基于姿态估计的动物行为识别研究进展
2023-05-11吴赛赛吴建寨程国栋邢丽玮韩书庆
吴赛赛 吴建寨 程国栋 张 楷 邢丽玮 韩书庆
(中国农业科学院 农业信息研究所/农业农村部区块链农业应用重点实验室,北京 100081)
动物行为学是研究动物如何通过行为与其环境之间实现动态平衡关系的一门学科,动物行为中蕴含着诸多健康信息,直接或间接地反映了其生理、病理以及营养等内在状态[1-2]。例如,走路时具有弓背、点头、步幅短等特征的牛只可能患有肢蹄病[3];将四肢缩于腹下而趴卧的猪只可能处于寒冷状态[4];跟随雌蝇并舔其尾部试图交尾的雄蝇表示可能处于求偶期[5]。因此,观察和有效识别动物行为对智能养殖和动物福利具有重要意义,有助于管理者根据动物的行为变化对疾病治疗、环境调整、喂养方案等做出及时反应和决策。在传统养殖中大多依赖人工观察来识别不同的动物行为,但由于工作效率低、人员培训成本高等原因逐渐被取代;而通过传感器来提取动物运动信息以实现动物行为分类的方式可能会造成动物的应激反应,还容易存在设备掉落导致数据丢失、电池寿命较短等问题。近年来,随着计算机视觉技术和深度学习的发展,基于视觉特征实现动物行为识别作为一种非接触式、自动化且经济高效的方式成为当前的主流方法[6]。
基于视觉特征的动物行为识别方法可分为基于整体图像特征和基于骨架特征的识别。基于整体图像特征的动物行为识别通过图像处理、视频分析等技术从图像中检测目标区域并提取区域的视觉特征,再基于传统机器学习或深度学习算法进行动物行为检测。基于传统机器学习的动物行为识别对图像数量要求不高,但人工分析在其中起主导作用;深度学习方法则利用数据驱动方式学习图像中的相关特征而无需人工提取特征,但对数据集规模要求较高,且由于从整张图像中提取到的目标区域和特征是比较粗粒度的,对于复杂行为和相似行为的识别较为困难。基于骨架特征的动物行为识别通过检测身体部位关键点和骨架,能够监测到更加细微的运动和行为变化,为行为分类算法的特征提取提供重要线索。动物行为可通过不同身体部位的运动姿态表现出来,姿态估计作为一种基于视频或图像观察物体骨架运动特征的非侵入性方法,利用深度学习算法检测人体或动物身体上的关键点位置,形成骨架特征并对其姿态进行可视化呈现[7],在人机交互、行为识别、运动捕捉和追踪、行人检测和重识别等任务中发挥着至关重要的作用[8-9]。因此,基于姿态估计的动物行为识别逐渐获得学者们的关注和认可。
目前,随着MPII[10]、COCO[11]、LSP[12]等大规模图像训练数据集的可用性,人体姿态估计研究取得重大进展;但动物姿态估计研究相对较少,主要是受到缺乏大规模可用标注数据和动物的非刚性运动导致姿态多变的限制。传统姿态估计方法一般基于图结构[13-14]的思想,将身体各部位之间的空间相关性表达为树状结构模型,具有耦合连接肢体的运动学先验[15-17]。但传统姿态估计方法的特征提取很大程度上依赖于人工设定的方向梯度直方图(Histogram of oriented,HOG)[18]和尺度不变特征转换(Scale invariant feature transform,SIFT)[19]特征,无法充分利用图像信息,导致算法受制于图像中的不同外观、视角、遮挡和固有的几何模糊性[20-21]。
近年来,计算机视觉和人体姿态估计领域的进步为动物姿态估计提供了方向和新工具,为深入分析姿态估计应用于动物行为识别任务的发展潜力,本文分别从二维和三维空间的角度详细论述基于深度学习动物姿态估计应用进展与发展方向,然后从姿态估计与行为识别相结合的角度出发,整合姿态估计在动物行为识别中的应用和相关研究成果,并结合研究和产业发展现状,讨论了当前研究中存在的问题并对未来的研究方向进行展望,为动物智能行为识别、动物福利等相关研究者扩展研究思路和研究方法。
