透过薄散射介质的目标事件分类方法
2023-06-13杨泊钰
杨泊钰,柯 钧
(北京理工大学 光电学院,北京 100081)
1 引 言
不同于光在自由空间中的传播,当携带有目标信息的光线通过散射介质(如云、烟雾、生物介质等)时,介质的内在不均匀性将会引起光线的散射,进而导致波前畸变。此时,探测器会检测到复杂的散射图像,使人眼无法直观地获得目标信息。该现象在日常生产生活、科学研究与安全保障中经常出现,影响了人们对物体的观测,因此,如何通过散射介质获得目标信息成为一个重要而充满挑战的问题。
透过散射介质成像在生物医学技术、天文现象观察、日常生活应用中均有着广泛的应用需求。不同领域的研究人员也提出了多种方法,如自适应光学技术(Adaptive Optics)[1]、波前整形技术(Wavefront Shaping)[2-6]、相关成像技术(Correlation Imaging)[7-11]以及最近新兴的神经网络技术(Neural Networks)[12-13]等。自适应光学技术利用可变形镜可以近乎完美地校正低阶像差,但其成像条件也较为苛刻,需要有一个明亮的点光源或者高对比度初始图像。波前整形技术可以做到透过高散射介质成像,其成像过程需要大量的光学目标估算。相关成像技术是基于记忆效应理论[14-15]在没有散射介质、目标物体或光源详细信息的条件下可做到无创成像,但其成像质量与选取的初值联系紧密。同时,其在成像精确性以及成像速度上还有很大的提升空间。随着近年来神经网络的发展,深度网络被应用于计算机视觉的各个任务之中,也包括由散斑重建目标信息,但所用的数据仍然是在较理想情况下由传统相机采集的散斑图,对成像条件要求较高[12]。
在如上提到的成像技术应用场景中,均需要质量较好的散斑图像,但在实际应用过程中,散射介质或(和)目标物体为运动状态的情况在所难免。同时,当针对于低亮度环境下的运动目标时,传统相机拍摄到的散斑效果更差。现有的算法效果,即使是功能强大的神经网络算法,也对此大打折扣甚至无法工作。但是,随着视觉传感器的发展,用于散射介质成像的传感器也有了更多选择,其中,事件相机凭借其高动态范围、低延迟和高时间分辨率等优点在低亮度、运动散斑采集方面具有巨大的潜力。
不同于传统相机,事件相机是新兴的一种视觉传感器。其每个像素独立工作,基于异步事件驱动,只处理亮度变化信息。工作时检测每个像素的亮度变化是否超过提前设定的阈值并输出事件流。事件流包括像素坐标、时间戳以及极性信息[16-18]。事件相机的动态范围可达140 dB,输出的事件时间分辨率是微秒级别。得益于其高动态范围、高时间分辨率和低延迟等特点,相较于传统相机在检测运动目标上具有明显的优势。
