用于多标签文本分类的深度模块化标签注意网络
2023-06-05田小瑜秦永彬黄瑞章陈艳平
田小瑜,秦永彬*,黄瑞章,陈艳平
(1.贵州大学 公共大数据国家重点实验室,贵州 贵阳 550025;2.贵州大学 计算机科学与技术学院,贵州 贵阳 550025)
0 引言
在传统的文本分类中,每个文本实例只与一个类别相关联,而随着大数据时代的到来,现实世界中的文本实例可能包含复杂且多样的语义信息,然而传统的分类方法已不能解决现有的问题。与传统的文本分类任务相比,多标签文本分类需要对文本有更深入的理解,进而全面地从文本中提取出与标签相关的信息来实现精准分类。此外,有效的多标签文本分类算法可以支持其广泛的下游任务,如信息检索、推荐系统、情感分析等。因此,多标签文本分类引起了业界和学术界的广泛关注。
到目前为止,研究者们提出了大量的多标签文本分类算法并都取得了不同程度的成功,它们大致可以分为三类:问题转化方法[1-3]、算法适应方法[4-5]和深度学习方法。由于深度学习具有较强的特征提取能力,研究人员基于深度学习对多标签文本分类方法进行了大量的研究。具有代表性的深度学习的方法有CNN[6-8]、RNN[9-11]和注意力机制[12]等,它们都在文本特征表示方面取得了巨大的成功。然而,它们中的大多数都只关注文本的特征表示,而没有显式地在文本和标签之间建立连接。这相当于让所有标签共享相同的特征空间,并没有针对性地为每个标签提取出与其关联的辨别信息,进而使得模型的性能受到限制。为了克服这一缺陷,有些模型[13-14]基于序列到序列的方法来提高模型性能,在一定程度上考虑了文本与标签的特征关联和标签之间的相关性,但依然没有从根本上解决问题。近几年来,为了从文本特征中提取与标签相关的鉴别信息,研究者们主要利用标签文本或标签描述中的标签语义信息从文档中获取标签特定的文本表示进而提升模型的分类性能[15-18]。虽然它们在某些情况下获得了很好的结果,但它们只是专注于从实例特征空间向标签空间的单向映射来学习标签特定的文本表示,因此只考虑标签和文本实例之间的简单关联且仍具有提升空间。
如上所述,现有的方法仍然无法充分且有效地利用标签和文档之间潜在的相关关系,继而在提取文本中与标签关联的鉴别信息上仍有不足之处。随着运用在问答任务上的动态共同注意网络的成功,它首次融合了问题和文本内容的相互依赖表示,以关注两者的相关部分[19-20]。基于此,本文在MCAN 框架[21]基础上提出深度模块化的标签注意网络,以克服现有标签特定文本特征学习方法的弱点。在网络构建过程中,本文设计了两个注意力单元:双向标签注意单元和自我注意单元。对于双向标签注意单元,一个方向是从文本到标签,可以获得每个文本的标签特定表示;另一个方向是从标签到文本,可以过滤与标签无关的噪声信息,生成干净的文本特征表示。对于自我注意单元,它可以用来增强文本特征。然后,通过双向标签注意单元和自我注意单元的模块化组合,得到了可以进行深度级联的模块化标签注意网络层(MLA)。此外,现有的模型往往只从标签文本或标签描述中获取标签的语义表达,就像单词嵌入一样。但在大多数数据集中,标签的描述信息极少甚至只是一个单词,这显然是不够的。因此,本文采用学习向量化从文本实例中学习丰富的标签表示。文章的主要贡献如下:
