一种改进GraphRNN的多标签文本分类方法
2023-05-12刘汉东钟学燕
刘汉东,钟学燕,陈 雁,王 欣
(西南石油大学 计算机科学学院,成都 610500)
1 引 言
多标签分类是机器学习领域中一个重要的学习任务,其样本可以被分配到多个标签上,被广泛应用于文本分类[1]、图像标注[2]、推荐系统[3]等实际场景.对于多标签分类问题,传统的多标签分类方法可分为问题转换[4-6]和算法适应[7,8],在标签数量较小的情况下效果不错,但当标签空间较大时,输出空间会出现指数级增长,最坏情况计算复杂度达到2q,q为标签空间大小,在这种情形下传统方法难以满足性能需求.
实际上,多数场景中标签之间存在关联,利用标签关联可以降低多标签分类问题的难度.由于传统方法建模标签关联的能力有限,因此有研究将循环神经网络(Recurrent Neural Networks,RNN)用于多标签分类[9-11].RNN具有短期记忆能力,常用于处理时间序列数据,在序列到序列(Sequence to Sequence,Seq2Seq)[12]模型下,基于RNN可以将多标签分类问题转换为多标签序列生成问题[13],能很好地建模标签关联.这种方法的关键是如何将多个标签按某种顺序转换为标签序列[14,15],事实上,分类结果受标签顺序影响,而现实场景中适合数据的标签顺序难以事先得知,预先指定顺序可能会破坏标签之间的自然关联.对于这一问题,现有研究主要有两类解决方法:1)使模型具有自适应确定合理标签顺序的能力[15,16];2)直接生成标签集[17,18],而非标签序列.然而,标签之间的关联是复杂的,共现频率高的标签关联程度高,共现频率低的标签关联程度相对偏低.在建模标签关联时,通常希望关联程度高的标签位置邻近,而关联程度低的标签相隔较远,利用标签关联程度可以对标签重排列,有助于分类.现有的两类方法能建模标签关联并减少模型对标签顺序的依赖,但在建模标签关联程度方面存在不足.
在文本分类领域,针对现有方法的不足,本文提出基于改进图循环神经网络(Graph Recurrent Neural Network,GraphRNN)[19]的多标签文本分类,能同时解决预定义标签顺序和建模标签关联程度不足的问题.具体地,本文从标签共现信息中挖掘全局性的标签关联程度,构建标签图来表示标签集,将原始问题转化为图生成问题,从而避免预定义标签顺序;在标签图生成过程中,节点生成建模标签关联,边生成建模标签关联程度,最后将生成的标签图转回为标签集,作为分类结果.本文主要贡献有如下两个方面:
1)将多标签分类问题转换为标签图生成问题,可避免预定义标签顺序;
2)利用标签共现信息,建模标签关联程度,可以更细致地建模标签关联.
2 相关研究
2.1 多标签分类
从利用标签关联的角度分析,多标签分类方法大致可以分为3类[20]:1)一阶方法,典型算法如Binary Relevance[4]、ML-KNN[8],这类方法简单有效,但忽略了标签关联;2)二阶方法,典型算法如Rank-SVM[7]、Calibrated Label Ranking[5],这类方法考虑标签对两两之间的联系,如排序问题中标签之间的前后关系[21];3)高阶方法,这类方法能建模多个标签之间的关联,但需要预定义顺序,存在累计误差,典型算法如Classifier Chains[22]、Ensemble Classifier Chains[22].在以上3类方法中,高阶方法能够更好地挖掘标签关联,目前围绕此类方法展开的研究居多.
为了缓解标签顺序对Classifier Chains的影响,赖德迪等[23]在Classifier Chains的基础上根据标签共现信息采用贪心策略和n-gram方法优化标签序列,但在标签序列的优化上易陷入局部最优.肖琳等[24]认为标签包含语义信息,利用词嵌入方法表示标签来隐式地考虑标签关联,并在注意力机制(Attention)下获取标签的文档表示,通过感知机预测每一个标签的出现概率,但缺乏显示地对标签关联进行建模,仅依靠标签语义难以建模语义上不相似但共现程度较高的标签间的关联.得益于图卷积网络(Graph Convolutional Network,GCN)强大的特征抽取能力,刘晓玲等[25]基于GCN建模标签高阶关联,但在建模标签关联时没有考虑输入的文本信息,而借助输入信息可以更好地在特定语义下表示标签关联.由于RNN具有记忆能力,近年来,不少研究还利用RNN建模标签高阶关联,Nam等[10]、Yang等[13]、王浩镔等[26]在seq2seq模型下,基于RNN将多标签分类转化为多标签序列生成问题,该方法由于使用RNN可以很好地建模标签关联,但受限于需要预定义标签顺序.
