基于特征加权的电影票房预测研究
2023-05-30吴正清曹晖崔泽宇
吴正清 曹晖 崔泽宇
关键词:票房预测;随机森林;特征权重;BP神经网络
电影票房在电影产业中占有举足轻重的地位,因此,在电影发行当天对电影票房做出准确的预估,可以帮助制片人控制风险,帮助影院制定排片计划,并引导影院和制片人制定市场战略。在前期对电影票房的影响因子及票房预估的探讨中,研究者着重于电影上映之前所确立的静态影响因子,如主演、导演、编剧、题材、制式、获奖及提名、上映档期、发行公司、电影地区等。目前,对于上述的一些静态影响因子,大部分学者都建立了比较完整的评价体系和比较科学的定量模型,而这些静态因子在票房预报方面也得到了广泛的应用。
本文使用从网络上利用爬虫技术搜集到的678部电影及其相关信息数据作为数据集,使用合理方法进行量化以及归一化处理后,通过计算随机森林变量重要性分数,衡量每个影响票房因素的重要性,并基于随机森林变量重要性得分对不同的变量赋予权重。其中300部电影用于计算随机森林特征重要性分数,其余电影使用10折交叉验证法,利用BP神经网络模型进行票房预测,分别对比赋予权重与不赋予权重的预测效果来研究随机森林特征赋予的有效性。
1相关工作
随机森林(Random Forest,RF)[1]是一种广泛使用的集合式机器学习方法,它包含多颗互相独立的决策树。决策树中的结点主要包括3类:根结点,含有所有的样本;内部结点,代表特性的判定;叶节点,表示决策的结果。
随机森林生成的步骤是:(1)将所有的样本进行有放回的Ⅳ次随机采样,得到Ⅳ个子样本,并为各子样本生成决策树;(2)从各采样到的子样本所含有的M项属性中,随机抽取m项,并在满足m<
BP神经网络是一种多层的、以误差反向传递为基础的神经网络。BPNN分为2个部分,即前向信号传递和反向误差传递。这种算法从输入到输出,进行误差的运算,然后由误差来校正网络中的权值和阈值。首先,通过隐藏层,将输入的信号非线性地传递到输出节点,由此在实际的和预期的结果之间进行误差的运算,再由隐藏层将其逆向传输到输入层,根据每个层次所得到的误差信息来调节每个神经元权值。经过对各结点的权重和阈值的调节,使得各结点的误差沿梯度方向逐渐减小,并在反复的迭代中不断地进行学习,最后得到输出误差最小的网络参数[2]。
