基于交互注意力机制的方面级多模态情感分析
2023-04-27范义飞张贯虹薛之芹
范义飞 张贯虹 薛之芹
关键词:方面级情感分析;多模态;双向长短期记忆网络;交互注意力机制
0 引言
方面级情感分析是情感分析的基本任务,旨在识别文本中特定方面的情感极性,其在商业、公共管理、社会保障等领域具有广泛的实际应用价值。先前方面级情感分析工作大多是面向文本的。随着互联网以及智能手机的不断普及,人们逐渐进入一个参与式的网络时代,由于手机往往是手头唯一的摄像机,因此网络上的文档(如商品评论、推文等)在性质上越来越具有多模态,即除了文本内容,还有图片。在图文融合方面级多模态情感分析任务中,图片信息往往和文本信息一样具有指示性,两者又可以相互加强和补充,共同传达用户生成内容的情感态度。在多模态数据中,文本和图像信息常与方面情绪联系密切。例如,对于拍照效果这一方面,用户可以发表一些用来描述拍照效果的积极词汇和高质量图片,来表达其对手机的拍照效果这一方面的满意,或是一些负面词汇和低质量图片样本(例如低光照片中的红色/紫色噪声)来表达其对拍照效果的不满。因此,与传统的基于文本或图像的单模态数据相比,多模态数据存在着各种的相关性,能够更加全面地揭示用户对某一方面的真实情感。
1 相关工作
目前,对于基于图文的方面级情感分析任务研究较少,Xu等人[1]提出了MIMN模型,该模型首先采用注意力机制获得基于方面词的文本表示和图片表示,然后通过多跳机制获得两个模态的交互表示。该工作首次将图像模态数据引入传统的基于文本的方面级情感分析任务中,填补了在方面层面和多模态情感分析任务交叉点上的研究空白。
2 模型概述
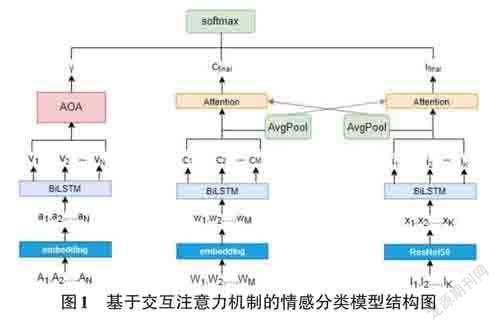
为了更好地捕捉方面词和上下文句子及各模态间的交互作用,本文采用基于交互注意力机制与AOA(Attention-Over-Attention)[2]神经网络相结合的方法来构建方面级多模态情感分析模型。本文提出模型的整体结构如图1所示。给定一个样本,假定多模态数据的输入包括文本内容T={W1,W2,...,WM}和一个图像集合I={I1,I2,...,IK},模型的目标是预测一个给定方面短语A={A1,A2,...,AN}的情感标签,其中L为文本上下文的长度,K为图片的数量,N为方面短语的长度。
2.1 特征提取
2.1.1 方面词特征提取
本文利用从百度百科语料库上预训练的word2vec[3]生成词向量,作为模型的输入。本文采用双向LSTM来获取方面词的上下文表示。
2.1.2 文本上下文特征提取
对于文本上下文特征提取,本文采用与方面词特征提取相同的方式,使用双向LSTM 来学习上下文信息。
2.1.3 图片特征提取
由于多模态数据中的图像通常是按顺序排列的,为了对这种普遍的图像序列信息进行建模,本文也采用双向LSTM模型。给定一个图像集I={I1,I2,...,IK},首先将它们的大小统一调整为224×224,然后将它们输入预训练的卷积神经网络ResNet50[4]中,并去除顶部的全连接层。
2.2 注意-过度注意网络AOA
为了更好地捕捉方面和文本上下文之间的交互,笔者引入AOA神经网络,其可以共同学习方面和文本的表示,并自动关注文本中的重要部分。具体来说,将方面上下文词表示V和文本上下文表示C作为输入传入AOA神经网络中,输出最终句子表示γ。
2.3 交互注意力机制
由于在融合了图文的多模态数据中,图片和文本往往具有一定的相关性,为了捕获这种相关性,本文采用交互注意力机制[5]将文本和图片进行交互式地建模。利用文本的隐藏状态和图片的隐藏状态的平均值来监督注意向量的生成,并采用注意力机制捕获文本和图片中的重要信息。通过这种设计,文本和图片可以交互式地生成它们的表示。
2.4 情感分类
最终将通过交互注意力机制得到的文本和图片表示与先前通过AOA神经网络得到的最终句子表示γ 进行拼接,并传入Softmax 层预测该方面的情感得分。
3 实验分析
3.1 数据集
