基于模态交互学习的属性级情感分析
2023-06-05张绍武崔席郡伊博乐杨亮
张绍武,崔席郡,伊博乐,杨亮
(大连理工大学 计算机科学与技术学院,辽宁 大连 116024)
0 引言
情感分析是利用自然语言处理、文本分析、计算语言学和生物统计学来系统地识别、提取、量化和研究人类的情感状态和主观信息的窗口。人们在互联网上发布的带有情感特征的信息以指数级增长,情感分析系统广泛应用于几乎所有商业和社会领域。意见是大多数人类活动的核心,是我们行为的关键影响因素,而我们的思想与对现实的感知以及我们所做的选择,在很大程度上受制于他人对世界的看法和评价[1]。因此,情感分析对研究个人与社会发展非常重要。
其中,面向文本的情感分析可以分为三个层面,即文档层面、句子层面和属性层面[2]。文档层面的情感分析中假设整个文档中只包含一个主题。这很明显在很多情况下是不合理的。通常的情况为一个句子将会包含多个主题(即属性),在同一个句子中,这些主题表达的情感可能是相反的。属性级情感分析的目的是判断讨论每个主题所表达的情感极性,在此之上利用评论/推文提供的更多信息进行更详细的分析。
基于文本的情感分析模型已经在近几年得到了较大的发展并趋近成熟,且互联网上大部分的信息往往是文本与其他媒介(即模态)共存的。模态交互的情感分析依赖一种以上模态(如文本和图像)获得的信息进行分析[3]。模态交互学习即在文本模态的基础上,引入其他模态的信息,对多个模态进行交互学习。对文献的调查显示,与文本情感分析相比,模态交互的情感分析能使得计算机能够以更加全面而立体的方式分析人类的情感,也使情感分析进入到了全新的领域。
以图像-文本双模态为例,模态本身为信息的渠道,来自多个源的数据大部分在语义上是相关的,互补的[4]。在拥有图片信息的基础上,对文字中情感的判别将起到更加积极的作用,如给出文本:“My [mother] is looking at the kitchen VS My [father] is looking at the kitchen.”我们很难从文本中分别判断属性词“mother”和“father”的情感极性,而若以图片信息加以辅助,如图1 所示,则很容易得到他们正确的情感极性,即“mother”的情感极性为Negative,“father”的情感极性为Positive。而基于另一模态能得到的信息远不止于此,它能发现单一模态无法发现的更多属性关系。因此,模态交互的属性级情感分析也正在成为一个值得深入研究的子课题,得到国内外研究者的广泛关注[5]。

