基于车载数据k均值聚类的特种车辆行驶工况识别
2023-05-16赵津王立勇张金乐
赵津,王立勇,张金乐
(1.北京信息科技大学 机电工程学院,北京 100192;2.中国北方车辆研究所,北京 100072)
0 引言
为了提高特种车辆的性能及可靠性,通过采集车载传感数据,开展车辆关键部件服役状态评估研究是目前的重要技术途径。但由于特种车辆行驶环境恶劣、工况多变,传动系统的受力情况十分复杂,不仅受到来自动力系统的周期激励作用,还有来自路面的随机激励和车辆多种行驶工况对传动系统不同特征的冲击[1]。这些多变的工作环境,给车辆运行状态判别和寿命预测带来极大难度。
目前,车辆的行驶工况识别主要针对民用车辆,关注重点是速度-时间历程特征[2-4]。特种车辆的工况是一个十分宽泛的概念,工况识别需要综合考虑动力性和操纵性等多种因素[4]。根据驾驶员换挡操纵可将车辆工况分为换挡工况和稳态工况,复杂的运行环境会导致换挡操作十分频繁,而换挡过程中不同程度的换挡冲击,会使车辆传动系统的零部件产生很大的动载荷,降低其使用寿命[5];根据车辆直驶下速度状态可将工况分为加速、匀速和减速运行工况;根据车辆行驶过程中造成主要激励源的路面不平整度可以将工况分为平地工况和坡度工况;根据车辆转向控制系统状态可将工况分为直驶工况和转向工况。
本文基于车载数据主要研究挡位工况、运行工况、坡道工况和转向工况的特征参数计算方法;通过对数据进行消噪处理,利用自上而下分割算法对数据进行短时序片段划分;最后提出一种基于k均值(k-means)的聚类方法,实现对特种车辆4种行驶工况的识别。
1 工况分析及特征参数计算
本文行驶工况判别基于多种传感器采集得到的车载数据,包括动力装置、传动装置、操纵装置和行动装置等机械或液压系统状态参数。其中与特种车辆行驶工况有关的主要参数有:反映动力装置状态参数的发动机转速和输出转矩等;反映操纵装置工况参数的操纵力和离合器工作油压等;体现车辆转向状态的转向泵马达内部工作油压;控制车辆速度与加速度的加速踏板开度;直接反映当前车辆行驶状态以及对车辆未来状态产生间接影响的车速等。
工况分析主要研究挡位工况、运行工况、坡道工况和转向工况的表示方法,通过分别选取并计算合适特征识别参数来实现识别目的。
1.1 挡位工况
换挡时,变速箱根据挡位位置信号,通过操纵换挡执行机构选取不同的传动比来达到换挡的目的。特种车辆共有6个前进挡和2个倒挡,配置共6个离合器,分别是C1、C2、C3、CH、CL和CR。换挡的过程也是离合器充油和放油过程,所以操纵离合器工作油压可以直接反映当前挡位。换挡过程中,相应挡位所需要结合的离合器压力将会升高,而分离的离合器压力将下降为零,压力变化范围约为0~2 MPa。利用离合器油压判断挡位工况的逻辑如图1所示。

图1 挡位工况判断逻辑
基于上述挡位工况判断逻辑,选取各离合器油压和离合器油压之和的变化量作为特征参数。所有离合器油压之和SP可以表示为
SP=sum{Pi,i=C1,C2,C3,CH,CL,CR}
(1)
式中:Pi为各离合器油压值,单位为MPa。则换挡离合器油压之和变化量ΔSP为
ΔSP=SPt-SPt-ΔT
(2)
式中:SPt为当前时刻离合器油压之和,ΔT为此段时间序列的长度,单位为s。总结挡位工况特征参数如表1所示。

