基于生成式对抗网络的类不平衡软件缺陷预测过采样方法
2023-05-24张恒伟贾修一
张恒伟,贾修一
(南京理工大学 计算机科学与工程学院,江苏 南京 210094)
软件缺陷是每个开发人员都会面临且必须解决的问题,需求理解不正确、软件开发过程不合理或开发人员的经验不足,均有可能产生缺陷[1]。软件缺陷预测可以识别出软件中哪些模块或类容易出现缺陷,是软件工程领域中非常关键且必不可少的工作之一[2]。通过机器学习方法建立相关模型,可以准确地识别出软件中的缺陷。预测模型的准确性通常受数据集不平衡性质的影响[3],然而在软件项目中,含有缺陷的样本远比无缺陷的样本少得多,这会导致软件缺陷预测中的数据集严重不平衡[4-6]。当数据集不平衡时,预测模型没有充分获取少数类(缺陷)的信息,其预测结果会偏向于多数类(无缺陷)的样本,忽略了缺陷样本或对缺陷样本进行错误的分类[7,8]。因此,类不平衡问题是公认的软件缺陷预测模型性能较差的主要原因之一。近年来,越来越多的研究试图缓解这一问题。
目前解决类不平衡问题的方法较多,主流的方法是使用数据采样技术。截至目前,大多数数据采样方法都是基于合成的过采样方法。在过采样中,通过复制或者简单计算生成少数类样本来平衡数据集中两类样本的个数。为了克服随机过采样(Random over-sampling,ROS)中出现的过拟合问题,Chawla等[9]提出了一种综合少数过采样技术(Synthetic minority over-sampling technique,SMOTE),用于生成新的少数类样本,使得少数类样本与多数类样本达到平衡。SMOTE为每个少数类样本找到k个少数类最近邻,然后在这些邻居中使用线性插值来生成新的合成样本。通过将合成样本添加到给定的数据集,SMOTE可以帮助扩展少数类的决策范围。Han等[10]提出了一种仅对边界附近的少数群体样本进行过采样的方法(Borderline-SMOTE),试验表明该方法可获得更好的Recall和F-measure。He等[11]提出了一种新的自适应合成过采样方法(ADASYN)。ADASYN的基本思想是根据不同的少数类样本的学习难度,对它们进行加权分配。与那些较容易学习的少数类样本相比,较难学习的少数类样本生成的合成数据更多。ADASYN自适应地将分类决策边界移向困难样本改善了数据分布从而减少由类不平衡引起的偏差。