融合机器翻译与复述生成的手语文本生成方法
2023-05-16李世炜侯霞汪良果
李世炜,侯霞,汪良果
(北京信息科技大学 计算机学院,北京 100101)
0 引言
手语是一种通过视觉去理解的自然语言。为了方便失聪或失语的特殊人群,有些新闻节目有专门的手语播报员进行同步的手势翻译。但是在进行翻译时,由于人工手势动作相对新闻语音较慢,往往难以做到与新闻同步,会造成部分内容的丢失。随着人工智能技术的发展,人们开始探索手语自动生成的技术。根据新闻文本自动生成对应的手语,并通过虚拟人进行展示,可突破人工手势动作速度的局限性,极大提高手语生成效率。
当前手语方面的主要研究包括手语识别[1]、手语翻译[2-3]与手语生成[4-5]。其中,手语识别与手语翻译的任务目标是将手语视频翻译为对应的文本词汇或语音。手语生成的研究内容是将常规文本或语音翻译为手语视频。手语生成任务的研究方法分为两种:第一种是直接进行端到端的手语视频生成。该方法比较直接,但是在训练时需要精确捕捉相应手势动作,并且难以编辑;第二种是先将常规语言的文本翻译为手语文本,然后根据手语文本生成视频的两阶段方法,由于手语文本单词可以与对应的手语图片映射,因此相比第一种方法大大缩减了捕捉动作所需要的成本[6]。
在手语识别的分阶段方法中,手语文本的生成质量是影响手语视频生成的重要因素。本文重点研究从汉语文本到手语文本的生成,本质是一种机器翻译任务。经过调研总结,当前手语机器翻译的研究难点有如下三点:
1)任务目标不完全相符。常规机器翻译任务是两种不同语种之间映射,且两种语言各自符合自己的语法规则。而从汉语文本到手语文本的翻译存在一些特殊性。分析汉语文本和相应的手语文本后可知,汉语文本与手语文本使用同一种语言进行表示,相较于机器翻译中不同种语言来说在表达上存在更多的相似性。但是,手语文本比汉语字词更精简,且可能并不符合汉语语法。这些特点使得不同语言间的机器翻译方法直接应用于手语文本生成时并不能获得预期效果。
