融入互注意力的风险领域实体关系抽取研究
2023-05-12杨美芳
杨美芳,杨 波
(江西财经大学 信息管理学院,南昌 330013) (江西财经大学 信息资源管理研究所,南昌 330013)
1 引 言
随着人工智能技术的发展与应用,学界与工业界开始加大对知识图谱的关注和投入.百度CTO王海峰在世界人工智能大会上指出,如果知识是人类进步的阶梯,知识图谱就是AI进步的阶梯[1].Gartner于2020年发布的人工智能技术成熟度曲线表明,知识图谱的成熟度由2019年的创新出发阶段一跃达到预期膨胀高峰阶段且非常接近最高点[2].伴随着知识图谱在各行各业的深入应用,通用型知识图谱难以满足领域个性化知识需求.鉴于此,国务院发布的《新一代人工智能发展规划》中,明确将“领域知识计算引擎”作为“新一代人工智能关键共性技术”的第一要务,提出要“具备概念识别、实体发现、属性预测、知识演化建模和关系挖掘等能力,实现知识持续增量的自动获取,形成可泛化的领域知识图谱”.
领域实体关系抽取是领域知识图谱构建的核心问题之一,旨在从领域文本中挖掘实体间的关系,进而为构建领域知识库、语料库与知识图谱提供知识支持[3].目前,面向通用领域的实体关系抽取已取得较好的效果.然而,在风险领域特定情境下,受限于可靠标注的领域知识与开放数据集的规模,以风险领域文本为核心的实体关系抽取仍面临诸多挑战.
面向风险领域的实体关系抽取的核心难题在于领域文本中实体的类型多样且实体间关系的交叉互联,该特性主要表现为风险领域文本数据中包含多种不同类型的实体,实体间可能产生多种类型的关系,且相同实体可能参与不同的关系对[4,5].以风险领域语料为例:“2016年8月25日海底捞爆出老鼠爬窜、餐具清洗不到位等一系列卫生问题,当日下午北京食药监局立即对其进行调查,并通报存在的安全卫生问题,对此海底捞发布公开致歉信,并对门店实现后厨公开可视化,落实食品安全主体责任,全面进行限期整改.”该风险领域文本描述中包含6类风险实体与10组实体关系对,且同一实体“海底捞”参与7组实体关系对中.领域文本中实体间关系错综复杂且相互关联,容易导致模型的欠拟合,从而影响风险领域实体关系抽取的性能.因此,风险领域实体关系抽取模型需充分理解文本语义层面的信息,而并非简单的语法或字词信息.
早期的领域实体关系抽取主要采用基于规则或统计学习的方法[6,7],这些方法需预先人工抽取大量的领域特征集,耗时费力且抽取效果参差不齐.近年来,研究者尝试使用深度神经网络方法进行领域实体关系抽取[8,9].此类方法可减少模型对特征工程的依赖,有效提高模型的训练效率,同时能够挖掘领域实体间深层次的特征与联系,进一步提升模型的抽取性能.最近,有学者将注意力机制成功应用于实体关系抽取中,并在模型训练效率与抽取性能方面获得较好的效果[10,11].然而,这些方法均为通用领域实体关系抽取模型向特定领域文本关系抽取的简单迁移,仍未解决风险领域文本中丰富的语义信息与复杂的实体关系给模型带来的数据噪声问题.
针对风险领域文本特点与领域实体关系抽取的最新进展,本文提出基于知识图谱与文本互注意力的风险领域实体关系抽取模型.该模型引入了风险领域知识图谱与文本的互注意力机制,运用各自特有的信息辅助彼此相互学习,并结合领域知识图谱“量少质优”和领域文本“规模效应”的特点,充分挖掘知识图谱中的隐性知识,以此开展大规模领域语料文本中的知识深入挖掘与学习,实现已有领域知识与机器深度学习的优势互补.
2 相关研究
领域实体关系抽取的本质是领域实体关系识别问题,其任务在于挖掘蕴含于特定领域实体间类型多样化的语义关系,挖掘结果通常用于构建或动态更新已有的领域知识图谱.领域实体关系抽取的相关研究从基于统计方法的分类模型向深度学习模型逐渐演进.早期的领域实体关系抽取大多采用基于统计特征的分类学习方法,其核心在于从领域文本中抽取语义特征,并运用支持向量机(SVM)[12]、条件随机场(CRF)[13]与最大熵[14]等模型进行关系分类.Zhao等人运用SVM的核函数表征领域文本中的词句语法信息,并利用SVM分类模型在ACE竞赛数据集上取得较好的效果[15].Culotta等人将条件随机场应用到领域实体关系抽取任务中,同时充分利用词性、上下文等特征进一步提高关系抽取的性能[16].Mikolov等人提出了融合词性、实体类型与依存树等特征的最大熵分类模型,该模型验证了多层次的语言特征能够有效提升领域实体关系抽取的效果[17].此类方法虽然在领域实体关系抽取任务上取得了较好的效果,但往往依赖于大量的人工干预,如通过繁琐的特征工程获取领域文本特征.
与传统基于统计特征的领域实体关系抽取相比,基于神经网络的深度学习方法无需进行大量的人工特征筛选,为通用领域实体关系抽取研究提供了新的方向.此类方法通常采用基础神经网络模型将领域实体关系抽取问题转换为文本分类问题,具有代表性的方法是循环神经网络模型(RNN)与卷积神经网络模型(CNN)[18,19].Socher等人采用RNN模型学习领域文本中词句间关系路径的向量表示,从而用于领域实体关系分类[20].RNN模型能够有效学习领域文本上下文的依赖信息,但很难发掘词句层面的关系特征.王林玉等人运用CNN卷积神经网络学习领域文本词性与实体位置等特征,该方法可将文本中的实体语义信息融入关系抽取模型中,能够有效提升关系抽取性能[21].CNN模型重点关注了领域文本中的局部信息,而对于全局信息的学习能力不足.鉴于此,有学者在基于神经网络的实体关系抽取方法上提出相应改进.Lin等人将CNN模型与注意力机制相结合,进一步对句级别的特征进行语义编码与深度学习[22].