图1 模态交互的属性级情感分析用例Fig.1 An example of modality interaction aspect-based sentiment analysis
目前模态交互任务所存在的问题在于:
(1)引入图像模态可能会引入一些噪声,如一些与文本模态无关的图片信息,可能会导致模型性能的下降。
(2)图文模态之间的交互如何进行,如何更好地让模型将图像模态中的信息引入到文本模态之中。
基于以上问题,本文基于目前先进的方法首先对文字、图像双模态分别使用BERT,ResNet 预训练模型进行特征提取工作,在关系提取模型决定文本与图像模态融合方法的前提下,使用Self-Attention 机制与跨模态Attention机制得到文本与图像模态之间的关系概率值并将其应用于属性词提取、情感极性分类两个下游任务中。本文在Twitter15 和Twitter17 两个数据集上对模型进行了测试,得到了较为理想的实验结果。
1 相关工作
多模态属性级情感分析是多模态情感分析中一项重要的、细化的任务[6]。以前的研究通常将社交媒体中的多模态属性级情感分析视为两个独立的子任务——属性词提取和属性级情感分类。首先,属性词提取旨在从自由文本及其附带的图像中检测出所有潜在的一组属性词。其次,属性级情感分类的目的是对特定属性的情感极性进行分类。
对于多模态属性词提取任务,Ma 等[7],Karamanolakis 等[8]提出了序列标记的方法。在实体识别的相关研究基础上,Moon 等[9]在RNN 上提出了ResNet 模型进行属性词提取,并利用图像模态的信息来增强文本模态的表示。在此之后Yu 等[10]在Transformer 上建立了模型,为了捕捉模态内的动态,Yu 等利用一种有效的Attention 机制来生成属性词敏感的文本表示法,然后将它们与文本特征聚合并对图像模态进行了视觉环境的噪音清洗,在此基础上进行了模态融合与属性词的位置预测。Zhang等[11]在GNN 上,针对基于图的模型分析句法结构时忽略语料库级别的单词共现信息的缺点提出了使用全局词汇图来编码语料库级别的单词共现信息模型,在句法图和词法图上建立了一个概念层以区分含各类型依赖关系的词对,并在此基础上,设计了一个双级交互图卷积网络,该模型在任务评估中并取得了优秀的结果。
对于多模态属性级情感分类任务,与Liang等[12]研究的基于文本的属性级情感分类不同,所用模态的增多也代表了模型复杂度的上升。其中,在多模态的任务上,Xu 等[13]第一个从数字产品评论平台标注了一个中文数据集用于多模态属性级情感分析,并为这一任务提出了多交互式记忆网络模型,其中使用了两个交互式记忆网络来监督文本和图像信息的属性,同时学习跨模态数据间的交互影响与单模态数据的自我影响。在最近的研究中,Yu 和Jiang[14]在Twitter 中标注了两个数据集Twitter15 与Twitter17 用于多模态的情感分类任务,在此基础上,Yu 和Jiang[14]利用BERT 作为基线模型,建立了模态内的动态模型,该研究中使用BERT获得目标属性词敏感的文本表征,并使用Self-Attention 的思想设计属性词Attention 机制来进行属性词和图像的匹配,以获得属性词敏感的图像模态表征,在此基础上该研究建立了模态间的动态模型,进一步使用跨模态Attention 层捕捉多种模态之间的互动并最终得到了可观的结果。
在文本和图像模态的交互任务中,模态融合为研究的核心与关键所在。在Alakananda等[15]标注Twitter 文本图像关系数据集(本研究所应用的数据集)前,多模态文本与图像关系方面的工作没有集中在Twitter 等社交媒体的数据上。Alikhani 等[16]在食谱数据集上围绕以下维度对教学文本和图像之间的关系进行注释并训练模型,而Chen 等[17]使用社交媒体数据研究文本与图像关系,利用预测关系类型的文本和图像内容建立模型,其研究重点是区分图像在整体上与文本内容视觉上相关或不相关。本实验使用的关系数据集关注了推文语义重叠和对整个推文意义的贡献。而在文本与图像的提取任务方面,Feng 等[18]实现了在图像基础上生成相应的文本,Mahajan 等[19]使用推文等来源的嘈杂图像文本对进行训练,在此大型训练数据集的基础上建立了模型并实现了图像标签预测的任务。Moon 等[20]的多模态命名实体模糊化任务则利用社交媒体图像的视觉背景向量来实现命名实体的模糊化处理。Sorodoc 等[21]所实现的多模态(文本与图像)主题标签任务则侧重于为给定的主题生成候选标签,并根据相关性对其进行排序。这些任务前提是数据集中的文本与图像的意义必然有关联,而在Alakananda 等[15]的研究中表明这种关联性并不是一定存在的,这也为本研究的文本图像关系挖掘打下了基础,提高了文本与图像模态进行融合时的可行性与有效性。而关于本研究中所用到的标注数据集(Alakananda 等[15]),将会在下文中进行详细阐述。
2 ReBERT模型
2.1 关系提取模型
本研究在文本图像模态融合时主要选用Attention 机制进行模态融合,其流程图如图2所示。

