基于遍历异或运算的RFID标签所有权转移算法
2023-05-08卢爱芬
卢 爱 芬
(广州科技职业技术大学信息工程学院 广东 广州 510550)
0 引 言
射频识别技术出现在20世纪,由于当时科技等因素,未能广泛得到运用[1]。进入21世纪后,不断有新科技产生,诸如云计算、大数据、物联网、区块链等技术的运用,也逐渐带动射频识别技术再次推广[2-3]。
一个典型的RFID系统一般包含标签、读卡器、服务器,其中电子标签在其一生使用过程中,归属者可能经常发生变更[4-5]。一个典型的嵌有电子标签的物品归属者变更例子如下:嵌有电子标签的商品在未出厂之前,商品的归属者是厂商;待批发商从厂商手中购买走该批商品,商品的归属者由厂商变更为批发商;当零售商又从批发商手中购买走商品,则商品的归属者再次由批发商变更为零售商;最后消费者从零售商那里买到该商品,商品的归属者最终变更为消费者[6-7]。在商品归属者变更过程中,原来的归属者不能去访问当前归属者存放在商品中的隐私信息,相对应的,当前归属者亦不能访问原来的归属者存放在商品中的隐私信息,为能够确保用户存放在商品中隐私信息的安全,需要用到所有权转移算法[8-9]。
文献[10]最先给出所有权转移概念,同时提出一个所有权转移算法,该算法基于传统的对称密码体制对信息进行加解密,同时算法中引入TTP进行相关信息的更新操作,不仅增加了通信的复杂度,而且算法存在去同步化攻击安全隐患。文献[11]中基于树设计一个所有权转移算法,具备一定安全需求,但仍无法抵抗攻击者的跟踪攻击,无法推广。文献[12]中同样引入可信第三方,使用TTP来掌握相关共享秘密值的更新操作,对算法分析,算法无法提供前向安全的安全需求,攻击者可以利用前向安全分析获取隐私信息。文献[13]中利用哈希函数及对称加密算法给出一个所有权转移算法,算法除了存在计算量大问题外,算法还无法提供后向隐私信息的安全,攻击者可以发动异步攻击,迫使通信实体之间失去一致性。文献[14]基于优化的Rabin加密算法设计一个所有权转移算法,对使用的优化的Rabin加密算法分析,发现其本质就是模运算,对于计算受限制的标签来说,模运算计算量有些超出标签的计算能力,无法推广。同时对算法本身进行分析,发现算法本身存在多余的计算步骤。
鉴于现有的较多经典算法存在安全不足或计算量大或无法满足要求等缺陷,本文在结合众多算法的基础之上给出一种改进的所有权转移算法。本文算法在保证安全的情况,秉着尽可能降低标签及其他通信实体计算量的理念,引入创新型设计的遍历异或运算实现对信息的加解密,遍历异或运算采用位运算的方式实现,能够将计算量提升到超轻量级的级别。同时尽量优化算法的通信过程,避免出现冗余的计算步骤。对算法从安全和计算量角度分析,算法能够提供较好的安全需求,同时相对于原算法而言,计算量有较大幅度的降低。
