基于细粒度特征与注意力机制的机载图像匹配
2023-05-12俞心蕊姚竹贤连思铭丁祝顺
俞心蕊 姚竹贤,2 连思铭 丁祝顺
1. 北京航天控制仪器研究所,北京 100039 2. 中国航天电子技术研究院,北京 100094
0 引言
机载图像匹配技术是定位导航、目标跟踪等应用的基础,对匹配精度与效率都有着极高的要求。随着计算机技术的发展,基于深度学习的策略成为机载图像匹配任务的主流研究方向。目前绝大多数策略都是基于卷积神经网络,如文献[1-3]分别基于VGG[4]网络、ResNet[5]网络、NCN[6]网络来解决正射视角的航空图像匹配问题。但在实际飞行中,拍摄视角具有不确定性,图像会有空间上的转换,需要充分理解全局关系。而基于卷积神经网络的方法感受野较小,无法在不破坏细粒度特征的同时获取全局特征关联。为此,学者们将具有全局感受野的注意力机制[7]引入机载图像匹配任务,如文献[8-9]分别基于空间转换器[10](Spatial Transformer, ST)和视觉转换器[11](Vision Transformer, ViT)来处理多视角机载图像匹配问题。但上述方法在特征提取阶段忽略了匹配图像间的关联关系。而文献[12]已证明,进一步学习图像间的相似性特征能有效提高后续匹配的精度。
因此,本文提出了一种基于细粒度特征和互注意力机制的机载图像匹配方法(Image Matching based onFine-Grained Features andMutualAttention Mechanism, FGMA)。该方法以ViT为主干网络提取局部细粒度特征和全局语义信息,引入互注意力机制来联合学习匹配图像间的相似性特征,将细粒度特征按注意力得分进行分割对齐,并使用改进的三重损失约束FGMA模型,实现多视图多视角机载图像匹配。
1 基于细粒度特征与互注意力的机载图像匹配框架
1.1 FGMA模型结构
FGMA由特征提取模块和匹配模块组成,具体如图1所示。特征提取模块利用ViT提取图像局部细粒度特征和全局语义特征并融合,通过互注意力机制来增强图像间相似度高的细粒度特征;匹配模块通过计算每个细粒度特征的均值得到对应的注意力得分,按分值将细粒度特征分割对齐,用改进的三重损失约束模型进行训练。
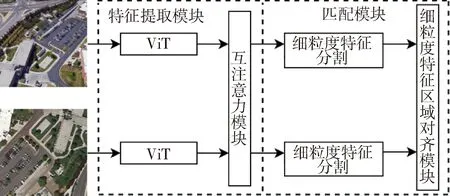
图1 FGMA模型结构示意图
