基于DE-Q 学习算法的移动机器人路径规划*
2023-05-19马泽伦肖文东
马泽伦,袁 亮,2*,肖文东,何 丽
(1.新疆大学机械工程学院,乌鲁木齐 830047;2.北京化工大学信息科学与技术学院,北京 100029)
0 引言
路径规划是移动机器人的重要研究方向,它在一定程度上反映了移动机器人的智能水平。移动机器人的导航已经广泛应用于工业、农业、服务等领域[1]。在移动之前进行路径规划,可以提高移动机器人的精度和效率[2]。路径规划的目的是根据评估标准,帮助移动机器人获得从初始点到目标点所需的运动路径[3]。并且机器人在这条路径上运动时不会相互碰撞,同时也会尝试优化路径[4]。当移动机器人完成各种任务时,还必须能够处理各种突发事件[5]。
路径规划算法有蚁群算法、粒子群优化算法和遗传算法[6-8],使用上述算法进行路径必须事先知道完整的环境信息[9],而强化学习不同,其学习过程是动态的,是不断与环境相互作用的,故使用强化学习进行路径规划不需要事先知道完整的环境信息。因此,强化学习涉及许多对象,如动作、环境、状态转移概率和奖励函数。强化学习中最广为人知的算法是时间差分(TD)算法[10]。时间差分算法在动态规划中借鉴了自举法,在实验结束前估计出值函数,以加快学习速度,提高学习效率。TD 算法主要包括异策略的Q 学习和同策略的Sarsa 算法[4]。
2017 年,SHARMA A 等提出了一种利用Q学习算法的多机器人路径规划协作方法[11]。在Holonic 多智能体系统上,对原有的Q 值表进行改进,添加协同更新策略,使环境中的机器人可以通过自身经验学习,同时也可以学习其他机器人的经验。实验结果表明,该算法能够利用多机器人协作解决未完成或未知环境下的路径规划问题。Q 学习算法能适用于未知环境地图下的路径规划,是因为其迭代过程是一个试错和探索的过程。
虽然Q 学习具有这些优越的特性,但它仍然存在收敛速度慢的缺点[12]。以上研究并没有提高Q 学习算法的收敛性。为了加快Q 学习算法的收敛速度,本文引入了方向奖惩机制和估价函数,以优化Q学习算法的奖励机制。
1 强化学习算法简述
1.1 强化学习模型
智能体通过选择动作与未知环境进行交互,完成路径规划。智能体在动作和环境的影响下会获得一个新的状态。同时,环境也会给智能体一个奖励值。智能体在使用不断更新的数据优化动作策略后,继续与环境交互以获取新的数据。之后,智能体使用新数据进一步优化行为策略[4]。强化学习模型如图1 所示。
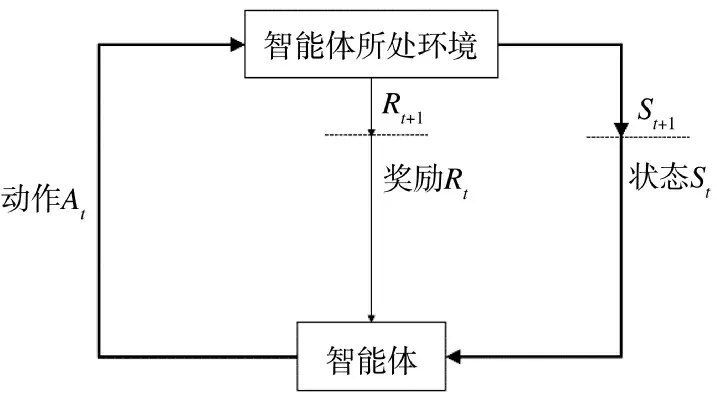
图1 强化学习模型Fig.1 Reinforcement learning model
强化学习算法可以分为基于值函数的、基于策略的和基于模型的3 种算法,Q 学习算法是一种基于值函数的算法[4]。
基于值函数的算法从如何评估策略的质量开始。为了更简洁、更方便地评估策略的质量,引入了奖励机制。在智能体选择每一个动作后,都会获得奖励。其过程如下:在初始状态下,智能体选择一个动作,然后智能体从环境中获得一个奖励值,在完成此操作后,智能体将获得一个新的状态。在这种状态下,智能体选择下一个动作,并将从环境中获得奖励值。完成移动后智能体将获得一个新的状态。这个过程依次循环,直到智能体到达最终状态[4]。
1.2 马尔科夫决策过程

1.3 经典Q 学习算法
Q 学习算法是马尔科夫决策过程的一种表达形式,Q 学习算法会学习特定状态下特定动作的值。利用Q 学习算法构建一个Q 表,以状态为行,动作为列,Q 学习算法根据每个动作的奖励值更新Q表[4]。Q 学习算法是一个异策略算法,这意味着行动策略和评价策略是不同的。Q 学习中的动作策略为ε-greedy 策略,而更新Q 表的策略为贪婪策略[4]:
贪婪策略:

Q 学习算法输出的是所有的状态-动作的值函数Q(St,At),Q(St,At)的值由式(3)进行更新:
式中,St为当前状态,At为在St状态下执行的动作,Rt+1为通过状态St执行动作At获得的奖励,St+1为下一个状态,a 为能选择的动作集。α 为学习因子,控制Q 学习算法的学习速度,0<α<1。γ 表示折现系数,表示后一行为对当前状态奖励的影响较小,且0<γ<1。经典Q 学习算法如表1 所示。

表1 经典Q 学习算法Table 1 Classical Q-learning algorithm
2 DE-Q 学习算法
Q 学习算法的优点在于不需要先验地图,缺点在于收敛速度过慢,为了加快Q 学习算法的收敛速度,本文提出在经典Q 学习算法的基础上,加入方向奖惩机制,同时引入估价函数以优化Q 学习的奖惩机制。
2.1 方向奖惩机制
使用Q 学习算法进行路径规划时,为了加快Q学习算法的收敛速度,引入方向奖惩机制以改进Q学习算法的奖励矩阵。以移动机器人运动的起始点在栅格地图的西北角,目标点在栅格地图的东南角为例,改进后的方向奖惩机制如式(4)所示:
rewarddirection表示移动机器人在进行动作选择时的方向奖励值,通过设置rewarddirection使得移动机器人选择趋向于目标点的动作。
2.2 估价函数
在传统的Q 学习算法的基础上,引入估价函数,以加快Q 学习算法的收敛效率。估价函数的主要作用是建立移动机器人的动态位置和起点、终点的位置之间的关系,如式(5)所示:
式(5)中,f(N)表示估价函数的值,将其作为Q 学习算法的奖励值,N 表示移动机器人当前位置的栅格编号,αe和βe为估价函数的权重因数,ps 表示移动机器人在当前位置到起始点的欧式距离,pe 表示移动机器人在当前位置到终点的欧式距离。nx和ny分别表示移动机器人当前位置的横、纵坐标,Sx和Sy分别表示移动机器人运动轨迹起始点的横、纵坐标,Ex和Ey分别表示移动机器人运动轨迹终点的横、纵坐标。
在使用Q 学习算法对移动机器人进行路径规划时,移动机器人的动作选择为离散的8 个可行方向,ps 计算了移动机器人沿可行方向到达的位置与移动机器人路径起点位置的欧氏距离,ps 的值越大说明移动机器人距离目标点越近。pe 计算了移动机器人沿可行方向到达的位置与移动机器人路径终点位置的欧氏距离,pe 的值越小说明移动机器人距离目标点越近。为了防止pe 对于估价函数的影响过大,引入了权重系数αe与βe。
文献[9]中提出的激励函数仅使移动机器人接近目标点,即仅连接智能体与目标点的位置信息,估价函数在此基础上不仅能使移动机器人接近目标点,还能使移动机器人远离起始点。
2.3 DE-Q 学习算法
移动机器人在运动环境中运动时,如果区域可行环境奖励值为1,如果区域不可行则环境奖励值为-100,到达目标点则环境奖励值为20,如式(6)所示:

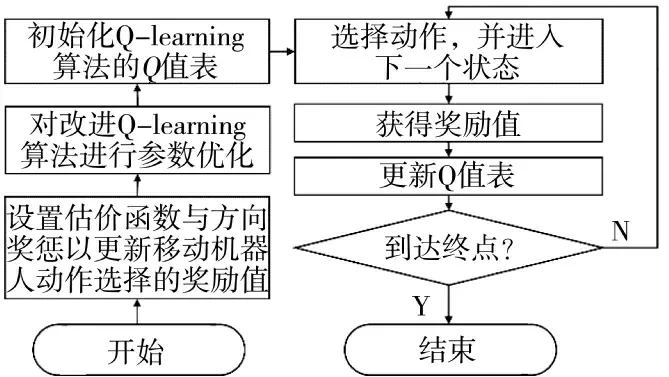
图2 DE-Q 学习算法流程图Fig.2 The flowchart of DE-Q-learning algorithm
移动机器人在使用Q 学习算法时优选奖励值更大的动作,DE-Q 学习算法优化了Q 学习算法动作选择的奖励机制,使得移动机器人趋向于目标点的动作奖励值增大,从而提高了Q 学习的收敛效率。
3 仿真实验及结果分析
为了说明改进算法的优越性,使用MATLAB 对经典Q 学习算法,Dir-Q 学习算法,Eva-Q 学习算法以及DE-Q 学习算法进行仿真模拟,并进行对比,其中,Dir-Q 学习算法为仅通过方向奖惩机制改进Q学习的奖励机制,Eva-Q 学习算法为仅通过估价函数改进Q 学习的奖励机制,DE-Q 学习算法为同时通过方向奖惩机制与估价函数改进Q-学习的奖励机制。现对两种复杂程度不一的地图进行仿真模拟。
现对如图3 所示的移动机器人运动环境进行仿真实验。
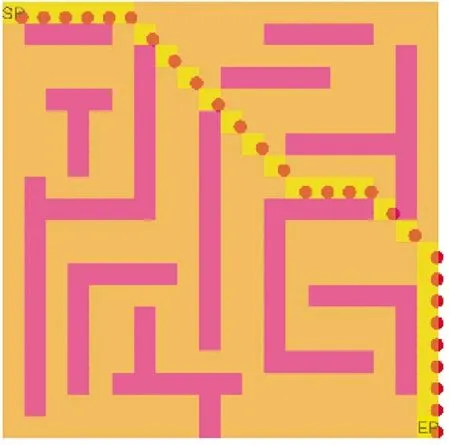
图3 移动机器人运动环境与最短路径Fig.3 Motion environment and shortest path of mobile robots
对图3 进行50 次路径规划算法模拟仿真实验时,其达到收敛时的次数如表2 所示。
表2 中,Num 即为50 次实验中算法达到收敛时的学习次数。方向奖惩机制与估价函数提高了Q学习算法的收敛速度。DE-Q 学习算法在图3中的收敛效率较经典Q 学习算法提升了24%以上。

