学业预警知识图谱的构建与应用
2023-05-29刘爽英王伟艳
闫 瑾, 刘爽英, 白 姗, 王伟艳, 张 丹
(中北大学 软件学院, 山西 太原 030051)
0 引 言
随着教育现代化的不断发展, 新时代高等教育背景下对大学生学业预警的研究关系到国家人才培养体系的建设。近年来, 高等院校对学生学习过程的管理愈发严格, 学业管理也在由“事后处理型”向“事前事中预防型”转变, 以确保我国高等教育人才的培养质量[1]。学业预警机制能够帮助学生进行自我评估, 及时端正学习态度, 避免出现挂科、无法毕业等学业问题。各大高校学业预警机制已经形成, 并且开始初步应用, 但一般仅应用于评奖学金、转专业等特殊情况, 并未将其融入到学校的日常教育教学活动管理中。因此, 如何完善学生学业预警体系, 提高预警相关主体对预警机制的重视程度和执行力已成为当前研究的热点[2]。
目前, 常用的学业预警方法有数据挖掘、云计算、区块链、机器学习等, 申民哲[3]提出了一种基于数据挖掘的学生画像与学业预警方法, 姜志鹏等[4]提出了一种基于云计算的高校学生学业预警技术, 梁建[5]提出了一种基于区块链的新工科人才培养的智慧管理方法, 这些工作通过对学习数据以及考试数据进行挖掘, 分析数据并构建模型进行预测, 能够得到较高的预测准确度。但是, 这些方法较为注重预测结果, 在一定程度上忽略了过程, 在早期干预方面存在不足且不够直观。
为了更直观地呈现学生学习的情况, 并能够在挂科、无法毕业等问题出现之前采取措施, 本文使用了知识图谱的方法。知识图谱具有强大的查询和推理能力、较强的实时更新与人机交互性能, 以及出色的可视化性能。知识图谱在学科建设中已被广泛研究和应用, 如: 张春霞等[6]对数学课程进行了研究, 通过构建数学课程本体, 提出了一种数学课程知识图谱构建方法以及知识推理方法; 黄焕等[7]通过对适应性学习系统的功能需求进行研究, 设计了以“Java程序设计基础”课程为示例的课程知识图谱; 郎亚坤等[8]以“C++”课程为例, 构建了课程知识图谱, 并使用Neo4j图数据库完成可视化。知识图谱强调实体间关系与实体属性, 因此, 知识图谱能够很好地表达出知识点的掌握关系。
借鉴以上研究, 本文进行了学业预警知识图谱的构建与应用, 首先, 通过protégé完成模式层的构建, 对知识的数据结构(包含实体、关系、属性)进行了设计; 其次, 以事实三元组为单位, 存储具体的信息; 最后, 使用D2RQ对模式层与数据层进行映射, 完成学业预警知识图谱的构建。本文所构建的知识图谱重点针对线上教学, 对学生未完成的学习内容进行重点提示, 以实现“事前事中预防”的目标。此外, 本文还结合学生线上和线下所学科目, 在其可能影响到学生正常毕业前就进行学业预警, 以解决学业预警方法中过程化与可视化不足的问题。
