基于时空深度度量学习的单样本人体行为识别算法
2023-04-27李萱峰张奇
李萱峰 张奇
关键词:单样本行为识别;骨骼数据;度量学习;时空建模
0 引言
随着互联网技术的发展以及个人电子设备的普及,视频数据的规模增长迅速。如何合理利用视频样本理解人体行为具有重要的研究价值和广泛的应用需求。但是人体行为复杂多变,行为种类丰富多样,导致行为数据集制作困难,采用小样本学习方法识别不存在于训练数据集中的行为种类成为近期的研究热点。此外,由于人体的骨骼数据不易受背景、人体外貌等干扰因素的影响,且具有数据规模小、计算效率高等优点,因而备受国内外学者的关注。
本文针对人体骨骼数据的单样本行为识别问题,提出一种基于时空深度度量学习的方法识别不存在于训练集的行为类别。受到度量学习方法在单样本人脸识别、行人再识别等任务中成功应用的启发[1],一些用于行为识别的度量学习方法被提出[2-3]。然而,先前的方法具有许多局限性:(1) 先前的方法将骨骼数据变换成伪图像后采用传统卷积提取特征,丢失了关节点的空间几何结构信息;(2) 度量学习旨在缩小类内距离、扩大类间距离,但相同种类的行为实例也可能展示出不同的特征,盲目追求缩小相同种类样本之间的距离可能导致模型的泛化能力不足。针对上述问题,本文提出一种全新的时空深度度量学习(Spatial-Temporal Deep Metric Learning,ST-DML) 行为识别模型。本文的主要贡献有:(1) 首次将图卷积应用在基于深度度量学习的单样本行为识别中,以骨骼数据的原始拓扑结构作为输入,保留了人体骨骼的空间信息;(2) 行为识别是一种时空耦合问题,本文将获取嵌入向量的过程分为空间流和时间流,设计了一种时空度量学习模型,使得模型能够获得包含不同特征信息的子嵌入向量,提高模型的泛化性能。
1 问题描述
与预测类别标签的分类方法相比,度量学习方法的目标是学习一个嵌入函数,通过该嵌入函数,将输入数据转换到一个嵌入空间中,单样本行为识别问题就变成了嵌入空间中的最近邻搜索问题。单样本行为识别的步骤为:(1) 划分数据集,得到训练集、验证集、参考集;(2) 使用训练集训练网络;(3) 通过训练好的模型获得测试集和参考集的嵌入向量,计算嵌入向量之间的距离以确定测试集样本的行为种类。
设St = {(xmt,ymt ) }表示训练样本集合,其中xt 表示骨骼序列,yt 表示骨骼序列xt 对应的标签,且yt ∈ Yt,m ∈ M,Yt 表示训练集标签集合,M 表示训练集样本总个数。类似地,测试集定义为Se = {(xne,yne ) },ye ∈ Ye, n ∈ N,Yt ∩ Ye = ∅,N 表示测试集样本的总个数。参考集定义为Sa = {(xka,yka ) },k ∈ K,K 表示参考集样本的总个数,参考集中的样本个数和测试集的标签类别个数相同,其意义为从验证集的每个种类中抽取一个样本作为集合,即单样本行为识别的由来。
2 ST-DML
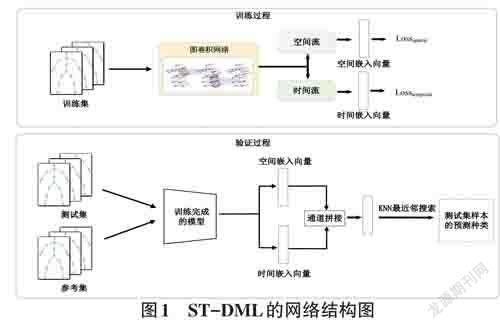
本文所提出的ST-DML网络结构如图1所示。訓练阶段,采用图卷积网络学习基本的骨骼特征表达,随后,通过空间流和时间流增强空间信息和时间信息。验证阶段,通过训练好的模型得到空间嵌入向量和时间嵌入向量,并根据嵌入向量进行最近邻搜索,获得行为种类标签。
2.1 特征提取网络
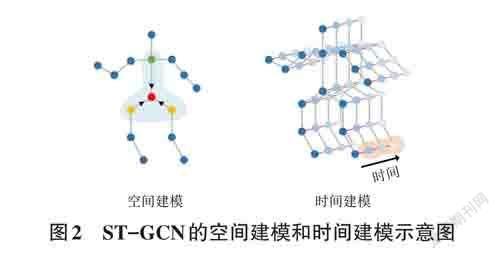
近期的研究表明,图卷积的方法明显优于卷积的方法[4],且图卷积方法在基于骨骼的行为识别中成为主流。文献[5]首次将图卷积技术应用在行为识别任务中,并提出一种时空图卷积网络(ST-GCN) ,本文以此为基础构建特征提取网络。ST-GCN采用一种空间建模和时间建模交替循环的方式学习骨骼数据的空间特征和时间特征。空间建模过程是离心点和近心点向根节点传递信息,可用公式(1) 表示。
其中,γout 表示输出特征图,χin 表示输入特征图。D 表示空间卷积核的大小,且D 的大小由空间配置分区策略决定,该分区策略将关节点的邻居节点分为三个子集,分别是根节点集合、向心节点集合、离心节点集合,因此D 设置为3。Aˉd 表示邻接矩阵Ad 的归一化, Wd 表示可学习的权重向量,∙表示Hadamard乘积,R是一个可学习的掩码矩阵,可以给关节点分配不同大小的权重。时间建模是将同一关节在时间维度上进行信息聚合,以此获得骨骼序列的时间特征。空间建模和时间建模的过程如图2所示。