2电影票房影响因素数据处理
2.1数据获取与数据预处理
电影数据的主要来源是中国票房网和豆瓣网,利用网络爬虫技术收集电影的有关资料,并从各种其他渠道收集所需电影相关的各项数据。从网站上获得的最终票房都是按照“万元”单位转换为浮点格式的:整合后的电影制作区域包括中国大陆,欧美,日韩,和其他地区等:一些影片的主题与内蕴有关,如武侠题材的动作电影,这些也需要整合起来。另外,对于票房较差的影片,其研究价值较低,并且特征缺失问题严重,所以仅选取票房超过3000万的影片作为预测数据。
2.2影响因素量化
2.2.1电影制式
本文对不同制式电影的历史票房总和取平均来计算相应的影响力,以达到量化电影制式的目的。
2.2.2电影题材
对于电影题材的量化,本文通过各种题材电影的平均票房乘以各种题材电影所占比例来实现。同时,采用该指数的均值来表示具有多种题材的电影。
2.2.3影人因素
本文以导演、编剧和导演作品之前的票房平均来衡量影片的票房收入,并以导演、编剧和主演表中排名靠前的5名演员来进行预估。1部影片往往由多个导演、编剧和演员组成,因此,本论文选取了多个演员的平均影响力指标作为各个维度的定量指标。
2.2.4是否IP,是否续集
由于是否IP、是否续集等因素使电影票房起到正向的影响作用,因此,本文在对其量化时就简单地将其使用布尔变量表示。
2.2.5制片地区
在对电影地区进行定量时,以平均票房和所占比例的方式来进行计算。1种影片可以是多个地区的合作作品,因此,本文选取了各个制片地区的平均影响指标。
2.2.6发行公司
在本文中,当公司的发行电影超过5部时,以公司的平均票房来衡量公司的影响力,如果是5部以下的公司,则会合并成其他公司,以已发行电影的平均票房来衡量公司的影响力。
2.2.7上映档期
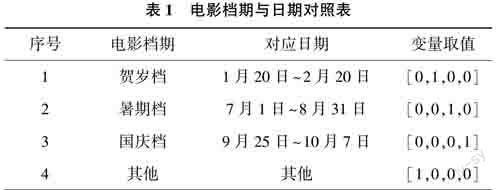
根据我国节假日实际情况划分出4个档期,并将档期转换成one-hot向量,如表1所列。
2.3数据归一化
本文使用最大一最小标准化(Min-MaxNormalization,也称离差标准化)方法进行数据标准化,经过数据标准化后的数据会落在[0,1]区间。
3实验结果与分析