1 学业预警知识图谱构建的分析
知识图谱是一种以图的形式表示实体与实体之间关系的知识库[9], 实质上是不同规模的语义网络, 将知识实体或概念作为节点, 语义关系作为边, 其基本组成单位是“实体—关系—实体”和“实体—属性—值”两种三元组[10]。知识图谱技术能够为异构信息提供统一化的表示平台, 能够有效呈现实体间的关系, 因此便于使用者从“关系”层面分析问题。
知识图谱构建过程包括模式层和数据层的构建, 模式层构建在数据层之上, 是整个知识图谱的核心。模式层存储的是结构化的、具有概括性的知识, 数据层主要存储的是结构化的数据, 常存储在数据库中[11]。通过知识图谱的构建可以将本体中的知识和实例数据进行具体的结合。
学业预警知识图谱以学校课程、学生和课程知识作为具体研究对象, 由实体关系和属性的获取、专业课程知识的表示、图谱的构建和应用三部分组成。知识图谱构建框架如图1 所示。

图1 知识图谱构建框架图
首先, 实体关系和属性的获取需要从学生数据、课程数据和知识点数据入手, 抽取知识并处理为结构化数据; 其次, 根据学校专业课知识点框架对知识进行表示, 将学生、课程、知识进行有效链接, 构建知识图谱; 最后, 基于知识获取和专业知识图谱完成构建, 使用Neo4j图数据库完成可视化, 实现直观的学习表示与学业预警。
2 学业预警知识图谱的构建
2.1 模式层构建
知识图谱的模式层通常采用本体库来管理, 本体(Ontology)可以看成描述某个学科领域知识的一个通用概念模型。本体构建的目标旨在获取、描述和表示相关领域的知识, 提供对该领域知识的共同理解, 确定领域内共同认可的词汇, 提供该领域特定的概念定义和概念之间的关系, 提供该领域中发生的活动以及该领域的主要理论和基本原理, 达到人机交流的效果[12]。
知识图谱模式层的建立通常分为自顶向下和自底向上2种模式。对于较为成熟的领域, 采用自顶向下的方法进行图谱构建就足以满足需求。但是, 对于知识体系欠缺完备性的领域, 就需要通过自底向上的方式, 对这类知识进行基于数据驱动的方式构建[13-15]。本文采用自顶向下的方式构建知识图谱, 后续再通过各类实例数据自底向上补充完善。
首先设计模式层, 本文采用树状结构进行模式层中类层次的构建, 每个子类继承其祖先节点的属性, Object类是根节点, 其他所有类是其子节点。然后对类关系、类领域、类属性进行定义。类关系定义描述了类之间存在相互的关系, 包括isGet, isPass, isInclude; 类领域定义是为了便于将多个领域中的类进行分组管理, 包括User类、Course类、Knowledge类以及各自的子类; 类属性定义用于描述各个类具有的属性。本文模式层中类层次结构的设计图如图2 所示。