表2 Q 学习算法达到收敛时的次数Table 2 The number of times when Q-learning algorithm reaches convergence
由于移动机器人需要对环境进行探索,因此,Q学习算法在进行动作选择时的策略为ε-greedy 策略,这说明移动机器人在进行动作选择时不总是选择奖励值最大的方向进行动作,为了探索环境,移动机器人也会选择其他方向进行移动,这就导致使用Q学习算法进行移动机器人路径规划任务时,最终路径趋近于最优路径。如图4 所示,在图3 中使用Q 学习算法,Dir-Q 学习算法,Eva-Q 学习算法,DE-Q 学习算法进行路径规划时,最优路径的长度为31.4,为了更好地说明Q 学习及其改进算法的收敛效果,设置移动机器人最优路径的收敛区间为len∈[31.4,35]。现从50 次重复实验中,随机挑选一次仿真实验的结果,如图4 所示,该次实验收敛效率提升了60%。

图4 规划路径长度变化趋势Fig.4 Changing trend of planned path length
如图4 所示,Dir-Q 学习算法即为仅通过方向奖惩机制改进Q 学习的算法,Eva-Q 学习算法即为仅通过估价函数改进Q 学习的算法,DE-Q 学习算法即为同时通过方向奖惩机制与估价函数改进Q学习的算法。其中,使用DE-Q 学习算法进行路径规划时的收敛效果最优。
为了证明地图的非特殊性,现对如图5 所示的移动机器人运动环境进行仿真实验。
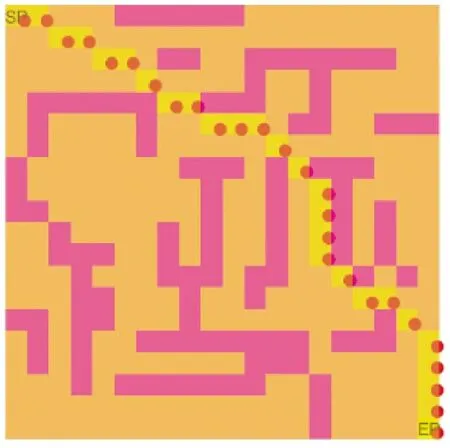
图5 移动机器人运动环境与最短路径Fig.5 Motion environment and shortest path of mobile robots
对图5 进行50 次路径规划算法模拟仿真实验时,其达到收敛时的次数如表3 所示。

表3 Q 学习算法达到收敛时的次数Table 3 The number of times when Q-learning algorithm reaches convergence
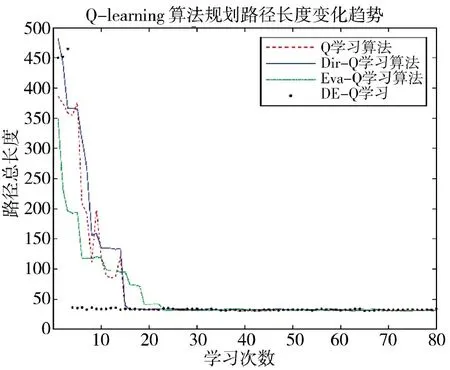
图6 规划路径长度变化趋势Fig.6 Changing trend of planned path length
上述实验说明对于障碍物较规整的地图与障碍物较随机的地图而言,DE-Q 学习算法均提高了Q 学习算法收敛效率,并且DE-Q 算法的收敛速度最快,同时相较于Dir-Q 学习与Eva-Q 学习而言,DE-Q 学习算法的鲁棒性更优。
4 结论
文中针对Q 学习算法收敛速度过慢的情况,提出了方向奖惩机制与估价函数以改进奖励机制,从而达到加快Q 学习算法收敛的目标。同时使用MATLAB 进行仿真分析,在两种复杂程度不一的地图中,对Q 学习算法,Dir-Q 学习算法,Eva-Q 学习算法,DE-Q 学习算法进行仿真模拟实验,实验结果表明在不同的环境中,方向奖惩机制与估价函数都加快了Q 学习算法的收敛效率。DE-Q 学习算法具有更快的收敛速度和更优的鲁棒性。
