LI-Tree:一个基于非易失性内存和轻量级B+树的学习索引
2023-05-23王中华舒碧华陈书宁刘瀚阳万继光
王中华,舒碧华,陈书宁,刘瀚阳,崔 秋,万继光
1(华中科技大学 武汉光电国家研究中心,武汉 430074)
2(北京平凯星辰科技发展有限公司,北京 100192)
1 引 言
数字时代下,急剧增长的数据量[1]对存储系统提出了更高的容量、性能和成本挑战[2].然而,对存储系统性能至关重要的经典内存索引结构却无法满足当前的需求[3].一方面,传统DRAM内存面临着容量和能耗等方面的问题[4],另一方面,经典范围索引结构经过多年发展,其结构弊端明显且优化空间有限[5].
在设备方面,为了进一步逼近性能、价格与容量的博弈极限,工业界推出了新型非易失性内存(Non-Volatile Memory,NVM)[6],它拥有堪比固态驱动器(Solid State Drive,SSD)的容量和接近DRAM的性能.除此,NVM还具备按字节寻址、快速访问、掉电非易失、静态功耗低等优良特性,是构建下一代存储索引结构的重要存储介质[7].然而NVM也存在一些缺点,例如读写不对称[8]、非易失性带来的一致性问题等[9,10].所以基于DRAM设计的索引结构无法直接部署到NVM使用,尤其是NVM支持超大容量,而传统的面向DRAM的索引结构基本无法在大数据量下支持较高性能的索引性能[11].
在软件方面,大数据背景下大放异彩的机器学习模型为海量数据索引提供了新思路-学习索引结构(Learned Index,LI)[12].现在绝大多数键值存储系统中,将存储其中的键值对(Key-Value)按关键字排序是后续高效处理数据的前提,因此键值对在存储系统中的地址与其关键字存在一对一映射.B+树及其派生的索引结构[13,14]通过从根节点到叶节点的跳转来实现这个映射关系,所以与数据量正相关的树高度很大程度上决定了映射性能在海量数据下的低效性[15].哈希索引虽然可以通过计算直接实现关键字到地址的映射,但是牺牲了关键字之间的有序性.LI的思想是利用机器学习模型[16,17]来实现这个映射,该模型既可以通过计算在常量级别的时间复杂度内预测出一个关键字的位置又保留了关键字之间的有序性.
为了构建适应海量数据的索引结构,现在有两种优化改进方向,一是对传统索引结构进行适应NVM的优化,二是基于DRAM的非传统的学习索引的性能优化.学习索引对大量数据的优秀性能和非易失、大容量的NVM的结合是天然适配的,然而两者的简单结合很难获得收益[18].据本文调查,目前基于NVM的LI研究非常稀缺[19],在如何结合NVM和LI来高效地索引海量数据方面还有许多问题需要解决.在对NVM硬件性质、传统索引结构性能和LI结构优势深入研究后,本文设计了一种基于NVM的智能索引结构LI-Tree,它充分利用学习索引的快速索引性能,通过学习索引降低B+树的高度来提高结构的查找性能,并且设计结构扩展算法来保证LI-Tree在数据量不断增长的情况下仍能保持良好的性能.
本文的主要贡献如下:
1) 对NVM设备特性、传统B+树索引结构和当前LI索引结构进行大量实验,分析利弊,为设计更为高效的索引架构奠定基础.
2) 针对 1)中分析的结果,设计了一种新的基于NVM的索引结构LI-Tree,使用学习模型降低B+树索引结构高度,从而提高索引性能.此外,为了在数据不断增长的前提下保证索引性能,本文还为LI-Tree设计了扩展算法将其访问路径维持在一个较低的高度.
3) 在真实的NVM产品上实现了LI-Tree索引结构,同时将现有的几种代表性索引结构也移植到NVM上,并将它们与LI-Tree进行了详细的对比和分析,验证了LI-Tree的高效性.
2 相关工作
本节首先介绍了当前国内外在学习索引结构方面的相关研究,及其结构对性能的影响.然后介绍了大量基于NVM的索引结构的相关研究工作,并着重阐述了优化方向和优化效果.
2.1 学习索引结构的相关工作
最初对学习索引进行初步尝试的Kraska等人[12]将常见的范围索引B+树看作是一个模型,它的输入是一个key,输出是key对应的value在排序数组中的位置,这个位置是value所在内存块或磁盘页中第一个key的位置.作为一个探索性工作,它仅支持只读负载.
为了更适用于真实负载,许多工作试图对学习索引进行支持写操作优化.FITing-Tree[20]将已排序的数组按照范围划分为多个段,查找时使用B+树来索引到段,每个分段中使用线性函数来拟合数据分布.同时每个段内预留缓冲区来容纳写入数据,缓冲区写满时,对数据进行重排序和重训练.ALEX[21]使用类似B+树的结构,在节点中使用线性模型索引.同时,通过在已排序的数据数组中预留槽来支持写操作,当没有足够的预留插槽时,重新建立排序数组和重训练模型.PGM-index[22]使用类似LSM-tree的方式来保存数据,但只在最后底层存储数据,并在该层维护一个学习索引模型,而其余层被用作写缓冲区,最后一层合并数据时更新索引模型.此外,为了减少频繁重训练的代价,PMG-index还使用了高效的重训练方案.XIndex[23]使用分段线性拟合的策略建立学习索引,每个分段内使用缓冲区来支持写操作,缓冲区满时进行重排序和重训练,另外,XIndex还使用一些锁机制来保证学习索引的并发写.Dabble[24]使用K-Means算法将数据划分为互不相交的K个区域,在每个区域内,使用一个双层神经网络模型拟合函数位置.同时,Dabble使用LSM-tree方式来延迟数据更新.
