基于空间金字塔池化的YOLOv3的柑橘多分级研究
2023-05-08徐中贵谢知音
周 剑,徐中贵,谢知音
(1.湖北民族大学林学园艺学院,湖北 恩施 445000;2.湖北民族大学智能科学与工程学院,湖北 恩施 445000)
0 引言
随着机械化农业与计算机视觉的快速发展,在深度卷积神经网络的技术支持下,水果识别检测、果实产量预测等成为目前农产品生产工业的研究热点[1]。柑橘产业在我国水果产业中的占比相对较重,产量上升的同时导致柑橘在生产过程中所需要的劳动力也在增加[2]。而柑橘分级在柑橘生产中是一重要环节,该环节工作量大,人工分级易出错。因此,实现柑橘的高效精确分级研究至关重要。
近年来,国内外关于水果的分级检测研究提出了多种解决方案。传统水果图像识别技术主要利用水果的颜色、纹理、几何形状特征进行水果定位识别[3]。基于水果颜色特征主要利用果实与背景之间的颜色差别,将目标与背景分开。熊俊涛等[4]提出使用YCbCr 颜色模型对荔枝图像进行阈值分割,去除复杂背景,可实现荔枝果实与果梗的识别。项荣等[5]使用基于边缘曲率分析的方法去识别被轻微遮挡的番茄,对遮挡率为25%~50% 的番茄目标的识别正确率达76.90%。HUSSIN 等[6]使用霍夫变换对柑橘进行识别检测,检测准确度较低,且在柑橘重叠严重时,易出现错误检测。SENGUPTA等[7]提出由Hough 圆检测结合基于支持向量机的纹理分类等技术对户外柑橘进行检测,算法准确率达到80.4%。WU 等[8]采用颜色结合形状特征进行水果分割,利用水果像素特征粗分割,同时采用点云簇的视点特征直方图(viewpoint feature histogram,VFH)精分割水果区域,准确率达到80.09%。以上传统识别技术受环境因素影响大,特征提取复杂,并且难以对水果进行实时性检测。
随着深度学习的深入研究,目标检测算法在水果识别领域得到了广泛应用。GAN 等[9]将彩色图像与热图像进行结合,采用Faster-RCNN 对图像进行实时检测,达到了较高的识别精确度。由于两阶段算法存在检测速度慢等问题,REDMON 等[10-12]在2016 年提出You Only Look Once(YOLO)算法用于对象检测,该算法将区域建议网络(RPN)与分阶段训练进行结合,实现网络结构简单的同时,具有较快的计算速度与较高的计算效率,体现出了较好的检测性能,使其成为真正意义上的实时检测器。