基于数据标签的智能电网监控与异常检测
2023-05-26谢小川
管 荑,谢小川,胡 琳,尚 鹏,黎 明
(1.国网山东省电力公司,山东 济南 250001;2.四川师范大学 计算机科学学院,四川 成都 610101;3.国网山东省电力公司建设公司,山东 济南 250001)
近年来,智能电网(smart electrical grid,SEG)快速发展,电网承载的业务数据快速增长,业务数据中蕴含大量高价值信息和异常数据未得到挖掘和利用,存在数据量大而信息匮乏的现象。大数据技术的发展和应用,一方面,使得SEG能快速、高效地处理和挖掘业务数据中的高价值信息和异常数据;另一方面,由于SEG数据具有多源异构性、高维度和先验性等,对SEG进行监控时,须挖掘和提取高质量的SEG运行数据,并整合SEG外部环境数据进行有效的监控和异常数据检测,以实现由单一监视向大数据监控发展[1-2]。对SEG基于数据标签的监控和异常数据检测进行研究,旨在减少电网异常发生和提高SEG运行效率。
SEG系统中,由于设备故障和性能下降导致用户数据异常,在设备工况检测、故障监测、设备监控等多方面需要实时数据监控与分析。另外,因SEG数据源类型多、数据量大、数据复杂度高、数据维度和实时性高,使得异常数据检测时开销大、容易漏判错判,进而导致检测的准确性和效率等受到影响,难以满足大区域电网对异常检测精度、效率和实时性等要求。
综上,针对SEG监控存在的数据传输协议的不一致性、业务数据定义的不规范性、数据计算与处理的效率和实时性不足等问题,利用数据标签对数据进行抽象与规范,将各种数据传输协议定义的数据源统一以数据标签化进行规范,提升数据多源汇聚效率和规范性,并对数据标签进行全使用周期的监控;同时,对数据标签的异常检测流程、稀疏化与精简算法和检测算法等进行设计。
1 相关工作
关于SEG监控,研究者们已在提高电网智能化、数据实时性、数据利用率和用户满意度等方面取得较好效果,但仍然存在一些问题和不足[3-4],主要为:1)传输协议不一致。电网数据产生量巨大,所使用的通信协议有IEC608705-101协议、IEC60870-5-104协议、IEC61850协议和循环远动协议等,这就使得在分层分类存储数据时不规范,无法提高监控主站效率和高速数据互联互通等[5-7]。2)业务数据不一致。缺乏面向全电网的业务数据规范标准,使得全电网在建设和管理数据粒度上存在差异;并且在多源数据描述和表达上,亦具有数据异构性和多样性,严重影响对全电网数据需求的规范描述与表达[8-10]。3)数据处理和计算效率不高。电网监控数据分析未从业务应用角度挖掘和处理累积的各种数据,使得业务数据的处理和计算无法满足毫秒级、微秒级的实时性要求[11-13]。4)电网监控异常数据检测存在不足。SEG监控的异常检测在检测架构[14]、实时数据检测[15]、电网内部的异常行为检测[16]和异常数据检测[17]、电网外部的信息入侵检测[18]和虚假攻击检测[19]等方面存在问题,使得异常数据检测[20]和异常流量数据检测[21]在实时性和准确性等方面仍存在不足之处。