图2 类层次结构设计图
2.2 数据层构建
知识通常以“实体-关系-实体”或者“实体-属性-值”三元组作为基本表达方式。存储在图数据库中的所有数据将构成庞大的实体关系网络, 形成知识的“图谱”。知识图谱数据层通常存储在MySQL、Oracle及SQL Server等关系型数据库中, 通过对类、对象属性和数据属性的映射, 将数据层与预设模式层结合, 实现知识图谱的实例化[16], 最终存储到图数据库Neo4j并展示。本文实例数据使用MySQL数据库来存储, 其中包含4个数据层类表与6个数据层关系表, 如表1 和表2 所示。

表1 数据层类表

表2 数据层关系表
完成知识图谱模式层的构建后, 设计对应的映射语句, 将表1 和表2 中的结构化数据转化成三元组数据。知识图谱基于关系型数据库的本体映射方法主要有两种, 一种是将三元组数据存储在SQL中, 再将SQL数据转化为RDF数据, 并与本体OWL文件关联, 另一种是将本体存储在关系型数据库中, 通过外键连接。由于第二种方法需要大量自连接操作, 开销巨大, 而第一种方法比较灵活方便, 因此, 本文采用第一种方法, 使用D2RQ工具进行映射。
3 实验与应用
3.1 知识图谱构建实验
采用本体建模软件protégé完成本体构建, 作为知识图谱的模式层。使用MySQL数据库来存储数据, 关系型数据库可以实现数据与本体的映射。对关系型数据库中的结构化数据, 抽取数据信息, 通过D2RQ工具将结构化数据转化为三元组数据, 存储在SQL中, 并将SQL数据转化为RDF数据, 与本体OWL文件关联, 然后加入到知识图谱中, 再使用Neo4j图数据库实现可视化和查询。这种直接映射的方式能够让用户更加灵活地编辑和设置映射规则。
D2RQ映射语言是一种声明性语言, 用于描述关系数据库架构与RDFS词汇表或OWL本体之间的关系。该映射定义一个虚拟RDF图, 其中包含数据库中的信息。这类似于SQL中的视图概念, 不同之处在于虚拟数据结构是RDF图, 而不是虚拟关系表。它的机理就是通过mapping文件, 把对RDF的查询等操作翻译成SQL语句, 最终在RDB上实现对应操作。
将数据库中的每一张表看作是一个类, 因此, 表中的每一行就是该类的一个实例, 表中的每一列就是这个类所包含的属性, 表3 所示为部分关系数据库与本体库的映射关系。
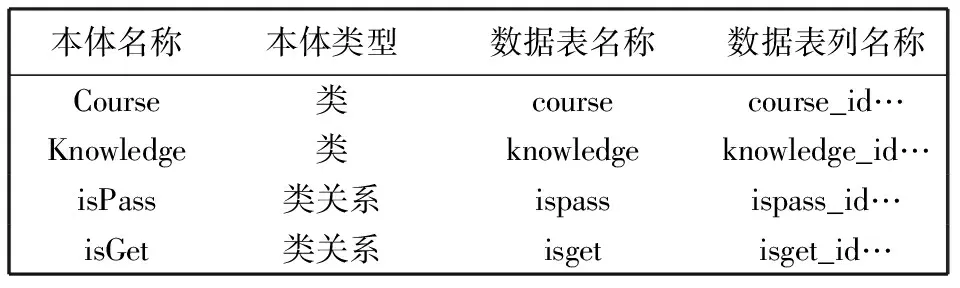
表3 部分映射关系表
