基于注意力机制的兵棋对抗态势预测方法*
2023-05-19陈锦阳郝文宁靳大尉余晓晗
陈锦阳,郝文宁,靳大尉,陈 刚,余晓晗
(1.陆军工程大学,南京 210000;2.解放军77606 部队,拉萨 850000)
0 引言
兵棋是运用规则、数据和程序描述实际或假定的态势,对敌对双方或多方的军事行动进行模拟的统称[1],是典型的非完全信息博弈。由于进入不通视地域、超出我方算子观察能力、进入隐蔽地形等原因,陆战场战术级兵棋中部分存活的敌方算子处于不可观察状态。对抗态势是指对抗各方通过实力对比、调配和行动等形成的状态和趋势[2]。本文研究的兵棋对抗态势预测即基于已观察状态预测不可观察状态和趋势,为下一步任务规划、路径规划等环节缩小搜索空间,增加决策的预期收益。
兵棋对抗态势预测中常需要考虑众多分类特征,分类特征进行独热编码后,特征向量稀疏高维,难以捕捉稀疏高维特征向量中具有预测价值的不同特征域间高阶交叉作用。以往需要专家经验人工设置有意义的特征交叉。近年来,出现了一系列自动学习捕捉特征交叉的模型,如FM[3]、Wide&Deep[4]、Deep & Cross[5]、DeepFM[6]、Autoint[7]等。Transformer 利用注意力机制在破解长距离依赖问题、发现重要特征方面取得了重大进展[8],有潜力发掘兵棋态势特征。
本文主要研究相关特征交叉技术在兵棋对抗态势预测中的应用,提出基于陆战场战术级兵棋注意力模型——LBTWAM(land battlefield tactical wargaming attention model)的兵棋不可观察算子实时位置预测方法。以兵棋不可观察算子实时位置预测这一子问题为例,探讨注意力机制在兵棋对抗态势预测中的应用。通过对输出层和特征的调整,模型也能够解决兵棋态势预测中的其他问题。例如将输出层改为二分类学习器,即可根据兵棋实时态势预测对局胜负等二分类信息;将输出层改为回归学习器,即可预测选手最终打击分、净胜分等数值信息;改为多分类学习器,则可预测算子机动终点[9]。
1 不可观察算子位置预测
陆战场战术级兵棋不可观察算子位置预测是兵棋对抗态势预测中的重要内容。即给定算子细分类型、基础速度、分值等N 个特征域,将它们拼接成特征向量x∈RN。根据特征向量x,预测算子出现在各个六角格的概率f(x),后者如式(1)所示,是一个和为1,长度为地图六角格个数G 的向量函数。
本文将预测问题的真实标签进行独热编码。设想定地图中有G 个六角格,此时算子在各个点出现情况即真实标签向量y。当某一秒算子位于想定地图上按行展开的第g 个六角格时,y 为第g 个分量为1,其余分量皆为0 的向量。
为了避免给分类属性引入不存在的“序”关系,对x 中分类特征值进行独热编码。同时对数值型特征值进行最大最小归一化。这使得x 成为一个高度稀疏的长度为Ns,非0 分量位数大于等于N,N<<Ns的向量xs。当x 中有“携带武器类型:便携导弹、步兵轻武器、火箭筒”这样的多热分类特征域时,xs中非0 分量位数可能大于N。可将此类多热分类特征域当作多个独热分类特征域处理,为便于讨论,本文只使用独热分类特征域。即有Ns个稀疏态势特征域,每个样本即兵棋引擎返回的N 个特征域的N 个特征值。例如特征域“算子细分类型”的特征值可能为“重型坦克”。设x 中有α 个分类型特征域,β 个数值型特征域,第i 个分类特征域xi有特征值个,则特征域xi对应xs中的位分量,有:
将稀疏态势特征向量xs输入线性回归学习器等学习器时,在小样本条件下,预测方程组为欠定方程组,系数矩阵有无穷多组解。给定相同的特征向量,系数矩阵不同的解将给出不同的预测值。即学习器容易发生过拟合,难以学到有意义的系数矩阵,学习器泛化能力不足[10]。此外,特征交叉对于预测算子位置具有重要意义,即预测方程中要考虑特征交叉项。特征交叉额外增加了需要估计的权重值数目,更加剧了过拟合问题。
近年来,矩阵分解[11]、因子分解机[3]、注意力机制[7-8]等方法在自动特征选择、防止过拟合和自动组合高阶特征交叉等方面取得了明显成果。本文给稀疏特征向量xs中每个分类特征值学习一个低维嵌入向量,解决特征向量高维稀疏带来的过拟合问题,并用注意力机制学习特征交叉对预测结果的影响。
2 模型架构
如下页图1 所示,将兵棋复盘数据进行预处理,整理算子位于图1 右下角的“战争迷雾”时,其他可以确定的特征,得到算子兵棋特征向量,将向量中各个分量进行低维嵌入。嵌入向量进入4 层带残差连接、层正则化(Add&Norm)的多头自注意力(MHA)模块和前馈全连接(FFN)模块组成的特征交叉层(interacting layer)。特征交叉后的特征嵌入向量经过ReLU 激活和全连接层(FC)转换得到G 个输出,最后通过Softmax 激活函数得到G 个六角格上的预测值,降低算子实时位置的不确定性。
2.1 数据预处理层
从逐秒返回的战场态势信息中,抽取博弈对手对不可观察算子能确定的相关特征值拼接成特征向量x,并以此时该算子所在六角格的编号作为真实分类标签,生成数据集D。
2.2 嵌入层