近年来,以知识图谱与深度学习为支撑的理论与方法为风险领域实体关系抽取问题的研究提供了有效的解决方案.He等人运用CNN基础模型对该问题进行建模并在工业风险领域数据集上进行验证,实验结果表明,CNN模型所学习的风险领域局部特征有利于表达高密度实体对的特性,而对于相距较远的实体对缺乏辨识能力[23].肖毅等人运用双向循环神经网络BiLSTM对企业财务风险文本信息进行特征抽取,然后通过池化层对隐藏层输出进一步编码,最后通过特征向量合并的方式传入softmax层进行模型训练与分类[24].虽然BiLSTM模型有效解决了CNN模型的长层依赖问题,但对风险领域文本信息重要性的区分能力不足,仍无法适应风险领域复杂的实体关系抽取任务.随后,有学者将注意力机制引入CNN模型,并验证了该模型在风险领域实体关系抽取任务中的有效性.Su等人将注意力机制融入CNN模型的池化层,进一步对风险领域文本中的噪声数据进行过滤,从而使模型更关注领域文本短语级特征的学习[25].然而,融合注意力机制的CNN模型仍存在梯度消失的问题,无法对风险领域篇章级文本进行依赖信息的学习.
随着领域知识图谱理论与技术的发展与完善,有学者以现有的领域小规模知识图谱为指导,充分提取与利用其中的语义信息辅助领域实体关系的自动抽取[26].基于此,本文引入新颖的互注意力机制,允许小规模领域知识图谱与大规模领域文本利用各自特有的信息进行相互学习.在领域知识图谱的指导下,关系抽取模型中的噪声数据被削弱.同时,领域文本关系特征被反馈回知识图谱模型,从而进一步增强对训练影响较大的领域知识权重.知识图谱表示学习模型与领域文本关系表示学习模型在训练推进过程中通过相互指导逐步强化各自效果.因此,本文针对风险领域文本的特征与差异性,同时考虑模型整体训练的效率,提出基于知识图谱与文本互注意力的关系抽取框架,用于提升实体关系抽取在大规模风险领域文本上的性能表现.
3 方法与关键问题
基于知识图谱与文本互注意力的关系抽取框架主要包括知识表示学习与基于互注意力的联合学习模型.领域文本关系表示学习模型的核心在于运用深度神经网络方法挖掘蕴含于领域文本中的语义信息,并将语义信息所描述的关系嵌入低维空间进行关系抽取.领域文本关系表示学习是基于关系实例的表示学习,其效果主要取决于量少质优的基准表示向量.另外,相同类型的关系表示向量具有聚集性,提供一定量的基准关系表示向量能够有效避免单个表示向量的偏差.因此,领域文本关系表示学习模型适用于小规模知识图谱指导下的语义关系学习.此外,领域文本关系表示学习是基于词嵌入表示向量进行学习,而词嵌入表示向量的学习无需标注语料,因而可以充分发挥大规模领域文本语料集的作用.
由此可见,在小规模知识图谱的指导下,从领域文本关系表示学习入手开展风险领域实体关系抽取具有其独特的优势.既可以发挥大规模领域文本语料集的作用,又可以充分发挥小规模知识图谱的指导作用.鉴于此,本文将领域文本关系表示学习模型与领域知识图谱表示学习模型联合起来进行统一的关系抽取.该联合学习框架将词句与实体、文本关系模式与图谱关系模式进行全面对齐,使得它们的特征能够充分融合,同时让各模型能够在统一的连续空间中同时训练学习.在领域文本与知识图谱全面对齐的基础上,为进一步解决实体间关系的交叉互联以及远程监督标注存在噪声数据的问题,本文在联合学习框架中融入新颖的互注意力机制,允许知识图谱与领域文本模型运用各自特有的语义信息来辅助彼此进行相互学习,从而有效提升风险领域实体关系抽取性能.
3.1 风险领域实体关系判定思路
本文研究的问题为知识图谱指导下风险领域实体关系抽取,即给定风险领域实体及其对应的领域文本,判定领域实体间存在的关系类型.根据领域实体关系抽取的研究成果并结合风险领域实体关系抽取的特点,本文通过实体关系约束条件判定实体间存在的关系类型,如表1所示.由表1可知,大规模风险领域文本语料集可用于训练实体关系表示向量;而小规模领域知识图谱既可用于构造实体类型约束,还可以作为领域实体关系抽取模型训练的基准表示向量.有研究表明,少量质优的领域知识图谱可高效的生成领域文本关系表示向量[27].因此,本文提出同时满足实体类型约束、关系判别约束与事实关联约束的风险领域实体关系抽取思路,如图1所示.图1所示的风险领域实体关系抽取思路既能够发挥大规模领域文本与小规模领域知识图谱的各自作用,又能缓解模型对人工标注语料的过度依赖.

表1 风险领域实体关系判定的约束条件Table 1 Risk field entity relationship decision constraint
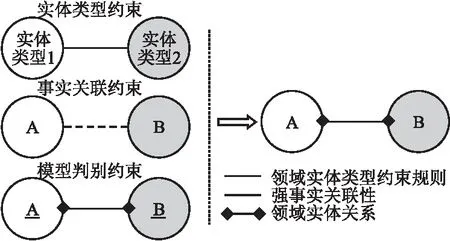
图1 风险领域实体关系抽取思路Fig.1 Risk field entity relationship extraction ideas
3.2 风险领域实体关系抽取方案与关键问题
基于上述风险领域实体关系抽取思路,结合当前风险领域实体关系抽取与注意力机制的相关研究,本文将风险领域实体关系抽取任务划分为4个子任务,如图2所示.风险领域实体关系抽取任务包括4个关键问题:1)风险领域小规模知识图谱的构建与领域实体关系类型约束的表示;2)基于领域未标注文本与知识图谱的表示学习问题;3)基于互注意力机制的联合学习问题;4)风险领域实体关系抽取问题.