1 算法设计
1.1 原算法的分析
文献[14]基于Rabin算法给出一个标签所有权转移算法,算法具体步骤可以见文献[14]中描述,此处不再赘述。对算法进行分析,该算法主要存在两个不足之处,详细分析如下:
1) 原算法在第五步骤中,标签原所有者对标签进行验证过程中,标签原所有者通过E和F两个消息即可实现标签原所有者对标签的验证,但算法在对E和F进行计算验证之后,将再次对D进行验证,完全没有必要多此一举。
2) 原算法在第七步骤中,标签对标签新所有者进行验证过程中,标签通过H和G两个消息即可实现标签对标签新所有者的验证,但算法在对H和G进行计算验证之后,将再次对P进行验证,完全没有必要多此一举。
基于上述两个不足之处,还引出其他问题,问题一:整个通信过程中,标签发送给标签原所有者消息没必要发送D、E、F三个,只需要发送两个消息即可;标签新所有者发送给标签消息没必要发送H、G、P三个,只需要发送两个消息即可,使得整个通信过程中通信量增大。问题二:标签一端因需要计算D、E、F三个消息,使得标签的计算量增大;同时标签对标签新所有者的验证也因H、G、P三个消息而增大了计算量,两处计算极大地增加了标签一端的计算量。
基于上述,文中改进的算法避免出现冗余的计算步骤,从而尽可能降低标签一端的计算量;同时改进的算法采用计算量更低的遍历异或运算实现对信息的加密,更进一步降低标签一端的计算量。
1.2 遍历异或运算的设计
遍历异或运算(Ergodic XOR operation,EXO(X,Y))按照如下方式实现:
(1)X、Y、Z均表示二进制序列,长度取值均为L位。
(2)Wt(X)、Wt(Y)分别表示二进制序列X、Y的汉明重量。
(3)Px、Py分别表示指向二进制序列X、Y的指针。
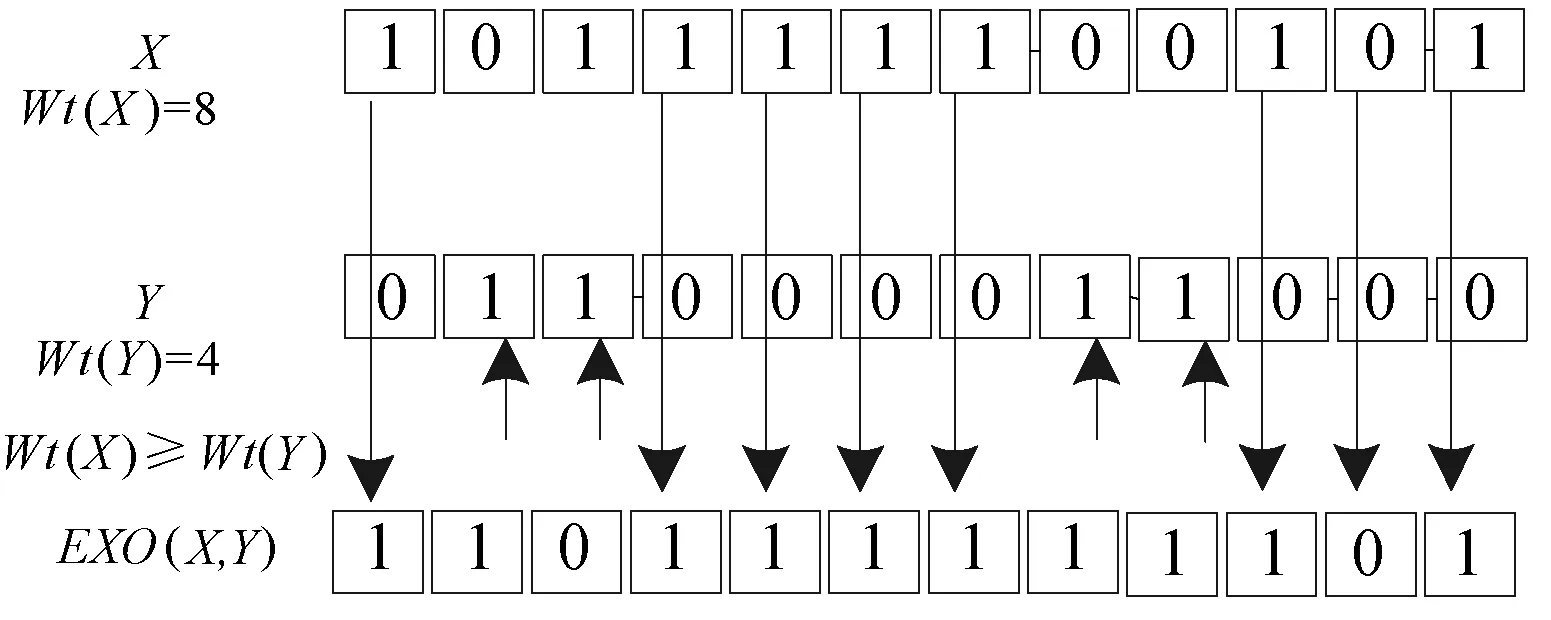
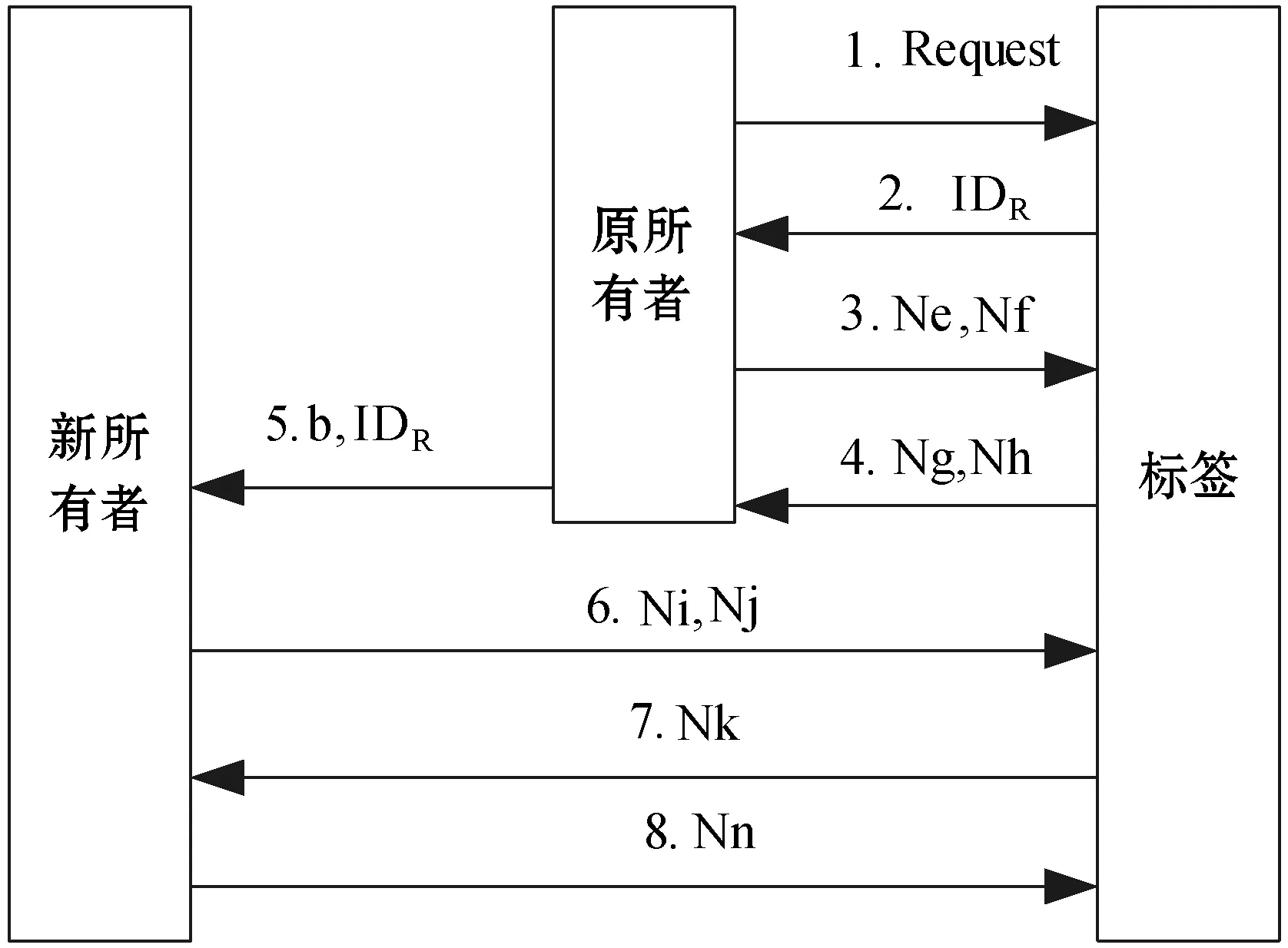
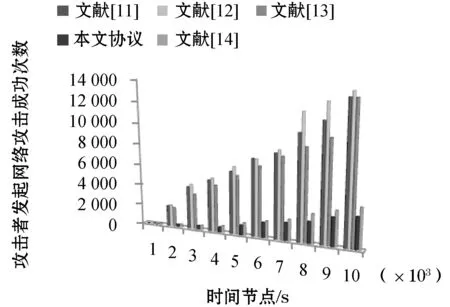