避免预定义标签顺序的方法主要有两类:自适应确定标签顺序和预测标签集.对于自适应确定标签顺序的方法,Chen等[16]在图像分类中利用注意力机制自动生成标签,但在训练阶段仍然需要初始化标签顺序;Vinyals等[15]使模型自适应选择概率最大的标签顺序用于训练,但训练后期的样本可能会被施加不合适的标签顺序;因此,Vinyals等[15]又通过采样的方式选择标签顺序训练模型,增加了标签顺序多样性,但易受概率较小的标签顺序影响.在预测标签集的方法中,Yang等[18]提出seq2set模型,将多标签文本分类作为一个强化学习问题;Qin等[17]提出set-RNN方法,将标签集概率近似为TopK种排列组合下的序列概率之和,在预测时,选取集合概率最大的标签集作为预测结果.以上两类方法,均能避免预定义标签顺序,并建模标签关联,但没有对标签关联程度进行区分,而实际上标签关联也有大小之分.
综上所述,已有方法主要探索如何建模标签高阶关联,其中又以基于RNN的方法居多,而在利用RNN建模标签高阶关联时,存在需要预定义标签顺序的问题,同时缺乏对标签关联程度的建模.
2.2 GraphRNN
GraphRNN是You等[19]提出的一种图生成模型,其基于RNN,包含节点生成(Node-level RNN)和边生成(Edge-level RNN)两部分,前者生成当前图的拓扑结构状态,后者生成边信息.模型输入为初始图状态,输出为不同时刻对应的邻接向量,根据邻接向量可还原邻接矩阵,进而得到生成的图.然而,GraphRNN生成的图节点没有具体含义,这与标签具有实际含义相悖.另外,GraphRNN只输出邻接向量,缺少节点输出模块,因而无法直接用于多标签分类,需适当改进.
因此,在利用RNN建模标签高阶关联时,不同于现有方法,本文将标签集表示为标签图,建立图生成模型并用于多标签文本分类,避免预定义标签顺序.不仅如此,通过图生成中的边生成过程还能建模标签关联程度,更细致地建模标签关联.本文与现有研究的主要区别在于:避免预定义标签顺序,不仅建模标签关联,还建模了标签关联程度;改进GraphRNN以适用多标签文本分类.
3 基于改进GraphRNN的多标签文本分类
3.1 多标签文本分类定义
定义1.假设样本输入空间X⊆Rd,标签输出空间L={λ1,λ2,…,λq},当前数据集为D={(xn,yn)|1≤n≤N},xn∈X表示某样本输入信息,yn⊆L表示某样本对应的标签.多标签文本分类任务就是从数据中学习一个决策函数h:X→2L,使得每个文本被分配到一组标签上去.
3.2 标签图构建
本文将多标签文本分类转换为标签图生成问题,因此在建立模型之前,需要将文本对应的原始标签集转换为标签图G=(V,E),其中节点vi∈V表示标签,边ei,j∈E表示vi与vj的关联程度,可通过标签共现信息进行描述,具体做法为根据标签共现程度大小划分出多个区间,不同的区间对应不同的标签关联程度,从而表示标签之间的连边大小.如图1所示,将单个文本的所有标签对视为共现标签对,对于N个文本,统计标签频次、标签对共现频次,给出标签间的共现程度定义.