2.3 特征交叉层



2.4 输出层
XRes在ReLU 激活后拼接成特征嵌入向量,通过输出维度为G 的全连接层(FC),得到长度为G 的输出向量。经过Softmax 激活得到不可观察算子实时位置位于各个六角格的预测概率。
2.5 训练优化

3 实验
3.1 实验设置
本文采用中科院自动化研究所发布的2020 年11 月砺智杯分队级人机对抗复盘数据(http://turingai.ia.ac.cn/data_center/show),包含对抗系统每秒给选手返回的兵棋态势信息。原始数据包含80 场共1 048 575 帧对局态势,比赛想定为连级水网稻田地形遭遇战斗想定,地图尺寸为92*77,共有7 084 个六角格。实验选取55 盘红蓝双方打击得分均在30分以上的高质量对局,共737 478 帧。由于同一盘对局中相近时间内特征态势相似程度较高,本文以对局为单位选择40 盘训练集、10 盘验证集、5 盘测试集,进行5 折交叉检验。梳理表1 所示算子ID 等14个特征域。带“*”号特征域为特征值多于3 的分类特征域,带“#”号特征域为布尔型或三值分类型特征域,其余特征域为数值型特征域。由于多头自注意力机制能自动发现和组合有预测价值的相关特征,实验不进行交叉特征人工设置。

表1 模型使用的特征域Table 1 The feature domain used by the model
为测试模型分类准确度,本文以SVM、KNN、逻辑斯蒂回归等传统分类算法和Wide&Deep 等推荐系统算法为对照进行对比试验。以样本的标签值落在模型的预测值最高的前1、5、10 个六角格内的概率作为准确率的衡量。本实验计算机主要配置为:CPU:Intel Xeon Gold 5218R CPU 2.1 GHz*6;内存:32 G;显卡:Tesla v100-PCIe。编程语言为Python,使用的计算框架为PyTorch,优化方法为ADAM,主要超参数如表2 所示。

表2 主要超参数设置Table 2 Major hyperparameter settings
3.2 实验结果
3.2.1 不同模型的对比
实验结果如表3 所示。其中,KNN、LR、SVM 算法将分类特征进行独热编码,将数值特征值除以该特征域最大值特征值,再将两类特征进行拼接,组成所有分量都在0~1 之间的特征数据集,最后利用scikit-learn 软件包进行分类。Wide&Deep 等算法自动学习高维组合特征,准确率高于传统分类算法。从图3 中可以看到LBTWAM 对不同算子的预测准确度,坦克、战车算子的预测准确度较高,说明不同选手对它们的应用方法较为一致。红方步兵算子的预测准确度高于蓝方步兵算子的预测准确度,说明蓝方两个步兵算子可互相交换任务,增加预测复杂度。蓝方坦克、战车算子的预测准确度没有因此降低,它们作为该兵棋中重要的火力来源,常出现在对方观察区域内,比运动速度慢、更易隐蔽的步兵算子拥有更多的特征信息(表1 中12、13、14号)。红方巡飞弹1 的预测准确度高于巡飞弹2,推演规则规定必须先发射巡飞弹1,巡飞弹1 击中目标或超出存活时间后方能发射巡飞弹2,巡飞弹作为该想定中机动速度最快的算子,飞行期间位置预测困难的情况相吻合。巡飞弹2 在未发射时随战车机动,呈现与战车接近的预测准确度。

表3 对比实验结果Table 3 Comparative experimental results
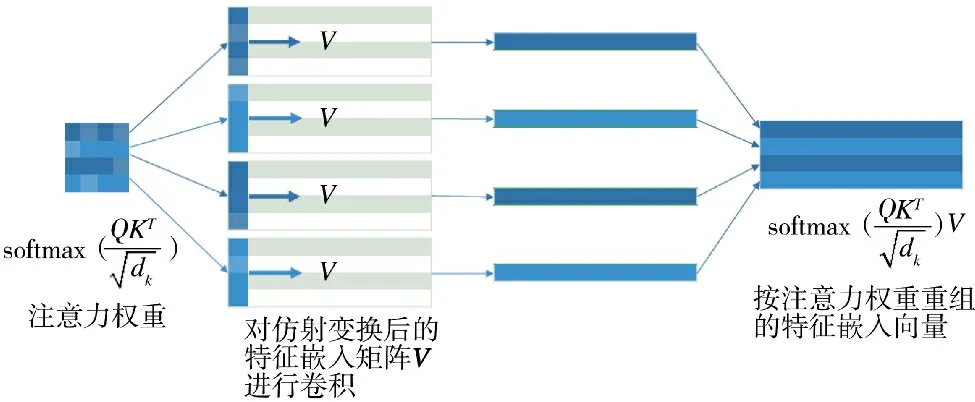
图2 利用特征交叉得到的注意力权重重组特征嵌入矩阵Fig.2 Reorganize the feature embedding matrix by attention weights obtained by feature crossing