Barua等[12]提出了一种称为多数加权少数过采样技术(MWMOTE)的新方法,用于有效处理不平衡学习问题。MWMOTE首先识别难以学习且信息丰富的少数类样本,并根据它们与最近的多数类样本之间的欧氏距离来分配权重。然后,它使用聚类方法从加权的信息丰富的少数类样本中生成合成样本。这样做的结果是,所有生成的样本都位于少数类集群中。Yun等[13]提出了一种称为自动邻域大小确定的过采样方法(AND-SMOTE)。这种方法限制了SMOTE中邻域的大小,以保持数据的原始分布,并有助于SMOTE发挥最佳性能。定义和检查包括少数类样本及其领域在内的样本可确保生成合成样本的安全性。通过独立生成具有自动预定义k值的合成少数类样本,可实现更好地分类。Douzas等[14]提出了一种简单有效的基于k均值聚类的过采样方法(K-means-SMOTE)。这种方法避免了噪声的产生并有效地克服了类之间和类内部地不平衡。Bennin等[15]提出了一种基于遗传染色体理论的和针对软件缺陷数据集的新颖有效的合成过采样方法(MAHAKIL)。利用此理论,MAHAKIL将两个不同的子类解释为父级,并生成一个新样本,这样本继承了每个父级的不同特征并有助于数据分布内的多样性。Gong等[16]提出了一种基于群集的带噪声过滤的过采样方法(KMFOS)。KMFOS首先将缺陷样本划分为k个群集,然后通过在每两个群集的样本之间进行插值来生成新的缺陷样本。最后,通过最近列表噪声识别(Closest list noise identification,CLNI)来清理噪声样本。Kiran[17]提出了一种新颖的类不平衡减少算法(CIR),通过考虑数据集的分布特性来创建不平衡数据集中缺陷样本和非缺陷样本之间的对称性。
总而言之,最近有很多过采样技术旨在缓解不平衡的数据集。SMOTE及其变体(含ADASYN和KMFOS)都需要设置公共参数k(少数类最近邻的数量),根据k确定候选区域来生成合成样本。但是由参数k生成的合成样本可能位于不适当的区域,这些区域会降低模型的预测性能。且参数k的设置也并非那么容易,需要不断地测试来获取相对最佳的效果。其次,在实际应用中,少数类样本的分布是不均匀的。因此,新生成的样本将仍然遵循原始样本的分布。虽然合成的样本在数量上平衡了两类数据,但本质上并没有对数据的分布改善多少。这些缺点使得SMOTE及其变体的应用变得复杂化。CIR只是简单计算缺陷类样本所有属性的质心以合成新样本,该方法过于简单且没有好的理论依据。MAHAKIL同样也有一些局限之处:首先,该方法只能识别小型的集群数据,对庞大而复杂的数据集群识别效果不佳;其次,该方法需要花费较高的代价计算马氏距离,并且对于特征数较少的数据集,无法对协方差矩阵求逆,这会严重影响算法后面的计算结果。
