基于YOLOX 的作物种子自动计数方法
2023-05-10逄正钧温钊发张世豪秦立浩
逄正钧,董 峦,温钊发,张世豪,秦立浩
(新疆农业大学计算机与信息工程学院,新疆 乌鲁木齐 830052)
0 引言
种子是农业最基本的生产资料,农业收成在很大程度上取决于种子质量。千粒质量是检验种子质量的一个重要指标,是1 000 粒种子的质量,体现种子大小与饱满程度,一般测定小粒种子千粒质量时是随机数出3 组1 000 粒种子,分别称质量,求其平均值,其中最关键和最烦琐的任务是精确计算出种子数目[1]。
目前,在农作物种子计数中主要采用人工、光电式、压电式和机器视觉4 种方法。人工计数效率低;光电式、压电式两种计数方法都存在成本高、精度较低、时间长的缺点;基于机器视觉的种子计数方法计数速度快、精确度高,但是需要搭建一个符合要求的计数环境,对输入的图像质量要求高且图像预处理工作量大,模型泛化能力弱[2-4]。提出一种基于目标检测技术并可部署在移动端的种子计数方法,解决人工计数慢、计数仪器设备成本高且不易携带等问题,降低人力、设备成本,大幅提高计数效率。
作物种子计数可视作一种密集的小目标检测任务,国内外研究者尝试使用深度学习方法解决类似研究问题。LIN Zhe 等[5]通过无人机采集的棉株图像,采用MobileNet 和CenterNet 两种深度学习模型,对棉花苗期植株进行检测和计数,结果显示,CenterNet 模型的F1分数为87%,对棉花植株检测计数具有较好的综合性能[6-7]。有学者使用YOLO 检测大型果园中苹果的确切数量,结果显示,模型具有更高的实时性,即使苹果目标在一定程度上重叠也能有效地计数,在真实图像中平均检测准确率为91%[8-9]。还有学者以无人机航拍的云杉可见光图像为研究对象,构建了YOLOv3 云杉计数模型,结果显示,该模型平均计数准确率为90.24%,优于全卷积神经网络分割加Hough 圆检测方法[10-11]。王超等[12]为实现成捆钢筋端面的准确计数,在YOLOv5 模型框架的基础上增加了空间金字塔池(spatial pyramid pooling,SPP)和小目标检测层,使用特征金字塔(feature pyramid network,FPN)和路径聚合网络(path aggregation network,PAN)对多尺度特征图融合以降低密集小目标漏检率、误检率,改进后的模型平均精度均值(mean average precision,mAP)达到了99.9%。研究以6 种常见作物种子构建数据集,在YOLOX 的基础上提出YOLOX-P 模型,使其适配密集小目标检测任务[13]。
1 数据集
1.1 数据集构建
