BERT编码与注意力机制结合的长文本分类研究
2023-05-14陈洁
陈洁
摘 要: 预训练语言模型具有强大的特征表达能力但无法直接应用于长文本。为此,提出分层特征提取方法。在BERT允许的最大序列长度范围内按句子的自然边界分割文本,应用自注意力机制获得首块和尾块的增强特征,再利用PCA算法进行压缩获取主要特征成分。在THUCNews和Sogou数据集上进行5折交叉验证,分类准确率和加权F1-score的均值分别达到95.29%、95.28%和89.68%、89.69%。该方法能够提取与主题最相关的特征,提高长文本分类效果,PCA压缩特征向量能够降低分类模型的复杂度,提高时间效率。
关键词: 文本分类; 预训练语言模型; 注意力机制; 特征向量; PCA
中图分类号:TP391.1 文献标识码:A 文章编号:1006-8228(2023)05-136-04
Research on long text classification based on the combination of BERT
feature representation and attention mechanism
Chen Jie
(School of Data Science and Information Technology, China Women's University, Beijing 100101, China)
Abstract: The pre-trained language models have strong feature expression ability, but could not be applied to long text directly. A hierarchical feature extraction method is proposed for this purpose. Within the maximum sequence length allowed by BERT, the text is segmented into blocks according to the natural boundary of the sentence. The self-attention mechanism is applied to obtain the enhanced features of the first block and the last block. Then PCA algorithm is used to compress the initial feature vector to obtain the main feature components. The 5-fold cross validation is carried out on THUCNews and Sogou datasets, and the mean values of the classification accuracy and weighted F1-score on the two datasets are 95.29%, 95.28% and 89.68%, 89.69%, respectively. The proposed classification model can extract the text features most related to the topic and improve the classification effect of long text. PCA compression feature vector can reduce the model complexity and improve time efficiency.
Key words: text classification; pre-trained language model; attention mechanism; feature vector; PCA
0 引言
海量文本的自动分类在知识发现、主题挖掘、舆情监控等任务中发挥了巨大作用,成为自然语言处理(NLP)的重要研究内容。文本表征对文本分类效果至关重要,长文本因其语义更加多样化,文本蕴含的主题不惟一且存在冗余和噪声等问题,增加了分类难度。