针对以上不足之处,本文提出了一种新颖的基于生成式对抗网络(Generative adversarial networks,GAN)[18,19]的过采样方法来解决软件缺陷预测中的类不平衡问题。这方法充分考虑了样本的空间分布信息,可以生成更加合理且多样化的样本。不仅可以提高缺陷样本的识别率,且降低了对非缺陷样本的误分类率。为了说明方法的有效性,本文进行了充分的试验,与6种常见的过采样方法:ROS、SMOTE,Borderline-SMOTE、MWMOTE、ADASYN和MAHAKIL以及未使用过采样的方法进行性能比较,使用了来自NASA、AEEEM、ReLink、SOFTLAB和PROMISE数据仓库的26个不平衡缺陷数据集,并考虑了8种分类算法在重新采样的数据集上进行评估。试验结果表明,本方法在Precision、Recall、F-measure和G-mean上都得到了明显的提升。
1 本文方法
1.1 概述
要构建缺陷预测模型,第一步是从软件仓库中创建数据样本,例如版本控制系统、问题跟踪系统等。根据样本是否包含缺陷,可以将样本标记为有缺陷或无缺陷。然后,基于获得的度量和标签,通过使用一组训练样本来构建缺陷预测模型。最后,预测模型可以对新测试样本是否有缺陷进行分类。方法整体框架建构如图1所示。
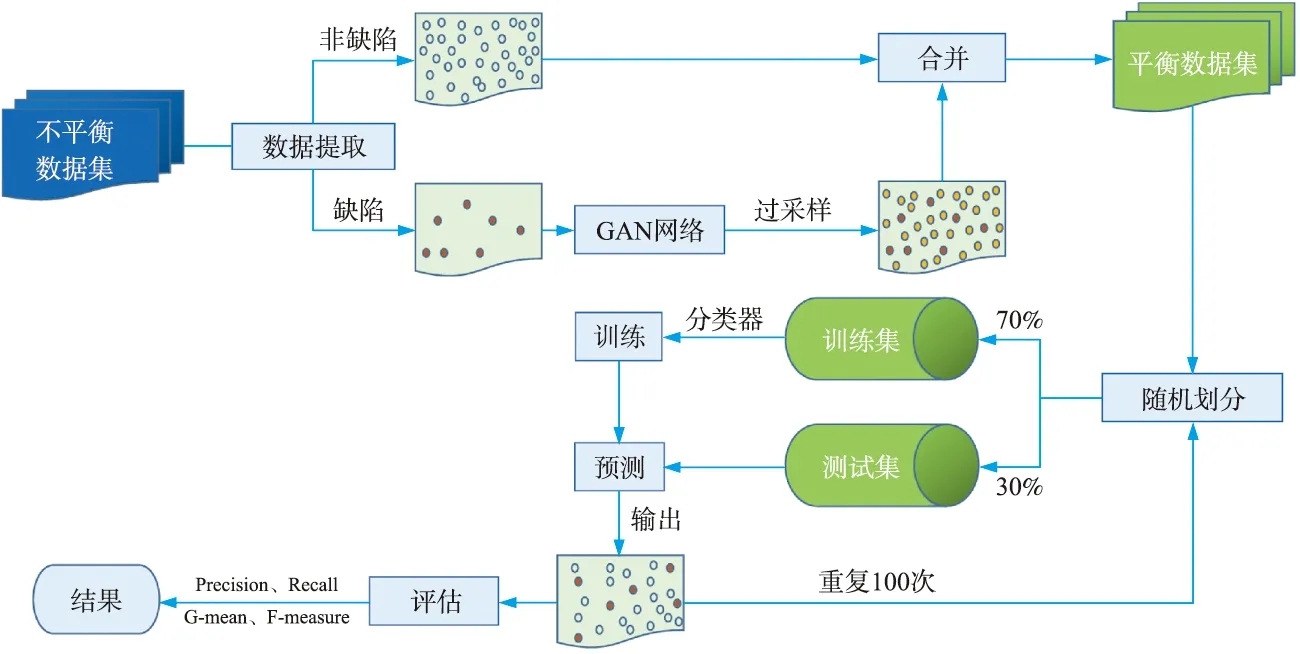
图1 方法整体框架图
针对上文提到的合成过采样方法的不足之处,本文受GAN网络能够生成多样化的图片而启发,这方法符合生成特定数据样本的目标。通过将有缺陷的样本输入到GAN网络中,可以得到期待的类似缺陷类样本的合成样本。GAN网络生成器会将随机变量与真实的缺陷样本进行比对,使随机变量朝着真实缺陷样本的分布进行过度。通过判别器和生成器之间交替优化的方式,使得生成的合成样本与真实的缺陷样本分布类似。这些合成样本虽然是根据缺陷类样本而生成,但又有各自的独特之处,并不是所涉及的缺陷样本的直接副本。此外,GAN在生成合成样本的时候,充分参考了所有缺陷样本的信息,这样生成的样本会更加的多样化。总之,利用GAN不仅能平衡缺陷预测中两类数据的分布,而且可以使数据地分布更加多样化。本方法主要包括两个步骤:数据提取和生成合成样本。下面详细描述这两个过程。

