基于多尺度双通道网络的人脸活体检测
2023-05-29况立群谢剑斌薛红新
任 拓, 况立群, 谢剑斌, 薛红新
(1.中北大学 计算机科学与技术学院, 山西 太原 030051;2.山西省视觉信息处理及智能机器人工程研究中心, 山西 太原 030051;3.机器视觉与虚拟现实山西省重点实验室,山西 太原 030051)
0 引 言
人脸活体检测是人脸识别的关键一环, 通过人脸活体检测可以有效筛选出伪造人脸, 从而保障人脸识别系统的安全。然而, 现阶段人脸活体检测算法普遍存在泛化能力不足的问题。一些学者提出使用频率域的方法来提取伪造人脸图像上的伪造痕迹, 比如使用高通滤波器提取高频信息来获取图像纹理和边缘信息。使用频率域处理虽然可以提取隐藏在图片中的伪造信息, 但是对光照环境和采集设备变化的适应性差, 鲁棒性较差。故本文针对频率域的方法进行改进, 在使用频率域的同时引入空间域方法, 通过提取频率域和空间域的多尺度信息来提高人脸活体检测的效果。
1 相关工作
人脸活体检测技术是指一种判断人脸是否伪造(如人皮面具、数字照片、打印照片、视频等)的技术。现有的人脸活体检测技术主要分为两类: 基于空间域的活体检测和基于频率域的活体检测。
基于空间域的方法可以分为基于传统手工特征和基于深度学习的方法。传统手工特征包括LBP[1]、HOG[2]、SIFT等静态特征和面部活动、眨眼、光线变化、远程生理信号特征RPPG[3]等运动特征。但是, 静态特征所含信息层次较低, 并且提取操作繁琐; 基于运动特征的方法对回放视频类攻击的识别率不高。此外, 时间信息也是一些学者关注的方向, 甘俊英等[4]提出了基于时空信息的3D卷积神经网络。利用深度学习的方法主要包括Auxiliary[5]、STASN[6]、CDCN[7]等, 其中, Auxiliary方法[5]将循环神经网络RCNN模型估计的人脸深度和利用视频序列估计的RPPG信号融合在一起, 来区分真实人脸和伪造人脸。STASN方法[6]利用LSTM对时间信息编码进行分类, 利用SASM模块从多个区域中提取特征, 寻找边界、反射伪影等细微证据, 从而有效地识别伪造人脸。CDCN[7]指中心差分卷积网络, 通过聚合强度信息和梯度信息来获取人脸内在的细节模式。但是, 空间域方法在数据采集设备干扰较大的情况下, 仍然无法提取到更为有效的伪造信息。
