以TensorHolo 最终的光学重建结果具有极强的真实感。2022 年,该研究团队进一步提出TensorHolo v2 网络,利用神经网络预处理避免了双相位编码中的人工选参过程,实现了图像-相位全息图的端到端训练[24]。此外,为实现三维场景的全息图生成,Tensor-Holo v2 对比了如图4(a)所示的RGB-D 和分层两种不同的网络输入形式。TensorHolo v2 的三维光学重建结果如图4(b)所示。
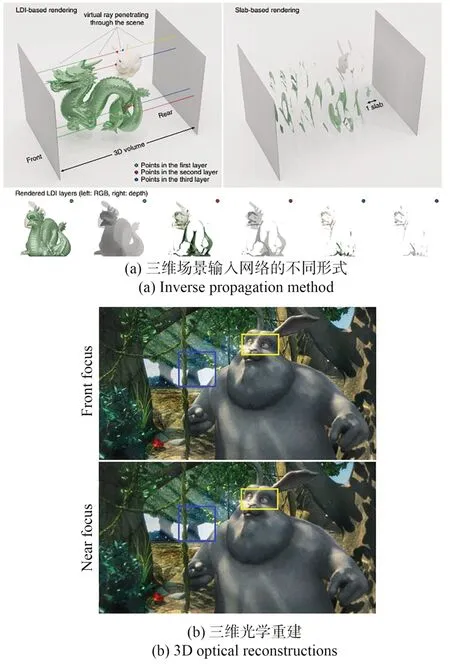
图4 TensorHolo v2 的三维场景输入及光学重建[24]Fig.4 3D scene inputs and corresponding optical reconstructions of TensorHolo v2 [24]
此外,基于数据驱动的深度学习技术还被广泛应用于与计算全息相关的像差校正[25]、全息图压缩[26-27]、全息图去噪[28]、全息图超分辨[29]、全息图加密[30-31]和二维转三维[32-33]等研究方向,均获得了高速且与传统算法质量相近的神经网络预测结果。
3 模型驱动深度学习
从上述的研究工作可以看出,由于神经网络只被单纯用于拟合图像数据集与相位全息图数据集间的映射关系,数据驱动深度学习最终的预测结果严重依赖于数据集的选择。具体体现在如下几个方面:相位全息图数据集的质量决定了网络预测结果的质量上限;为了更准确地拟合二者的映射关系,相位全息图数据集的数据量往往十分庞大,无论采用何种生成算法都十分耗时;相位全息图数据集的通用性较差,在重建距离、照明光波长等基础参数改变时均需要重新计算生成。
为突破相位全息图数据集质量、规模和通用性的限制,基于模型驱动深度学习的相位全息图生成算法应运而生。物理模型驱动已成为当前深度学习发展的一个重要方向,即将逆问题相应的正向数学模型嵌入网络训练过程充当约束,神经网络据此通过极小化损失函数的方式来解算任务,而非单一的数据拟合,从而突破了数据集的限制,获得了高速且质量优于传统方案及数据驱动深度学习方案的网络预测结果。准确易得的正向数学模型是应用模型驱动深度学习的前提和基础。在相位全息图的生成问题中,所涉及到的光波近场传播物理过程可用波动光学中的菲涅尔衍射模型进行精确描述,且可基于快速傅里叶变换(Fast Fourier Transform,FFT)实现快速计算。其中,单次傅里叶变换(Single Fast Fourier Transform,S-FFT)和角谱(Angular-spectrum method,ASM)[34]两个常用模型分别具有快速和准确的特点,可充分满足模型驱动深度学习的要求。