目前,事件相机有众多的应用场景,包括目标跟踪/检测[19]、光流估计[20]、HDR 图像重建[21]等。在激光散斑工作方面,2021 年,Edmund Y.Lam[22]等人使用事件相机代替DLSA,比较了事件传感器与传统CMOS 传感器在分析动态散斑方面的性能。由于事件传感器只有在场景中有运动时才有输出,因此事件传感器节省了数据使用量,降低了算法复杂度。在极端条件下,由于严重的运动模糊,基于普通强度的传感器无法捕获聚焦图像,而事件传感器仍然可以捕获具有高时间分辨率的事物并指示正确的动态级别。同年,Edmund Y.Lam[23]等人提出一种基于事件的激光散斑相关技术用于微运动检测。实验结果表明了其提出的方法在正常场景和高速场景下的可行性。
虽然以上工作验证了事件相机应用在激光散斑工作中的可行性,但并没有进一步涉及较为复杂的运动目标信息。同时,由于缺少动态散斑相关事件数据,事件相机在透过散射介质的目标探测任务中,特别是涉及到需要大量数据训练的神经网络工作中受到很大阻碍。为此,本文借助V2E算法从多组传统灰度散斑中模拟产生相应的事件流,进而制作为“事件散斑”数据集,将其送入神经网络进行目标分类训练,分析原始运动的手写数字目标信息,最终获得了90%以上的十分类精确率。
2 基于神经网络的事件流生成
2.1 事件相机工作原理
传统相机以固定的速率捕获图像,对整幅图像进行输出;而事件相机异步测量每个像素的亮度变化,并输出编码亮度变化的时间、位置和符号的事件流[15-17]。因此,事件相机的输出是数字“事件”或“尖峰”的可变数据序列。每个事件都表示对应像素在对应时间点上对数亮度发生的变化,事件相机的输出操作如图1 所示。
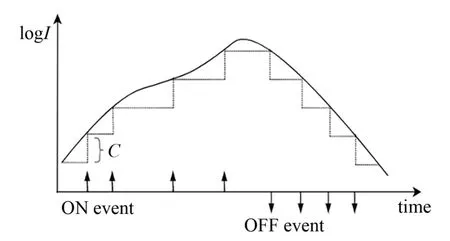
图1 事件相机输出操作示意图Fig.1 Schematic diagram of the event camera output operation
事件相机的每个像素独立工作,对连续的对数亮度信号L(logI)的变化做出响应。每个像素每次发送事件后会记录当前对数亮度的强度,当该像素u的对数亮度强度在时刻tk变化超过设定的阈值C时,事件相机便输出事件。生成事件的公式如式(1)所示:
输出事件为像素信息u(x,y,t,p),其中x、y表示该像素的坐标,t表示该事件触发的时间戳,p∈{-1,1}表示极性信息。当亮度增加时输出ON事件,p=1;亮度减少时输出OFF 事件,p=-1。
相较于传统相机,事件相机的优点包括高动态范围(可达140 dB)、高时间分辨率(可达μs 量级)、低功耗、高像素带宽(可达kHz 量级)。同时,由于其工作原理,事件相机还减少了运动模糊的出现。凭借独特的工作方式及明显的优势,事件相机与神经网络相结合已应用于多种领域。但是,神经网络的训练需要大量的事件数据集。虽然已有一些实采的事件数据集[24],但其数量仍远少于传统相机数据集。据我们所知,更是没有透过薄散射介质的目标事件数据集。因此,由灰度数据制备事件数据成为了一种获得事件数据集的重要方式。
