汉语-哈萨克语平行语料库构建及技术研究
2023-06-05古丽孜热艾尼外旷志寰
古丽孜热·艾尼外,旷志寰
(1.伊犁师范大学 教师工作部,新疆 伊宁 835000;2.南京大学 自然语言处理实验室,江苏 南京 210023)
0 引言
机器翻译是自然语言处理(NLP)领域最具挑战性的任务[1],在信息检索、信息安全等许多领域发挥重要作用,也是跨语言信息处理中不可或缺的技术之一,同时也在日常生活中为普通用户提供了多方面的数字信息化服务,包括ATM 自动取款机交易、手机银行转账、电子商务等,极大地推动了经济贸易的效率[2-4]。近年来,随着互联网信息技术的迅速发展和计算机能力的飞速提升,大规模的多种语言平行语料库得以建立与发展,平行语料库的研究价值得到越来越多的认可,国内外很多研究机构都致力于相关任务的研究与应用。
在大数据时代的背景下,数字旅游、数字医疗等电子文档的应用频率在逐步增加,我国与沿线各国的经济贸易、互联互通、区域合作医疗、金融合作、旅游文化交流与合作等更加密切,如何利用信息技术和新媒体手段,通过“数字一带一路”的建设,进一步确保电子商务与信息安全,促进信息化建设、实现共同发展显得十分必要。目前,新疆地区信息处理和网络信息安全方面都存在着巨大需求,开展汉-哈(汉语-哈萨克语)机器翻译的相关研究也变得至关重要。而语料库的构建是多语言平行语料库相关研究的立足之本,大规模汉-哈文平行语料库的缺乏已经成为相关研究工作的瓶颈。因此,提出一种创建汉-哈文平行语料库的有效方法在汉-哈文机器翻译领域至关重要。
现有的汉-哈文平行语料库的构建方法主要有两个问题:第一,数据资源缺乏。哈萨克语的语料的来源较少,主要是“天山网”“新疆日报”等数字报刊网站,加之汉-哈文平行语料库的构建主要依靠人工方式,费时费力,数据资源的缺乏大大影响了汉-哈文平行语料库的规模,同时,也无法满足汉-哈机器翻译的时效性要求。第二,数据处理方法单一。现有的工作中对平行文本的收集仅仅是对汉语、哈萨克语两种语言的数据进行简单的累积,没有进行篇章和段落的对齐加工,因此这些语料库对后期的研究价值有限。而汉-哈篇章、段落多层次自动对齐技术研究还处于起步阶段。
为了解决这些问题,本文利用自然语言处理的相关方法提升平行语料库构建质量,通过分析现有的词对齐方法,针对性地提出一系列文本预处理和段落(句子)对齐方法,并开发设计了辅助工具软件Corpus 对汉-哈文自动段落对齐的可视化界面。并根据段落对齐进行数据的自动编排存储,进一步提高了汉-哈文平行语料库的构建质量和效率。
1 相关工作
国内外语料库构建已有三十多年的历史,近几年来,面向机器翻译的平行语料库的建设和应用研究更是得到了国内外研究者的广泛重视。自然语言生成平行语料库的构建技术是语言学横向发展的新趋势[5-6]。语言研究者已经清楚地认识到高质量平行语料库的构建对机器翻译研究和智能信息处理等方面的巨大作用,对多语平行语料库也开展了较多的研究。