图2 融入互注意力的风险领域实体关系抽取流程Fig.2 Integration of risk-related risk sector entity
整个过程形成具有一定可靠性的动态知识抽取模式.本节针对风险领域实体关系抽取的关键问题予以阐述,其中具体的抽取方法可视不同领域实践情况进行相应的调整.
3.2.1 实体类型约束规则的构建
风险领域实体类型约束规则包括领域实体类型与实体间关系的类型.该约束规则是针对特定的风险领域的实体及其关系,且要求领域知识具有高度的概括性与准确性.风险领域实体类型约束规则的构建包括风险领域小规模知识图谱的构建以及风险领域实体关系类型的界定与实体约束规则的表示.
1)风险领域小规模知识图谱的构建
风险领域小规模知识图谱对领域知识的精确度要求较高.因此,本文在前期对风险领域知识图谱研究的基础上,再借鉴清华大学知识工程实验室提出的“四步法”进行风险领域小规模知识图谱的构建[28,29].风险领域小规模知识图谱的构建过程如图3所示,具体内容如下.
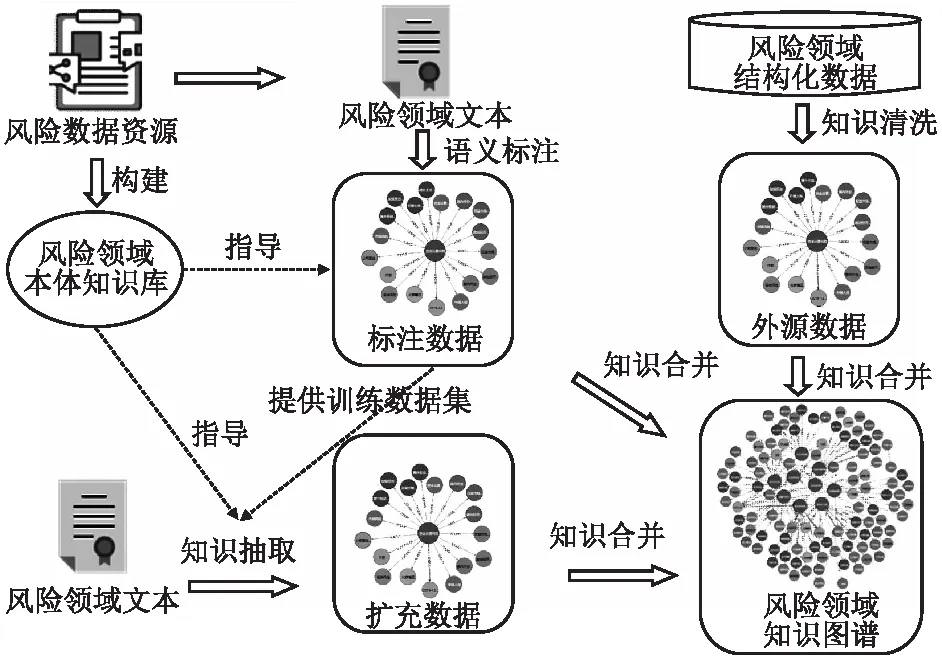
图3 风险领域小规模知识图谱的构建过程Fig.3 Construction process of small-scale knowledge maps in risk
首先,风险领域本体构建.基于项目合作单位搜集的风险领域数据资源,以及通过网络爬虫与信息抽取等技术获取的公开风险数据,本文运用OWL本体建模工具与OpenIE知识抽取方法,并结合风险领域专家的指导意见,完成风险领域本体知识库的构建.
其次,风险领域文本语义自动标注.本文将获取的公开风险数据作为语义标注的对象,并以风险领域本体知识库作为标注依据,运用文本标注系统进行自动语义标注,最终形成已标注的风险领域文本.
再次,风险领域外源数据补全.按照风险领域知识图谱的本体结构,从结构化的风险领域外部数据库中获取相关实体、关系及其类型,这将作为风险领域知识图谱重要的知识来源.
最后,风险领域知识抽取与图谱构建.针对半结构化与非结构化风险领域数据,本文将已标注的风险领域本体知识库作为标注数据完成实体关系及其类型的抽取,同时结合知识元与神经网络等方法实现有效知识元的融合[30].在此基础上,本文通过知识分类、推演及关联挖掘等推理操作发现风险领域新知识,从而进一步扩充风险领域知识.最终将风险领域知识存储在Neo4J图数据库中,形成风险领域知识图谱[31].
2)风险领域实体关系类型的界定与实体约束规则的表示
风险领域实体关系类型的界定需要领域专家一定程度的参与,但本文中的领域专家更侧重于对领域实体类型及实体关系等知识规律的描述,而非传统知识图谱构建中提供的领域中具体的实体关联知识.此方案设计的优势在于,既能够避免出现大量穷举式的繁琐工作,又能有效挖掘领域专家所拥有的隐性知识.风险领域实体关系类型的界定方法包括两个方面,一方面可以通过“自顶向下”的方式列举风险领域常见的实体类型与实体关系约束;另一方面可以通过“自底向上”的方式统计领域图谱中知识结构较复杂的实体关联类型及其组成实体类型的约束.风险领域实体关系类型界定的过程中,本文采用三元组表示实体约束规则,如<实体类型1,实体类型2,实体关系类型>.
3.2.2 基于领域未标注文本与知识图谱的表示学习模型
1)风险领域词嵌入的向量表示
近年来,广泛适用的词嵌入表示受到学者们的关注,尤其是在深度神经网络学习模型中,词嵌入向量常用于神经网络模型的输入,而词嵌入向量的质量对领域实体关系抽取性能具有重要影响.