1.2 FGMA特征提取模块
1.2.1 视觉转换器ViT模块

(1)
(2)
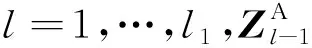
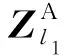
(3)
(4)
1.2.2 互注意力模块
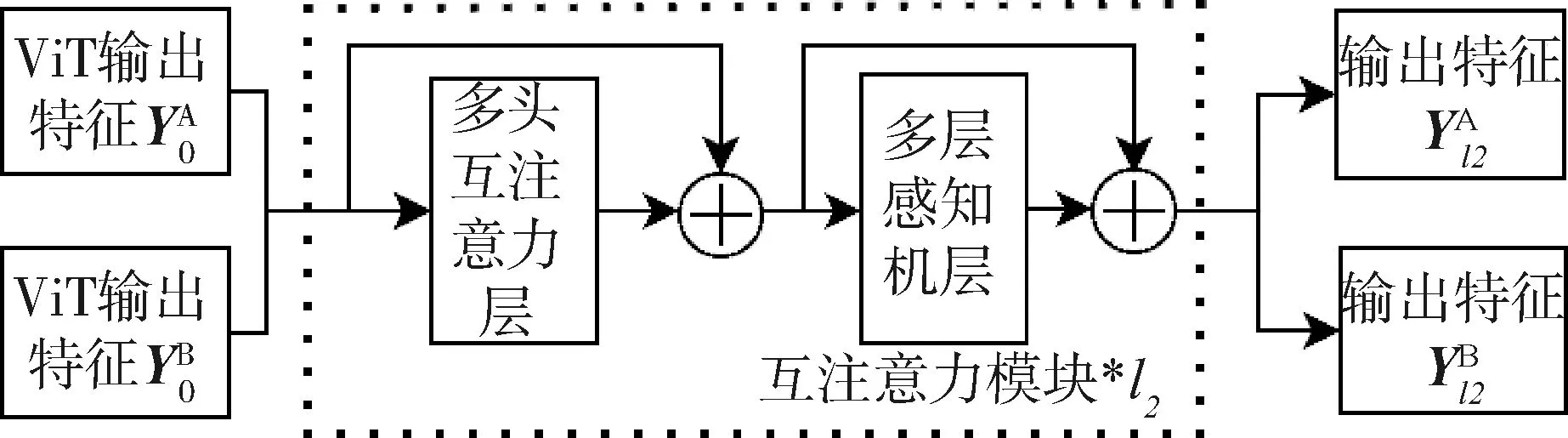
图3 互注意力模块结构示意图
(5)
(6)
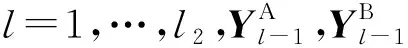
1.3 FGMA匹配模块
在多视图多视角图像匹配中直接引入衡量全局特征差异会导致图像匹配的精确度不高。基于此,本文引入了基于细粒度特征的分割对齐方式。根据每个细粒度特征的注意力得分,将特征划分为m个区域对齐。特征分割示意图如图4所示,其中(a)为原输入图像,(b)为注意力得分的可视化热力图,(c)为特征分割示意图。

图4 特征分割示意图
(7)
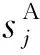

(8)

取m=3,即将按注意力得分重新排序后的细粒度特征按分值划分为3个等级,使用数字1、2、3来定义。令得分最高的细粒度特征区域为f1,其次为f2,f3,对fi,i={1,2,3}进行平均池化操作,得到描述每个区域的特征向量Ei表达式如下:
(9)
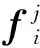
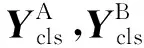
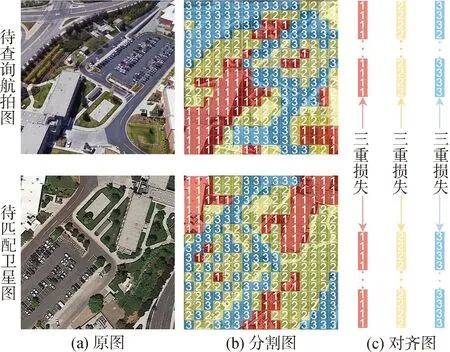
图5 特征块对齐示意图
1.4 损失函数
FGMA模型的损失函数由交叉熵损失和三重损失组成。其中,交叉熵损失用来预测图像的类别,三重损失用来约束图像中不同区域间的距离,具体过程如下。
通过交叉熵损失L1对图像分类结果进行约束,公式如下:
(10)
式中:pi表示样本i的标签,正类为1,负类为0;qi表示样本i的预测正确的概率。
为了使模型建立更准确的匹配关系,应用改进的三重损失L2对分类后的细粒度特征进行自监督训练,最小化两张图像中相似区域之间的距离,表达式如下:
L2=ln(1+exp(d(a,p)-d(a,n)))
(11)
(12)
2 实验
2.1 数据集