表1 挡位工况特征参数
1.2 运行工况
远程监控车辆速度状态时,除了依据由驾驶员侧操控的加速踏板和制动踏板信号外,车辆的行驶状态还可以由车辆当前的速度信号体现。本文选择更直观的加速度信号,通过定义加速度信号区间,将速度运行工况划分为加速、匀速和减速3种工况。
首先对车速信号加固定长度的窗口,计算每个窗口长度内数据的斜率,以此作为当前窗口对应运动学片段的运行加速度。选取不同窗口长度进行加速度值搜索的过程如图2所示。此外,对于特种车辆的加速、匀速和减速区间内加速度范围没有明确规定,需要迭代搜索定义[6],搜索过程如图3所示。
由图2和图3可得结论:
1)加速度窗口宽度选择1 s合适。当取0.5 s或更小值时,加速度值分辨率更高,但输出的加速度曲线波动较大,会影响识别的准确率;但当窗口宽度过大时,加速度值会存在延迟失真现象。此外,工况识别的精度一般以s为单位,计算加速度的窗口宽度设置为1 s符合识别精度要求。
2)匀速工况加速度边界选取± 0.12 m·s-2较为合适。从图3可以看出,若匀速区间加速度边界选± 0.08 m·s-2时,加速度值会反复穿过边界,造成较大的工况识别误差。当匀速区间加速度边界选择±0.12 m·s-2时,较多信号值相切于边界值,可最大程度减少匀速区间因加速度波动造成的识别误差。
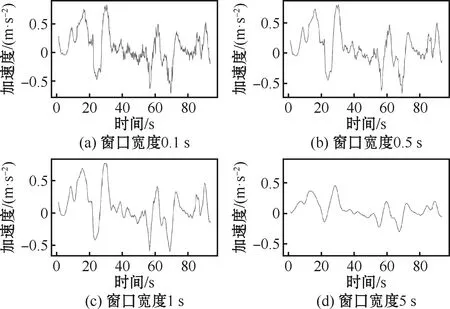
图2 不同窗口宽度下加速度值
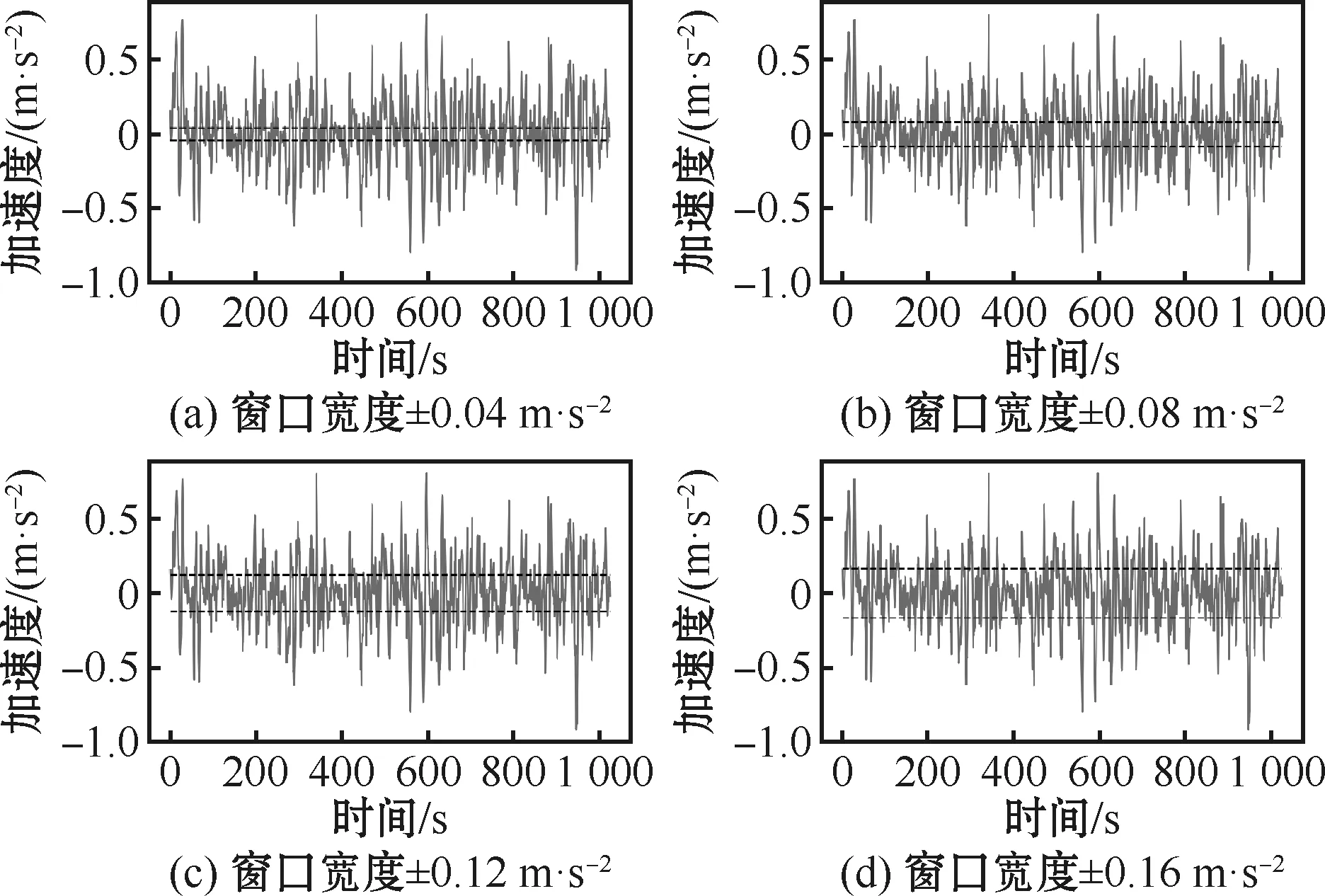
图3 运行工况加速度范围搜索过程
综上所述,识别运行工况的特征参数如表2所示。