(1)通过考虑文本和标签之间的双向映射,提出了一种深度模块化的标签注意网络来处理多标签文本分类。
(2)采用学习向量化来构建更加丰富的标签语义表示。
(3)在三个常用的基准数据集上,运用多个评价指标对深度模块化双向标签注意力的性能进行了深入的比较和分析。
1 相关工作
文本语义表示是多标签文本分类的第一步,对多标签分类器的性能有重要影响。随着深度学习的成功,一些研究者倾向于从原始文本中提取特征来区分所有的标签。而一些研究者假设每个标签都有自己的鉴别特征,这些特征会表现在带有该标签的文本中,他们设计了一些策略来获取文本中关于标签的辨别信息且获得了较理想的表现。下面详细总结了获取文本特征表示和标签特定文本特征表示的方法。此外,还有一些关于标签语义表示的方法。
对于文本语义表示,研究者提出了一些基于卷积神经网络(CNN)的模型[6-8],这些方法可以通过共享卷积核自动提取需要的特征。尽管在一定程度上取得了成功,但由于受到卷积核大小的限制,使得局部和整体之间的语义关联被忽略,大量有价值的信息在池化层中丢失。为了克服这些缺点,研究者们利用循环神经网络(RNN)并得到了出色的结果,此类方法可以确定文本的长距离依赖关系[9-10]。此外,Lin 等[11]假设对于文本分类,人类不会只是简单地基于单词级别的信息而分配文本标签,而是通常基于他们对源文本中显著意义的理解,例如一些词组。因此,他们设计了扩张卷积(MDC),在支持接受域的指数扩展的同时不损失局部信息,以产生更高层次的文本语义单元表示。Peng 等结合RNN 和CNN,分别使用双向RNN 捕捉上下文信息和CNN 捕捉关键字[22-23]。
为了获得特定于标签的文档表示,需要建立文本和标签之间的语义连接。对于这类方法,研究者们假设每个标签都有其对应的语义表示,进而可以明确地告诉模型要分类什么,并从文本中挖掘出与标签相关的部分来进行精准分类。Xiao 等提出了标签特定注意网络(LSAN)来学习新的文本表示,并将其与自我注意相结合构建标签特定的文本表示[16]。Liu等假设细粒度的标记级文本表示和标签嵌入有助于分类,提出了一个标签嵌入的双向注意模型,以提高BERT 文本分类框架的性能[18]。Guo 等认为文本的每个部分对标签推理的贡献不同,因此双向注意流被用于两个方向上的标签感知文本表示:从文本到标签和从标签到文本[24]。尽管这些工作在多标签分类领域取得了进展,但仍有改进的空间。
