数据驱动下基于量子人工蜂群的K均值聚类算法优化
2023-05-24周湘贞
周湘贞,李 帅,隋 栋
(1.郑州升达经贸管理学院 信息工程学院,河南 郑州 451191;2.北京航空航天大学 计算机学院,北京 100191;3.北京建筑大学 电气与信息工程学院,北京 102406)
大数据驱动多个行业深度发展,通过大数据进行有效挖掘及深度分析成为近年来研究的热点。由于大数据具有特征量大、维度高及关联性强等特点[1],仅靠人工统计的方式对其进行数据分析存在效率较低的问题,而聚类作为一种机器学习工具,在数据分析中应用前景广阔。由于各行业聚类需求差异明显,对聚类性能要求不一,聚类准确率、聚类效率及稳定性等要求彼此制约,在选择聚类算法时,常需要结合实际需求来定。K均值聚类作为常用聚类算法,其应用场景非常广泛。但是为了提高其在不同聚类需求中的适用度,常需要对K均值进行优化。由于随机设置的聚类中心不容易获得较高的聚类性能,因此常需要针对该不足进行深度优化,如用深度学习算法或者仿生算法实现自动确立中心的策略,来实现有针对性的优化。
当前,关于K均值算法的改进策略研究较多,贺思云等[2]分析了粗糙K均值聚类算法的不足,并采用人工蜂群进行聚类中心优化,以增强粗糙K均值聚类的Silhouette性能。郭婧等[3]将K均值用于大数据挖掘,并采用菌群优化(Bacterial foraging optimization,BFO)算法对聚类中心进行优化,有效提高了K均值的分类精度。可以看出,上述两个研究为了提高K均值算法在不同需求下的聚类适应度,都采用仿生算法对其初始聚类中心进行优化,取得了较高聚类性能,但仍有较大提升空间。
近期,量子计算由于其强大的并行计算能力被应用于各种算法优化领域。将量子计算引入到状态转移概率计算中可以有效避免群体智能优化算法易陷入局部最优解,并同时提高收敛速度。早期被提出的量子粒子群算法用量子位的概率幅对粒子位置编码,提高了收敛速度和寻优精度。量子人工蜂群(Quantum artificial bee colony,QABC)作为其后续版本,均采用量子编码思路,但是相比于前者能有效避免早熟收敛问题。因此,本文采用人工蜂群对K均值进行改进,并对蜂群位置进行量子表示,以减小搜索粒度,提高了聚类中心的搜索精度,基于QABC改进的K均值算法具有更优的聚类性能。