王辉等[13]将YOLO 算法进行改进后提出一种水果识别模型,将网络中原有的Batch Normalization 方法用Group Normalization 方法替代,并对其参数进行优化,实现目标检测的实时性,但算法中的特征金字塔网络模块对特征进行融合的效果较差,不能充分提取到水果的特征,进而导致检测效果不理想。华南农业大学薛月菊团队[14]对于果园场景下的芒果采摘问题,将YOLOv2 网络进行改进,设计出新的密集连接网络,较好地解决了果实遮挡与重叠问题,同时采用目标前景标注方法,大大提高了对于未成熟芒果的检测准确率。吕石磊等[15]也提出一种改进的YOLOv3-LITE 轻量级神经网络,该网络将GIOU 边界回归损失函数进行引入从而实现目标果实识别的回归框准确率。
本文基于目标检测算法在水果识别领域的研究,提出一种使用YOLOv3-SPP 的柑橘分级研究,利用YOLOv3 算法的多尺度特征融合检测结合空间金字塔池化,实现多尺度的输入加上多尺度的识别检测。通过该算法可实现食品工业环境下柑橘的快速分级,为水果产业提高技术支持。
1 材料与方法
1.1 数据集的采集
本次试验所采用的试验对象为处于不同生长周期的柑橘果实,根据果实的成熟度进行后续划分。由于目前没有现成的柑橘分级图像数据集,因此需要采集大量图像来建立新数据集。数据集中的图像样本采集自湖北省宜昌市秭归县的脐橙,在自然光照条件下用相机进行拍摄,图像分辨率为3 864×3 864,共拍摄图像500 张。
本研究将柑橘按照柑橘表面着色率的高低,将柑橘划分为4 个等级,分别是一级(着色率为25%以下)、二级(着色率为50%左右)、三级(着色率为75%左右)、四级(着色率为95%以上)。图1 为各划分等级的柑橘示意图。

图1 各划分等级的柑橘示意图
1.2 数据增强
深度卷积神经网络在训练过程中,数据集的数量对于模型最终的性能表现具有重要作用。试验中所采集的图像是有限的,图像中的目标可能存在于不同的环境中,所采集到的图像并不能较好地体现出数据的完整性,因此需要对数据进行增强操作。数据增强并不是简单的数据扩充,而是模仿物体处于不同场景中的姿态,比如在不同的方位、亮度、位姿、缩放比例等。