2.2 V2E 算法
目前已出现多种事件数据模拟生成方式。早期Katz 等人[25]提出借助廉价的高帧率(125 帧/s)USB 相机结合PC 机的事件传感器的模拟方法,从传统的强度图像中模拟生成事件流数据。但相较于使用事件相机,该方法对PC 负载要求较高,实际使用时模拟生成速度有限。ESIM 事件相机模拟器[26]并非直接使用相邻强度帧之间的差异生成事件流,而是提出自适应渲染方案,根据视觉信号的预测动态调整采样率,可用于从合成视频或者图像数据集中生成所需的事件数据,数据生成质量与效率也均有提高。Rpg_vid2e[27]是ESIM 的一个拓展,它首先将视频插帧处理,之后对于每个像素,其连续的强度信号在时间上通过高帧率视频帧之间的线性插值近似,当强度变化幅度超过设定的阈值时便产生事件。但是,这两种方法针对的是不存在时间噪声、泄露的DVS (Dynamic Vision Sensor)事件和均匀分布的阈值失配情况,而这种情况并不适用于真实相机。新出现的V2E 算法[28]弥补了上述缺陷。V2E考虑了事件阈值适配、有限强度相关带宽和强度相关噪声等,使其可生成覆盖一系列光照条件的事件数据。为了使生成的散斑事件流更真实可靠,本文采用的是最新的V2E 算法。V2E 生成事件流数据过程如图2 所示。
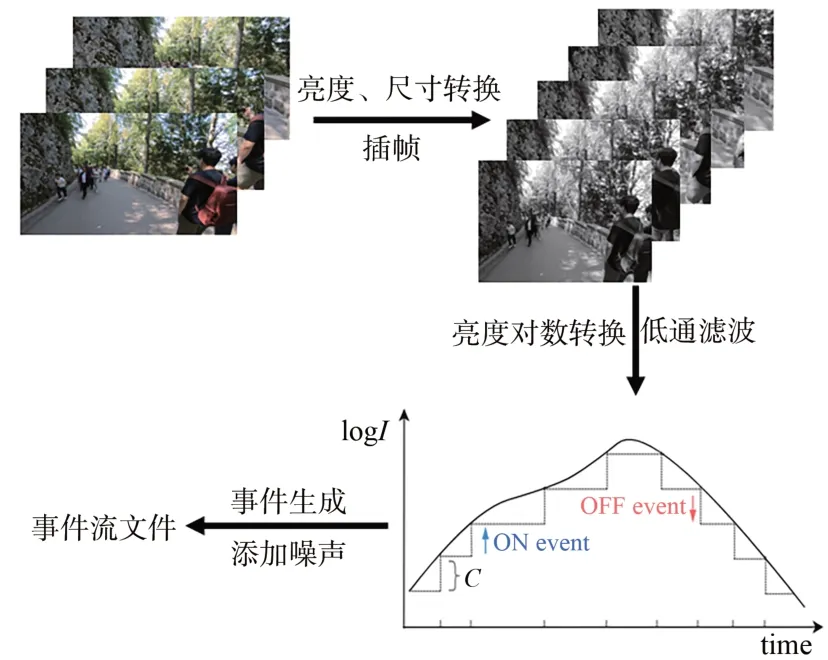
图2 V2E 工作流程图Fig.2 V2E workflow diagram
V2E 算法首先将时间T内的彩色视频转换为M个亮度帧:Is=其中,每一帧都与一个时间戳ti(0=t1<..<ti<..<tM=T)相关联。灰度视频帧的像素值作为亮度值处理,之后将视频帧缩放到指定尺寸。得到指定分辨率的视频帧后,借助Super-SloMo 视频插帧网络[29]对其进行插帧以提高时间分辨率。为了使插帧效果更好,V2E 算法在Adobe240FPS[30]数据集上将RGB 帧转换为亮度帧后重新训练了Super-SloMo。从亮度帧中生成事件的方法是基于Katz等人的工作[25,31]。由于事件相机输出依据的是对数亮度的变化,而标准的数字视频通常是线性表示强度,所以需要建立亮度I(0~255)与对数强度L之间的映射。对于亮度值I<20 的像素,采用强度到对数强度的线性映射。
为了模拟真实事件相机的有限模拟带宽,V2E 算法通过使用随强度值单调增加的滤波带宽模拟该影响,即滤波器的带宽与亮度值I成正比(防止带宽为0,存在一个加性常数限制其最小值)。每个像素存在一个记忆亮度值Lm,新的低通滤波亮度值为LlP,进而通过ΔL=Llp-Lm来产生正、负事件,若ΔL是阈值的倍数则产生多个事件。同时,记忆亮度值也进行更新。真实事件相机的阈值随高斯分布变化,因此,在模拟生成事件数据前便仿造相应高斯分布变化存储了正负阈值二维数组以供后续使用。同时,V2E 算法添加了热噪声事件、泄漏事件和时间噪声。