本文选取从ZOL网站上爬取的手机领域基于方面的图文评论数据集Multi-ZOL进行实验。在Multi-ZOL数据集中一共有5 288条多模态评论。每一条多模态评论中包含一个文本内容,一个图像集以及至少一个但不超过6个方面。这6个方面分别是性价比、性能配置、电池续航、外观手感、拍照效果以及屏幕效果。整个数据集中有28 429个方面-评论样本对,对于每个方面,数据集的情感标注是一个从1到10的情感得分。训练集、验证集和测试集按照8:1:1的比例划分。
3.2 模型设置
本文利用word2vec中的skip-gram模型训练词向量,词向量的维度Dw设置为300,LSTM隐藏表示的维度Dh设置为100,图片输入的大小为224×224。本文利用预训练过的ResNet50模型去除顶部的全连接层,以提取2 048维的视觉特征向量。文本长度M设置为300,方面长度N设置为2,如果实际长度超过设定的长度,那么截断;反之,则补零。一条多模态评论中的图片的最大填充数K设置为5。
本文以模型在测试集上的准确率和f1值为评价指标。在模型训练过程中,使用Adam[6]优化算法来最小化交叉熵损失函数,学习率设置為0.001。训练的批处理大小为16,训练轮数设置为100。本文采用了早停机制,检测参数为验证集的F1值,当F1值连续10个训练轮数不上升时,则停止训练。本文所有模型的训练都是在GPU(NVIDIAGeforceGTX 1080) 上进行的。
3.3 基线模型
为了验证本文提出的多模态方面级情感分类模型的分类性能。将该模型与几种基线模型进行比较。实验中的对比模型如下:
1) MemNet[7]:MemNet 是一个用于方面级情感分类的深度记忆网络,它将方面嵌入作为查询向量,在由输入词嵌入叠加的记忆上使用多重注意力机制来生成深度记忆。将最后一层注意力层的输出传入Softmax 层用于方面级情感预测。
2) Co-Memory[8]+Aspect:是共记忆网络的一种变体。除了利用共记忆注意力机制去交互性地建模文本和视觉记忆的相互影响之外,它引入了方面嵌入的平均值作为文本和视觉记忆网络的输入。
3) MIMN:MIMN通过一种多交互式记忆网络来捕获多模态数据中的多重相关性来用于方面级情感分析,其中包括方面对文本和图像的影响,以及文本和图像两种模态数据之间的交互。
3.4 实验结果及分析
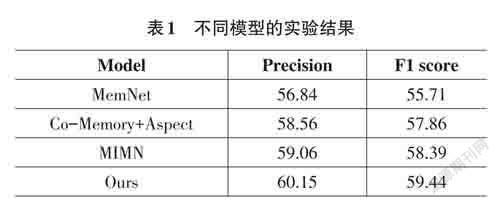
实验结果如表1所示,MemNet使用深度记忆网络有效地捕捉了上下文词的重要性,并且提取到了更深层次的注意力特征。但由于其仅融入了一个模态的数据,表现并没有其他模型突出。附加了方面嵌入的共记忆网络与MemNet模型类似,但是其引用了另一种模态数据,即图像,并充分考虑了文本和图像之间的交互作用,因而取得了比MemNet模型更好的效果。对于MIMN模型,由于其使用的多交互注意力机制不仅学习了跨模态数据引起的交互影响,还学习了单模态数据引起的自我影响。因此,它的性能优于上述所有基线方法。但是,MIMN模型并没有充分考虑到方面词和文本上下文之间的关联性,而本文提出的模型将AOA神经网络与交互注意力机制相结合,在捕捉到方面词和上下文之间的相关性的同时,也捕捉到了文本和图片两种模态数据之间的相关性。因此,本文提出的模型在所有的基线方法中获得了最好的性能。
4 总结与展望
针对当前对于方面级多模态情感分析的研究甚少,本文引入了一种基于交互注意力机制的图文方面级情感分析方法,并嵌入了AOA神经网络来更好地捕捉方面和上下文句子之間的交互作用。最终将AOA神经网络学习到的联合特征和通过双模态交互注意力机制得到的文本及图像特征进行拼接,经过一层全连接层送至Softmax进行情感分类。本文所提出的模型在真实数据集Multi-ZOL中进行了实证研究,并与不同的基线模型进行对比分析,实验结果表明,本文提出的模型具有一定的优势。
同时,本文也存在一些不足。本文对于模型的改进主要体现在对上下文和方面之间的融合策略上进行改进,对于不同模态表征之间的交互并没有进行过多研究。如何更好地捕捉不同模态间的关联和交互将是未来研究的重点。