图2 关系提取模型模态融合Fig.2 Modal fusion of relation extraction model
与Ju 等[6]使用的方法类似,本研究首先对文本与图像模态分别使用Self-Attention 捕捉各模态内部的信息并进行特征表示,该模块采用了多头Attention 模型来进行实现。多头Attention 即当给定相同的Q,K,V(查询,键,值)的组合时,为了令模型可以基于相同的Attention机制学习到不同的行为,不单单使用一个Attention 池化,该模型通过线性投影来变换Q,K,V,将变换后的Q,K,V并行进行Attention池化。将不同线性投影的Attention 池化输出进行concat 后,通过线性变换即可产生最终输出。该模型的主要框架如公式(1)—(4)所示。
(1) 字向量与位置编码
(2) Self-attention 机制,其中WQ,WK,WV均为可学习参数
(3) 残差连接与归一化处理
(4) 每个Attention 头的计算方法,其中WQ,Wk,WV均为可学习参数,而f(x) 为Attention 池化函数。
基于这种设计,每个Attention 头都能够关注输入的不同部分。可以表示比简单加权平均值更复杂的函数结构,更多角度地实现其特征表示。每个文字经过多头Attention 机制之后会得到一个R矩阵,这个R矩阵表示这个字与其他字在N个角度(Attention 头)的关联。Transformer 结构依赖于Attention 机制,以优异的性能取代了基于Encoder-Decoder 的循环层,并引入了位置嵌入,本研究的多头Attention 总数为8,能够较好地捕捉模态内的联系。
而后进行跨模态交互,分别对文本图像模态进行跨模态Attention 以捕捉文本图像模态之间的信息,其有关跨模态Attention 如以下公式(5)所示,最后再分别对其Self-Attention 与跨模态Attention 的特征进行concat 操作,再将其送入前馈神经网络中进行预测,从单模态以及多模态多个层面更加全面地得到其预测结果,其预测分数将表示为Sr。
如公式(5)所示,跨模态Attention 模型同样为多头Attention 模型,其大体模型结构与上文中的单模态下自Attention 的框架类似,该模型利用Transformer 从跨模态交互中捕捉每个序列间的互动。设其中一模态为α,另一模态为β,则模态(β→α)之间的跨模态Attention 则为Zα,CMβ→α为跨模态Attention 机制,其中两模态的输入为Xα,Xβ,d为输入维度,在此基础上进行跨模态运算。
2.2 ReBERT模态交互属性词提取模型
本研究提出基于关系提取的属性词提取模型,即ReBERT,其关键是利用上文关系提取模型对图像模态输入进行控制,并在此基础上使用Attention 机制,在数据集进行跨度(Span)标注的前提下进行属性词预测,其主要模型结构如图3 所示。
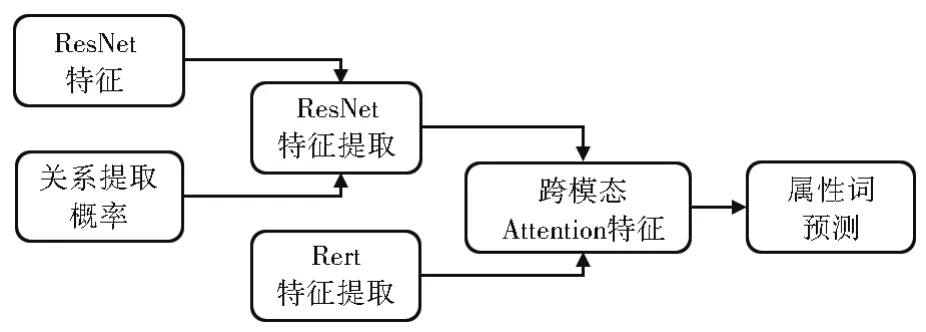
图3 属性词提取的ReBERT模型结构Fig.3 Overall architecture of ReBERT for aspect term extraction
基于关系提取模型的输出结果Sr,在进行模态间融合前应进行输入图像模态的控制,其控制方式如公式(7)所示:
Re函数为前文关系提取模型的概括函数,当其输入为T,I即文本模态与图像模态后,将其得到的关系概率值与从ResNet 模型中新训练的图像模态In进行点乘,以得到被赋予关系概率的与文本模态进行交互的图像模态特征。
应用上文中的跨模态Attention,将文本模态与图像模态进行交互,如公式(8)所示:
其中 ⊕ 为元素的哈达玛积(Hadamard product),对输入向量T给定的“权重”也就是经处理后的图像模态Inr进行列缩放,wa和ba分别为可学习的权重和偏置。
而hL将用于接下来的预测任务中,与RAN 与UMT 等使用BIO 标签的模型不同,该模型采用了Ju 等[6]与Hu 等[22]的SPAN 标签方法,即基于跨度(Span)的提取框架,在属性词跨度边界的监督下,直接从句子中提取多个属性词并利用其跨度表示对相应的情感极性进行分类。
如上文Twitter15/17 数据集的标记方法,本研究根据Hu 等[22]的研究引入了其提取框架用于属性词的提取。该算法要求其使用启发式多段编码来提取(多个)属性词,并用其跨度表示对其进行分类解码。采用该方法的优点是属性词提取的搜索空间可以随着句子长度的增加而线性减少,远远低于RAN,UMT 所用的BIO 标签法的复杂度。
其中,ws与we为其可训练参数,得到Ps与Pe则分别为SPAN 标记法所标注的属性词的开始位置与终止位置。在Twitter15 与Twitter17 数据集中为“T-NEG/POS/NEU-B”到“T-NEG/POS/NEU”且下一标记为“O”的位置。
该模型的损失函数Losse如下公式(10)所示:
其中,若每个句子中有多个属性词,则其判别结果将存储于一个新的向量中。对于所记录的属性词开始位置,则在ys中存储;对于所记录属性词的结束位置,则在ye中存储。
2.3 ReBERT模态交互属性级情感识别模型
本研究提出基于关系提取的属性级别情感识别模型即ReBERT,其关键是利用关系提取模型控制图像模态的输入,并在此基础上使用Attention 机制来进行模态内与模态间的交互,其主要模型结构如图4 所示。