1 K均值聚类简介
K均值聚类首先需要根据聚类类别数设定合适的聚类中心,假设第i个中心为xi,其他样本点与xi的距离[4]为
(1)
设所有样本点的维度为n,那么xi可写成(xi1,xi2,xi3,…,xin),非中心点xj可写成 (xj1,xj2,xj3,…,xjn),xi与xj的距离[5]为
(2)
采用式(2)逐个计算样本点与各个中心点的距离,并对距离采用升序排列,根据距离最小值来判定该样本点所属类别。在实际训练时,由于聚类中心可以不断变化,因此一般是求解样本点与所有中心点的距离集合,求解方法为
(3)
xj∈N(xi)表示N个样本点中除了xi的其他点,且有∑j,xj∈N(xi)Sijxj=1,Sij≥0。
将式(3)化简得
(4)
优化函数[6]为
minε
(5)
由以上公式知,在K均值聚类过程中,算法的复杂度与样本点维度有极大关系,同时初始中心点的选择也非常关键,常见的K均值改进主要从这两点出发进行K均值的优化。
2 量子人工蜂群的初始聚类中心优化
在对K均值进行改进时,本文选择了初始聚类中心优化,考虑采用量子人工蜂群进行初始聚类中心优化求解,下面给出ABC算法计算过程。
2.1 人工蜂群算法
人工蜂群(Artificial bee colony,ABC)算法旨在获得最优适应度蜜源,通过探测蜂进行规定运动边界的广度搜索,确定蜜源大致位置,然后采用跟随蜂进行细粒度搜索,获得最优蜜源。
设初始蜜源i,探测蜂的d维初始位置Xid是[7]
Xid=Ld+rand(0,1)(Ud-Ld)
(6)
式中:Ud为d维搜索边界上限,Ld为下限,d∈{1,2,…,D},D是总维度。探测蜂从Xid处执行蜜源搜索,其在设定范围内探测新蜜源Vid的方法为
Vid=Xid+φ(Xid-Xjd)
(7)
式中:j≠i,φ∈[-1,1],Xjd≠Xid且属于[Ld,Ud]范围内。
当获得新蜜源Vi(Vi=[Vi1,Vi2,…,Vid])后,调整适应度fi[8]
(8)
根据fi计算值,将Vi和Xi两者中较大的定义为新蜜源。
跟随蜂获得了探测蜂的信息后,在若SP个蜜源中根据pi选择其偏好蜜源,pi计算公式[9]为