表2 运行工况特征参数
1.3 坡道工况
坡度用来描述道路表面的起伏程度,是重要的路况信息,通常采用度数表示法记录坡度值的大小。当坡度变化率较大时,路面的平整度降低,会导致车辆的动载荷增加,是车辆行驶过程中的主要激励源[7]。所以道路环境会直接影响车辆的行驶状态参数,可以结合典型坡度算法模型和车辆外力平衡行驶方程计算实际坡度值。
坡度计算公式为
(3)
式中:ai为车实际行驶加速度;a为同工况下车辆在平路的加速度;g为重力加速度;β为坡度。
车辆的实际行驶加速度可使用上节所述方法通过车速计算得到。同工况下车辆在平路的加速度可通过车辆外力平衡行驶方程[8]计算,公式如下:
(4)
式中:Te为发动机转矩;ig为变速箱传动比;i0为后传动比;iq为前传动比;ηT为传动效率;r为车轮半径;CD为空间阻力系数;A为迎风面积;v为车速;m为车重;f为滚动阻力系数;δ为旋转质量换算系数。发动机输出扭矩利用发动机特性曲线插值获得,忽略坡道阻力。
利用上述数值计算公式,通过车载数据计算坡度值,部分坡度计算结果如图4所示。

图4 路面坡度计算结果
获得坡度数据后,选用坡度平均值作为识别坡度的特征参数,平均坡度βm计算公式如下:
(5)
式中:βi为各时刻的路面坡度,单位为(°);N为子数据段内样本点个数。
1.4 转向工况
特种车辆的转向为差速转向,即两侧行走装置形成速度差造成车辆转向,速度差越大,车辆转向半径越大。特征车辆的转向齿轮驱动机构由转向泵驱动机构和零轴驱动机构组成[9],左右两侧行走机构速比K可以通过式(6)计算得到。
(6)
式中:VC为传动主轴转速;V0为转向零轴转速;m为汇流行星排特性参数,本文研究对象的m=2.857。将车载传感器测得的VC和V0信号作为输入,利用式(6)计算左右两侧的行走机构速比,结果如图5所示。
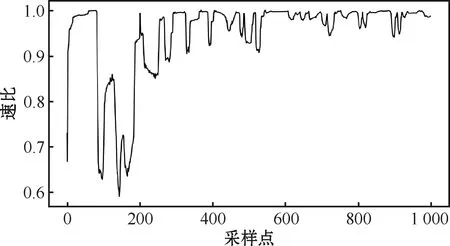
图5 两侧行走机构速比
计算速比的平均值作为识别转向程度的特征参数,平均速比Km计算公式如下:
(7)
式中:Ki为各时刻的两侧行走机构速比;N为子数据段内样本点个数。
2 信号分段
信号分段是将原始信号按照一定规则根据数据特征分割成短片段,计算短片段的特征值作为后续工况聚类识别算法的输入,短片段划分精度一定程度决定着工况识别的精度。本文研究对象为某型特种车辆,车载传感信号的采样频率为20 Hz,选取约2 000 km行程的数据,共获得8万多数据点。
2.1 原始信号去噪
由于发动机和车身振动、路面不平整度产生的激励以及传感器振动等原因,传感器信号中混杂各种噪声,出现突变、尖峰等干扰。信号的强噪声会使得在进行短行程分段时无法准确识别信号的变化趋势,影响分割的精度。因此,本文采用阈值函数折衷的小波阈值降噪算法对数据进行去噪处理[10],此算法可以保持软阈值函数信号连续性的优点,又可以降低信号重构后的幅度失真现象。阈值函数为
(8)

车载传感数据属于高频信号,小波基选择有较好正则性和消失矩的sym8;阈值设定采用固定阈值法,计算公式为
(9)
式中:δ为噪声的标准方差;N为噪声的长度。采用上述理论方法对本文信号进行多次滤波实验,最终发现小波阈值降噪分解层数为5、阈值折衷系数T选0.7时,降噪效果最好。以车速和C1离合器油压为例展示原始信号及滤波后信号对比如图6所示,可以看出,经过小波阈值降噪,信号毛刺明显减少,信号平滑,说明噪声被有效去除。