表1 用于解决软件缺陷预测中类不平衡问题的GAN网络过采样算法
1.2 数据提取
假设不平衡缺陷数据集DS={s1,s2,s3,…,si,…,sn}(1≤i≤n,DS已归一化),其中si表示项目中的第i个记录,即第i个样本。每个si包含m个属性,其中每个属性是软件代码分析的相关度量,例如代码行数、Halstead科学度量和McCabe循环复杂度等[2],最后外加一个类标签属性。类标签的值代表该模块中出现的错误数,其中零值表示是一个非缺陷的模块,非零值表示是一个有缺陷的模块。由于软件缺陷预测属于二分类问题,需要将所有类标签值改为0或1,因此通过预处理,将类标签中所有大于1的值改为1。
根据类标签的值,可以把数据集划分为两类:标签值为0的是非缺陷类,标签值为1的是缺陷类。由于软件缺陷预测中一般缺陷类总是少于非缺陷类,因此缺陷类是少数类,非缺陷类是多数类。其次,统计出少数类和多数类的样本个数,分别用N-和N+表示。故待生成的缺陷类样本个数为N=N+-N-。与此同时需要统计出数据集DS中属性的维度(除类标签值属性),用Dim表示。将DS、N和Dim送入GAN网络中进行训练,最终生成缺陷类合成样本。
1.3 生成合成样本
数据提取完成之后,利用GAN网络可以生成缺陷类样本。GAN生成合成样本的具体过程如下:GAN包含生成器G和判别器D两个部分,生成器和判别器都采用神经网络。对于生成器,它的输入为一个随机变量z,经过几次线性变换和激活函数之后,将其映射到跟缺陷类样本属性维度(即Dim)同样大小的特征空间中,最后经过sigmoid激活函数使生成的假样本数据分布能够在0~1之间。关于判别器,它的输入可能是真实的缺陷数据x,也有可能是生成器生成的尽量服从缺陷类数据分布的样本G(z),通过多层感知器和激活函数,最后接sigmoid激活函数得到一个0~1之间的概率进行二分类。D的目标是实现对数据来源的二分类判别:真(来源于真实缺陷数据x的分布)或者伪(来源于生成器的伪数据G(z))。假如输入的是真实缺陷样本,网络输出就接近1,输入的是假样本,网络输出接近0。而G的目标是使自己生成的伪数据G(z)在D上的表现D(G(z))和真实缺陷数据x在D上的表现D(x)一致。GAN网络判别器训练过程如图2所示。

