联合多尺度与注意力模型的双分支局部特征提取方法
2023-05-23黄鑫涛蔡有城
黄鑫涛,曹 力,2,蔡有城,李 琳,2
1(合肥工业大学 计算机与信息学院,合肥 230601)
2(安全关键工业测控技术教育部工程研究中心,合肥 230601)
1 引 言
图像匹配是指从图像中检测兴趣区域并在不同视图中进行匹配的过程.作为计算机视觉任务的关键步骤之一,图像匹配被广泛应用在同步定位与地图构建(SLAM)[1,2]、运动恢复结构(SfM)[3]、目标检测[4]以及图像检索[5]等领域.以SIFT[6]和SURF[7]等为代表的传统手工方法,基于局部特征描述进行匹配,其具备良好的旋转、平移和尺度不变性,现今仍被广泛使用.传统方法将提取管线划分为检测器和描述器两部分.其中,检测器能够有效地提取图像中具备显著特征的兴趣区域,而描述子作为相似性度量的特征描述向量,包含邻域兴趣特征的编码信息.相对应地,提取具备高重复性检测子和高区分度描述子对最终的匹配效果有着至关重要的作用.然而,传统方法在检测和描述阶段过于依赖人工设计策略,在面对日益复杂的图像数据时难免出现不同程度的性能瓶颈.
近年来,深度学习方法在数据驱动型任务中表现突出,应用深度学习思路来预测图像深层特征成为主流趋势.现有采取学习策略的局部特征提取方法也取得了相当可观的结果.前期方法大多独立于整个特征提取管线,分别基于检测器或描述器学习,导致仅有的针对性优化在集成后表现仍然不佳.相比之下,端到端学习框架则较好平衡了该问题.目前的解决方案大致可分为:1)先检测后描述方法,严格遵循传统手工方法提取流程,但依赖手工方法提取的先验信息;2)先描述后检测,利用CNN预先提取密集描述子,获得较高匹配度的同时,损失了部分关键点的精确定位;3)同步检测和描述,针对不同阶段设定差别优化目标.DeTone等[10]提出的SuperPoint方法,利用双分支编码器-解码器结构,实现了同步预测关键点位置和建立描述符两阶段.但由于在编码器节点仅采用单一降采样处理,一定程度上丢失了不同尺度下的关键特征.为此,本文在此基础上针对尺度单一以及区分度不高等问题,提出了联合多尺度和混合注意力的局部特征提取方法,该框架包括一个共享编码器和两个解码器,分别用于检测与描述.依据特征金字塔理论,对编码和解码阶段进行多级并联实现多尺度融合的关键点解码器,可以大幅提高网络预测的关键特征数量;与此同时,采用注意力机制,将空间、通道混合注意力模型与 CNN 网络级联,构建具备自主学习能力的描述符解码器,实现冗余特征的筛选.此外,引入了检测器相似度损失用于强调一对匹配点之间的相似程度,以及用于鼓励正确匹配和抑制错误匹配的描述器铰链损失,从而进一步优化网络训练并提高局部特征的鲁棒性.
2 相关工作
局部特征有着区别于邻近位置的显著特性,一般包括图像中的角点、斑点等兴趣区域.早期的角点检测方法主要关注灰度图像中的局部像素差异,Morevec 算子[11]采用滑动二值矩形窗口寻找灰度变化的局部最大值.Harris[12]利用二阶微分算子对极值判别进行进一步优化.为了满足实时性任务需求,Rosten 等[13]基于灰度像素值比较提出了 FAST 算子.之后,ORB 算法[14]基于FAST以及BRIEF描述子在精度和实时性上获得大幅提升.另一方面,斑点具备更好的抗噪能力,能够更加有效应对匹配任务.SIFT[6]方法即利用高斯差分(DoG)对高斯拉普拉斯(Laplace of Gaussian,LOG)算子进行近似估计,并引入尺度空间,在相对降低LOG复杂度的情况下,获得了更好的稳定性及尺度不变性.此外,Bay 等[7]提出SURF 方法,目的是借助积分图像进一步提高计算效率.苗权等[15]则基于 SURF 方法提取兴趣点,通过统计灰度信息分布获得基于区域和二维灰度直方图描述子,在光照和视角等图像变化中获得了更好适应性.