2.2 空间流和时间流的设计
对于行为识别这类时空耦合问题,我们自然地将集成学习引入其中[6],提出一种时空集成学习方法,同时将行为特征嵌入时间域和空间域,迫使嵌入特征具有不同的特点。笔者在特征提取网络后设计了双流结构,空间流采用空间自注意力机制增强空间信息,时间流采用时间自注意力机制增强时间信息。
设计空间流的目的在于增强特征的空间表达能力,获得骨骼序列的空间嵌入向量,具体做法为:在每一帧内使用空间自注意力模块来提取嵌入在身体各关节之间的底层特征,以增强空间信息。假设在第t帧上的关节点vi 表示为vti,通过对关节点特征vti∈ RCin进行线性变换计算得到查询向量qti∈ Rdq,键向量为kti∈ Rdk,值向量为vti∈ Rdv,Cin、dq、dk、dv 分别表示关节特征的通道维度、查询向量的通道维度、键向量的通道维度、值向量的通道维度。首先,使用点积计算关节点vi 和vj 之间的权重wt ij = qt i∙ktjT,该值不仅用来表示两关节之间的关系强弱,而且将作为vtj 关节点的权重系数,为关节点vti 重新计算一个嵌入特征稳定性,lti将作为关节点vti 的新的嵌入表达,该嵌入表达起到了增强空间信息的作用。
2.3 深度度量学习
深度度量学习的目的是学习一个函数,将骨骼数据转换到一个嵌入空间中,在这个空间中,相似样本的嵌入向量之间的距离较近,而不相似样本的嵌入向量之间的距离较远。在训练期间使用三组损失监督学习过程,使相似样本间的距离更近,不相似样本的距离更远[7]。三元组损失可表示为:
其中SO 为锚样本,S↑为正样本,S↓为负样本,σ 为一个额外的距离边界。
3 实验
本文在大型行为识别数据集NTU-RGB+D 120 (NTU-120) 上做了充分的实验[8],评估了ST-DML的性能,提出的模型在PyTorch深度学习框架上实现,且所有实验都在GTX 3090 上进行,最大Epoch 设置为100,Batchsize设置为16。
3.1 数据集
NTU RGB+D 120数据集是应用最广泛的大型行为识别数据集之一,该数据集包括120个种类的行为,共计114480个视频样本。本文只采用该数据集的3D 骨架序列数据形式,该序列的每一帧由25个关节点的三维坐标组成。为了便于模型的训练,将所有骨骼序列的长度固定在300帧,序列长度不足300帧的用0值填充。所有实验均在100/20数据集分割方式下进行(训练集含100个种类,测试集含20个种类)。
3.2 实验分析
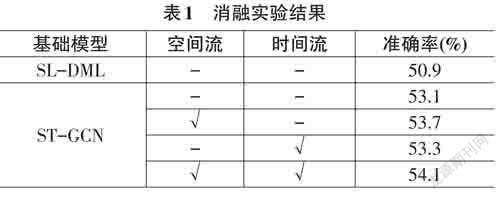
为了验证本文提出方法的有效性,笔者遵循SL- DML的参数设置,使用线性层代替图卷积网络的分类层,以获取大小为128嵌入向量。从表1中可以看到,笔者提出的使用ST-GCN构建特征提取网络的方法准确率达到53.1%,比使用传统卷积的SL-DML模型高出了2.2%,这表明图卷积方法在单样本行为识别任务中仍具有优越性能。此外,为了验证提出的双流结构的有效性,我们使用空间流和时间流的不同组合进行了四次实验。从表1可以看出,不添加空间流和时间流的方法准确率最低,当单独添加空间自注意力机制或时间自注意力机制时准确率均有提升。同时采用空间流和时间流时准确率达到了54.1%,这表明,我们提出的时空度量学习方法迫使模型学习到了辨别性的时空特征。
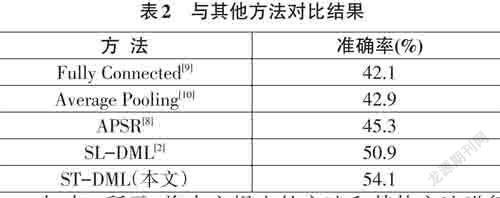
如表2所示,将本文提出的方法和其他方法进行对比,可以看出,本文提出的方法ST-DML优于现有的方法,比 SL-DML 高出 3.2%,这充分证明了 ST- DML具有学习人体骨骼时空信息的优越性能,且泛化能力比以往的模型有所提升。
4 结束语
本文提出一種用于单样本人体行为识别的时空深度度量学习模型。该模型首先采用图卷积方法学习基本人体特征表示,随后将图卷积网络学习到的特征分别送入空间流和时间流,以获取丰富的时间和空间子嵌入表达,提升模型的泛化能力。实验表明,本文提出的ST-DML优于现有的方法,并取得了54.1% 的准确率。