2.3 事件散斑生成
采用以上方法得到的事件流并不方便直接用于后续目标分类工作,需要对事件流进行处理。目前应用较广的处理方法有事件帧/2D 直方图[32-33]、体素网格[34-35]、3D 点集[36-37]等方式。本文将其制作为“事件散斑”。首先对获得的事件流数据进行去噪处理,针对每一组运动目标采集的事件流以固定时长分割,对该时间段内的每一个触发事件进行判断,查询其同一行相邻位置是否有其他事件触发。若有则保留该事件,若没有则删除该事件,对所有触发事件重复执行此步骤。
在得到去噪后的事件流后,将事件序列进行分割。之后将分割出的序列内所有事件在一幅画面上进行累加,制作一张事件帧。在累加过程中利用事件的极性p与时间戳t,使用体素网格[38-39]的方法对事件进行归一化的处理。具体如下:
将每个手写数字目标对应的事件流分割为3段事件流,各自在画面上进行累加,制作为3 张事件帧。在累加过程中利用事件的极性p与时间戳t,对事件进行类似于归一化的处理,归一化事件时间戳公式如式(2)所示:
进行如上操作的目的是,使不同时间触发的事件在事件帧中的影响不同,两种极性p可以表示两种亮度变化。经过归一化处理后,如果每一个运动的目标对应采集的事件流为N,随后分割成的3 个子序列为Sd,对应制作为3 张事件帧,每一事件帧的计算公式如式(3)所示:
其中:i对应每一个事件的序号,(x,y)为触发事件的坐标,p为该事件的极性,S为事件子序列,d为事件子序列的序号(当制作第一个子序列时d=0,第二个子序列时d=1,第三个子序列时d=2)。采用如上方法制成所需的事件帧,即事件散斑。
2.4 分类网络
本文采用的分类网络基于ResNet101[40]。ResNet的出现主要针对网络加深后产生的梯度消失或梯度爆炸的问题。该退化问题会阻碍网络的收敛,影响测试结果。ResNet有多种变形,但结构特点相同,主要包括输入部分、中间卷积部分和输出部分。ResNet101 的具体结构如图3 所示。
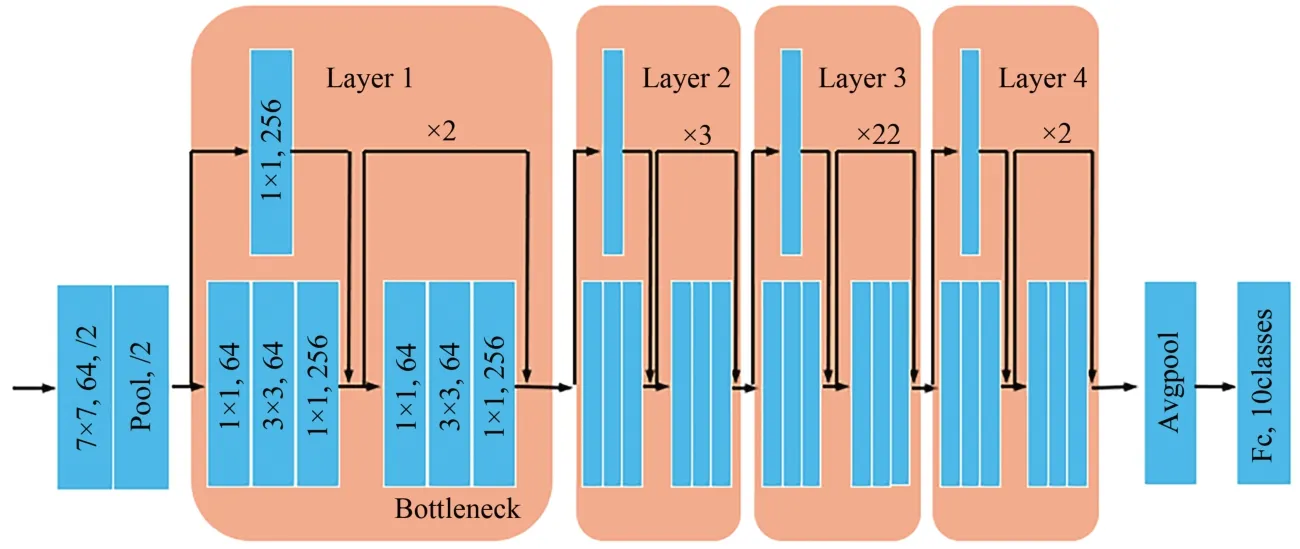
图3 ResNet101 结构图Fig.3 ResNet101 block diagram
ResNet 网络的输入部分由卷积层和池化层组成。其中卷积层的核为7,步进值为2。池化层的核为3,步进值为2。采用卷积层和池化层配合的目的是减小输入图像的尺寸同时增加通道数,降低运算所需的存储。中间卷积部分有4 层,分别由多个bottleneck 结构构成。bottleneck 的输入数据分成两路,一路经过1×1 卷积、3×3 卷积和1×1 卷积,另一路直接与前者输出结果相加,经过激活函数Relu 向后输出。其中,1×1 卷积的存在不仅起到对通道数升维和降维的作用,还在保持原有特征图大小的情况下实现多个特征图的线性组合,同时大幅降低了运算复杂度。ResNet 的输出部分通过全局自适应平均池化将特征图尺寸变为1×1,输出2 048 类初始分类结果,之后由全连接层输出手写数字目标的十分类结果。