相较于传统 SIFT[6]稀疏描述,深度神经网络通过像素级输入预测更为稠密的局部特征.主流采取学习策略的方法大致分为3类:先检测后描述(传统)、先描述后检测以及同步检测和描述.LIFT[8]开创性的对传统流程进行学习,并利用 SfM 算法生成的特征点对图像块进行逐步训练.LF-Net[16]设计了一种没有手工方法的介入的新颖深度特征提取网络.RF-Net[17]利用增加感受野(Receptive Fields)的方式,实现进一步扩展.另一方面,D2-Net[9]先通过 CNN 提取稠密的特征描述符后进行关键点预测,实现了先描述后检测框架,D2D[18]方法遵循类似处理思路.SuperPoint[10]通过单个共享编码器和两个独立的解码器实现了同步检测和描述特征提取网络,同步采用合成数据集预训练基础检测器实现自监督学习.最近的 R2D2[19]和 GoodPoint[20]方法均选择类似 SuperPoint[10]架构处理局部特征提取问题.前者试图重新定义局部特征的属性描述,而后者通过微调 SuperPoint[10]网络实现了完全无监督学习,但实际性能提升非常有限.
检测图像中兴趣区域作为特征提取任务的核心问题,相比于设计传统手工和基于学习的算法,人类视觉有着快速扫描一对图像中相似或不相似的区域的能力.Bahdanau 等[21]最早提出注意力机制(Attention Mechanism)就在模拟这一机制,并首次在图像分类任务中获得了绝佳评价.DELF 方法[22]在大规模地标数据集上训练注意力模型,为处理图像检索任务积累了相当丰富的语义信息.伴随注意力机制的广泛应用,其自身的学习机制也在不断创新.Transformer 模型[23]提出了完全依靠自注意力来计算其输入与输出表示的基础模型.Jaderberg 等[24]引出空间注意力概念,并在卷积层之间加入空间变换器网络(Spatial Transformer Networks,STN)模块,通过参数预测、坐标映射和像素获取来模拟空间变换,使得学习到的特征将具有更高的不变性.SENet 方法[25]学习通道的权重,对每个通道特征响应进行自适应校正.随后,以 CBAM[26]和 BAM[27]为代表的混合注意力模型被提出,其分别采用串联和并联的方式联合学习空间注意力及通道注意力,其中 BAM[27]作为本文方法的注意力参考模型.
3 本文方法
本文提出的方法旨在从输入图像中预测出更多可重复的关键点和具备较高区分性的局部描述符.主干框架采用双分支编码器-解码器结构,由共享编码器、关键点解码器以及局部描述符解码器组成.如图1所示,共享编码器对输入图像进行降采样处理,预测多个尺度下的特征信息,并将最终的输出作为解码器的特征输入.关键点检测分支对输入特征进行等尺度的上采样,并与编码器阶段中相同尺度特征层进行并联构建特征金字塔网络(Feature Pyramid Network,FPN)结构[28],从而有效的将多层次语义特征的进行融合,使局部特征适应图像的尺度变化,进而提高关键点的检测重复率.与直接预测描述符不同,局部描述符分支加入了空间和通道混合注意力模块,利用全局以及上下文信息对参数进行学习,实现描述符区分度的大幅提升.
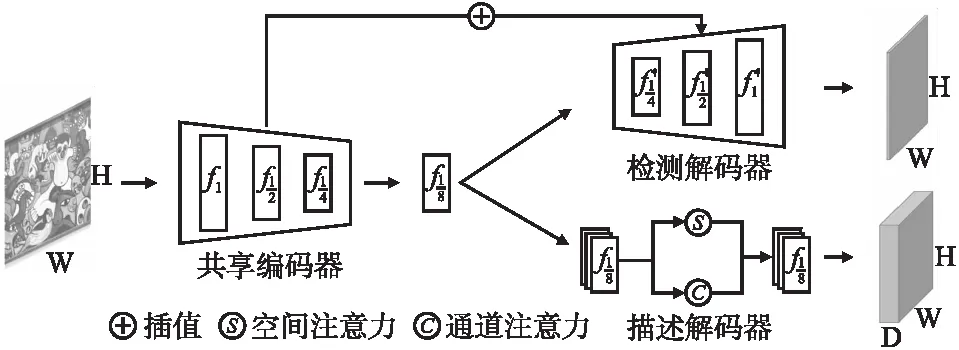
图1 本文方法总体框架
3.1 共享编码器
共享编码器采用 VGG-Style 多层卷积结构,对于输入图像,在经过大小为3×3卷积核进行最大池化,分别获得大小为{1/2,1/4,1/8}的特征图f(I),其中f1/8将作为解码器的初始输入.对输入图像进行多级编码,其主要目的是降低网络的计算量及参数量,以及获取不同尺度下的特征信息.