频域分析是图像信号处理中一种经典而重要的方法, 已经广泛应用于诸如图像分类[8]、纹理分类和超分辨率重建方面。已有学者利用小波变换(WT)或离散傅里叶变换(DFT)[8]将图像转换到频域并对潜在伪影进行挖掘。例如, Durall等[8]利用DFT变换和不同频带的振幅来提取频域信息, Stuchi等[9]利用一组固定频域滤波器来提取不同范围的信息, 然后通过全连接层来获得输出。还有学者在人脸活体检测中采用滤波方法对伪造图像中的潜在细微信息进行提取和挖掘。例如, 使用高通滤波器、Gabor滤波器[10]等来提取基于高频成分的特征(例如边缘和纹理信息)。Wang等[11]发现, 经过高通滤波后, 真实图像和假图像的光谱有显著差异。然而, 在这些研究中使用的滤波器往往是固定的和手工制作的, 因此不能自适应地捕获伪造痕迹。Jourabloo等[12]利用快速傅里叶变换(FFT)来分析伪造攻击噪声, 发现低频特征与颜色失真和重放伪影有关, 而高频特征对打印攻击更敏感。最近, Chen等[13]融合了高频和低频特征以提高人脸活体检测的普遍性, 使用三个固定的滤波器从输入图像中提取高频信息, 并用高斯模糊滤波器来提取低频特征。Qian等[14]提出一系列可学习的频率滤波器并用于人脸伪造检测。然而, 手工制作的和固定的过滤器可能无法覆盖完整的频率域, 并且频域方法对光照环境和采集设备的变化很敏感, 所以, 频域方法很难自适应地捕获伪造信息。
综上, 基于频率域的方法可以有效地提取富含边缘信息和纹理信息的高频信息和富含颜色信息和均衡度信息的低频信息, 但是普通频率滤波器的方法不能自适应地捕获伪造信息, 同时, 基于空间域的方法在传感器干扰大的情况下无法直接捕获伪造信息。由于这两种图像处理方法在高分辨率和高频处都有相同的语义信息, 故本文提出基于多尺度双通道的人脸活体检测方法, 对频率域和空间域的方法进行改进, 本文的主要贡献有:
1)提出多尺度双通道网络, 一个通道负责频率域的处理, 一个通道负责空间域的特征提取, 分别提取高低中频信息和高低中分辨率的空间信息。
2)在设计的双通道网络中, 利用空间注意力机制将对应的各个尺度下的频率域特征和空间域特征进行了特征融合, 增强了网络的特征提取能力, 提高了人脸活体检测效果。
2 本文工作
2.1 基本框架
本文提出多尺度双通道人脸活体检测方法, 具体网络架构如图1 所示, 该网络由两个分支组成, 第一个分支为频率域分支, 主要用于图像的频率域, 将图像分为低、中、高、全部4个频段, 分别负责提取人脸图像的纹理信息、上下文内容信息等; 第二个分支为空间域分支, 主要负责从图像的空间域提取有效信息, 通过提取图像多尺度分辨率下的特征图, 获取颜色、均衡度、图像上下文信息和图像纹理四个方面的信息。具体实现过程如下: 首先, 使用MTCNN检测出人脸, 获取人脸区域, 将输入图像归一化为224×224×3的图像; 其次, 进行人脸对齐获取人脸关键点, 利用人脸眼角关键点的连线, 将所有人脸图像旋转为竖直的人脸图像, 将预处理后的人脸图像输入频率域分支和空间域分支, 通过多尺度频率域与多尺度空间域信息的有效结合来实现人脸活体检测。其中, 频率域和空间域的具体实现分别在2.2节和2.3节中阐述。