选取6 种常见作物种子作为研究对象,分别为小麦、西瓜籽、玉米、红豆、花生和葵花籽。使用手机在白色背景下拍摄3 024 像素×3 024 像素的种子可见光图像,拍摄高度为30~50 cm,采集作物种子图像共432 张。为保证模型训练效果,进行数据集的扩充,利用左右翻转、中心翻转、亮度改变3 种方式进行数据增强操作。由此数据集中共有图像1 728 张,其中小麦100 张、西瓜籽424 张、玉米436 张、红豆168 张、花生200 张和葵花籽400 张。使用LabelImg 软件进行数据标注,按照PASCAL VOC 格式构建数据集,并按8∶1∶1 的比例将数据集划分为训练集、验证集和测试集,数据集部分图像如图1 所示。

图1 数据集部分种子图像Fig.1 Crop seed image samples
1.2 数据集分析
数据集共标注西瓜籽框8 480 个、红豆框9 784 个、葵花籽框8 232 个、玉米框44 736 个、花生框6 888 个和小麦框9 192 个。由图2 可知,每粒种子的边界框平均占单幅图像总像素数的0.005%~0.066%,数据集中的种子属于较难识别的小目标。
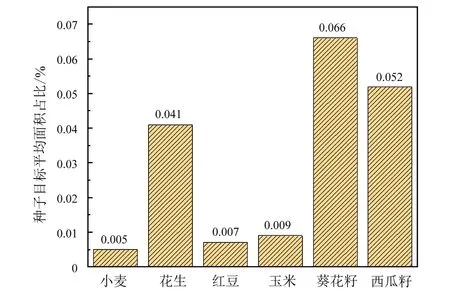
图2 种子标注框面积占图像面积的平均比值Fig.2 Average ratio of single seed bounding box to whole image
2 模型
对种子进行检测计数时目标具有尺寸小、稠密、粘连和堆叠的问题,并且不同类别种子的尺寸大小不一,最大种子面积是最小种子面积的15 倍,导致快速准确地统计种子数量较为困难。基于深度学习的目标检测算法YOLOX 在设计中引入特征金字塔模块,进而能够利用底层细粒度特征,克服了高层次特征语义丰富但分辨率低的问题,从而能够对图像中的小种子进行准确检测。基于YOLOX 的这个特点选取其作为种子计数模型,在对YOLOX 进行初步试验后,发现其在检测小麦等颗粒较小的种子时精确度较低,为此从注意力机制和损失函数两方面进行改进,提出了YOLOX-P 模型。
2.1 YOLOX 目标检测模型
YOLOX 是旷视科技在2021 年提出的高性能检测器,其研究者将解耦头、数据增强、无锚点及标签分类等目标检测领域的优秀进展与YOLO 进行了巧妙地集成组合,不仅实现了超越YOLOv3、YOLOv4 和YOLOv5的平均精度 average precision(AP),而且取得了极具竞争力的推理速度[14]。
YOLOX 使用YOLOv5 提出的Focus 通道增广技术,其在一张图片中每隔一个像素拿到一个值,获得4 个独立的特征层,将4 个独立的特征层进行堆叠,此时宽高信息就集中到了通道信息,输入通道扩充了4 倍,拼接起来的特征层相对于原先的3 个通道变成了12 个通道,如图3 所示。此技术提高了每个点感受野并减少原始信息的丢失,减少网络计算量,加快了运行速度。以YOLOv4 提出的CSPDarkNet 作为特征提取网络并加入SPP 结构,该结构分别由5×5、9×9、13×13 的最大池化层组成,融合不同尺度特征图的信息完成特征融合,丰富最终特征图的表达能力[15]。