2)语料较少。虽然我国在2018年出台了《国家通用手语方案》,但是普及情况不够乐观,例如不同的省份甚至会有其手语的“方言”。其次,在《国家通用手语方案》中收录词汇仅有8 000多个,仍然有大量的词语未进行标准化规定。例如,汉语中“元素”一词,手语中并没有其相关翻译,也没有邻近词进行替换,在手语翻译中只能对其用逐字翻译的方式进行翻译,将“元”用“元帅”来代替,“素”用“荤素”来代替。最后,由于手语学习者较为匮乏,且与手语使用者沟通难度较大,导致数据集构建困难,数据集的缺少使得研究较难开展。使用语法与词汇的不统一也加大了数据集构建的难度。
3)现代汉语与手语的语法存在差异。目前,很多手语受众将不接受电视手语新闻的原因解释为“担任手语新闻翻译的播报员使用的手语不规范”[7],而没有认识到主要原因在于电视手语播报员使用的不是手语受众的自然手语,而是手势汉语,这证明即使是人工翻译,也未考虑到手语中实际的语法规则。由于人工智能方法自动生成的手语在进行生成算法中往往会学习到目标语言的语法等句子特征,因此产生的输出结果也会对手语使用者更加友好。
复述生成是自然语言处理领域的一个经典任务,研究内容是同一语言之间两个语句的同义转换,与手语文本生成相似。所不同的是,复述生成任务的源语言和目标语言是完全相同的语言,具有一致的语法和表达习惯,使得复述生成模型不需要构建语法空间的转换。
本文的研究目标是汉语文本到手语文本生成,其特点在于汉语文本与手语文本使用同一种语言,但是又遵循不同的语法。根据机器翻译能够实现不同语法空间转换、复述生成能够实现同种语言改写的特点,本文提出一种融合机器翻译与复述生成的手语文本生成方法,将手语文本的生成看成是语言翻译与复述生成的结合过程。首先是语法形式的转化,利用机器翻译方法将原始汉语文本转化为符合手语语法的中间表示;然后通过复述生成进行语言表述的转化,对中间结果进行修正,最后获得所需手语文本。
1 生成方法
1.1 模型整体架构设计