根据计算得到的随机森林变量的重要性分数,确定各因素在票房中的重要程度,同时对随机森林中變量的重要性分数给予不同变量作为权重。然而,基于随机森林的性质,通过对各因素的权重系数进行分析,通过多次实验得出的各项因素的重要性分数有差异,而通过多次实验发现,各因素的重要性分数的变化存在一定的范围,故用多次实验求平均。因为各个特征间的重要性分数差异很大,若将其作为权值,则会导致某些特征的数值偏大,而在其他特征数值偏低时,则会降低权值。因此,本文通过对计算得到的重要性分数进行对数转换,求出各特征的重要度,从而使其在[0,1]范围内,获得最后的权值。
本文使用十折交叉验证(10-fold cross-validation)来测试模型的效果,该方法的基本思路是:将所有的数据集平均分为10个部分,依次抽取9个部分当作训练集,剩下1个部分当作测试集进行测试,然后将10轮训练与预测后的结果进行平均,将平均值作为模型最后的估计结果。该方法可以有效解决由于不正确分割数据集而导致的模型过度拟合等问题。因为在用数据集较小时,进行建模很可能会产生这种情况,所以采用交叉验证的方式来评价小规模数据集会有一定的优越性。由于所采用的资料集数量少,因此,采用十折交叉验证方法比较适合。
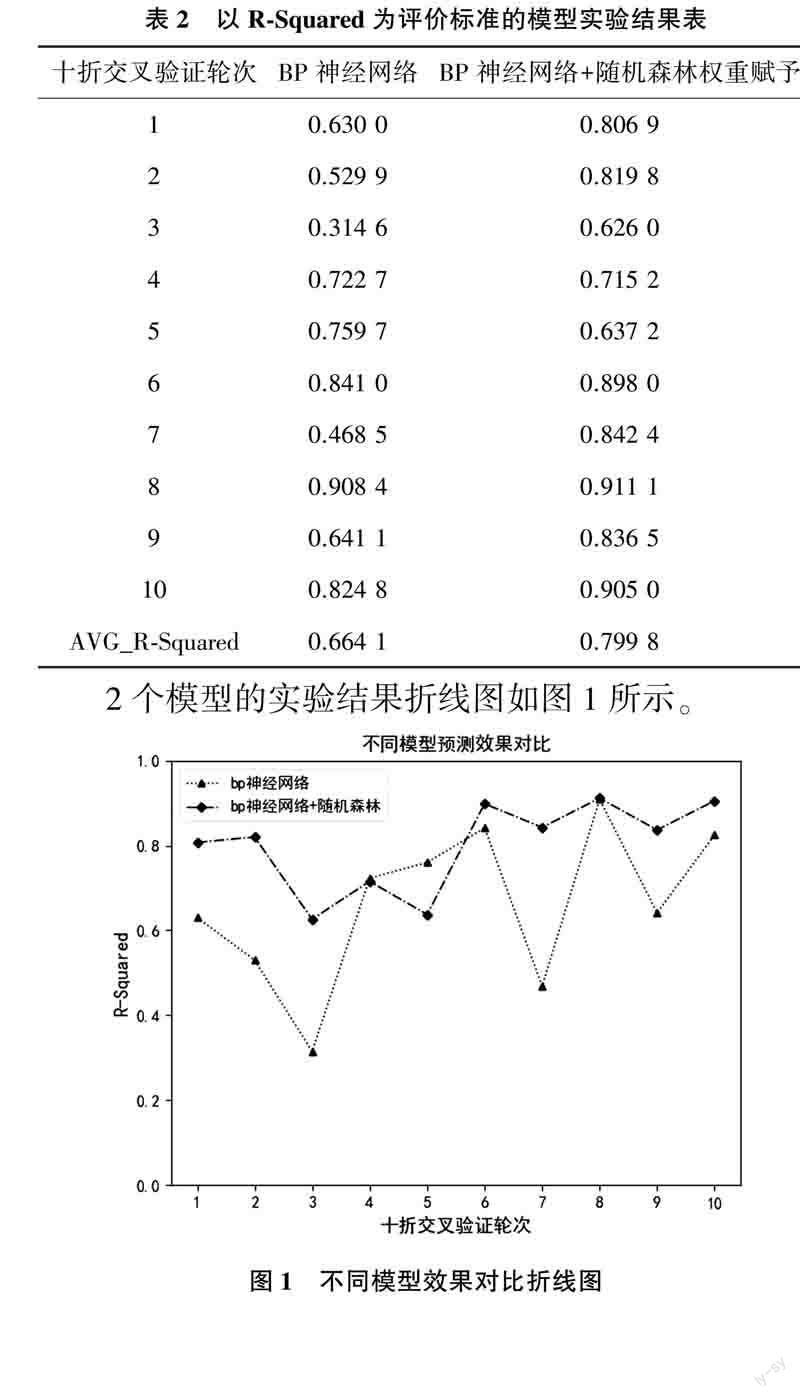
以R-Squared为评价标准,本文模型以及对比模型的实验结果如表2所列。
2个模型的实验结果折线图如图1所示。
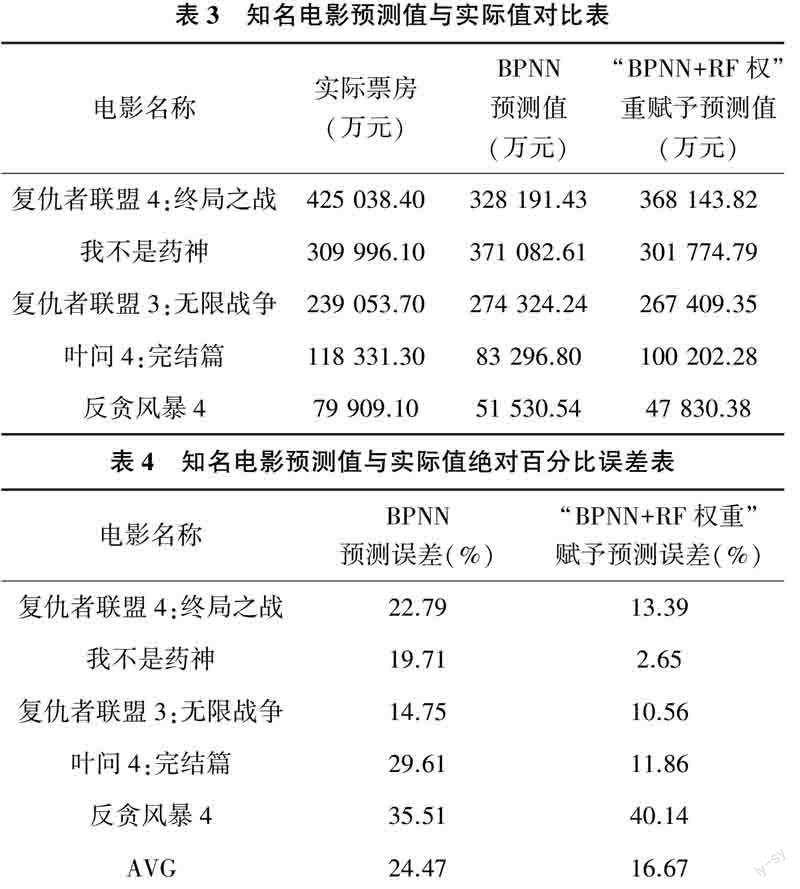
在检验所建立的模型的票房预测结果时,除比较R-Squared模型的总体预测结果,还进行了一系列的实验,以此模型,得出了5个最近几年比较出名的影片的预测结果。它们的预测结果和实际值的比较表与绝对误差的百分数如表3和表4所列。
4结束语
本文搜集了678部电影并将其作为数据,选择电影制式、电影题材、制片地区、发行公司、是否IP续集、主演、导演、编剧以及档期等作为主要影响因素,随机选取其中300部电影使用随机森林算法计算特征重要性,之后使用BP神经网络对剩余电影进行票房预测。实验结果表明,对电影影响因素赋予权重后的模型R—squared值高于未赋予权重的模型,对近年来的5部电影进行票房预测的结果也更接近于实际值。