3.2 关键点解码器
特征检测最重要的目的是提取出图像中目标特征,而尺度不变性作为衡量局部特征优劣的典型特性,影响后续关键点的提取和描述符的建立.传统手工方法 SIFT[6]、深度学习方法 Key.Net[29]和 HDD-Net[30]均通过输入多个不同分辨率图像的方式加以处理,但这样在一定程度上牺牲了整个框架的计算性能.遵循通用的深度神经网络思路,均在追求利用卷积和池化操作,逐层抽象直接学习到图像中目标特征.以 D2-Net[9]、ASLFeat[31]、R2D2[19]等方法为例,利用降采样对输入图像进行多个阶段的特征预测.尽管计算效率得到提升,但并未从根本上提升多尺度适应性,且一定程度上丢失了低层高分辨率下的空间信息.
为了平衡上述存在的不足,本文提出了基于 FPN 的关键点解码器,其目的是充分利用低层特征的高分辨率以及高层特征的高语义信息,提升检测器尺度不变性,进而提高关键点的重复性.不同于图像金字塔,FPN 利用卷积网络下预测的特征图构建金字塔,其结构如图2所示.FPN 具备以下两个优势:1)相比于直接处理不同分辨率图像,FPN 极大的降低其计算量;而对比非金字塔结构,由于 FPN 本身在进行插值计算时只在网络结构的层与层之间进行,该部分增加的计算量可以忽略不计;2)由于融合多层级特征图,有效的弥补采样过程中信息丢失,且充分利用了网络在不同尺度下预测的语义特征.
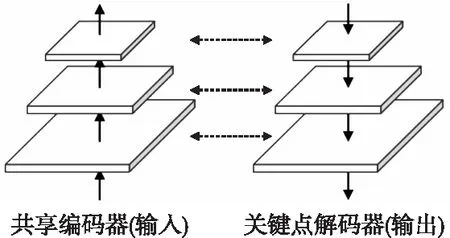
图2 特征金字塔结构
检测解码器结构对应于共享编码器,将共享编码器中输出的特征层作为解码器头部,同样采用3×3卷积核进行3次插值上采样,得到大小为{1/2,1/4,1/8}的特征图f′(I),并与编码器中获得的相同尺度特征层进行链接,从而构成FPN关键点检测器网络,最后一层的输出作为特征检测的结果,包含了图像中预测的关键点的位置信息.
FPN 联合了编码和解码阶段预测特征信息,在保证参数量尽可能低的同时,丰富了关键点的特征信息,从而使得提取出的局部特征对真实图像尺度变化具备较好的鲁棒性.
3.3 描述符解码器
描述符作为目标匹配的重要依据,描述了关键点位置及其领域内的相似程度,其区分性对匹配结果发挥重要作用.如何在端到端的结构中尽可能提高特征描述的区分性显得非常必要,同时也极具挑战性性.在以传统先检测后描述的处理流程的思路上,LIFT[8]、LF-Net[16]方法不约而同的在建立描述符之前,通过学习特征响应(Score Map)并对图像进行裁剪得到图像块,然后借助 STN 模块[24]模拟图像变换达到提升描述符区分性的目的.此外类似 HDD-Net[30]方法利用深度神经网络输入多分辨输入图像,将学习到的特征信息进行融合得以提升其性能.以上这些方法本质上都在试图以数据增强的方式来提升描述子的区分程度,但却牺牲了网络轻量化的可能性.