图3 不同算子的预测准确度Fig.3 Prediction accuracy of different operators
3.2.2 超参数的影响
为探究不同的嵌入维度、交叉层数、注意力头数量对LBTWAM 学习和泛化能力的影响,本文对上述3 个变量进行了对比实验,模型在验证集上的Top1 预测准确率如表4 所示。可以发现兵棋态势特征合适的嵌入维度相对自然语言中的子词(token)较低,说明兵棋态势特征的多样性和语义信息不如自然语言字词丰富。对比不同交叉层数的准确率发现交叉层数过高时,模型出现过拟合。多个注意力头能在多个投影空间捕捉不同的注意力关系,有助于提高模型泛化性。但每个注意力头下的嵌入维度也需要维持一定长度以保持表示能力。

表4 超参数对比实验结果Table 4 Comparison experimental results of hyperparameters
3.2.3 消融实验
从下页表5 可知,在LBTWAM 模型的基础上,分别去除残差连接模块和前馈全连接模块,和原模型进行对比。LBTWAM-Res 和LBTWAM 的比较,说明残差连接模块对预测准确度有贡献,证明学习奇阶特征交叉能提高模型准确度[7]。LBTWAM-FFN和LBTWAM 的比较,说明FFN 发挥了进一步提取特征的作用。

表5 不同LBTWAM 网络的测试准确率Table 5 Test accuracy for different LBTWAM networks
3.2.4 嵌入向量学习情况分析
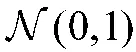
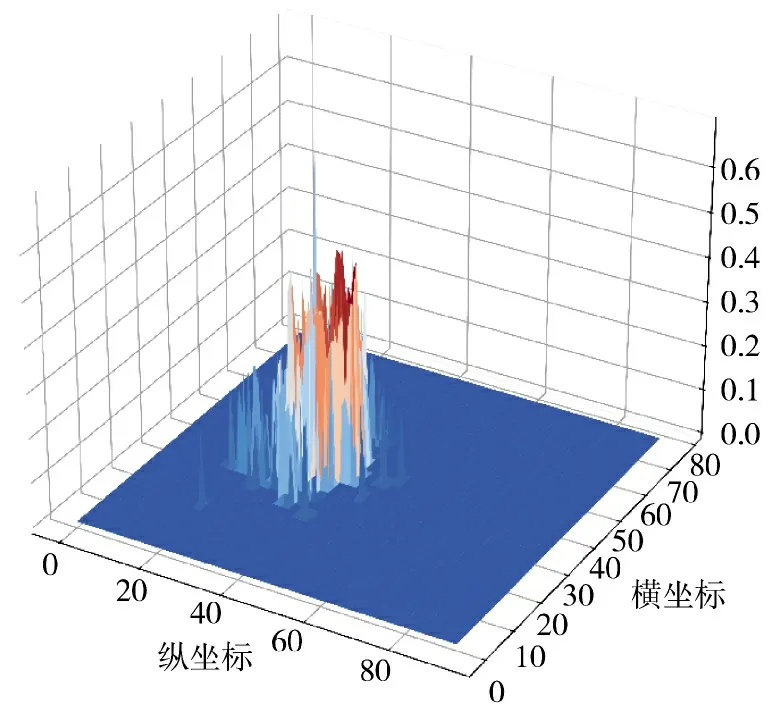
图4 训练完时“消失前被观察到的位置”特征嵌入向量的范数分布情况Fig.4 The norm distribution of the“position observed before disappearing”feature embedding vector at the end of training

图5 训练完时“消失前被观察到的位置”特征相邻六角格的嵌入向量的余弦相似度Fig.5 The cosine similarity of embedding vectors adjacent to the hexagonal lattice of the“position observed before disappearing”feature at the end of training
3.2.5 注意力可视化解释

图6 一个样本对应的注意力权重Fig.6 The attention weight corresponding to one sample

图7 该样本对应的对抗态势Fig.7 Confrontation situation corresponding to this sample
4 结论
本文以兵棋不可观察算子实时位置预测这一子问题为例,探讨了注意力机制在兵棋态势预测中的应用。将兵棋地图的各六角格视为单独的类,将算子位置预测转化为稀疏特征下的多分类问题,对高维稀疏的兵棋态势特征进行低维嵌入,用多头自注意力机制学习特征交叉,以多分类概率实现不可观察算子实时位置预测,预测准确度高于经典分类算法和推荐系统类算法,并具有良好的可解释性。揭示了不同算子位置预测准确度的特点和影响规律,指出预训练特征嵌入有望提高态势预测准确度。