1 基于深度学习的动物姿态估计方法
随着深度学习尤其是卷积神经网络(Convolutional neural networks,CNN)的发展和突破,即使不依赖于先验知识,也可以利用神经网络提取比人工特征更为准确和鲁棒的卷积特征,能够预测更加复杂的姿态,特别是当使用更深的卷积架构时。CNN不仅可以学习更好的特征表示,还能获取不同感受野下多尺度多类型的关节点特征和每个特征的全部上下文(Contextual),然后对这些特征向量回归身体部位坐标以反映当前姿态。随着CNN在人体姿态估计领域的成功应用,基于CNN及其不同变体实现动物姿态的自动检测也受到越来越多的关注。按照维度差异,本文从单目标和多目标的角度来梳理二维姿态估计方法,从两阶段和端到端方法来梳理三维姿态估计(图1)。

图1 基于深度学习的姿态估计方法Fig.1 Deep learning-based pose estimation method
1.1 二维姿态估计方法
二维姿态估计通过对图像的关键点标注和特征处理,首先检测人体或动物身体上的关节点,然后对这些关节点进行聚类和关系建模,形成身体骨架和可视化姿态。根据图像中的对象数量可以划分为单目标姿态估计和多目标姿态估计。
1.1.1单目标姿态估计
单目标人体姿态估计算法在训练网络参数时一般采用有监督的训练方法,根据真值(Ground truth)的类型和监督的方式不同,可以分为4种方法:基于坐标回归、基于热图检测、回归与检测的混合模型以及端到端方法[20-21]。
DeepPose[22]是卷积架构在单人人体姿态估计上的首次尝试,将姿态估计表述为基于深度神经网络(Deep neural networks,DNN)的身体关节直接坐标回归问题,但预测坐标是一种非线性很强的回归任务,对于卷积网络来说没有充分利用图像上的空间信息,因此难以估计复杂的人体姿态。基于热图(Heatmap)检测的模型能够保留图像中的更多信息,不仅构建基于概率分布的真值标签,还添加了一些人体部位之间的结构信息,主要包括将卷积网络和图结构模型[23]或树结构模型[24]联合的方法,以及通过增大感受野以隐式地学习人体结构信息,设计的典型卷积网络主要有卷积位姿机(Convolutional pose machines,CPM)[25]、堆叠沙漏网络(Stacked hourglass networks,SHN)[26]等。但卷积网络在池化过程中经常以降低定位精度为代价,因此回归+热图检测的混合模型开始出现,通过串联[22]或并联[27]结构将两者直接级联在一起,在检测与回归2个过程的共同作用下保证姿态的估计精度,但由于模型往往采用很大的卷积核或很深的网络去获取高质量热图,也导致效率难以提升。
单目标动物姿态估计更多的是应用端到端的神经网络进行目标检测和关键点估计。2018年,Mathis等[28]开发了开源工具包DeepLabCut,成为动物姿态估计领域的一个里程碑,同时也证明了端到端网络可以提高姿态估计性能。DeepLabCut基于人体姿态估计方法DeeperCut[29]的改进,同时利用迁移学习方法,即使只标注少量训练数据(约200帧),也取得与人体姿态估计准确率相当的性能。其2个关键成分是:在关键点估计中应用了在ImageNet数据集上预训练的ResNet-50[30]网络;将去卷积层取代了ResNet输出的分类层,用来对视觉信息进行上采样,并产生空间概率密度。