针对智能电网数据异常检测,国内外研究者进行了相应的研究,主要分为基于统计分析和基于机器学习算法的检测方法。其中,基于统计的异常检修方法,通过假设正常数据服从同一概率分布,异常数据的概率分布与正常数据概率分布存在差异而实现异常数据检测;该方法不能检测到局部异常数据,特别是小范围、单点单域的异常无法检测[22]。关于基于机器学习、深度学习方面的异常检测,Jiang等[23]进行了综述,并指出了各种机器学习、深度学习算法在异常数据检测方面的优缺点。Chahla等[24]将聚类与预测结合,提出了一种新的无监督深度学习检测功耗异常数据算法,并对算法进行实验验证;但算法运行时间复杂度未明显提高。在基于机器的异常检测方面,有研究者采用神经网络算法、Markov理论和时序等进行研究,如:Tsukada等[25]利用神经网络进行边缘设备的异常检测研究;Wu等[26]利用双隐马尔可夫模型对无线终端非信任环境下的异常检测进行研究;Cook等[27]综述了物联网时序异常数据检测的研究现状及未来潜在的机会等。如上所述,这些研究能有效应用于各种检测任务,但每种检测方法都有其优缺点,对SEG的异常检测提供了有益参考。
虽然研究者对SEG监控和异常检测进行了诸多研究,但仍存在难以准确发现监控时的异常数据的问题,特别是在多维异构特性下,其异常数据挖掘难度更大。因此,本文利用数据标签实现SEG监控,在监控中利用异常数据检测算法实现SEG数据标签监控异常数据检测,并提出了相应的流程和算法。
2 监控架构
2.1 系统结构
在提出的SEG数据标签监控系统中,针对各种协议的原始数据输入,首先,对原始数据进行数据源命名、设备信息数据和数据结构等规格化处理;然后,按照规格化后的统一格式传输到数据标签化处理中。数据标签化处理过程中,对各类数据进行标签化处理,如监控运行数据、检修数据和用户数据等。将经过标签化处理的监控数据输入到后端进行数据集标签提取与分析,即进行数据标签语义提取、可交互监控数据标签集提取和数据文本语义提取等,这一过程在SEG监控大数据处理与分析中完成[28]。具体框架如图1所示。

图1 SEG监控数据标签与异常检测框架Fig.1 SEG monitoring data-tag and anomaly detection framework
如图1所示,经过标签提取后,将数据发布到计算分析部分,进行数据标签的关联性分析、数据稀疏化、精简关联数据集生成和异常检测等处理,得到SEG数据标签监控的正常数据和异常数据,以便进行各种实时处理和管理决策。
原始数据来源于5个方面:1)电网原先的监控系统采集而得到的数据;2)现有监控的遥测、遥感、遥调和遥控数据;3)发电端输入电网的输变电在线采集、检测的实时数据,以及二次侧在线录波数据和各种占用及电网设备采集数据与运行数据;4)SEG各种子系统的设备检修、故障、缺陷和台账等基础管理数据;5)各种SEG相关辅助子系统的各种辅助数据,如气象、工作票、雷电监测、视频、地理信息系统等。依据数据源的差异和特征,对图1进行层次化和模块化抽象,得到SEG标签数据监控架构,如图2所示。