常用的数据增强的方法主要有:图像翻转、图像旋转、图像裁剪、亮度增强与减弱、图像模糊、添加噪声等,通过数据增强所生成的图像是很难从有限条件下的场景中获得的,因此数据增强对于数据集的完整性具有重要作用。本文中所用到的数据增强方式如图2 所示。

图2 模拟不同环境的数据增强效果
数据增强的作用主要体现在:①可有效地避免模型过拟合,当数据集中的数据存在一种显著的特征信息时,例如在同一个场景拍摄有多张图像,可采用数据增强的方法避免模型学习到与目标不相关的特征信息。②可提高模型的稳定性,降低模型对于图像的灵敏度,当图像中的检测目标出现遮挡、亮度缺失、模糊等状况时,通过数据增强的方式,对训练数据添加噪声等方法提高网络模型在训练过程中的稳定性。③增加训练的试验数据,提升算法模型的泛化能力。④避免因数据较少造成的样本不均衡,在正负样本不平衡的情况下,需要对样本较少的一方进行数据增强,降低不均衡比例。经过图像增强后的数据集将图像扩充到1 846张,使用1 476 张图像进行网络模型的训练,370 张图像用来对模型的检测性能进行验证。样本统计结果如表1 所示。
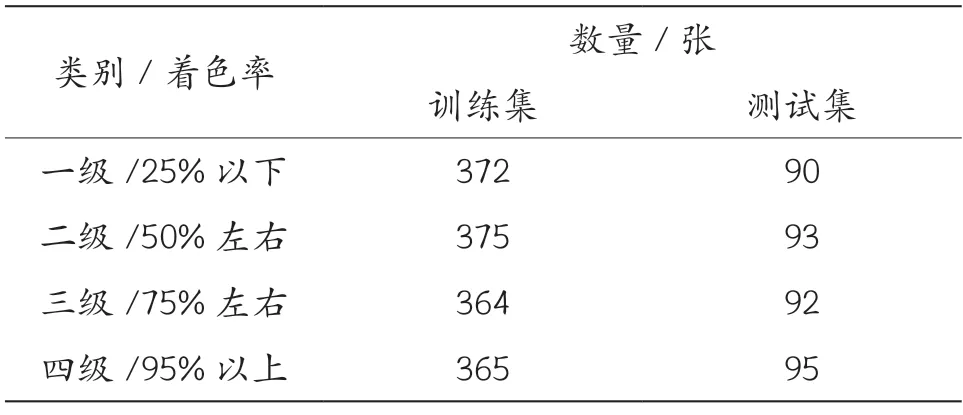
表1 柑橘数据集样本统计
1.3 数据集准备
基于深度学习的目标检测算法需要从大量的数据中提取有效信息,因此数据集的质量与数量在算法训练过程中显得尤为重要,选择一种适合目标检测算法训练的数据集也是关键所在。对于数据集的制作,除了对柑橘图片的采集外,还需要对所采集到的数据进行类别标注,标注原理是对图像中需要识别的物体进行标记,只有经过标注后的图片数据才可为目标检测算法模型提供真实值,模型根据真实值与预测值之间的关系才可进行反向传播,进而更新参数。根据本次试验所采集的图片数据,对所有图片进行标注工作。
本次试验所有数据集由标注工具LabelImg 标注,LabelImg 工具是一个图形图像注释工具。通过使用矩形框手动框选出含柑橘的图像中的柑橘目标位置,该矩形框包含了柑橘目标在图像中的位置信息,再根据事先规定好的柑橘类别标签进行划分。值得注意的是每一张图片中的柑橘目标都需要被标记,不可漏标或错标,以免提供错误的信息给模型,进而影响模型的训练。
2 柑橘多分级检测模型与分析
2.1 YOLOv3模型