通过D2RQ映射将数据库中的表与本体中的类相关联。D2RQ提供了自己的mapping language, 根据数据库自动生成预定义的mapping文件, 对文件进行修改, 把数据映射到本体上。以Course表为例, 部分映射语句如下:
map:Course a d2rq:ClassMap;
d2rq:dataStorage map:Database;
d2rq:class:Course;
d2rq:uriPattern “course/@@course.id@@”;
d2rq:classDefinitionLabel “course”;
再使用命令“.dump-rdf.bat-o kg_course.nt.kg_course_mapping.ttl”将数据转为RDF, 使用命令“CALL semantics.importRDF(“ file:///course.rdf”,“RDF/XML”,{ shortenUrls: false, typesToLabels: true})”将数据导入Neo4j图数据库进行查询和可视化展示。
3.2 知识图谱应用
构建知识图谱需要获取相关数据与属性, 由于作者所在学院在读研究生总数仅为160人, 数据量较少, 实验结果说服力较弱。因此, 使用Kaggle与百度百科网页的数据, 分为可视化测试与有效性测试。数据集具体信息、实验过程与实验结果如下所述。
3.2.1 可视化测试
使用八爪鱼采集器获取百度百科中相关课程信息进行可视化测试, 对采集到的数据进行处理, 将非结构化文本数据转化为结构化数据, 使用Cypher语言中Match子句进行查询。
Cypher是Neo4j官网提供的声明式查询语言, 使用它可以完成任意的知识图谱查询过滤操作。从Neo4j数据库查询数据的方法有多种, 最常用的是使用Match子句指定搜索模式进行操作。
在可视化测试中主要通过红色粗线条的数量来进行警示, 红色粗线条指向未通过的课程, 红色越多代表挂科数目越多, 则毕业越可能受到影响。
在知识图谱中查询学生“张三”的课程通过情况, 如图3 所示。其中已通过课程用绿色细线条呈现, 关系为“ispass”, 未通过课程用红色粗线条呈现, 关系为“nopass”, 可以直观地看出张三同学未通过“随机过程”科目。

图3 “张三”课程通过情况知识图谱
再对学生“王五”课程通过的情况进行查询, 如图4 所示, 由图可知, 王五同学课程通过情况图谱大面积标红, 有8门未通过的科目, 已经达到总科目数量的一半, 会影响到正常毕业。
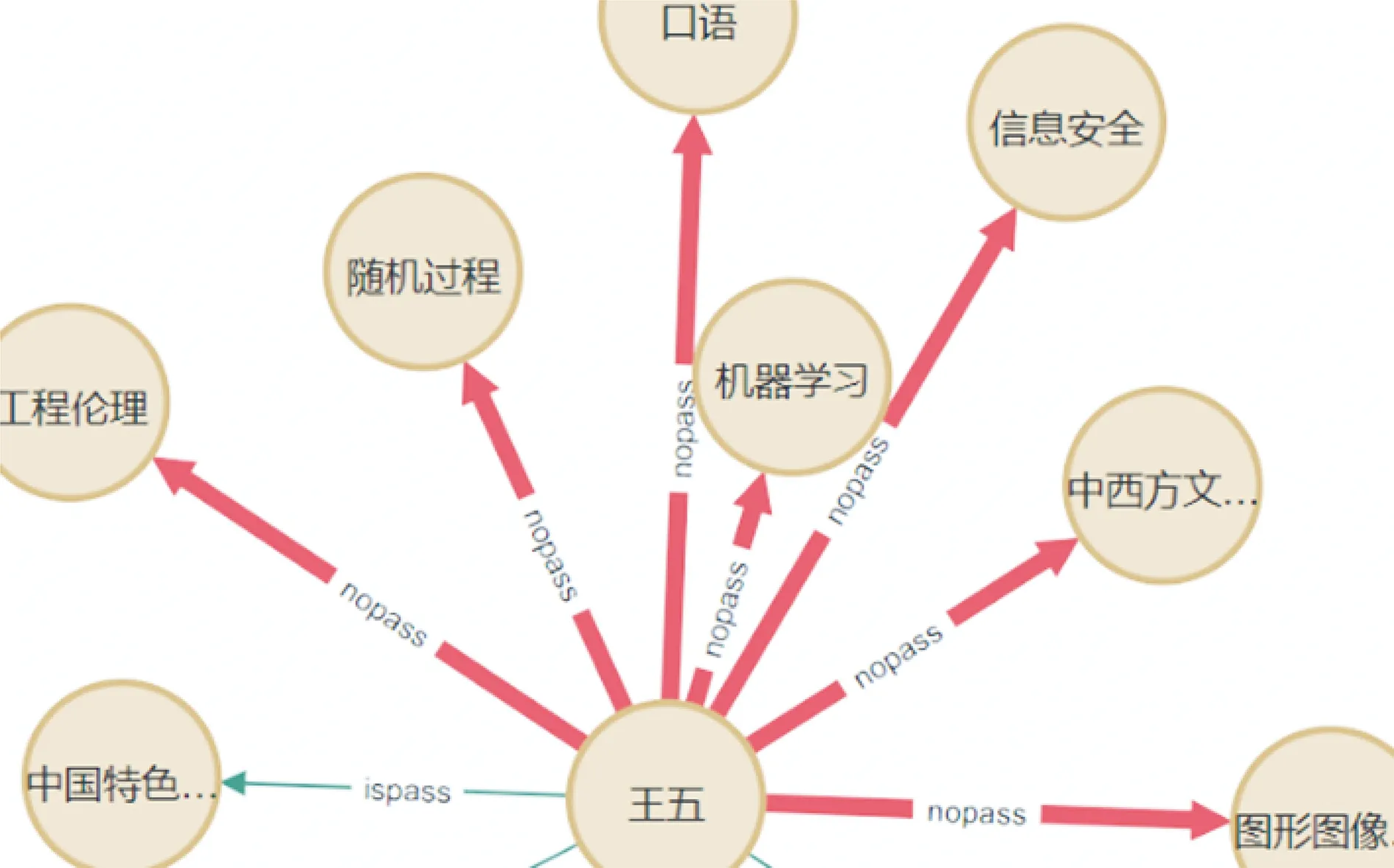
图4 “王五”课程通过情况知识图谱