传统的向量空间模型可以生成文本特征向量,但丢失词序,不能表征全局语义。神经网络语言模型可以获得分布式文本表示,使得文本能基于语义关联进行分类。目前,神经网络分类模型的文本表征有基于词嵌入方式和基于预训练语言模型方式。
以BERT[1]为代表的预训练模型具有强大的特征提取功能,但是Transformer结构对输入序列有一个固定的长度限制,在BERT中最大为512。基于BERT模型,层次法成为长文本编码的主要方式。文献[2]以句子为单位进行编码,以首句作为主题句,采用首句拼接注意力加权句向量方式生成文档向量,由于句子长短不一,短句通常包含较少的上下文信息,并且如果首句不是主题句则会影响文档表征效果。文献[3]以200字的文本片段分割文档,对每个片段进行嵌入表示,两个连续片段之间有50字的重叠,然后利用LSTM循环神经网络组合各个片段向量获得全局特征表示;文獻[4]将长文本分割为500字的重叠块,再通过平均池化获得全局特征表示,根据固定长度划分序列,没有考虑句子的自然边界,会因分割片段在语义上的不完整而影响整体的语义理解。
针对已有研究中存在的问题,构建HT-ATT-CONC模型,在BERT允许的最大序列长度范围内,将文档分割为具有完整语义的数据块,再结合文本分类任务的特点,利用BERT编码并结合自注意力机制整合数据块,有效获取全局语义表征,在THUCNews和Sogou新闻数据集上通过5折交叉验证模型在长文本上的分类性能。
1 注意力机制
BERT采用深度双向Transformer结构,使用多头自注意力(Self-Attention)机制对文本建模,不仅可以捕捉长距离的文本特征,而且在编码当前单词的时候还关注上下文中和它有关的单词,将注意力集中在重要的信息上,并通过深层网络结构学习深层次的上下文关联,增强了模型的表达能力。注意力机制的核心邏辑就是从全局信息中挖掘重点信息,并给予更多的重视[5]。
利用Self-Attention机制,可以通过注意力分布生成不同的权重,使得权重与数据本身的重要性相关,即焦点词语的权重大,由此得到目标字的注意力加权值,获取全局上下文信息[6,7]。
2 BERT与注意力机制结合的分类模型
利用BERT进行长文本编码,为了获取全局语义特征,需要切分文本,再组合分片向量以解决文档碎片问题。本文构建HT-ATT-CONC模型,首先将文本分割为具有完整语义的数据块,并对每个数据块进行嵌入表示;再利用自注意力机制整合块向量,突出与分类主题最相关的内容特征;最后通过一个全连接层和Softmax层,完成文本分类。
2.1 分割文本块
从阅读行为可知:段落比单个句子会包含更多与文本主题相关的语义;文本中存在的各种标点符号对阅读起着重要作用,保持这种分割可以有效保留原始文本中的语义信息;新闻首尾部分的内容通常与新闻主题的相关性最大。
为此,在BERT允许的最大序列长度范围内,将文本分割为具有完整语义的文本块。方法如下:
⑴ 按照句子的自然边界,将文档分割为不超过 510字符的数据块,数据块中的句子保持完整,不跨段,否则将最后一句划分到下一个数据块。
⑵ 分割后的数据块如果超过三个,则调整最后两块,从后往前截取不超过510字符的内容,数据块中的句子保持完整。
2.2 文档特征表示
⑴ 文本块的编码
在BERT模型中,“[CLS]”作为特殊字符,本身不具备任何语义,可用来代表输入文本的综合语义信息,本文用该字符的嵌入表示作为每个数据块的特征向量,文档中第i个数据块的特征编码为Ei。
预训练语言模型利用不同领域的大规模语料预训练以学习通用的先验语义知识,生成的向量维度通常都是上百维,而下游任务一般只涉及某个领域的应用,因此可以利用PCA(Principal Component Analysis,主成分分析法)算法对分布式表示的Ei进行压缩,提取主要特征成分。
⑵ 全局语义表征
为获得全局语义特征,需要组合文档中的块向量。Self-Attention具有关注全局又聚焦重点的特性,并且新闻的首尾部分通常与主题的相关性更高,为此,将文档中的各个块向量分别与首块和尾块对齐,通过注意力权重突出与分类主题最相关的内容特征。本文采用Scaled dot-product attention方法进行注意力加权:
[α=softmaxQKTd] ⑴
[att=α*V] ⑵
Q(Query)表示目标文本、K(Key)表示上下文中的文本、V(Value)表示文本块的原始向量,通过计算Q和K的注意力得分对V加权。[α]为注意力权值,利用Softmax函数进行归一化,得到(0,1)范围的注意力分布;d是一个调节参数,较小的取值可以保持指数函数的输入尽可能大,关注最重要的文本块;[att]为注意力加权向量,代表目标向量Q的增强语义表示。