此后,Pereira等[31]和Russello等[32]分别提出LEAP和TLEAP模型,相比于DeepLabCut更加轻量且推理速度更快,但它们为了提高训练速度而降低了准确性。因此,为缓解DeepLabCut网络参数多导致推理速度慢以及LEAP模型对数据变化鲁棒性差的问题,Graving等[33]推出的DeepPoseKit工具利用堆叠DenseNet通过对图像的各种空间变换和噪声变换以优化鲁棒性和泛化性,还大量减少网络参数以提高推理速度,同时还能应用于多目标姿态估计,DeepLabCut、LEAP以及DeepPoseKit算法的比较如图2所示。Liu等[34]还介绍了一种多帧动物姿态估计框架OptiFlex,由FlexibleBaseline和OpticalFlow(光流)2个模块组成,它不仅可以灵活适应各类动物数据集,OpticalFlow[35]还通过聚合附近帧的变形信息以提供有关目标帧关键点最可能位置的足够信息,当将其添加到DeepLabCut[28]、LEAP[31]和DeepPoseKit[33]这些基础模型时,性能都有一定程度的提升。

(a)DeepLabCut算法流程;(b)LEAP算法流程;(c)DeepPoseKit算法流程。(a) DeepLabCut algorithm flow;(b) LEAP algorithm flow;(c) DeepPoseKit algorithm flow.图2 DeepLabCut、LEAP和DeepPoseKit算法流程Fig.2 DeepLabCut,LEAP and DeepPoseKit algorithm flow
一些在2D人体姿态估计中流行的检测器也被应用到动物姿态估计中,如钟依健[36]和Li等[7]利用多个基础模型对牛只的关键点进行定位和检测,实验结果均显示SHN的性能最佳,16个关键点的平均检测精度达到90%以上。基于SHN在编码-解码过程中容易丢失网络浅层信息的问题,张雯雯等[37]在SHN基础上提出基于SE注意力机制的多尺度最大池化模块以解决特征信息丢失问题;同时引入一种基于Convolutional block attention module(CBAM)注意力机制的改进沙漏模块,提高网络对多通道信息的提取,该方法对于马的PCK@0.05精度为74.01%,对于老虎的精度为66.40%。在姿态估计这类任务中,需要生成一个高分辨率的heatmap来进行关键点检测,因此高分辨率网络(HRNet)[38]被应用于鸟类[39]、大熊猫[40]等动物的姿态估计中,还引入了空洞空间金字塔池化(Atrous spatial pyramid pooling,ASPP)模块,在提升特征感受野的同时捕获多尺度信息,其PCK@0.05精度为81.51%。针对当前算法通常在时间和空间维度上分别提取动物骨架特征而忽略了骨架拓扑结构在时空维度的整体性问题,孙峥等[41]在时空图卷积网络(Spatial temporal graph convolutional networks,ST-GCN)基础上插入全局时空编码网络,在猴类数据集研究中虽然比基准模型ST-GCN提升6.79%,但整体准确率仅达到76.54%。