针对手语文本生成任务中汉语文本与手语文本都是由同一种语言文字构成但是语法并不完全相同的特殊性,本文以多语言双向和自回归转换器(multilingual bidirectional and auto-regressive transformers,mBART)模型[8]和质量控制转述生成(quality controlled paraphrase generation,QCPG)[9]模型为基础,通过融合和改进,提出一种融合机器翻译与复述生成的手语文本生成方法s-BPG(self-mBART with paraphrase generation),用于完成汉语文本到手语文本的生成。
模型整体思路如图1所示。首先,使用改进后的机器翻译模型将汉语文本翻译成汉语文本与手语文本之间的中间文本,数据在输入到翻译模型之前,先进行预处理。使用添加锚点的方法[10]对汉语文本与手语文本进行替换,减少两个文本之间的差异性,拉近语言距离,以达到加快模型收敛的目的。其次,使用字书对编码(byte pair encoder,BPE)[11]算法进行词表构建、语料编码/解码。为了使模型能够更好地计算关键词的信息特征,在原mBART的基础上添加一层自注意力层对模型进行改进,帮助模型将关键词的注意力得分与其他词汇更加准确地分离,改进后的模型我们称为self-mBART(self-attention in mBART)模型。翻译后的中间语句中包含了部分目标语言的语法信息,经过机器翻译后的文本与真实的手语文本的语法距离更加接近。然后,机器翻译生成的中间语句与手语标记文本形成伪平行数据集,作为复述生成的训练语料,通过质量控制的复述生成模型QCPG学习两种“语言”的词法、句法、语义等特征,对文本进行“修正”,最后生成所需的手语文本。但是原始的QCPG模型是应用于英文数据集的,为了使模型适用于中文,我们将其中的词法质量控制评分标准更换为更适用于中文的词嵌入(改进的QCPG模型命名为QCPG-WV模型)。
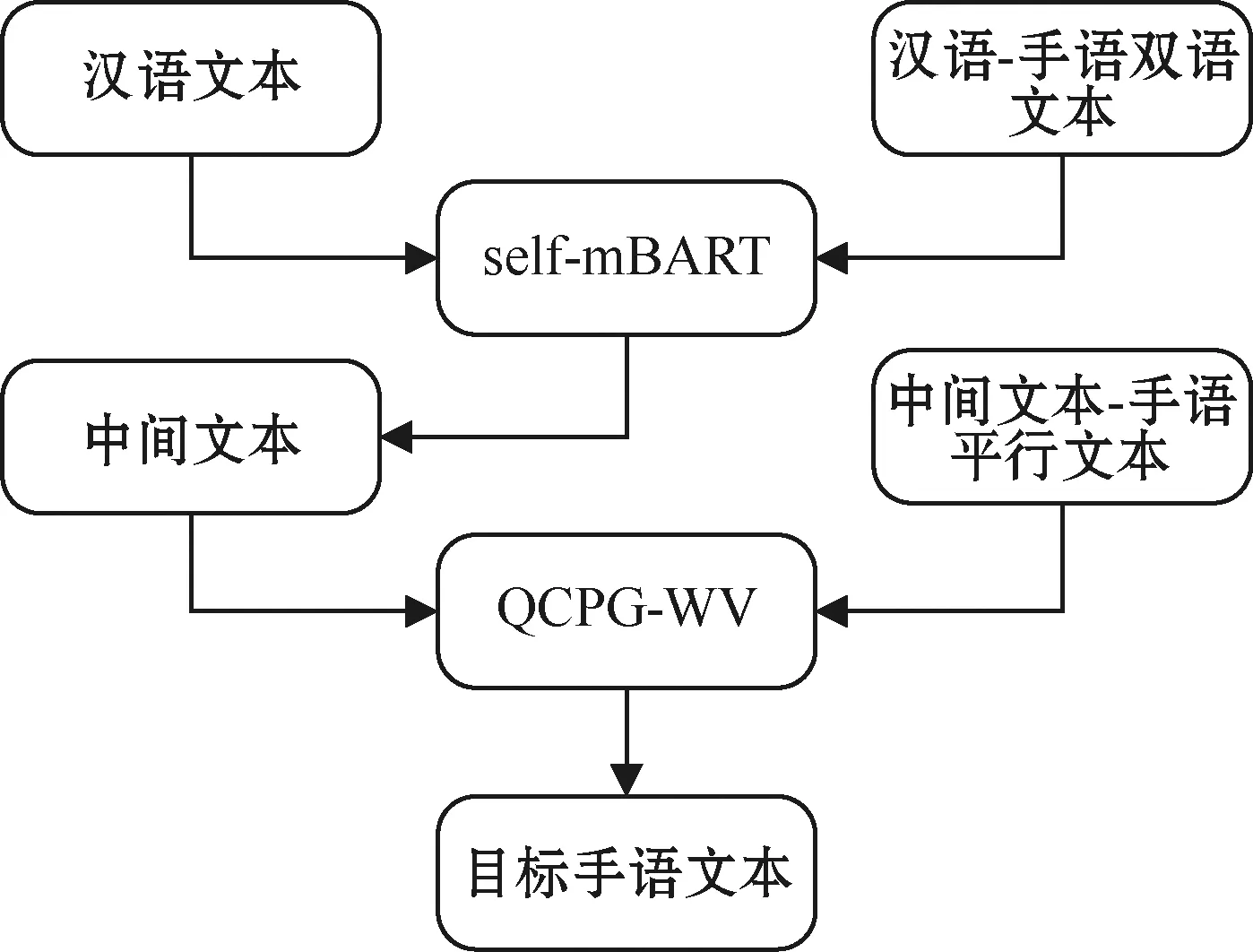
图1 模型流程
1.2 self-mBART的建立
本文提出一种改进的mBART模型——self-mBART模型进行第一阶段的初步翻译,模型结构如图2所示。在self-mBART模型中,首先将源语句与目标语句提取位置编码的词嵌入,这些嵌入被传递到一个屏蔽的自注意层,接下来为了增加模型对关键词的注意力,将上一层提取的表征输入到一层额外的自注意力层中。注意力计算如下:
(1)
式中:Q、K和V分别表示查询矩阵、键值矩阵和实值矩阵;dk表示特征维度。编码器(encoder)自注意力层的Q、K和V均来自于上一层解码器的输出。另外,这个注意力子层会接一个归一化层和残差网络,归一化层能够加快模型训练速度,残差网络能够防止神经网络模型退化。经过二次提取过的表征信息再通过一个非线性的前馈层作为解码(decoder)层的输入,上述的操作都要经过残差连接和归一化,至此模型学习完成。
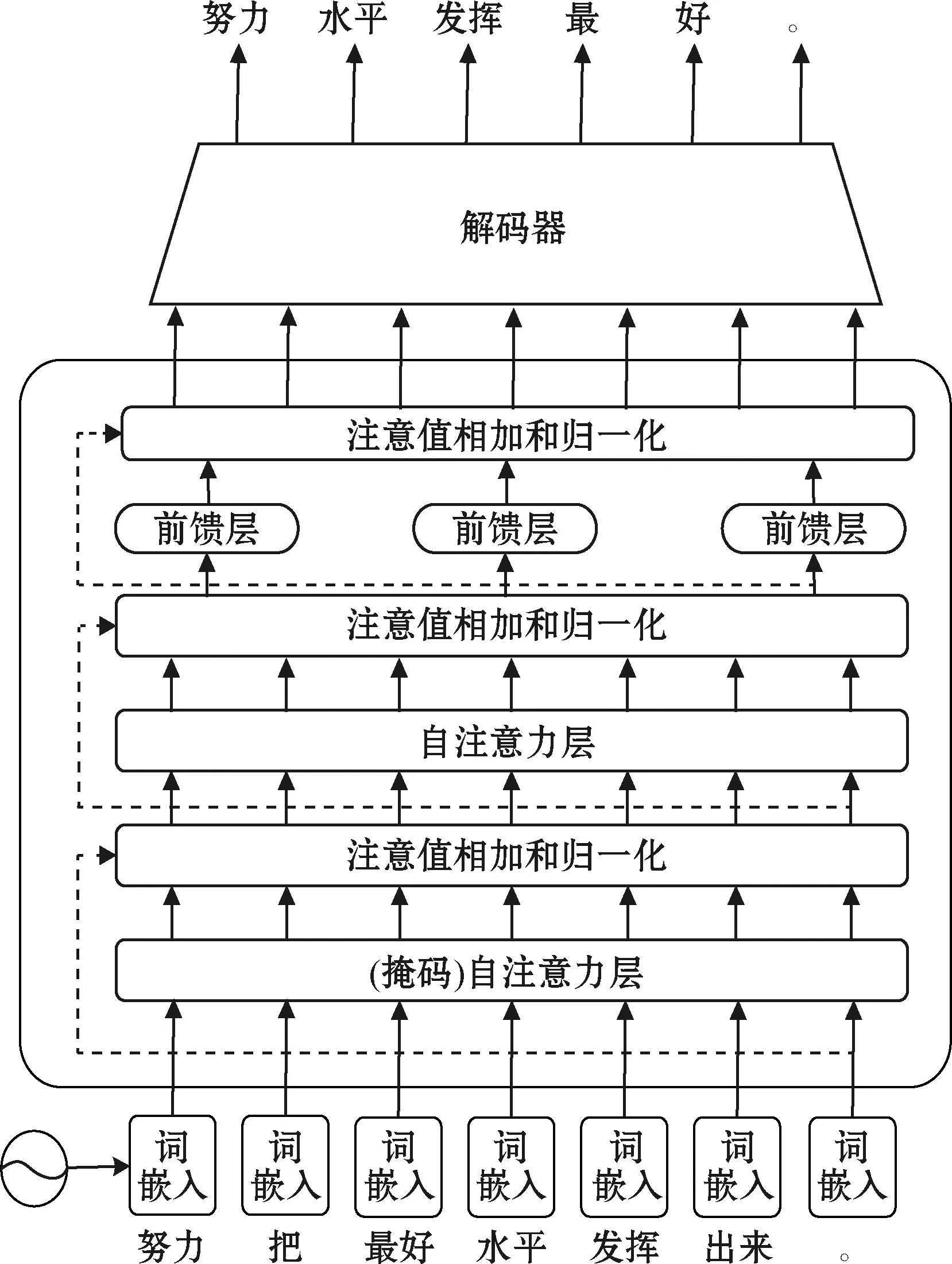
图2 self-mBART翻译模型结构
最后,使用训练完成的模型对源语句进行翻译,生成出的结果与原数据集中的目标语句共同构建成伪平行数据,用于后续复述生成部分的训练。
1.3 优化质量评价指标的复述生成模型QCPG-WV
由于手语有着独特的语法,因此在复述生成时,使用带质量控制的复述生成方法能够更多地考虑输入与输出的语法差异性。在质量控制生成语料的研究中,一个主要的挑战是选择适当的输入控制值,控制值不能仅仅根据经验选择或者多次实验进行调整,我们更希望能够寻找到一个简单有效而且能够根据源语句与目标语句进行控制值调整的方法。
词法、句法、语义是评价文本质量常用的三个方面,因此可以在这三个方面的评价中选择合适的评价指标作为控制质量的参数,由这三个方面的评价指标可以确定出一个三维控制向量对文本生成的质量进行控制。QCPG中使用的词法评价指标是根据Levenshtein算法来计算的,该算法是根据一个字串转化成另一个字串最少的操作次数来计算,操作包括插入、删除、替换,但是在中文使用时由于替换到相应的中文单词所需步骤往往较少,导致计算得到的分数差浮动范围过小,因此该方法并不完全适用。由于平均词嵌入之间求余弦相似度的方法中,并没有考虑词序问题,使其能够增加与句法指标之间的脱钩,这样的差别会使获得的三维向量差异性更大,不同得分的单词其向量空间也会因此更加精确,所以,我们将词法评价指标替换为词嵌入的余弦相似度。词嵌入余弦相似度按式(1)计算:
(2)
式中:θ为两个句子的相似度;xi和yi分别为源语句与目标语句的第i个单词的词频。
Iyyer等[12]使用解析树之间的归一化树编辑距离[13]来表示句法评价指标,证明了在释义生成任务中该评价指标是简单有效的,因此,我们将此方法作为本文质量控制指标中的句法评价指标;语法差异性评价指标使用BLEURT[14](该方法与人类判断的相关性最高),将结果使用Sigmoid函数进行归一化处理,以确保三个质量维度的统一值范围在[0,1]之间。
如图3所示,训练时,根据源语句与目标语句在语义等方面的差异计算出一组差异性评分,经过模型训练后获得各单词在不同评分下的分布。在测试阶段生成目标语句时,预测的单词按照文本在各个得分下的分布生成目标单词,并根据模型学习到的语义语序对句子结构进行重组后完成文本生成任务。
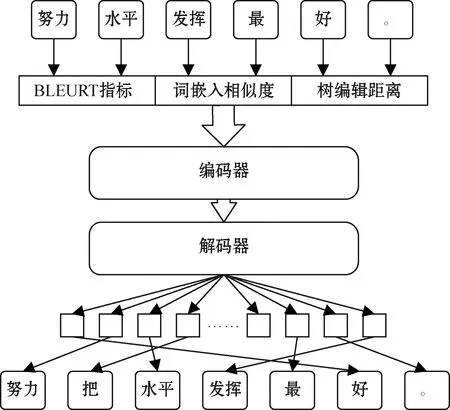
图3 QCPG-WV复述生成模型结构
2 实验
2.1 数据集
目前国内没有公开的中文手语数据集,因此本实验使用数据集为某公司人工构建的手语数据集。数据集中的汉语文本数据来源于体育新闻,对应的手语文本由人工翻译,并由手语专家进行评分。各位专家对手语文本评价时,统一用1~4分的标准进行打分。为了使模型具有一定的健壮性,数据集中包含一些较低评分的语句作为噪声。最终数据集包含27 000条汉语和手语对应的数据。表1是数据集中各评分等级的数据分布情况。

表1 各评分等级的数据分布
2.2 实验设置
本文提出的self-mBART是基于Large-50版本的mBART预训练模型,模型的解码器和编码器层数均为12层,多头注意力层设置为16个注意力头,前馈神经网络维度是4 096,训练过程使用Adam优化器进行优化,学习率设置为10-5,dropout设置为0.1,激活函数使用常规的GELU函数。