卷积神经网络试图利用卷积核从输入图像中过滤不同的局部特征来模拟人类视觉,这是最为简单和符合直觉的,因此直接利用卷积层保留的多层图像特征用于特征描述成为首要解决方案.D2-Net[9]和 D2D[18]方法作为先描述后检测方法的代表验证了这一处理思路,利用 CNN 直接处理高分辨率输入图像预测得到的特征,将兴趣点检测这一步骤推迟而直接预测描述符,在多项实际应用中取得到了非常好的性能表现.更进一步,注意力机制赋予神经网络更大的可能性,极大程度上还原了人类视觉系统,利用“关注哪里及如何关注”的原则,对参数进行再分配使得网络从全局中学习到更有价值的信息.
本文提出将瓶颈注意力模块(Bottleneck Attention Module,BAM)[27]与卷积解码器集成,从空间域和通道域内联合预测局部描述符,如图3所示.
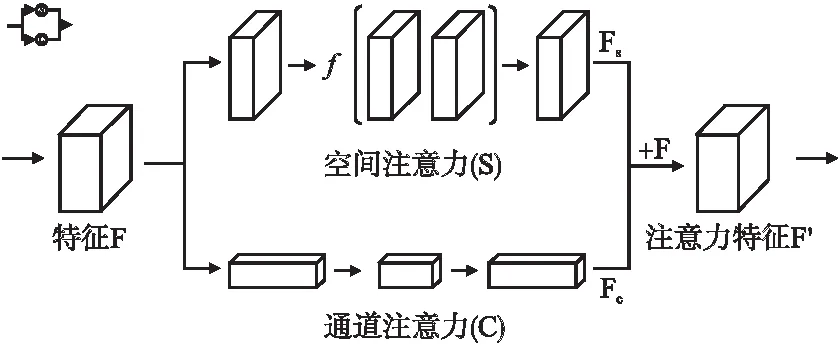
图3 瓶颈注意力模块
空间注意力分支使用空洞卷积实现强调或抑制不同空间位置的特征,预测得到大小为Fs∈RH×W的空间注意力特征图S;通道注意力分支则对输入特征图F进行平均池化实现聚合多个通道的响应特征,得到全局信息编码后的Fc∈RC×1×1通道向量,然后使用多层感知机估计各个信道的注意力强度.随后,空间和通道注意力特征层均经过(Batch Normalization,BN)层输出归一化后的特征.最终在 Softmax 激活函数下对S和C进行相加,并与输入特征层F进行相乘得到重构后的混合注意力特征图F′.经过注意力模块的学习,重构后的注意力特征综合了通道和空间域下全局特征.最终将注意力特征图通过插值计算,得到局部描述符(D=256).
3.4 损失函数
本文针对同步预测的关键点和局部描述符进行独立优化,分别定义了检测器损失用于约束预测点位置与伪标签之间误差以及同源匹配点对之间的相似度;以及描述器损失实现强调和抑制匹配对之间的关系.
对于输入图像I、I′,基于SuperPoint[10]预先训练的伪标签yI、yI′,利用FPN网络预测图像的关键点位置XI、XI′,并应用交叉熵函数分别计算探测器的损失.
(1)
正如前面定义一样,计算预测值与真实值之间的误差是必要的,它尽可能的描述了检测器自身的准确性,但这还远远不够.由于关键点重复性定义的是同一场景下,不同图像相同的区域应该能被重复检测到,而且不受外界因素的影响.因此本文提出了关键点相似性损失(Similarity Loss),其描述了来自同一场景下不同图像的匹配点对XI、XI′,之间的相似程度.如果其对应于同一场景中相同位置,则误差应当尽可能小,表示如下:
Lsimi(XI,XI′)=‖W(XI),XI′‖1
(2)
其中,‖·‖1表示平均绝对误差,W 表示对关键点进行变换(Warping)操作.
描述符损失的设计目标是提高正确匹配的比例并抑制错误匹配.为此定义了p(i),表示一对正确匹配之间距离,并用n(i,j)计算相邻错误匹配最小距离.利用欧氏距离来计算一对正确匹配之间的距离,同时计算4组相邻匹配之间的距离,公式如下:
p(i)=‖di-d′i‖2
(3)
n(i,j)=min(‖di-d′j‖2,‖d′i-dj‖2,‖di-dj‖2,‖d′i-d′j‖2)
(4)
其中错误匹配取自4组相邻匹配之间的最小距离.以改进的铰链损失作为描述符损失函数,计算每对匹配的累积距离.