为了获取到标签的语义表示,可以通过利用标签结构或者标签文本或描述嵌入编码为向量来作为标签语义表示[15-18]。Chai 等利用强化学习中的抽象/抽取模型获得标签描述进而得到标签的语义表示[25]。Guo 等利用单词和标签共现关系构建一个异构图,然后通过metapath2vec 学习标签表示[24]。这些方法包括一些文本语义信息挖掘方法[26-27],虽然表现良好,但仍然无法获取到充分的标签语义信息。
2 深度模块化标签注意网络
2.1 问题定义
2.2 标签语义表示
在大多数多标签文本分类数据集中,并没有针对标签进行具体的描述,大多只是一个标签词,并不能提供足够的标签语义信息,这会影响模型后续训练的效果。为了获取到丰富的标签语义表示,我们以学习向量化的方式从标记的样例文本中学习标签的语义表示C∈Rl×k。首先,我们从带有标签i的样本中随机选择一个样本的语义表示作为标签i的初始语义表示Ci,然后通过使用与标签距离最近的样本表示Pj更新Ci,如果样列j带有标签i,那么更新标签表示的方式如下所示:
如果样例j不带有标签i,那么更新方式如下:
其中样例与标签之间的距离计算公式如下:
根据以上的跟新方法,重复迭代多次,直到达到最大迭代次数,学习得到标签的语义表示C={C1,C2,…,Cl}∈Rl×k。
2.3 标签注意网络层
如图1 所示,为了处理文本和标签的输入特征,在标签注意网络层构建了两个注意单元,最终输出为特定于标签的文本特征,并将其用于分类。这两个注意单元分别为双向标签注意单元和自我注意单元。
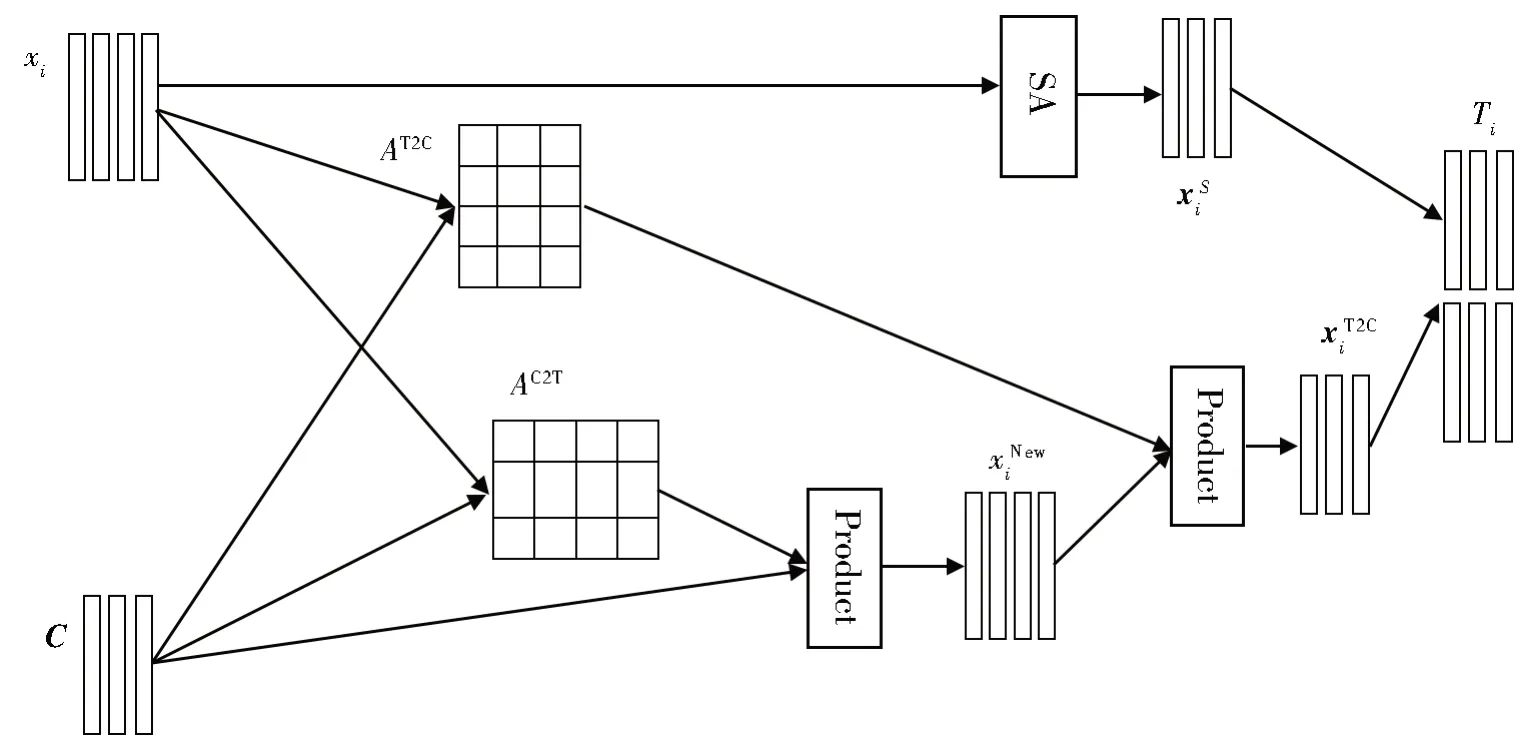
图1 标签注意网络(SA是自我注意机制的英文缩写)Fig.1 Label attention network(SA denotes Self-Attention Mechanism)
对于双向标签注意单元,我们利用文本特征和标签语义表示的相互作用,基于注意力机制从标签到文本和文本到标签的方向来结合这两种表示。双向标签注意单元的输入是文本特征表示xi={w1,w2,…,wn}∈Rn×k和标签语义表示C={C1,C2,…,Cl}∈Rl×k。为了建立文本和标签之间的联系,首先需要计算两者的相似度矩阵,计算公式如下所示:
其中Sij是指文本中第i个单词和第j个标签的相似度。双向标签注意单元依赖相似度矩阵S,将其按行归一化为文本中的每个单词在标签中产生的关注权重AT2C=soft max(S);将其按列归一化为每个标签在整个文本中产生的关注权重AC2T=soft max(ST)。标签到文本方向的注意机制是只关注文本中与标签相关的信息。因此,我们首先在标签到文本的方向通过公式(5)计算得到一个新的文本表示。通过这种方式,我们可以过滤掉原始文本表示中与标签无关的噪音信息,使文本中的标签特征更加明显。