(9)
当运行了trial代后,探测蜂根据式(10)选择下一步执行策略[10]
(10)
式中:Itrmax是最大迭代次数。
由于探测蜂在运动时,其精度对rand(0,1)(Ud-Ld)的依赖程度高。因此对蜜蜂位置进行量子表示,能够实现更细粒度的搜索,从而获得更优质量的蜜源。
2.2 量子优化
量子表示方法[11]
|φ〉=α|0〉+β|1〉
(11)
式中:|·〉表示狄拉克符号,α和β表示常量,|α|2+|β|2=1,|α|2表示量子为“0”的概率,而|β|2表示量子为“1”的概率。
将上式用矩阵[12]表示
|φ〉=[α,β]T
(12)
令α=cos(θ),β=sin(θ),则式(11)可写为
|φ〉=cos(θ)|0〉+sin(θ)|1〉=
[cos(θ),sin(θ)]T
(13)
采用矩阵方式对蜜蜂个体位置编码
(14)
式中:θij=2π·Rand(),Rand()∈(0,1),i∈{1,2,…,n},j∈{1,2,…,m},n是蜂群规模,m是位置维度。将式(14)化简得
(15)
设θ是[α,β]T在|0〉=[1,0]T方向上的相位,则式(14)变为[13]
(16)
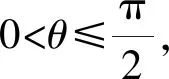
2.3 基于QABC优化的K均值聚类流程
在执行QABC+K均值聚类算法时,首先获得待聚类的样本并进行初始化,同时初始化聚类适应度函数。接着,随机设置类别中心坐标,并采用QABC进行聚类中心优化,通过蜜源运动确定最优中心坐标。
在进行QABC对聚类中心进行优化时,有两个关键因素(蜂群规模和搜索边界)需要考虑。在实际操作时,蜂群规模和搜索边界可以差异化设置,验证不同参数条件下的K均值性能,从而获得更优的QABC参数,以进一步提升QABC对聚类中心的优化程度。
最后,采用QABC获得初始聚类中心来进行K均值聚类,输入待聚类样本,按照式(1)~(5)执行聚类操作,输出聚类类别,具体如图1所示。

图1 基于QABC+K均值的聚类流程
3 实例仿真