目前,国内外对于语料库的研究已经取得了不少显著成果[7-10]。加拿大议会会议记录是国外著名的法英平行语料库,也称为Canadian Hansards Corpus,早期很多关于语料库的研究都是以此为基础开展的。
在国内,从20 世纪90 年代后期众多语言学和翻译学学者也建成了诸多大、中、小型平行语料库。香港科技大学对香港立法委的会议记录进行了搜集、整理,建立了一个汉英平行语料库。1980 年起,我国开始了汉语语料库的构建工作,至今已经构建了一些大规模的语料库。例如,北京大学中国语言学研究中心所建立的包含了现代汉语语料库、古代汉语语料库和汉英平行语料库的CCL 语料库,复旦大学、哈尔滨工业大学等高等学校、人民日报、新华社等出版机构建立的汉英平行语料库。由翻译研究所等科研单位研发的跨语言的机器翻译系统,也有一个较为完善的平行语料库。
目前在语料库的语言种类上,国内学者更多的是关注中英、中日语料库的建设。相比之下,我国低资源语料的基础研究水平还比较薄弱,新疆大学多种多语信息处理实验室研究语料库建设工作,产生出大量的研究成果,奠定了多语言信息处理研究基础。于清等[11]提出的汉维医疗语料库中已建成110 多万字、3000句对汉维平行对齐语料,对构建中小型语料库有重要参考价值。
而在我国各种少数民族语种之中,对于哈萨克文的自然语言处理研究也相对落后。新疆大学艾山·吾买尔等[12-13]自20 世纪90 年代中期开始对包括哈萨克文在内的多种语言信息处理技术和语料库建设方法开展了研究,新疆大学古丽拉·阿东别克等[14-20]对哈萨克文分词方法、词性标注等方面进行了研究。
但是目前,汉-哈文信息处理的相关研究还处于初步阶段,大规模汉-哈文平行语料库构建的研究相对较少,平行语料库的缺乏成为汉-哈文机器翻译的最大障碍。
此外,由于其他平行语料的构建方法不完全适用于汉-哈平行语料的构建[7,8-10,21],直接套用会影响最终的语料库质量。在平行语料的构建中,早期平行文本的收集仅仅是文本的累积。如果不进行后续的段落对齐加工等技术处理,都会影响累积的文本量后期的研究和使用价值。所以,在汉-哈平行语料库构建及机器翻译中,段落语料多层次的自动对齐加工非常重要。因此,本文提出了一种有效的汉-哈文平行段落对齐语料库的构建方法。
2 汉-哈文平行语料库构建方法
段落是组成篇章的基础,多层段落之间的对齐效果,直接影响到篇章机器翻译整体上的语义效果[22]。目前的汉-哈机器翻译关注多层次段落对齐的技术应用环节较少。本文针对目前汉-哈文平行语料库构建存在的问题进行研究,提出了一种基于信息量比值的段落自动对齐方法。本文主要工作如图1 所示。
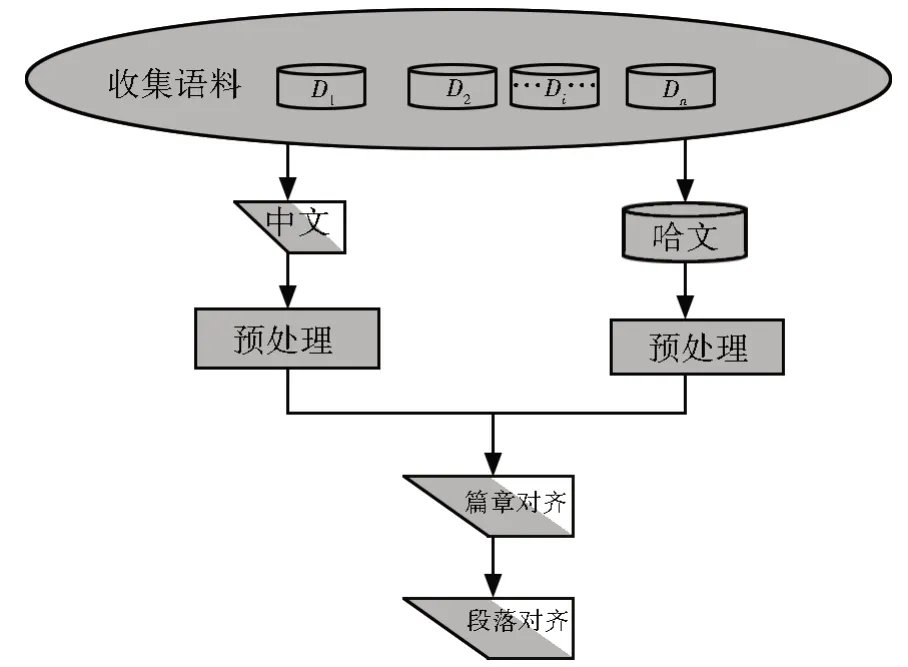
图1 汉-哈文平行语料库构建流程图Fig.1 Flow chart of constructing Chinese-Kazakh parallel corpus