图2 SEG数据标签监控架构Fig.2 SEG data-tag monitoring architecture
图2中,虚线框内的数据层,即图1的规格化数据接入部分,在此仅对其进行了细化,如输电线路组成,即各种输电线路传感器、无线感知设备、设备识别标签、摄像头等感知监控数据,经过规格化处理后,通过传输通道进入下一个数据处理层。在标签层,对规格化数据按照标签化处理,得到感知数据集的数值语义标签和时序文本语义标签;感知数据集的数值语义标签和时序文本语义标签在次层依据关联规则进行关联。服务层包括信息平台标签数据库、各种专业服务器和客户监控终端等,在服务器中设置专用标签提取与分析算法,并将标签提取与分析分析结果输出到应用层。应用层主要进行各种监控数据状态分析及应用,包括监控数据标签提取后的呈现形式、表示方法和结果反馈等。
2.2 数据标签
数据标签采用非手工标签生成方式,即依据业务规则构建标签,主要包括属性标签、事实标签、模型标签和复合标签等。SEG的各种数据,需要建立数据标签化规则,即:对各类设备的标签,建立分类分级、应用场景、组织对象、供应商和所属员工等属性,以便进行标签对属性关联[29]。
SEG运行时各种监控感知数据和运行数据均为单一数值构成的集合,称集合为感知数据集。感知数据集为具有同一属性且在连续时间段内的数值序列,即:
式中,pi为在某时刻感知数据集pdsObj设备vi收集的值,i=1,2,···,n,n为 感知层设备数量。对pdsObj的数据集赋予一个数据对象和数值 λ,构成数据集的数值语义标签numSL,即:
式中,λ为数据对象的影响因子。
感知数据文本与感知数据集语义相关联,感知数据文本txtObj是感知数据集对应标签的一份文本数据,即:
式中,wi为txtObj中设备vi的权重。
主体词库keyTwl为主体词的集合,包括语料库中所有感知文本数据的语义标签,用以限定语料库的语义范围,即:
式中,keyi为主体词库中设备vi的主体词。
主体词表示文本语义或具有一定辨识度的词或短语,每个主体词对应一个权值的概率,即:
式中,wvi为 主体词keyi取权值wi的概率。
属性词是经由分词标注处理后的词或短语,是实际语义的载体。属性词aW为一个与主体词关联的权值概率序列,即:
式中,pvi为 属性词aW的主体词keyi的权值概率。
由此,原始感知数据集由原数值型数据转换为具有标签特性的感知数据文本sdlObj,且感知数据集与感知数据文本具有关联关系,即:
对sdlObj添加时间分量,使得感知数据集与感知数据文本关联的同时,具有时序关联特性,即:
式中,timeObj为感知数据集的时序关联特征值序列,即:
式中,ts表示感知数据集pdsObj在 时刻s的时序值。
由此,利用式(1)~(9),即可建立SEG监控感知数据集的时序文本关联数据标签。
2.3 任务划分
SEG监控状态判断采用潮流计算模型,即用极坐标方式描述数据[30]。其描述的极坐标形式为:
式中:ξ ∈Eψ,Eψ为和节点 ψ 相联的节点集合;Uψ为检测节点 ψ的电压幅值;θψζ为节点 ψ 和 ζ 的相角;Pψ、Qψ为节点 ψ的有功和无功功率;Gψζ、Bψζ为节点 ψ 和 ζ相联的自导电和自电纳。