在构建特征金字塔时使用PANet 模块对获得的有效特征层进行加强特征提取来结合不同尺度的特征信息,该模块实现了自顶向下和自底向上的双向融合,解决了传统FPN中底层特征无法影响高层特征的问题,提高了网络的表征能力[16]。与之前YOLO 版本的解耦头(YOLO Head)不同,以前所用的YOLO Head 分类和回归在一个1×1 卷积里实现,YOLOX 认为这给网络的识别带来了不利影响。在YOLOX 中,YOLO Head 分别实现分类和回归,最后预测的时候才整合在一起。
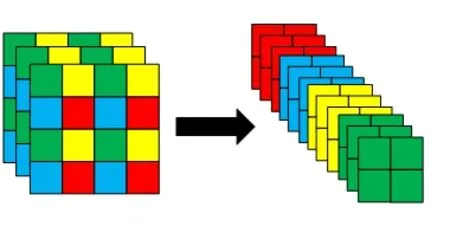
图3 Focus 模块Fig.3 Focus module
2.2 YOLOX-P 模型
2.2.1 注意力模块CBAM
深度学习中注意力机制的核心目标是从众多信息中选择出对当前任务目标更关键的信息,让神经网络在执行预测任务时可以更多关注输入中的相关部分。CBAM 注意力模块(Convolutional block attention module)是WOO S 等[17]提出的一种轻量注意力模块,采用两个独立的注意力机制,在通道和空间维度上分别进行注意力操作,在通道注意力模块(CAM)后,接入空间注意力模块(SAM),实现了通道注意力和空间注意力的双机制,最后将注意力机制得到的权重乘以输入特征图以进行自适应特征细化。其中CAM 具体实现过程如图4 所示,首先将输入的特征图分别进行最大池化操作和平均池化操作得到两个维度为[C,1,1](C为通道数量)的权重向量,通过共享的全连接层MLP 网络映射成每个通道的权重,相加后经过Sigmoid 非线性运算输出得到的通道权重与原特征图按通道相乘实现通道注意力的提取。SAM 具体实现过程如图5 所示,首先特征图按照通道分别进行最大池化操作和平均池化操作,形成两个维度为[1,H,W](H、W分别为图像的高和宽,下同)的权重向量,即对同一特征点的所有通道池化。将得到的两张特征图进行堆叠,形成[2,H,W]的特征图空间权重,经过一层卷积层得到一个[1,H,W]的权重向量,其表示图上每个点的重要程度,最后经过Sigmoid 非线性运算与原特征图相乘,实现空间注意力的提取,让网络自适应关注需要关注的地方。
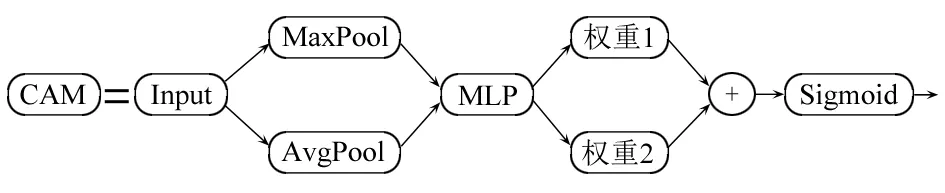
图4 通道注意力模块Fig.4 Channel attention module

图5 空间注意力模块Fig.5 Spatial attention module
受此启发,针对小麦种子因遮挡、粘连严重导致特征信息不明显的问题,提出将CBAM 模块搭建于YOLOX 算法的主干网络CSPDarkNet 后,在主干网络的第2 个、第3 个、第4 个特征层后分别添加一个CBAM 模块来更多地关注遮挡、粘连严重的小麦种子,得到改进后的模型YOLOX-P,CBAM 模块及模型整体结构如图6 所示。
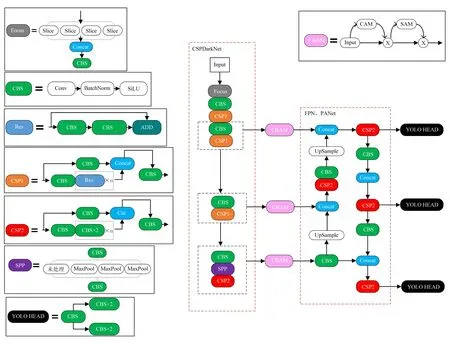