1)骨干网络。YOLOv3 用于提取特征的骨干网络为Darknet53,主要借鉴于YOLOv2 网络中的Darknet19 结构。不同于Darknet19 的是,Darknet53结构中采用了大量的残差结构,去掉了池化层,采用步长为2、卷积核大小为3×3 的卷积层代替池化层的下采样工作,其网络结构如表2 所示。
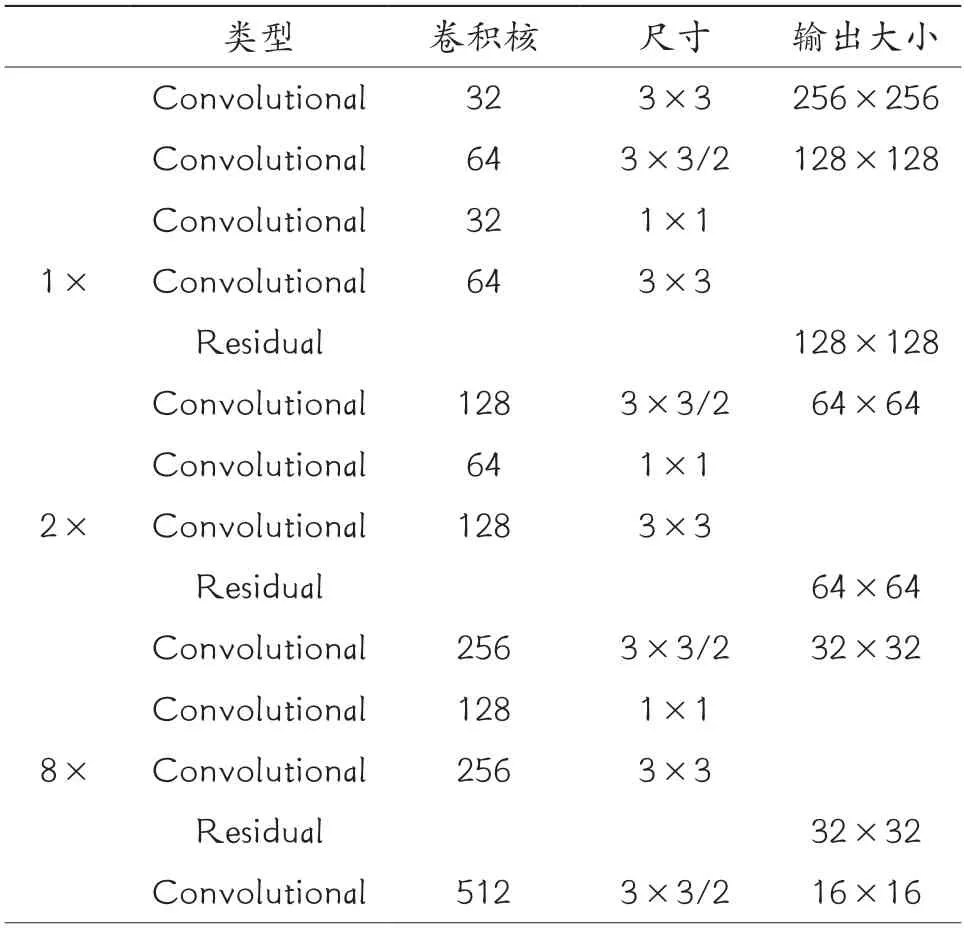
表2 Darknet53模型结构
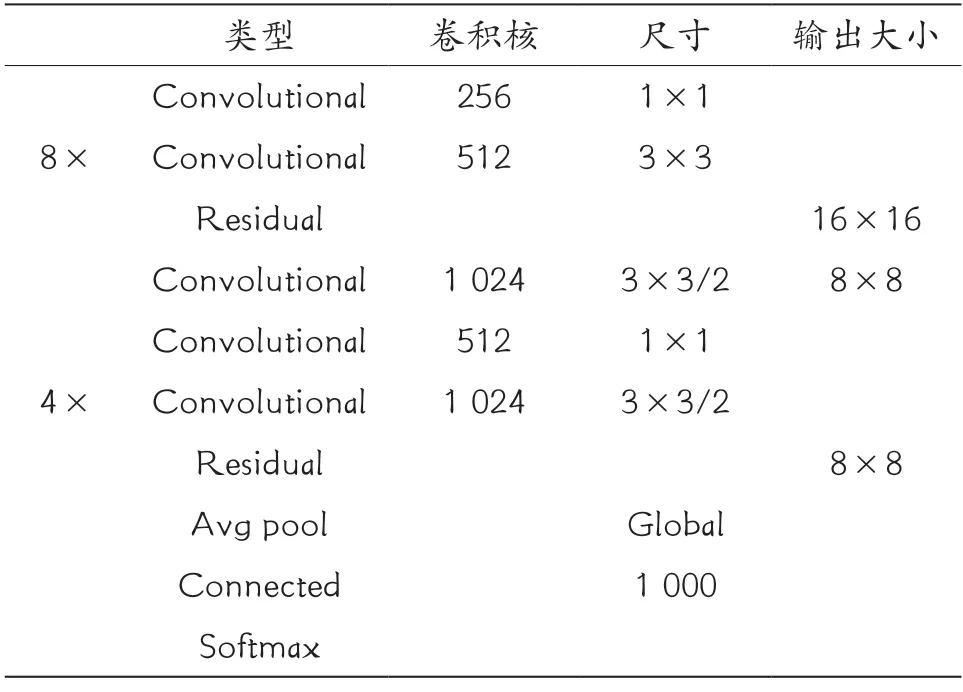
续表
Darknet53 作为YOLOv3 的主干网络表现出两大特点,其一是Darknet53 中大量使用残差结构,该残差结构的主要工作步骤为:①采用卷积核大小为3×3,步长为2 的卷积对特征图进行处理,该卷积可压缩特征图尺寸,将压缩后的特征图层命名为layer。②对layer进行1次1×1的卷积与1次3×3 的卷积,将卷积后的结果与layer 进行有效叠加,进而形成残差结构。通过如此不断叠加,即可加深网络深度来提高准确率,残差结构中使用skip connections 解决了加深网络导致的梯度爆炸与梯度消失问题。其二是Darknet53 中每一个卷积都采用了DarknetConv2D 结构,并对每一个卷积进行L2 正则化,之后再进行Batch Normalization 与LeakyReLU。
2)YOLOv3 网络结构。YOLOv3 通过结合目标检测领域的高性能模块,实现了速度与精度上的均衡。YOLOv3 目标检测算法主要对遮挡物进行回归处理。YOLOv3 算法网络架构如图3 所示,首先,将416×416的三通道图像输入进网络,经过一系列的特征提取,可得到3 种不同特征大小的图像,分别为13×13、26×26、52×52。然后网络将预测特征图划分为S×S个单元格,当待检测目标的中心点落入某单元格中时,该单元格则负责检测该目标,每个单元格预测多个边界框的位置信息与置信度。对于COCO 数据集,输出的预测特征图维度大小为255,最终输出的特征图大小为13×13×255、26×26×255、52×52×255。