由于本文研究内容侧重于机载图像匹配,因此所用数据集是基于开源的University-1652数据集[15]重新划分所得。其中,训练集包含1012对无人机图像和待匹配卫星图像;测试集包含128*10=1280张待查询无人机多图像和896张待匹配卫星图像。
2.2 实施细节
在参数初始化方面,分类器模块采用kaiming[16]初始化。训练时,本文输入图像先经过图像增强(如随机填充、随机裁剪和随机翻转等),并将大小调整为256×256。优化器方面,采用随机梯度下降法,设置动量为0.9,权重衰减为0.0005,小批量为32。对于初始学习率,主干网络参数设置为0.0015,其余可学习参数设置为0.05。模型总共训练了100个周期。网络使用交叉熵损失和三重损失分别约束分类结果和匹配效果。在测试过程中,使用欧氏距离计算查询图像和待匹配图像间相似度。FGMA模型基于Pytorch框架实现,所有实验都在Nvidia GTX 1080Ti GPU上进行。
2.3 实验评估
为了验证所提出方法的有效性,设计如下实验: 1)验证基于注意机制的多视图多视角机载图像匹配效果。该实验分为2个部分,首先在其他模块不变的情况下用ResNet网络替代ViT网络,来验证获取全局信息的必要性。其次,在以Vit为主干网络的基础上,通过改变互注意力模块的深度验证互注意力模块的有效性。2)对比划分区域数量对图像匹配效果的影响,验证按注意力得分重新划分后的细粒度特征类别的可靠性。
2.3.1 基于注意力机制的机载图像匹配实验
表1对比了基于注意力的ViT网络和基于卷积的ResNet网络处理本文任务的效果。从表中数据可以看出层深为8的小尺寸Vit-S网络比ResNet-50的F1分数高10.12%,比ResNet-101的F1分数高6.17%,推理时间仅为ResNet-50的1.26倍,相比于ResNet-101推理速度更快。这是因为注意机制允许网络关注全局信息,而基于纯卷积神经网络的方法只关注显著信息,忽略了全局信息。因此,上述实验证明了全局信息有助于提升多视图多视角机载图像匹配性能。此外,还比较了层深为12的标准尺寸视觉转换器Vit-B网络,发现加深ViT网络在牺牲推理速度的同时匹配效果并没有带来明显的改善。因此选用ViT-S作为模型的主干。
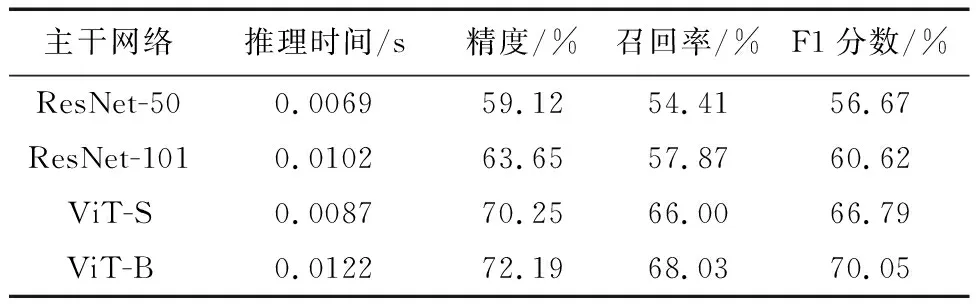
表1 不同主干网络对比