(5)
mp和mn分别表示正确及错误匹配的约定间距,用于衡量预测结果与正负样本之间的相似度,使得预测结果与正样本差异越小,与负样本差异越大.因此,最终的损失函数表示为:
(6)
其中λ作为平衡检测器和描述器的权重系数.
4 实验结果与分析
本文使用 MS-COCO 2014[32]作为实验训练集,包含80 个类别和大约 83K 张图像,随机地从数据集中选择图像,使用预定义单应矩阵进行数据预处理,以构建适合训练的图像对.
4.1 数据集及实验环境
为了验证方法的有效性,本文分别在2个开放数据集上进行测试,各个数据集中每个序列均包含一幅参考图像和五幅待匹配的目标图像,以及相对应的5组单应变换矩阵,数据集示例如图4所示.HPatches Sequences 数据集[33]是一个用于局部补丁描述符基准测试的公开数据集;它包含116个序列和696幅图像,其中57幅属于光照变化,59幅是透视变化.Hannover 数据集[34]则用于评估检测器精度,它包含5组图像序列,共30幅图像,主要包括光照和视角变化.为了保证实验公平性,所有输入的图像数据均依据实验分组要求裁剪到统一尺寸.

图4 实验数据集
本文实验环境包括 Windows 10 操作系统,Intel Core i7-9000k 16GB 内存,NVIDIA-GTX 2070 GPU 8GB 显卡,Python3版本开发语言、PyTorch 深度学习框架以及 CUDA 10.1 运行平台.
4.2 模型细节及实验设置
本文采用自监督学习方式同步预测图像中的关键点位置并建立局部描述符.在训练阶段,使用 SuperPoint[10]中初始角点检测器在 MS-COCO 2014数据集[32]上训练得到的关键点位置作为自监督伪标签.其中,初始角检测器模型是通过监督学习训练从已知关键点正确位置的简单二维图像数据集中训练生成的.本文的网络框架基于 PyTorch 并使用 Adam 算法进行优化.模型训练时,初始学习率设置为0.0001,所有输入图像被缩放为240×320,将批大小设置为8共计训练18个epoch.此外,损失函数中的mp和mn分别被设置为0.2和1.0.该架构在实验环境下训练2天~3天,平均每个epoch训练约1.0小时,最终得到本文局部特征提取模型.
在测试阶段,采用半径为3px的非最大抑制(NMS)来过滤关键点,其目的是用于约束一对点之间的最小距离.为了获得公平且一致的实验结果,所有的输入图像被分为两组,包括:1)图像大小为240×320,关键点数量限制为500;2)图像大小为480×640,关键点数量限制为1000.同时,为了保证实验充分性,本文模型将与传统手工方法以及最新基于学习的方法进行比较,其中传统手工方法包括 SIFT[6]、SURF[7]和 ORB[14],其使用 OpenCV 库实现;基于学习的方法包括 LIFT[8]、LF-Net[16]、SuperPoint[10]和 D2-Net[9],代码来自于论文作者于 GitHub 上的开源实现.
4.3 评价方法
为了评估本文方法的综合性能,评价方法将涵盖关键点、描述符以及单应性估计等多个维度.
重复性是指同一场景中的相同特征可以在不同的图像中被反复检测.一般来说,任何小于指定阈值的关键点对都被定义为重复的.因此,本文主要使用重复率(Repeatability,Rep)来评估关键点的重复性,其主要计算所有预测点中重复关键点的百分比.
描述符评价指标采用匹配分数(Matching Score,MS)和平均匹配精度(Mean Matching Accuracy,MMA).利用限制阈值的最近邻与次近邻距离比值的Ratio Test方法来计算正确匹配.其中,MS表示图像对中正确匹配的百分比,用于衡量局部特征提取管线的整体性能.将MMA 指标应用于每个图像序列中的参考图像和待匹配的图像,统计不同阈值下所有匹配点之间的距离误差,以比较各个方法的综合匹配性能.
单应性矩阵描述不同视图中对应点在同一平面上的映射关系,即共面点之间的约束关系.单应性估计精度(Homology Estimation Accuracy,HEA)是评价算法估计单应性矩阵能力的重要指标,常在图像中选定4个角点,计算真实单应变换后的角位置与预测位置之间的距离误差,统计所有满足指定阈值内点的百分比.实验过程中,阈值常设置为3个像素(ε=3).