3.1 网络框架及训练原理
模型驱动深度学习的网络框架如图5 所示。神经网络根据输入的图像数据集预测相应相位全息图,其中DIV2K 为模型驱动中较为常用的图像数据集[35]。菲涅尔衍射模型被用于数值模拟SLM 平面到重建像平面的光场传播过程以得到数值重建结果。网络参数将依照数值重建与图像数据集间的损失函数进行更新,从而使神经网络自主地求解相位全息图的编码方式。在无需耗费大量时间生成相位全息图数据集的同时,还获得了优于传统方案和数据驱动深度学习方案的重建结果。更直观的对基于数据驱动深度学习和模型驱动深度学习的相位全息图生成算法两者的对比如表1 所示。值得注意的是,在模型驱动深度学习中,三维场景的损失函数需要采用依照深度位置分层计算数值重建的方式实现。
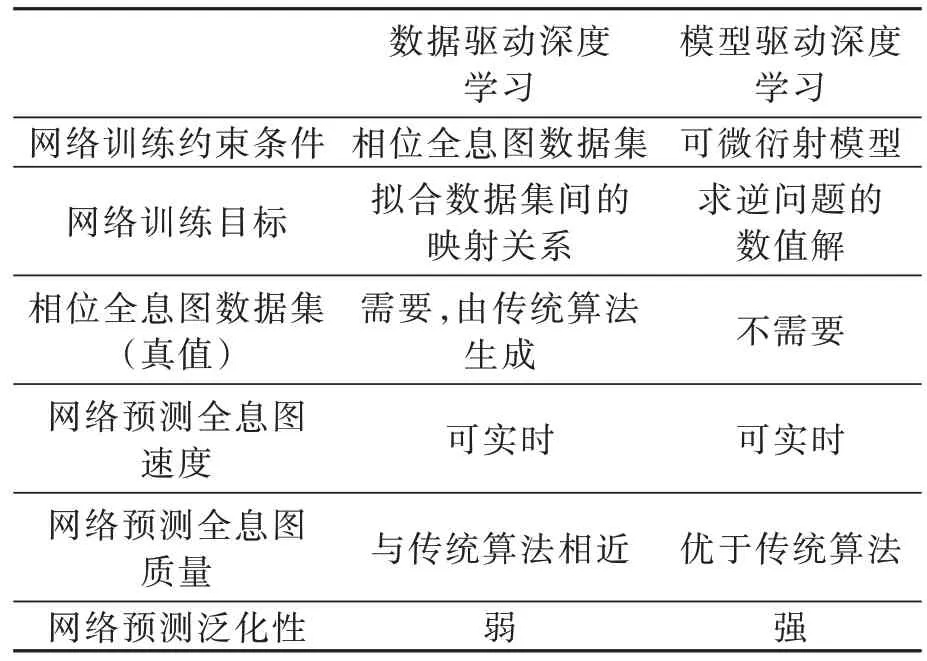
表1 基于数据驱动和模型驱动深度学习的相位全息图生成算法对比Tab.1 Comparison of POH generation algorithms based on data-driven and model-driven deep learning methods
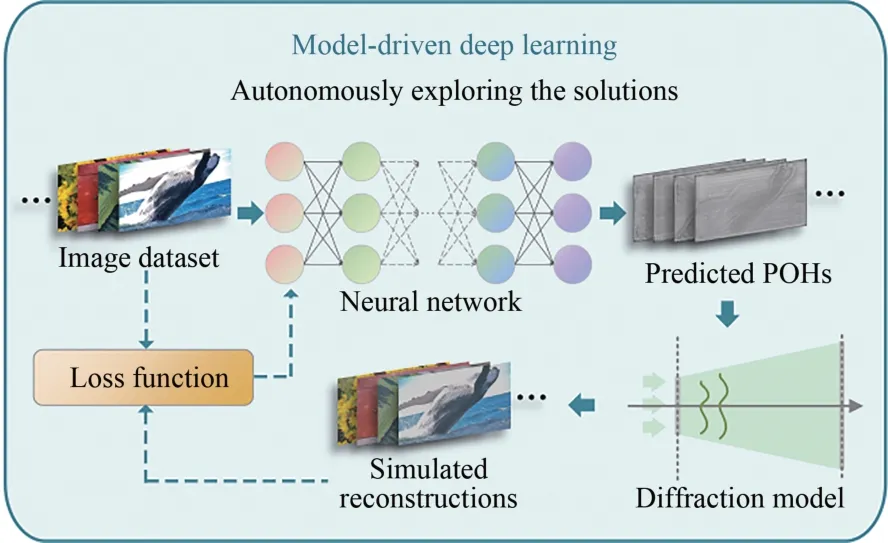
图5 基于模型驱动深度学习的相位全息图生成算法网络框架及训练原理Fig.5 Network framework and training principle of POH generation algorithms based on model-driven deep learning
3.2 基于模型驱动深度学习的相位全息图生成算法
2020 年,斯坦福大学的Peng 等人提出了如图6 所示的非端到端模型驱动深度学习网络框架——HoloNet[13]。框架将相位全息图的生成过程进行了细致的任务拆分,内含图像相位生成器和相位编码器两个神经网络,分别用于预测目标光场像平面相位分布和将SLM 平面的复振幅分布转化为相位全息图。
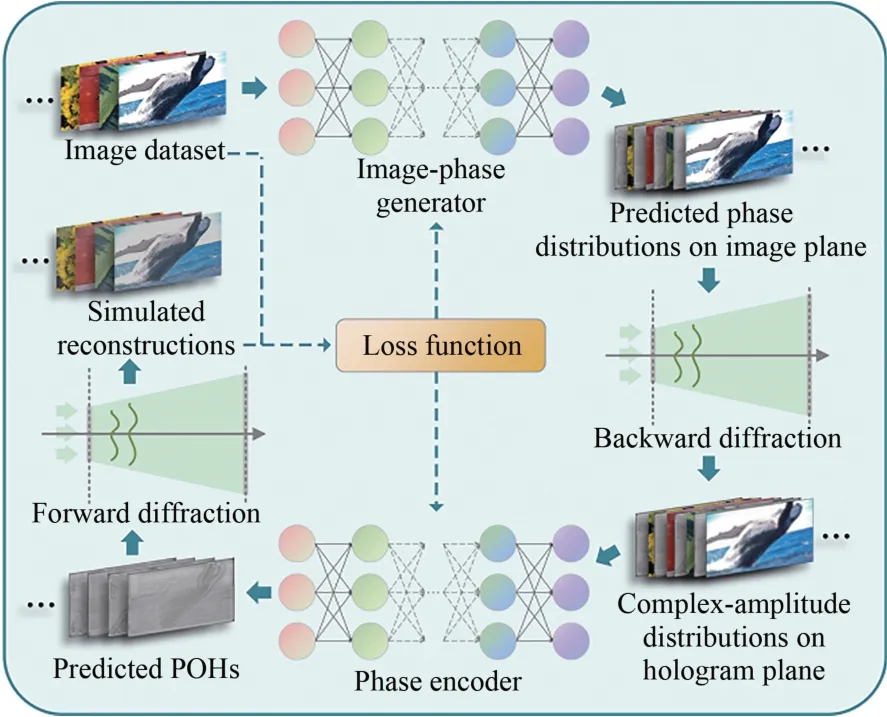
