结合主题模型的中国古代诗人大五人格预测
2023-06-05闫滢钰汶东震张冬瑜林鸿飞
闫滢钰,汶东震,张冬瑜,林鸿飞
(大连理工大学 计算机科学与技术学院,辽宁 大连 116024)
0 引言
古代诗人擅长用诗歌理解世界和记录生活,中国古典诗歌作为中华民族传统文化的重要载体,被认为是中国古代人类智慧与文化的结晶。诗歌是诗人物我相接、思维传达的产物,很大程度上体现着我国古代诗人的个性,并且蕴含着诗人的情感。同样,诗人的性格也极大地影响着诗歌的写作主题与风格。只有对诗人的性格有科学的掌握才能更好地辅助对诗歌的理解。随着自然语言处理领域的发展,通过对大量文本的情感进行挖掘,判断个体性格的研究已经成为该领域的热点研究问题,并推进了计算机科学和心理学领域的共同发展。诗歌文化也是我国素质教育的重要部分,通过分析古诗并结合心理学理论模型研究诗人的人格特质,可以对人们理解中国古代诗人、研究诗词提供极大帮助,有助于传统文化教育的发展,对诗词的传承起到很好地辅助作用。
近年来,学者开始围绕与古代诗歌有关的课题展开研究。其中,对古诗的情感鉴赏以及探究诗人的人格特质一直是品析诗文化研究的重要内容,也是数字人文近年来研究的热点方向,但目前相关的研究还处于起步阶段。与其他文学作品相比,诗歌文体的语言简明精炼,而在内容上又表现出浓重的抒情色彩,情感紧凑和丰富。当前的情感分析研究语料多集中在新闻评论、商品评论、社会传媒评论、个人博文等,对古诗的研究则相对较少。前人提出了一些诗歌情感分析的方法,但是对情感的分析仅限于诗歌层面,目前还没有面向诗人的分析研究。现阶段人格分析任务的研究主要对人们在社交软件(如微博、推特等)上发表的言论及用户行为进行分析,从而反映用户的人格特质。其中人格研究者关注与支持最多的一种理论模型,即大五人格模型,被广泛应用于分析人格特质的任务中。中国古代诗歌作品同样可以看作是古代诗人用来表达自身想法与情感的“微博”。大五人格被证明在世界主要区域都具有稳健性,对诗人进行大五人格的分析,可以对中国古代诗人有更深刻的认识。
然而,在自然语言处理领域,鲜有类似的工作发表,并且也没有可用的语料库。这显然阻碍了该领域工作的进展。在中华文化发展的历史长河中,历代诗人留下的佳作不计其数,这使得人们只能通过一个诗人的部分经典诗歌对诗人进行分析,当诗人的诗歌数目比较多时,有必要引入自然语言处理相关技术对诗人人格进行分析。同时,诗人创作诗歌时,常常基于某些的特别的主题和情绪。诗歌的主题对于诗歌的情感具有决定性的影响。因此,分析诗歌的主题,就是对诗歌的语义进行全面的把握,这对于诗人的人格分析、诗歌生成都具有一定的意义,同时也有助于从数字科学的角度来分析和了解诗人的诗歌创作意图,反应诗人性格。
本文研究工作主要内容如下:
(1)目前计算机领域关于古代文学的工作集中于分析诗词而不是诗人,并且没有学者开展对诗人进行人格特质分析的任务。为填补此类任务的空白,本文构建了一个针对唐宋两代诗人的大五人格数据集,用于支撑对古代诗人的人格特质分析任务。
(2)由于诗歌写作主题极大程度地反应了诗人性格和情感,本文提出结合主题模型的诗人大五人格分析方法,并应用于诗人画像构建。实验证明,本文方法可以提高对诗人人格特质预测的准确性与科学性。
1 相关工作
1.1 古诗词与古代诗人相关研究
最早对古诗词的计算分析起源于20 世纪90 年代。在对古诗词语料库的构建方面,刘岩斌等[1]建立了我国第一个利用电脑进行古代诗词研究的系统,提供了词汇、韵律、文体等相关功能。在诗歌分析方面,学者们提出了一些诗歌分类与情感分析的方法,诸雨辰等[2]将文本分类任务引入唐诗研究,Tang 等[3]结合CNN和GRU 提取唐代诗歌特征,并对其进行情感分析。
