银行客户交易场景智能分类
2023-06-01黄丽胡丹妮李普
黄丽 胡丹妮 李普


摘 要:如何聚合多维度海量数据,充分挖掘数据的内在价值,是商业银行数字化转型的重要目标之一。文章以银行个人客户支付交易数据为例,探索Textgrocery与FastText两类自然语言处理算法对交易所属场景的分类效果。实验表明,Textgrocery效果在分场景和整體方面均优于FastText,故文章最终选择Textgrocery算法对交易数据所属场景开展自动化、智能化、高效化分类。模型场景分类结果可以帮助银行为个人客户建立消费行为维度的客户标签,从而使数据资源变得可使用、有价值。
关键词:自然语言处理;海量数据智能化分类;非结构化数据处理;Textgrocery;FastText
中图分类号:TP181 文献标识码:A DOI:10.19881/j.cnki.1006-3676.2023.04.10
一、引言
金融行业在运营过程中生成海量金融数据,这些数据中蕴含了交易场景等重要的客户消费行为信息,但大部分涉及交易场景的高价值信息以文字形式存在于订单详情等字段中,属于非结构化数据或半结构化数据,无法通过简单的正则方法加工处理,信息挖掘难度大。而采用人工打标方式逐一对上亿量级的交易数据进行场景分类,则存在分类标准不一、成本高、效率低等问题。如何利用人工智能赋能银行业海量数据挖掘,提高分析效率,增加分类准确性,降低处理成本,是银行数字化转型中亟待解决的问题。
基于此,笔者将以脱敏后支付交易数据为对象,探索人工智能等新方法赋能海量数据挖掘和分析的方案,帮助银行更好地洞察客户行为,完善个人客户画像。[1]笔者针对海量支付交易数据场景分类问题,提出一种基于人工智能的支付交易场景分类模型,引入自然语言处理算法,对支付交易数据中订单详情等字段进行文本分析,并实现交易场景的自动化、智能化分类,利用人工智能算法为海量数据处理赋能。[2]相比于传统的交易流向分析方法,研究中模型的创新点包括如下3个方面:其一,针对交易数据特点,探索非结构化及半结构化数据处理及应用方式,扩充数据挖掘覆盖数据类型,丰富分析数据来源。其二,结合人工智能技术与银行业现实需求,通过分析用户交易数据,实现海量交易智能化自动分类。其三,探索自然语言处理方法与常用工具,对比基于传统机器学习的文本分类代表算法Textgrocery和基于深度学习的文本分类代表算法FastText,从而更好地挖掘交易数据中文本信息存储的高价值信息,丰富客户画像维度。
二、自然语言处理方法
人工智能是使用计算机来模拟人的各种思维或行为,再利用计算机的储存、计算等优势对人的智能进行扩展延伸的过程。1自然语言处理则是人工智能的一个重要分支,融合了计算机科学、语言学、逻辑学等领域知识。自然语言处理使用计算机来模拟人类对自然语言的理解与生成方式,目的是使人类可以用自然语言形式与计算机进行有效通信。[3]
常见的自然语言处理任务包括文本分类、情感分析、信息检索、词性标注、机器翻译等。其中文本分类是指计算机通过算法对输入的文本按照一定的分类标准进行自动化归类的过程。笔者将使用交易详情等字段分析交易场景,该字段内容长短不一,用语不规范,且文本字符数量大多小于60个字符,待解决的问题可归类于短文本分类问题。相较于长文本,短文本词汇个数少、描述信息弱,具有稀疏性和不规范性等特点,因此如何准确提取并表示短文本的特征,及如何选择文本分类算法是实现短文本分类的关键。短文本分类主要包括两类方法:传统文本分类(即基于传统机器学习的文本分类)和基于深度学习的文本分类。
(一)基于传统机器学习的文本分类
基于传统机器学习的文本分类通常需人工对特征进行提取,再应用各类传统机器学习算法对文本进行分类,其过程主要包括文本预处理、文本表示、特征提取、模型构建等步骤(见图1)。[4-5]
文本预处理的目的是把文本转化为适合机器处理的形式,并保留对分类有意义的特征,主要包括分词、降噪、去除停用词、划分训练集与验证集等流程。文本表示的目的主要是把预处理后的文本数据转换为机器能识别的结构化数据(即词向量),通常可使用词袋(BOW)、向量空间模型等方法。特征提取的目的是借助特征选择方法实现关键特征提取,降低向量空间的维度,提高分类效率,因此特征提取的质量对文本分类效果有较大影响,向量空间模型的特征提取对应特征选择和特征权重两部分,通常可使用TF-IDF方法。模型构建主要是基于线性回归、逻辑回归、支持向量机、朴素贝叶斯、决策树等分类模型进行训练。[6-7]