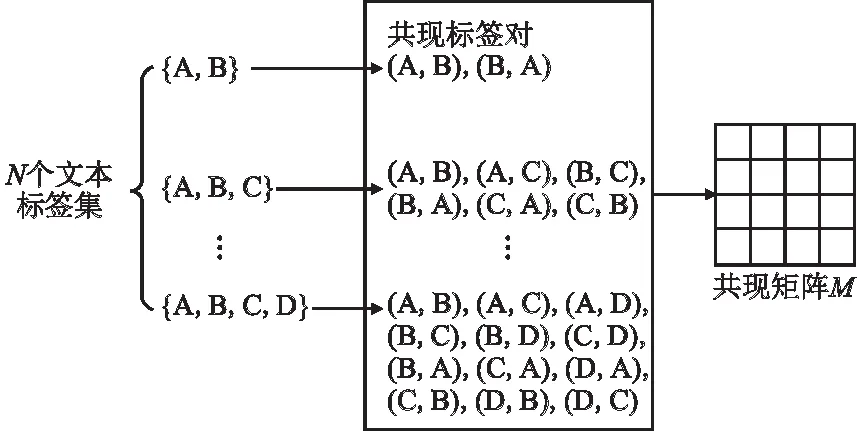
图1 构建共现矩阵Fig.1 Generationof the co-occurrence matrix
定义2.标签共现程度定义为标签之间的正点互信息(Positive Pointwise Mutual Information,PPMI),PPMI可可衡量两个事物之间的相关性,其计算如式(1)所示,λa和λb表示来源于L的两个不同标签,p(λa)和p(λb)分别表示λa和λb的标签频次,p(λa,λb)表示标签对(λa,λb)的共现频次.
(1)
由于相关性高的标签通常共现程度也高,故此处将PPMI用于衡量两个标签之间的共现程度.根据定义2,计算L中标签两两之间的PPMI,得到q×q的对称标签共现矩阵M,主对角线上的元素为0,其保存了标签两两之间的共现信息,值越大表示二者关联程度越大.假设vi和vj对应的标签恰为λa和λb,其PPMI为Mab,Mab表示标签共现矩阵第a行第b列的元素,则可根据关联程度阈值θz划分出多个区间,进而确定标签连边ei,j.如式(2)所示,θz,z=1,2,…,m,表示标签共现程度大小,值越大关联程度越大,ei,j取值范围为[0,m]间的整数,0表示不存在连边,即标签关联程度较低,设置不同的θz可将标签关联程度划分成多个区间,对应不同的标签连边大小.
(2)
标签连边确定之后即可构建标签图,图2展示了标签集{A,B,C}转换为标签图的过程.

图2 数据转换示例Fig.2 Example of data transformation
3.3 模型框架
GraphRNN模型将图表示为G,其概率分布如式(3)~式(5)所示:
(3)
(4)
(5)
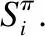
定义3.在改进GraphRNN中,将节点集合表示为V,节点对应的邻接向量集合表示为S,则G=(V,S),当考虑输入文本信息x时,图G的条件概率表示为p(G|x),如式(6)所示:
(6)
在式(6)中,π表示某种节点顺序,|V|表示节点集合大小,vi表示第i个节点,si表示第i个节点的邻接向量,si,t表示si中第t个元素,T表示si元素个数.根据式(6)单个样本的条件概率,可得出在所有样本上的训练目标,如式(7)所示:
(7)
由此,基于改进GraphRNN的多标签文本分类模型框架如图3所示,包括:Encoder、改进GraphRNN和Graph2Seq这3个模块.模型所使用的RNN均为门控循环单元[27](Gated Recurrent Unit,GRU),GRU为RNN的一种变体,可缓解RNN存在的梯度爆炸或消失问题,下文将分别介绍这3个模块.
3.3.1 Encoder
(8)
3.3.2 改进GraphRNN
在图3中,输入文本信息x经encoder编码后在注意力机制下被送至改进GraphRNN.改进GraphRNN即解码器(Decoder)端,由节点生成(Node-level RNN)和边生成(Edge-level RNN)组成,改进点包括两个方面:
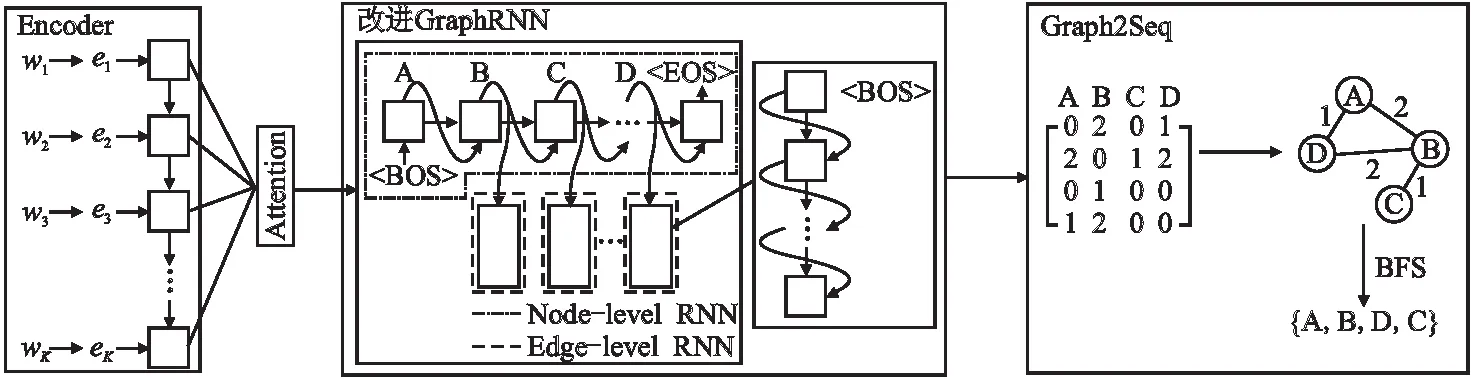
图3 基于改进GraphRNN的多标签文本分类模型框架Fig.3 Multi-label text classification model framework based on improved GraphRNN
1)节点生成添加softmax模块后生成标签节点,建模标签关联;
2)边生成由二分类改为多分类,可以建模标签不同的关联程度.