本文构造的伪平行数据集是由上一步中输出的结果与原数据集中的目标语句共同组成,在算出得分后,放入到QCPG-WV模型中进行训练。其中QCPG-WV中使用的encoder-decoder模型是self-mBART模型,结构与翻译模型中相同。
2.3 对比实验
由于本文实验的任务目标本质上是机器翻译任务,因此,将Transformer、mBART、mT5、ByT5几个经典翻译模型作为对比模型。同时,由于模型中也使用了复述生成模型QCPG,因此,将QCPG模型也作为对比模型。
Transformer[16]模型是基于多头自注意力机制的模型,近年来许多模型都是在Transformer的基础上进行改进而生成的。
mBART[8]模型在低资源语言上的机器翻译结果表现较好,较为适用于汉语文本到手语文本的翻译问题。
mT5[17]模型是统一模型框架,用于处理多种自然语言处理(natural language processing,NLP)任务。针对本文任务微调后,使用该模型可以进行手语文本的生成。
ByT5[18]模型是字节级的翻译模型,对噪声更加具有鲁棒性。
QCPG[9]模型是使用质量控制生成的复述生成模型,在句法,词法和语义层面对生成的意译语句进行控制。
本文在手语数据集上测评了模型效果。评价指标使用机器翻译领域内较为权威的BLEU和ROUGE。BLEU从生成结果与目标语句的准确率方面进行评价,是一种与语言无关且与人类评价结果高度相关的评价方法。与BLEU相似,ROUGE也是衡量生成结果和标准结果的匹配程度,不同的是ROUGE基于召回率来进行评价。
表2给出了本文模型与其他模型的对比结果。
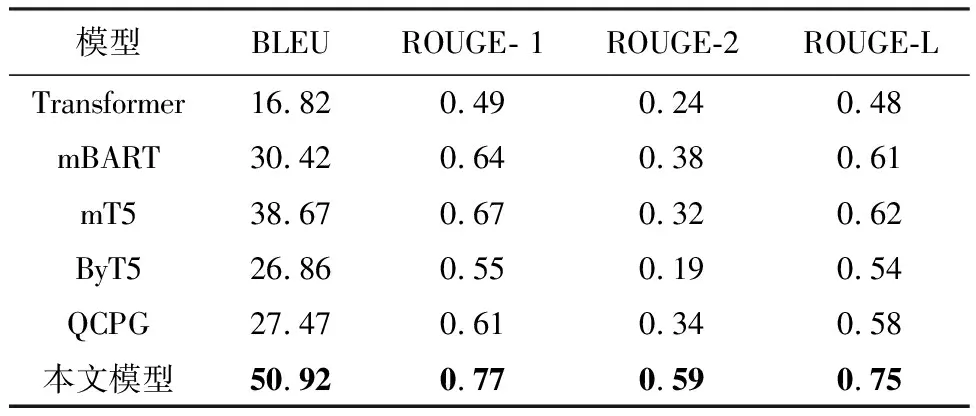
表2 模型结果对比
从表3可以看到,传统Transformer模型表现欠佳,BLEU和ROUGE-L,ROUGE-1,ROUGE-2四个指标都小于其他模型。mBART模型的翻译结果从BLEU与ROUGE-L两个指标来看相比于Transformer模型都有较大的提升,在加入了Attention层之后,mBART效果有了略微提升。而仅仅使用QCPG的复述生成模型时,结果甚至不如mBART。
