基于互邻信息的树型近邻分类方法
2023-05-24胡新平鞠恒荣黄嘉爽丁卫平
尹 涛,胡新平,鞠恒荣,黄嘉爽,丁卫平
(南通大学 信息科学技术学院,江苏 南通 216002)
作为一种经典的分类方法,k近邻(k-nearest neighbor,kNN)分类方法被广泛应用于机器学习,模式识别和信息检索等领域。因为算法实现简单,分类性能较好,目前k近邻分类算法主要应用于分类和回归问题[1-4]。例如,赵晋陵等[5]将高光谱图像空间信息转化为特征向量,通过k近邻分类器提高图像的分类性能。Han等[6]将k近邻与遗传算法(Genetic algorithm,GA)相结合,用于类星体的光度红移估计。张雯超等[7]优化k近邻分类中的欧式距离,构建Spearman-k近邻分类地铁深基坑地连墙变形的预测模型,提高预测精度。

另一方面,传统k近邻分类算法是一种单向判别方法。但该方法仅适用于数据均匀分布的场景。然而,在实际应用中,数据的分布往往是有差异的。在此情况下,对于测试样本k近邻中的样本而言,该测试样本并不一定被其认定为最近的k个样本之一[23]。kNN规则中单向判别策略在一定程度上导致最近邻样本中存在噪声数据,降低了k近邻分类算法的性能。k值代表样本辐射范围的大小,假设未分类样本x1的k值为3,样本x2,x3,x4都在样本x1的邻近区域中。然而对于样本x2,未分类样本x1不存在于样本x2的邻近区域。x2是未分类样本x1的k近邻样本,x1却不是x2的k近邻样本。因此样本x1和x2的关系是单向的,这种联系缺乏可靠性,导致无关数据x2干扰分类结果。为了解决这个问题,Denoeux等[23-24]将D-S证据理论应用于k近邻分类,根据k个邻近样本证据信息预测样本类别。Pan等[25]提出了一种基于双边模式的k近邻分类方法。这种双边模式下的k近邻方法通过扩大邻域范围,提升分类准确率。但在一些情况下,同样会囊括部分噪声数据,造成分类性能的下降。
为了解决上述问题,本文借鉴前人的工作,提出了基于三阶段的k近邻分类方法。首先,在第一阶段通过LASSO模型获取每个样本的最优k值,构造kTree模型,提升待分类样本搜索最优k值的速度。其次,在第二阶段,采用双向策略,排除噪声数据的干扰,确定待分类样本的近邻空间。最后,采用投票策略完成分类任务。