图4 情感分析的ReBERT模型结构Fig.4 Overall architecture of ReBERT for sentiment analysis
令M为一组多模态数据,每一个多模态数据mi∈M由以下三部分组成:推文文本Si=(w1,w2,…,wn),其中n为文本的词数;推文相关的图像Ii;推文属性词Ti,其中Ti为Si的子集。
其中推文属性词的情感标签可以分为yi∈ {Negative,Neutral,Positive}.而本研究的目标是训练一个模型能够计算函数f:(Ti,Si,Ii) →yi,即做到属性词情感极性的预测。
基于关系提取模型的输出结果Sr,在进行模态间融合前应进行输入图像模态的控制,其控制方式如公式(11)所示,与前文属性词提取任务采用相同的方法对模态进行交互与连接。
在此基础上应用上文中的跨模态Attention,而根据Yu 等[14]的研究,对多模态进行最终池化的方法有三类。其一为多模态输入序列的第一个标记总是区域图像特征的加权和,该隐藏状态作为一个图像模态的多模态表现,包含了比较丰富的模态信息,因此可以作为输出。即Out=H0;其中H为经Attention 操作之后用于进行分类操作的多模态特征。其二为[CLS],特殊标记(即句子输入中的[CLS]标记)的最终隐藏状态作为一个文本模态的多模态表现,包含了比较丰富的模态信息,因此可以作为输出。即Out=H[CLS];其三为将文本图像双模态的隐藏状态进行concat 后混合输出,即Out= [H0,H[CLS]]。此后将Out送入一个线性函数则可以得到情感的预测值,其计算如公式(12)所示:
其中,wp为其可训练参数,该模型的损失函数Lossc如公式(13)所示:
3 实验
3.1 实验数据
3.1.1 关系数据集
该实验进行图像与文本模态关系模型训练时所用的Twitter 数据集为Alakananda 等[15]所标注的Twitter 文本图像关系数据集。在对2016 年的推文进行注释后使用langid.py 过滤非英文推文,最终用于本实验的关系数据集包含4471 条推文。该数据集使用 Figure Eight(CrowdFlower)平台对4471 条从推文中收集的文本图像进行注释。