表2展现了互注意力机制在多视图多视角机载图像匹配中的效果。从表2可以看出仅加入1层互注意力机制,整个模型的F1分数提高了2.97%,而推理速度仅仅增加了0.0028s,证实了所加互注意力机制的有效性;如果加入5层,在略微增加耗时的情况下,模型F1分数提高了8.02%;但继续加深互注意力机制,模型性能不升反降,分析原因应是随着层深增加,参数过多,造成过拟合现象。因此,本文FGMA模型中设置5层互注意力层。
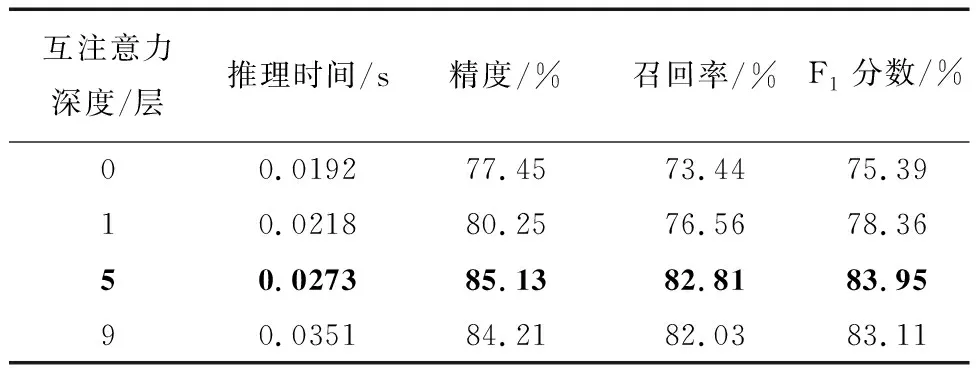
表2 互注意力机制的影响
2.3.2 区域数量对匹配效果的影响实验
表3展现了分割区域m的选择对匹配性能的影响。从表中可以发现,选取不同的m,模型匹配性能会略有不同,但m>1时的匹配性能明显优于m=1,即将图像分割后按区域对齐,要优于直接按整张图像对齐的匹配策略,证实了本文FGMA模型匹配模块的有效性。此外,从表中可以发现,分割区域并不是越多越好,分割区域的数量与模型提取的细粒度特征大小息息相关,而细粒度特征的大小决定了它学习信息的能力。
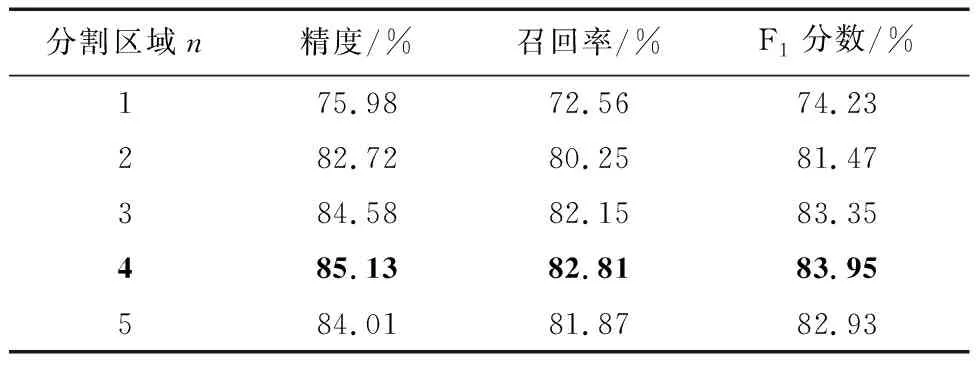
表3 分割区域数量的影响
图6展示了FGMA模型在University-1652数据集上测试的部分结果。图中返回的匹配图像上方数值为1表示为正确匹配,为0则为错误匹配。图6(a)展示了不同场景图像的匹配结果,均为正确匹配,证实了所提模型具有一定的泛化性。图6(b)和(c)展示了不同视角拍摄的同一场景图像的匹配
结果,其中(b)是分割区域m=4时的匹配结果,(c)是m=1时的匹配结果。从图中可以发现,当m=1,即不分割区域时,不是所有视角的图像都能返回正确匹配,而当m=4时,不论从什么视角拍摄的机载图像,都能返回正确的卫星图像。因此,证实了本文提出的FGMA模型对多视图多视角的机载匹配图像具有鲁棒性。
3 结论
将注意力机制应用于多视图多视角机载图像匹配任务,来融合细粒度特征和全局语义信息。此外,还引入互注意力模块和细粒度特征分割与对齐模块来提高模型的匹配性能。其中,互注意力机制着重学习具有匹配性的细粒度特征,而细粒度特征分割与对齐模块,用来处理图像空间上的变化。同时,改进三重损失函数使模型训练更加平滑,加快模型收敛。最后实验结果表明,FGMA方法的匹配精度高于目前先进算法,后续将进一步修改ViT的结构,以降低时间复杂度。