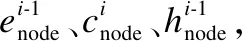
(9)
(10)
(11)

(12)
(13)
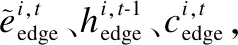
(14)
(15)
经过softmax模块得到第t步连边概率分布,如式(16)所示,Wedge表示要学习的参数,根据p(si,t|si, (16) 在图3中,当预测节点标签为“ 3.3.3 Graph2Seq Graph2Seq模块将生成的标签图G转换为标签集,作为分类结果.具体地,由改进GraphRNN生成的节点集合V和邻接向量集合S可以还原邻接矩阵,进而得到标签图,在图上以V中的第1个节点v1作为起始节点进行广度优先搜索(Breadth-First Search,BFS)得到标签序列作为分类结果.在图3中,GraphSeq模块根据图生成结果构建邻接矩阵,进而画出由标签A、B、C和D构成的标签图,在图上进行BFS得到最终的标签集{A,B,D,C},作为多标签分类结果. 将改进GraphRNN用于多标签文本分类,包括训练和测试两个过程,具体描述如算法1. 算法1.基于改进GraphRNN的多标签文本分类 输入:训练集Dtrain={(xu,yu)|1≤u≤U},测试样本xtest,最大前驱节点数T,结束标识符 输出:测试样本标签集合ytest 训练过程: 步骤1.确定训练轮数epochs,批量大小batchsize,迭代次数iterations=U/batchsize 步骤2.forepoch= 1 toepochsdo 步骤2.1.foriteration= 1 toiterationsdo 步骤2.1.1.将Dtrain中一个batchsize的数据送入模型经Encoder编码,改进GraphRNN解码 步骤2.1.2.计算交叉熵损失并利用梯度下降法更新模型参数 步骤3.训练结束后,得到模型参数,包括Encoder、Attention、改进GraphRNN的参数 测试过程: 步骤4.将测试样本xtest送入模型经Encoder编码 步骤5.将xtest编码后的信息送入改进GraphRNN解码 步骤5.1.node-level RNN根据式(13)预测节点vi 步骤5.2.whilevi不为 步骤5.2.1.fort= 1 toTdo 步骤5.2.1.1.edge-level RNN根据式(16)得到预测连边si,t 步骤5.2.2.得到vi对应的邻接向量si 步骤6.得到预测节点集合V={v1,v2,…,v|V|}和预测邻接向量集合S={s2,s3,…,s|V|} 步骤7.在Graph2Seq模块中根据V和S得到生成图的邻接矩阵,进一步将邻接矩阵转换为标签图G 步骤8.在标签图G上进行BFS遍历,得到测试样本预测标签集合ytest,算法结束 首先根据3.2将标签数据转换为标签图.在训练模型时,需要确定图节点的顺序π.当图节点数目较大时,图节点顺序的组合方式过多,难以将所有的顺序纳入计算.本文采用You等[19]的方法,在图上使用BFS以获得节点顺序.实际上,使用BFS可带来两点好处:1)是不同的节点顺序可以对应到相同的BFS序列,即BFS序列与节点顺序是一对多关系;2)是BFS可对节点顺序重排列,使得存在连边的节点比较邻近.