表1 关系数据集中各类型数据Table 1 Statistics of the relationship dataset
3.1.2 Twitter数据集
Twitter2015 与Twitter2017 数据集由Yu等[10]从TwitterAPI 上集中获取,包含了从2016年5 月,2017 年1 月和2017 年6 月提取的推文及其相关图像。该数据集在数据筛取时未考虑不含有图片的信息,且若推文有一个以上的图片与之相关,则该数据集仅随机选取了其中一个图像作为其关联图像。
数据集将被随机分割为train(60%),development(20%)与test(20%)部分,分割后的Twitter2015 与Twitter2017 各情感标签下的数据如表2 所示。

表2 Twitter 2015和Twitter 2017数据集数据量表Table 2 Statistics of the Twitter 2015 and Twitter 2017
3.2 实验参数
实验参数如表3 所示。

表3 实验参数设置Table 3 Experiment parameters settings
3.3 评价指标
情感识别任务中,常用的评价指标是精确率(Precision),召回率(Recall)与F1 值。其对应的计算公式如(14),(15)与(16)所示:
对于多标签分类任务(如本研究属性级别情感预测中的三标签POS/NEU/NEG 分类任务),应对F1 值的算法进行一些调整。Macro-F1 的计算方法如公式(17)所示:
3.4 对比模型
(1)LSTM + InceptionNet 模型:Alakananda等[15]用了concat 的特征融合方法与全连接层的预测方法。
(2)RAN 模型:RAN 是由Wu 等[23]提出的首个多模态属性词提取模型,其重点在于从图像模态捕捉正确的信息并加入对属性词位置的分析中。
(3)UMT 模型:UMT 是Yu 等[24]提出的多模态属性词提取模型。
(4)TomBert 模型:TomBERT 是由Yu 等[14]提出的基于BERT 的多模态属性级情感识别模型。
(5)ESAFN 模型:ESAFN 是由Yu 等[10]基于LSTM 提出的多模态属性级情感识别模型。
3.5 实验结果与分析
3.5.1 关系提取模型实验结果
Alakananda 等[15]的研究模型为LSTM +InceptionNet,本研究的模型则为BERT +ResNet,其中LSTM + InceptionNet 模型的超参数设置与Alakananda 等进行实验时所设置的相同,而本研究BERT + ResNet 基础上的关系提取模型中使用的超参数列表如表3 所示,其参数初值主要参考了Khan 等[25]同样基于BERT的多模态属性级情感识别任务,在本研究基础上进行微调即得到模型较优的参数设置。
本研究用训练集的十折交叉验证来调整参数以测试算法的准确性。其训练结果可表示为Ei。最后对训练后的10 个模型的结果求均值,如公式(18)所示,该结果即可作为最后交叉验证的结果。
经十折交叉验证取平均后,本研究中使用BERT + ResNet 模型的实验结果与Alakananda等[15]LSTM +InceptionNet 的实验结果如下表4所示。

表4 关系提取模型实验结果Table 4 Experimental results of relation extraction model
通过对比关系提取模型可以看出,在文字与图像模态的特征提取模型变化后,其对图片是否会对文本产生增益的判断效果没有任何影响。基于关系数据集构造的关系提取模型能够较好地预测图像模态的数据是否需要与文本模态进行融合,在已有模型的基础上对下游任务的效率与预测结果进行了优化。
3.5.2 属性词提取模型实验结果
在属性词提取这一子任务上,本研究提出的模型ReBERT 分别与上文中提及的经典模型UMT 与RAN 分别进行了对比实验,并进行了消融实验。以上实验均在Twitter 2015/2017 两数据集上分别进行测试,其使用方法为上文关系提取模型中所用到的十折交叉验证方法,从10 次结果中取平均值得出可靠性强的实验结果。其各模型上的实验结果如表5—表8 所示,分别展示了各任务下各实验模型的精确率,召回率与其判断重要标准F1 值。