图6 信号滤波前后对比
2.2 基于自顶向下分段线性表示算法的数据分段
车载传感器数据皆为时间序列数据,以离合器油压信号为例,其时间序列可定义为:P={P1,P2,…,PN},是N个油压信号值以采样时间递增的顺序排列而成的序列。时间序列中每一个信号是一个键值对Pi=(ti,pi),其中ti为观测时间,pi为观测油压值。
时间序列的分段线性表示算法(piecewise linear representation,PLR)是根据序列特征从时间序列P中提取重要点,并用M条直线进行拟合表示,最终达到分段的效果,模型表示为
PPLR={(P1L,P1R,t1),(P22,P2R,t2),…,
(PiL,PiR,ti),…,(PML,PMR,tM)}
(10)
式中:(PiL,PiR,ti)为第i个分段,i=1,2,…,M;PiL,PiR分别为第i分段的起始值和结束值;ti为第i分段结束值对应的时刻;M表示此时间序列划分所得的子段数目[11]。
自顶向下分段线性表示算法(PLR_Top2down)是对整个时间序列数据进行扫描,寻找第一个最佳的分段位置并计算左右两个子序列段的拟合误差;若误差已经低于设定的阈值,分段结束;否则会继续分割子段序列,直到所有子段序列的拟合误差都低于阈值,算法流程如图7。
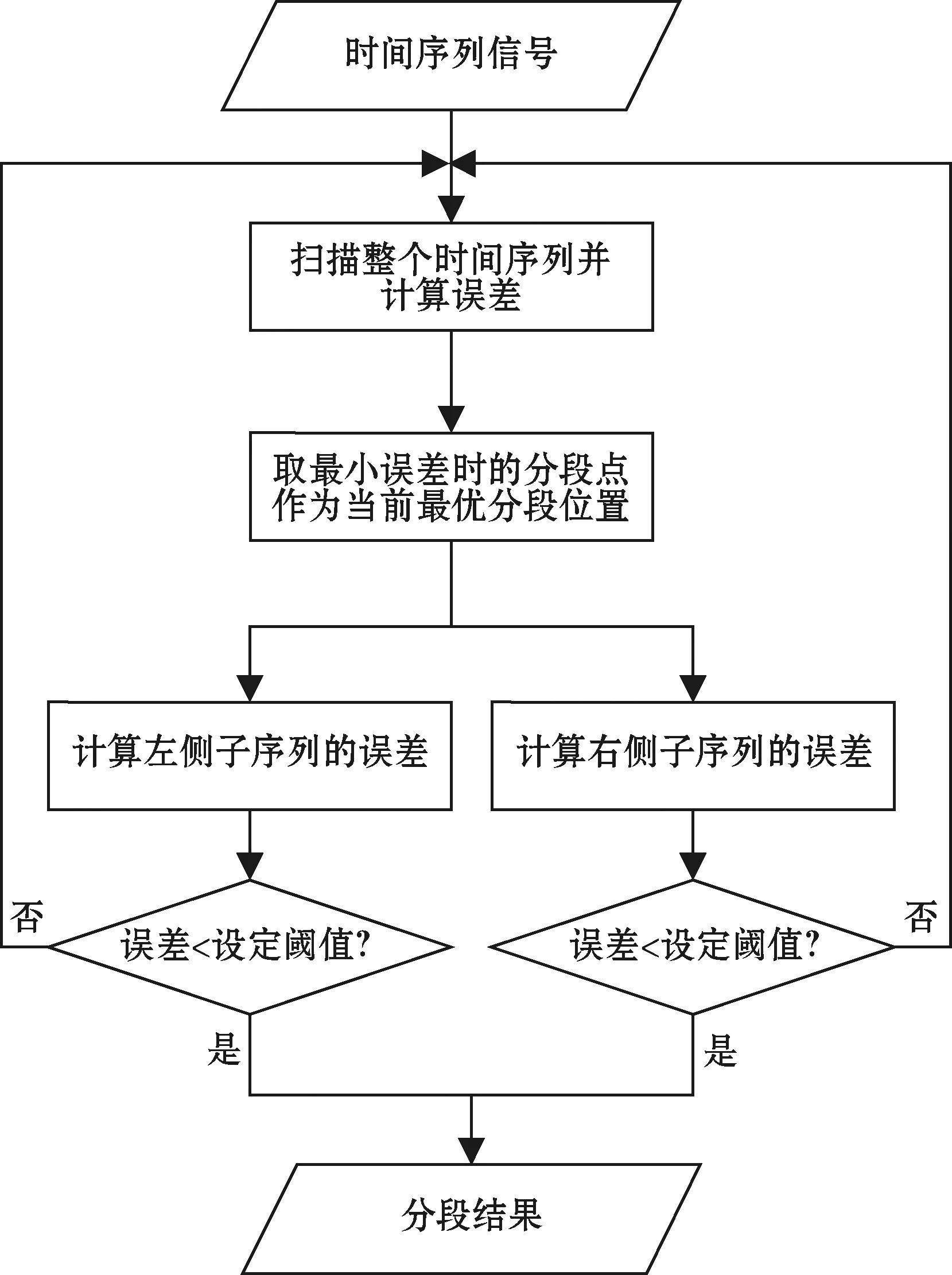
图7 自顶向下分段线性表示算法流程
本文采用基于最小二乘的直线回归方法对每个子段数据进行拟合,即离散形式最佳平方逼近问题的求解。已知子序列段由n组键值对组成函数表(ti,pi),在函数空间Φ中求解一个函数S*(t),使得
(11)
为求解这一问题,令S(t)为
(12)
则有多元函数
(13)
所以,为求得S*(t),需求多元函数I(c0,c1,…,cl)的极小值点,通过多元函数极值的必要条件:
(14)
即可求得S*(t)多项式系数向量。