除了上面这些使用机器学习方式完全取代传统B+树方案,还有些工作使用机器学习作为传统数据结构的辅助.IFB-Tree[25]在建立B+树索引时判断每个节点是否是插值友好的,即节点中所有数据使用插值搜索的误差都小于阈值,如果是则在节点中使用插值搜索,否则使用传统B树节点.
综上所述,当前LI主要是针对支持写操作或者并行写操作的优化,主要的支持机制有3种:建立写缓冲区法,预留排序空间法和插值法.然而,写缓冲区法存在缓冲区内查找慢和缓冲区写满后数据重排序和模型重训练开销的问题;预留空间法中索引密度与重训练频繁存在博弈,当索引密度大时重训练频繁,当索引密度小时,空间浪费严重;插值法虽然一定程度上加快了查找,但并没有改变B+树随数据量变大导致访问路径变长的缺陷.
2.2 基于NVM的索引结构优化的相关工作
为了更好的将NVM应用于存储系统,提升数据查询和空间管理效率,研究人员针对基于NVM的范围索引结构设计优化做了大量工作.为了减小多层存储带来的开销,许多研究者提出了基于单层NVM的索引结构.Shivaram等人[4]提出了一种基于 NVM 的B树结构 CDDS,该方案采取版本控制的方法来保证数据一致性,使得B树索引结构可以从一个版本原子更新到另外一个版本.wB+树[26]也是一个基于单层NVM的B+树索引,每个节点包含一个位图数组,索引结构通过位图的原子更新来保证插入/删除操作的一致性.Fast-Fair[27]同样是基于NVM内存的B+树结构,它在插入和删除的时候设置重复指针,系统崩溃时可以通过检测重复指针来确定崩溃时数据更新位置.除此,Fast-Fair还提出了一种无锁查询机制来支持NVM并发性.
由于单层NVM的访问速度相对较慢,一些研究者使用DRAM作为NVM的辅助内存来加快访问速度.NV-Tree[28]采用基于DRAM/NVM混合内存的B+树结构,将底层的叶子结点存放在NVM上,其余结点存放在DRAM上,以此来减去内部节点一致性开销.FP-Tree[29]也是一种基于DRAM/NVM混合内存的B+树索引结构,它兼具了NV-Tree的节点分布和wB+树的位图.除此,它还引入了哈希和硬件事务内存机制来加速查找和支持并发.HiKV[30]是DRAM/NVM混合索引结构,NVM中部署哈希索引,DRAM中部署范围索引B+树,避免了NVM速度慢导致的多层查找开销大的问题.同时,在NVM中,HiKV还利用8字节原子写保证一致性,并且采用分块锁机制来支持并发性.
除了上面这些基于NVM的B+树的结构优化方案,还有其它流行的索引结构提出了基于NVM的优化方案.WORT[31]针对NVM速度不及DRAM的缺陷,提出了基于NVM的radix tree索引,该方案在数据稀疏分布时将同一路径下的数据项压缩到一个节点中来压缩访问路径,提升查找性能.同时WORT使用8字节原子写来保证操作一致性.CRB-Tree[32]是一种基于NVM的红黑树,它为每个节点保存两个版本:一致性版本和更改版本,所有操作都在更新版本上进行,当一次更新操作完成后,通过一个8字节的原子命令将更新版本变更为新一致性版本.NoveLSM[33]是一种基于NVM的日志结构合并树,为了利用NVM容量大的优势,该方案扩大了memtable的容量,可在memtable中就地更新,并且提出一致性恢复策略.除此,它还提出一种DRAM/NVM/SSD三级设备的并行查找机制.
上面的论文中可以看出由于介质特性不同,适用于DRAM的索引结构无法直接用于NVM中,并且综合上述相关工作可以观察到:1)NVM相比DRAM读写速度稍慢,所以在NVM中减少访问路径的收益更大;2)NVM的持久性优势带来的副作用是部署其上的索引结构必须考虑数据一致性.
3 问题分析
在本节中,首先对学习索引结构在NVM上的问题进行试验分析,然后阐述索引结构在NVM上面临的挑战,最后揭示LI-Tree的设计理念.
3.1 现有学习索引在NVM上性能不佳
学习索引(LI)结构使用学习模型来学习关键字及其位置之间的映射关系,并据此模型来预测关键字的位置,从而达到索引的目的.因此一旦关键字的顺序发生改变(例如插入操作),模型准确度就会下降,需要重新训练,这导致LI结构虽然可以实现极好的查询性能,但是在插入方面表现欠佳.