文本到标签方向的注意力可以挖掘出文本中特定于每个标签的语义信息。因此,我们利用(5)中得出的新文本表示基于文本到标签方向的注意力机制计算得出特定于标签的文本表示,公式如下所示:
在双标签注意单元的基础上,为了更加充分捕获文本的多标签语义,本文还使用了只关注文本特征表示的自注意机制(SA),计算得出来补充可能在双向标签注意单元中被忽略的掉的一些特征,公式如下所示:
其中W1∈Rda×k且W2∈Rda×l。最后我们通过水平连接向量和得到第i篇文本综合的特定于标签的文本表示Ti∈Rl×k,这是标签和文档的双向依赖表示。
2.4 深度模块化标签注意网络
本文将图1 所示的标签注意网络组合得到模块化的标签注意网络(如图2(左)所示)用于处理多标签分类的标签和文本特征,然后将其进行深度级联,使上一个标签注意层的输出直接馈入下一个标签注意层(如图2(右)所示)。以前面提到的文本表示xi和标签语义表示C作为输入,即xi_0=xi,C_0=C,本文利用m层标签注意网络级联得到深度模块化标签注意网络。MLAi表示第i层标签注意网络,其输入为第i-1 层的输出,表示形式分别为xi_(i-1)和C_(i-1)。输出用xi_i和C_i表示,与xi_i随m变化不同,C_i是不变的,即C_m=C_(m-1)=…C_0,具体的计算过程如下所示:
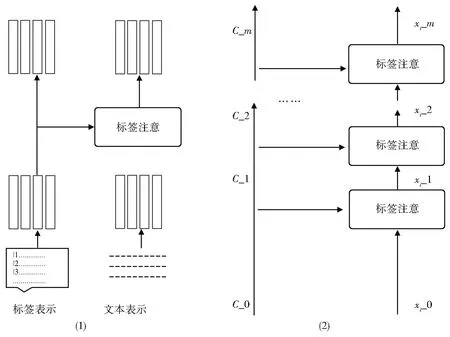
图2 深度模块化标签注意网络Fig.2 Deep modular label attention network
(xi_m,C_m)=MLAm(xi_m-1,C_m-1),(8)其中xi_m∈Rl×k是最终的特定于标签的文本表示。
2.5 分类器
最后,本文利用特定于标签的文本表示来预测每个标签的概率。模型采用带有非共享参数的l个分类函数{f0,f1,…,f(l-1)},其中fj以xi_m的第j行作为输入,即第i个文本特定于标签j的语义特征表示,输出为第i个文本关于标签j的预测概率。对所有标签执行这个过程,得到第i个文本关于所有标签的预测分数Si={Si0,Si1,…,Sil}。
然后再通过sigmoid 激活函数得到第i个文本 关 于 所 有 标 签 的 预 测 概 率Pi={Pi0,Pi1,…,Pil}。为了优化分类器,本文采用交叉熵损失函数作为目标损失函数,其详细的计算公式如下:
3 实验结果及分析
3.1 实验数据集
(1) Reuters Corpus Volume I(RCV1)
这个数据集来自路透社的80 多万篇人工标记的新闻文本组成,其中每篇新闻都包含多个主题标签,标签总数为103 个。对于每篇文本,它都与多个主题标签相关联。
(2) Arvix Academic Paper Dataset(AAPD)
这个数据集是从Arvix 的网站上收集和整理的关于计算机科学领域的论文摘要,总共包括55 840 篇,每一篇摘要被分配多个学科标签,标签总数为54。