对古代诗人的研究主要集中在人文学科领域,学者们偏向于对某一具体诗人的性格,或对其某一作品进行独立的分析,如李贞[4]结合杜甫的人生经历分析了杜甫的性格,夏妍月[5]从《古风五十九首》中分析李白的悲剧蕴藉。这体现出了传统的人文科学的许多研究方法倾向于从单一方面或单一作品分析思考和写作得出结论,缺乏一定的科学性和完整性。利用现有的计算机技术,可以极大影响到传统的人文学科,可以更科学和全面地了解古代诗人。
1.2 大五人格
自20 世纪90 年代,心理学界提出了大五人格理论[6]之后,大五人格模型得到了广泛的关注,它抓住了大部分现有的人格特质的共同性和共通性,在不同年龄、文化和性别中具有普遍性。大五人格包括开放性、外倾性、神经质性、尽责性和宜人性五方面的人格特质,开放性反映了个体对知识的好奇心、创造力;外倾性反映了个体自信、善于交际的特性;神经质性反映了个体对冲动的控制力较差;尽责性反映了个体的自律性,倾向于细心规划而不是无计划地行动;宜人性反映了个体对同情和合作的倾向性。大五人格为各行各业的研究者提供了一个系统的人格描述模型。虽然大五人格最早是由西方学者根据词汇学方法和聚类统计方法提出来的人格特质模型,但是过去十几年对大五人格模型的跨文化研究表明,大五人格模型同样适用于其他国家,具有跨语言、跨文化和跨评定者的稳健特质,在世界主要国家和地区具有普适性,这使得大五人格模型被心理学家普遍接受[7]。早期获取大五人格信息采用的是传统的问卷方式,时效性很低。后来人们开始运用机器学习等手段预测人的性格,使得越来越多其他行业的研究人员将大五人格与自己的研究相结合。比如在分析人格特质的任务上,Lin 等[8]基于大五模型的不同特征和测量方法,应用经典的机器学习模型研究了Facebook用户个性特征的可预测性。目前还没有研究将古代诗人与大五人格进行结合,借助机器学习并结合现代心理学对古代诗人的人格特质进行科学解读,而这是本文要解决的一个重点任务。
2 数据集
2.1 数据预处理
本实验的数据库选取唐朝和宋朝的诗人进行构建,因为唐朝和宋朝的诗歌与诗人相关记载和相关史料相比其他朝代的更加完整,有利于对古代诗人大五人格的标注工作。本文首先收集了唐代和宋代的诗人与诗歌,原始数据来自Github 上名为chinese-poetry 的开源数据库①https://github.com/Chinese-porty/Chines-porty,此项目整理了中华古典诗集与文集,包含 5.5万首唐诗、26 万首宋诗、2.1 万首宋词和其他古典文集。此数据库通过 JSON 格式存储诗歌,格式如图1。

图1 原始数据格式Fig.1 Format of original data
本文使用了针对古汉语的开源分词器甲言②https://github.com/jiaeyan/Jiayan对古诗进行预分词,其主要包含正向最大匹配分词和预训练的隐马尔可夫模型来分词两种方式。
数据清洗分两步,得到诗歌的分词结果后首先删除不完整、有错误和重复的诗歌数据。第二步对语料库进行筛选,首先去除无作者信息的诗歌(如作者名为无名氏、不详或缺名),同时去除一些朝代的礼乐歌词(如郊庙朝会歌辞),为了保证数据集的科学性与可用性,提高数据集标注的质量,同时提高模型学习的准确性,本文选择诗歌作品数目在30 以上的唐宋诗人进行标注,避免某些诗人的语料过少,导致对诗人人格的不合理预测,并删去目前无记载或记载较少的作者。最后,数据清洗后的语料库共包含581 名作者创作的246 458 首诗,后续将对233 个唐代诗人以及348 个宋代诗人进行标注工作。表1 展示了语料库中诗人的基本统计信息。