为了对现有LI结构进行分析,本文将现有最先进的学习LI结构Dynamic-PGM[22]、XIndex[23]和ALEX[21]和基于NVM优化的B+树代表性的方案Fast-Fair[27]进行对比.由于这些LI都是基于DRAM设计的,本文将它们移植到NVM上做性能测试.其中,D-PGM(Dynamic-PGM)是支持插入操作的PGM-Index,它类似LSM的索引结构,上层被用作写缓冲,只有最底层会建立PGM-Index[22].XIndex直接建立主副两个写缓冲区轮流接收写入数据.ALEX通过在排序数组中预留空位来吸收后续写入(详细描述在章节2).
图1展示了YCSB[34]数据集上的测试结果,图中纵坐标表示吞吐量,单位是Kop/s,横坐标表示插入操作所占比例.测试时,首先加载4亿条数据(key和value均为数值类型),然后按照不同读写比例执行1千万条操作并统计吞吐量.以20%写操作为例,将2百万的随机写操作和8百万的随机读操作打乱后执行并统计吞吐量.由于D-PGM采用类似LSM的结构来支持写操作,所以读性能非常糟糕.测试时为了保证D-PGM的读性能,本文在100%读操作时禁用了上层写缓冲.
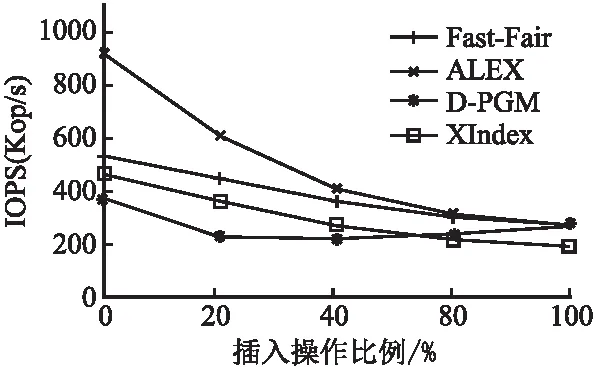
图1 不同插入操作比例下学习索引的性能
图1中可以看出,随着插入操作比例增加,LI结构的性能逐渐下降,ALEX[21]为例的LI结构的查询性能相对较好,然而随着插入操作比例的上升,LI结构的性能降级明显快于B+树.可以看出LI结构的查询性能虽然优秀,但在NVM上的插入性能明显不足,所以,NVM上的LI结构需要更优先考虑插入性能的优化.
3.2 NVM读写性能不对称明显
上面3.1节的测试展示了基于NVM的索引结构普遍具有插入性能明显弱于查询性能的现象,这一方面是索引结构,尤其是LI结构本身的原因,另一方面与NVM介质特性有关.
与DRAM相比,设计基于NVM的索引结构需要考虑两点.1)读写不对称:NVM的读延迟与DRAM相当,但写延迟预计要慢的多[8].2)保证软件崩溃/断电时的数据一致性[35],现有CPU Cache和内存控制器经常会为了提升性能而重排数据进入内存的顺序,当系统崩溃时,可能的暂时性不一致数据会被非易失的NVM保存下来.同时,由于NVM难以保证大于8字节数据的原子写,当写入内存数据大小大于8字节时,未写完的错误数据同样会被保存在NVM中.为了避免这两种不一致的情况,最简单的解决方案是采用日志来保护NVM写操作.然而该方案又会带来大量的额外写操作,由于NVM的读写不对称性,这些写操作会严重降低软件性能.所以对基于NVM的索引结构进行写优化是非常必要的.
3.3 现有学习索引模型各有千秋
为了设计出更为合理高效的LI结构,本小节对当前LI方案使用的学习模型进行较为详细的测试.测试结果如表1所示,表中“训练耗时”是模型训练所用时长,单位是ms,“预测耗时”是单次预测所用时长,单位是ns.RMI[12]模型是目前最流行的模型,它是一个类似B树结构的多层模型,每层包含一个(根模型)或多个具体的学习模型(浅层神经网络[36]/线性模型[37]),查询时从根节点向下预测,每个具体模型负责一个键值范围,最后一层预测值为key所在的具体位置.PGM-Index[22]是有代表性的新型学习索引模型,它使用分段线性逼近模型(Piecewise Linear Approximation,PLA),采用自下而上的训练方式,首先以排好序的key作为输入,在给定的最大误差范围内,通过分段线性逼近获取多个线段(segment),建立最低层模型,然后以线段的位置和最小值作为输入向上建立模型,不断递归,直到最后只有一个线段的层作为做顶层,结束递归.