(3) European Union Law Document(EURLex)
该数据集是与3956 个主题相关的欧盟法律文件。在公共版本3 中有11 585 个训练实例和3865 个测试实例。
本文在三个公共数据集上验证了我们提出的模型的性能,这些数据集的划分细节如表1所示。

表1 实验数据集统计Table 1 Summary of experimental datasets
3.2 对比模型
为了验证我们模型的有效性,本文从现有的方法中选择了六个代表性的模型作为基线。他们分别是XML-CNN[7]、DXML[28]、SGM[13]、Attention-XML[29]、EXAM[15]、LSAN[16]。
XML-CNN:该模型的主要思想是利用卷积神经网络(CNN)的动态池化技术,结合CNN的优点从原始文本中提取更高级的语义信息,用于多标签文本分类。
DXML:它在特征空间和标签空间建立非线性嵌入,改进了传统的基于深度学习的框架,首次利用标签图结构通过深度游走的方式嵌入标签。
SGM:该方法将多标签文本分类视为序列生成问题,考虑到标签之间的相关性,利用序列生成模型将输入文档转换为输出标签作为多标签文本分类器。
Attention-XML:设计了一个以文本语义表示作为输入的多标签注意网络,确定每个标签的相关组件,然后用一个浅宽的概率标签树来处理标签,尤其是“尾标签”。
EXAM:将标签编码为一个可训练矩阵,其中每行是每个标签的表示,然后利用交互层构建文档和标签之间的连接来获得交互特征。最后,基于交互特性设计一个聚合层来计算对数。
LSAN:利用标签语义信息确定标签与文档之间的语义联系,构建标签特定的文档表示。同时,采用自注意机制从文档内容信息中识别特定于标签的文档表示。最后将两者融合在一起进行分类。
3.3 实验评价指标
本文使用两种度量方式来验证模型的效果,这两种度量分别是排名第k处的精度(P@k)和排名第k处精度的归一化折现累积收益(nDCG@k)。P@k定义为只考虑每个预测类别的前k个元素的正确预测次数除以每个预测类别的前k个元素。nDCG@k将每个测试实例的预测分数标准化。根据分类器预测的标签概率P∈Rl和真实地面标签y∈{0,1}l,我们将计算P@k和nDCG@k,具体计算过程如下所示:
其中rankk(P)为当前预测结果得分最高的前个标签索引。计算真实标签向量y中相关标签的数量。IDCG@k是DCG@k在理想情况下的最大值。
3.4 实验参数设置
对于这三个数据集,本文设置文档的最大长度为500,对于标签表示和文档表示,特征维度k为300。此外,我们根据数据集的特点来设置标签注意网络层的层数,具体见实验分析部分。整个网络通过Adam 进行训练,学习率为0.001。由于EUR-Lex 数据集标签总数巨大,故用200 次迭代次数训练模型,其他数据集均用20 次迭代次数训练。