2.2 多级频率分解网络
基于深度学习的人脸活体检测方法在已知数据集上的检测性能较好。但在未知数据集上进行测试时, 性能通常会急剧下降, 这可能是由于攻击设备(传感器噪音)和捕获环境(光照环境)的变化造成的。为了解决这一问题, 本文提出基于频率域与图像域结合的处理方法, 这种可学习的多尺度频率域和空间域的人脸活体检测方法是将输入的人脸图像分解成不同级别的频率成分和不同级别分辨率的图像。下面介绍频率域的多级频率分解网络的设计。
采用非手工设计的二进制基滤波器将频域划分为低、中、高频段。二进制基滤波器的目标是大致相等地划分从低频到高频的频谱。这种二进制基滤波器中定义
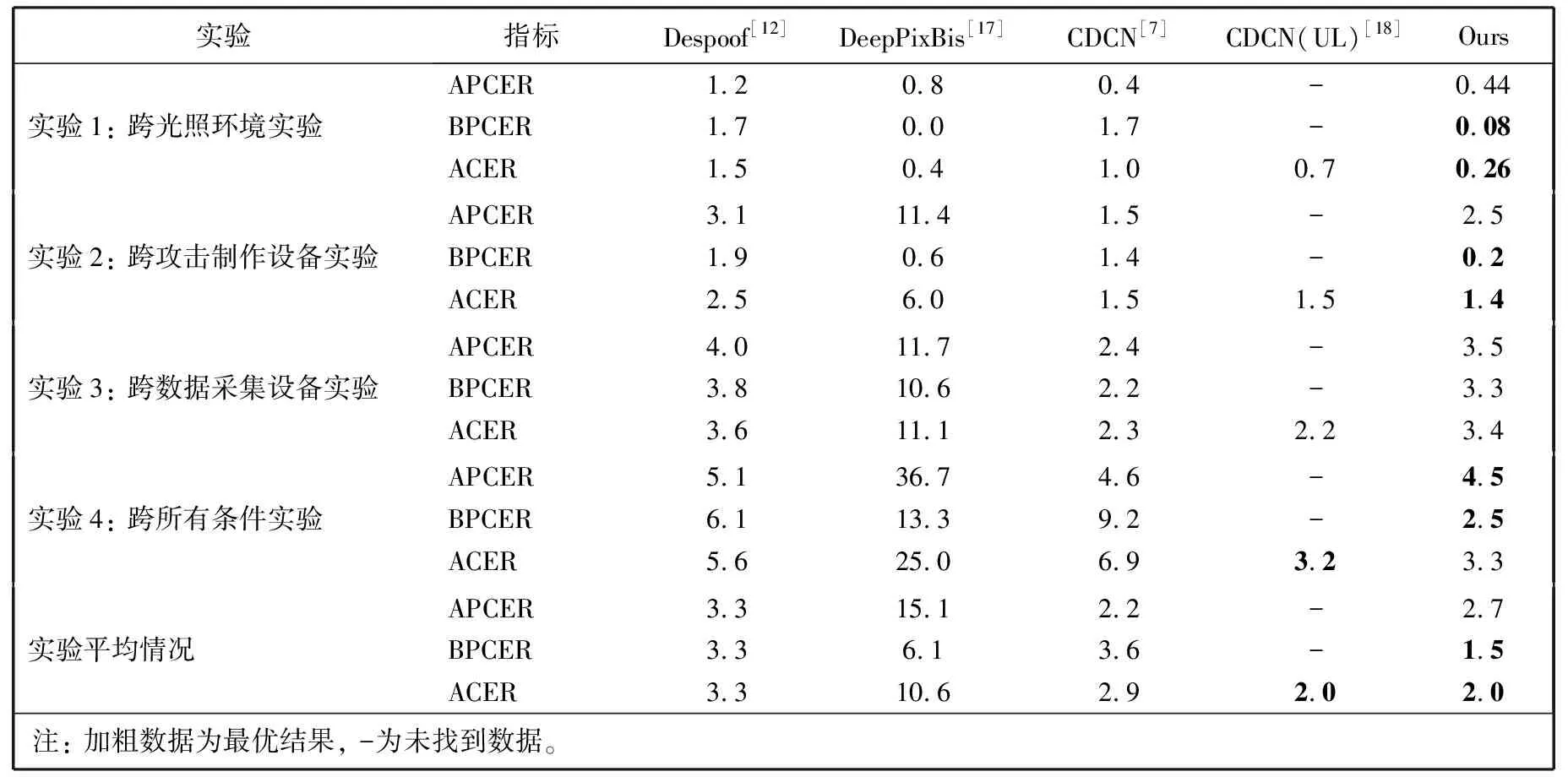
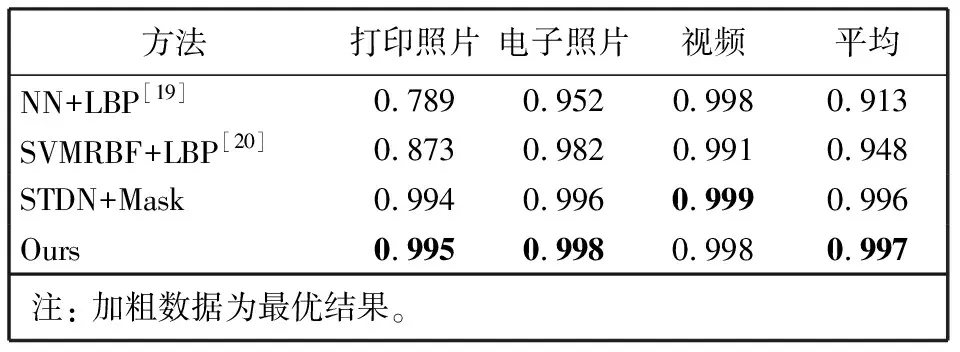
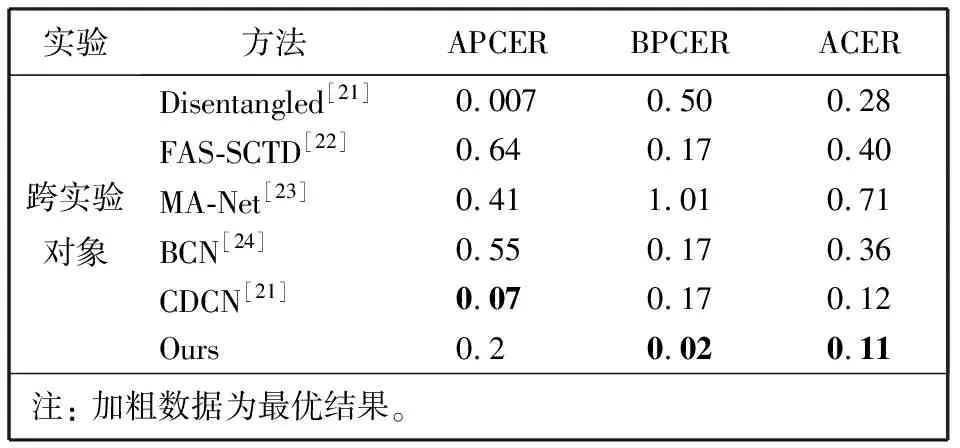
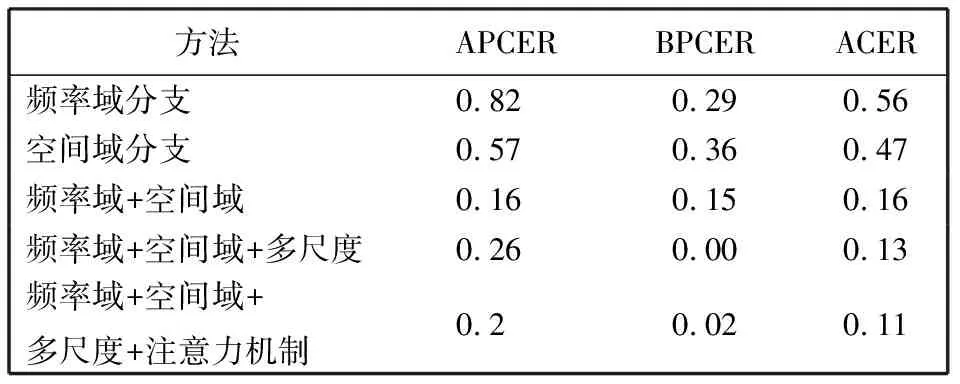
Fbi={fbi|0 (1) 式中:fbi表示第i多尺寸的频域滤波器;n=4, 分别表示低频、中频、高频、全频。fbi定义为 fb={fbjk=1|pstart pstart (2) 式中:pstart,pend分别表示低、中、高频谱的起始位置。 本文在二进制基滤波器的基础上增加了可学习的滤波器, 旨在自适应地选择感兴趣的频率。该滤波器是一个符合均值为0.0, 方差为0.1的正态分布。综上, 本文的频率域滤波器定义为 根据病畜临床表现,在排除恶性传染性疾病的基础上,现场对4头24 h内死亡的牦牛尸体进行了解剖。在4头病死牦牛的肝、胆部都发现了大量片状吸虫寄生,寄生虫虫体为深红褐色,腹背扁平,长30~50 mm,在放大镜下观察,虫体前端有明显突出的头锥,体表密布细小棘刺。在病死牦牛其他器官未发现寄生虫,也未检出其他种类寄生虫。 Fi=fbi+σ(fli)={fbijk=1|pstart k 0 (3) 式中:Fi表示第i个滤波器;fli表示第i个可学习的滤波器;N表示正态分布;σ表示sigmoid操作。 