(15)
基于上述数值计算理论及算法,以C1离合器油压信号为例,计算子片段拟合结果和误差如图8和图9所示。从图中可以看出该算法能够很好地将离合器油压的稳定阶段和充放油过程区分开,在此基础上获得有效分割片段。
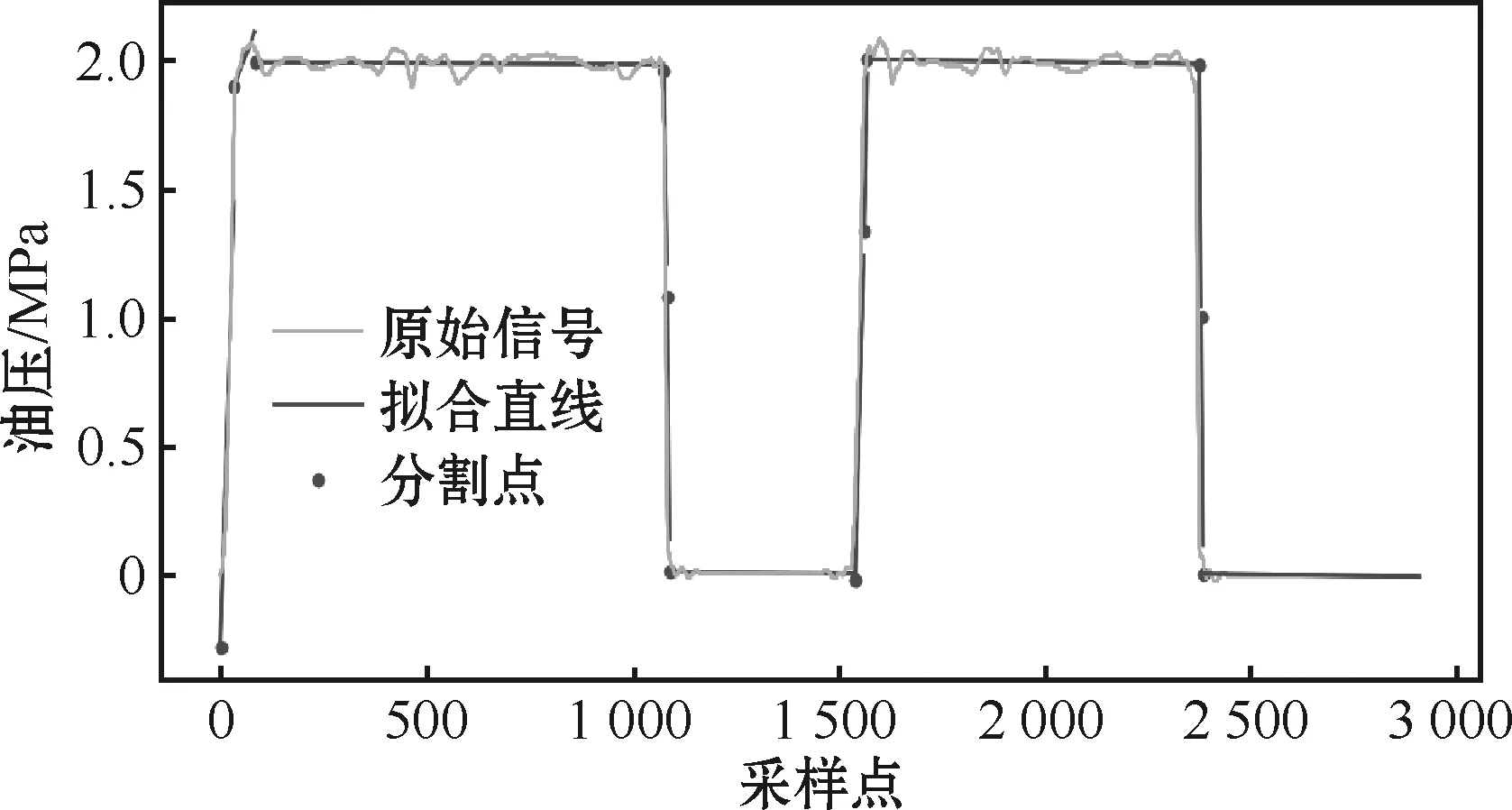
图8 C1离合器油压时间分割效果