表6 Twitter2017属性词提取对比实验结果Table 6 Comparative experimental results of aspect extraction on Twitter 2017

表7 Twitter2015属性词提取消融实验结果Table 7 Ablation experimental results of aspect extraction on Twitter 2015

表8 Twitter2017属性词提取消融实验结果Table 8 Ablation experimental results of aspect extraction on Twitter 2017
由以上实验结果,可以看出本研究模型在原基线模型上的进步,在消融实验基础上与RAN 与UMT 模型进行比较,可以发现当关系模型或图像模态从ReBERT 模型中去除时其模型效果的下降十分明显,甚至在模型表现上劣于基线模型。而对比将图像模态去除时的实验结果,可以发现ReBERT 模型的效果下降比除去关系模型时的程度小。因此可以得出关系模型对ReBERT 实验结果的影响较大,文本图像模态的融合是该任务得到提升的关键之一。
3.5.3 属性级情感分析模型实验结果
在属性级情感分析这一子任务上,本研究提出的模型ReBERT 分别与上文中提及的经典模型TomBERT 与ESAFN 分别进行了对比实验,并进行了消融实验。
其实验设置同上述章节。其各模型上的实验结果如表9—表12 所示,分别展示了各任务下各实验模型的精确率、召回率与F1 值。
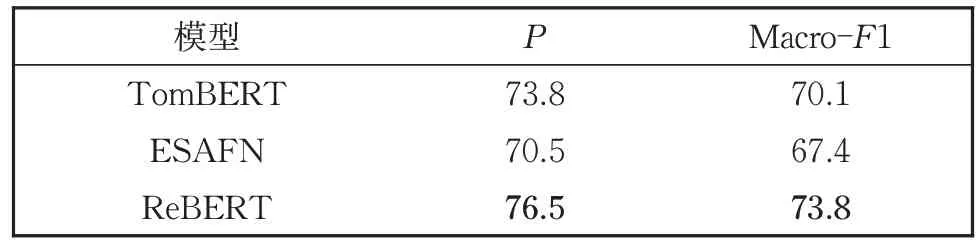
表9 Twitter2015属性级情感分析对比实验结果Table 9 Comparative experimental results of sentiment analysis on Twitter 2015

表10 Twitter2017属性级情感分析对比实验结果Table 10 Comparative experimental results of sentiment analysis on Twitter 2017

表11 Twitter2015属性级情感分析消融实验结果Table 11 Ablation experimental results of sentiment analysis on Twitter 2015

表12 Twitter2017属性级情感分析消融实验结果Table 12 Ablation experimental results of sentiment analysis on Twitter 2017
在消融实验基础上与TomBERT 和ESAFN模型进行比较,可以发现当关系模型或图像模态从ReBERT 模型中去除时其模型效果下降明显,且在少数情况下模型表现上劣于对比实验模型。消融实验的结果表明去除关系模型与去除图像模态对ReBERT 模型的影响几乎相当。由此可以推断,与属性词识别不同,属性级别情感识别任务对图像模态更加敏感,受图像模态影响更大。
4 结论
本文分别介绍了关系提取模型,属性词提取模型,属性级情感识别模型的实验结果,分别在Twitter 15/17 数据集上进行了多重验证,在已有研究的基础上进行了对比试验,论证了实验的可行性;在本研究模型的基础上进行了消融实验,论证了实验的必要性;本研究的所有模型结果均在十折交叉验证的基础上得出,保证了实验结果的准确性。由此得出本研究建立的基于关系提取的属性级情感识别模型能够较好地完成任务,根据本研究的评价标准,本研究的研究成果符合要求。