(4) 当Wt(X) (5) 当Wt(X)≥Wt(Y)时,对二进制序列X、Y同时从第一位开始遍历,指针Px指向二进制序列X的第i位Xi时,指针Py指向二进制序列Y的第i位Yi,如果Yi=1,则Xi和Yi进行异或运算,并将运算结果放置于二进制序列Z的第i位上,得到Zi;如果Yi=0,则直接将二进制序列X的第i位Xi的值放置于二进制序列Z的第i位上,得到Zi。 通过下面两个例子来说明遍历异或运算的实现。取值L=12位,X=011000000100,Y=101011010101,则可以得到Wt(X)=3、Wt(Y)=7,满足Wt(X) 图1 EXO(X,Y) Wt(X) 再次取值L=12位,X=101111100101,Y=011000011000,则可以得到Wt(X)=8、Wt(Y)=4,满足Wt(X)≥Wt(Y)条件,根据(5)中操作步骤,可得到遍历异或运算最终结果为EXO(X,Y)=Z=110111111101。具体可以见图2所示。 图2 EXO(X,Y) Wt(X)≥Wt(Y) 算法中涉及到的符号含义如下: SN:标签所有权新所有者; SO:标签所有权原所有者; T:标签; State:标签所有权归属标志位,当State=0时,表示标签所有权当前归属于SO;当State=1时,表示标签所有权当前归属于SN。 a:SO产生的随机数; b:T产生的随机数; c:SN产生的随机数; IDL:T的标识符左半部分; IDR:T的标识符右半部分; KO:T与SO之间的共享秘密值; KN:T与SN之间的共享秘密值; ⊕:异或运算; EXO(X,Y):遍历异或运算。 本文算法与其他算法一致[15-16],SN与SO之间通信链路安全,SO与T之间通信链路不安全,SN与T之间通信链路不安全。所有权转移算法开始之前,SN存放信息有IDL、IDR、KN;SO存放信息有IDL、IDR、KO;T存放信息有IDL、IDR、KN、KO。 改进的所有权转移算法示意图如图3所示。 图3 改进的所有权转移算法 结合图3,本文算法具体步骤如下: (1)SO向T发送Request命令,开启所有权转移过程。 (2)T收到信息,当前State=0,表明标签所有权当前归属于SO所有。T将IDR发送给SO。 (3)SO收到信息,在数据库中查找是否有与IDR相等的参数。没有,算法结束;有,先产生随机数a,再调用与IDR相对应的IDL的值,分别计算Ne、Nf,并将Ne、Nf发送给T。其中Ne=a⊕IDL、Nf=EXO(a,KO)。 (4)T收到信息,通过Ne计算得到随机数a′,将a′、KO结合计算得到Nf′,比较Nf与Nf′的值。若不等,T验证SO失败,算法结束。若相等,表明a′=a,T产生随机数b,分别计算Ng、Nh,并将Ng、Nh发送给SO。