为了验证QABC+K均值算法聚类性能,从多种角度对其不同指标进行仿真,仿真对象为UCI集,充分对比QABC+K均值算法对于不同复杂程度样本的聚类效果,选取了维度差异较大的六类样本,具体见表1。首先,采用QABC+K均值算法对六类样本集进行聚类仿真。其次,分别采用K均值算法、ABC+K均值算法及QABC+K均值算法对表1中的六类样本集进行仿真。最后,采用常用K均值改进聚类算法和QABC+K均值算法分别进行聚类仿真,验证不同算法聚类性能。
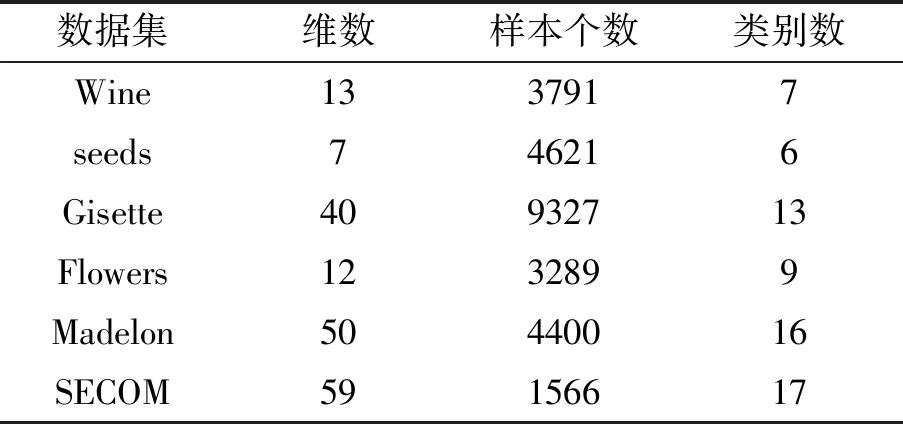
表1 仿真样本集
3.1 QABC+K均值的聚类性能
采用QABC+K均值算法对表1的六类样本集进行聚类仿真,聚类算法共执行训练100次,求解各种聚类性能的均值。
从表2知,QABC+K均值算法在Wine样本集的聚类准确率最高,均值为0.957 2,在SECOM的样本集聚类准确率最低,均值为0.863 5。对比发现,对于维数较高的样本集,QABC+K均值算法的聚类准确率均低于维数较低样本集。这说明样本集的维度对QABC+K均值算法的聚类准确率影响敏感。对比最大与最小值,它们与均值的偏移程度均较小。
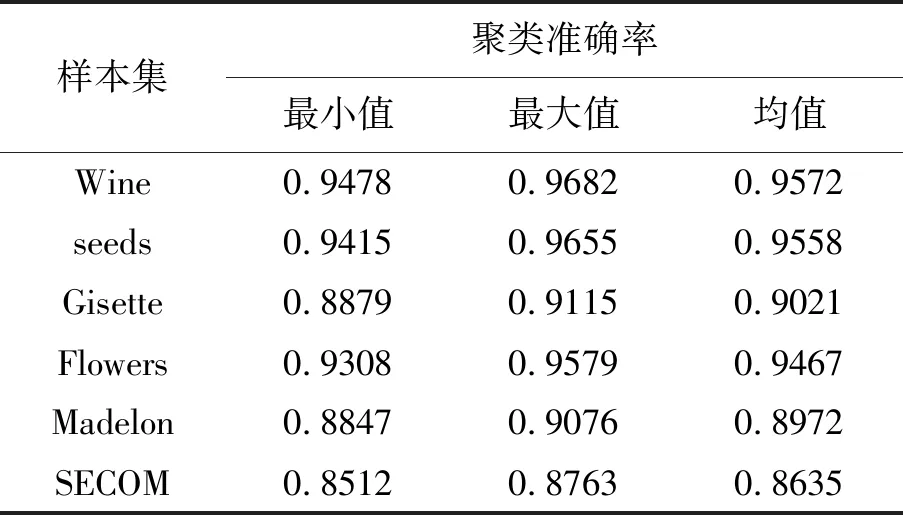
表2 QABC+K均值的聚类准确率
从表3得,在Silhouette性能方面,QABC+K均值算法在seeds数据集获得了最高值0.539 1,而在SECON集获得了最小值仅为0.397 4,主要是因为SECOM高维度引起的聚类Silhouette性能下降,这说明QABC+K均值算法的聚类Silhouette性能对样本维度依赖程度高,在高维度样本的聚类中,虽然通过了QABC优化,但是K均值的聚类Silhouette性能仍受到了较大影响。所提算法的均方根误差(Root-mean-square error,RMSE)如表4所示。

表3 QABC+K均值的Silhouette值
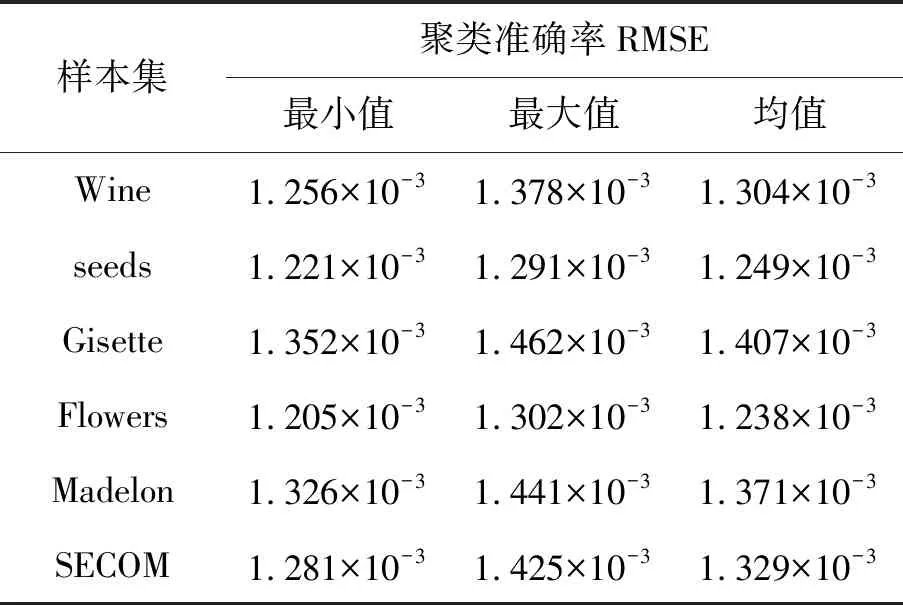
表4 QABC+K均值的RMSE
从表4可知,QABC+K均值算法在六类样本集的RMSE方面性能均较高,其中最低的Gisette集的聚类RMSE均值为1.407×10-3,这表明QABC+K均值算法对六类样本的聚类稳定性较高。
3.2 QABC对K均值聚类的性能影响