1 基础知识介绍
k近邻分类的主要思想:一个样本与其邻近区域中的k个样本相似度最高,假设这k个样本中的多数数据属于某一个类别,则该样本也属于此类别。一般地,决策信息系统可定义为S=〈U,AT∪D〉,其中U代表所有样本的集合。AT为条件属性集,D为决策属性集合。依据决策信息系统,可定义样本的k个邻居如下所示:
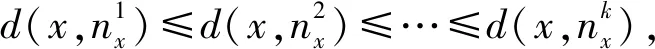
(1)
式中:d(xi,xj)为样本xi与样本xj的距离函数,且满足如下性质:
(1)d(xi,xj)≥0;
(2)d(xi,xj)=0,如果xi=xj;
(3)d(xi,xj)=d(xj,xi);
欧氏距离是一种机器学习中常用的距离计算方法,对于样本xi与样本xj之间的欧氏距离函数可定义为
(2)
根据欧氏距离,样本的k个最近邻居样本可以被计算获得。基于邻近样本的类别标签,可定义k近邻分类规则如下所示。
定义2在决策信息系统中,∀x∈U,样本xi的k个最近邻居表示为NK(xi)。w1,w2,…,wm为基于决策属性D的m个类别标签。NK(xi)对应的样本标签可表示为
(3)
根据少数服从多数投票原则,样本x的类别标签wx可定义为
(4)
式中:I(x)为指示函数,x为真时取值为1,否则取值为0。k近邻分类算法主要内容如下所示。

算法1k近邻分类算法
输入:训练样本集(X1,X2,…,Xn),训练样本的类别标签(C1,C2,…,Cn),测试样本Y,测试样本的k值。
输出:测试样本的预测标签L。
①计算测试样本Y与训练样本集(X1,X2,…,Xn)之间的距离(D1,D2,…,Dn);
②根据距离(D1,D2,…,Dn)的递增关系完成排序;
③选取距离最小的k个样本(X1,X2,…,Xk)以及对应的类别标签(C1,C2,…,Ck);
④计算k个样本所属类别的出现频率;
⑤返回k个样本出现频率最高的类别作为测试样本Y的预测标签L。
算法1的时间复杂度为O(n),具有简单高效的优点。
2 主要方法
2.1 k值获取