图2 GAN网络判别器训练过程
在训练判别器时,先固定生成器G;然后利用生成器随机模拟产生样本G(z)作为负样本,并从真实缺陷数据集中采样获得正样本x;将这些正负样本输入到判别器D中,根据判别器的输出(即D(x)或D(G(z)))和样本标签来计算误差;最后利用误差反向传播算法来更新判别器D的参数。在训练生成器时,先固定判别器D;然后利用当前生成器G随机模拟产生样本G(z),并输入到判别器D中;根据判别器的输出D(G(z))和样本标签来计算误差,最后利用误差反向传播算法来更新生成器G的参数。
2 试验方法
如上所述,本文研究的主要目标是使用新提出的过采样方法来提高在不平衡数据集上训练的缺陷预测模型的性能。将本方法与没有进行过采样的方法(NONE)以及一些经典的过采样方法进行全面的比较。下面,描述用于研究的数据集,试验的相关设置以及一些用于评估模型性能的指标。
2.1 数据集
为了验证本研究对软件缺陷预测中不平衡数据集的影响,对来自PROMISE、NASA、AEEEM,ReLink和SOFTLAB数据仓库的26个项目进行了试验[2]。表2详细列出了试验中使用的数据集的相关信息。其中缺陷率=缺陷样本个数/样本总数*100%,不平衡率=(样本总数-缺陷样本个数)/缺陷样本个数。
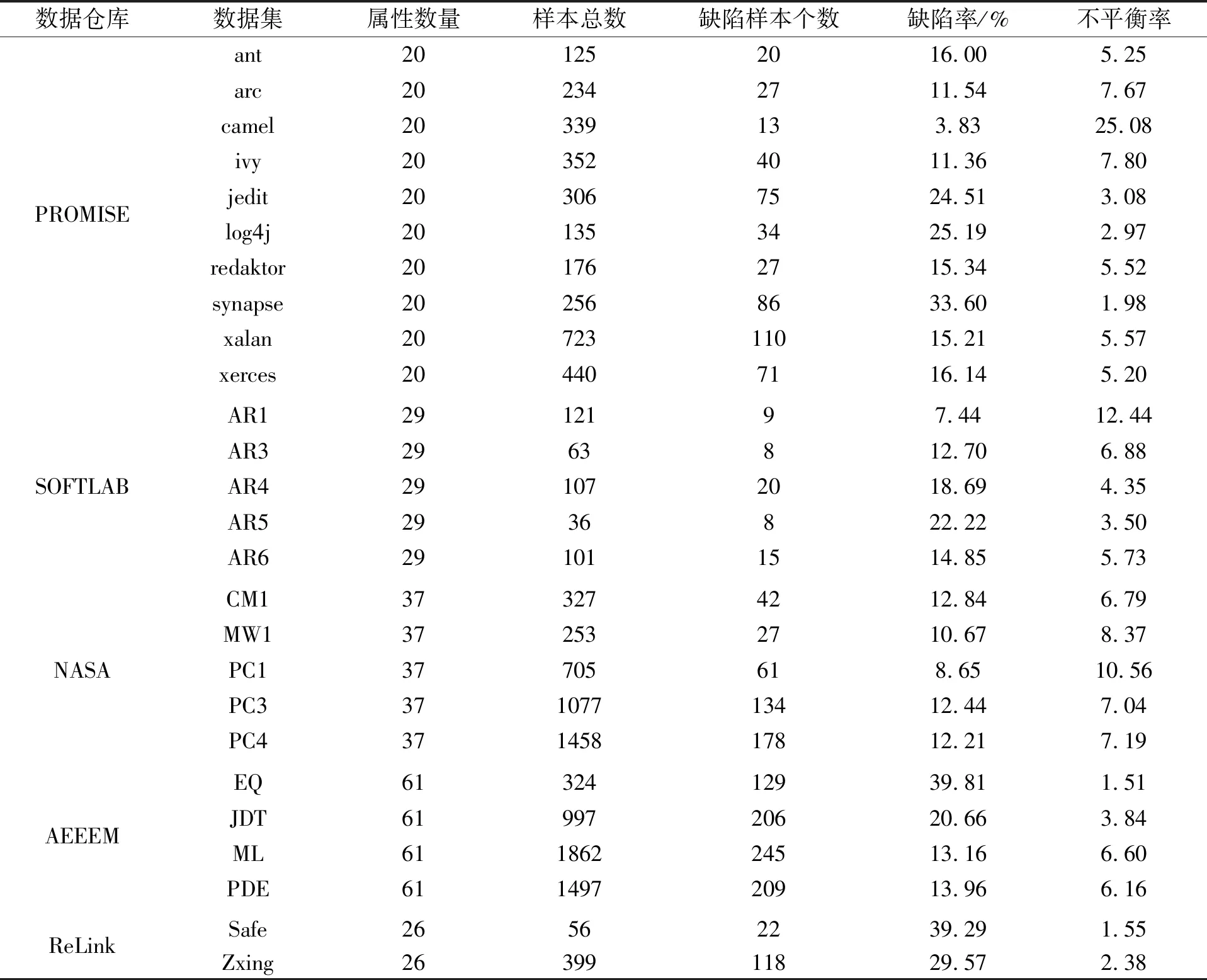
表2 从5个数据仓库中提取的26个不平衡数据集的简单统计
从表2可知:(1)试验所用的数据集分布广泛,来自于5个不同的数据仓库,不同数据仓库中数据集的属性个数都不同,因此可以验证本研究在不同数据集上的表现效果,使得试验更具代表性。(2)每个数据集中包含的样本个数都不相同,且数量差异较大。最少的有35个样本,而最多的达到1 862个,这也间接说明试验所使用的数据集的多样性。(3)数据集中的缺陷样本个数都很少,其中缺陷最严重的是camel数据集,其缺陷率达到了3.83%,缺陷最少的数据集也有39.81%。数据集中的缺陷率都低于40%,其中绝大部分都低于20%,这表明试验所使用的数据集满足类不平衡问题的需求。(4)数据集中的不平衡率都远大于1,表明数据集中的非缺陷样本个数远多于缺陷样本。其中大部分数据集的不平衡率都超过了5,表明数据集中的缺陷样本个数只有不足2成,这为研究软件缺陷预测中类不平衡问题的有效性提供了方便。
2.2 试验设置