同时,针对动物姿态估计领域训练数据匮乏的问题,学者们研究通过迁移学习的方式来进行缓解。Cao等[42]设计了一种跨域适应方案来学习人类和动物图像之间的共享特征空间;Zhang等[43]提出基于知识蒸馏的框架以提高各种基于CNN的目标检测器性能,其中以Faster-RCNN[44]作为教师模型进行训练,Single shot multibox detector(SSD)[45]作为学生模型;周兵[46]融合随机背景增强方法RBA、注意力模块MGAM、半监督学习方法SSTCL和孪生网络结构DNS,在标签训练数据量少的情况下也能明显提升姿态估计预测的准确率。
1.1.2多目标姿态估计
与单目标姿态估计相比,多目标姿态估计不仅容易存在个体之间的遮挡、截断等问题,还需要将检测到的所有关节点正确地关联到对应的个体身上,具有更高的挑战性。目前对于多目标姿态估计的研究思路分为自顶向下(Top-down)和自底向上(Bottom-up)2种方法。
自顶向下方法分为目标检测和姿态估计2个阶段,首先通过目标检测器将图片中的多个个体分别划分在不同的目标检测框中,然后对每个目标提议框进行单目标姿态估计。目标提议框的漏检、定位偏差与冗余等问题将直接导致后续姿态估计出现不完整、不准确或重复检测等情况,因此自顶向下方法侧重于检测器的研究。在多目标人体姿态估计中,经典的目标检测算法包括Region-CNN(R-CNN)[47-48]、Spatial pyramid pooling networks(SPP-net)[49-50]、Fast region-CNN(Fast R-CNN)[51-52]、Faster R-CNN[44,53]、Mask region-CNN(Mask R-CNN)[54]、SHN等模型,以及可以端到端输出类别和相应定位的YOLO系列[55-56]和SSD模型[45]。
Graving等[33]和张宏鸣等[57]都以一种特殊的自顶向下方法实现多动物姿态估计,其姿态估计模型流程图如图3所示,首先对单目标体框进行检测和裁剪,然后进行单目标姿态估计,最后再将单目标图像关键点映射至原图像所在位置,依序连接关键点形成多目标姿态。其中,DeepPoseKit利用堆叠的DenseNet检测动物关键点,张宏鸣等[58]则在YOLO v3的基础上添加RFB(Receptive field block)模块以扩大感受野进行目标检测,然后利用8层SHN实现单牛关键点检测,该方法在一定肉牛目标数量范围内缓解模型精度急剧降低的问题,其单牛骨架提取的平均精度达到90.75%,多牛骨架为66.05%,不过当目标数量从1提升至6时,模型精度波动幅度较小,当数量增至10头以上模型精度才出现大幅下降。宋怀波等[59]提出基于部分亲和场(Part affinity fields,PAF)的多目标奶牛骨架提取方法,但模型精度较低,其中单目标检测精度为78.9%,3个及以上目标仅为48.59%。

图3 姿态估计模型流程图[33,57]Fig.3 Flowchart of the pose estimation model of literature[33,57]
虽然自顶向下方法能够输出较高的精度,但由于关键点估计过程建立在目标检测结果的基础上,目标检测的错误会传播到关键点检测任务中,而且当图像中目标较多时,其效率会受到较大影响。
自底向上方法的过程与自顶向下相反,主要包括节点部件检测和节点部件聚类两个步骤,首先利用单目标姿态估计方法检测出图像中所有目标的关节点,然后对这些关节点进行聚类和拼接,匹配到正确的目标身体上,因此自底向上方法侧重于关节点的聚类研究,经典算法设计包括整数线性规划[29,60]、部分亲和场[61]、语义部分分割等[62]。Lauer等[63]运用自底向上的方法实现老鼠、小狗、狨猴和鱼的多目标姿态估计和跟踪,对DeepLabCut的主干网络ResNet进行调整,引入更强大的DLCRNet_ms5提取特征,多个并行反卷积层预测关键点,然后利用部分亲和场对关键点进行连接和关联个体。