收集数据和预处理:针对汉-哈两种语言之间的机器翻译面临的个性化技术需求,从技术共享与应用互补的角度,本文综合分析了目前支持汉-哈文平行语料库所采用的构建方法,提出了汉-哈平行语料的收集方法,结合哈萨克语的特点,提出了相关的数据预处理技术,包括对汉-哈萨克语料统一格式、删除多余标记等,并对汉语和哈萨克语的数据进行篇章对齐。
汉-哈文段落对齐及平行语料库构建:针对段落对齐,本论文采用了一种基于段落信息量比值的段落对齐方法,该方法建模的基础是互为翻译的文本有固定信息量比值,即在对齐的两个篇章中,源语言(汉语)相邻段落之间的信息量变化等同于目标语言(哈语)相邻段落之间的信息量变化。对确定“1∶1 型”、“1∶n型”的信息量比值的段落对齐结果进行编排存储,将段落编排中“1∶n型”段落合并生成为一个段落,从而最终得到基于信息量比值的“1∶1”的段落对齐结果。
在汉-哈平行段落自动对齐研究的基础上,开发了辅助软件Corpus,对汉-哈文段落进行可视化,有效地提高了段落语料的效率和质量。
下面分模块介绍本文的主要工作。
2.1 数据收集与预处理
汉-哈文档篇章对齐的质量直接决定了后续能否得到正确的对齐段落,因此,收集数据和预处理是篇章对齐研究中的一项重要的技术。本文选择了语料质量较好、规模较高的新闻网站文本作为数据来源,并进行相关的汉-哈文翻译工作人员人工识别确认,保证语料的质量。
通过分析可知,平行新闻网页之间存在相似性,且网页结构简单、噪声内容相对较少,提取篇章文档较为容易,可以最大程度地保证文本质量。因此,本文采用新闻网页作为汉-哈文本平行语料来源。利用网络交互式爬虫,对包含汉-哈文信息的新闻网站进行网页爬取,并将网页文档html 下载到本地,利用正则表达式进行正文信息的提取。根据汉-哈文新闻网页相似性,生成汉-哈篇章文档。从汉-哈新闻网站上人工选取数据,通过URL 查找相似性网站,下载汉文-哈文新闻信息,生成一组汉、哈篇章文档。对于每一个汉文文档,利用篇章对齐的交互式方法,在哈文文档中检索对译篇章。
在预处理的过程中,汉语、哈萨克语篇章需要根据对应的语言特性统一格式;例如,需要将哈萨克语处理为拉丁化的字符表示等。其中,汉语作为主流语言,其处理流程已经非常成熟。因此,本文主要根据哈萨克语的语法特性,对哈萨克语进行篇章级文档处理。
“天山网”(https://www.ts.cn)上包含了国内官方权威新闻《人民日报》的哈萨克语版。本文采用“天山网”上的中-哈文平行数据进行对齐研究。收集和预处理数据包括以下几个步骤:
1) 从网页中抽取篇章文档html 文件,并将其存储到本地;
2) 从html 文件清理得到原始文档数据,清除空行、乱码和图形图片等非文本内容;
3) 将清洗后的文档按照语言类别分别归档到A、B 两组,文件格式分别为 Ai.txt(中文文档)、Bi.txt(哈文文档)进行存储,其中i为索引号;
4) 根据索引号i进行汉-哈文档的匹配,生成汉-哈文篇章对齐。
2.2 汉-哈文自动段落对齐辅助软件Corpus