利用滤波器对输入图像进行分解得到图像分量, 其计算公式为 0 (4) 通过上述公式, 可以获得明确划分的低频、中频和高频带的频域和互补的全频带[14]。本文选择3个波段: ①fb1为整个频谱的前1/16的低频带; ②fb2为整个频谱的1/16和1/8之间的中频带; ③fb3为整个频谱的1/8和7/8之间的高频带。除此之外, 为避免分段频率引起的真实人脸图像和伪造人脸图像之间的伪造痕迹的丢失, 本文增加了一个额外的可学习滤波器, 该滤波器作用于整个频谱fb4。 为了补充频率域的信息, 本文引入空间域分支, 在3个分辨率尺度下提取特征, 兼顾了图像的颜色、上下文、纹理等信息。首先使用下采样对图像进行编码, 将图像由224×224变为112×112, 56×56, 28×28的特征图; 其次再通过上采样对特征图进行解码, 分解得到56×56, 112×112, 224×224的特征图, 这3个分辨率下的特征图分别代表图像伪造信息中的颜色范围、均衡偏差、图像上下文内容信息和图像纹理。最终将下采样得到的3个不同尺度的特征图归一化为14×14, 并拼接起来; 再次经过卷积神经网络将其提取为1张代表伪造信息的二值化特征图, 若输入图像是伪造人脸, 生成的二值化特征图分布将接近0, 反之, 该分布将接近1。同时, 将低级的空间域信息与低阶段频率域的信息相结合, 高级语义信息与高频段信息结合, 实现了频率域与空间域的互补。 为了进一步提高人脸活体检测实验结果的效率, 本文提出了分层注意力机制(HAM)来整合频率域和空间域的特征, 并利用双通道中不同层次的特征进行融合。多级频率域分解这一通道有多层次的频率特性, 并且滤波器的权值在模型训练时可以自适应学习。其中, 高频分量包含边缘和纹理信息等特征, 低频分量则包含色域的空间分布特征。在空间域中, 高分辨率图像强调边缘纹理信息, 中间分辨率图像强调上下文信息, 低分辨率图像强调图像颜色范围和均衡偏差。随着网络层数的提升, 其所提取的特征会越来越高级, 低级特征往往包含图像的纹理和边缘信息, 高级特征往往包含一些高级的语义特征。如图1 所示, 本文将2个通道中间特征图28×28, 56×56, 112×112拼接起来, 使用卷积神经网络进行特征聚合, 最终生成3个14×14的特征图, 将3个尺度生成的特征图拼接生成1个14×14的二值化特征图, 对该特征图的约束为 (a)Oulu-NPU数据集示例 (5) 式中:m为样本总数;zi为单个样本的特征图约束, 定义为 (6) 式中:xi,yi分别表示预测的特征图和数据的预定标签, 即真实人脸图像的预定标签为14×14的全1特征图, 伪造人脸图像的预定标签为14×14的全0特征图。 