传统的词向量方法对于领域文本中的每个字词均适用相同的向量进行表示,而实际的风险领域文本中,不同语境中的字词可能具有不同的含义.针对这一问题,Perters等人提出基于上下文相关的词向量表示模型ELMo[32].该模型通过词嵌入的双向神经网络提取领域文本上下文特征,从而获取具有上下文语义的词向量.ELMo模型最早应用于英文领域,将空格切分的英文单词特征化后作为输入进行训练学习.随后,Che等人将ELMo模型应用于中文领域.而中文领域文本无空格切分,因此他们首先利用中文分词工具对文本进行分词,然后使用ELMo模型训练中文词向量[33].虽然ELMo模型能够有效表示文本上下文语义信息,但未针对汉字特点进行学习,无法获取字词内部的结构信息.因此,本文运用基于笔画的ELMo模型训练风险领域词向量,通过引入笔画序列既能刻画汉字的内部结构,又能描述字词间内在关系.笔画ELMo模型的优势在于:1)传统的字符ELMo以字符向量作为实体抽取模型的输入,将导致低频字与未登录字难以获取准确的特征向量.但笔画ELMo能够根据笔画序列生成任意的字向量,从而缓解低频字或未登录字存在的问题;2)传统的字符ELMo难以获取汉子的内部结构特征,而笔画ELMo能够在大规模领域文本上通过输入汉字笔画特征学习字词间的内在关系,进一步增强领域文本的语义表示能力.笔画ELMo嵌入预训练语言模型结构如图4所示.
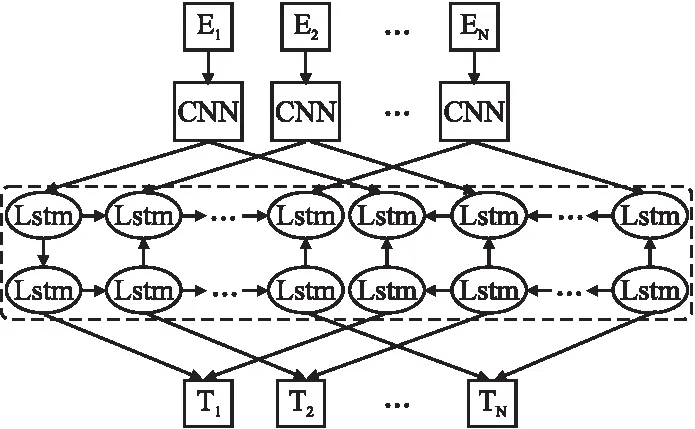
图4 笔画ELMo嵌入预训练语言模型Fig.4 Strike ELMO embedded pre-training language model
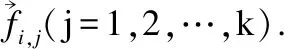

表2 笔画信息映射表Table 2 Stroke information mapping table
在此基础上,本文运用笔画ELMo模型对企业大规模语料进行预训练.针对后续具体企业风险领域文本的表示,本文通过笔画ELMo模型的中间层线性合并获取文本字向量.笔画ELMo模型中双向LSTM的2K+1层表示为公式(1):
(1)

(2)
其中,wj表示双向LSTM模型各层的标准化权重,σ是笔画ELMo模型的优化参数.
因此,笔画ELMo模型能有效刻画汉字内部结构特征,并能有效学习风险领域文本上下文的语义关系,从而增强词向量表示能力.
2)知识图谱表示学习模型
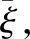
(3)
其中,P(KGrd|ξE,ξR)为条件概率,用于刻画风险领域实体关系嵌入表示向量对知识图谱的表征能力,即能够找到最好的嵌入表示最大限度的使KGrd中的事实概率变大.而知识图谱表示学习模型可将该条件概率转化为P(e1|(r,e2),ξE,ξR)、P(e1|(r,e2),ξE,ξR)和P(r|(e1,e2),ξE,ξR).
对于风险领域知识图谱中的实体对(e1,e2),本文定义潜在的关系向量re1e2表示实体向量e1到实体向量e2的关联关系,具体形式为公式(4):
re1e2=e1-e2
(4)
与此同时,风险领域知识图谱中的三元组存在显式关系向量r′描述实体e1和实体e2之间的关联关系.因此,三元组(e1,r,e2)的能量函数为公式(5):
(5)
其中b为偏置向量.基于能量函数,条件概率P(e1|(r,e2),ξE,ξR)可表示为公式(6):
(6)
类似的,可以定义P(e1|(r,e2),ξE,ξR)和P(r|(e1,e2),ξE,ξR)的条件概率.为适应知识图谱与领域文本的联合学习,本文引入TransD对知识图谱中的三元组进行编码和嵌入,具体如公式(7):
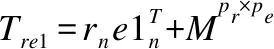
(7)
其中,rn,e1n,e2n均用于向量间的映射向量,pepr分别为实体向量与关系向量的维度.
3)风险领域文本关系表示学习模型
风险领域文本关系表示学习模型通常运用深度神经网络的方法挖掘风险领域文本的语义信息,并将语义信息中所描述的实体关系嵌入低维空间以进行关系抽取.如给定一个包含两个风险领域实体的句子“海底捞爆出一系列安全卫生风险事件”,通过该句字词与句子本身的语义信息可以直接推测“安全卫生风险”与“海底捞”存在风险与风险所属组织的关系.
考虑到风险领域文本语料的内容较长且其中蕴含的实体间关系复杂,本文运用卷积神经网络对风险领域文本关系进行表示学习.卷积神经网络具备更强的并行性与泛化能力,更少依赖人工特征选择,且能充分利用GPU的并行性,适用于从大规模风险领域文本语料中抽取风险信息.本文将风险领域文本语料D通过卷积神经网络得到关系表示向量rtext之后,风险领域文本关系表示模型最终会得到评分函数,见公式(8):
S=Mrtext
(8)
其中,M表示风险领域实体关系评分矩阵.