笔者计划采用Textgrocery作为传统机器学习文本分类算法的代表。Textgrocery是一个基于LibLinear中SVM(支持向量机)算法和结巴分词的短文本分类工具,其特点是高效易用,同时支持中文和英文语料,在小样本集上表现良好。原生的SVM只支持二分类,无法解决多分类问题。而Textgrocery的底层虽然也是SVM,但经过包装后已支持多分类,且训练及预测速度较快。
(二)基于深度学习的文本分类
基于深度学习的文本分类是通过深度学习模型对数据进行训练,无需人工提取特征,数据量和迭代次数是影响文本分类效果的重要因素。基于深度学习的文本分类可根据算法类型分为两类:第一类是使用词向量对文本进行表示后,运用端到端的神经网络算法对文本进行分类,依靠算法而非人工手段进行特征提取。第二类则无需手动进行词向量表示,使用预训练语言模型,通过大数据预训练加小数据微调,减少对于人工调参的依赖。第二类的出现是由于各类任务对于上下文语义理解的需求不断加深,同时希望解决同义词所带来的问题,从而促使技术不断发展。
在研究中,由于交易详情等特征为短文本,具有稀疏性和不规范性,其内容对句法和语义理解的需求较低,因此只需使用浅层网络即可满足本文需求。因此笔者选择了FastText模型作为基于深度学习的文本分类算法代表。FastText是Facebook于2016年开源的一个轻量级词向量表示与文本分类工具,典型应用场景是“带监督的文本分类问题”。与基于神经网络的分类算法相比,FastText的优点一是在保持高精度的情况下加快了训练及测试速度,二是FastText不需要预训练词向量,因为在运算过程中FastText会自己训练词向量。FastText结合了自然语言处理和机器学习中最成功的理念,在传统算法Word2vec的基础上进行了两类重要优化,分别是子词特征(N-gram)和层次(SoftMax)。N-gram子词特征通过隐藏表征在类别间共享信息,层次SoftMax则利用类别不均衡分布的优势来加速运算过程。[8-9]
FastText模型输入文本,即词的序列,输出这个词序列属于不同类别的概率。序列中的词和词组组成特征向量,特征向量通过线性变换映射到中间层,中间层再映射到标签。FastText在预测标签时使用了非线性激活函数,但在中间层不使用非线性激活函数。
N-gram是基于语言模型的算法,基本思想是将文本内容按照字节顺序进行大小为N的窗口滑动操作,最终形成窗口为N的字节片段序列。N-gram包括字粒度的N-gram和词粒度的N-gram,在英文中也可以以字符粒度工作。N-gram除了获取上下文信息,还可以让模型学习到局部单词顺序的部分信息,将语言的局部顺序保持住。例如“羊吃草”,如果不考虑顺序,可能会出现“草吃羊”的语义不正确问题。因此在使用N-gram时,会将N个字向量取平均后得到大小为N的词的向量,通过这种方式关联相邻的几个词,让模型在训练的时候保持词序信息。然后在隐藏层将得到的所有N-gram的词向量求平均,得到最终的一个向量。
SoftMax函数常在神经网络输出层充当激活函数,目的就是将神经元输出构造成概率分布,主要就是起到将神经元输出值归一化到[0,1]的作用。在标准的SoftMax中,计算一个类别的SoftMax概率时,需要对所有类别概率做归一化处理。这种做法在类别数量很大情况下非常耗时,因此提出了层次SoftMax。其思想是利用了类别不均衡,即一些类别出现次数比其他类别更多的事实,通过使用Huffman算法建立用于表征类别的树形结构来代替标准SoftMax,令频繁出现类别的树形结构的深度比不频繁出现类别的树形结构的深度更小,进一步使得计算效率更高,通过层次SoftMax可以将复杂度从N降低到log(N)。
三、模型实验流程及结果
笔者主要构建基于传统机器学习的文本分类算法(Textgrocery)和基于深度学习的文本分类算法(FastText)模型,并在同一数据集上进行测试和效果对比。