如图3 所示,该网络的骨干网络是基于Darknet53 结构的,网络中主要使用1×1 与3×3 的卷积核,其中1×1 的卷积核用于增加非线性特征以及简化网络训练的参数,3×3 的卷积核则是为提取图像上的特征信息。DBL 模块表示一个卷积块,其后进行Batch Normalization 归一化处理以减少过拟合导致的检测效果不佳的问题,并在最后采用Leaky RELU 激活函数。res 模块为残差模块,主要借鉴了残差网络,采用跳跃连接的方法解决深层网络带来的梯度爆炸与梯度消失问题。为增强网络提取特征信息的能力,将网络的输入图像大小调整为512×512。

图3 YOLOv3 网络结构
2.2 空间金字塔池化
在传统深度卷积神经网络中,卷积层后一般跟着全连接层,全连接层的结构是固定的,其中特征数是预先设计好的,故网络输入尺寸也需固定。但在实际训练过程中,输入图像的尺寸大小不一,通常需要进行图像预处理,包括图像裁剪与图像拉伸等操作。但在对输入图像进行处理的过程中,图像的原始尺寸大小与比例都会随之改变,进而改变图像中保存的原始信息。何凯明等[16]提出的SPP(Spatial Pyramid Pooling)能够较好地解决该问题。
SPP 的主要工作原理是在卷积神经网络中的卷积层后加入SPP层,SPP 层将特征图处理成固定尺寸的特征矩阵,最后将特征矩阵输入到全连接层中,完成网络后续训练。SPP 在网络训练过程中表现出的优点在于,一方面解决了proposal regions 的尺寸问题,即将不同尺寸的输入图像进行尺寸统一化,进而产生固定长度的输出。另一方面,SPP 中包含的池化结构为多层级而非单一层级的池化核,可对不同尺度的特征进行池化处理,并且处理后的结果可实现共享,节省了大量计算时间。SPP 模块的结构如图4 所示。
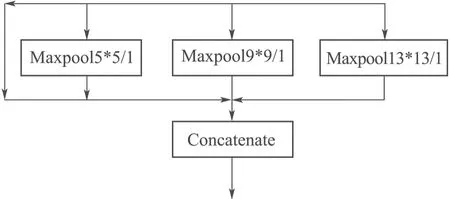
图4 SPP 模块
2.3 YOLOv3-SPP模型
在对柑橘分级检测过程中,图像采集设备所采集到的图像往往没有很清晰,这使得图像识别算法难以识别,按照原有的YOLOv3 网络需要对输入图像进行裁剪和变形,此类操作容易丢失图像原始的特征信息。在这种情况下,柑橘中存在的难以检测的缺陷以及不明显的颜色差异将影响柑橘的分级效果。针对这一问题,本研究中使用的网络YOLOv3-SPP 在YOLOv3 网络的基础上进行了性能改进。YOLOv3-SPP网络主要是在YOLOv3 网络中加入SPP 模块,使得网络可接受不同尺寸的输入图像,并对不同尺度的特征进行提取,其网络结构如图5 所示。
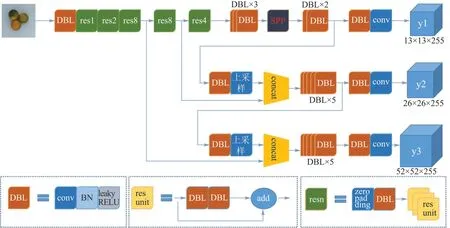