4.4 结果分析
4.4.1 关键点及描述符性能对比
表1是本文方法与6个对比方法在 HPatches Sequences[33]和Hannover[34]数据集上关于局部特征的性能对比测试结果.
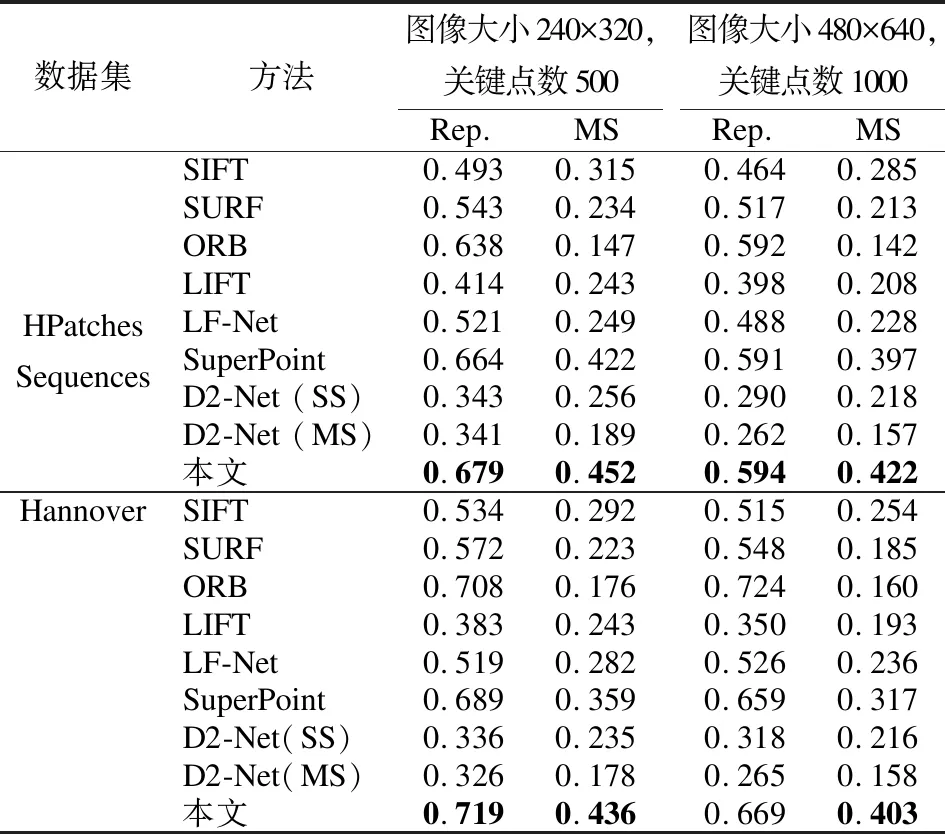
表1 现有算法在测试数据集上性能比较
可以看出,本文方法相较于 SuperPoint[10]基准模型,有较大幅度的提升,同时几乎优于所有对比方法.具体来说,在关键点重复性Rep指标上,本文方法几乎处于最佳,仅在Hannover数据集[34]上低于ORB方法[14],这是由于ORB[14]方法采用密集的均匀提取策略,对每个像素进行关键点检测(尽管重复率上升但评估区分性的MS指标会大幅下降);而在描述符重复性上,本文方法在 HPatches Sequences 数据集[33]上分别提升约7.1%和6.0%,而在 Hannover 数据集上分别提升了21.3%和27.3%.因此,本文所提出的方法通过融合多尺度的丰富语义特征以及注意力学习的方式,能够使局部特征提取管线获得整体性提升.
4.4.2 匹配性能综合对比
在 HPatches Sequences 数据集[33]对匹配性能进行更为详细的测试,实验分别对比了各个方法在光照(Illumination)、视角(Viewpoint)以及整体(Overall)上的性能差异.如图5所示,详细说明了在1~10的不同重投影误差阈值列表中,每种方法的平均匹配精度.显然,随着阈值不断增大,所有方法的匹配精度均得到了不同幅度的上升.本文方法在光照和视角变化上获得了最佳的匹配结果,相比基准模型 SuperPoint[10]有一定幅度上的提升,尤其是在视角(Viewpoint)变化中完全领先.同时,可以看出本文方法明显优于 D2-Net[9]等其他对比方法.