针对汉-哈文对齐任务,通过分析爬取的汉-哈数据,本文开发设计了一款辅助使用的工具软件 Corpus,利用该工具实现汉-哈文段落对齐的可视化界面,并对具有特定汉-哈文篇章对齐结构的源文档进行自动编排。Corpus由 PHP 编程语言实现,能够从html 和xml 文件中提取格式化数据,实现汉-哈文的段落对齐功能。Corpus 初始界面如图2 所示。

图2 Corpus辅助汉-哈对齐的初始登录界面Fig.2 Login page of Corpus
Corpus 辅助软件提供了导航、汉-哈文自动段落对齐和词典搭配统计分析功能,是构建汉-哈文平行语料库技术的基础。Corpus 段落对齐基础功能包括:段落之间合并、段落冗余删除、自动校对、段落自动对齐。段落对齐语料结果最终构建并不断扩容新的汉-哈文本平行语料库。自主研发工具软件Corpus 实现汉-哈文本段落自动对齐功能,将交互式收集的汉-哈篇章对齐网页语料导入(https://www.tilmuhyt.com/;http://47.108.77.137/index.php/index/login/index.html)界面,初步编排序列汉文数据A(A1、A2、A3、…)和哈文数据B(B1、B2、B3、…),使之对应。示例如图3 所示。

图3 汉-哈文本段落对齐界面的实现示例Fig.3 Implementation example of Chinese-Kazakh text paragraph alignment interface
2.3 基于信息量比值建模段落表义边界
当给定一段原文后,确定其对应译文的表义边界,就得到了此段落的对齐边界。由于哈萨克语的变态语序特性,即使确定了标点句读,句段的相对位置对应汉语依然可能存在错位。因此,本文从汉-哈文段落互译角度出发,将若干形成互译关系的连续段落,统一视为段落层级对齐的数据,将相邻连续段落之间的信息量比值作为汉-哈文段落对齐的边界。
本文研究的仙神河大桥是一座较为典型的独塔预应力混凝土部分斜拉桥,地处山西省和河南省交界处,桥墩高150.07 m,采用的是正八边形薄壁空心高墩结构,为典型的薄壁空心高墩,桥墩布置如图4所示。主墩截面八边形内切圆直径为墩顶10.04 m,墩底16 m,自墩顶到墩底截面采用直线斜率变化,墩壁厚度均为1.2 m。该桥所在的地域属于晋城市山区河谷地区,昼夜温差变化较大,而且由于地形地貌等条件的限制,沿墩身各部分接受太阳辐射的时间也不一样,对于墩顶部分一天中接受太阳辐射时间要多一些,而墩底部分则受日辐射作用很少。因此温差对空心墩的影响比较大。
首先,利用固定的字符作为对齐边界,划分汉、哈文段落的结束位置;其次,在互译评分大于一定阈值的汉-哈文文档中查找同时满足平行连续对齐的段落,并将满足验证条件的文档作为对齐数据自动编排保存。
具体而言,利用回车符和标点两类标记确定段落边界,接着根据信息量比值进行段落层级对齐。基于此,使用以下对齐策略:
1) 切分段落时,汉语的切分标点为“。”“,”“:”和“;”。哈萨克语的切分标点为“.”和“,”“:”和“;”。其中对于前后字符都是数字的冒号,不能作为切分符号。切分后,对大致对齐的段落匹配其中包含数字信息的片段(例如匹配小数点“.”,连续数字串等),并以这些信息量比值的分段边界,将其前后分属的切分段纳入汉-哈文本段落对齐中。