为了验证量子人工蜂群对K均值聚类的性能影响,采用K均值算法、ABC+K均值算法及QABC+K均值算法对表1样本集进行聚类仿真。
从表5知,从聚类类别方面来看,QABC+K均值算法契合度最高,仅在Gistette集比实际类别少1,其他完全符合实际类别数,而ABC+K均值的聚类类别在3个样本集出现了与实际类别数不一致的情况,K均值聚类类别在4个样本集出现了与实际类别不一致情况。因此在聚类类别方面QABC+K均值算法优于其他两种算法。

表5 3种算法的聚类类别
从图2知,对于六类样本集,三种算法的聚类准确率分层明显,QABC+K均值算法优势远高于其他两种算法,这表明经过QABC优化后,K均值算法对六类样本的聚类准确率得到了较大提升。对于复杂度较高的多属性样本,三类算法的聚类准确率差异体现得更明显,QABC+K均值的优势更大,这表明K均值算法对维度高样本聚类准确率性能较差,经过QABC优化后,其性能提升明显。在聚类时间上看,K均值算法略高于其他两种算法,但差距并不大,这是因为虽然QABC在初始聚类中心优化时消耗了一些时间,但是减少了聚类的运算时间消耗。
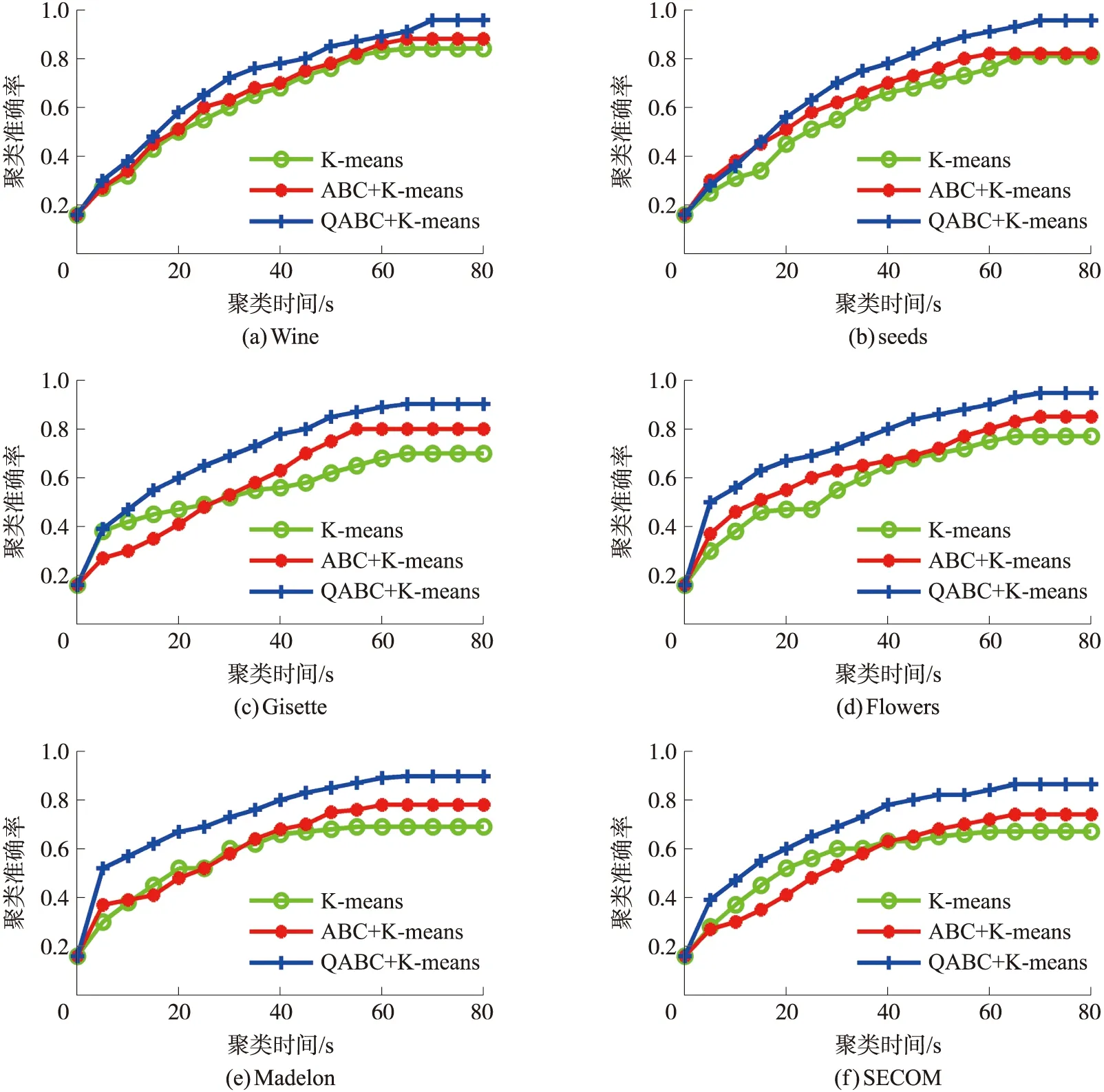
图2 3种算法的聚类准确率
从图3可得,在Silhouette性能方面,经过ABC优化后,K均值算法的Silhouette值得到了较大提升,对于六类样本集,K均值的Silhouette值维持在0.35以下,而ABC+K均值算法和QABC+K均值算法的Silhouette值都保持在0.37以上,这说明经过ABC优化后,提升了K均值的聚类结果类间分布合理性。对于seeds数据集,ABC+K均值算法和QABC+K均值算法的Silhouette值非常接近,其他5类集,QABC+K均值算法的优势更明显。

图3 3种算法的Silhouette值
3.3 不同算法的聚类性能
为了验证不同K均值算法优化后的聚类性能,分别采用三种经过优化后的K均值聚类算法:粒子群优化(Particle swarm optimization,PSO)K均值(PSO+K均值)[14]、灰狼优化(Grey wolf optimization,GWO)K均值(GWO+K均值)[15]、菌群优化K均值(BFO+K均值)[3],将三种算法与量子人工蜂群优化K均值算法对六类样本进行聚类仿真。