由于DeepLabCut假设一帧只有一个对象且适合干净背景的实验环境,Liu等[64]则在DeepLabCut基础上增加一个CNN层,以帧差图像为输入以减少颜色变化的影响,克服低视频质量和重遮挡问题。然后在后处理模块中利用非最大限制方法识别候选身体部位,并基于关键点约束函数和空间聚类来估计相应的奶牛中心位置,中心点数量则代表图像中的奶牛数量,但该方法检测效果不佳,尤其是在多头牛的图像数据集上,交并比(IOU)仅为58.7%。Pereira等[65]提出的Social LEAP(SLEAP)框架是LEAP的继承,同时实现了自顶向下和自底向上的多目标姿态估计和跟踪,以模块化的U-net[66]作为网络架构,支持30多种先进的神经网络主干。
1.2 三维姿态估计
二维姿态估计可以获取目标在图像平面的位置和形态,是目标在图像平面的投影。虽然从2D视频跟踪动物运动对于监控特定身体部位很有用,但全身姿态估计以及复杂或微妙行为的测量需要在3个维度上进行跟踪,因为重要信息可能会由于多动物间的遮挡而丢失,并且运动量化也受到视角的严重影响。三维姿态估计可以在三维空间对目标的三维结构进行重建,但由于需要预测身体关节的深度信息,其训练数据更加难以获取,因此目前大多应用于实验室环境的单目标姿态估计,对于自然环境和多目标估计还难以适用。
目前三维姿态估计主流方法包括两阶段方法和端到端方法。两阶段方法是以二维姿态估计发展较为成熟为前提的,因为其需要先从图像中获取二维姿态,然后将二维姿态作为输入,进一步估计三维姿态;该方法的重点是第二阶段,即如何将二维姿态信息提升为三维姿态信息[67-71]。端到端的三维姿态估计方法以二维图像作为输入,直接使用卷积神经网络进行回归,输出三维姿态[72-75]。大多数三维姿态估计方法都应用了2D到3D的提升策略,如OpenPose[61]、DeeperCut[29]、HRNet[38]等已广泛作为3D姿态估计方法中的2D姿态检测器。
在三维动物姿态估计中,为了获得三维空间信息,目前大多研究利用不少于2台相机来融合多视角信息,基于多目图像重建3D姿态,如表1所示。从多目图像进行3D重建的过程中,关键在于如何确定场景中同一个点在不同视角下的位置关系,一般采用相机校准板、引入多视角的一致性约束以及借助于立体视觉中的triangulation方法进行3D重建。DeepFly3D[76]工具包为了克服相机校准板在果蝇这种小体型动物上的不适用性,使用类似于人体姿态估计的稀疏束调整[77]校准模式,并将SHN作为关键点检测器进行2D姿态估计,然后通过7台同步相机及其多视图冗余,在进行triangulation的3D关节位置重建时,利用图形结构[13]迭代投影3D姿态以自动检测和纠正2D错误估计。Freipose则不是以triangulation方法对3D姿态重建,而是直接在3D中重建身体姿态和运动轨迹,利用新颖的 3D 卷积网络架构通过整合所有可用视图的信息来重建 3D姿态,还允许对老鼠行为进行自动聚类[78]。
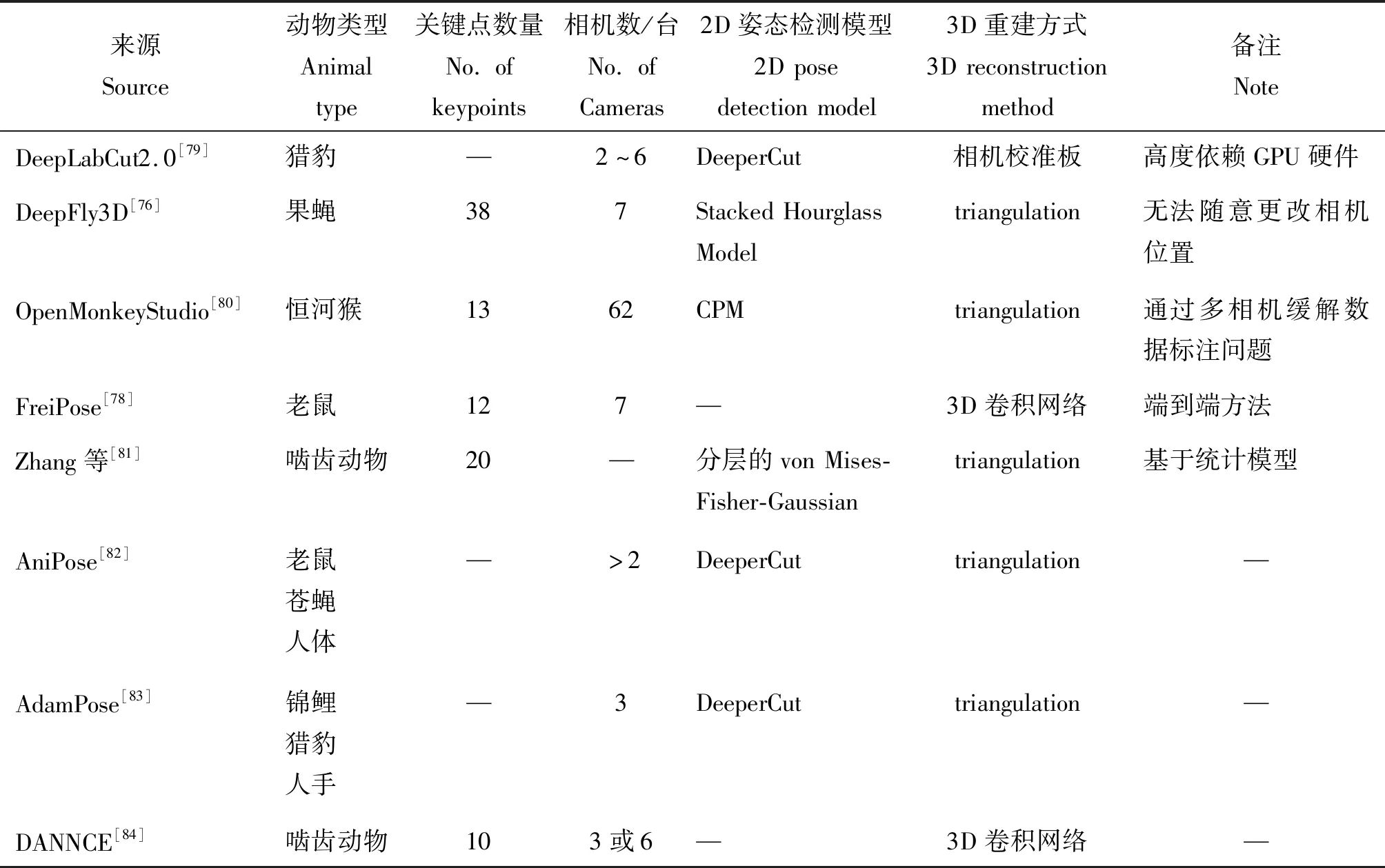
表1 三维动物姿态估计相关研究Table 1 Research related to 3D animal pose estimation
1.3 常见数据集