2) 对汉语和哈文段落生成对齐。对于同一条文本,中文表达通常比哈萨克语表达包含更多的字符,因此,切分算法以汉语的切分单元为基准,来匹配哈萨克语。对齐过程限制哈文分段(j<n≤255)对应的哈文段落信息量值不能超过len(P哈j)≤255 个字符。以汉语为准,逐步增加平行语料匹配所用的切分段,匹配时,按照序列长度比例接近“1∶1 型”和“1∶n型”信息含量比值的段落对齐结果,以匹配累积最快的片段达到信息含量比为段落级对齐。值得说明的是,在累计段落较长时需要引入人工对齐的方法,如图4 所示。

图4 Corpus汉-哈文本段落对齐的界面Fig.4 Chinese-Kazakh paragraph alignment interface of Corpus
比如,Corpus 平行段落层的对齐实际操作中,段落生成后,原来P汉i+1原信息量值为513字符,分割为三个段落P汉1,P汉2,P汉3。其中,第三个段落P汉3的信息量值为68 字符,P哈3信息量值316 字符,对齐异常。其原因是对齐中哈文段落信息量比值已超过255 字符。
3) 值得注意的是,在对齐的段落内,不同的语言中公用的数字和代码字符,可以极大便利段落对齐工作。在数字代码字符的数量高达20% 左右,可以将其视为现成的段落对齐依据。因此,在上文策略的基础上,额外加入数字配对信息作为多层分段对齐的依据。
在此过程中,本节针对汉-哈文的段落对齐,提出了使用信息量比值的段落层对齐方法。信息量比值是基于序列长度定义的特征,在给定篇章内自动生成为段落后,可通过“1∶1型”显著的边界符号,例如:汉文段落边界“。”对应哈文段落边界符号“.”。此特征大致确定对应的汉-哈段落序列边界,得到初步的段落对齐关系。
2.4 基于段落对齐的数据编排存储
段落对齐的编排存储的实际意义是人工对段落对齐数据进行进一步优化。上述的对齐过程并不能完美覆盖所有可能情况下的段落对齐,因此,研究人员必须对初步结果进行人工对齐保证语料质量,为后续构建更细致的段落对齐数据作准备。针对汉-哈文料的构建需求,开发对应的段落对齐软件,用于存储和对齐语料,如图5 所示。
在对齐的两个篇章中,先把汉语篇章导入到对齐软件中的A列,再把对应的哈萨克语篇章导入到对齐软件中的B列中;导入后自动分成两组对应的段落模块A=(A1,A2,…,An)和B=(B1,B2,…,Bj…,Bn);以换行符为区隔,对数据进行自动生成为汉-哈文对齐的段落序列A和B。
通过上文介绍的基于信息量比值的对齐,对段落内的进行对齐分析。在汉-哈文段落对齐中,超过字符255 的段落进行人工移到下一行,不足字符的移上一行,移除空行。本文研究传统的excel 软件段落对齐功能基础上,提供使用了可视化扩展软件“Corpus”,它覆盖了以上段落自动对齐功能的优化。该软件段落自动对齐同时可以自动编排存储已对齐的段落平行语料数据,也提高了段落对齐的速度和质量。