在k近邻分类器中,k值的选择影响分类性能优劣。在众多研究中,k值的选择一般基于样本的总个数,往往忽略样本之间的联系。对于k近邻分类算法,距离更近的样本被认为联系更加紧密。所以通过距离寻找最近邻样本,同样是寻找关系更加紧密的样本,因此与测试样本关系紧密的样本数量是k值的直观体现。在本文中,笔者鉴于Zhang等的kTree模型,采用LASSO模型[20-22]刻画样本之间的紧密程度。首先,应用留一法将一个训练样本单独列出,通过LASSO模型与其他训练样本重构此独立样本,得到独立样本的重构权重向量。以此类推,依据整个训练样本的重构权重向量,组成重构权重矩阵。根据权重矩阵W与相关性阈值δ,可以获得与样本相关性较高的样本数量,即为该样本的k值。LASSO模型[20-22]定义如下所示:
定义3X为训练样本,Y为测试样本,W为训练样本重构权重矩阵。通过训练样本重构测试样本的目标函数如下所示
(5)


在这个例子中,训练样本的个数为5,权重矩阵W∈R4×5,相关性阈值为0.1。权重矩阵W的第一列数据显示第一个训练样本与其他训练样本的相关性大小。根据相关性阈值,得到第一个训练样本的k值为3,第二个训练样本的k值为3,以此类推,可以获得所有样本的k值。
2.2 kTree模型的构建
在获得样本的有效k值之后,通过这些k值,构造kTree的学习模型,学习测试样本的有效k值。由上文可知,训练样本的有效k值通过LASSO模型获取。在本文中,采用留一法,获得训练样本中其它样本对该样本的紧密程度。以此类推,整个训练样本的k值可以计算得到。笔者鉴于Zhang等的kTree模型,根据训练样本和对应的k值,以k值为叶子节点,构建kTree[19]。kTree的每一个叶子节点都存在一个有效k值。在测试阶段,从kTree的根节点到叶子节点,遍历整个树,赋予测试样本最优k值。通过kTree学习获取的k值,有效的体现自身的辐射范围。kTree的流程如图1所示。
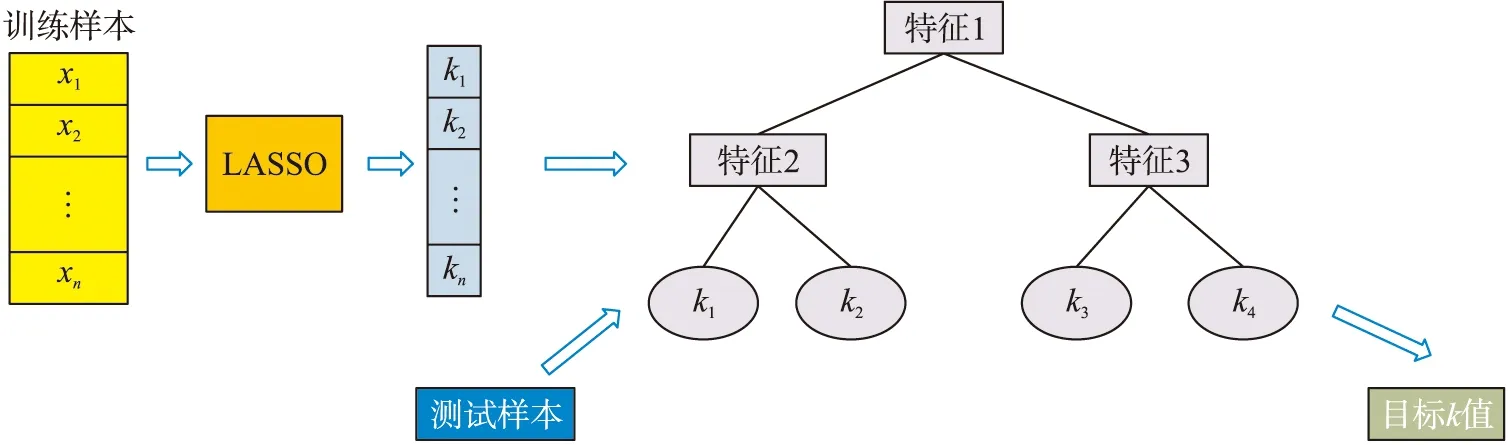
图1 kTree的构建
kTree算法的时间消耗主要体现在训练样本的k值获取。通过LASSO模型得到训练样本之间的紧密程度,其主要时间复杂度为O(n2),kTree的构建主要的时间消耗为O(logn)。总的来说,算法的时间复杂度为O(n2)。
2.3 MIkTree模型的构建