动物种类繁多,目前还不存在一个规模较大、覆盖丰富的动物种类的数据集基准,来验证姿态估计算法的性能和泛化能力。为不同种类的动物标注骨架和姿势不仅需要大量的人力物力,还需要生物学相关的领域知识作为标注依据。各类物种之间的外貌和骨骼具有较大的差异性,使得标注过程也存在一定的困难和误差。因此,目前在动物姿态估计领域常见的数据集大多是以研究某一特定物种为目的,通常仅包含某一类动物(如肉鸡)或几类相似物种(如猫狗马牛羊),且所定义的关键点位置和数量均有不同,如表2所示。AP-10K[85]是当前包含动物种类最丰富的姿态估计数据集,以9个公开发布的动物数据集作为基础,经过仔细清洗、鉴别、再组织和标注,构建了一个包含59 658张图像的动物数据集,涵盖了23科,54个物种的集合。AP-10K类比人体关键点,基于动物的骨骼位置和运动特点角度的权衡,最大程度上描述了这些动物的外形和运动特点,定义了17个关键点来描述不同种类的哺乳动物。NWAFU数据集包含2 134张奶牛和肉牛各种姿势的图像,定义了16个关键点,并手动标注了每张图像的相应注释,成为目前牛只姿态估计的数据集基准,具体的关键点位置和定义如表3和图4所示。

表2 动物姿态估计常见数据集Table 2 Common datasets for animal posture estimation
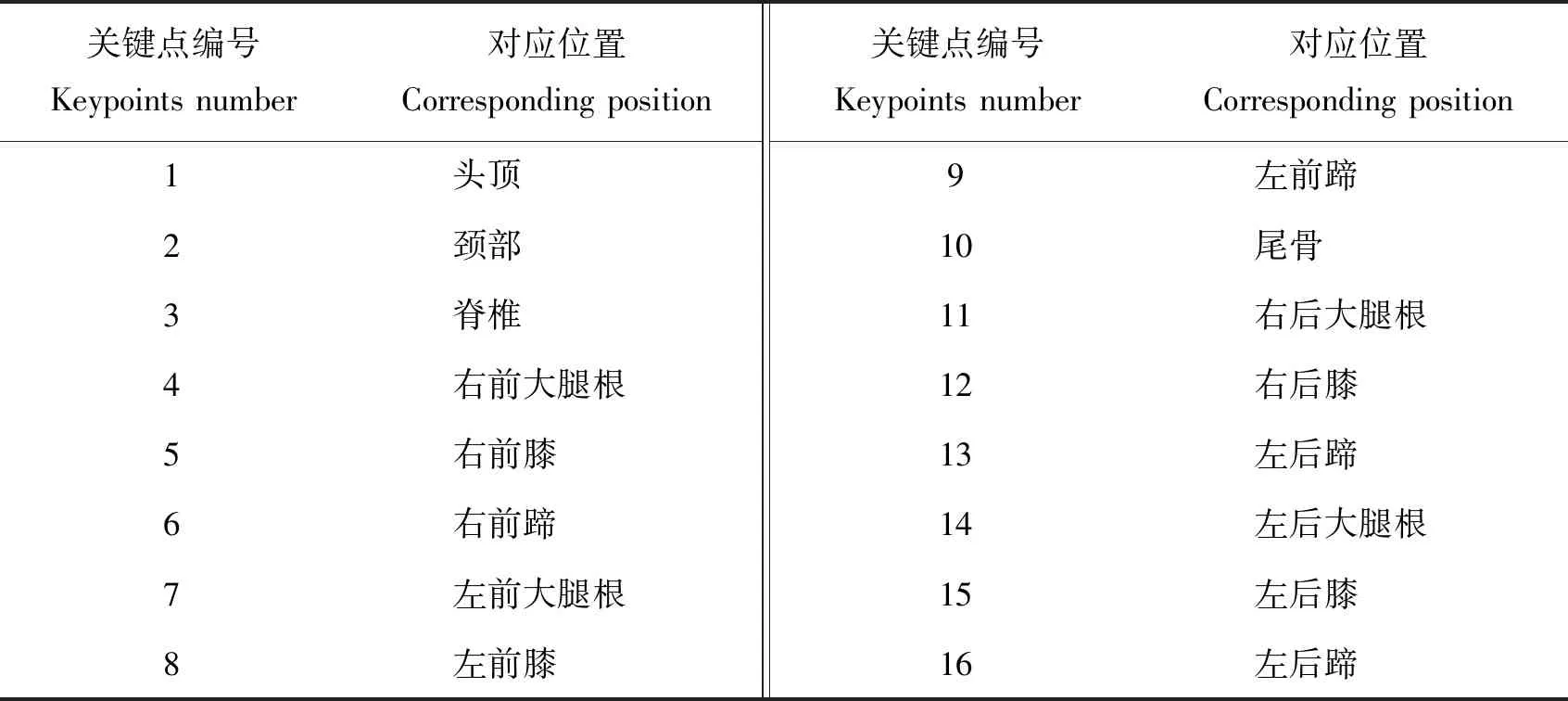
表3 NWAFU数据集的关键点定义Table 3 Definition of keypoints of the NWAFU dataset

图4 NWAFU数据集关键点标注示例Fig.4 Example of key points annotation for NWAFU dataset
1.4 评价指标
目前,在姿态估计领域较常用的评价指标包括正确关键点百分比(Percentage of correct keypoints,PCK)、物体关键点相似性(Object keypoint similarity,OKS)、全类平均精度(Mean average precision,mAP)以及均方根误差(RMSE)。
PCK定义正确估计出关键点的比例,计算检测的关键点与其对应Ground truth之间的归一化距离小于设定阈值的比例,如PCK@0.05则表示在阈值为0.05时的正确关键点百分比。其计算公式如下:
(1)
式中:i表示关键点,di表示关键点i的预测值与Ground truth之间的欧式距离,d表示动物的尺度因子,T为人工设定的阈值。
OKS是COCO姿态估计挑战赛中提出的评估指标,旨在计算预测关键点与Ground truth的相似度。其计算公式如下:
(2)
式中:δ表示关键点的可见程度,0表示不可见,1表示可见,S表示图像像素面积,di表示关键点i的预测值与Ground truth之间的欧式距离,σi为关键点i的归一化因子。
在计算出测试集中所有图像的OKS后,通过人工设定阈值,得到出平均精度(Average precision,AP),对设定的多个阈值所得到的多个AP进行综合加权平均,即为mAP。
RMSE为均方根误差,表示预测关键点与Ground truth之间的平均像素距离的平方根。计算公式如下:
(3)
式中:m为关键点数量,xi表示关键点i的预测值,yi为关键点i的Ground truth。
2 姿态估计在动物行为识别中的应用进展
姿态估计通过关键点检测的方式获取了动物的骨架信息和动作姿态,通过观察关键点的位置和活动角度、频率等特征,能监测到更加细微的运动和行为变化,同时也能为行为分类模型提供精确的目标特征区域,提高行为识别的准确性。基于姿态估计的动物行为识别相关研究如表4所示。