其中a′=Ne⊕IDL、Nf′=EXO(Ne⊕IDL,KO)、Ng=b⊕KO、Nh=EXO(b,a)。 (5)SO收到信息,通过Ng计算得到随机数b′,将b′、a结合计算得到Nh′,比较Nh与Nh′的值。若不等,SO验证T失败,算法结束。若相等,表明b′=b,SO通过安全信道将信息b、IDR发送给SN。其中b′=Ng⊕KO、Nh′=EXO(Ng⊕KO,a)。 (6)SN收到信息,产生随机数c,分别计算Ni、Nj,并将Ni、Nj发送给T。其中Ni=c⊕IDL、Nj=EXO(KN,c)。 (7)T收到信息,通过Ni计算得到随机数c′,将c′、KN结合计算得到Nj′,比较Nj与Nj′的值。若不等,T验证SN失败,算法结束。若相等,表明c′=c,T计算Nk,并将Nk发送给SN。其中c′=Ni⊕IDL、Nj′=EXO(KN,Ni⊕IDL)、Nk=EXO(c,b)。 (8)SN收到信息,通过相同的运算规则计算得到Nk′,比对Nk′与Nk的值。若不等,SN验证T失败,算法结束。若相等,SN计算Nn,并将Nn发送给T。其中Nk′=EXO(c,b)、Nn=EXO(b,KN)。 (9)T收到信息,通过相同的运算规则计算得到Nn′,比对Nn′与Nn的值。若不等,T验证SN失败,算法结束。若相等,T将标志位State的值由0置换为1,表明现在标签的所有权归属于SN,到此标签的所有权转移顺利结束。其中Nn′=EXO(b,KN)。 本文算法在减少系统会话参数量之后,仍能保障信息的安全性,通过如下各不同角度对算法进行安全性分析。 (1) 所有权排他转移。所有权排他转移指的是算法完成之后,标签所有权归属于SN,而非归属于SO。本文算法通过T一端的标志位State来标记标签所有权当前归属于谁所有。算法没有开始之前,State=0,表明所有权归属于SO,当且仅当SO、SN、T三者之间通过彼此之间的认证之后,标签一端的标志位State的值才会发生变化,由0变为1,当State=1时,表示标签所有权当前归属于SN。本文算法中,SN与T之间用到KN作为共享秘密值,SO与T之间用到KO作为共享秘密值,KN与KO的值不一样,且SO不知晓KN的值,因此SO就无法假冒SN通过T的验证,从而无法修改标签一端标志位的值,因此,本文算法能够保障所有权排他转移安全。 (2) 目标标签转移。标签所有权转移过程中涉及到很多标签的隐私信息,因此必须确保转移的标签是目标标签,而非其他标签。本文算法通过通信实体之间的认证来确保转移的标签就是目标标签,具体的如下:SO通过算法中的步骤(3)、步骤(5)确定是目标标签身份;SN通过算法中的步骤(8)确定是目标标签身份。