利用式(10)对SEG节点 ψ的运行状态进行判断时,依据Pψ、Qψ、Uψ、θψζ中的任意两个参数值,以及约束条件,求解另外两个参数[31]。若式(10)的节点 ψ数目较多,则式(10)的计算量巨大;为了在给定时间内计算得到SEG的状态值,利用潮流计算得到结果,从而满足电网需求。
依据数据标签的SEG监控和式(10)计算量,采用主从模式进行任务划分。假设节点 ψ 与 ζ相联异常,将该异常进行细分,在MapReduce大数据处理中用Map代表若干细分,所有Map为串行潮流计算,即可得到节点 ψ运行状态。Map等价于MapReduce中的子任务,即采用该方式对SEG数据标签监控进行任务划分,但SEG的节点 ψ 与节点 ζ相联不一定导致异常,故需要对数据标签SEG监控的异常数据进行映射,并将各映射与异常数据检测算法进行归纳,以输出异常数据检测算法的结果。对图1的计算分析部分,进行基于MapReduce的SEG数据标签任务划分,得到任务划分模型如图3所示。

图3 SEG监控大数据任务划分Fig.3 SEG monitoring big data task division
3 异常检测模型
3.1 检测流程
依据第2节论述和SEG数据特征,以及SEG监控大数据系统对链路延迟、网络吞吐率和存储使用率等对时序的要求,对数据标签增加时序关联,以进行数据标签的异常检测[32]。
定义1 设SEG由多个设备节点构成的时序关联无权图G(V,E),其中:V表示SEG节点集合,|V|=n为设备节点数量;E为网络中边的集合。
根据定义1,设di(t) 为 设备节点i在t时刻的时序关联数据,即为数据关联时序,则:
式中,D(t) 为 SEG中所有节点在t时刻的时序关联数据集。
由此,将SEG数据标签监控的异常数据检测转化为数据标签化后的时序关联,用给定时间序列对所有时刻的时序关联数据集D进行时序检测,以检测是否存在时序异常的数据。因此,对时序关联数据集D依据如图1所示的计算分析步骤,即进行时序关联数据生成、时序关联分析、异常数据检测和数据输出,细化流程如图4所示。
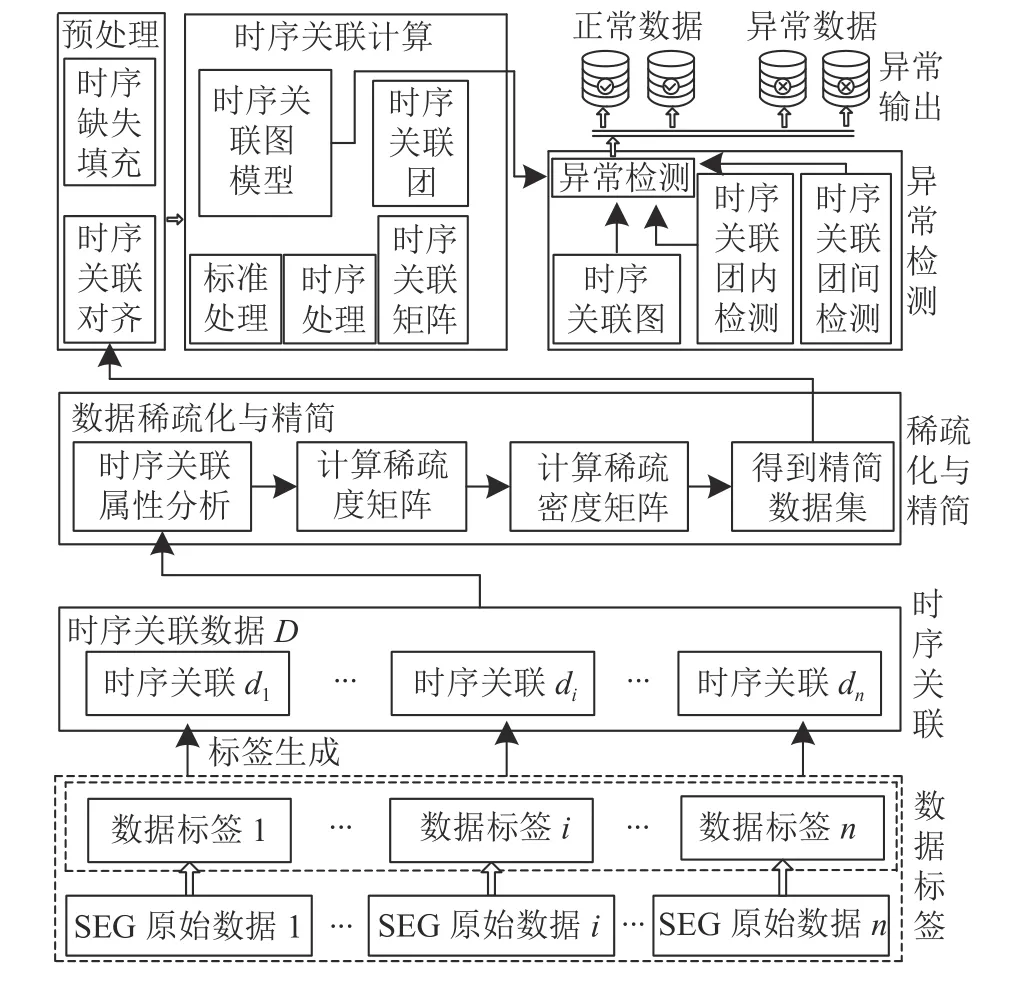
图4 SEG数据标签异常检测流程图Fig.4 SEG data-tag anomaly detection flowchart
由图4可知,异常检测时,先进行时序关联,并依据关联分析得到的属性进行时序关联稀疏矩阵和时序关联系数矩阵的密度矩阵计算。异常数据检测包括预处理、时序关联计算和异常检测等步骤。其中:预处理先对SEG数据标签的时序关联数据进行时序对齐和时序缺失填充等处理;时序关联计算是对是预处理后的数据进行标准和时序关联处理,生成时序关联矩阵,并依据矩阵中元素值建立时序关联图,再对时序关联图按照关联性阈值划分时序关联团;异常检测将检测结果输出为正常数据和异常数据。
3.2 稀疏与精简算法
依据图1和4,对得到的数据标签时序数据进行稀疏化处理,得到精简数据集,并设计稀疏和精简算法[33]。
定义2 设a为指定的一组属性,则定义A为包含属性a的p维数据集,即:
定义3 设dij为大小为p×n的时序关联数据集D的元素,dij为 设备vi(i=1,2,···,n)在属性Aj(j=1,2,···,p)上的取值,di为 设备节点vi收集的数据集合。
由定义2和定义3可知,若给定Aj上对vi的di j值,得到dij稀疏度SMDij为:
式中:x为dij的k近邻集中的设备节点的随机感知值;y(dij)为dij的k近邻集,y(dij)=Knns(dij),|y(dij)|=k+1,Knns(di j) 为 点vi在 维 度 为Aj上 的k阶 近 邻 集;cvij为y(dij)的中心值,其表达式为:
若SMDi j的值比较大,则dij在稀疏区域下;否则,dij在稠密区域中,且位于时序关联数据集D的每个维度。
又因k阶近邻使时序关联数据集为D的数据量急剧增加,为降低数据量,设计算法1生成精简时序关联数据集。

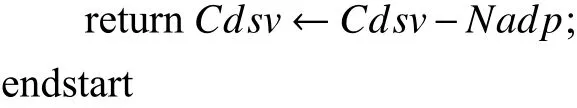
算法1中:首先,对D中数据按照每个数据的维度值进行升序排列,并按照1维k近邻在排序后的数据集Ds中搜索,依据式(13)计算D中的每个数据的稀疏度SMDij,且将稀疏度SMDij存储于稀疏矩阵B的元素bij中。然后,在给定稀疏度阈值 ξ下,对B进行稀疏区和稠密区的识别,得到稀疏密度矩阵C,cij为C的元素。若bij<ξ ,则cij=1,即dij位于稠密区;否则,cij=0,即dij在稀疏区。最后,对C中的值进行剪枝,得到精简数据集Cdsv。
3.3 检测算法
对Cdsv数据集进行逆向逐段聚集均值处理,以使数据集进一步减少而降低运算复杂度,且有利于对各时序数据集的属性进行提取[34],设hi为 节点vi在数据集Cdsv中对应的数据点。
定义4 设数据点hi的 最近邻节点hm总 数为K,m=1,2,···,K。hi的扩展邻域Ekd(hi)包括3类节点的集合,与3类节点关系如下:
式中,Ekd(hi)为hi所有近邻点的集合,knn(hi) 为hi的k正则最近邻点的集合,krnn(hi) 为与hi的k-共享最近邻点个数为0的点的集合,ksnn(hi) 为 与hi的k-共享最近邻点个数为1个或多个的点的集合。
定义5 数据点vi的k近邻扩展可用带控制因子的高斯核函数kEdf(hi)描述,为:

式中,Rpaa(hi)为hi的滑动平均分段聚合近似值,Eud(hi,hm)为hi、hm的欧几里得距离。
根据定义4和定义5,hi密度与局部k近邻间的差异度Dlknd(hi)为:
定义1对G(V,E) 进行时序关联初始化,即Gr=(V,E);若Dlknd(hi)≥α ,α为设定的关联差异度值,则对Gr=(V,E) 的所有V顶点进行遍历;对遍历所得到的图再进行处理,其处理流程为:
1)设置时序关联差异度 α,用算法1 对Gr=(V,E)每个顶点初始化,得到稀疏度矩阵B。
2)i从1到n,l从i+1到n,若Dlknd(hi)≥α ,则Gr中加入边eil=(vi,vl)。
3)得到Gr即为时序关联图。
定义6 对时序关联图Gr=(V,E) ,假设Vtag为定义1确定的顶点集合,即Vtag={v1,v2,···,vn},当n≥2时,dov(vi) 为 顶点的度,woe(eil) 为 边eil的 权值。若Vtag满足:
1)∀vi∈Vtag,有vi∈V(Gr),V(Gr)为图Gr的顶点集合;
2)∀vi∈Vtag,有dov(vi)≥|Vtag|/2;
3)给定 α,∀vi、vl∈Vtag,有woe(eil)≥α;
4)Vtag为Gr上满足条件1)、条件2)的最大顶点集。则称Vtag为时序关联图Gr上的一个时序关联团。

依据定义4~定义7,利用算法1得到的精简数据集Cdsv,将Cdsv作为算法2输入,得到异常数据集OutlierDS。在算法2中:先将异常数据集OutlierDS设置为空集和时序关联图Gr;然后,利用算法1输出的精简数据集Cdsv进行时序关联图的时序关联团构建,再进行时序关联团内和团间的异常数据检查;最后,输出异常数据集OutlierDS。其具体算法过程为:



由算法2可知,其时间消耗于精简时序数据集Cdsv的稀疏度计算、时序关联图构建和求解最小覆盖与计算异常时序关联数据。算法2中,求解最小覆盖时使用匈牙利算法,求解和计算异常时序关联数据时使用禁忌搜索算法,在此不再描述。
算法1的时间复杂度为O(n×p),最坏情况为O(n2) 。而算法2给定Cdsv数据集按照式(17)计算Dlknd(vi) 的时间复杂度为O(n2),计算时序关联图的时间复杂度为O(n×p),但求解最小覆盖与计算异常数据的最坏情况时间复杂度为O(n3)。
4 实验与仿真
4.1 实验设置与实例
依据设计的框架,以电压为500~220、220~35 kV的主变电站为实验数据,进行近3个月的数据感知与存储,采集数据频率为每秒记录2次。利用所提出的算法1和算法2,对SEG数据标签异常监控与异常数据检测实验。
如图5所示,在主变电站的500~220 kV主变压器、220~35 kV变压器、电容器组、主变压器抵抗、站用变和各种母线、刀闸等,使用标签和相应的传感器进行监控,采集到变电站监控数据、调度信息、雷电信息和输电监控等数据,将数据迁移到大数据系统中。其中,数据表2 000多张,数据10亿多条,非结构化数据100万个文件以上,总数据量达到30 TB。
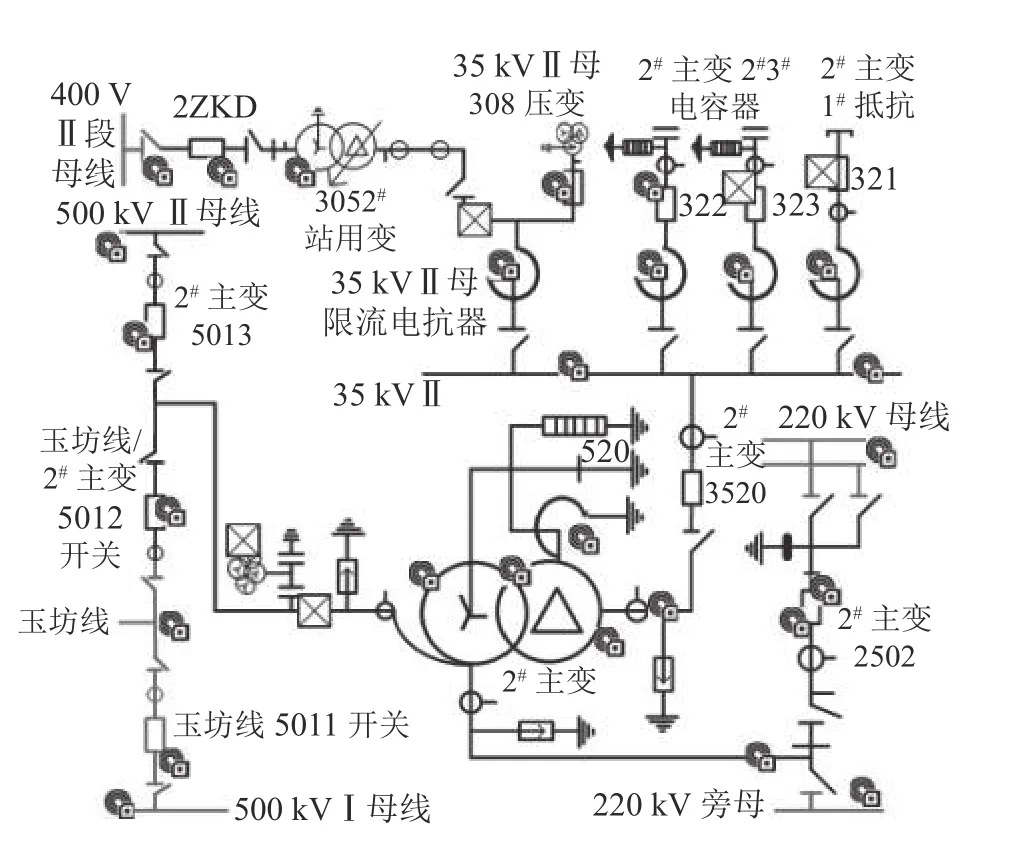
图5 主变电站监控智能分析结构Fig.5 Main substation monitoring intelligent analysis structure
首先,对采集到的原始数据进行标签化处理;然后,依据采集时间进行时序关联;最后,利用本文算法进行异常数据检测。得到异常数据后,对异常数据依据数据标签进行反析定位,得到2#号主变压器保护RC12屏的35 kV电压偏移异常后,须立即进行应急处理。
上级调度依据监控智能分析得到的异常数据,立即通知变电站所,对2#号主变压器异常信息的位置、信息归类归档,现场进行查验核对,检查2#号主变压器保护RC12屏35 kV电压偏移、35 kV母线电压,并做好现场防护与保护。经过细致查验,未发现现场异常,汇报上级调度,申请试分合322、323开关。现场断开322开关,异常信号仍然存在;拉开323开关,异常信号消失;合上322开关后正常,无异常信号。