图9 C1离合器油压各子段拟合误差
2 000 km行程的车载传感信号经过PLR_Top2down算法计算的分段结果及残差平方和的均值如表3所示。图10展示了各特征参数600个观测值下的分割子段及分割点。

表3 工况信号分割结果

图10 分割后子数据段示意图
3 特种车辆工况识别计算
k-means作为一种经典的聚类算法,结构简明且收敛速度快[12],是一种以距离作为相似性评价指标迭代求解的聚类分析算法,该算法步骤如下:
1)初始化:随机选取k个点作为聚类中心。
2)类划分:计算每个点到k个聚类中心的欧式距离,然后将该点分到最近的聚类中心,形成k个簇。
3)中心点计算:再重新计算每个簇中所有样本点的均值,作为下一次迭代的聚类中点。
4)迭代计算:重复以上步骤2)和3),直到质心的位置不再发生变化或者达到设定的迭代次数,使用平方误差E作为精度指标判断是否收敛:
(16)
式中:p为簇Ci中样本点;mi为Ci的聚类中心。不断进行迭代计算,直到E值收敛。
本文采用轮廓系数法确定最优聚类个数,不同簇数下聚类结果的轮廓系数St可用式(17)计算。
(17)
式中:
(18)
其中:ai为点到所在簇内其他点的平均距离;bi为点到所有其他簇内点的平均距离。
St的取值范围为[-1,1],结果越接近1说明聚类效果越好。
依据上述两节所述方法,将各工况子片段的特征值输入k-means聚类模型中进行工况判别。表4对比了各工况在不同聚类簇数下的轮廓系数。
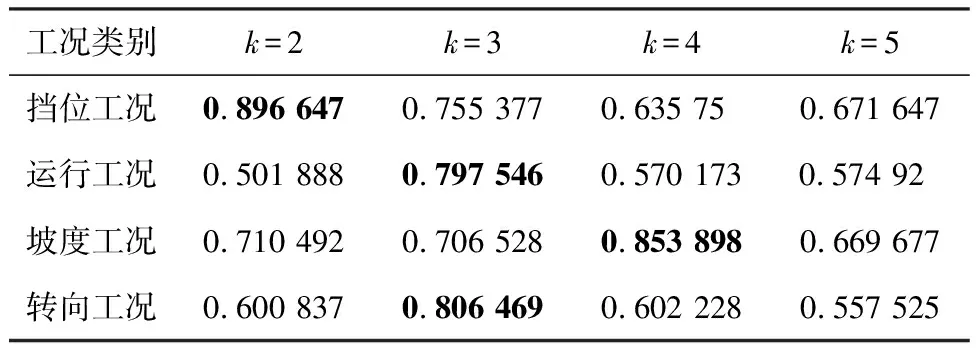
表4 各工况不同聚类数下轮廓系数
从表4可以看出,运行工况和挡位工况的聚类簇数分别取3和2时轮廓系数最大,符合前文所设定的工况类别数。另外,各工况最大轮廓系数均大于0.79,说明k-means聚类在本文工况识别中具有较好的效果。对于工况特点,只依赖聚类结果难以分析,因此进一步从聚类簇内信号的物理含义及特征对各个工况的识别结果进行分析。
3.1 挡位工况计算结果分析
提取聚类后的稳态工况片段和换挡工况片段的操纵油压和作为特征值,可以对工况识别结果进行检验,如图11所示。由于每个挡位下有两个操纵离合器结合,所以图中稳态工况片段的油压和基本保持在3.8 MPa左右;换挡工况片段的油压和在短时间内的变化量较大,代表当前为离合器分离或结合的过程。另外,根据各离合器油压可以识别当前挡位。表5展示了各工况的聚类中心。