表1 语料库中诗人的基本统计信息Table 1 Statistical information of poets in the corpus

表2 诗人大五人格评级标准Table 2 Big Five personality rating standards for poets
2.2 标注规则
本文邀请了两名汉语国际教育硕士生以及一名计算机技术硕士生担任标注员。将大五人格每个维度分为五个评分等级。分别表示诗人在该人格维度上的评价为极差的(1 分)、较差的(2 分)、一般的(3 分)、较好的(4 分)、或极好的(5 分)。标注时结合诗人诗歌作品、诗歌主题、作者史料和作者生平经历进行标注。有关诗人的史料记载与相关信息来自百度百科①https://baike.baidu.com/、知网②https://www.cnki.net/、万方③https://g.wanfangdata.com.cn/index.htm、古诗文网④https://www.gushiwen.cn/以及中国历代人物传记数据库⑤https://projects.iq.harvard.edu/chinesecbdb(CBDB)中诗人的相关信息以及对诗人性格的评价。同时参考唐宋诗人相关的出版书籍,比如林庚先生的《唐诗综论》[9],张学淳的《唐宋诗人故事》[10],王运熙的《中国古代文论管窥》[11]等含有唐宋诗人人格特质描述的相关章节,同时统计每个诗人的高频词为参考依据辅助标注工作。
2.3 标注流程及一致性控制
标注期间为保证数据集的标注质量,标注工作的整体流程分为试验标注阶段和正式标注阶段两个阶段。在试验标注阶段,标注人员主要熟悉标注的规则以及流程,每位标注人员在待标注数据中随机抽取50 条进行标注。通过本阶段的标注结果,着重讨论标注结果不一致的部分,讨论解决方法并合理更新标注规则,当三位标注员对标注结果达到较高的一致性并且完善了标注规则之后,进入正式标注阶段。
在正式标注阶段,每一个诗人的大五人格评分先由一名汉语国际教育硕士生以及一名计算机技术硕士生进行标注。标注者之间的一致或意见分歧程度的大小选用Kappa 系数[12]来衡量,Kappa 系数是一种广泛使用于衡量标注者之间评分一致性的指标。在正式标注阶段,两位标注员的Kappa 值达到了80.36%,这表明了整个数据集上评分的高度一致性,同时反映了该数据集的标注结果的可靠性。对于标注不一致的地方,由标注员共同讨论并由第三位标注员进行仲裁。
2.4 标注结果分析
唐代和宋代大五人格每个维度的均值如图2 所示。唐代的诗人们大多心系国家,充满着想求取功名的心态,渴望建功立业,所以唐朝诗人的尽责性普遍较高。同时,唐代诗人性格豪放,随心所欲,在人生的坎坷之路上仍能保持热情,总体体现出较高外倾性。宋代作为中国文学历史上的又一高峰,十分重视文治教化。在这个哲学气氛浓厚,大多数文人为探寻真理进行思辨的社会,哲学和美学相互作用,总体体现出宋代诗人较高的开放性。另外,宋词主题多为伤春悲秋、离愁别绪、风花雪月、儿女情长等,也体现出了宋代诗人较高的神经质性。
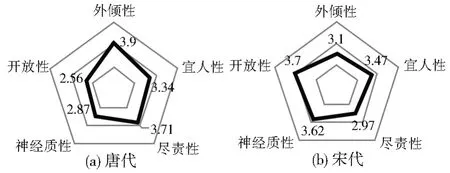
图2 诗人大五人格分布均值情况Fig.2 Mean distribution of poets' Big Five personalities
本文构建的数据集有助于古代诗人的画像构建,帮助解决诗人自然属性识别特别是人格特质方面的问题,帮助走出传统人文学界只针对单一诗人,单一题材或者单一诗歌风格的定性研究,同时可以用于辅助风格可控的诗歌生成,多方面地推动数字人文领域的发展。