3 实验结果
本文利用灰度相机采集所得散斑图模拟产生事件数据。目标为MNIST 手写数字数据集[41],其中包含0~9 的手写数字。对于每一个手写数字目标,通过向左、向上两次移动,采集3 幅(512×512)清晰灰度散斑图像。将3 幅存在相对位移的灰度散斑送入V2E,生成该运动手写数字目标的事件流,其中正负阈值C大小设定为0.15,其余参数默认不变。实验共制备4 200 组手写数字目标的事件流数据,转换结果如图4 所示。
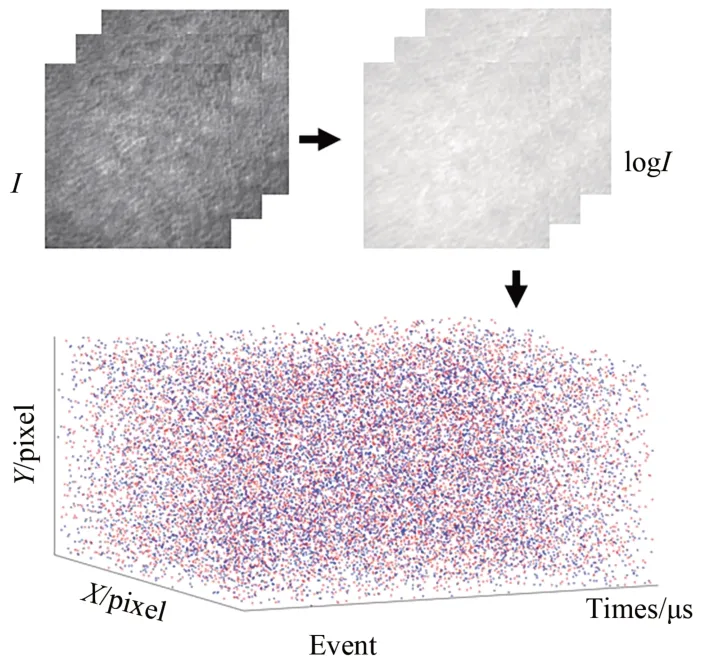
图4 事件流转换结果示意图Fig.4 Diagram of the result of the event stream transformation
V2E 的一个明显特点是会模拟真实情况在事件数据中添加噪声。我们对比了无噪声与有噪声的事件散斑,结果如图5 所示。对于特定的一个运动数字目标,V2E 产生的噪声事件数约为3万个(总事件数约为23 万)。更真实的添加噪声的事件散斑由于受到噪声的影响相较于没有噪声影响的事件散斑表现效果较差(为了方便观察,将图像灰度值进行了归一化处理)。

图5 事件散斑添加噪声前后对比图Fig.5 Event speckles before and after noise added
得到上述事件流数据后,我们通过2.3 节中所描述的方法将其处理为事件散斑。图6 是手写数字目标对应的灰度散斑及事件散斑。

图6 手写数字目标对应的灰度散斑及事件散斑Fig.6 Handwritten digit targets corresponding to grayscale speckles and event speckles
对于目标识别部分,在利用V2E 算法将这些灰度散斑图像制作为初始事件流后,接着利用体素网格方法,将初始事件流以不同的切片方法制作为两类512×512的事件散斑(每类均为4 200组数据)。在第一类中,我们将一个数字目标的所有事件流制作为一张事件帧,即单通道事件帧。在第二类事件散斑中,我们将一个数字目标的事件流划分为3 部分,制作为3 张事件帧,即三通道事件帧。针对两类事件散斑进行两组实验,分别送入ResNet101 网络中。网络开头添加卷积层使单通道事件帧与三通道事件帧来适配网络输入,之后输入事件散斑分别经过网络的输入部分、中间卷积部分、输出部分与全连接层得到十分类结果。对于每个目标,神经网络输出其0~9 的类别概率大小,例如,对手写数字“0”的十分类输出结果为[16.255,-2.349,0.088,-4.748,-3.426,-0.199,1.053,-1.930,-2.360,-2.920],可以看到网络判断该目标为“0”的概率最大,因此该目标分类正确。同时,我们提取了输入部分降采样得到的特征图,如图7 所示。