攻击者缺少必要的认证信息,无法假冒目标标签进行通信。因此,本文算法能够确保转移的标签即为目标标签。 (3) 定位攻击。本文算法标签在发送消息的时候,所有信息加密过程中含有随机数,其中Ng和Nh中含有随机数a和b,Nk中含有随机数c和b,使得每次通信过程中Ng、Nh、Nk的值都是不同的。当攻击者截获上述消息时,攻击者也无法定位标签的位置。因此,本文算法可以确保标签的位置安全。 (4) 暴力攻击。攻击者对截获的消息进行穷举的方式进行破解,该种攻击方式可称之为暴力攻击。攻击者通过监听一个完整的消息交换过程,可以获取IDR、Ne、Nf、Ng、Nh、Ni、Nj、Nk、Nn信息,攻击者可以根据窃听的消息对其中任何一个或几个发起暴力攻击。选择Ne、Nf为例进行分析,其他消息暴力攻击分析方式相一致,不再阐述。 首先攻击者获取的Ne、Nf是加密之后的密文,设定攻击者知晓Ne、Nf加密的运算法则,即攻击者知晓Ne是由SO产生的随机数a与IDL进行异或运算所得。攻击者可对Ne进行变形,变形之后得到a′=Ne⊕IDL。接着攻击者再将变形之后得到的数据代入Nf中,可得到Nf′ =EXO(a′,KO) =EXO(Ne⊕IDL,KO)。在整个变形或计算过程中,涉及到的参数有a、IDL、KO,其中a可由Ne和IDL变形得到,因此在最后变形得到的Nf′中实则有IDL、KO两个参数值攻击者不知晓。再结合本文遍历异或运算加密算法的定义可知,攻击者同时也不知道Ne⊕IDL、KO汉明重量值,因此,于攻击者而言,有四个参数值不知道,故攻击者对消息Ne、Nf发起的暴力攻击是失败的。 (5) 假冒攻击。会话系统中共有三个会话实体,攻击者可假冒其中任何一个实体与其他实体进行会话。此处选择攻击者假冒成电子标签与标签所有权原归属者、新所有者进行消息交换进行分析。 当攻击者假冒成电子标签与标签所有权原归属者进行会话时,攻击者想要通过SO的验证,则攻击者必须获取合法的IDR值。当然攻击者可以窃听上轮会话获取该消息值,可以通过SO的第一次验证;当攻击者通过SO的第一次验证之后,SO会进行一系列操作之后向攻击者发送合法的Ne、Nf消息,但SO收到后无法正确地解密得到SO产生的随机数a。当攻击者无法解密得到正确的a时,攻击者只能随机选择一个数值充当a,进行后续的加密操作得到错误的消息Ng、Nh。当SO再次收到攻击者发送来的消息,并对攻击者再次验证时,攻击者是无法通过SO的第二次验证的。