3 主题增强的诗人大五人格预测模型
从上述数据标注过程可以看到,诗人的作品是其生平经历、人生态度以及处世哲学的反映。诗人的不同人生阶段中发表的诗歌往往是对诗人本身特性的映照。因此本文提出一个主题增强的诗人大五人格预测模型,基于多视角特征以及多任务学习方法并结合诗篇信息对诗人的大五人格特性进行建模。
如图3 所示,模型分为三个部分,第一个部分是作者特征嵌入矩阵,用于对作者生平特征进行学习。第二个部分是利用基于预训练语言模型的诗词分析器抽取作者全部诗文语义特征。第三个部分为在诗歌语料库上训练的主题模型,用来获得当前诗文的主题特征信息。最终三种特征向量以拼接方式进行特征融合,独立的五个大五人格特征强度分类器会对作者的大五人格属性特质进行预测。

图3 主题增强的诗人大五人格预测模型Fig.3 Model of poet's Big Five personality analysis with theme enhancement
具体而言,在作者特征嵌入部分,以唐、宋两代诗人名录为词表构建嵌入矩阵。此处假定作者为Ai∈VA,其中VA表示当前数据库收录的所有作者,包括当前数据集中收录的作者名称以及一个特殊符号<UNK>,该符号用于表示数据集之外的所有作者(即Out of Vocabulary情形),用于处理未经收录的诗人的情况。即当Ai∉VA时有Ai=<UNK>。此处设置一个用于学习作者特征的作者嵌入矩阵EA,其中有EA∈R|VA|×dA,即每个作者的表示向量为一个dA维的实数向量。此处本文约定EA(·)表示获取指定作者表示向量的操作,则当前作者Vi的表示向量fA如公式(1)所示,在模型学习阶段参与作者文风特征的记忆网络进行训练学习。
作者诗文特征抽取部分,本文采用在四库全书数据上基础上预训练的语言模型“sikubert”来获取古诗文表达的深度语义特征表示。本文将作者的所有诗文拼接为一个篇章作为作者生平的作品表示TAi。TAi为包含n个单词的长文本,TAi=[w1,w2,…,wj,…,wn],其中文本中第个j单词为wj。此处本文约定BERT(·)为获取指定文本在BERT 模型下的特征向量表示。则作者的生平作品的深度语义表示特征向量fs可以通过公式(2)所示表示。在进行输入时本文遵循Bert 模型的输入格式,在作者作品文本上拼接<CLS>和<SEP>确保语言模型正确性,则最终输入BERT 模型中的文本格式为。
具体而言,在拼接作者诗文进行输入时,首先按照作者诗文发布的时间进行分桶处理,同时为了避免在使用预训练BERT 模型处理输入文本时的超长问题,同一个作者的不同分桶拼接的诗文总长度小于512 字符。同一作者的不同分桶输入最终通过作者特征嵌入向量fA进行进行统一学习,确保同一作者的诗文特征学习过程的稳定。
而主题模型部分,本文首先在整个唐、宋古诗文数据语料库上对古代诗歌文本进行主题模型的训练。主题模型部分本文选用隐狄利克雷分布模型(LDA)作为诗歌主题特征的获取方式,此处预训练的模型记为LDAp,简化的主题模型可以视为一个输入文本到主题特征的映射函数LDAP(TAi),因此可以得知针对古代诗歌作者分析时,作者生平作品的主题特征表示向量可通过公式(3)得到:
其中fT∈R1×dT,即dT表示当前对作者诗文主题分析时的主题数目,fT涵盖了作者生平所有诗文的总体主题特征,对应在dT维的主题空间上。最后,在特征融合阶段本文使用谷歌提出Wide&Deep 方法,将三种视角的特征进行拼接作为作者人格特质预测的多视角融合的特征向量:
针对五种人格特质,采用5 个独立的分类层来预测人格特质的5 个等级,此处约定分类权重矩阵We,Wo,Wa,Wn,Wc,分别表示外倾性、开放性、宜人性、神经质以及尽责性五种人格特质的分类权重。均有W∈Rdf×5,其中df=|fbig5|,即用于人格特质预测的特征向量的维度。而上文提到,本文将5 种人格特质划分为5 个等级进行预测以更细粒度方式对诗人人格特质进行建模,因此权重W的第二维度对应为5 作为分类输出等级,则如公式5 所示,假定当前人格特质预测目标为yp,其对应的分类权重为Wp∈{We,Wo,Wa,Wn,Wc},则在此基础上结合Softmax 非线性映射对结果进行变换可以得到最终人格特质的5 个等级预测概率。
而训练阶段,本文使用交叉熵损失函数进行人格特征等级的监督学习,每个人格特质分别使用交叉熵函数对当前特质继续训练,如公式6 所示:
可以看到,在进行人格特质预测时本文使用同样的特征向量fbig5,搭配不同的分类权重参数对相应的人格特质进行预测。5 种人格特质预测任务之间的训练和预测过程相互独立。但诗人的5 种人格特质相互之间存在着一定的约束和影响,因此单一地进行模型训练是不可取的。因此在最终的人格特质预测训练过程中本文引入了多任务学习方法。本文在分析大量诗歌文本基础上,对诗人不同人格特质在诗歌体裁的文学作品中的体现程度进行了加权划分,结合这样的权重,本文对5 种人格特质的预测损失函数进行了融合,得到最终的综合人格特质损失lbig5,最终的损失函数如公式7 所示:
4 实验效果
4.1 评价指标
诗人大五人格数据集强度等级分为依次递进的5 个类别,因此评价指标方面本文使用准确度(Accuracy)作为模型预测效果的评估方法。此处假定样本总量为N,针对五种人格特质中任一特质进行预测时正确预测等级的数目分别为:C1,C2,C3,C4和C5,分别对应一个人格特质中预测正确的样本数目。则准确度分数计算方式如公式8 所示:
4.2 基线模型和实验设置
本文使用SIKU-BERT①https://github.com/hsc748NLP/SikuBERT-for-digital-humanities-and-classical-Chinese-information-processing作为预训练语言模型,该模型对于古文语料有着更好的理解和表示能力。主题向量通过gensim 库中的LDA 模型工具包进行生成。本实验设置训练集和测试集的比例为8∶2。对比实验部分,本文选取国内外大五人格特质预测分析研究的相关工作,由于部分工作尚未进行开源,因此本文根据论文对方法的描述对其实验方案进行了复现,并在本文提出的数据集上进行实验,以验证本文方案的合理性。
机器学习模型部分,本文选用Ramon 等[17]的实验方案作为基础的基线实验进行结果对比。其方案在数据采集基础上构建了文本的特征表示,并在此基础上结合线性回归、逻辑回归和决策树模型进行人格特质分类的研究。Rudi 等[18]基于支持向量机模型构建了人格特质分类模型,此处本文同样基于这一模型复现进行结果对比。Michael 等[8]基于梯度提升决策树模型,研究大五人格特质分类问题,在myPersonality 数据集上达到了最优的效果。而深度模型方面,Ren 等[19]构建基于文本特征,结合卷积网络和循环网络构建分类模型研究人格特质预测任务,此处本文复现了作者的方法,并在本文提出的数据集上进行了测试。此外,为了对比的公平,本文去除复杂的神经网络特征学习结构,使用词向量平均以及多层感知机方式构建作者诗文的特征表示。