图11 挡位工况聚类结果
挡位工况的聚类中心如表5所示。

表5 挡位工况聚类中心
3.2 运行工况计算结果分析
分别从代表加速、减速和匀速工况的聚类结果中提取加速度值分析运行工况的识别结果,每个工况取采样长度为10 000的加速度数据,数据展示如图12所示。可以看到加速度参数显著分布于1.2节所设定的3个运行区间内,虽有部分数据会穿越区间边界,但各工况在相应区间比例保持在0.7以上,根据分类结果计算运行工况运动学特征值如表6所示,可代表各运行工况特征。
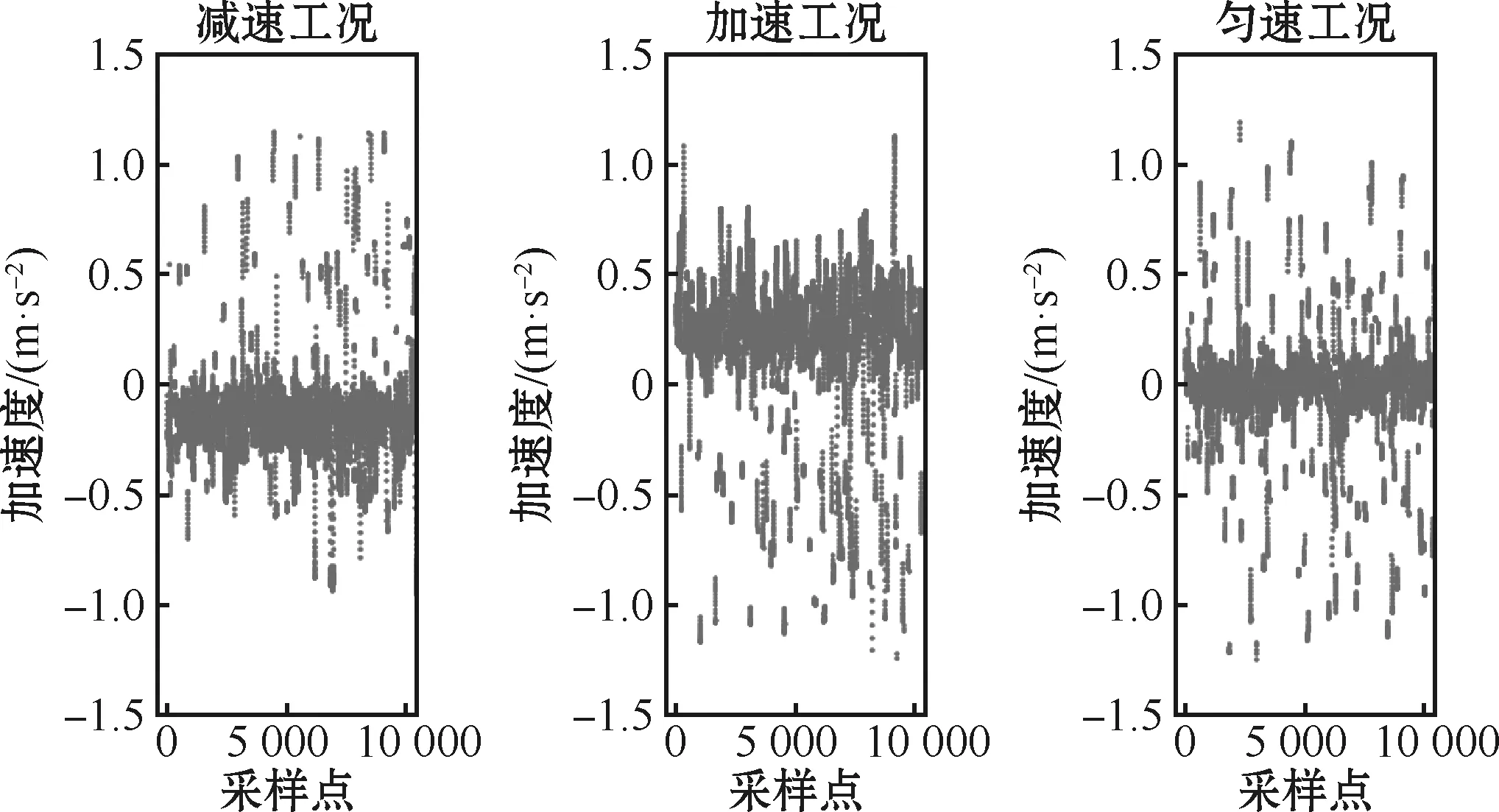
图12 运行工况加速度特征示意图
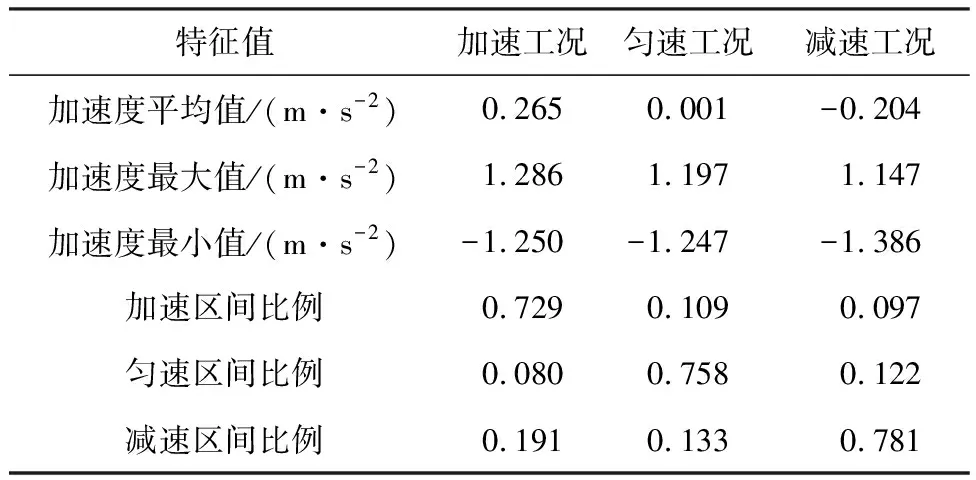
表6 运行工况运动学特征值
3.3 坡道工况计算结果分析
坡道工况聚类结果的轮廓系数在k=4时为最大值,计算每个聚类结果的坡度平均值及标准差,结果如表7所示。簇2和簇3的坡度平均值较小,而标准差相较于其他簇的大,说明簇2和簇3都属于平地工况,但路面不平整度较大。
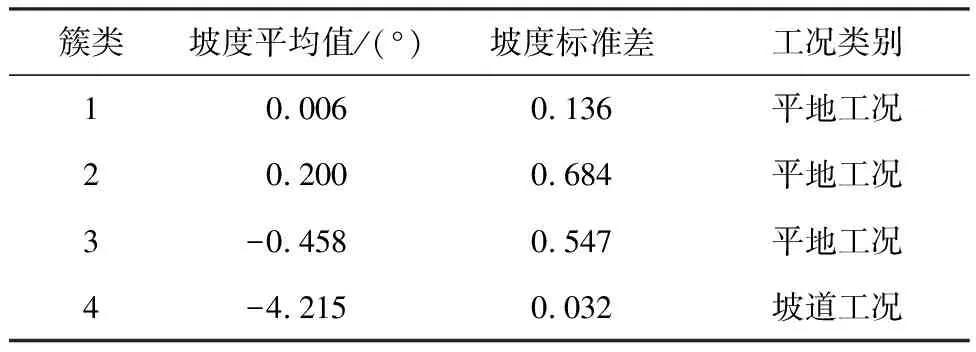
表7 坡道工况聚类中心及特征值
3.4 转向工况计算结果分析