在知识图谱中, 对科目“随机过程”中“随机过程的基本概念”知识点的掌握情况进行查询, 如图5 所示。图5 中, 已掌握的知识点用绿色细线条呈现, 关系为“isget”, 未掌握的知识点用红色粗线条呈现, 关系为“noget”, 可以直观地看出图中未掌握的知识点有平稳随机过程的概念与定义、平稳随机过程相关函数的性质、平稳随机过程的相关系数和相关时间。
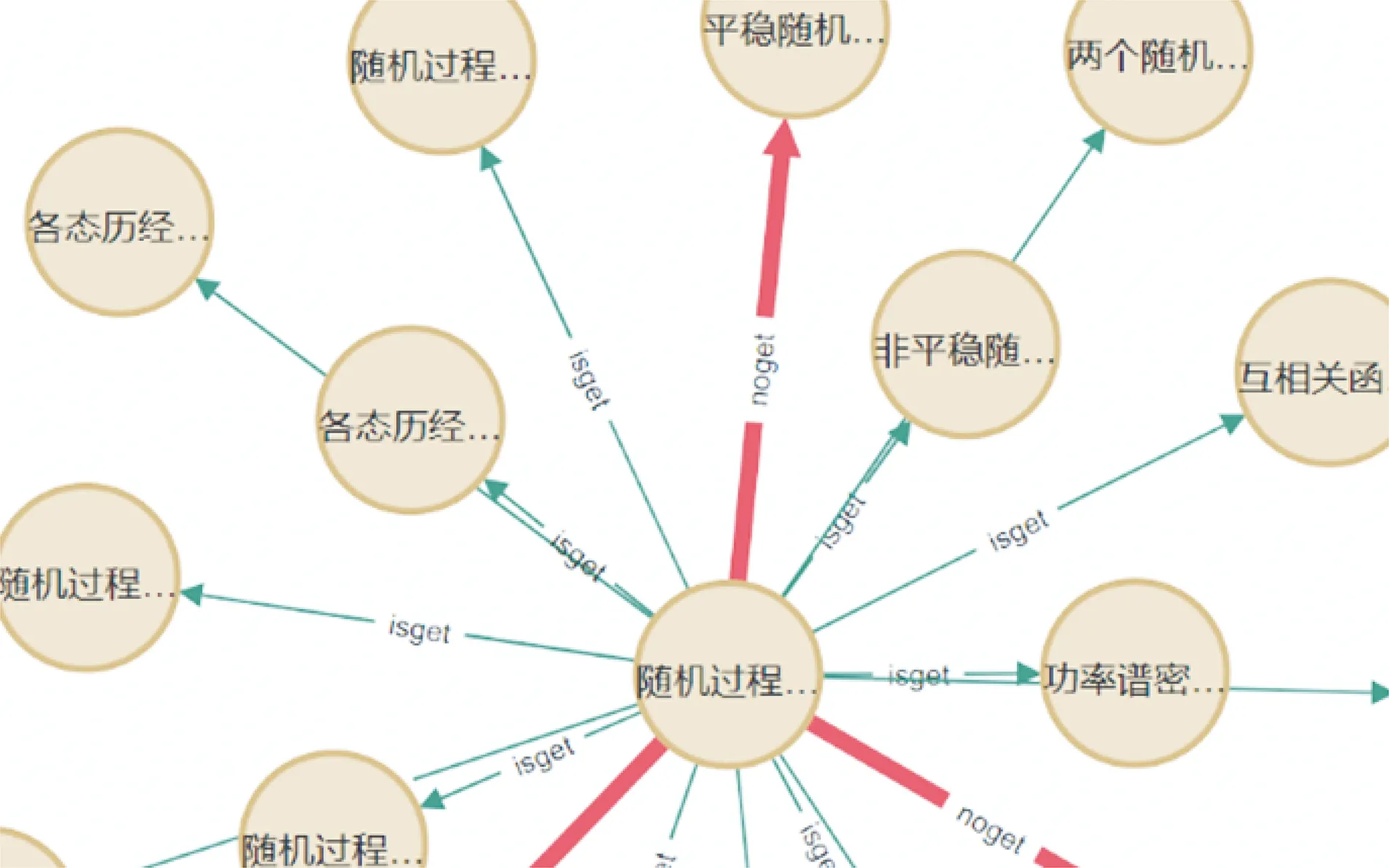
图5 知识点掌握情况知识图谱
在知识图谱中查询各类知识点之间的关系情况, 如图6 所示。其中的知识点关系主要有“include”和“parallel”。可由知识点之间的包含关系、并列关系确定知识学习顺序, 由简到难。

图6 知识点关系知识图谱
对系统的时效性进行测试, 以查询知识图谱中所有实体与关系的响应时间作为评估指标。使用“MATCH(n)RETURN n”进行多次查询测试, 系统平均在9 ms后开始传输, 并在25 ms后完成。
3.2.2 有效性测试
为验证本文知识图谱构建的有效性, 进行实验测试。由于作者所在学院在读研究生总数仅为160人, 数据量较少, 实验结果说服力较弱, 且本模块的目的为验证所构建的知识图谱中每门课程的通过节点数与未通过节点数是否与数据集中一致, 是否出现了较大错误, 因此, 使用Kaggle公开数据集1(https://www.kaggle.com/datasets/spscientist/students-performance-in-exams)和公开数据集2(https://www.kaggle.com/datasets/aljarah/xAPI-Edu-Data[17-18])进行模拟验证, 本文所构建的知识图谱是基于学生课程成绩的, 此数据集中包含大量学生课程成绩, 可替代性较强。
数据集1包含8个属性, 对数据集进行处理并融合模拟数据得到7 817条学生数据, 选取关键属性math score, reading score, writing score, 增加name属性。name表示姓名, 为保护隐私用字母代替, math score, reading score, writing score分别为数学成绩、阅读成绩、写作成绩。其中, 通过数学课程的有4 539人, 通过阅读课程的有4 712人, 通过写作课程的有4 734人, 数据集1中部分信息如表4 所示。
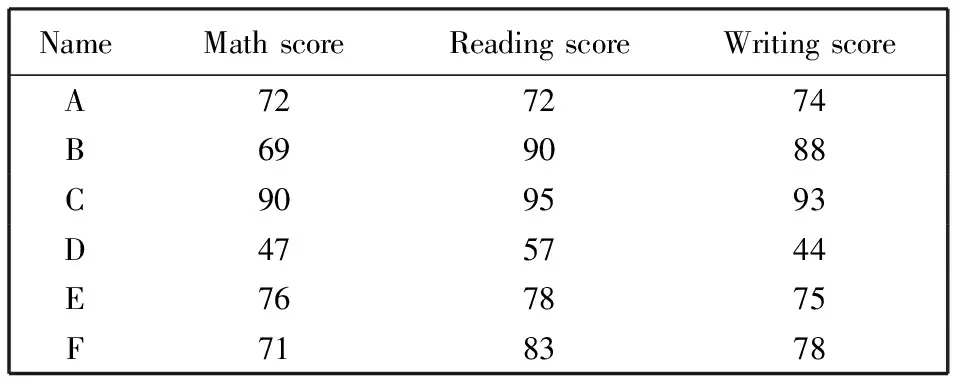
表4 数据集1部分信息
使用“MATCH p=()-[r:’ispass’]->()RETURN p”对三门课程的通过节点数进行查询, 查询结果如表5 所示, 查询结果与表4 中的信息一致。