图6 非端到端模型驱动网络框架及训练原理Fig.6 Network framework and training principle of the two-step model-driven deep learning method
2021 年,清华大学的Wu 等人首次提出了如图7(a)所示的端到端模型驱动深度学习网络框架——Holo-Encoder[35]。Holo-Encoder 利用单个神经网络直接进行相位全息图的求解。简单易构的框架避免了多个子网络同步所造成的训练难收敛问题,在0.15 s 内得到了如图7(b)所示的高质量无散斑光学重建结果。
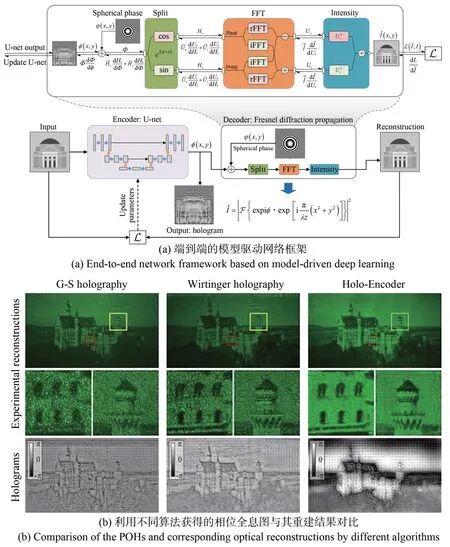
图7 Holo-Encoder 端到端网络框架与其光学重建[35]Fig.7 End-to-end network framework and optical reconstructions of Holo-Encoder[35]
在模型驱动深度学习中,网络学习能力决定了数值重建质量,模型准确性决定了光学重建与数值重建间的差异。从这两方面出发的优化工作也被陆续提出。
在网络学习能力方面,模型驱动深度学习对其提出了更高的要求。清华大学的Liu 等人在Holo-Encoder 的基础上提出了4K-DMDNet 网络[36]。为在不改变网络整体参数量的情况下增强其学习能力,4K-DMDNet引入了如图8(a)所示的亚像素卷积上采样策略。亚像素卷积用可学习参数代替传统转置卷积中的大量无效零参数[37-38]使网络数值重建的清晰度和保真度有了明显的提升,获得了如图8(b)所示的高保真光学重建结果。此外,还可利用DDRNet 等结构增强网络学习能力[39]。
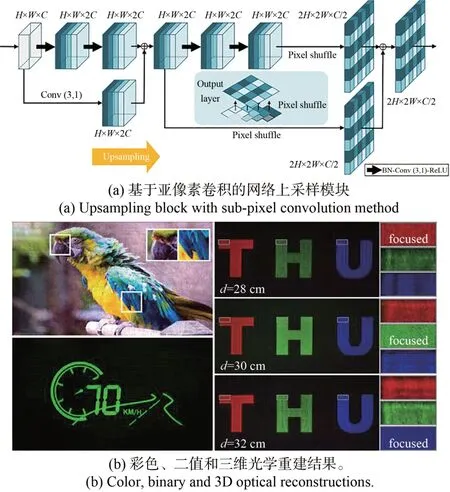
图8 4K-DMDNet 中的上采样模块结构与其光学重建[36]Fig.8 Upsampling block and optical reconstructions of 4K-DMDNet[36]
在模型准确性方面,HoloNet 将由Camera-inthe-loop 方案得到的、考虑了实际光学重建过程中出现的照明不均匀和透镜泽尼克像差问题的衍射模型用于网络训练[13]。4K-DMDNet 考虑了奈奎斯特采样定理的要求,在模型中引入了密集采样操作[36]。此外,还可以在建模过程中考虑实验中常被用来消除SLM 零级光影响的二维闪耀光栅相位,将优化目标设置为模型计算得到的1 级衍射级次[40]。这些工作都基于现有的光学理论建立了更贴合实际物理过程的数学模型,获得了与数值重建更为相近的光学重建结果。