3 实验及结果分析
3.1 实验设置
3.1.1 数据集
本文实验使用辅助工具对齐软件Corpus 和PHP 语言来实现的汉-哈文本对齐,它针对特定汉-哈文篇章对齐结构的源文档设计,适用于从html 和xml 文件中提取格式化数据。PHP(Personal home page)是目前最流行的网站开发语言,据统计有80% 的网站由PHP 开发。因此,本研究构建的汉-哈语料库的文档对齐方法使用PHP 进行开发。
本文通过跨语言网页《天山网新闻》的(https://www.ts.cn)和(https://www.kazakh.ts.cn)获取汉-哈文本新闻文档数据,包括段落对齐后的汉-哈文段落句。以下几个步骤:
(1)从本网页中抽取篇章文档镜像存储到本地;
(2)需要数据文档生成为两组文件格式A*.txt、哈文文档B*.txt 格式存储;
(3)根据题目和内容进行汉-哈文档的匹配;
(4)通过搜索新闻,不断获取更新和收集数据。
本文选择了语料质量和规模比较高的新闻网站文本数据,人工识别确认。因此可以保证从新闻网文本有一定的翻译质量。
3.1.2 实验环境
1) 硬件环境:T14i7-10510u、8 GB 内存、512 GB 固态硬盘。
2) 软件环境:软件环境:Windows 10,64 位操作系统,记事本txt、excel 等办公应用软件及数据库软件作为构建汉-哈文篇章平行语料环境。同时,在约定网站上下载汉文、哈文文档的网页存储到本地生成篇章对齐文本数据。同时通过扩展汉-哈文本语料对齐软件“Corpus”汉-哈文段落对齐语料构建系统,提供了段落对齐的优化功能,该软件方便机器翻译和平行语料研究者使用,方便在后续实验工作中增加新的功能或借鉴使用现有的一些软件,也方便预处理和语料构建的结果。此外,该对齐系统也拥有直观、简洁的用户界面。
3.1.3 评价指标
本文采用召回和正确率评价算法的有效性。召回率和正确率的计算公式如下:
3.2 实验结果分析
本节实验随机选取汉-哈文新闻网页获取数据,筛选80~100 篇章对齐观察,并总结信息量比值的分布情况。具体实验情况如下:(规模小,实验单一)
通过实验共识别筛选出806 条段落句对齐数据的“1∶1 型”比较汉-哈段落数长度计算比较,人工段落对齐发现较长的汉语段落171 字符单位对应的哈语段落540 字符单位,如图6所示。
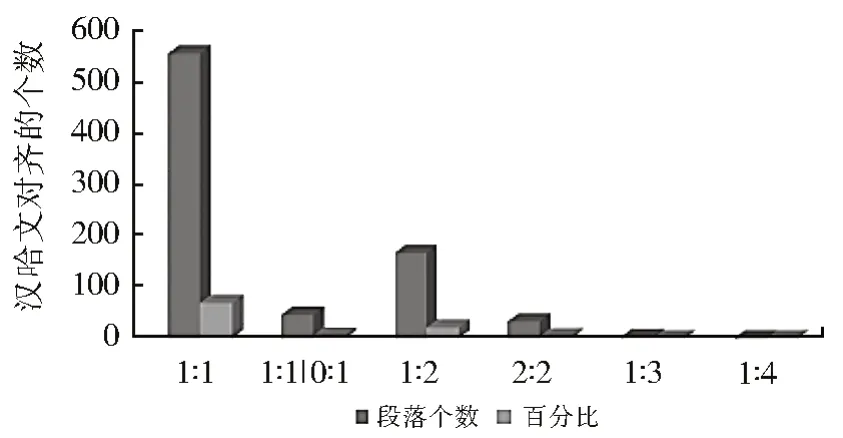
图6 文章对齐效果统计Fig.6 Statistics of alignment results
从实验结果中可以看出本文的段落对齐方法有较多的1∶1 和1∶2 及2∶2 类型,而1∶3和1∶4 类型较低,说明数据文本所含杂质数据极少。
(1) 在汉-哈平行篇章内的不同信息量比值的段落都有较高的准确率和召回率。信息量比值对齐段落包含了人工识别对齐的段落(句)4967 个条,将近正确率93%,召回率为100%。并且采用本文提出的信息量比值方法使段落对齐的准确率有所提高。以此进行自动对齐时,对齐篇章、段落文本长度比值相近,如图7—8 所示。