处理完现场异常立即汇报上级调度,即将电容器组323有接地的情况予以记录并汇报,上级调度将异常汇报给相关决策者,决策者授权于上级调度,并下达对2#主变压器的3#电容器组进行检修的工作票。
4.2 算法仿真与分析
采用Matlab软件进行算法仿真,并结合Spark和Storm大数据分析系统,利用第4.1节采集到的30 TB数据,进行仿真与分析。
待检测数据均为正常数据,通过算法1和算法2检测后,得到异常数据[35]。设定正常数据经检测成为异常数据称为Nd2od,异常数据经检测成为异常数据称为Od2od,正常数据经检测为正常数据称为Nd2nd,异常数据检测为正常数据称为Od2nd,算法的准确率Dda和召回率Drr的指标分别表示为:
实验选取30 000个时刻、每个时刻96列数据。首先,对数据进行标签化处理;然后,进行时序关联处理;最后,用本文算法和参比算法,进行实验与仿真对比。其中,参比算法为独立同分布分类异常检测[36]、统计聚类异常检测[37]和机器学习异常检测[38]的算法,亦是异常检测领域较为先进的算法。实验时,对不同时序关联数据量、维度总数和异常数据量下中的算法性能进行对比实验,且设置Dda和Drr的基准值均为0.8,得到本文算法与参比算法在异常数据检测性能方面的对比曲线。不同数据量下的Dda和Drr如图6所示。

图6 不同实验数据量下的算法准确率和召回率对比曲线Fig.6 Algorithm accuracy and recall comparison curves under different experimental data volume
由图6(a)可以看出:随着测试数据量的不断递增,当数据量在0到20组之间时,文献[36]、文献[37]和文献[38]的算法准确率呈现急剧下降的趋势;然后,文献[38]算法准确率呈现震荡上升,文献[37]算法准确率在上升到一定值后,缓慢下降而趋于平稳。但本文算法,随着数据量递增,其准确率呈现缓慢递增而逐步趋于平稳。由图6(b)可知:当数据量增加时,3个参比算法召回率伴以波动递减;本文算法的召回率总趋势为递减,但递减幅度较参比算法小,且曲线呈缓慢下降,其召回率在数值上维持在大于80%。
图7为数据量相同时,在不同数据的维度p下,本文算法与参比算法准确率和召回率曲线的比较。图7(a)中:随着数据维度p从3到45不断递增,文献[37]算法准确率在波动中平缓下降,而文献[36]算法准确率在50%到68%之间波动且下降梯度较大;本文算法在维度数较低时,准确率为93%,当维度数增加时,起初呈现下降趋势,但当维度数达到9以后,呈现平稳上升趋势,其上升幅度在5%以内;文献[38]算法表现较为平稳,但其准确率不高,仅在75%到78%之间。图7(b)中,本文算法的召回率在85%到90%之间,且随着维度数的增加而呈现缓慢上升趋势,上升幅度在4%以内;参比算法在数据量增加时,召回率总的趋势为下降。

图7 不同时序数据维度数下的算法准确率和召回率对比曲线Fig.7 Algorithm accuracy and recall comparison curves under different time series data dimensions