(一)数据来源
2020年7月1日—2020年12月31日样本客户脱敏后的支付交易数据。
(二)数据预处理
由于模型文本信息输入来自多个字段,需将各字段合并为单一字段文本信息,并进行语料清洗,去除符号、数字等无意义字符,仅保留中英文内容。处理后对交易记录进行再次筛选,仅保留文本信息不为空交易记录作为有效数据。
(三)分类打标
分类打标主要是用于模型训练,确定分类规则。研究希望通过对交易数据进行細分,了解各交易场景分布情况。分类打标的另一个作用是将验证样本自动分类后的类别与预先打标好的类别进行对比,借助评价指标评估模型分类效果的好坏。研究根据业务经验把支付交易场景分为45类,包括商超便利、理财投资等。样本数据方面,随机选取4.2万余条数据用于模型训练及验证,并逐条对交易数据场景分类进行人工标注。
(四)模型训练步骤
1.切分训练集和验证集
模型的X变量为交易详情中的文本信息,Y变量为人工标注的45类交易场景。建模数据样本按照训练集80%,验证集20%的比例随机拆分整体数据,并进行人工核查确保训练集和验证集均涵盖45类交易场景数据。
2.基于Textgrocery的短文本分类流程
(1)入模数据标准化
训练集数据:将每一条训练集数据输入转化为Textgrocery的标准输入格式,('分类标签','输入文本')。
示例:[('商超便利','便利店')]
验证集数据:与训练集数据格式保持一致。
(2)模型训练
将训练集数据输入Textgrocery模型中,训练并保存模型结果。再将验证集数据送入训练好的模型中,分析模型评价指标以确定模型表现。
3.基于FastText的短文本分类流程
(1)结巴分词切割文本
使用结巴分词的精确模式对每一条数据中的文本信息进行切分,词与词之间以空格间隔。
(2)入模数据标准化
训练集数据:将每一条训练集数据输入转化为FastText的标准输入格式,'__label__分类标签\t输入文本'。
示例:['__label__基金\t诺安','__label__基金\t基金']
验证集数据:将以空格间隔的切割后文本信息作为输入。
(3)模型训练
将训练集数据输入Fasttext模型中,训练并保存模型结果。再将验证集数据送入训练好的模型中,分析模型评价指标以确定模型表现。
(4)参数调优
对模型参数进行独立或联合调优,将在验证集上表现最好的一组参数作为模型的最终参数,训练所得模型作为最终应用模型。
最终确定模型参数为:WordNgrams=1,Epoch=40,Lr=0.3,Dim=100,Loss=softmax(WordNgrams:单词n-gram的最大长度,wordNgrams=1表示只有一个单词;Epoch:迭代次数;Lr:学习率;Dim:向量维度;Loss:损失函数类型)。
(四)模型评价
对于文本分类效果的评价,通常使用准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1值来评价,具体计算公式如下:
Accuracy= (1)
其中,TP为正样本预测正确的个数,FN为正样本预测错误的个数,TN为负样本预测正确的个数,FP为负样本预测错误的个数。准确率(Accuracy)为预测正确的样本与总样本的比值。通常来说,准确率越高,模型效果越好。
Precision= (2)
其中,精确率(Precision)为预测正确的正样本数与预测为正样本数的比值。
Recall= (3)
其中,召回率(Recall)为所有的正样本中,模型预测正确的比例,衡量的是所有正例能被发现多少。
F1==(4)
其中,F1值是精确率和召回率的调和平均值,F1值认为精确率和召回率一样重要。
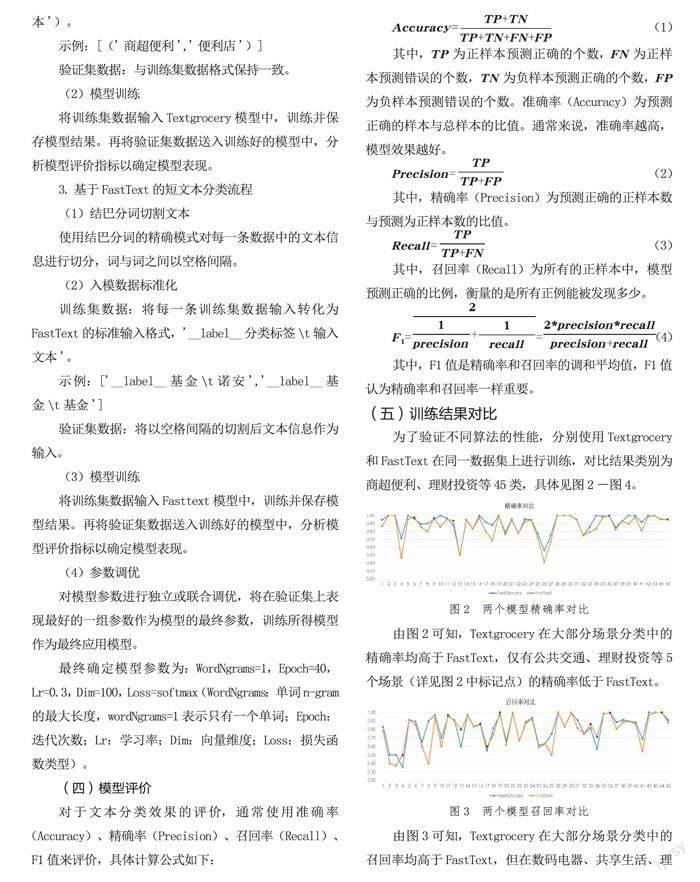
(五)训练结果对比
为了验证不同算法的性能,分别使用Textgrocery和FastText在同一数据集上进行训练,对比结果类别为商超便利、理财投资等45类,具体见图2-图4。
由图2可知,Textgrocery在大部分场景分类中的精确率均高于FastText,仅有公共交通、理财投资等5个场景(详见图2中标记点)的精确率低于FastText。