具体过程如下:
⑴ 利用PCA算法来对Ei进行主成分分析,得到降维后的特征编码Ei。
⑵ 利用公式⑴计算文档第一个块向量E0对文档所有块向量Ej(j=0,1,2,…,n-1)的注意力得分(Q为E0,K、V为Ej)得到注意力加权的文档特征向量Eatt(h),第一个数据块的特征权重最大,其次是与第一块关系密切的其他数据块,由此,可以增强首块的语义表示,使分类特征更加显著。
⑶ 利用公式⑴计算文档最后一个块向量En-1对文档所有块向量Ej的注意力得分,得到注意力加权后的文档特征向量Eatt(t),增强尾块的语义表示。
⑷ 将Eatt(h)与Eatt(t)进行拼接,得到文档表征E,作为初始的分类特征向量。
[E=Eatt(h)⊕Eatt(t)] ⑶
2.3 分类性能度量
本文采用准确率(Acc)和加权F1-score(WF1)来评价模型的性能。
准确率是分类正确的样本数占总样本数的比例,计算公式为:
[acc=TP+TNTP+FP+TN+FN] ⑷
其中,TP表示正确分类的样本数,FP表示错误分类的样本数。
F1-score是精确率P和召回率R的调和值,是一个综合指标。当数据类别不平衡时,加权F1-score(WF1)可以更准确的评价分类性能,计算公式为:
[F1=2*P*RP+R] ⑸
[WF1=i=1kwi*F1i] ⑹
其中,k是样本类别数,[wi]是数据集中第i类样本占总样本的比例,[F1i]是第i类样本的F1-score。
3 实验与结果分析
3.1 实验设置
⑴ 实验数据集
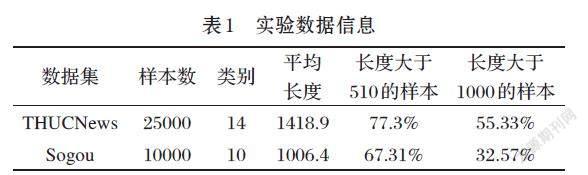
实验选择THUCNews 和Sogou两个公开的新闻数据集进行测试,随机选择长度在100~10000之间的新闻,如表1所示。
⑵ 数据块编码与对比模型
实验采用BERT改进版的Roberta(Chinese_Roberta_wwm_ext)作为编码器,嵌入向量的维度为768,Roberta在训练语料和MASK方式上与BERT存在差异,编码效果更出色。利用THUCNews数据集微调后再编码。对比实验有以下4种,文本特征维度均为768。
① Baseline模型:使用文本第一个数据块的特征向量作为文档的特征表示。
② H-ATT模型:使用注意力加权的首块特征向量作为文档的特征表示。
③ HT-CONC模型:使用PCA算法对初始块向量进行主成分分析,得到维度为384的新的块向量,再将首块与尾块拼接,得到文档特征向量。
④ HT-ATT-CONC模型:使用PCA算法对初始块向量进行主成分分析,得到维度为384的新的块向量,再将注意力加权后的首块与尾块拼接,得到文档特征向量。
3.2 实验结果
基于Keras的bert4keras框架构建模型,分类训练和预测的神经网络包含一个全连接层、Dropout层和Softmax层,使用 ADAM 优化器。采用5折交叉验证,用5次结果的准确率(Acc)和加权F1-score(WF1)的均值作为分类性能的评估。为考查长文本特征表示方法在分类应用上的效果,进一步对不同长度范围内不同类别的文档分别评估Acc和WF1性能。
⑴ THUCNews数据集的实验结果
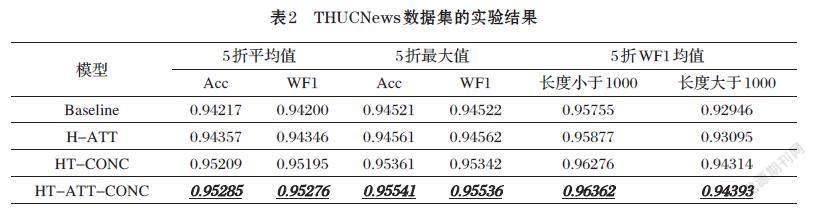
全连接层的隐藏单元数为64,Softmax层的隐藏单元数为14,结果如表2所示。
Baseline模型的ACC均值和WF1均值都超过94%,表明文档开头部分包含了较强的主题特征。三种对比模型的分类性能均超过Baseline,说明对文档开头和结尾部分的特征补充,可以增强主题特征,提高分类效果。其中,H-ATT模型通过注意力机制关注了文档其他部分的相关特征;HT-CONC模型通过文档首尾两部分特征的拼接表达全局语义,这也表明,新闻语料的开头和结尾部分通常包含了更多的主题特征;HT-ATT-CONC模型不仅利用了首、尾部分的特征信息,还通过注意力机制融合了文档其他部分特征,因此模型效果最好,与Baseline相比,ACC均值提高1.134%,WF1均值提高1.142%,
对于长度大于1000的样本,HT-ATT-CONC模型的WF1均值提高了1.56%,表明该模型能够很好地提取THUCNews实验集中长文档的主题特征。