3.5 实验结果及分析
如表2—表3 所示,我们分别基于P@k和nDCG@k评价指标验证本文模型较现有模型的性能优势,其中每行用粗体标记出最佳结果。不难发现,本文提出的方法在RCV1 和EURLex 数据集上大多数指标都取得了较好的效果。主要有两个原因,一是我们不仅考虑从文本到标签的表示,而且还考虑了从标签到文本的表示。二是利用学习向量量化的方法从实例中学习每个标签的表示语义表示,可以针对数据集文本的特点捕获更丰富标签语义信息,而标签语义信息可以明确地指导模型分类,提高分类效率。对于AAPD 数据集大部分指标低于LSAN 的原因在于该数据集的标签总量以及文本平均标签量较其他两个数据集少,在标签语义向文本语义映射时不能完全表达出文本语义,进而影响后续表达效果。因此结合表1-3一起分析可以看出,标签总量和文本平均标签量越多,模型对分类性能提升越大。Attention-XML 在RCV1 和AAPD 数据集上的表现优于XML-CNN 和DXML 的情况说明注意机制的重要作用。但该方法的主要缺点是只关注文本的语义表示,没有直观地建立标签和文本的语义连接,这就是我们的模型和LSAN 优于Attention-XML 的原因。本文模型与LSAN 的主要区别在于标签呈现方式和标签与文本的语义关联方式,因此本文模型能够取得比其他深度学习模型更好的性能。值得一提的是,本文模型都是基于注意力机制改进,因此模型时间复杂度较低且效率较高,在设置的迭代次数内是收敛的。

表2 在实验数据集(AAPD、RCV1、EUR-Lex)上关于指标P@k (k=1,3,5)的对比结果Table 2 Comparison results on experimental datasets(AAPD, RCV1, EUR-Lex) in the term of P@k (k=1,3,5)

表3 在实验数据集(AAPD、RCV1、EUR-Lex)上关于指标nDCG@k (k=3,5)的对比结果Table 3 Comparison results on experimental datasets(AAPD, RCV1, EUR-Lex) in the term of nDCG@k (k=3,5)
此外,为了进一步观察通过学习向量化得到的标签语义表示效果,本文为RCVI 数据集设置了两种获取标签语义表示的方式:标签词嵌入和学习向量化,并将其对比结果列在表4中。结果表明,基于学习向量化方法得到的实验结果更好,说明该方法可以从标记样本中学习到更丰富、更准确的标签语义。

表4 在数据集RCV1上标签语义表示方法对比结果Table 4 Comparison results on RCV1 for the methods of label semantic presentation