本文提出的方法,无论BLEU和ROUGE相关指标都比其他方法有较大的提升。ByT5模型虽然具有鲁棒性,但是由于模型更关注于字节级文本的生成,因此其更适用于短文本翻译,在本文实验的结果中表现并不理想。
2.4 消融实验
为了证明本文方法的有效性,进行了消融实验,实验结果如表3所示。由于self-mBART和QCPG-WV分别是根据mBART和QCPG模型改进的,因此将mBART与QCPG模型加入了消融实验中进行对比。

表3 消融实验结果对比
如表3所示,在mBART模型中加入了self-attention,由于其增加了模型对部分关键词的注意力,因此翻译的文本质量有小幅度提升。并且,由于将Levenshtein替换为更适合中文词法的单词词嵌入距离计算方法,使模型在控制生成文本的质量时获得更加有效的单词分布,帮助模型生成结果优于使用Levenshtein算法的质量控制模型。最后,融合机器翻译与复述生成方法的本文模型,使整体性能得到较大幅度的提升。
2.5 实验结果分析
在数据集中随机抽取两个专家评分高的生成样例来说明不同模型的手语生成结果,分别如表4和表5所示(表中的①、②是代表同一单词对应的不同手势)。
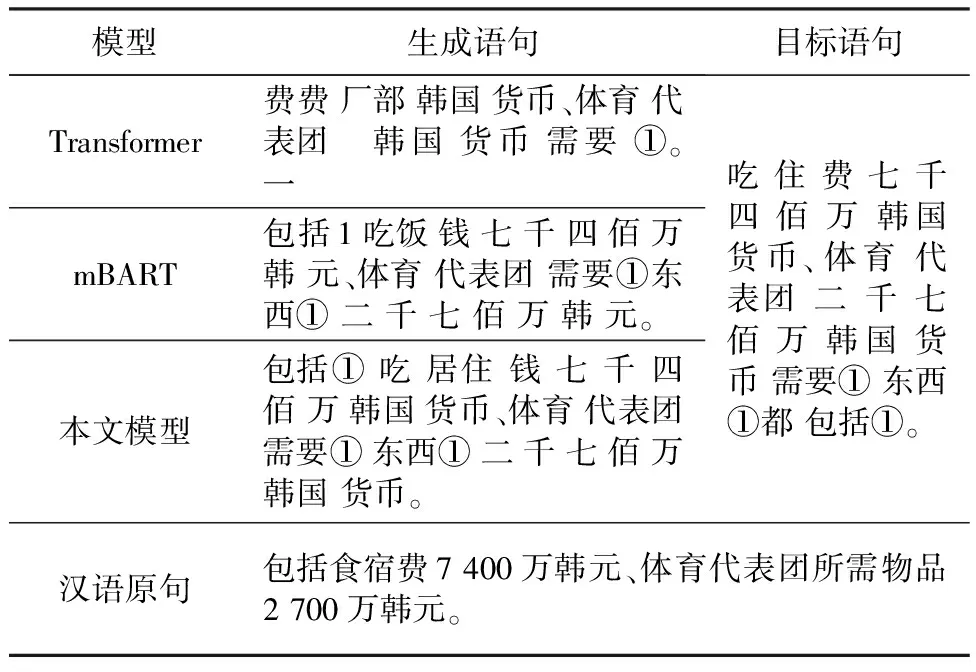
表4 生成结果1
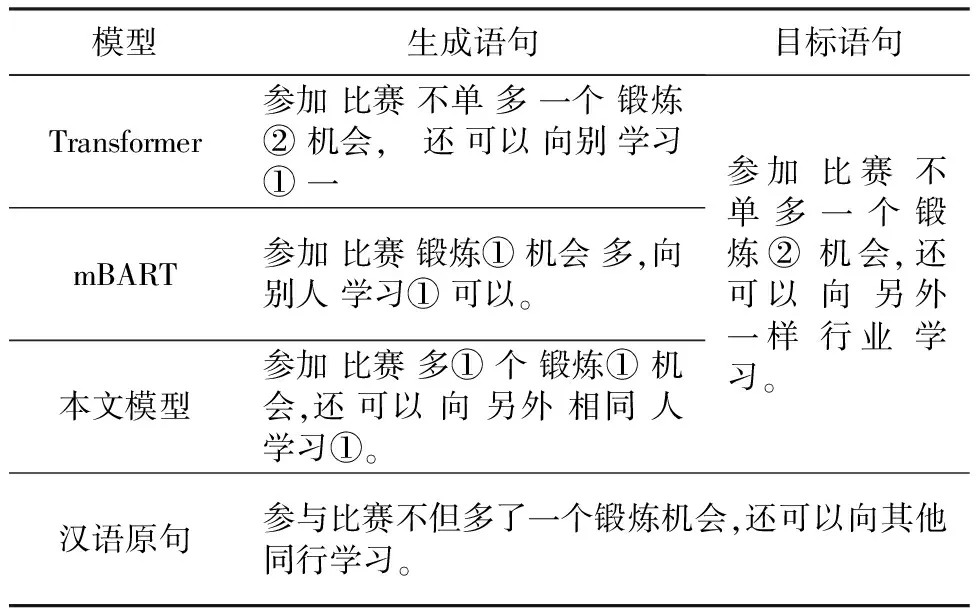
表5 生成结果2
由表4可以看出,采用Transformer模型生成的语句中,仅仅翻译出来了核心词“体育代表团”和“韩国货币”,其他词汇都没有翻译出来,效果较差;mBART在语义与基本词句上将原文较为完整的翻译出来,但是仍旧缺少“吃住”中的“住”这一概念,如果仅仅照此进行语义表达转述,会产生歧义;在本文提出的模型生成的文本中,将“包括”这一单词提前,并且将“吃住”这一合成词翻译成“吃”、“居住”,未影响语义,且没有语义信息丢失的情况。在表5的例子中,三个模型都没有将“行业”这一谓语翻译出来,从Transformer翻译的结果可以看出语句逻辑并不通顺,但是大致语义已经翻译出来了;mBART模型翻译的结果中,已经基本完全包含了所有语义信息,但是前半句与后半句的之间递进关系表达词“还”并没有翻译出来;我们的模型不仅翻译出来了递进关系的表达词“还”,也使翻译结果与目标语句的语序更加接近。