⑵ Sogou数据集的实验结果
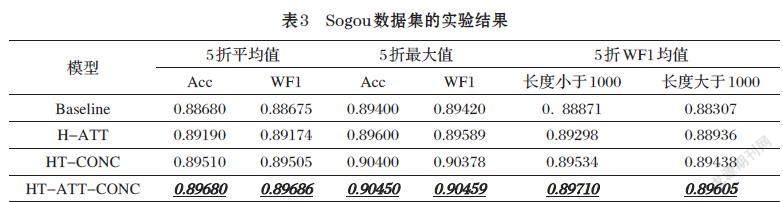
全连接层的隐藏单元数为128,softmax层的隐藏单元数为10,结果如表3所示。
Baseline模型的ACC均值和WF1均值都超过88%,三種对比模型的分类性能均超过Baseline,且HT-ATT-CONC模型效果最好,与Baseline相比,ACC均值提高1.128%,WF1均值提高1.140%。对于长度大于1000的样本,HT-ATT-CONC比Baseline模型的WF1均值提高了1.47%。
⑶ 压缩文档特征对分类性能的影响
上述模型采用PCA算法降维,文档特征维度均为768。若直接使用初始特征,则文档特征的维度为1536,使用HT-ATT-CONC模型在两个数据集上的分类结果如表4所示。
特征维度为1536时的分类性能并没有明显的改善,甚至稍有降低;而且,训练参数增多,也增加了模型的训练时间。采用PCA算法对数据块的初始特征进行降维,提取主要特征再进行分类是有效的。
4 结束语
BERT具有强大的特征提取能力,注意力机制具有关注全局又聚焦重点的特性,将二者结合应用于长文本特征表示,构建HT-ATT-CONC分类模型,在分割文档时保证语义的完整性、在应用注意力时选择合适的对齐目标,对文档开头部分和结尾部分进行语义增强表示,再将两者拼接起来,形成全局语义表征,能够提高长文档分类效果。
HT-ATT-CONC模型在一些数据上的分类性能不太显著,后续将进一步改进,应用多头注意力使提取的语义信息特征更为全面和鲁棒,以取得更好的分类效果。
参考文献(References):
[1] DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-
training of deep bidirectional transformers for language understanding[EB/OL].(2019-05-24)[2022-10-7].https://arxiv.org/pdf/1810.04805.pdf.
[2] 叶瀚,孙海春,李欣等.融合注意力机制与句向量压缩的长文
本分类模型[J].数据分析与知识发现,2022(6):84-94
[3] Raghavendra Pappagari,Piotr Zelasko,Jesus Villalba etal.
Hierarchical Transformers for Long Document Classification[EB/OL].(2019-10-23) [2022-10-07].https://arxiv.org/pdf/1910.10781.pdf.
[4] Mandal A, Ghosh K, Ghosh S et al. Unsupervised
approaches for measuring textual similarity between legal court case reports. Artificial Intelligence and Law[J].Springer,2021,(29):417-451
[5] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you
need[C]//Proceedings of the Advances in neural information processing systems.2017:5998-6008
[6] Guo Q,Qiu X,Liu P,et al. Multi-Scale Self-Attention for
Text Classification[J].American Association for Artificial Intelligence(AAAI),2020,34(5):7847-7854
[7] Ran Jing.A Self-attention Based LSTM Network fffor Text
Classification[C]//Proceedings of 2019 3rd International Conference on Control Engineering and Artificial Intelligence(CCEAI 2019).Los Angeles,USA,2019:75-79