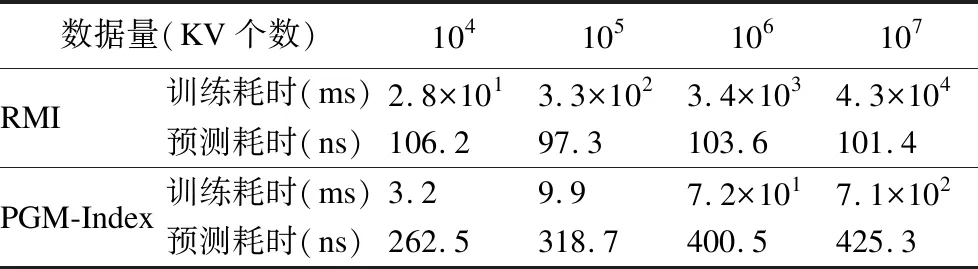
表1 不同数据量下学习模型性能
从表1中可以看出,RMI模型的训练时间要明显的高于PGM-Index,在数据量达到1千万时,RMI模型的训练时间需要几十秒,但是PGM-Index的训练时间仍然在一秒之内.然而,在训练时表现良好的PGM-Index模型的预测时间却随着数据量的增加逐渐增加,从262ns到425ns;而RMI模型的预测时间基本在100 ns左右.很明显,当前的LI方案所使用学习模型的优劣势都比较突出.
综上所述,1)LI结构将访问路径与数据量进行了解耦,可以有效解决B+树性能随数据增加而下降的问题,但是由于当前LI方案并未重视写性能优化的问题和NVM读写不对称的问题,移植到NVM上的LI结构插入性能不佳,因此需要对插入操作进行额外的优化;2)目前常见的学习索引结构所使用的模型有各自的优势,自然地,应该设计一种模型能让它们扬长避短.基于上述测试和分析,本文针对性地提出了一种新的基于NVM的智能索引结构LI-Tree.
4 LI-Tree设计
LI-Tree设计要实现的目标是在保证数据有序性的前提下,保持常量时间复杂度的访问性能.考虑到NVM读写不对称性,LI-Tree采用两种措施来减少插入过程中的NVM写次数,提高索引结构的插入性能.1)使用无序存储加排序索引的方式取代传统的B+树节点结构,消除插入数据时为了保证有序性而带来的数据位移.2)通过精心设计写操作(包括插入、删除、更新和结构修改)来使用高效的8字节NVM原子写保证数据一致性,避免日志操作等带来额外的NVM写.
LI-Tree的整体架构如图2所示,包含3层结构:模型层、数据索引层和数据层.模型层是学习索引结构的模型,它可以用常量级的操作来取代B+树的中间节点的逐级查找,实现数据量与访问路径的解耦.数据索引层是少量中间节点组成的有序静态索引数组,数组中每个entry都包含一个数据缓冲区和一个指向数据层的指针,不仅支持了整个索引结构的范围查找操作而且避免了单个数据插入导致数据层大量数据位移的情况.这对读写不平衡的NVM来说是非常高效的设计.数据层包含多个轻量级B+树(Lightweight B+tree,Lbtree),每个Lbtree存储一定键值范围内的数据.具体地,数据层中不仅Lbtree是有序的,相邻Lbtree之间也是键值有序且不重叠的,这样保证了整个LI-Tree结构中数据的有序性.接下来按照自底向上的顺序具体解释每一层的结构.

图2 LI-Tree整体架构
4.1 数据层数据布局
LI-Tree的数据层包含许多键值不重叠的Lbtree,Lbtree与传统的B+树结构相似,但为了减少不必要的NVM写,重新设计了其节点的结构.同时为了节省关键字key的空间占用,Lbtree中的关键字key也执行前缀压缩处理.
Lbtree的节点包含一个节点类型、一个指针和一个数据区.其中节点类型有两类非叶子节点和叶子节点.对于非叶子节点而言,指针指向第一个孩子节点,节点内数据区记录子节点的信息.对于叶子节点来说,指针指向键值有序的下一个叶子节点,节点内数据区记录的是当前节点键值范围内的键值对.具体地,节点中数据区包含元数据和键值对.其中元数据包括压缩前缀长度、数据计数和排序索引.数据计数记录当前节点内的KV数量.由于Lbtree的节点数据量较少,数据计数和排序索引可以被放在一个8字节内来高效的保护插入操作.为了避免前缀压缩导致的键值对无法8字节对齐,进而影响更新操作的一致性保证,数据区中的关键字key和值value被分开存储,关键字在数据区中从前向后存储,而值在数据区中从后向前存储.
4.2 数据索引层架构
LI-Tree的数据索引层包含一个巨大的有序数组,它作为一个数组整体时是模型层的预测数组,作为一个个数组项时为数据层中每个Lbtree提供索引是保障LI-Tree结构有序的关键组件.如图2所示,每个数组项(被命名为entry)包含一个关键字、一个指针和一个数据缓冲区.其中关键字表示当前entry指针指向的Lbtree的最小的关键字;数据缓冲区使用追加写来快速吸收后续写入数据.由于每个entry里面包含的关键字都在一个小范围内,缓冲区内关键字key的相似度非常高,因此缓冲区内采用前缀压缩方法,减少关键字key所占用的空间.具体地,数据缓冲区包含元数据和键值对.头部包含压缩前缀长度和数据计数;同Lbtree同样原因,数据缓冲区内的关键字和值也被分开存储.数据缓冲区写满后,其中有效数据会被批量刷入相应的Lbtree中,减少了由于单个键值直接写入数据层带来的多余NVM写.