利用PLR_Top2down算法对行走机构速比信号进行分割后共获得144个代表不同转向特征的子片段。将子片段输入到k-means聚类模型中,计算获得两个聚类簇,聚类中心如表8所示。簇1的聚类中心为0.720,说明两侧行走机构具有较大的速度差,可以代表转向工况,同理,簇2代表直驶工况。

表8 转向工况聚类中心
3.5 组合工况计算结果
取特种车辆采样点长度为1 000的车载数据,数据样本如图13所示。基于上文提出的工况识别方法,能够获得各类单一工况对应的起止时刻,通过对识别结果取交集,可以得到车辆在每一时段内组合工况状态。组合工况识别结果如图14所示,经实验验证求得聚类的准确率为92.75%,精度能够满足工程需求。

图13 特种车辆原始车载数据

图14 工况识别结果
4 结束语
本文针对特种车辆的工况识别问题,采用了操纵离合器压力变化量、加速度、坡度和两侧行走机构速比等信号分别作为挡位工况、运行工况、坡道工况和转向工况的识别参数;通过自顶向下分段线性表示算法对车载信号进行分割,获得各工况有效的子片段数据,并通过k-means算法实现了各单一工况的识别。实验结果表明,这种方法可以有效地区分特种车辆的不同行驶工况,并且具有较高的识别精度。此外,对各单一工况起止时间求交集,可以获得车辆一段时间内组合工况状态,为特种车辆服役性能退化评估研究提供了数据基础。未来的研究可以进一步优化算法以提高识别精度。此外,还可以探索如何结合其他传感器数据来提高工况识别的精度和全面性。