由图3可知,Textgrocery在大部分场景分类中的召回率均高于FastText,但在数码电器、共享生活、理财投资等10个场景(详见图3中标记点)的召回率低于FastText。
由图4可知,Textgrocery在大部分场景分类中的F1值均高于FastText,仅有数码电器、共享生活、理财投资等7个场景(详见图4中标记点)的F1值低于FastText。
由表1可知,整體情况方面,Textgrocery算法在准确率、精确率、召回率、F1值方面效果均优于FastText算法0.011左右。综上所述,不论是分交易场景还是整体方面,Textgrocery效果均优于FastText,故笔者选择Textgrocery算法对全部交易数据进行短文本分类,得到对应的交易类别。
四、重点交易场景关键词分析
根据Textgrocery算法开展场景自动化、智能化分类的结果,笔者选取理财投资场景进一步开展订单详情关键词分析。筛选支付交易数据中被分入理财投资场景的对应文本信息数据,使用结巴分词工具将这些文本数据进行词语切分。按照场景类别分别对每个场景下所有分词结果进行词频统计,选取该场景下出现次数最多的前300个关键词,并删除其中空格、单个字母、乱码字符等无意义词语。同时,使用永洪BI工具将关键词表按照词频绘制词云图,词云中以较大形式呈现的词语表示出现频率较高,反之则出现频率相对较低(见图5)。
在理财投资场景中(见图5),出现频率较高的为基金及支付渠道相关名词:基金、管理、支付宝。次之是一些常见的基金公司及产品名称,如天弘、华安、景顺、广发基金等。一些基金的属性名词也会被分出来,如医疗、白酒、定期、成长等。
此外,借助自然语言处理技术对交易数据开展自动化、智能化分类,还可以帮助银行为个人客户建立消费行为方面的客户标签,从而使得数据资源变得易理解、可使用、有价值。例如,基金公司购买基金、在全家便利店买零食等交易,则可为其打上理财投资、商超便利的标签,并分析不同标签下消费情况。
五、结语
笔者通过运用人工智能技术赋能数据分析的一次探索和尝试,借助自然语言处理技术实现了对海量交易数据的场景自动化、智能化分类,解决了支付交易数据中文字信息无法直接用于数据建模的问题,帮助银行将描绘客户的维度从资产、收入、征信、还款行为等静态、低频数据扩展至个人客户衣、食、住、行、娱等动态、高频消费行为数据,可以为银行个人客户标签提供有力补充,形成更加完善的客户画像。基于场景分类结果,运用RFMP方法,可从消费行为维度完善客户画像,后续结合机器学习、深度学习等算法开展数据建模分析,可为银行精准营销、风险管理等业务领域提供有力支持。精准营销方面,可运用大数据分析客户多维度信息,描绘千人千面的客户画像,将分析颗粒度从客户群体精细化到每个客户,更好地洞察客户需求,满足客户潜在金融和非金融服务需求,并提供个性化的产品推荐,帮助银行挖掘优质客户,实现精准营销。风险管理方面,可整合银行内部客户信息、资产信息,及司法、税务、社保等外部机构数据,构建个人客户信用评价体系,用于贷前、贷中、贷后的风控管理,不断提升信用评价工作的效率和准确性。
在大力发展数字经济的背景下,商业银行也需加快数字赋能的脚步,积极推进数字化转型。首先,银行可不断提升数据治理和应用能力,充分挖掘自身经营中积累的海量数据,真正将原始数据资源转化为数据资产,充分发挥数据资产的价值潜力。其次,银行应加强与政府部门、公共资源机构、运营商等外部机构的跨界合作,通过与外部机构数据的“合纵连横”,打破数据孤岛,扩展数据维度,丰富数据应用场景。最后,银行还需及时跟进隐私计算、区块链、人工智能等前沿技术发展,探索和研究新技术与金融服务的有机融合,建设企业级隐私计算平台,形成数据安全联合共享能力,发挥数据要素价值潜力。[10]
注释:
1. 该定义引自百度词条“人工智能(计算机科学的一个分支)”,该词条由“科普中国”科学百科词条编写与应用工作项目组审核。
参考文献:
[1] 杨唯实.人工智能发展前景及金融行业应用[J].金融电子化,2017(06):52-54.
[2] 马千,赵洪丹,陈丽爽.金融科技的创新发展及趋势研判[J].科技智囊,2022(07):23-29.