图4是本文模型的两个阶段中文本的变化。
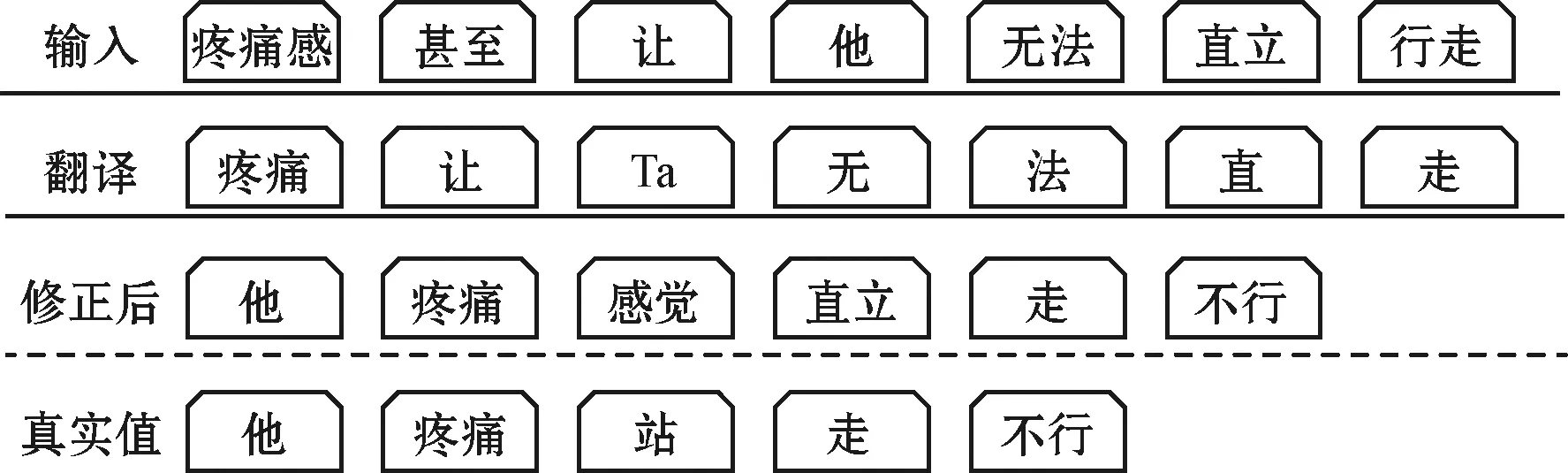
图4 文本生成过程
由图4可以看出,经过第一步翻译后,已经获得了初始的翻译结果,但是其中“无”“法”翻译成了两个独立的单词,不能表达出“不行,没有办法”的意思,且“直”与“直立”的意义也不相同,经过复述生成修正后,用“不行”来替换“无”“法”两个字,将“直”替换“直立”后更贴近真实值中“站”的意思。
由图4中生成的文本在不同阶段的变化可以看出,经过self-mBART模型翻译后,能够使语句中含有目标语句的大多数语义信息,只不过在语序与复合词翻译等细节存在一些差异。在复述生成任务中,输入与输出语句语义都需要接近,而经过初步翻译后的中间文本已经具备目标语句中的大部分语义,我们可以将汉语与手语之间的语序等差异视为不同“语法”表达的差异,这样一来,初步翻译出来的中间文本的结果与手语文本所构成的伪平行数据集更加符合复述生成任务的输入标准,使复述生成任务能够将第一步所生成的中间文本转换成更加符合手语语法的结果。
3 结束语
针对手语文本生成的特殊性,本文提出一种融合机器翻译方法与复述生成的手语文本生成模型,从中文原始文本出发,使用self-mBART机器翻译模型获取初步结果生成中间文本,然后通过改进的质量控制复述生成方法对中间文本修正得到所需的中文手语文本。实验结果表明,与基线模型相比,本文提出的融合机器翻译方法与复述生成方法从BLEU与ROUGE两个指标来看相比原mBART与QCPG模型都有较大幅度的提升,能够更好地生成符合语义的手语文本内容。
基于质量控制思想的QCPG包含句法、词法和语义三方面的评价。本文在改进时,仅对其中一个方面的评价指标进行了修改,当对三方面评价指标赋予不同权重时,会对最终效果产生影响。如何进行最优配置是有待深入研究的一个方面。