图6 YOLOX-PFig.6 YOLOX-P
2.2.2 损失函数
YOLOX 的损失函数由3 个部分组成,包括回归框损失、置信度损失和分类损失,其中回归框损失为计算真实框和预测框之间交并比的损失。YOLOX 提供了两种计算交并比损失的方法,分别是IOU 损失和GIOU损失(generalized IOU loss)。IOU 损失定义非常简单,即1 与预测框A和真实框B交并比之间的差值,如式(1)所示,但其只在真实框与预测框重叠时才有效,在没有重叠情况下,将不会提供滑动梯度。GIOU 为解决此问题,在IOU 损失的基础上新增了一个惩罚项,如式(2)所示,以解决检测框非重叠造成的梯度消失问题。式中A是预测框,B是真实框,C是预测框和真实框的最小包围矩形框。但是GIOU 存在一个问题,如果预测框完全包着真实框,则GIOU 损失就和IOU损失一样,无法精确确定锚框位置,造成精度上的损失。ZHENG Z 等[18]提出了利用CIOU 损失来解决此问题,其增加了两个惩罚项,分别是中心点距离和长宽比。CIOU 如式(3)所示,其中A和B分别表示预测框和真实框的中心点坐标,ρ(a,b)表示两点间的欧氏距离,c为预测框和真实框最小包围框的对角线长度。长宽比惩罚项如式(4)所示,α是一个正数,ν用来测量长宽比的一致性,其中wgt和hgt分别为真实框的宽和高,w和h分别为预测框的宽和高,这个惩罚项作用是控制预测框的宽高能够尽可能快速地与真实框的宽高接近。基于此,将原始模型中回归框损失中的IOU 损失替换为CIOU 损失,以提高模型训练时损失的收敛速度和精确度。
2.3 模型评价指标
采用目标检测算法最基本和常用的评价指标,使用精确度(Precision)、召回率(Recall)、mAP(mean Average Precision)来衡量目标检测的准确度。True positives(TP)表示被正确地划分为正例的个数;False positives(FP)表示被错误地划分为正例的个数;False negatives(FN)表示被错误地划分为负例的个数。其中,召回率表示被正确识别出来的目标与测试集中目标个数的比值,精确度则表示检测出来的目标中正确目标的个数;用mAP值衡量平均检测准确率,mAP越趋近于1,则表明检测的准确率越高。因千粒质量对于种子计数精确度要求高,在计算以上指标时设定IOU 阈值为0.6。
精确度计算公式为

3 试验结果与分析
3.1 模型训练
训练环境为Python3.7,CUDA11.0;所有模型的训练均在显存为16 GB 的NVIDIA Tesla P100 显卡上进行,所有模型的检测均在显存为6 GB 的NVIDIA GeForce RTX 2060 显卡上进行。