4.3 模型层设计
LI-Tree模型层设计遵循的目标是:既可以快速地根据模型预测到数据索引层中entry的位置,又可以保证模型的训练时间不要过长.为了实现这个目标,本文设计了一种混合学习模型,如图2所示,模型的上层是RMI模型,下层是单层的PGM-Index学习模型PLA.首先利用PLA线性训练时间复杂度的优势快速对数量较多的entry建立底层学习模型,然后对少量的PLA模型建立RMI模型,以优化预测速度.具体地,RMI为两层,使用线性学习模型;PLA学习模型中,保存每个线段的最小关键字、斜率和截距.
模型训练过程:首先以数据索引层中每个entry的关键字作为训练数据,以entry的位置作为标签,训练出PLA模型.进一步地,以PLA模型中每个线段的关键字为标签并以线段的位置作为标签,训练出RMI模型.
5 LI-Tree操作
在本章描述了LI-Tree中查找、插入、更新、删除、初始化和结构扩展的操作过程.
5.1 点查询操作
点查询操作是根据一个关键字key找到其对应的值value的操作.对于一个给定key,首先通过RMI模型预测到线段的位置,并在误差范围内通过二分查找定位准确的线段,然后再根据线段预测数据索引层entry的位置,如果需要则使用二分查找确定正确entry位置.接着在entry的数据缓冲区中查找数据,如果在缓冲区找到所需的数据即结束查找,否则需要在entry所包含的Lbtree中查找.在Lbtree中,LI-Tree通过使用二分查找排序索引确定正确的数据位置.点查询操作的时间复杂度如式(1)所示.
O(n)=O(1)+O(log(error))+O(log(2ε))+O(k)+O(log(m))
(1)
其中,O(1)是模型预测复杂度,error是RMI模型的平均误差,ε是PLA模型的最大误差,k是数据索引层entry中缓冲区的平均数据量,m是数据层Lbtree的平均数据量.可以看出,LI-Tree的查询复杂度完全与数据量解耦,一次查询的复杂度是常量级的.
5.2 范围查询操作
范围查询操作是LI-Tree中根据一个关键字key索引到一组键值连续的key和value.具体地,首先定位到范围查询的起始关键字所在的entry位置,操作同查询操作;然后对entry中数据缓冲区的数据进行排序;接着顺序遍历entry中数据缓冲区的数据和entry包含的Lbtree中的数据;最后移动到下一个entry重复上述操作,直到超出查询范围.
范围查找的时间复杂度:相比点查询,范围查询的操作中增加了对entry中数据缓冲区的排序操作,该操作所需时间复杂度为O(klog(k)),其中k为entry中数据缓冲区的平均数据量.
5.3 插入操作
插入操作是向LI-Tree结构中插入一条键值对.具体地,首先按照点查询的过程定位正确的数据索引层entry的位置;然后判断该entry是否被锁定(正在扩展),如果是,则等待;如果不是,且entry的数据缓冲区未被写满,直接将数据追加到entry的数据缓冲区中;如果entry的数据缓冲区已满,则先将entry的数据缓冲区中的数据批量刷入指针指向的Lbtree中,然后再将数据追加到数据缓冲区中.
插入的时间复杂度(不包括定位过程):在查找到正确的entry后,如果数据缓冲区未满,则写复杂度为O(1);如果数据缓冲区写满,则将缓冲区数据刷入Lbtree中,写复杂度为O(log(k)),k为数据缓冲区大小.
插入的一致性:LI-Tree在插入数据时,最后操作是使用NVM原子写操作更新数据计数.在数据计数加一之前,最新被插入的键值是不可见的.
5.4 更新操作
更新操作指在LI-Tree中更改一个key所对应的value值的操作.具体地,首先找到key和value所在位置,然后,因为value都是8字节,所以直接对value进行原子更新.更新操作的是本地更新,复杂度为O(1).
5.5 删除操作
删除操作是指在LI-Tree中删除一条键值对的操作.具体地,假如待删除键值对在entry的数据缓冲区中且位于缓冲区末尾,则直接删除,并使用原子写更新数据计数;假如待删除键值对在数据缓冲区中且不位于缓冲区末尾,则将末尾键值覆盖写入待删除键值对位置,并原子更新数据计数;否则,待删除数据在Lbtree中,删除数据在排序索引中的位置,并原子更新数据计数和排序索引.删除操作的复杂度同样为O(1).
5.6 初始化
LI-Tree的初始化是从B+树结构转化成LI-Tree的过程.最开始时,LI-Tree采用传统B+树结构,因为轻量级的B+树的性能表现良好.当B+树的数据量达到一定阈值后,将B+树转化为LI-Tree结构.
初始化时,首先将B+树中的每个叶子节点,变成一个LI-Tree中数据层的一个Lbtree的根节点,生成一个Lbtree;接着根据数据层的每一个Lbtree的根节点和最小关键字,构建数据索引层的entry数组;然后对entry数据进行训练,生成LI-Tree的学习索引模型;最后原子修改LI-Tree的访问入口指向学习索引模型,并删除旧B+树结构,完成初始化.