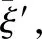
(9)
其中,P(D|ξV)为条件概率,用于从风险领域文本语料D中学习文本特征,并得到领域文本与语义关系的嵌入表示,即能够最大限度地使D中的文本语义信息与其描述的实体关系相对应.为具体描述语义信息与实体关系匹配的概率,本文将P(D|ξV)变换为公式(10):
P(D|ξV)=P((d,rd)|ξv)
(10)
该公式定义了在已知风险领域词嵌入的向量表示的基础上D中句子d能准确描述语义关系ds的条件概率.根据风险领域文本关系表示模型得到的评分函数,本文将P((d,rd)|ξv)表示为公式(11):
(11)
3.2.3 基于互注意力机制的联合学习模型
从已有研究来看,风险领域实体关系获取方法通常有两种:1)通过构建实体关系抽取模型从风险领域文本中获取;2)通过使用知识表示学习模型从风险领域图谱中获取.以上两种方法均可以有效获取风险领域文本中的实体关系,但已有的研究较少将两种途径结合起来进行风险领域实体关系的获取.
针对这一问题,本文采用基于知识图谱与领域文本互注意力的联合学习模型进行风险领域实体关系抽取,如图5所示.该模型中的联合学习方法主要是在风险领域文本与实体、风险领域文本关系模式与图谱模式上进行全面对齐,使它们的特征得以充分融合.在风险领域文本与知识图谱全面对齐的基础上,为进一步缓解远程监督的噪声问题,该模型在联合学习的基础上引入新颖的互注意力机制,允许知识图谱与风险领域文本模型使用各自特有的信息来辅助彼此进行学习.

图5 融入互注意力机制的风险领域实体关系抽取框架Fig.5 Risk field entity in the intense attention mechanism Extraction framework
在风险领域知识图谱的指导下,充分运用图谱中蕴含的领域实体关系信息,在一定程度上能够帮助风险领域文本关系的自动抽取.与此同时,风险领域文本特征也被反馈回领域知识图谱模型去加强那些对训练影响较大的知识三元组.在训练推进的过程中风险领域知识图谱表示学习模型与领域文本关系表示学习模型通过相互指导可以逐步强化各自效果.
1)联合学习的整体模式
整个联合学习模型能够支持风险领域文本关系表示学习模型与知识图谱表示学习模型在统一的低维空间中同时进行训练,从而可以同步获取领域实体、关系及文本的嵌入表示.在训练的过程中,本模型通过统一低维空间使风险领域实体关系判定约束与特征信息能够便捷的在领域文本关系表示学习模型与知识图谱表示学习模型中进行共享和传递.本文将嵌入表示学习模型及其涉及到的参数均定义为模型参数ξ,并将其表示为ξ={ξE,ξR,ξV},其中ξE、ξR和ξV为上文介绍的风险领域文本关系表示学习模型与知识图谱表示学习模型中的实体、关系与文本的嵌入向量和相关参数.因此,该模型的任务是找到一组最优的参数ξ使其满足公式(12):
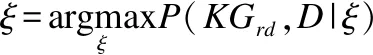
(12)
而联合学习模型的条件概率P(KGrd,D|ξE,ξR,ξV)可进行变换得到公式(13):
P(KGrd,D|ξE,ξR,ξV)=P(KGrd|ξE,ξR)P(D|ξV)
(13)
其中,P(KGrd|ξE,ξR)为知识图谱表示学习模型优化的条件概率,P(D|ξV)为风险领域文本关系表示学习模型优化的条件概率.P(KGrd,D|ξ)为联合学习模型待优化的条件概率,用于刻画风险领域实体、关系与领域文本嵌入ξ的情况下,嵌入表示学习对领域文本与知识图谱的拟合能力.该联合学习模型本质上是找到最好的嵌入表示向量最大限度的拟合给定的风险领域文本语义信息与知识图谱结构.
2)知识图谱与文本的互注意力机制
风险领域知识图谱与领域文本互注意力机制主要由两部分组成,包括基于知识的注意力机制与基于语义的注意力机制.这两部分相互指导与合作,辅助联合学习模型进行关系抽取.
①基于知识的注意力机制
对于风险领域知识(e1,rd,e2),可能存在多个包含实体对(e1,e2)的句子Trd=(d1,…,dn),这些句子往往蕴含实体间的关系rd,其中n为包含实体对的句子总数,且句子的表示向量为{x1,…,xn}.由于基于神经网络的关系抽取算法标注的句子可能存在错误或模糊的噪声成分.因此,本文认为这些句子中有部分句子对领域文本关系表示发挥着较大的作用.而联合学习模型可以充分利用这部分额外的风险领域知识来强化模型训练过程中领域文本词句的向量表示.具体地,本文定义潜在关系向量re1e2为基于知识的注意力用于突出训练数据中较为重要的词句,并通过加权求和获取全局最优的领域文本关系模式的表示向量rs,从而有效缓解模型训练的噪声数据.领域文本关系模式的表示向量rd的计算方法见公式(14):
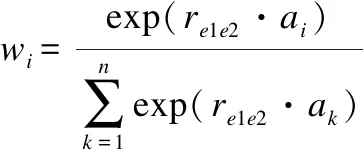
(14)
其中,Md为权重矩阵,bd为权重的偏置向量,wi是句子输出xi的权重.
该表示向量rs可用于计算风险领域文本关系表示学习模型的评分函数S与概率分布P((Trd,rd)|ξv).
S=Mrd
(15)
(16)
②基于语义的注意力机制
风险领域知识图谱的任意关系r均有多个蕴含该关系的实体对EPr={(e11,e21),…,(e1n,e2n)}.实体对EPr对应的潜在关系向量表示为{re11,e21,…,re1n,e2n},其中n为实体对的数量.风险领域知识图谱表示学习模型的目标是运用知识表示学习方法使领域实体对间的所有潜在关系嵌入尽可能接近实体的关系向量.
由于风险领域实体间关系的复杂性与领域知识图谱构建过程中引入的误差,因此风险领域知识图谱表示学习模型训练的过程中很难将实际的实体关系向量与潜在的实体关系向量相接近.为提升风险领域知识图谱表示学习模型的性能,本文尝试从风险领域文本关系表示学习模型中提取相关的语义信息,并运用相关的语义信息帮助实际的关系向量逼近实体对所对应的最准确的潜在关系向量.