本文方法在3个公开可用的人脸活体检测数据集Oulu-NPU[15]、Siw[5]和Idiap Replay-Attack[16]上进行了评估。Oulu-NPU[15]数据集由55名受试者和6部手机录制的5940个视频组成, 具体包括3种光照环境, 照片和回放视频两种欺骗攻击方式, 高清电子设备和普通电子设备两种攻击设备。图2(a)展示了Oulu-NPU数据集的样本, 从上至下分别为光照1, 2, 3; 从左至右分别为真实人脸照片纸质打印照片1、纸质打印照片2、录制视频1、录制视频2。Idiap Replay-Attack[16]包含50个受试者和不同传感器及不同光照条件下捕获的300个视频。具体包括两种类型的攻击: 打印攻击和回放视频攻击, 两种光照: 可控光照和不均匀光照, 两种数据采集设备: 固定机位采集和移动机位采集。 图2(b)展示了该数据集的样本, 从上至下分别为逆光场景和均匀光照场景, 从左至右分别为纸质打印照片、手机电子照片、高清平板电子照片、手机录制视频、高清平板录制视频和真实人脸照片。Siw[5]数据集包括165个受试者, 每个受试者有8个真实视频和20个伪造视频, 含纸质打印照片和回放视频两种攻击方式, 纸质打印照片攻击采用2种不同质量的打印纸材, 回放视频采用4种不同品牌的手机录制, 所有数据使用2种不同的相机采集(佳能和罗技)。图2(c)展示了纸质攻击样本示例, 从上至下分别为高分辨率图像和低分辨率图像, 从左至右分别为光面纸质和亚光面纸质。图2(d)展示了Siw数据集视频攻击样本示例, 从上至下分别为不同的摄像方式, 从左至右分别为ipad视频、iphone视频、电脑视频、三星S8视频。测试时, 本文遵循所有的测试方案, 并与SOTA方法进行比较。与之前的大多数工作类似, 本文只使用上述数据集中的人脸区域进行训练和测试。 3.1.1 实验评价指标 本文采用APCER、BPCER、ACER和AUC两种实验评价指标。APCER、BPCER、ACER描述给定一个预定阈值的性能, AUC描述分类器效果的好坏。具体地, APCER表示伪造人脸图像被当成真实人脸图像的概率; BPCER表示真实人脸图像被当作伪造人脸图像的概率; ACER表示平均分类错误率, 即APCER和BPCER的平均; AUC表示ROC曲线下的面积, 横坐标为FPR, 纵坐标为TPR, TPR即APCER。计算公式分别为 (7) 式中: FP指False Positive, 即假的正样本, 表示伪造人脸图像被当作真实人脸图像; TN指True Negative, 即真实的负样本。 (8) 式中: FN指False Negative, 即假的负样本, 表示真实人脸图像被当作伪造人脸图像; TP指True Positive, 即真实的正样本。 FPR=1-BPCER。 (9) 3.1.2 实验参数设置 本实验在NVIDIA GeForce RTX 3090, 16 GB内存的实验环境下进行, 在Pytorch框架中实现。初始学习速率为1×10-4, 总共训练100次迭代, 批处理大小为256, 并按照3个轮次不更新损失的规律等比例降低学习率。 3.2.1 Oulu-NPU数据集实验结果 为了评估人脸活体检测方法的通用能力, Oulu-NPU数据集提供了4种实验方案。实验1用于测试不同光照环境对活体检测的影响, 实验2用于测试不同攻击制作设备对活体检测的影响(比如纸质打印照片的不同材质, 回放视频的不同录制设备), 实验3用于测试不同数据采集设备对活体检测的影响, 实验4用于测试不同光照、不同攻击制作设备、不同数据采集设备(即跨所有条件)对活体检测的影响。为了进行公平的比较, 本文严格遵循这些实验的定义和评价标准。Oulu-NPU数据集的示例如图2 所示。 将本文多尺度双通道人脸活体检测方法与近年文献中提出的Despoof[12]、DeepPixBis[17]、CDCN[7]、CDCN(UL)[18]人脸活体检测方法进行比较, 具体实验数据见表1。本文方法在各个实验上获得的ACER值分别为0.26%, 1.4%, 3.4%和3.3%。可以看出, 本文方法所得结果优于现有方法。例如, 在最具挑战性的实验4中, Despoof[12]获得的最低平均分类错误率为3.2%, 而本文方法的平均分类错误率为3.3%。表1 中最后一组数据展示了各个方法在4个实验上的平均错误率, 本文方法在Oulu-NPU数据集上的BPCER和ACER达到了最优, APCER达到次优。 表1 Oulu-NPU数据集测试结果 3.2.2 Idiap Replay-Attack实验结果 本文在该数据集的纸质打印照片、电子照片、回放视频3种攻击上进行实验, 表2 为Replay Attack数据集针对3种欺骗类型(纸质打印照片、数字照片、视频)的AUC值, AUC值代表了分类器效果的好坏, AUC值越高, 说明分类器效果越好。 表2 Idiap Replay Attack 数据集实验结果 由表2 可知, 本文方法对纸质打印照片和电子照片的活体检测效果在所有对比方法中为最优, 并且在3种攻击下的平均检测效果也最优。 3.2.3 Siw数据集实验结果 本文在Siw数据集上严格遵循第1个实验方案, 即跨实验对象。