图5 YOLOv3-SPP 网络结构
2.4 损失函数
损失函数(Loss Function)本质上是用来计算模型训练过程中预测值与真实值之间的差距的一类函数。本次试验所采用的损失函数为交叉熵损失函数(Cross Entropy Error Function)。函数表达式为
式中:
yi——样本的真实概率;
该函数表述了真实值与预测值之间的差距,差距越小,交叉熵则越小,即预测结果越准确。
3 结果与分析
3.1 试验环境
本试验采用Pytorch 作为柑橘分类模型搭建和试验平台,模型在GPU 环境下运行。具体配置如表3 所示。
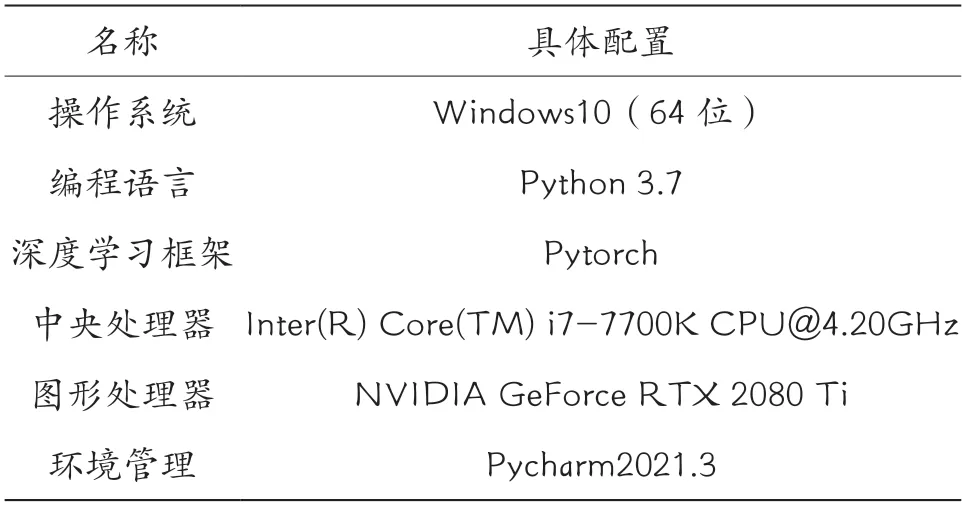
表3 试验具体配置
3.2 评价指标
深度学习模型在学习任务过程中的性能表现需要定量的指标进行评估,才可对模型的整个性能进行横向对比。评价指标主要是利用试验数据进行对比分析得出一个评判标准,良好的评价指标能够较好的判断算法的有效性和合理性,还可根据评价结果分析出深度学习模型中存在的问题与不足,进而实现有目的性的改进。
深度学习中常用的评价指标包括:混淆矩阵(Confusion Matrix)、准确率(Accuracy)、精确率(Precision)、召回率(Recall)、平均精度(Average Precision)、mAP(mean Average Precision)、IoU 等。
1)混淆矩阵(Confusion Matrix)是评判模型结果的指标,主要用于判断分类器的好坏,也可称为误差矩阵。混淆矩阵中包含的参数主要有:TP(正样本被正确检测为正样本)、TN(负样本被正确检测为负样本)、FP(负样本被错误检测为正样本)、FN(正样本被错误检测为负样本),混淆矩阵的主要结果如图6 所示。
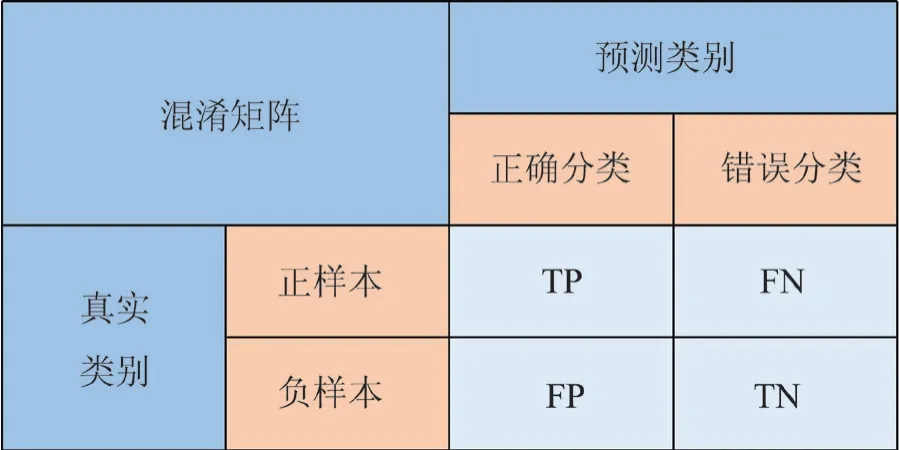
图6 混淆矩阵示意图
2)准确率(Accuracy)为正确分类的样本数与总样本数的比值,其计算方式为
3)精确率(Precision)为正确分类的样本数与检测出的样本数的比值,其计算方式为
4)召回率(Recall)为正确分类的正样本数与正样本数的比值,其计算方式为