机器学习模型部分参照现有研究选用词频-逆文档频率(tf-idf)作为模型输入特征[20],针对每个人格维度独立训练模型进行学习。深度模型部分本文使用预训练模型的分词器对古诗文进行分词并使用相同的词嵌入向量获取诗文的表示特征,以便于对比的公平。主题向量会与模型抽取得到的特征向量拼接,之后针对不同的人格维度通过线性层进行分类。
深度学习模型分词器和词嵌入向量部分与siku-bert 模型保持一致,本文从预训练的语言模型中抽取了已经训练好的词向量特征,并使用相同的分词器对诗文进行分词。深度学习模型训练优化器使用AdamW,学习率保持在1×10-4,使用混合精度训练保证训练效率和显存占用的均衡。深度模型的多任务学习过程与本文提出模型保持一致,损失融合部分不同人格维度的权重设置通过本文实验验证。
在权重选择部分,本文将交叉验证策略与随机搜索(random search)策略相结合。模型验证时,本文使用五折交叉验证方法对模型进行验证评估。数据集划分中相应将训练集等分为五份,分别训练模型并交叉验证。并在选择达到最好结果的模型在测试集数据上进行测试以评估最优模型。在交叉验证阶段,本文使用网格搜索对五项人格特质权重进行选择,权重范围限制为0~1,权重步长为0.1。在五项人格特质权重组合中,每次训练随机使用一种组合进行模型训练效果的验证。最终得到外倾、开放、宜人、神经质、尽责分别采用0.2、0.2、0.3、0.1、0.2 时能够得到最稳定的训练结果。
4.3 诗歌主题模型分析
诗歌主题对于诗人情感倾向分析十分重要,本文提出主题增强的诗人大五人格预测模型以及对比模型中均对主题特征向量的重要性进行了分析。因此本文针对主题数目这一参数进行分析。在整个诗歌语料库上结合LDA 模型构建主题模型,使用UMass 指标[21]计算共现分数如公式9、10 所示:
其中,V是一组主题词,∊表示平滑因子。D(x,y)统计包含单词x和y的文档数量,D(x)统计包含x的文档数量。并设置10~500 的不同主题数目,实验结果如图4 所示,可以看到当主题数目为50 时能够取得最好的共现分数指标,因此本文在构建模型过程中使用50 作为主题数目参数。

图4 主题模型不同主题数共现分数Fig.4 Number of scores for different topics
4.4 实验结果与分析
机器学习模型部分的实验结果如图5 所示,其中柱状图部分为不同机器学习模型对于5 种人格特质的预测结果。背景的阴影堆积面积高度表示当前模型和特征结合预测结果的平均值情况,图中左侧纵轴对应柱状图数值,右侧纵轴对应折线图数值。从图5 中平均值的面积堆积图可以看到,从左向右整体趋势表现出向上增长特性,说明诗文的主题特征向量对于诗人人格特质建模有着重要影响。

图5 机器学习基线模型结果Fig.5 Machine learning baseline model results
深度学习基线模型结果如图6 所示,对比可以看出,相比于传统tf-idf 抽取的文本稀疏编码特征向量,预训练模型中获取的稠密向量在文本语义编码效果上效果更好。整体来看卷积神经网络在深度语义建模方面效果相对更好,而循环神经网络相对较差。原因在于在构建作者粒度的诗文向量表示时,直接使用了文本词向量的平均池化结果作为特征,对于诗文的顺序结构有所破坏。未来可以针对这一问题进行进一步的探究。最后整体来看深度学习基线模型的平均结果的分数情况,随着LDA 特征的加入,模型对于人格特质预测的结果会有较大的提升。

图6 深度学习基线模型结果Fig.6 Deep learning baseline model results