k近邻分类算法主要依据与之距离最近的k个样本,预测样本的类别。然而,同样存在一些问题。在k近邻分类过程中,假设一个样本a被选为样本b的k个最近邻之一,表示样本a在样本b的邻近范围之内。但并不意味着样本b一定存在于样本a的邻近范围之内,意味着样本a可能成为样本b的无关数据。同时,引出一个常见的问题,k近邻分类的k个样本的选择往往只考虑样本之间单向的联系,而双方之间联系没有被考虑,这也会导致样本预测准确率的下降。
为了解决这个问题,Pan等[25]提出了一种基于双边的一般最近邻算法。训练样本与测试样本的共同邻域信息被称为互邻信息[25]。假设训练样本x1属于测试样本y1的k个最近邻之一,或者测试样本y1属于训练样本x1的k个最近邻之一,那么x1为测试样本y1的k个一般最近邻之一。为了提高k近邻分类的分类性能,本文提出了一种基于双向策略的k近邻分类算法。
本文提出的MIkTree分类方法利用训练样本与测试样本互邻信息的重叠区域判断样本是否为测试样本的可靠最近邻样本。对于待分类样本x,如果样本y满足式(6),则可被视为可靠样本。样本x,y之间的关系是可靠的,可以有力地支持样本的正确分类。
x∈NKy(y)∩y∈NKx(x)
(6)
对于这些可靠的样本,通过最大投票策略,可以预测出样本的类别,提升了样本的分类性能。具体的算法步骤如算法2所示。
算法2MIkTree分类算法
输入:训练样本集(X1,X2,…,Xn),训练样本的类别标签(C1,C2,…,Cn),测试样本Y。
输出:测试样本的预测标签L。
①根据LASSO模型与kTree模型分别获得训练样本集和测试样本Y对应的k值;
②将测试样本Y加入训练样本集(X1,X2,…,Xn)中,新的训练集表示为TS′;
③选取距离最小的k个样本(X1,X2,…,Xk)以及对应的类别标签(C1,C2,…,Ck);
④根据式(1),得到TS′中每个样本的k个最近邻居NK(x);
⑤在训练集TS′,对于任意样本Xi,Y(1≤i≤n)如果满足式(6),则将Xi加入到集合MIkTree(Y);
⑥返回集合MIkTree(Y)中出现频率最高的类别作为测试样本Y的预测标签L。
算法2的时间复杂度主要体现在步骤1中对于样本k值的获取,主要的时间消耗为O(n2),步骤2的时间复杂度为O(n)。所以,算法2的时间复杂度为O(n2)。
3 试验分析
为了验证本文提出的MIkTree分类算法的有效性,本文从美国加州大学Irvine分校机器学习测试数据库中选取了9组数据集对本文所提出的算法的分类性能进行测试[26]。试验数据集的具体信息如表1所示。