显而易见,在最后原子修改入口指针之前,任何系统崩溃都不会导致LI-Tree的数据不一致.LI-Tree通过一个简单的8B原子写保护了初始化过程.
5.7 结构扩展
为了保证Lbtree总是保持高性能状态,LI-Tree数据层中每个Lbtree的数据量必须保持在较小范围内.LI-Tree设定数据层的键值对数量相比上次扩展后的数据层的键值对数量的比值不得超过阈值.当超过阈值(默认为4倍)时,对整个数据结构进行扩展,增加数据索引层中entry的个数,也即是增加数据层Lbtree的个数,并对数据进行重新分布,重新训练学习索引模型.通过这样的设计可以保证LI-Tree的查找时间复杂度保持在常量级别的.
LI-Tree的扩展比较耗时,需要多次遍历整个数据层的Lbtree.第1次遍历确定新数据索引层大小:对每个Lbtree进行高度判断,如果高度高于2(包含根节点),则说明该键值范围内的数据为热数据,需要将该Lbtree的最底层的非叶子节点当作一个新Lbtree的根节点,然后分配新数据索引层空间.第2次遍历将数据填写到新建的数据索引空间中,完成重建数据索引层entry.为了减少LI-Tree在扩展过程中对应用请求的影响,LI-Tree的扩展过程做了两个优化方案:一是后台扩展,二是多线程扩展.具体地,在第二次遍历时将LI-Tree的数据索引层分为多个区间,每一区间由一个线程维持一个扩展窗口来进行扩展操作,扩展窗口左侧是扩展后的键值范围,右侧是待扩展的键值范围.每个扩展窗口包含正在扩展的一个或者多个entry,这些entry扩展结束后,窗口向后滑动.由于LI-Tree的数据索引层是有序的,因此每个扩展窗口的区间也不会有数据重叠,各个扩展线程之间不再需要进行数据同步或者并行一致性保证操作.
图3展示了两个线程时LI-Free扩展的过程.首先,第①步要对数据索引层进行区间划分,图3中将数据索引层按数量等分为两部分,划分后每个区间由独立线程负责扩展;第②步是线程内部完成新数据索引层的数据填写.在图3的每个线程中,扩展窗口从左向右滑动,对于高度为2的Lbtree直接迁移到新的数据层,对于高度超过2的Lbtree,对其进行扩展,只取最底层的非叶子节点作为一个新Lbtree的根节点,对于高度低于2的相邻Lbtree,可以将这多个Lbtree进行合并,生成一个新的Lbtree;第③步是在所有线程扩展完成后,对扩展后得到的新entry数组进行训练,生成LI-Tree的学习索引模型,至此,多线程扩展完成.此外,图3两个线程扩展的过程中,每个线程都需要维护各自的扩展窗口,并且需要维护该线程的起始扩展位置,以及扩展进度.

图3 LI-Tree多线程扩展
在多线程扩展时,首先将应用请求分给对应的线程,在线程内部,判断请求所处的entry的扩展状态.如果是未扩展entry,则使用学习索引模型进行查找;如果是已扩展entry,则在新数据索引层的已扩展范围内二分查找;如果是正在扩展的,则等待.
在结构扩展过程中,会持久化扩展窗口与当前的扩展进度.如果在扩展过程中系统断电崩溃,在下一次系统重新启动时,根据扩展窗口,首先在新的数据索引层中,定位到扩展窗口的起始位置,放弃起始位置后面已经扩展完成的数据,重新从扩展窗口起始位置进行扩展;如果是在创建新数据索引层结束之后系统断电崩溃,只需要重新训练模型层的学习索引模型即可.同时,LI-Tree通过在CPU缓冲区中为每个entry维护一个锁来保证扩展时各种操作的一致性,当一个entry处于扩展窗口内时被锁定,此时该entry上不允许执行任何操作.
6 恢 复
LI-Tree在NVM预留位置保存了模型层的指针,每次更新模型层后会同时原子更新指针.正常关闭(/断电)时,LI-Tree使用原子写在指针旁保存一个正常关闭标志位,以指示成功关闭.恢复时,首先检查标志位,如果是成功关闭,则直接读取存储在预留位置的指针来直接工作.假如异常关闭,则按照章节5.7的策略恢复LI-Tree.
7 实验与分析
本章在实际的NVM设备上进行了大量的实验演示LI-Tree的优势,并揭示其背后的原因.
7.1 测试环境
测试平台:本文所有测试的都是在Liunx服务器(内核版本3.10.0 64-bit),该服务器使用2×Intel 1.1GHz×48 core CPU,512G NVM.本文显示的所有结果都是在NVM服务器(PMDK版本1.5.1)上运行得到的而不是模拟生成的.