(17)
其中,Md和bd为公式(14)中的权重矩阵,用于将神经网络中的特征映射到实体关系的图谱空间中.Hr为公式(15)中关系r对应的特征.wi为第i个潜在关系向量re1ie2i的权重.
综上,本文对这些实体对进行合并,并计算出知识图谱表示学习模型的概率分布P(r|(EPr,ξE,ξR),计算公式见式(18):
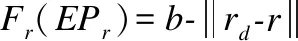
(18)
3.2.4 风险领域实体关系的抽取
本文结合小规模领域知识图谱与大规模领域文本语料库完成知识图谱与领域文本关系表示的联合学习任务,并构建了风险领域实体关系预测模型,用于判别蕴含于特定领域文本中实体间的关系类型.根据表1的实体关系判定的约束条件,风险领域实体关系抽取过程如下.
1)确定风险领域实体关系的类型,并明确构成实体关系的实体类型;
2)从大规模领域文本中获取事实关联强度较高的若干领域实体对;
3)根据小规模领域知识图谱与实体类型约束规则,将关联度较强的实体对划分为不同的实体类型;
4)结合风险领域实体关系类型判别的实体类型约束与事实关联约束,利用基于互注意力机制的联合学习模型进行风险领域实体关系抽取.
4 实验结果与分析
为验证风险领域实体关系抽取方案的有效性,本文以企业风险领域为例展开实验.本节主要从以下4个方面进行详细介绍,主要包括风险领域实验数据集构建、风险领域实体类型约束规则构建、基于互注意力的风险领域实体关系抽取以及风险领域实体关系抽取实例分析.
4.1 风险领域实验数据集构建
本实验需使用两类数据:1)用于指导风险领域实体关系抽取的小规模知识图谱,通过爬取学校购买的DIB风控系统中企业风险数据构建;2)用于提供基于互注意力机制的风险领域实体关系抽取模型训练的领域语料库,通过上市公司2019年企业年报中披露的风险内容进行构建.
4.1.1 风险领域小规模知识图谱构建
本文综合考虑企业风险内容披露习惯、风险领域实体丰富度以及实体关系复杂度与实体关系类型准确度等因素,拟利用学校购买的DIB风控系统中企业风险数据作为构建小规模知识图谱的数据来源.为准确高效获取风险领域相关数据,本文选取八爪鱼采集器V8.3为工具采集企业年报中风险披露内容条目下对应的风险名称、责任部门、风险源、风险后果和应对方法等实体,并根据风险与各类实体对应关系构造层次关系、演化关系、影响部门关系、风险表征关系、影响后果关系和风险应对关系等六类领域实体关系类型.风险领域知识图谱中的实体、关系类型及数量等相关统计信息如表3所示.
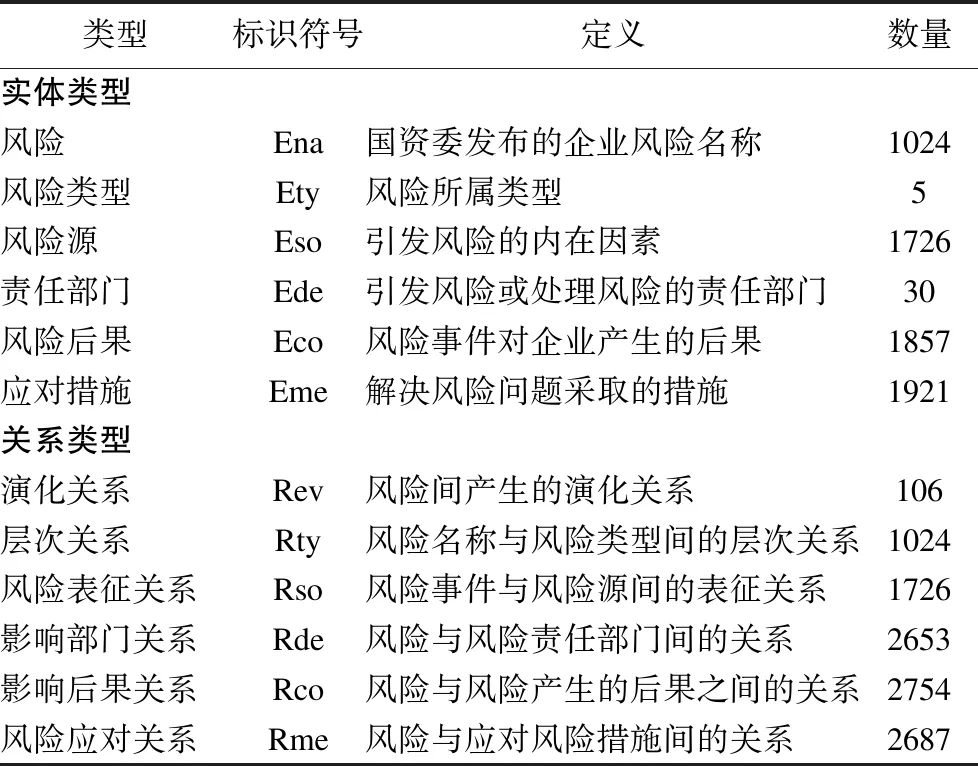
表3 风险领域实体与关系类型统计Table 3 Risk field entity and relationship type statistics
4.1.2 风险领域语料库构建
由于目前国内尚未有标准的企业风险领域文本语料库可用于实验研究,因此本文选取学校购买的DIB风控数据作为领域文本语料对象.选取DIB风控数据的原因在于:1)该库基本涵盖各行各业风险信息与风险案例,能够反映最完整的企业风险领域实体动态;2)该库针对校园网用户开源共享,方便研究者下载与文本数据处理.