5)AP(Average Precision)是P-R曲线与两坐标轴所围成的面积,P-R 曲线是以Recall 为横坐标,Precision 为纵坐标绘制成的曲线。mAP(mean Average Precision)为多个类别的AP 的平均值,其计算方式分别为
由于精确率与召回率呈反比关系,导致两参数在模型训练中不可同时调整,进而影响模型的查准率,P-R 曲线将精确率与召回率用曲线的方式进行分析,找到两参数间的平衡点,实现高精度的同时降低错误目标的概率,因此采用P-R 曲线来用于评判目标检测算法的检测性能。
本文主要采用的模型性能评价标准为平均精确率(AP)以及平均召回率(AR)。
3.3 模型对比试验
3.3.1 不同交并比对模型性能的影响
本文采用自制柑橘数据集对网络进行性能测试,在训练参数方面,默认模型多尺度训练,batch size 设置为16,使用momentum 动量优化,动量参数选择为0.9,初始学习率设置为0.001,在训练过程中对学习率进行衰减调整,初始学习率较大,模型收敛较快,训练后期使用衰减后的学习率可使模型找到最优权重,模型迭代次数为500 次。
交并比(Intersection-over-Union,IoU)为目标检测技术中的一个重要参数,是生成的候选框与所标记的框的重合率,即两者的交集与并集的比值,其计算方式为
式中:
C——候选框(candidate bound);
G——标记框(ground truth bound)。
本试验将探讨不同交并比对模型平均精度所造成的影响,分别测试交并比为0.50:0.95、0.50、0.75时对模型造成的影响,具体情况如图7 所示。当IoU 为0.50:0.95,即交并比IoU 阈值设为0.50 到0.95,步长为0.05时,模型平均精度相对较低且变化幅度大;当IoU 为0.50(交并比阈值设为0.50)时,模型平均精度开始上升并趋于稳定状态;当IoU 为0.75(交并比阈值设为0.75)时,模型平均精度在前者基础上不再上升并处于稳定状态。
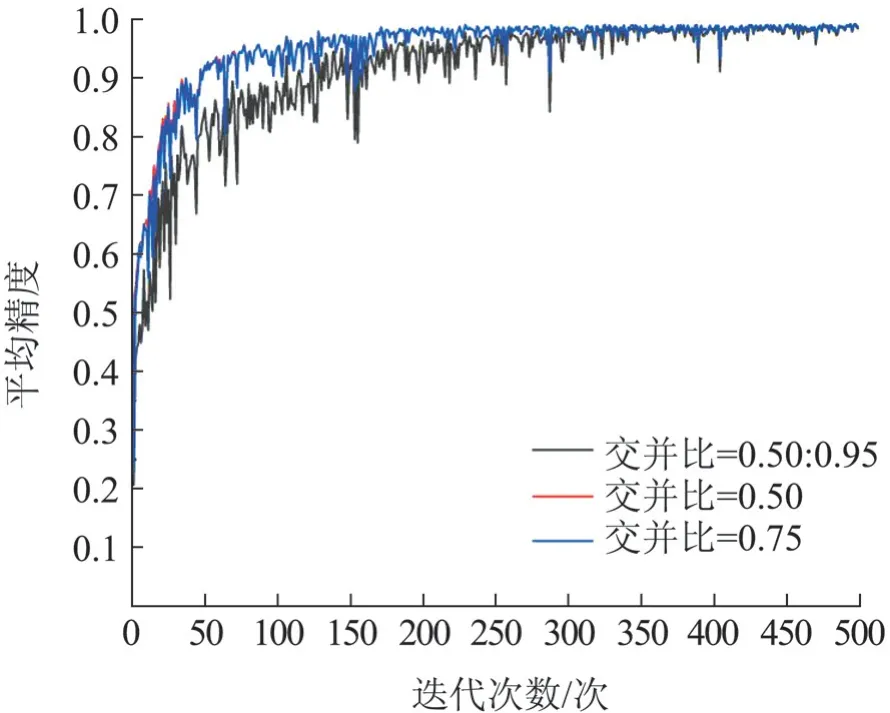
图7 不同交并比的平均精度对比
为验证该算法对于柑橘多分级工作的有效性,在相同数据集、相同试验条件下的基础上,对不同交并比的训练结果进行对比分析,表4 列出了模型训练完成后的平均精度对比。
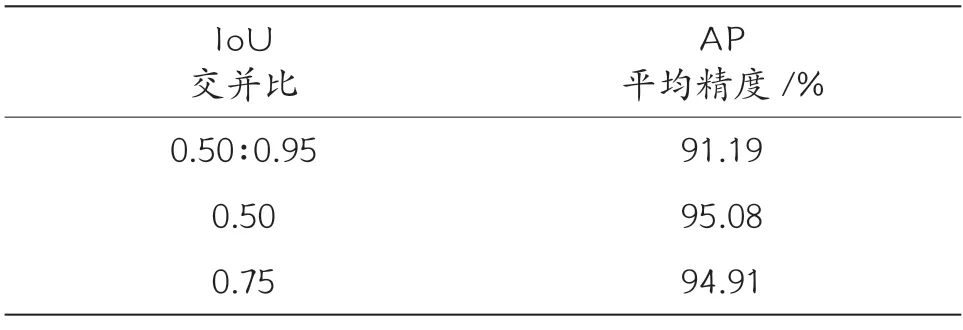
表4 不同交并比结果对比