原因在于:攻击者并不知晓IDL的值,因此无法解密出正确的a,就无法用正确的a加密得到正确的消息Ng、Nh值。基于上述,攻击者假冒电子标签向SO发起假冒攻击以失败告终。 当攻击者假冒成电子标签与标签所有权新归属者进行会话时,攻击者想要通过SN的验证,则攻击者必须计算得到正确的Nk消息(攻击者当然可以通过窃听的方式获取正在会话的Nk消息,并在下一轮会话时伪装成标签向SN发送该消息,但攻击者是无法成功的,具体原因可见下面一点的有关“重放攻击”的分析。)。既然攻击者无法通过窃听在重放方式通过SN的验证,那攻击者只能先破解计算正确Nk消息所需要的随机数c的值。攻击者无法通过窃听的消息中破解出SN产生的随机数c的值,同时攻击者也根本无法得到真正电子标签随机产生的随机数b的值,因此攻击者根本无法计算得到正确的Nk值。攻击者只能随机选择两个数作为上述参数的值进行计算,当SN收到消息只需进行简单计算,即可验证攻击者假冒。基于上述,攻击者假冒电子标签向SN发起假冒攻击以失败告终。 (6) 重放攻击。攻击者通过窃听当前会话完整过程,可以获取该轮会话的所有消息,然后在下次会话过程中,攻击者假冒其中一个实体向其他实体发送截获上轮消息,以企图通过其他实体的验证,进而进行获取隐私信息,该种攻击方式可称之为重放攻击。抵抗重放攻击最为常用的方法便是在每轮消息加密过程中都混入随机数。通过加密消息过程中混入随机数方法抵抗攻击者发起的重放攻击原因有如下:其一,随机数一般由随机数产生器随机产生,所得到随机数具有随机性,使得攻击者根本无法预测下轮会话加密用到随机数的值;其二,随机数产生器得到的随机数还具备互异性,即不会产生重复的随机数,这样使得前后每轮会话加密时混入的随机数一定不同,则每轮会话加密得到的同一个消息数值每次也不同。本文协议所有攻击者窃听获取的消息在加密时都混入随机数,因此,基于上述,本文算法能够抵抗攻击者发起的重放攻击。 将本文算法同文献[11-14]中算法进行相同环境下仿真实验。选择某个时间段内,上述不同算法面对攻击者发起的来自不同角度网络攻击进行仿真实验,因此选取的时间节点为1 000秒、2 000秒、3 000秒、4 000秒、5 000秒、6 000秒、7 000秒、8 000秒、9 000秒、10 000秒;并在每个时间节点进行仿真实验时,为提高仿真实验数据准确性,每个时间节点进行仿真实验次数不低于500次,同时记录这500次仿真实验数据,最后求取这500次实验数据的平均值作为最终的仿真实验结果,如图4所示。 