为了进一步验证双向标签注意网络的效果,本文在三个数据集上进行了双向标签注意网络的消融实验。本文主要通过与单向标签注意对比分析来验证双向标签注意网络的有效性,所谓单向标签注意即只考虑将从文本到标签方向的映射继而获取特定于标签的文本表示,对比结果列于表5 和表6。从表5 和表6 中可以很容易地观察到,本文提出的双向注意方法在除了AAPD 的其他两个数据集上的大多数指标上都取得了较好的效果,这充分证明了本文方法可以更充分地捕获文本中标签的相关信息,提高分类器的性能。而针对AAPD 数据集,单向注意力的性能优于双向注意的原因是标签数量以及文本平均标签量较少,在标签的语义映射为文本语义时会有一定的语义缺失,进而影响了模型效果。
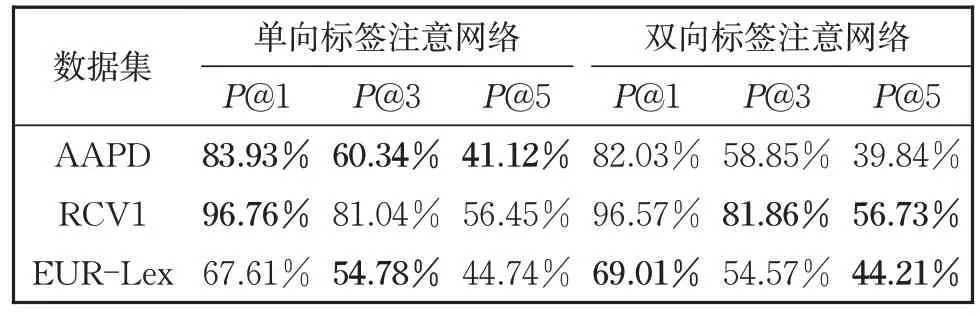
表5 在实验数据集AAPD、RCV1、EUR-Lex上关于指标P@k (k=1,3,5)的消融实验结果Table 5 Ablation test results on AAPD, RCV1 and EUR-Lex in the term of P@k (k=1,3,5)
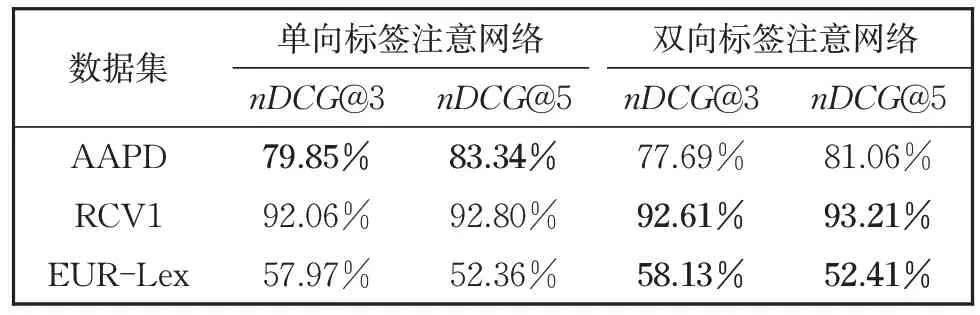
表6 在实验数据集AAPD、RCV1、EUR-Lex上关于指标nDCG@k(k=3,5)的消融实验结果Table 6 Ablation test results on AAPD, RCV1 and EUR-lex in the term of nDCG@k(k=3,5)
最后,为了进一步观察不同的双向标签注意层对深度模块化标签注意网络的影响,设置深度不同的双向标签注意网络层,表7 表明在RCV1 和ERU-Lex 数据集上,双向标签注意网络的性能与其级联的层数呈反比,而在AAPD数据集上,双向标签注意层为2 的性能最好。由于数据集的不同,双向标签注意层的数量是不同的,因此可以根据不同的数据集级联不同的双向标签注意层以获得最优的性能。
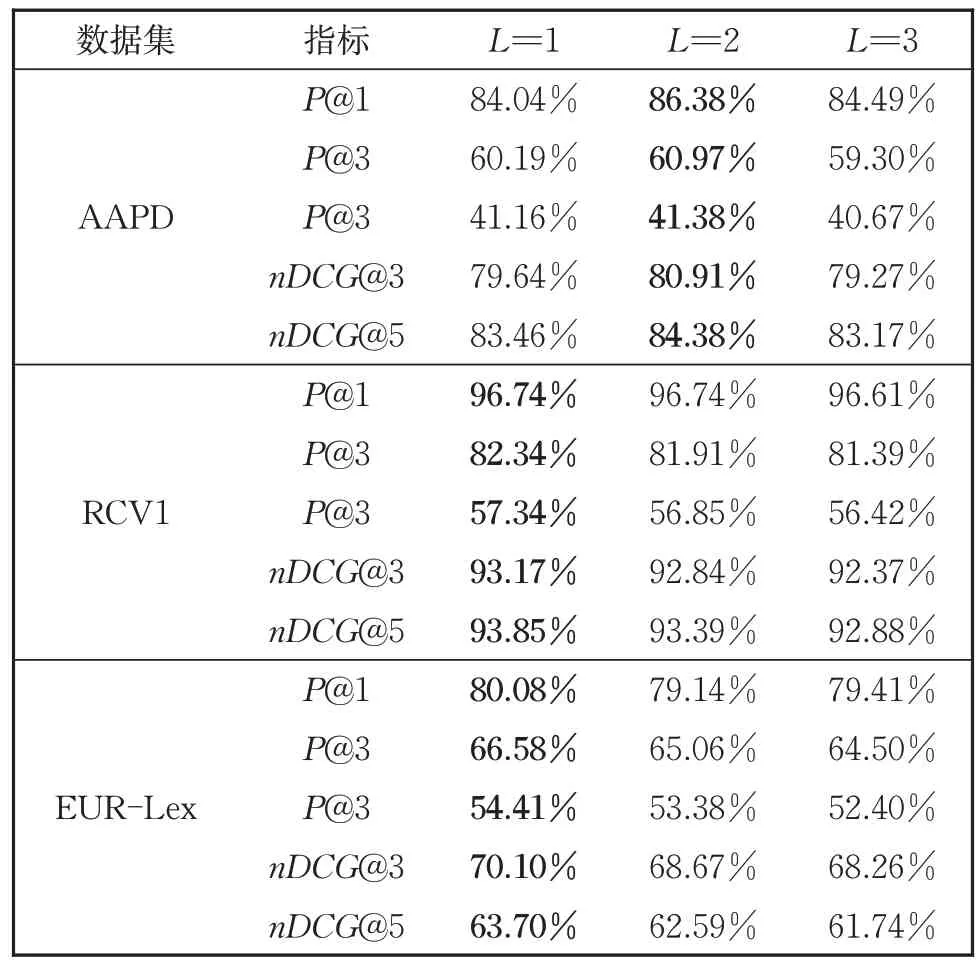
表7 在实验数据集AAPD、RCV1、EUR-Lex上标签网络层数对实验结果的影响Table 7 Influence of the layer number of the label attention network on AAPD, RCV1, EUR-Lex datasets
4 结论
本文提出了一种新颖的深度模块化双标签注意网络,该网络由双向标签注意层获得特定于标签的文本表示,利用学习向量化从样本实例中学习标签语义表示。大量实验表明模型在大多数指标上都显著且持续地优于其他基线模型。未来,在理论方面,我们将继续优化现有的方法,进一步提高各个指标的性能,例如,设计一种高效的集成方法,充分利用现有模型的优势。在实际应用中,落实已有方法,创造实用价值。