3.3.2 不同最大检测目标数对模型性能的影响
本试验在交并比固定的情况下,研究不同最大检测目标数对模型平均召回率的影响,分别测试最大检测目标数为1、10、100 时对模型性能造成的影响,具体情况如图8 所示。当图像中存在的最大检测目标数为1 和10时,由于所设定的检测目标数较小,导致模型训练出的结果并不理想;当图像中存在的最大检测目标数为100时,模型表现出的性能较为优越。

图8 不同最大检测目标数的平均召回率对比
不同的损失函数会对训练模型的收敛情况造成直接的影响,本试验使用交叉熵损失函数对模型进行训练,分别分析了模型的损失、定位损失、类别损失以及置信度损失的收敛情况。训练损失结果如图9 所示:(a)为模型的损失值变化曲线,(b)为模型的定位损失值变化曲线,(c)为模型的类别损失值变化曲线,(d)为模型的置信度损失值变化曲线。
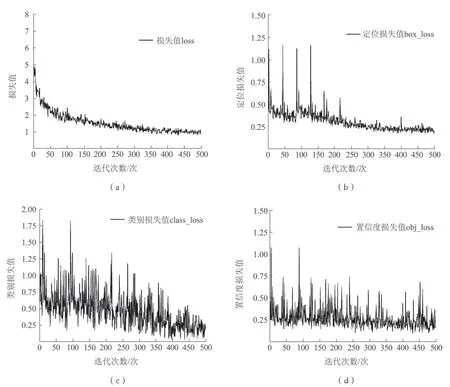
图9 模型损失图
在模型训练过程中,模型的迭代次数与模型整体性能并不成正比,网络模型在收敛过后若再进行训练,模型将进入过拟合状态。训练过程中,模型损失处于稳定状态不再下降,表示模型已训练完成。如图9 所示为YOLOv3-SPP 柑橘分级算法的训练损失图,可以看出随着迭代次数的增加,损失在不断降低,模型开始走向收敛,迭代到350 次之后开始走向稳定。
4 结语
本文提出一种基于YOLOv3-SPP 的算法对食品工业环境下的柑橘进行分级检测,通过构建柑橘数据集以及相应的数据处理操作,以提高深度卷积神经网络的泛化能力。利用SPP 模块特有的结构,使得网络可接受不同尺度的输入特征图,并对不同尺度的特征进行提取,从而提升了模型对图像中存在的特征信息的提取能力,进而提高模型的整体性能。通过运用基于空间金字塔池化的YOLOv3 网络对柑橘的多分级检测精确率达到95.08%。该模型基于其自身的快速精确的特点,在加入空间金字塔池化后对柑橘表面特征有了更好的提取能力,能够提取到更多的柑橘表面特征信息。该网络在对于柑橘多分级工作表现出的效果优异,有助于提供食品工业下柑橘产业的产品生产率,解决柑橘分级量大,消耗劳动力大,工作效率低等问题。
本次试验所构建的数据集只针对一个品种的柑橘,并不能实现多类别的柑橘分级,后续可根据实际需求增加数据集的类别与数量,完成更加多量的柑橘分级工作。