为了试验的公平性,本文在8个分类器上进行了试验,分别是AdaBoost(AB)、Decision Tree(DT)、Extra Tree(ET)、Gradient Boosting(GB)、Logistic Regression(LR)、Naive Bayes(NB)、Random Forest(RF)和Support Vector Machines(SVM)。试验中随机选择70%的数据集作为训练集,剩下30%作为测试集。为了减少随机挑选数据对试验结果造成的偏差,本文在每个分类器上都进行了100次试验,最后统计100次的均值作为试验的结果。试验中使用的生成器为Linear(z,256)-ReLU()-Linear(256,256)-ReLU()-Linear(256,Dim)-Sigmoid(),判别器为Linear(Dim,256)-LeakyReLU(0.2)-Linear(256,256)-LeakyReLU(0.2)-Linear(256,1)-Sigmoid(),随机向量维度为32,batch size为32,学习率为0.000 3,迭代次数为1 000。
通过采用控制变量法,本文确定了试验中各参数的相对最优取值。在随机向量维度上,分别选取了4、8、16、32、64、128、256和512进行试验。试验结果表明,随机向量维度在取值32时结果最好。同样,对于batch size分别选取了1、2、4、8、16、32、64和128,当取值32时效果最佳。本文对学习率分别从0.000 1~0.001每隔0.000 1进行测试,发现取值0.000 3时模型性能最优。至于迭代次数选取1 000是为了保证模型训练趋于稳定并得到一个最优的结果。试验中使用的GAN网络框架涉及的内部参数与默认的一致。
2.3 评估指标
在充分了解和比较各种评估指标的优劣之后,本文选择Precision、Recall、F-measure和G-mean作为本次试验的评估指标。Precision即精确率或查准率,它表示正确分类为缺陷的缺陷样本数与分类为缺陷的样本数之比;Recall即召回率或真实阳性率,它表示正确分类为缺陷的缺陷样本数与缺陷样本总数之比。该指标对于缺陷预测非常重要,因为预测模型旨在尽可能多地发现缺陷实例;F-measure是Precision和Recall的谐波平均值的综合度量;G-mean与F-measure类似,它是Recall和1-Pf(误分类率)的谐波平均值,在数据不平衡的时候,该指标很有参考价值。在此,真阳性(TP)、假阴性(FN)、假阳性(FP)和真阴性(TN)分别是被预测为有缺陷的缺陷样本的数量,被预测为无缺陷的缺陷样本的数量,被预测为有缺陷的无缺陷样本数和被预测为无缺陷的无缺陷样本数。具体公式如表3所示。