进一步,为使得关联程度较大的标签邻近,本文在BFS的基础上按照标签关联程度由大到小对节点顺序重排列.因此本文在训练模型时将标签图的概率近似为|V|个BFS序列下的概率之和,如式(17)所示.这|V|个BFS序列分别以各个标签为起点在图上遍历所得到. (17) 另外,为保证不同节点下生成的邻接向量长度一致,本文设置统一的前驱节点数T作为超参数,对前驱节点个数进行限制,使得边生成最大长度保持一致.例如,若设置T为2,以图2中原始标签顺序排列,则标签C对应的邻接向量可表示为[1 2]T. 图4 图生成示例Fig.4 Example of graph generation 在预测阶段,输入信息经过编码后,即可利用改进GraphRNN模块进行节点生成和边生成.图4为图生成示例.在初始时,既没有节点也没有边,首先进行节点生成,生成第个节点A后,由于不允许自环,在下一步继续进行节点生成;当第2个节点B生成后,开始生成B的连边,B节点连边生成完毕后,又通过节点生成得到C.后续过程中,节点生成和边生成往复进行,直到节点生成“ 本文采用文本数据集AAPD[13]和SLASHDOT[17]作为实验数据.AAPD来源于arxiv论文数据集,共54840条数据,标签数量为54,SLASHDOT来源于Qin等[17]整理的科技新闻数据,共24072条数据,标签数量为291.数据集详细信息如表1所示. 表1 数据集信息Table 1 Datasets information 由于数据集文本长度不一,本文对数据集设定阈值进行截断,AAPD最大长度设置为500,SLASHDOT最大设置长度为120,低于阈值长度的文本使用“ (18) (19) (20) q表示标签空间大小,N表示样本总数.HL计算预测标签和真实标签的对称差集,值越小越好,instance-F1、label-F1分别度量样本、标签的F1值,值越大越好. 表2 不同方法实验结果Table 2 Experimental results of different methods 本文使用设置对比方法如下: 1)Binary Relevance[4](BR):将多标签分类问题转换为二分类问题,没有利用标签之间的相关性. 2)Classifier Chains[22](CC):将多个BR级联起来,前一分类器输出作为后一分类器输入,该方法能考虑到标签之间的高阶关联. 3)Ensemble Classifier Chains[22](ECC):在Classifier Chains的基础上,随机集成11种标签顺序训练模型. 4)Seq2seq-GRU[10]:在seq2seq模型下基于GRU,按标签频次降序训练模型,生成多标签序列. 5)Set-RNN[17]:将多标签视为标签集合,直接生成多标签集合. 6)改进GraphRNN:本文方法,将原始问题转换为标签图生成问题,在图上进行BFS得到分类结果. 实验结果如表2所示,本文方法在instance-F1和label-F1上均表现最优.具体地,在两个数据集上,对于传统方法,CC建模标签高阶关联,除了HL以外表现优于BR,ECC在CC基础上集成多种标签顺序下模型的结果,相比CC取得更好的效果,尤其在HL上优于其他方法.