表5 数据集1的通过节点数
数据集2包含17个属性, 对数据集进行处理, 选取关键属性question, resource, announcement, discussion, 增加name属性。name表示姓名, 为保护隐私用字母代替, question, resource, announcement, discussion分别为学生在课堂上举手的成绩、学生访问课程内容的成绩、学生查看新公告的成绩、学生参加讨论组的成绩。其中, 通过question, resource, announcement, discussion每个项目的分别有210, 265, 112, 152人, 数据集2中部分信息如表6 所示。

表6 数据集2部分信息
使用“MATCH p=()-[r:’ispass’]->()RETURN p”对四项成绩的通过节点数进行查询, 查询结果如表7 所示, 查询结果与表6 中信息一致。

表7 数据集2通过节点数
为了保证学业预警知识图谱的质量, 通过随机抽样的方法进行知识图谱三元组质量的校验, 本文数据取自Kaggle公开数据集中的结构化数据, 并对数据进行了处理, 数据源质量可靠, 因此随机选取1/10进行校验, 采样得到782条三元组。将数据分发给5位具备专业背景的人员, 对实体及属性有无错误进行校验标注, 采样标注后得到的准确率为94.23%。
由实验结果可知, 本文提出的知识图谱构建方法有效, 采样标注后得到的准确率为94.23%, 能够呈现学习程度; 同时, 时效性良好, 在查询知识图谱中实体与关系的过程中, 平均响应时间为9 ms, 并在25 ms内完成知识图谱的加载, 未出现响应时间过长的问题, 可以正常使用; 另外, 在过程性与可视性方面的表现良好, 可以起到学业预警作用。
4 结 论
本文介绍了目前学业预警机制的常用方法和基本情况, 基于相关研究进行了学业预警知识图谱的构建与应用。主要对模式层与数据层进行了设计与构建, 并对二者进行映射, 并使用Neo4j图数据库进行可视化显示, 完成了学业预警知识图谱的构建。为了验证所构建知识图谱的可行性, 对公开数据集进行数据处理, 完成有效性和可视化测试, 实验结果表明, 所构建的知识图谱可以达到现有学业预警方法的效果, 经采样标注后得到的准确率为94.23%, 且时效性良好, 平均在9 ms内完成传输, 同时在过程化与可视化方面有较大提升, 能够实现“事前事中预防”的目标, 具有实际应用价值。在未来的工作中, 将进一步研究知识图谱中的知识融合技术, 通过融合同一领域中不同的知识图谱来扩充知识范围、细化知识点, 以达到学业预警个性化的目标。