所有模型的训练参数均统一设置,训练时输入图像大小为640 像素×640 像素,采用随机初始化训练和预训练的方法,两种训练方法Epoch 都设为100,批处理量设置为20,其中预训练分为冻结训练和解冻训练两个阶段。根据经验设置两阶段的初始学习率分别为0.001 和0.000 1,其中冻结训练的Epoch 为20、解冻训练的Epoch 为80,使用余弦退火学习率方法,权值更新权重设置为0.000 5,并在训练时使用了随机缩放方法进行数据增强,两种方法的训练损失如图7 所示(以YOLOX-P 为例),预训练相比随机初始化训练能更快地达到收敛且loss 值能降到更低。

图7 不同训练方法效果Fig.7 Effect of different training methods
3.2 试验结果
在构建的数据集上对YOLOX 模型和YOLOX-P 模型进行训练和测试,当IOU 阈值设定为0.6 时,YOLOX模型在测试集上的mAP值为98.64%,6 类种子的检测精确度Precision和AP值如表1 所示,结果表明该模型对于小麦种子计数的精度较低。
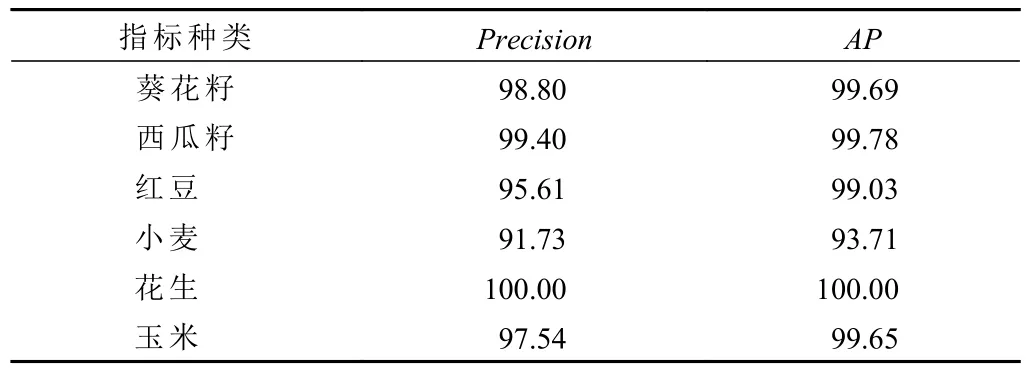
表1 YOLOX 检测6 类种子的指标数据Tab.1 Indicator data for YOLOX detection of six types of seeds单位:%
当IOU 阈值为0.6 时,YOLOX-P 模型在测试集上mAP值达到99.38%,以各类种子的AP、mAP、模型参数和推理时间作为评价指标对两种模型进行定量比较,结果如表2 所示。结果表明,YOLOX-P 在mAP与小麦种子的AP指标上分别比原始模型提升了0.74 和4.17 个百分点,而模型参数量仅比原始模型增加了0.09 M,推理时间仅增加2.09 ms。

表2 YOLOX 与YOLOX-P 对比数据Tab.2 YOLOX versus YOLOX-P data
为进一步验证YOLOX-P 模型性能的提升是得益于CBAM 注意力机制还是损失函数的改进,采用消融试验进行检验,结果如表3 所示。添加注意力机制或者改进损失函数对于原始模型的性能均有提升,当既添加CBAM 注意力机制又改进损失函数时,模型对于种子检测能达到最好性能。

表3 消融试验各个指标数据Tab.3 Indicator data for ablation study
综上所述,YOLOX-P 模型可有效解决种子粘连、重叠和不同类别的种子尺寸大小差异性大的问题,实现种子的精确计数。在硬件为显存6 GB 的NVIDIA GeForce RTX 2060 显卡条件下,YOLOX-P 模型对测试集图像的检测速度平均为124 ms/张,计数速度完全满足实时性要求。
3.3 种子检测效果和对比
在进行种子计数时,每一张图像中预测的边界框数量即为种子数量,具体示例如图8 所示。由图8a 可知,对于正常光照下的种子图像,YOLOX-P 模型可以准确识别种子并计数。由图8b 可知,对于光线较暗的种子图像,YOLOX-P 模型也可以很好地完成识别和计数。

图8 YOLOX-P 模型计数效果示例Fig.8 YOLOX-P model test results