从表6得,对于六类样本集,采用不同算法对K均值改进后,其聚类准确率呈现出较大差别,其中QABC+K均值、BFO+K均值、GWO+K均值和PSO+K均值算法的准确率范围分别为[0.863 5,0.951 5]、[0.831 1,0.915 8]、[0.825 6,0.901 5]和[0.793 4,0.892 8],QABC+K均值的优势显而易见,这表明QABC对K均值聚类准确率优化程度最高。横向对比六类数据集发现,虽然经过不同算法的K均值优化,但低维度和高维度样本的聚类准确率差距明显,这是因为K均值算法本身对高维度样本聚类适应度较差造成的。虽然通过不同算法对K均值优化,单优化算法仅针对K均值的初始中心类别点进行寻优,而聚类的本质运算仍是K均值算法来完成的[16],因此这四种算法的改进对解决高维度样本的聚类性能提升不明显。
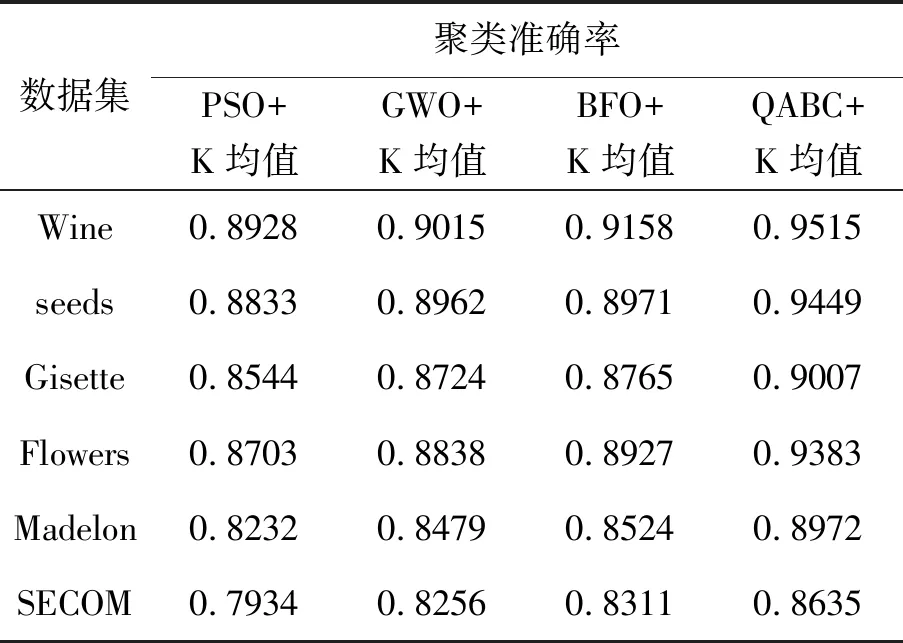
表6 四种算法的聚类准确率
从表7得,对于六类样本集的聚类准确率RMSE,QABC+K均值算法的RMSE最优,PSO+K均值算法最差,四种改进算法的稳定性最差和最优值在数据集的表现上不一致,PSO+K均值算法和GWO+K均值算法均在Flowers上获得了最差RMSE值1.932×10-3和1.721×10-3,而BFO+K均值算法和QABC+K均值算法均在Gisette上获得了最差RMSE值1.532×10-3和1.407×10-3,这说明改进的K均值聚类稳定性对样本数据维度不敏感。从统计结果得,四类算法的RMSE值在数量级上相同,这表明4类算法在稳定性方面并未拉开差距。
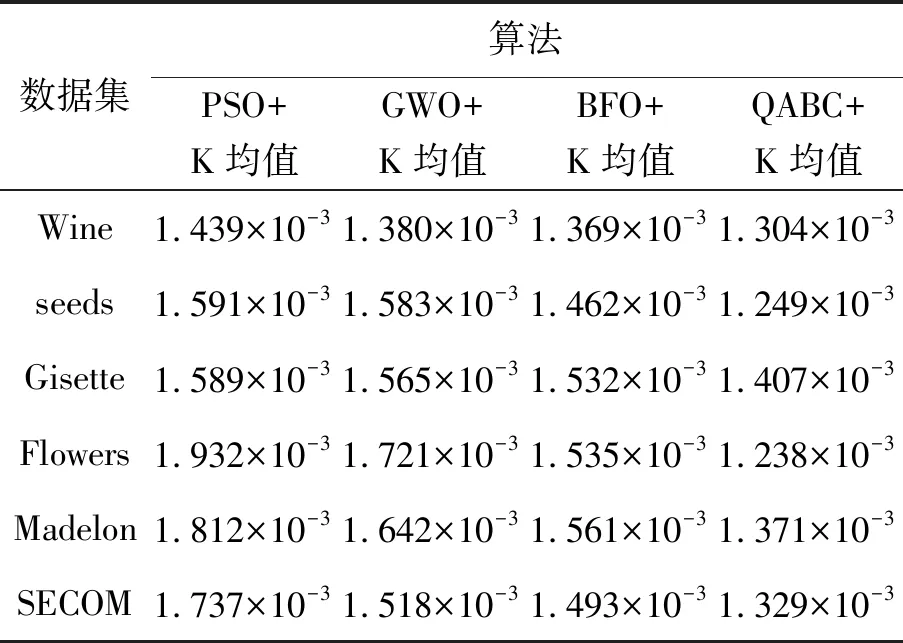
表7 四种算法聚类准确率RMSE
4 结束语
采用量子人工蜂群的K均值聚类,通过量子人工蜂群的高精度搜索,以及量子化的细粒度寻优,提高了聚类精度。本文采用QABC的寻优中,其主要参数均为常用设置,并未进行差异化参数的聚类性能验证,后续研究将差异化微调人工蜂群算法核心参数,尝试从蜂群规模、探测蜂的搜索边界等角度去进行聚类性能测试,以进一步提高本文算法的性能。