对比方案:本文的主要对比对象是在NVM上B+树代表性的方案Fast-Fair[27],另外,本文还对比了当前的最新学习索引结构Dynamic-PGM[22]、XIndex[23]和ALEX[21].由于Dynamic-PGM、XIndex和ALEX都是基于内存实现的索引结构(详细描述在章节2),因此为了对比的公平性,本文修改了Dynamic-PGM、XIndex和ALEX的代码,使其结构全部存储在NVM上面,并且对于插入、删除和更新操作在关键的位置加上NVM持久化的代码,以确保所有的数据最终全部正确存储到NVM上面.测试时,对比方案们的参数配置均参考各自论文中的最优解.
数据集&负载:本文采用常用的云服务器标准测试集(Yahoo!Cloud Servering Benchmark,YCSB)[34]进行的测试,它提供了一个框架和一组7个工作负载,用于评估键值存储的性能,即吞吐量.1)负载-Load:100%写操作,生成数据集满足Uniform分布;2)负载-A:50%读操作,50%写操作,Zipfian分布;3)负载-B:95%读操作,5%写操作,Zipfian分布;4)负载-C:100%读操作,Zipfian分布;5)负载-D:95%读操作,5%写操作,Latest分布;6)负载-E:95%范围查询,5%写操作,Zipfian分布;7)负载-F:50%写操作,50%读改写操作,Zipfian分布.
默认参数:LI-Tree测试时的默认参数包括:RMI模型平均误差为4,PLA最大误差为4;数据索引层entry的大小为128字节,Lbtree的节点大小为128字节,数据全部采用定长的8字节-8字节的键值对.其中entry的大小包括了entry中数据缓冲区的大小.
7.2 基本操作测试
基本操作测试指的是对索引结构的Get、Put、Delete和Scan操作的测试.测试过程中所有操作都是随机的,测试结果如图4所示,其中Load操作是加载4亿条数据的过程.图中横坐标表示的是操作类型,纵坐标表示的是基于Fast-Fair的吞吐量对其它测试方案的吞吐量进行归一化.

图4 LI-Tree基本操作测试
插入操作(Put):如图4所示,LI-Tree的插入性能明显好于对比的几种学习索引结构.相比ALEX、XIndex、D-PGM和Fast-Fair,LI-Tree的插入性能分别提高了80%,150%,130%和70%.LI-Tree的插入性能比Fast-Fair好是由于LI-Tree在数据缓冲区中采用追加写操作,写操作的一致性开销小.LI-Tree的插入性能比ALEX好是由于ALEX在插入时需要移动数据以保持数据有序,并且ALEX预留槽相对较少所以在插入过程中需要频繁的节点分裂.LI-Tree的插入性能比XIndex和D-PGM好是由于它们需要首先插入缓冲区,然后再合并缓冲区.另外,XIndex为了提高结构并行性,添加了锁操作.
查找操作(Get):从图4中可以看出LI-Tree的查找性能要远好于Fast-Fair、XIndex和D-PGM,但是比ALEX的略差.LI-Tree的查找性能不及ALEX有两个原因:1)ALEX不需要在模型间查找;2)LI-Tree采用的是追加写操作,查找操作需要在数据索引层的缓冲区内遍历查找,从而导致LI-Tree的查找性能不及ALEX.
删除操作(Delete):图4中所示,LI-Tree的删除性能与ALEX和XIndex相差不大.因为它们通过标记实现删除.ALEX删除键值对时,仅修改位图即可,同样,XIndex只需要将value的指针置为无效.
范围查询(Scan):范围查询测试是随机执行1千万个长度为100的范围查找操作,然后统计LI-Tree和对比方案的吞吐量.图4中所示,LI-Tree的范围查询性能比Fast-Fair略差,但是比D-PGM好.这是因为相比Fast-Fair,LI-Tree有一个未排序的数据缓冲区,范围查找时需要对缓冲区内数据进行排序.而D-PGM因为采用了类似LSM-Tree的结构,因此范围查询需要比较每一层的数据,查询操作增多.
7.3 YCSB通用负载测试
本小节测试了YCSB通用测试负载集,负载的特性如7.1节所述.测试时,首先加载4亿条数据,然后每个负载执行1千万条操作并统计吞吐量.范围查询的最大数据量设置为100.测试结果如图5所示,其中横坐标表示YCSB的负载类型,纵坐标表示吞吐量,单位是Kop/s,表示每秒千个操作.
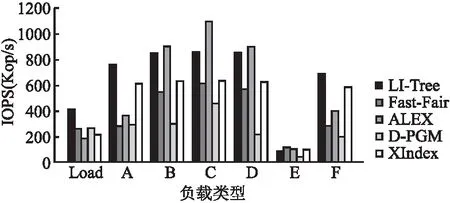
图5 YCSB负载的对比测试
从图5可以看出,LI-Tree在写密集型的负载下性能更好,在负载Load、负载A(50%更新)和负载F(50%读改写)中的性能比所有对比方案都好.LI-Tree在读密集型的负载下性能仅次于ALEX,且差距微弱.例如,相比ALEX,LI-Tree在负载B(95%读)、负载C(100%读)和负载D(95%读)时性能分别下降了5.7%、21.2%和4.5%.LI-Tree在除了负载E之外的各种负载中性能都优于XIndex、Fast-Fair和D-PGM好,这说明LI-Tree结构设计可以很好的将学习索引结构应用到NVM.