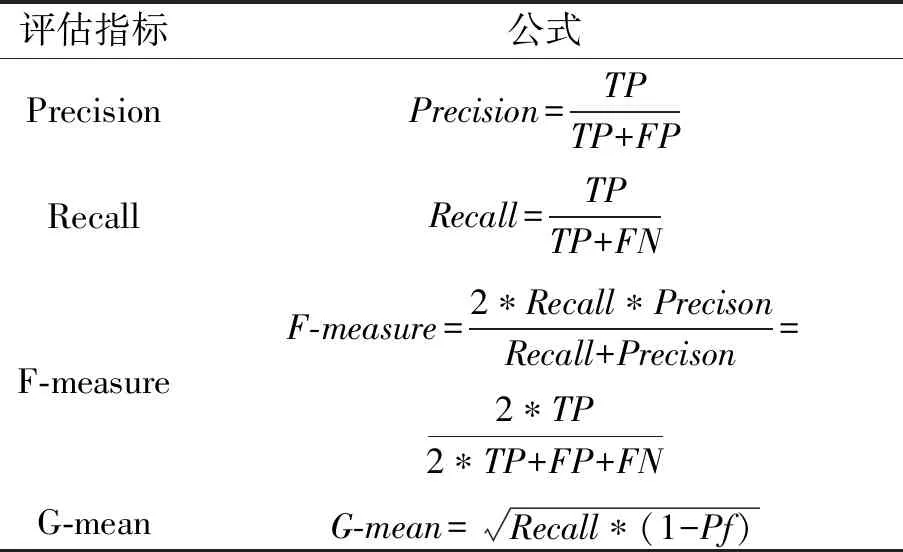
表3 试验所用评价指标
3 试验结果和分析
在26个不平衡数据集上用8种分类器对各种方法进行试验。在4个评估指标上进行全面地对比并得到了一些数据。最后用折线图来展示试验结果,图3~6分别是4个评估指标的折线图对比结果。图3~6分别是在26个不平衡数据集上针对不同评估指标在8个不同分类器上得到的平均值结果,其中横坐标表示数据集,纵坐标表示评估指标的值。从图中可以看出,本方法在4个评估指标上得到得结果都明显优于未进行采样的方法,这表明本方法在解决软件缺陷预测中的类不平衡问题上是有效果的。

图3 在26个不平衡数据集上对比各种方法在8个分类器上Precision均值的折线图
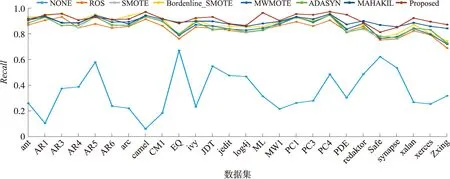
图4 在26个不平衡数据集上对比各种方法在8个分类器上Recall均值的折线图

图5 在26个不平衡数据集上对比各种方法在8个分类器上F-measure均值的折线图
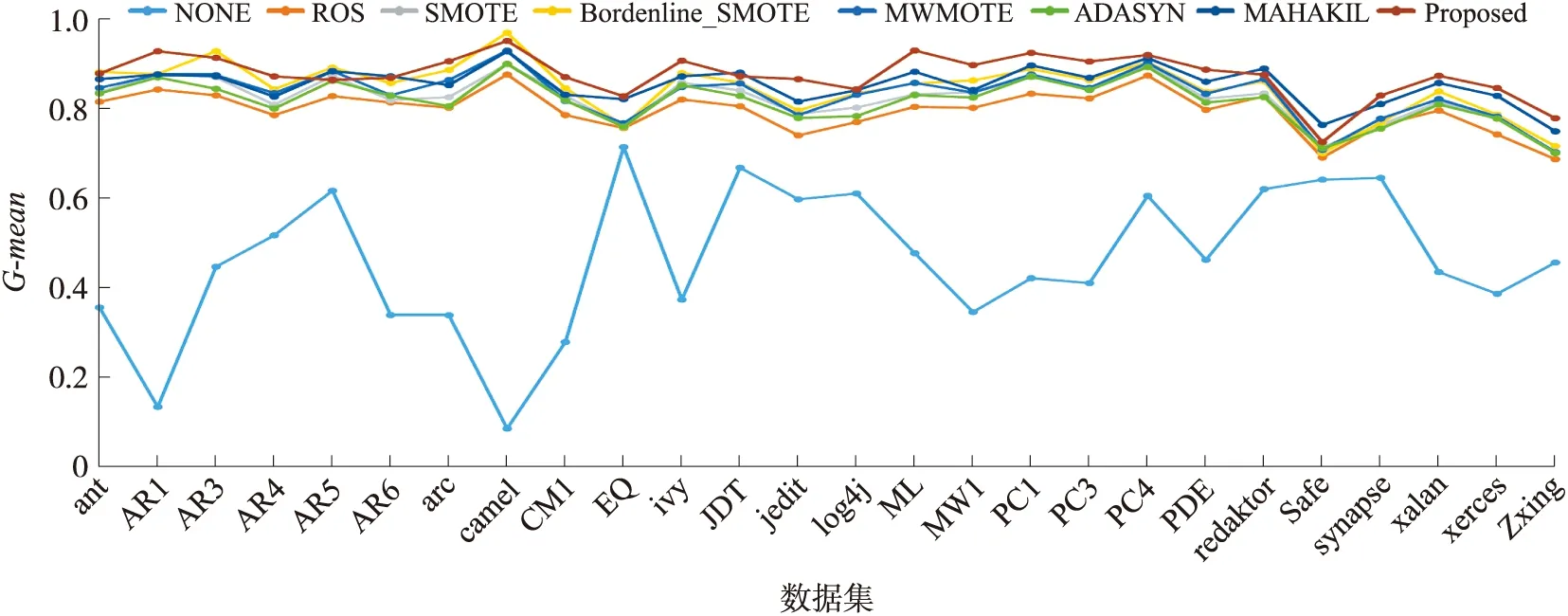
图6 在26个不平衡数据集上对比各种方法在8个分类器上G-mean均值的折线图
本方法在4个评估指标上的结果都在0.9左右,而未进行采样的结果绝大部分都在0.5以下。在大部分数据集上未进行采样的方法不及本方法的1/2,甚至在某些数据集上不足本方法的1/3。这表明本方法不仅能解决类不平衡问题,而且在处理类不平衡问题时表现良好。
在4个评估指标上的绝大部分数据集上本方法都比其他过采样方法结果要好。其中,比表现结果最差的ROS在26个数据集上的平均值分别提高了9.82%、7.39%、6.90%和6.25%,比表现次好的MAHAKIL也分别提高了4.36%、1.83%、2.58%和2.76%。这表明本方法较经典的过采样方法在性能上又有所提升,能够更好地识别出缺陷样本且降低了对非缺陷样本的误分类率。本方法之所以表现得最好,可能的原因是:本文方法是基于GAN网络来生成缺少的缺陷类样本,GAN网络能充分考虑到样本的空间分布信息,通过生成网络和判别网络的反复交替优化,使得生成的样本更加丰富且多样化。