为验证改进后的YOLOX-P 对小麦种子检测的精确度优于YOLOX,将二者进行比较,具体比较示例如图9 所示,其中圆圈部分为两个模型之间检测的差别。由图9 可知,原始模型未能很好地检测出堆叠、粘连严重的小麦种子,改进后的模型能检测出原始模型无法检测的困难目标。
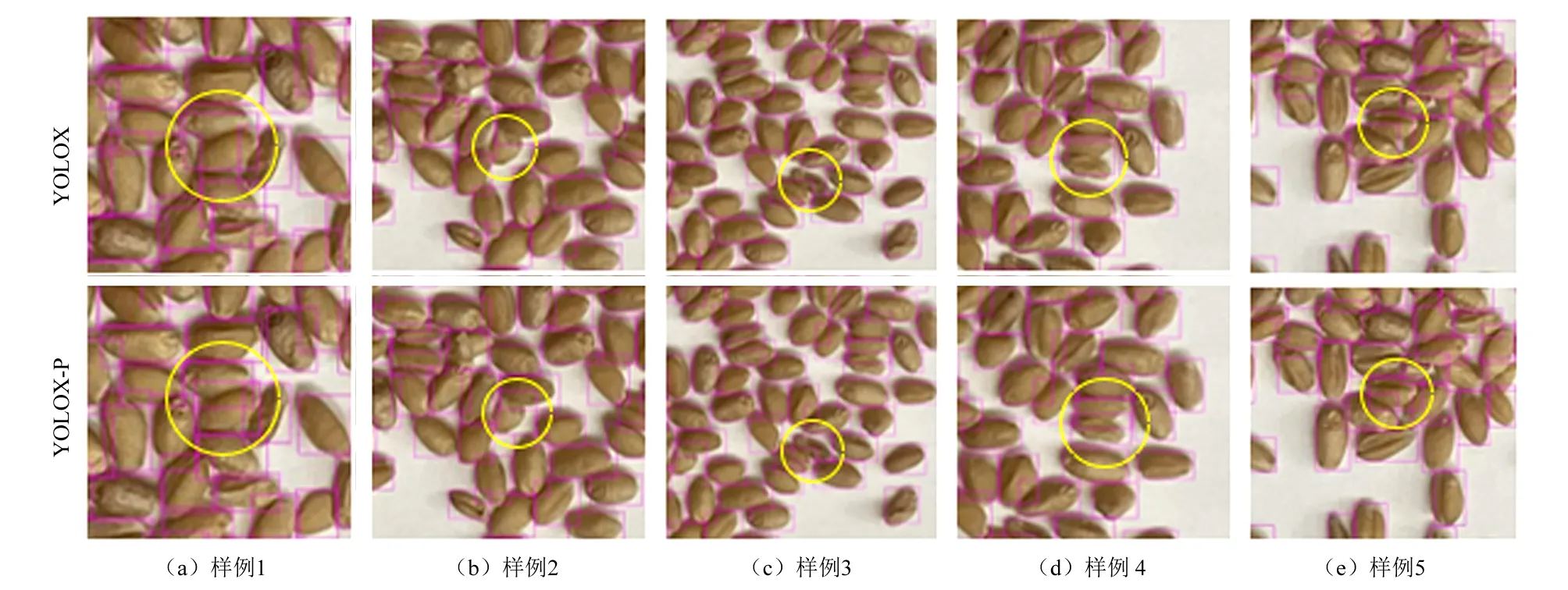
图9 YOLOX 与YOLOX-P 检测对比样例Fig.9 Sample comparison of YOLOX and YOLOX-P detection
除了将YOLOX-P 与原模型进行对比,还分别复现了两种目前主流的目标检测算法在相同的数据集上进行训练和对比,分别为CenterNet 和YOLOv4-M1 网络结构。CenterNet 网络结构以Resnet50 作为主干特征提取网络,YOLOv4-M1 网络结构以MobileNet v1 作为主干特征提取网络以代替CSPDarkNet53。3 种模型检测的mAP和模型权重指标对比如表4 所示(IOU=0.6)。

表4 CenterNet、YOLOv4-M1 和YOLOX-P 对比数据Tab.4 Comparison data of CenterNet、YOLOv4-M1 and YOLOX-P
由表4 可知,YOLOX-P 模型的mAP值最高且模型参数最少,其中mAP值比YOLOv4-M1 模型高15%,达到了99.38%。
为进一步验证YOLOX-P 模型的性能,以玉米种子为对象取1 000 粒种子,分成10 包,每包100 粒(人工精确计数)。取第1 包平铺到白色背景下,进行种子计数;然后用手随意搅动籽粒并平铺,计数;再次用手随意搅动籽粒并平铺,计数。取第2 包籽粒加到之前的100 粒种子中,如上重复计数操作3 次。随后再添加第3~10 包种子,并分别采集计数3 次。如此获得100~1 000 粒种子的3 次重复数种,试验数据如表5 所示,具体示例如图10 所示,结果表明,YOLOX-P计数结果的误差为±2 粒,实现了高精度计数。

表5 YOLOX-P 对每组玉米计数的数据Tab.5 YOLOX-P data on corn count per group

图10 YOLOX-P 对玉米的具体计数示例Fig.10 Example of YOLOX-P corn seed counting
4 结束语
种子计数是获取千粒质量指标最重要的环节之一,以自动化技术精确、快速地计算出种子数量从而减少人工是一项具有重要意义的研究工作。提出了一种基于YOLOX 的作物种子自动计数模型YOLOX-P。相比前者,YOLOX-P 能更好地检测出粘连、堆叠严重的小麦种子,可应用于实时种子计数任务。试验结果表明,YOLOX-P 的mAP为99.38%,在显存6 GB 的NVIDIA GeForce RTX 2060 显卡上推理时间为18.68 ms,能满足获取千粒质量指标时计数精度高和处理速度快的需求。