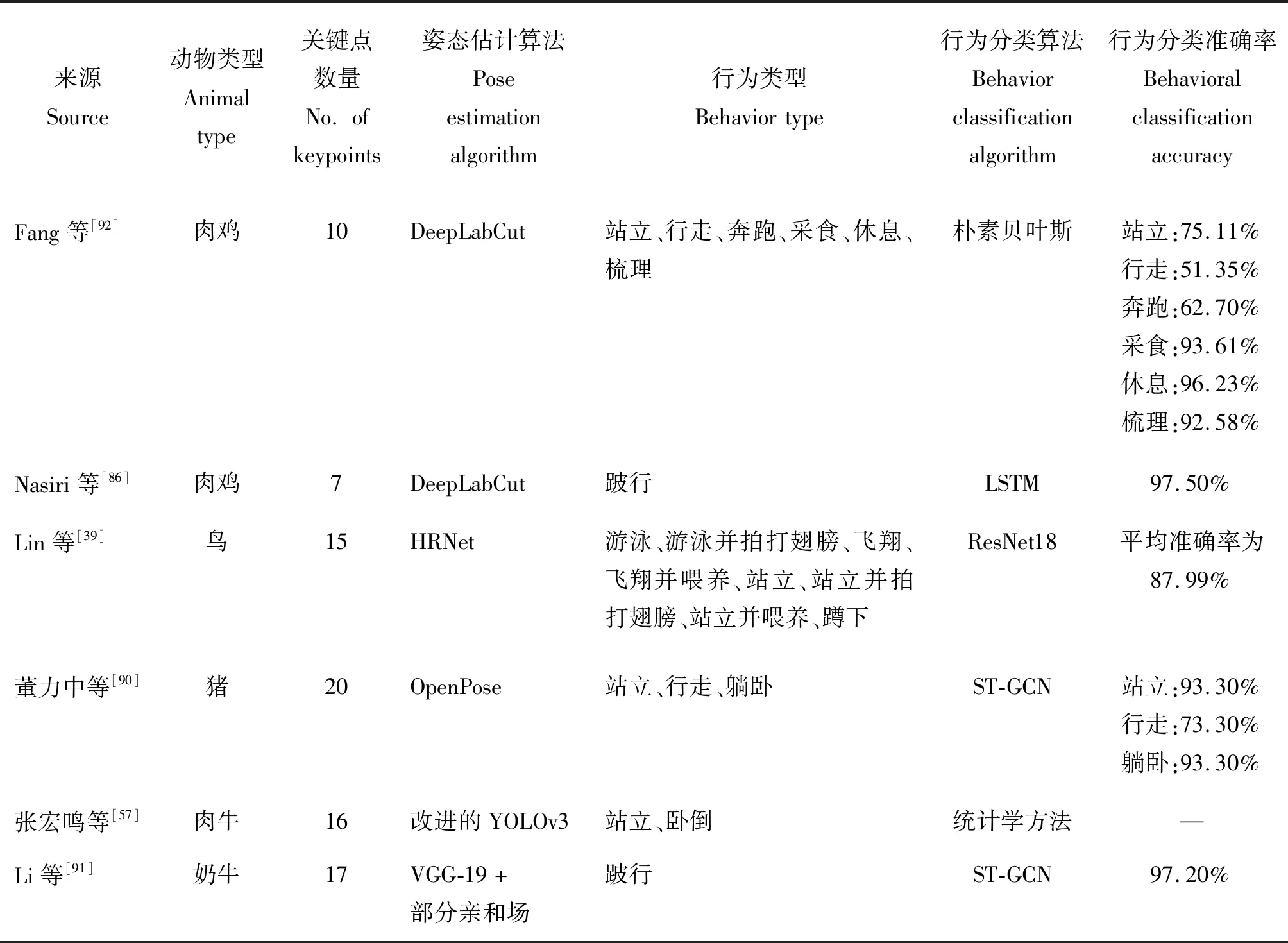
表4 基于姿态估计的动物行为识别相关研究Table 4 Research related to animal behavior recognition based on pose estimation
目前姿态估计主要应用于禽类和牲畜的行为识别中,对精准养殖和智能跟踪的效率有了很大提升。在禽类行为识别方面,Fang等[92]和Nasiri等[86]都将DeepLabCut作为关键点检测器进行肉鸡的姿态估计,在此基础上,Fang等[92]将关键点位置、凹陷、关键点形成的骨架、形状特征、骨架角度以及伸长率作为行为分类的6个特征,并使用对缺失数据不敏感的朴素贝叶斯法(Naive bayes model,NBM)进行6种日常行为的分类任务,其中休息行为的分类精度最高,达到96.23%,而行走和奔跑的精度较低,均小于70%,主要原因是行走和奔跑行为在图像中呈现的运动幅度较为相似,导致模型出现互相交叉误判的情况;Nasiri等[86]则将连续提取到的关键点输入到LSTM模型中,根据GS0-GS5的6点评估方法对肉鸡的跛行程度进行分类,其中GS0表示正常行走的肉鸡,GS5表示跛行情况非常严重、完全无法动弹的肉鸡,跛行程度的平均准确率高达97.50%,证明了基于姿态估计的模型作为一种自动和非侵入性的跛行评估工具,可以应用于家禽养殖场的有效管理。HRNet通过并行连接高分辨率到低分辨率卷积来保持高分辨率表征,在像素级分类、区域级分类和图像级分类中,都证实了这个方法的有效性。因此,Lin等[39]首先使用 HRNet作为骨干网络估计鸟类的关键点并生成用于鸟类行为识别的全局和粗略特征,然后将关键点聚类以定位兴奋区域,并使用卷积操作较少的浅层网络ResNet生成局部特征,融合全局和局部特征实现行为识别,即使存在多种相似行为,但其行为识别的平均准确率达到87.99%。
在牲畜行为识别方面,董力中等[90]和Li等[91]结合了自底向上策略和PAF方法来实现多目标姿态估计;且由于骨架关键点的结构实质上是一种图结构,两者均通过ST-GCN来抽取图像特征,不仅可以从每一帧中的关节点坐标表示的牲畜姿态中学习到动作的特征,还能够根据同一个关节点在连续帧中的位置变化形成的轨迹学习每个关节点对于动作识别的贡献,从而同时把握到骨架的自然连接关系与时序性的特征,2种方法的对比如图5所示。董力中等[90]研究了基于轻量化OpenPose的姿态估计和基于ST-GCN的猪只行为识别方法,首先通过目标检测算法YOLO v5和多目标跟踪算法(Simple online and realtime tracking,SORT)[93]提取并保留猪只目标区域,然后采用自底向上策略的VGG-19算法和部分亲和场(PAF)来检测猪只的20个关键点并衡量肢体骨架关节点之间的相关度,再执行一组二分匹配来关联候选部位,解析出合理的目标骨架。将提取到的猪只骨骼关节点在时间和空间上的特征输入到ST-GCN网络中,然后逐层对骨架时空图进行卷积操作,提取图结构中的更高级特征图,最后通过标准的Softmax分类器输出站立、行走或躺卧的相应猪只行为类别。由于单一特征难以取得很好的效果,Li等[91]融合RGB、光流和骨架多特征进行奶牛跛行检测,首先利用ResNet101深度残差网络提取RGB图像和光流的特征;然后利用VGG-19和部分亲和场提取行走中的奶牛骨骼关节点特征,将这些特征的时空特征输入到ST-GCN网络中,由于跛行奶牛的行走速度比非跛行慢2~3倍,相邻帧的运动差异不大,因此ST-GCN通过增加时间卷积核的大小,适当增加时间跨度以找到时间维度上高度可区分的特征。