企业风险领域语料库构建步骤如下.首先,选取DIB风险数据库中近几年上市公司的风险数据(即10299条粗粒度的文本记录),作为语料库构建的对象.然后,根据Mint等人提出的远程监督算法提取包含表3中风险领域实体、关系与事实的句子加入文本语料库[34].企业风险领域语料库包含102990个句子,6369个实体,共58931个事实三元组.本文将提取的企业风险领域文本语料库命名为RCData.
4.2 风险领域实体类型约束规则构建
风险领域实体关系较为复杂,本文参考国资委发布的风险管理数据以及企业年报中披露的风险数据,同时结合风险领域专家建议,构建了不同实体关系对应的实体类型约束,如表4所示.
4.3 基于互注意力的风险领域实体关系抽取
4.3.1 实验设置
本文从{0.1,0.01,0.001}中为P(KGrd|ξE,ξR)和P(D|ξV)选取知识图谱表示学习模型与领域文本关系表示学习模型的学习率,从{3,5,7}中为卷积神经网络CNN选取滑动窗口数.由于其他的参数对实验影响较小,且为保证实验结果的
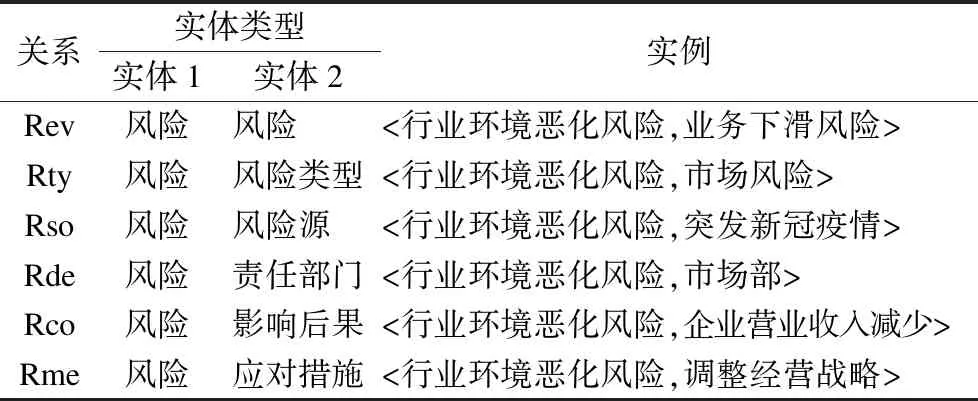
表4 风险领域实体类型约束规则Table 4 Risk field entity type constraint rules

表5 风险领域实体关系抽取参数设置Table 5 Risk field entity relationship extraction parameter setting
准确性与对比的公平性,本实验使用已有研究中对于卷积神经网络的参数设定.领域文本中字、实体和关系的嵌入维度设置为50.风险领域实体关系抽取模型中具体的实验参数设置如表5所示.
4.3.2 风险领域实体关系抽取结果分析
为验证基于互注意力的风险领域实体关系抽取模型的有效性,本文选取基于统计特征的word2vec相似词算法(STAT)、卷积神经网络模型(CNN)、加入句子级别注意力的卷积神经网络模型(CNN+ATT)以及联合学习后具有知识导向注意力机制的卷积神经网络模型(JointL+KGATT)进行对比实验,实验结果如图6所示,图中曲线由上至下分别对应于JointL+KGATT、CNN+ATT、CNN与STAT模型.
实验结果表明,JointL+KGATT模型的精度和效果均优于其他模型.当召回率>0.4时,JointL+KGATT模型的精度整体提升10%~20%,当召回率<0.4时,JointL+KGATT模型也取得较好的效果,且模型的稳定性更好.整体来看,经特征融合后具有知识导向注意力机制的卷积神经网络模型在风险领域实体关系抽取任务上具有明显的优势.此外,相比基于统计特征的关系抽取模型,CNN-ATT和CNN模型在召回率超过0.4时取得了超10%的准确度提升.这表明基于深度神经网络的风险领域实体抽取模型不局限于风险领域特征工程,并能够自动发掘风险领域文本数据中的关系特征,抽取性能稳定且有效.尽管基于统计特征的关系抽取模型精度下降较快,但在最高置信度的推荐中(即召回率在0.1~0.2区间上)能够取得较高的准确度.这表明人工设计的领域特征虽然存在局限性,但存在一定的有效性.基于统计特征的关系抽取模型的优势在于其计算规模较小,且无需大量的训练数据,但有效的特征需人工构建.基于统计特征的模型训练难度相比基于深度神经网络模型简单,将两者相结合用于风险领域实体关系抽取将是未来模型改进的重要方向.
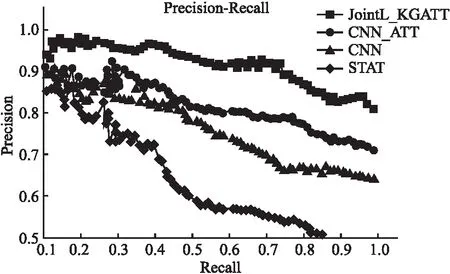
图6 风险领域实体关系抽取模型的准确率-召回率对比Fig.6 Accuracy of the entity of the risk field entity-recall rate comparison
为进一步验证基于知识图谱与领域文本互注意力机制对关系抽取模型性能的影响,本文部分实验采用评估高置信度推荐效果的测试方法.在风险领域实体关系抽取模型的实际应用中,人们通常更关注较高置信度区间的推荐结果,高置信度的推荐能够稳定保持较好的准确率往往更符合企业实际应用需求.评估高置信度推荐效果的测试方法是指将实验部分的推荐得分进行排序,选取较高置信度区间的推荐结果作为衡量模型性能的指标.本实验选取卷积神经网络模型与不同种类的注意力机制相结合,包括未添加注意力机制(NULL)、语句级注意力机制(ATT)与基于知识的注意力机制(KGATT).同时,本实验也将知识图谱表示学习模型与风险领域文本关系表示学习模型相结合,从而定量对比分析联合学习模型及各组合模型性能的优劣.JointL表示联合学习后卷积神经网络得到的关系抽取模型,CNN表示未与知识图谱进行联合学习的卷积神经网络实体关系抽取模型.各组合实验结果如表6所示,其中P@N表示前N个推荐准确率,AVG表示平均准确率.