除了上述建模工作外,还可以用神经网络代替现有数学模型,用数据驱动训练得到的衍射模型网络约束模型驱动过程[4,41-42]。如图9 所示,衍射模型网络从大量实验样本数据中学习拟合实际的衍射传播过程,从而更全面地缩小光学重建与数值重建间的差异,实验中光学重建的聚离焦效果也更为自然。
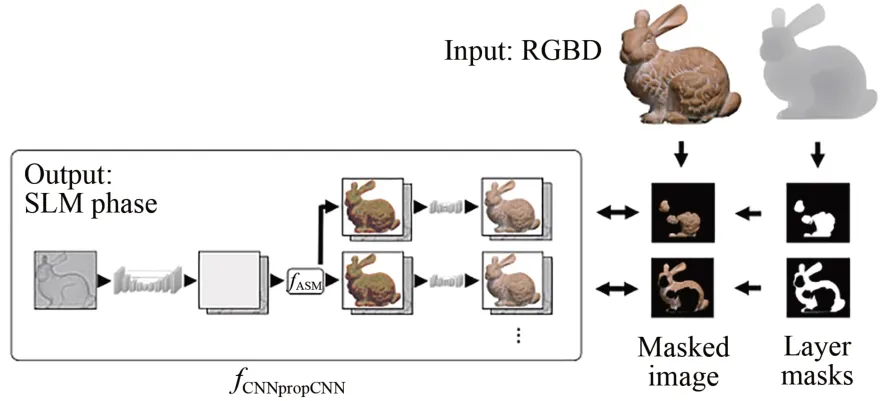
图9 网络拟合衍射模型CNNpropCNN [42]Fig.9 Learning-based diffraction model called CNNprop-CNN[42]
此外,选择合适的图像数据集和损失函数也可有效提升训练后网络的保真度和泛化性[43-45]。
4 总结与展望
当前显示技术正向着逼真、可交互、高集成的方向不断发展。计算全息显示技术让影像跳出了平面的限制,为构建虚实融合的近眼显示场景和多人实时交互场景提供了有力支持。无散斑高保真相位全息图的快速生成是计算全息实现更广泛商业落地的基础。随着LCoS 芯片生产良率的提升和成本的下降以及专用集成电路的高速发展,未来计算全息技术会成为三维显示真正走入千家万户生活的一大有力技术支撑。此外,计算全息在光束整形[46]、光场调控[47]、光学加密[48]、激光加工[49]、超表面设计[50]等研究方面也有着广阔的应用场景。
未来基于深度学习的计算全息技术也将不断发展,除了上述工作外,还存在如下的可能发展方向:
(1)引入对抗学习机制。生成式对抗网络(Generative Adversarial Network,GAN)是一类受博弈论启发而产生的网络训练模式。通过添加判别器进行与生成器间的性能博弈,GAN 可以实现基于少量样本的高性能网络训练。而当前使用到GAN 的计算全息相关工作多直接采用监督学习的训练模式,没有对其中判别器的功能进行深入的挖掘[51-52]。
(2)数据驱动与模型驱动相融合。数据驱动的解普遍具有更强的物理意义,而模型驱动的解的质量和泛化性更佳。如何将二者的优势融合也是一个非常重要的研究方向。
(3)自动化机器学习。自动化机器学习省略了网络训练过程中网络结构、超参数、正则化方法的人工选择过程,系统自动化地做出上述决策,决定最佳的训练方案,从而大幅降低了深度学习的使用门槛,进一步推动了其在计算全息领域中的应用。