图8为不同测试数据异常数据量下,本文算法和参比算法性能变化曲线。仿真采用的数据集为750组,数据集的维度设置为30。由图8可知:当异常数据量的增加时,本文算法准确率总的趋势表现为递减,但其准确度在仿真时均保持在82%以上;参比算法的准确率递减下降,且下降趋势较为明显。本文算法的召回率先是缓慢增加,然后缓慢下降,其值维持在90%以上;参比算法召回率在数据量增加时,总的趋势呈波动下降。
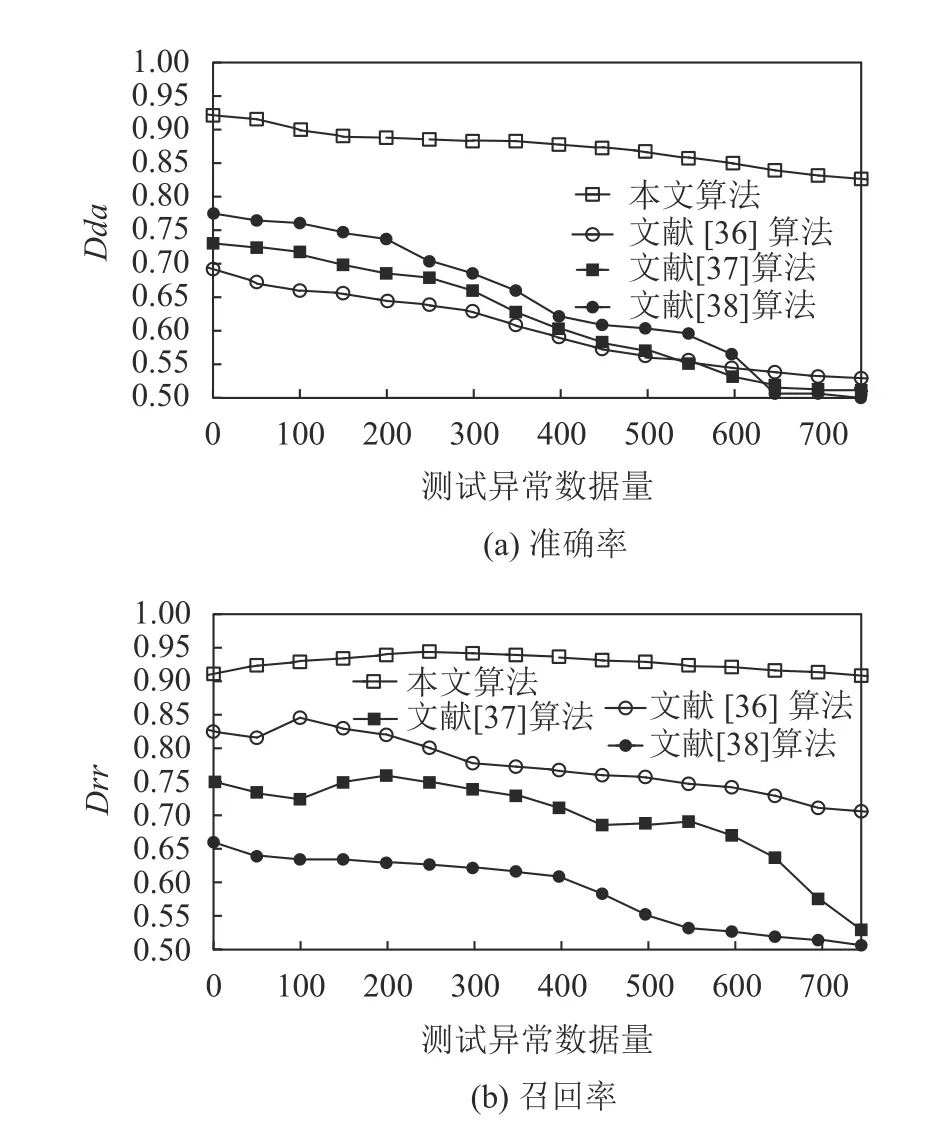
图8 不同异常数据量的算法准确率和召回率曲线Fig.8 Algorithm precision and recall curves under different abnormal data volume
综上,本文算法与参比算法相比,在准确率和召回率上均具有一定优越性,其原因是本文算法先按照算法1对原始数据进行了稀疏化和精简处理,使得在执行算法2进行异常数据检测时的运算复杂度明显下降。
采用不同数据量的测试数据集进行异常数据检测时,本文算法和参比算法运行时间比较结果如图9所示。

图9 测试数据集的算法运行时间比较曲线Fig.9 Algorithm runtime comparison curves for the test dataset
由图9可知:随着测试数据集数量的增加,本文算法和参比算法的运行时间均增加。在数据集较少时,文献[37]算法运行时间呈线性递增趋势;当数据量达到80以后,其运行时间增长平缓。其他参比算法运行时间呈现波动。本文算法的总体运行时间比参比算法少2.0~3.0 s,这是因为在测试时先按照算法1对数据进行处理,使得算法2的数据量比参比算法少,故其运行时间增加量较少。
通过实验和仿真对比分析可知,本文算法在不同数据源下,准确率维持在80%以上,召回率维持在85%以上。因此,本文算法有效性得到提高;同时,本文算法在相同数据量下的运行时间也较低,与参比算法比较,本文算法执行效率较高。
5 结论与展望
针对智能电网监控在局部传输协议不一致、效率较低和异常数据检测存在不足等问题,提出一种基于数据标签的SEG监控架构和异常数据检测算法。首先,对SEG数据标签监控与异常检测的框架、大数据监控分析架构、数据标签化和系统任务划分等进行设计;然后,提出系统异常检测流程、数据标签稀疏化与精简算法和异常数据检测算法;最后,对所设计的SEG数据标签监控架构进行电网实例分析,同时对提出的算法与参比算法在准确率、召回率和运行时间等方面进行对比仿真实验。可知:本文所设计的SEG数据标签监控系统能有效分析数据异常;与参比算法相比,本文算法在异常数据检测的准确率、召回率和运行时间等方面,有一定的改进和提高。
当然,本文所提出的SEG数据标签监控与异常检测算法仍存在优化空间,提出的算法仍然需要进一步提高准确率和召回率。下一步,将进一步对SEG数据标签监控体系结构进行改进;并对异常检测算法进行深入研究,提出更加有效的算法,以便更好地为电网服务。