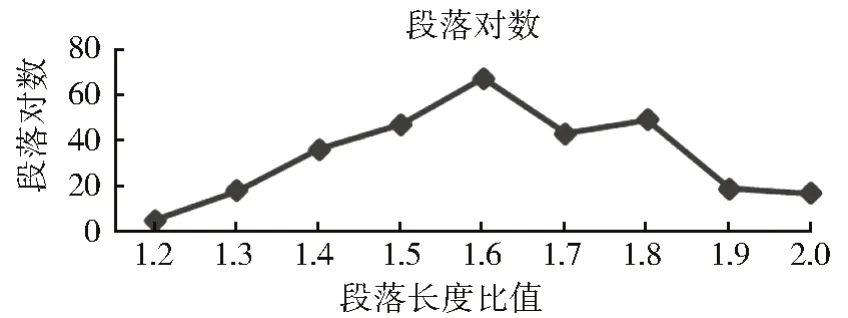
图7 段落长度比值Fig.7 Statistics of paragraph length ratio
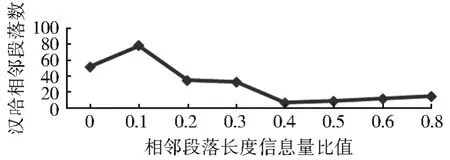
图8 相邻段落长度信息量比值Fig.8 Statistics of information ratio of adjacent paragraph
(2) 段落对齐结果对应的信息量比值分布所示,从统计实验数据及分析分布区间可以看出汉-哈文的段落长度以近似形似正态分布集中落于[1,7]区间,其中,区间[2,6]占到所有段落的95%。而哈文段落间比值和中文文段落间比值差值范围依然是[0,0.5],其中,区间[0,0.3]占到所有段落的94%,如图9 所示。
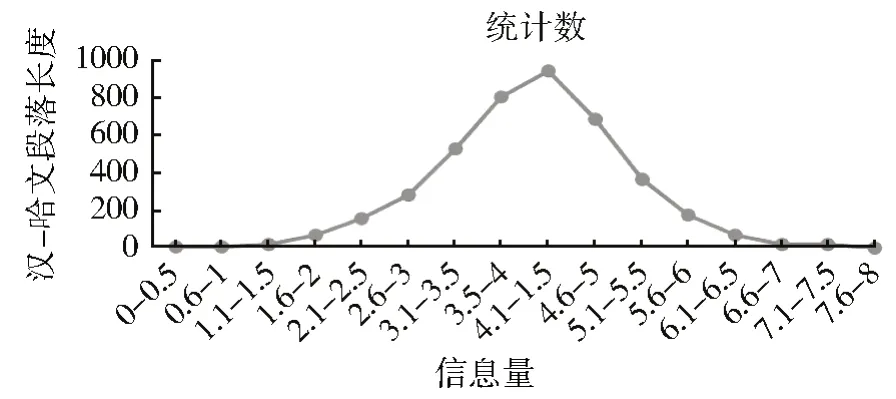
图9 信息量正态分布情况Fig.9 Normal distribution of information
由于各个实验方法的信息量的不同,直接对比段落对齐映射进行充分的比较,段落对齐的映射过程,汉-哈文相邻段落比值差变化不低于87.5%。该结果表明汉文段落与哈文段落的相对长度比值范围较为稳定,可以用于汉-哈文段落对齐,如表1 所示。
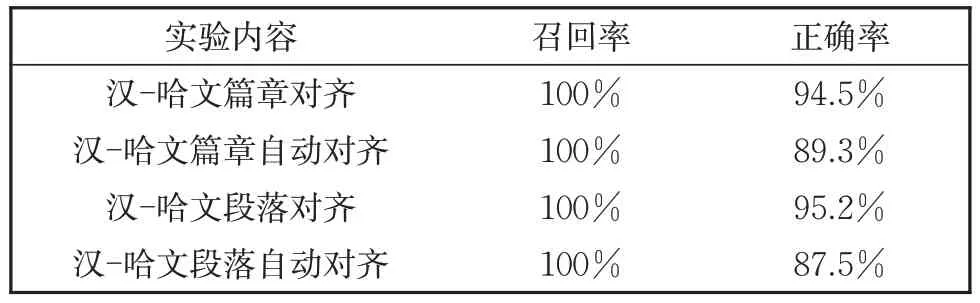
表1 篇章/段落对齐实验评价结果Table 1 Evaluation of chapter/paragraph alignment experiment
从表1 可以看出,汉-哈篇章手工对齐、汉-哈段落自动对齐、汉-哈段落自动对齐的召回率达到了100%、汉-哈自动对齐正确率稍有差异。汉-哈篇章手工对齐的正确率94.5%。
对于大规模语料库,使用相似度计算方法,结合小规模汉-哈文平行语料库的统计结果,可以发现本文提出的段落对齐方法仍然存在一些不足。但在大多数情况下,本文的方法不会影响原始汉-哈文平行语料库的规模和质量,能够提高对齐工作的效率。
4 结论
本文收集了汉-哈文篇章新闻网页的数据,提出了数据的预处理和信息量比值的段落对齐方法。其中,本研究针对文本预处理需求和对应流程,利用拓展开发的Corpus 软件进行语料预处理和自动段落对齐,实现了汉-哈文对齐边界,并对语料数据自动进行编排存储。实验结果表明,根据文本对齐质量和语料规模限制的汉-哈平行篇章与段落手工对齐正确率达到94.5%,95.2%;自动对齐正确率达到87.5%,89.3%,成功构建了适用于机器翻译的篇章或段落对齐汉-哈平行语料库。此外,相比于传统的段落对齐方法,该方法简单方便,能帮助研究人员加快高效地构建翻译平行语料,降低翻译数据获取成本,帮助汉-哈开展文字互译与信息交流,有利于我国人工智能领域发展,为跨国大数据建设提供支持。