对比负载C(全读)、负载A(半读半写)和负载Load(全写),从全读到全写,Fast-Fair的性能下降了40%,D-PGM的性能下降了52%,ALEX的性能下降了83%,XIndex的性能下降了64%,而LI-Tree的性能只下降了49%,并且在全写负载中,LI-Tree的性能几乎是对比方案们的两倍,LI-Tree展示了在插入操作方面的优势.LI-Tree在查找操作上相比较ALEX性能低了18%,但是插入操作性能明显高于ALEX.这是因为LI-Tree为了减少NVM写,采用缓冲区追加写的方式,有效的优化了插入操作的性能,但这也在一定程度上牺牲了LI-Tree的查找性能.
从YCSB负载测试明显看出,LI-Tree在写密集型的负载下表现的比所有对比方案都好.而在读密集型的负载下,LI-Tree的性能虽然相比ALEX略差,但是相比Fast-Fair和其它学习索引结构的性能依然更好.
7.4 结构扩展测试
相比DRAM,NVM的容量更大,应用在使用基于NVM的索引结构时索引结构的规模也比较大.因此,索引结构的拥有良好的可扩展性极其重要,即索引结构的性能与数据量解耦.
为了测试可扩展性,本小节在加载4亿条数据过程中,每加载1千万条数据后统计LI-Tree和对比方案的吞吐量.测试结果如图6所示,图中横坐标表示的是索引结构中已加载的数据量,纵坐标表示的是插入操作的吞吐量,单位是Kop/s,表示每秒千个操作.

图6 插入操作性能随数据量变化
图6中可以看出,相较对比方案,随着数据量的增长,LI-Tree的插入性能总体比较好,但是存在明显的性能波动.这些波动产生的原因是LI-Tree的结构扩展,在LI-Tree的扩展过程中,部分请求(即请求处于已经扩展的键值范围)无法使用LI-Tree的学习索引模型,而是采用二分查找,因此定位到数据层的时间增加,并且处于扩展窗口的请求也会阻塞,这些原因导致LI-Tree在扩展过程中性能有所下降,从而出现低谷.然而这些低谷很快就消失了,这意味着LI-Tree的结构扩展操作能很好的维持相对稳定的性能.Fast-Fair的插入性能随着数据量的增加逐渐下降.D-PGM的波动是由于上层写缓存向下合并.ALEX则是结构扩展,小波动意味着扩展位置靠近叶子节点,大波动意味着扩展位置靠近根节点.XIndex虽然表现一般但是非常稳定,它使用两个写缓冲区,一个缓冲区合并时,另一个继续接受写入,因此虽然延长了访问路径,但是合并时并不影响写操作.另外XIndex的方案还大大降低了空间利用率.
7.5 空间利用率
本文统计了加载4亿条键值对后,LI-Tree和对比方案的空间占用情况.测试结果如图7所示,图中横坐标表示的所有对比方案,纵坐标表示的是NVM的空间占用,单位是GB.
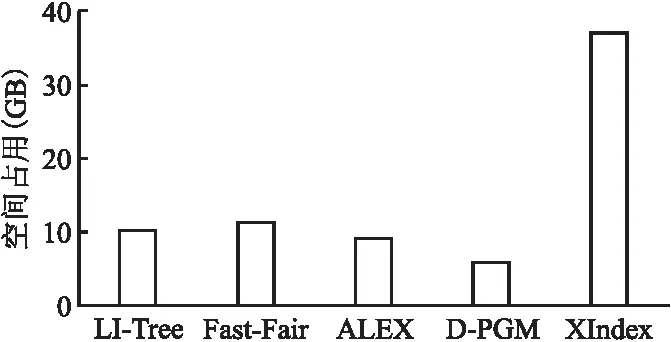
图7 索引结构的空间消耗
从图7中可以看出,XIndex的空间占用最高,这是因为XIndex为每个group都分配了一个写缓冲区,同时当group执行缓冲区合并时,还会创建一个临时缓冲区来吸收写操作.LI-Tree的空间占用低于Fast-Fair但多于ALEX,这是因为相比Fast-Fair,LI-Tree采用了前缀压缩,而相比ALEX在所有节点中都使用学习模型减少索引空间占用,LI-Tree仅仅在上层索引中使用了学习索引.另外,D-PGM的空间占用最低,是因为它的空间分配紧实,所有数据被存在一个大的非稀疏有序数组中.
8 总 结
海量数据背景下的数据管理是现代存储系统亟待解决的问题.本文在进行了广泛的实际测试的前提下,提出了一种基于新型NVM介质的高性能智能索引结构LI-Tree,利用机器学习模型解决了B+树访问性能随数据升高而降低的问题,并且利用低高度B+树读写性能高的优势来解决数据插入导致的模型频繁重训练问题.另外,在该结构基础上,本文还提出了一种后台的多线程的结构扩展算法,来保证LI-Tree稳定处较高性能状态.实验显示,相比其他索引结构,LI-Tree总体表现较好,尤其是在写操作方面性能提升明显.LI-Tree目前只支持定长的key,未来可以进行优化,以便支持变长key.
