融合多尺度特征的医学图像分割模型
2023-04-27徐志成何良华
徐志成 何良华


1 概述
在过去的几年里,卷积神经网络(CNN) 在医学图像分析方面取得了里程碑式的成就。特别是,基于U 形结构和跳跃连接的深度神经网络已广泛应用于各种医学图像任务。同时,随着MedT[1]在医学图像分割任务中的出色表现,越来越多的方法在医学图像分割中引入了Transformer,比如UCTransNet[2]、Swin-Unet[3]等,并且表现超越了传统的CNN同类方法。
虽然Transformer有很强的全局关系归纳能力,但是直接将原始Transformer用于图像分割任务中会带来巨大的参数量。为了解决这一问题,学者提出Swin Transformer[4]、CSWin Transformer[5]等,这两种结构都是通过针对图像的特点去改进注意力的计算方式,从而在保证分割效果的情况下,更加有效地降低参数。相较于Transformer的全局关系归纳能力,CNN可以对局部关系进行很好的归纳,在图像分割中这两种特征信息都十分重要。因此,将Transformer提取的全局特征和CNN提取的局部进行融合可以得到更加鲁棒、丰富的特征信息,从而提高分割的效果。结合上述思路,本文主要做了以下工作:
1) 提出基于CSWin Transformer[5]和CNN的U形网络结构模型CSWin-Unet,用于提取多尺度特征。
2) 提出特征融合模块代替传统U形网络结构的跳跃连接层,将CNN和Transformer的特征进行有效融合,并且利用上述网络结构模型在前列腺数据集上取得很好的分割效果。
2 相关工作
在医学图像分割领域,早期的分割方法主要是基于轮廓和传统机器学习的算法[6-7]。随着深度CNN的发展,文献[8]提出了用于医学图像分割的U形网络结构U-Net。该网络结构主要由编码器、解码器和跳跃连接层组成,由于U形结构的简单性和优越性能,各种类似Unet的方法不断涌现,例如Res Unet[9]、U-Net++[10]等,它还被引入3D医学图像分割领域,如V-Net[11]。
在机器翻译任务中,Transformer[12]首次被提出并应用,并且取得了最佳的性能表现。由于其出色的表现,研究人员在视觉任务中引入Transformer提出了Vision Transformer(ViT) [13],并且在图像识别任务中取得了优异的表现,但是这种基于Transformer 的方法与传统CNN方法相比,ViT需要在大型数据集上进行预训练。为了使ViT可以更好地进行训练,Deit提出了不同的训练策略,这些策略可以使ViT有更好的训练效果。另外,ViT在视觉任务的训练具有很高的计算复杂度,为此,研究人员提出了一种新颖的Transformer结构Swin Transformer[4],这种方法主要基于滑动窗口和分层结构,将注意力计算限制在一个窗口中,一方面能引入CNN卷积操作的局部性,另一方面能节省计算量,在视觉任务(包括图像分类、对象检测和语义分割)取得了最优异的性能表现。得益于Swin Transformer的优异表现,研究人员提出了基于Swin的U形网络结构并且应用在医学图像分割任务上,取得了優于同类CNN网络的分割效果,验证了Transformer在全局特征提取中的强大性能。与Swin类似,研究人员提出了另一种基于十字形窗口的Transformer结构,在限制计算复杂度的前提下进一步提升了性能。
近年来,研究人员尝试将Transformer引入CNN网络结构中用来提升网络的性能。MedT中将注意力机制融合到U形结构中用来实现医学图像分割。在医学图像分割领域,很多网络都是基于U形网络,但是使用简单的跳过连接方案来建模全局多尺度上下文仍然存在问题:
1) 由于编码器和解码器阶段的特征集不兼容,所以并非每个跳跃连接设置都有效,甚至一些跳跃会对分割性能产生负面影响。
2) 原始U-Net[8]在某些数据集上的表现比没有任何跳跃连接更差。UCTransNet[2]提出了一个新的分割模块,从通道的角度考虑注意力机制,用于引导融合的多尺度通道信息有效连接到解码器,在实验数据表现上也要明显优于U-Net。
3 CSwin-Unet
本文所提出的CSwin-Unet整体架构如图1所示。当前基于Transformer 的分割架构,例如Swin-Unet[3]等,都是基于U形结构将Transformer模块插入编码器和解码器,在我们所提出的方法中仍采用编码器和解码器的形式,但是取消了U形结构中的跳跃连接层,重新设计特征融合模块(CMT) 来代替,CMT通过融合来自Transofmer的全局多尺度特征和来自CNN的局部细节特征,从而实现更好的分割效果。
3.1 编码-解码结构
本文所提出的模型整体结构为编码-解码结构。首先,将输入图像x ∈ RH × W × 3 分别输入到CNN 和Transformer 模块进行编码。Transformer 模块中采用CSWin Transformer [5]结构,利用步长为4的7×7 的重叠卷积层将输入图像转化为H4× W4的token,并且每个token的维度都为C。整个Transformer编码器由三个阶段组成,在两个相邻的阶段之间使用卷积降低token的数量,同时增加通道的数量,每个阶段都是将token展开平铺并传入到输入为e ∈ Rd × Ci输出维度为Ci的线性嵌入层进行转换,然后再输入CSWin Transformer [5]块中来提取全局信息。CNN模块同样由三个阶段组成,每个阶段通过卷积池化操作来提取局部信息。解码器由CSWin Transformer块和上采样层组成,上采样层以2倍分辨率执行上采样,最后一个阶段以4倍分辨率进行上采样以恢复到输入分辨率。最后,将这些上采样特征输出为像素级分割结果。
3.2 CMT
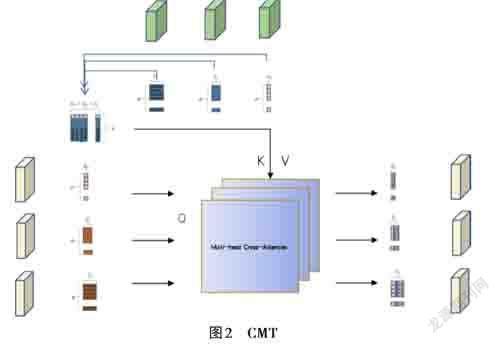
笔者提出了一个新的用来融合CNN和ViT 的融合模块(CMT) 。如图2所示,CMT通过对CNN 和ViT 进行交叉通道注意力计算来融合CNN和ViT所提取的局部和全局特征。
3.2.1 多尺度特征编码
3.2.2 注意力机制
如图2所示,将T ti ∈ Rd × Ci 作为query,TcΣ作为key 和value输入到通道注意力计算模块:
4 实验与结果分析
4.1 实验数据集
实验主要在前列腺数据集上进行,数据集包括153个病人,每个样本包含4个标签,标签器官分别为前列腺、肠和囊泡。
4.2 实验流程
本文主要以U-Net[8]、U-Net++[10]、Swin-Unet[3]、UC⁃ TransNet[2]和提出的CSWin-Unet进行对比。本文实验基于Python3.8 环境和PyTorch1.0 框架,使用2 块NVIDIA 3090 GPU进行训练和测试。所有实验的输入图像尺寸为224,batchsize为24,训练250个epoch,数据增强使用随机水平翻转和随机水平裁剪,优化器采用随机梯度下降并且动量设置为0.9。
4.3 实验结果
实现结果如表1 所示,采用特征融合模块的CSWin-Unet在DSC和HD系数的表现上都有很大的提升,在每个器官类别的分割DSC表现上都要优于传统算法。
5 总结
本文提出了基于Transformer的医学图像分割算法,通过对比和消融实验证明了本文所提出的算法在医学图像分割上比传统CNN分割算法有更好的效果。