此外,ROS只是简单的复制缺陷类样本;SMOTE及其变体都使用k近邻来创建新样本,这些新样本只是分布在一些较小的区域中;MAHAKIL考虑了样本多样化的问题,所以在这些经典的过采样方法中表现最好,但是其在各个分类器上的性能还是略逊于本方法,主要原因是MAHAKIL只适用于小型的数据集,对庞大而复杂的数据集识别效果不佳。试验中,使用的数据集中有部分数据集样本数和属性个数较多,因此,使得MAHAKIL方法的整体表现不如本方法。
此外,为了对本文方法进行统计评估并与其他6种过采样方法进行比较,使用Win/Tie/Loss进行评估。对所有方法中的Precision、Recall、F-measure和G-mean进行了Wilcoxon符号秩检验(p<0.05)。如果统计测试后本方法的性能优于对比的方法,则标记本方法为“Win”;反之,则标记为“Loss”。如果本方法与对比方法之间在统计学意义上没有显著性差异,则将此情况标记为“Tie”。然后,计算本方法Win、Tie和Loss的次数。通过使用Win/Tie/Loss评估,可以清晰直观地看出本方法与对比方法之间的优劣情况。
从表4可知,本方法与其他过采样方法在统计检验结果上有着明显的优势。其中在超过半数的对比方法上有多于20个数据集占据着优势。这表明本方法在提高缺陷样本识别率以及降低非缺陷样本的误分类率上比其他过采样方法做得更好。受篇幅所限,本文只展示G-mean的统计结果,在其他3个指标上可以得出同样的结论。

表4 将本方法与其他6个过采样方法在G-mean值上的统计检验结果
4 结束语
针对软件缺陷预测中的类不平衡问题,该文提出了一种新的方法来合成缺陷类样本。该方法使用GAN网络来生成缺少的缺陷类样本,GAN网络能够充分挖掘出样本分布的空间信息,通过生成器和判别器交替优化的方式使得生成的新样本更加合理科学。本文使用26个不平衡缺陷数据集在8种分类模型上与其他6种过采样方法以及未采样方法进行全面比较。经过上百次的试验,在Precision、Recall、F-measure和G-mean上进行测试。试验结果表明,本文方法是最优的。
在接下来的工作中,考虑将本方法应用到更多的数据集中,包括一些商业项目,来验证本方法的适用性。此外,还考虑在更多的预测模型中评估本方法的性能,并与更多的过采样方法进行比较。