最后,将通过归一化的RGB、光流和骨骼特征合并到Softmax分类器中进行跛行分类。由于RGB图像和光流对光照敏感,容易受到环境干扰,因此添加奶牛骨架信息来加强网络对牛本身的关注,增加了前景信息的权重。当RGB、光流和骨架特征的权重比例为1∶0.5∶0.5时,最佳准确率为97.20%。而在多目标肉牛姿态估计和行为识别中,张宏鸣等[57]提出的方法在一定目标数量范围内缓解模型精度急剧降低的问题,在YOLO v3的基础上引入RFB扩大模型感受野,剔除分类模块提高目标检测效率;由于肉牛毛色复杂、四肢高度相似、养殖环境多变、遮挡严重等问题,使用对细节特征感知能力较差的8层SHN来预测16个肉牛关键点以提取骨架和姿态信息。然后通过对关键点分布信息的统计,得到肉牛处于站立和卧倒状态下其识别角度的特征,以135°的识别角度分界线作为站立或卧倒行为的判断基础,证明了该骨架提取模型可以为肉牛行为识别提供技术支持。

图5 文献[90]和[91]的方法对比Fig.5 Comparison of the methods in the literature [90] and [91]
虽然动物的关键点容易受到视角、姿态、遮挡等情况的影响,但比起其他种类的特征信息,动物的关键点及骨架信息对于环境变化具有更高的稳定性,可以提供更有效的运动特征。目前基于姿态估计的动物行为识别研究大多首先采用深度神经网络进行动物关键点和骨架提取,然后再利用统计学或深度学习算法实现行为分类,取得不错的试验结果,但相关研究仍较少。
3 总结与展望
动物的行为中蕴含着许多健康信息,加强对动物行为的研究与分析,可以为其疾病预测、动物福利研究提供思路和解决途径。基于关键点检测的姿态估计作为动作识别、行为分析的前置任务,在人机交互、人体行为识别、行人检测和重识别等领域得到广泛而成熟的应用,但在动物行为识别等农业领域的应用场景还比较受限,相关研究尚不充分。基于姿态估计的动物行为识别不仅可以实现动物异常信息预警、身份识别和跟踪,还能根据行为变化及时发现动物福利需求并做出相应调整。目前动物姿态估计大多借鉴于人体姿态估计方法,还有如下问题值得继续研究。
1)构建大规模动物姿态估计数据集。深度学习模型的性能很大程度上依赖于大量的训练数据集,人体姿态估计的成熟发展也是得益于存在多个大规模标注数据集。而动物种类繁多且物种之间的外貌和骨骼具有较大差异,目前还不存在一个规模较大、覆盖全面的动物关键点数据集基准,这也是动物姿态估计领域研究进展缓慢的直接原因。因此,构建大规模动物姿态估计数据集是当前亟待解决的重要问题。
2)研究迁移学习策略以增强泛化能力。鉴于人体姿态估计的大量数据集及其成熟的方法,可以利用跨域学习的方式来提高动物姿态估计的性能。具有先验知识的迁移学习是减轻标注数据需求的有效途径,在关键点检测或行为分类任务中,不论是从人类领域到动物领域的数据或算法迁移,还是不同动物种族间的算法迁移方式,都能有效提升目标域的泛化能力,减轻标注数据量的壁垒。
3)训练强大的多目标姿态估计网络。多目标姿态估计具有更广泛的应用场景,但目前该算法不仅很难解决遮挡问题的鲁棒性,还存在精度随着目标增多而降低的问题。在未来的研究中,可以通过扩大模型感受野以增强特征提取能力,提高遮挡部分的检测精度。同时,自顶向下的多目标姿态估计方法首先检测目标框再进行关键点估计,在一定程度上能缓解目标较多时的精度问题,但这种方式的效率较低。因此,未来可以通过自顶向下和自底向上相结合的方式,在提高精度的同时保证检测效率。