[3] 李睿晶,房超,陈凯.新时代我国人工智能发展回顾与发展[J].科技智囊,2023(01):14-21.
[4] 冯园园.短文本分类技术及其场景应用研究—基于某某宝交易数据[D].杭州:浙江工商大学,2017.
[5] 李锐.面向新闻分类的文本表示方法研究[D].南京:南京信息工程大学,2020.
[6] 张彦超,王杰,陈生,王彦博.NLP在银行网络金融业务中的应用[J].银行家,2020(11)22-24.
[7] 吕俊锋,陈宏晓,张诚,秦雷.NLP技术在农行信用卡风险管理领域的应用[J].中国金融电脑,2019(11)29-34.
[8] 王光慈,汪洋.基于FastText的短文本分类[J].电子设计工程,2020(03):98-101.
[9] 林国祥,詹先银,薛醒思,等.基于fastText的股票咨询案例中文短文本分类技术[J].宝鸡文理学院学报(自然科学版),2020(03):48-52.
[10] 葛红玲,方盈赢,李韫珅.北京数字经济发展特点及提升方向[J].科技智囊,2023(02):11-19.
Intelligent Classification of Bank Customer Transaction Scene
HUANG Li HU Danni LI Pu
(Bank of China Limited,Head Office,Beijing,100818)
Abstract:How to aggregate multi-dimensional massive data and fully tap the intrinsic value of data is one of the important objectives in commercial bank digital transformation. Taking the payment transaction data of individual customers as an example,the article explores the classification effect of two kinds of natural language processing algorithms,Textgrocery and FastText,on the classification of transaction data scenes. The experimental results show that the effect of Textgrocery is superior to FastText in both scene segmentation and overall performance,so the article finally applies Textgrocery algorithm on automatically,intelligently and efficiently classification of the scenes of transaction data. The results of scene classification model can help banks to establish labels for individual customers in the dimension of consumption behavior,thus making data resources usable and valuable.
Key words:Natural language processing;Intelligent classification of massive data;Unstructured data processing;Textgrocery;FastText
作者簡介:黄丽,女,1987年生,硕士,经理,研究方向:数据分析、机器学习等。胡丹妮,女,1995年生,硕士,助理经理,研究方向:数据分析、机器学习等。李普,男,1987年生,本科,经理,研究方向:数据分析、机器学习等