图7 输入散斑及降采样特征图Fig.7 Input speckle and downsampling characteristic maps
利用4 000 组数据进行网络训练,200 组数据用于测试。实验在Linux 操作系统下进行,其中CPU 为Intel(R)Core(TM)i9-10900X,GPU 为NVIDIA GeForce RTX 3090,采用Pytorch 作为深度学习框架,调整初始学习率为0.001,批处理大小为16。我们调用torchvision的预训练ResNet101模型,优化算法采用随机梯度下降,权重衰减为0.000 5,在此基础上运行300 轮训练。
通过训练得到的手写数字目标十分类结果如表1 所示。单通道事件散斑、三通道事件散斑的十分类精确率分别为92.71%和94.27%。制作单通道事件散斑时,时间戳归一化仅以事件流开头为依据,这就导致长事件流中开头部分事件所占权重较小而结尾处权重较大。尽管在一帧事件散斑中包含有所有事件数据,但分类效果仍会受到影响。而制作三通道散斑是以事件流开头,中间、结尾为依据分别制作3 帧事件帧,事件流划分更细致,得到的分类效果更高。同时,V2E 算法制作事件流过程中网络效果、噪声等因素也会影响事件流生成的效果。未来可通过真实事件相机采集复杂目标进行分析,同样可调整神经网络结构达到更好的原始目标恢复效果。以上实验结果表明,由事件数据制成的事件散斑仍可较好地保留向左、向上运动的手写数字目标的0~9 类别信息,在目标分类任务上有较好的表现。在未来透过薄散射介质的目标事件分析工作中,可以进一步拓展运动目标种类及运动方式。
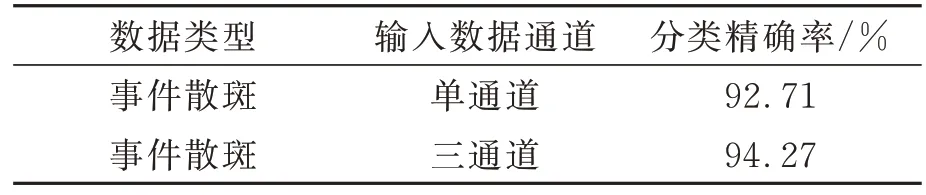
表1 手写数字十分类结果Tab.1 Ten-class classification results of handwritten digits
4 结 论
本文通过实际采集运动手写数字目标生成的灰度散斑,由V2E 算法生成灰度散斑对应的事件流,将模拟事件流制作为事件散斑送入残差网络进行十分类任务,达到了94.27%的精确率。实验结果表明,事件散斑较好地保留了原始运动目标的类别信息,证明了事件散斑在保留原始运动目标信息上的可行性,进而表现出事件相机在透过散射介质成像方面的巨大发展潜力。同时,本文工作也存在继续探索的方向,例如拓展运动目标的种类、采用更复杂的运动方式以及分析不同种类的噪声对事件散斑质量及运动目标检测的影响等。