图5 平均匹配精度性能对比结果
4.4.3 单应性估计性能对比
表2展示了在同一阈值(ε=3)下不同方法的单应估计性能.在单应估计时,本文使用L2范式距离作为基准(ORB[14]使用汉明距离进行计算),通过 Brute-force 匹配算法计算匹配,最后使用 RANSAC 估计真实与预测之间的匹配误差.实验结果显示本文方法在光照以及视角变化的数据集(HPatches Sequences 数据集[33]和 Hannover 数据集[34])上效果最佳.从整体上,本文方法在单应估计应用上仍具备较高性能.

表2 现有算法单应性估计精度对比
4.4.4 与基准方法的定性对比
采用3.2节中实验分组1的图像尺寸,并设置关键点数为1500,在HPatches Sequences数据集[33]上与基准模型SuperPoint[10]进行图像匹配效果对比,其中包括光照变化与视角变化.如图6(a)所示,线表示正确匹配,圈表示错误匹配,结果显示相较于SuperPoint[10],本文方法在光照变化条件下正确匹配数量更多且分散均匀;在图6(b)视角变化的匹配结果中,本文方法的最终匹配结果仍表现突出.综上,本文所提出的局部特征提取方法对光照以及视角变化具备更好的鲁棒性.

图6 光照及视角变换图像匹配结果
4.4.5 消融实验
为了更好地验证所提方法各个环节的有效性,本文设置了消融实验来对整个框架中不同模块进行测试.具体来说,在其他控制变量和参数相同的情况下,1)取消特征金字塔结构,即在检测网络中不进行多层特征融合;2)取消描述网络中的瓶颈关注模块,即直接利用卷积预测描述符;3)不使用相似度损失函数,其余实验设置参考4.2节.如表3所示,采用 FPN 结构后,Rep 和 MS 在两组实验中均获得大幅提升,说明融合多尺度特征所带来的尺度适应性,有效地提高关键点的重复性;BAM 模块的加入使得 MS 得到进一步提升;而相似度损失函数的引入使得关键点在 Rep(从0.656上升到0.679)上得到了较大幅度提升,进一步验证了匹配对间的相似度约束是有效的.综上,通过融合不同特征层以及利用注意力学习全局语义特征对提高局部特征精确度具有显著意义.
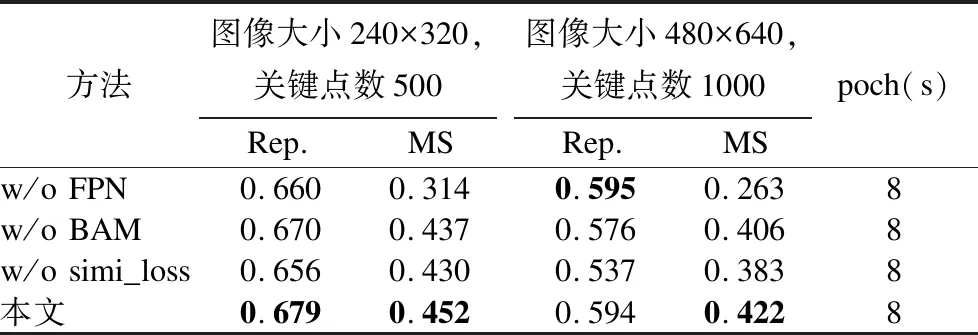
表3 消融实验
5 结 论
为了适应真实场景中的复杂图像变化和匹配的高精度要求,本文提出了一种新型的局部特征提取和描述方法.区别于现有方法,本文所提出的方案具有以下优势:1)在双分支架构基础上整合特征金字塔架构,融合不同尺度的特征图提升特征点对尺度变化的适应性,进而获得更高的重复率;2)将混合注意力模型与卷积神经网络相结合,充分利用空间和通道域信息增强描述符预测的区分性;3)针对检测和描述网络训练提出了独立的损失函数.与最先进的架构相比,本文方法对光照和视角变化具有更强的鲁棒性,并且在重复性和区分性等局部特征量化指标上取得了更好的性能.
未来,将进一步研究该方法应用于三维重建等实际应用的性能.或者利用无监督学习来简化整个前期的训练过程.