将本文方法与Siw数据集的Disentangled[21]、FAS-SGTD[22]、MA-Net[23]、BCN[24], CDCN[7]方法进行对比, 实验结果见表3, 由表3 可知, 本文方法在实验1中的检测错误率为最低。 表3 Siw 数据集实验结果 3.2.4 消融实验 在Siw数据集上进行消融实验, 分别从双通道、多尺度、以及注意力机制3个方面进行验证, 实验结果见表4。由表4 可知, 双通道网络的引入大大提升了人脸活体检测的准确率, 多尺度的引入对双通道网络进行了提升, 注意力机制在多尺度双通道的效果有所提升, 通过逐步消融实验证明了本文提出的双通网络、多尺度概念、注意力机制是有效的。 表4 消融实验结果 3.2.5 可视化结果 图3 为在SIW数据集上训练的热力图, 展示了本文网络在训练过程中着重关注的图像部位, 从上至下分别为真实人脸图像、纸质打印照片攻击图像、回放视频攻击图像, 从左至右分别为源数据、频率域通道的热力图、空间域通道的热力图、多尺度双通道的热力图。 图3 热力图 由图3 可以看出, 纸质打印照片在嘴角处、眼睛、鼻翼旁边有明显的摩尔纹和纸质纹理, 网络训练过程中也确实观察到了这些点, 说明本文网络在人脸活体检测上是有效的, 并且直观地观察到双通道的网络在训练过程中提高了人脸的注意力区域。 本文提出了基于多尺度双通道的人脸活体检测方法, 在频率域和空间域两个通道上提取多尺度特征, 并使用时空注意力机制融合频率域和空间域特征。为了验证本文方法的有效性, 在Oulu-NPU、Idiap Replay-Attack、Siw等3个数据集上进行实验, 其中在Oulu-NPU数据集上的平均错误率为2%, 在Siw数据集上的错误率为0.11%, 在Idiap Replay-Attack数据集上的检测准确率为99.5%以上。与同类方法相比, 本文方法在光照环境和传感器采集设备变化两个方面的适应性明显提升, 提高了人脸活体检测的鲁棒性和准确性。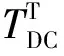
2.3 多尺度空间域分解网络
2.4 分层注意力机制

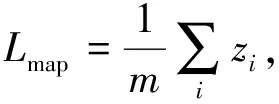
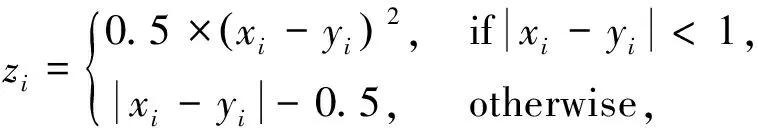
3 实验结果与分析
3.1 实验设置
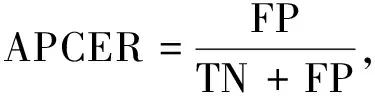
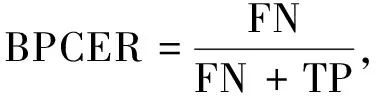
3.2 实验结果

4 结 论