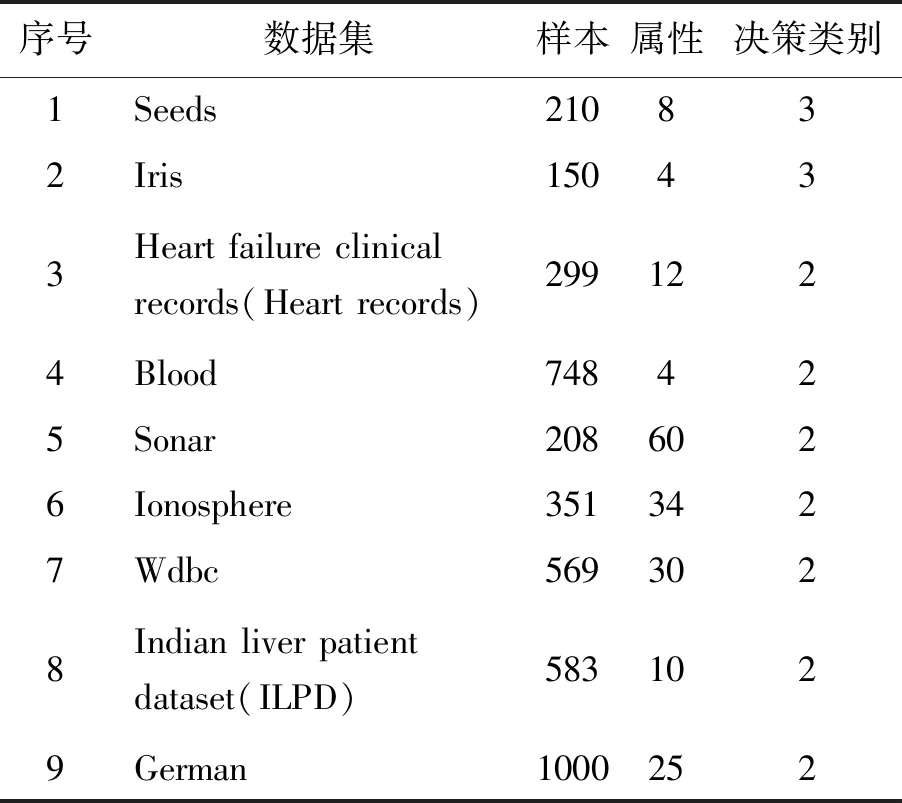
表1 UCI数据集
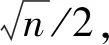
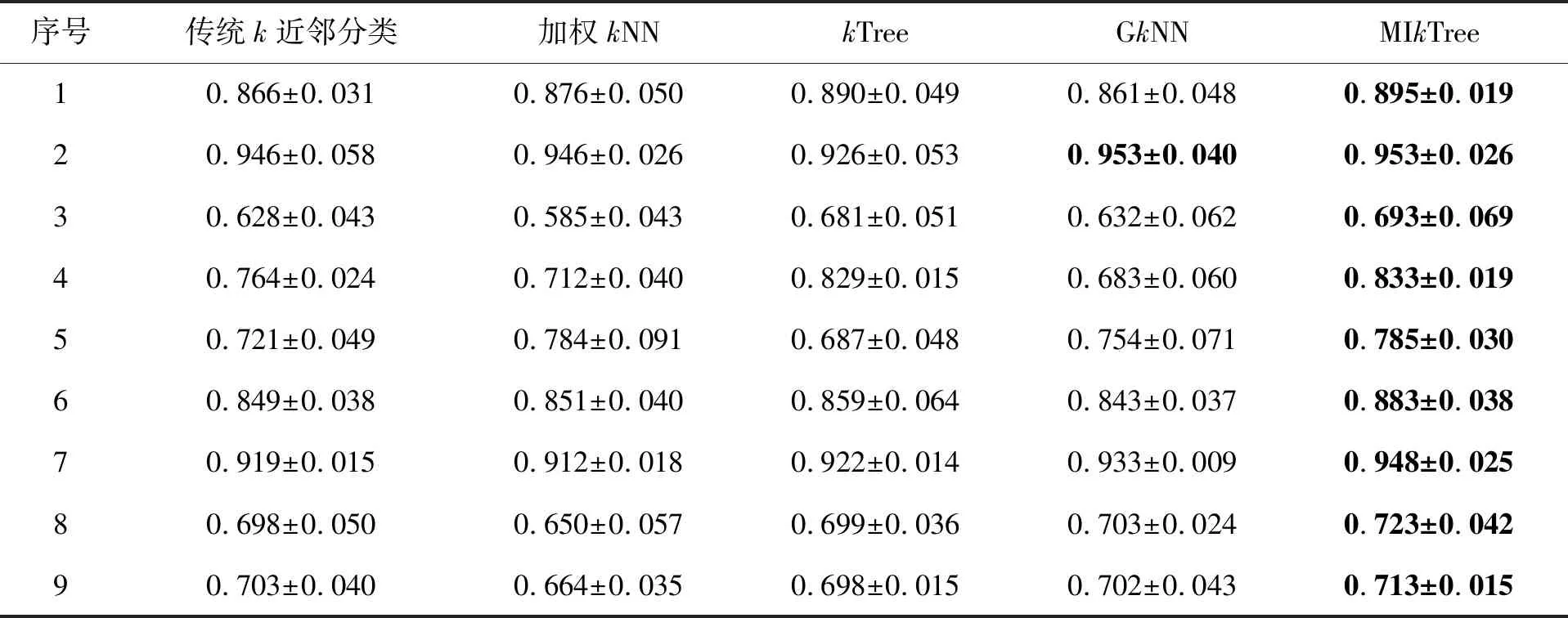
表2 与其他常用算法的分类对比
此外,本文在9个UCI数据集上完成基于不同样本大小的分类任务。图2给出了5种分类方法在不同数据量下的分类精度(即5次交叉验证的平均分类精度),其中横坐标为样本量,纵坐标为分类精度。在图2中,第一个矩形代表传统k近邻分类算法,第二个矩形代表加权k近邻分类算法,第三个矩形代表GkNN分类算法,第四个矩形代表kTree算法,最后一个矩形表示本文提出的MIkTree分类算法。由图2可知,在不同样本维度下,本文提出的方法MIkTree分类算法在所有数据集中拥有较高的分类精度。例如,对于图2的第7个数据集Wdbc,无论样本的规模如何变化,MIkTree分类算法的分类准确率约为0.95,k近邻分类的分类正确率约为0.93,加权k近邻分类和GkNN分类的分类准确率约为0.92,kTree算法的分类准确率小于0.93。MIkTree分类获取的分类精度高于其他对比算法,表明MIkTree分类算法能够有效提升分类的性能。
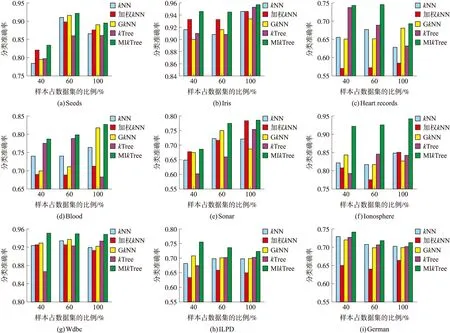
图2 基于不同样本维度的分类准确率
4 结论
为了提升k近邻分类算法的效果,本文提出了一种基于互邻信息的kTree分类方法。首先,本文通过LASSO模型获得样本之间权重关系,获取训练样本的k值,通过构建kTree,训练测试样本,获得测试样本的k值。与传统k近邻分类相比,k值的获取更加准确合理。其次,不同于传统k近邻分类单向选择k个最近邻样本。本文通过考虑二者之间的相互关系,剔除最近邻中存在的无关数据。试验结果证明,本文提出的方法能够有效的提升k近邻分类的分类性能。在接下来的工作,笔者尝试从以下两个方向继续k近邻分类的提升:
(1)对于样本之间紧密程度的刻画,训练样本重构的目标函数应该进一步优化。
(2)对于k近邻分类算法的提升,D-S证据理论应该尝试融入本文提出的k近邻分类方法。