图4 不同算法间网络攻击成功次数对比 从图4中可以分析得到,相对于文献[11-13]中算法而言,文献[14]中算法及本文算法面对相同仿真环境时,攻击者发起的网络攻击成功次数得到大幅度的减少,表明本文算法及文献[14]中算法安全性提高很多。但同时也可以看出,本文算法在每个时间节点统计的仿真实验数据均少于文献[14]中算法数据,表明本文算法具备比文献[14]中算法更好的安全性能。 原所有者和新所有者包含读卡器及服务器具备强大的计算能力和存储空间,因此仅选择标签为对象进行性能角度分析。本文算法与其他经典算法之间性能比较如表1所示。 表1 算法之间性能对比 表1中各符号含义如下,QPUF表示物理不可克隆函数的计算量,QW表示按位运算的计算量(按位运算常见的有按位异或运算、按位与运算等),QHASH表示哈希函数的计算量,QEK、QDK、QFT都表示变形或改进后的哈希函数的计算量,QL表示左移运算的计算量,QR表示右移运算的计算量,QRABIN表示优化之后的Rabin算法的计算量,QEXO表示遍历异或运算的计算量。L表示算法通信过程中每个消息的长度均为L长度,S表示算法通信过程中类似于Request命名指令占用长度。 在上述运算中,属于超轻量级运算的有按位运算、遍历异域运算、左移运算、右移运算,其他都不属于超轻量级运算。相对于超轻量级运算来说,其他运算的计算量远远多于超轻量级运算的计算量。上述比较的文献中,除了本文算法用到的运算均属于超轻量级,其他文献中的算法或多或少均使用到非超轻量级的运算,因此从标签一端的计算量角度出发,本文算法在计算量方面有较大程度上的减少。整个算法的通信过程中通信量大小与其他文献中的算法通信量相当,但本文算法能够弥补其他算法存在的安全缺陷,仍具备一定的优势,有一定的推广价值。 针对原算法存在计算多余缺陷,设计出一个改进的所有权转移算法。改进的算法在减少计算的同时亦能保证会话的安全性;本文算法并未沿用原算法中Rabin算法对信息加密,而是采用自创的遍历异或运算算法对信息加密,能够一定程度上减少系统整体的计算量;对算法本身进行分析,可以提供用户的安全需求;本文算法通过标签端标志位State值来显示当前标签所有权归属,只有通过严格的认证之后,标志位值才会发生变更,确保了所有权的唯一性。对本文算法进行安全和计算量角度的比对分析,本文算法在减少计算量和通信量的情况,能够提供较好的安全性,满足当前RFID系统对安全和计算量的要求。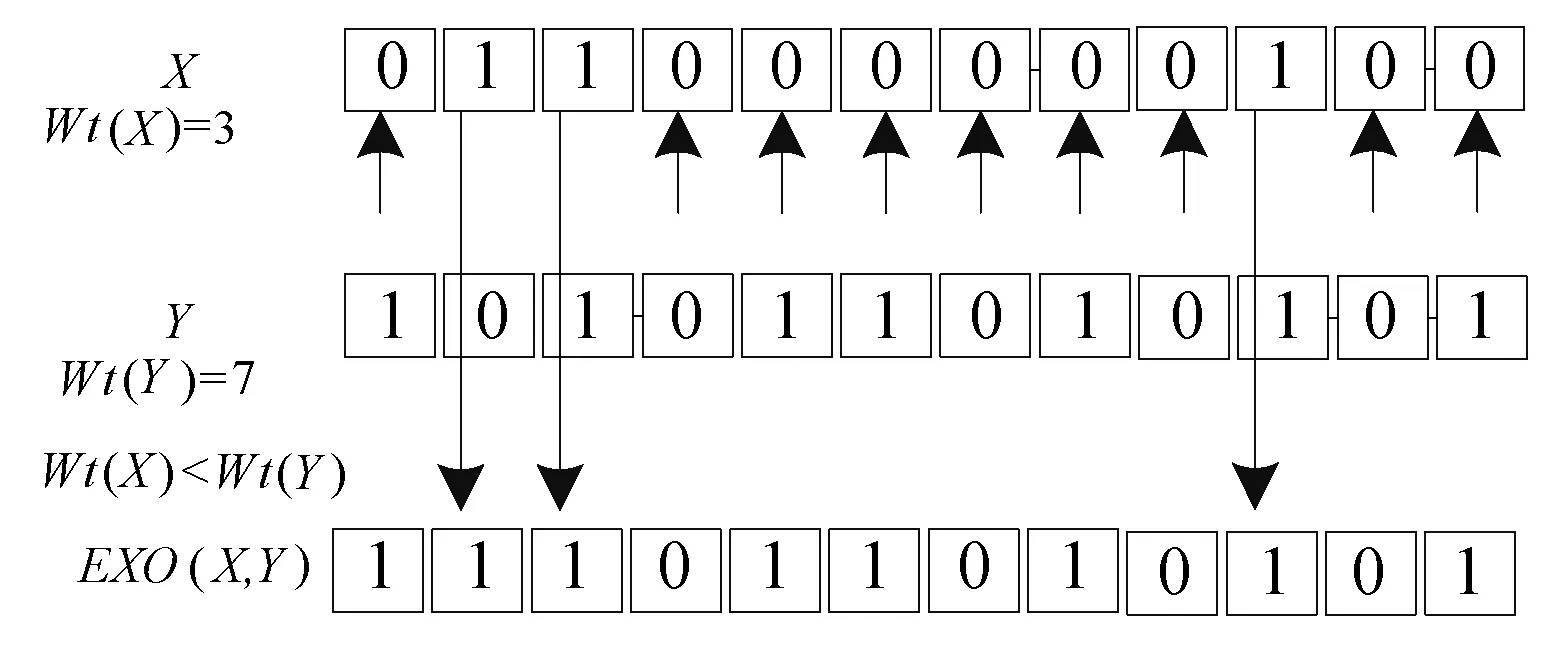
1.3 算法符号含义
1.4 算法实现
2 算法安全性
3 算法性能

4 结 语