本文提出的主题增强的诗人大五人格预测模型表现结果如表3 所示。表3 汇总了对比的基线模型与本文提出模型的全部平均结果,可以直观看出,诗人所有诗文的主题特征向量被加入时,模型对于其大五人格特质的预测能力会相应地提高,表明提取诗歌主题作为特征加入模型对预测诗人人格特质任务的重要性。

表3 大五人格预测模型表现结果Table 3 The performances of the Big Five personalities prediction model
最后,如图7 所示,本文进行了模型结构的消融实验。图中文本方法表示仅使用siku-bert作为诗文深度语义表示的抽取器,预训练模型本身参数不参与微调,仅微调人格特质分类层参数,作为预训练模型在本文数据集上的基线模型结果。

图7 模型消融实验结果Fig.7 Results of ablation study
而文本+LDA 方法与深度模型基线实验设置一致,获取到文本特征之后与主题特征拼接再进行人格特质预测。文本+作者则是结合作者表示向量作为预测特征。最后为本文完整模型,即融合了多视角特征和多任务学习方法的主题增强诗人大五人格预测模型。可以看到,结合主题特征的确能够对诗人人格特质预测产生贡献。而单纯加入作者特征嵌入特征时,模型在建模预测时表现出不稳定的情况。当融合三种视角特征时,模型取得综合最优效果。
4.5 案例分析
在本文针对诗人具体形象进行分析时,选取了唐代诗人李白和宋代诗人王安礼,结合其诗文文本内容和大五人格维度分数,对其人格特质和创作主题进行画像建模。
图8 对宋代诗人王安礼的作者形象进行了描绘。从作者的诗文主题词云可以看出,诗歌以赠答友人诗居多,体现出较高的外倾性。通过模型给出的大五人格预测分数得以看出,虽王安礼生平遭多人弹劾,但在外倾性方面仍表现出很高的特质分数,忧国忧民的铁骨柔情也反映出高的宜人性。这为研究王安礼的生平提供了全新的视角。

图8 宋代诗人王安礼诗人画像Fig.8 Wang Anli's persona
从图9 诗人作品主题词云可以看出,其作品大多抒怀壮志,诵清风明月,徜徉天地和美酒。体现出诗人豪放不羁恣意洒脱的情怀。在大五人格预测分数方面也进一步体现了其较高的外倾和宜人特性。
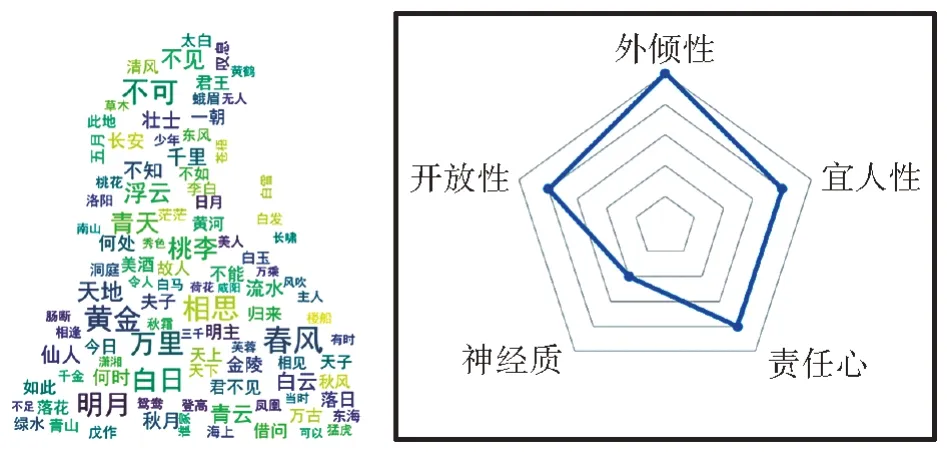
图9 唐代诗人李白诗人画像Fig.9 Li Bai's persona
在古代诗人大五人格分析工具基础上,本文能够更加细致地构建古代诗人的人格特质形象,为进一步窥探作者生平,分析作者隐式情感特性提供了新的思路与工具。
5 结论
大五人格是分析建模人格特质的有力工具,本文结合大五人格特质理论,面向中国古代诗人群体基于诗歌作品构建其大五人格特质画像。本文首先收集了唐宋两朝诗人作品,通过数据整理后邀请相关专业人员进行诗人大五人格特质的标注。其次,本文在标注数据上实现了常见的机器学习和深度学习预测方法,对数据集的质量进行全面评估。最后,本文重点针对诗歌主题对于诗人人格特质预测影响进行了研究,并以此提出主题增强的大五人格预测模型。
本文研究表明,诗人生平所谱写作品的主题是诗人性格各方面的良好映照。与当代人格分析,尤其是基于社交网络技术的人格特质分析的相关工作相对比可以看到,古代诗人的人格特质更为直白和外显,诗人不同时期的作品往往直接反映着其思想形态和情绪波动等特性。诗人所采用的借物喻情等写作手法特征也能够直接通过深度语义理解的方式进行捕获。而相比之下,当前人格分析研究面临的情感、态度以及观点的隐式表述问题更为突出,需要结合深度语义模型以及相关语料库进行更进一步进行分析。