表6 不同组合模型的P@N抽取结果Table 6 P@N extract results of different combined models
实验结果表明,联合学习框架下基于知识注意力的风险领域实体抽取模型精度优于其他组合模型,且抽取效果显著提升.从平均推荐准确率来看,CNN模型与CNN+ATT模型经联合学习后准确率也呈现一定程度的提升.这表明,联合学习框架下融合特征的有效性以及联合学习后文本模型在知识图谱指导下提升了自身的关系抽取效果.同时,对比引入注意力机制与未引入注意力机制的组合模型可知,引入注意力的语句合并机制的ATT与KGATT组合模型比未引入注意力机制的组合模型效果更好.原因在于各组合模型训练中使用的风险领域文本语料是通过远程监督机制自动构建的,构建过程中可能存在一些噪声数据.而注意力机制可以更多的关注风险领域文本中对于实体关系抽取更有意义的语句,从而有效削弱噪声数据对抽取效果的影响.
此外,KGATT和ATT模型对比进一步表明,在跨句注意力机制中,未引入风险领域知识图谱的注意力机制仍略显薄弱.原因在于风险领域实体丰富且关系复杂,即使相同关系的不同实体对间也会存在细微的差别.简单的ATT机制是通过模糊的全局向量进行语句重要性的选择,难以满足风险领域实体关系多样性的特征.而KGATT模型将知识图谱的实体关系相关信息融入注意力机制中.对于不同的实体对,KGATT模型运用局部向量对重要的语句进行选择,而这些局部向量又在全局上密切相关.因此,引入KGATT机制的组合模型相比ATT机制更具有区分度与识别能力.
4.4 风险领域实体关系抽取实例分析
由于风险领域实体关系多样,为便于风险领域专家的评估,本实验选取“新冠疫情风险”为例展开风险领域实体关系抽取的实例分析.根据风险领域实体关系抽取的3个约束条件,本文采用已有的风险领域实体抽取方法筛选“新冠疫情风险”强相关的领域实体,再运用基于互注意力机的联合学习模型预测领域实体关系的条件概率.风险领域实体关系预测的概率分布结果如表7所示.
为进一步检验风险领域实体关系抽取效果,本文邀请风控领域专家评估关系抽取结果.具体评估方法为从“是否可构成该实体关系”的角度考察联合学习模型下风险领域中“新冠疫情风险”相关实体关系抽取结果是否成立,按照“成立,模糊成立,不成立”等3个等级.
考虑到风险领域知识的复杂性与风控领域专家知识的全面性,本实验还配备了专业的信息分析人员,辅助风控领域专家共同进行结果评估,进一步确保了评估结果的公平性与准确性.评估结果为该关系类型成立、模糊成立或不成立的数量占该类关系总数的比例,如表8所示.
由表8可知,风险领域中“新冠疫情风险”相关实体关系总体评估为成立的关系占89.3%,评估为模糊成立的关系占3.5%,评估为不成立的关系为7.2%.鉴于风险领域实体丰富且关系复杂,风险间的演化、风险引发的后果及其应对措施等关系存在模糊不确定性,本文方法的整体误判率为10.7%,表明该方法整体有效可行.
从风险领域各类实体关系抽取角度分析,风险应对措施与风险影响部门关系判定为成立的比率较高,而风险演化关系与风险源表征关系判定为不成立的比率较高.其原因在于,风险领域中各风险间的演化复杂多变,且影响风险发生的内在因素多样,而风险责任部门及其应对措施等知识相对较明确.因此,风险领域实体关系抽取的准确率一定程度上受领域知识特性的影响.
综上所述,考虑到风险领域实体关系的复杂性与不确定性,本文在实验和评估中均采用了较为严格的标准,但实验结果仍表明基于知识图谱与领域文本互注意力的风险领域实体

表7 风险领域实体关系预测概率Table 7 Risk field entity relationship prediction probability

表8 风险领域相关实体关系抽取评估结果
抽取思路的可行性.通过风险领域实体关系抽取的实例分析,本文发现较多在领域知识图谱中不存在的“新冠疫情风险”相关实体关系对,如应收账款回收风险、产业链中断、技术部等.针对这一现象,风险领域专家表示,本实验抽取过程中发现的间接关系和诱发关系将对风险领域知识图谱的完善以及风险防控具有较高的参考价值.因此,基于知识图谱与领域文本互注意力的风险领域实体抽取研究与结果具有重要的实践意义.
5 结 论
本文从小规模知识图谱视角出发,在知识图谱与领域文本表示学习的基础上,引入新颖的互注意力机制辅助领域图谱与文本间相互学习,提出基于互注意力的联合学习模型,并在风险领域数据集上验证了该模型对风险领域实体关系抽取的效果.本文的主要贡献在于,理论上,将新颖的互注意力机制引入风险领域实体关系抽取中,深入研究了知识图谱指导下领域文本关系表示学习和领域实体关系抽取的原理与方法,系统性的构建了风险领域实体关系抽取模型与框架,这对于知识图谱与表示学习在风险管理领域的理论与发展具有促进作用.实践上,本文探究了不同的关系抽取模型在风险领域数据集上的效果,并结合风险领域具体实例对比分析了各类领域实体关系类型抽取效果,研究结果对风险领域知识图谱的完善以及风险防控具有借鉴作用.
本文的不足之处在于,受限于时间与数据集,本文仅在企业风险领域情境下研究关系抽取.在后续的研究中,本文将进一步探索本模型的扩展能力,并探索在实体关系复杂多变的领域文本中关系抽取的解决方法.此外,相比于通识领域风险领域本文仍存在较多的独特性.因此,风险领域文本特征的表达能力仍有较大的研究与提升空间,这也是未来风险领域知识抽取亟待研究与解决的问题之一.