而seq2seq-GRU利用神经网络建模标签高阶关联,能获取更复杂的标签依赖,在instance-F1及label-F1表现优于BR、CC和ECC.由于set-RNN预测标签集合,免受不当的标签顺序可能破坏标签自然关联的影响,效果优于seq2seq-GRU.相比于set-RNN,改进GraphRNN在instance-F1和label-F1上均取得最优效果,说明本文方法能更好地建模标签之间的关联.然而,CC、seq2seq-GRU、set-RNN和本文方法在HL指标上均表现不佳,其原因可能为累计误差使得误分类标签较多,预测标签数量相对真实标签较大,即真实标签集中不存在的标签也出现在预测标签中. 4.2.1 前驱节点数T的影响 在构建标签图时,设置不同的前驱节点数T,影响邻接向量的长度,代表着模型对标签关联程度建模的能力.本文设置不同的前驱节点数T进行对比实验,结果如表3所示,在AAPD上设置为2时表现最好,为1时其次,设置为4时较差,在SLASHDOT上设置为3时最好,为1和5时较差.以上结果说明,在设置T时,应根据数据集平均标签数进行设置,不宜过小或过大.当T过小时,难以建模更多的标签关联程度;而T较大时可以考虑更多标签之间的关联程度,若设置过大则表现不佳,说明模型边生成能力有限,对于位置较远的前驱节点,无法准确地预测与之的关联程度;对于平均标签数量较大的数据集,通常需要更大的T.实际上,较大的前驱节点数也会增加模型训练开销,在计算资源有限的情况下,需要在模型性能和计算开销上进行综合考量,因此文本方法更适用于样本标签较少的情况. 表3 不同T的实验结果 4.2.2 消融实验 为验证边生成过程对标签关联程度的建模是否能帮助模型提升性能,本文在设计消融实验时,去掉改进GraphRNN的边生成模块,只进行节点生成,并与完整的基于改进GraphRNN的方法进行对比,实验结果如表4所示. 表4 消融实验结果Table 4 Result of ablation experiment 从表4中可以看出,包含边生成模块的改进GraphRNN方法,在instance-F1、label-F1和HL3个指标上,相比不包含边生成模块,均表现更好.对标签关联程度的建模是对标签关联细粒度的区分,消融实验结果表明本文对标签关联程度的建模,能够增强模型建模标签关联的能力. 本文提出基于改进图循环神经网络的方法来解决多标签文本分类问题.为描述标签之间关联性,本文将多标签表示为标签图,其中节点表示标签,边表示标签共现信息,从而将多标签文本分类转换为标签图生成问题.标签图的生成不仅捕获了标签高阶关联,还能对标签关联程度进行区分,同时避免预定义标签顺序,减少模型对于标签顺序的依赖.本文提出的方法在instance-F1和label-F1指标上均优于基线方法,表明对标签关联程度的建模有效地增强了模型建模标签关联的能力,但在HL指标表现不佳,可能是受累计误差影响,下一步工作将对此问题展开研究.3.4 基于改进GraphRNN进行多标签文本分类
4 实 验
4.1 实验设置

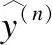
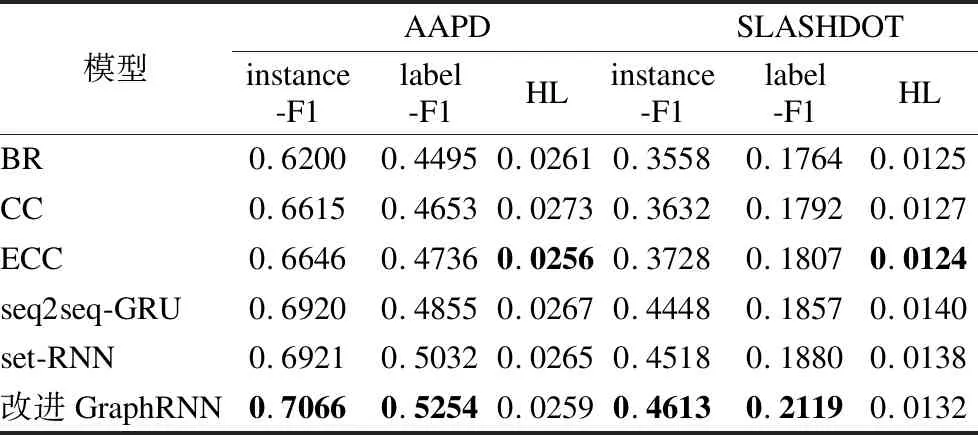
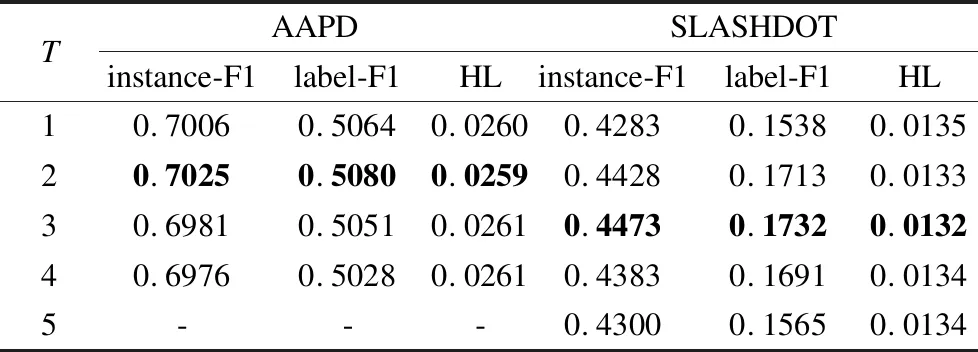
4.2 结果和分析

5 结 语
