基于深度学习的非合作目标感知研究进展*
2023-04-25何英姿张海博
何英姿,杜 航,张海博
(1.北京控制工程研究所·北京·100194;2.空间智能控制技术国防科技重点实验室·北京·100194)
0 引 言
近年来,由于近地航天器发射数目激增,在轨失效卫星和故障卫星逐渐增多,为应对这些问题,空间碎片清除和在轨服务等任务陆续被提出,其中包括萨里航天中心的Remove DEBRIS任务[1]、美国国防部高级研究计划局(Defense Advanced Research Projects Agency,DARPA)的凤凰计划[2]和美国航空航天局(National Aeronau-tics and Space Administration,NASA)的Restore-L任务[3]等。执行这些任务的关键是准确获取目标航天器相对于服务卫星的位置和姿态信息,然而,失效卫星、空间碎片等目标航天器是非合作的,没有已知的标记信息,并且无法向服务卫星提供有效的位姿信息。因此,要求服务卫星能够在无人参与的情况下估计和预测空间目标的相对位姿。为了实现自主姿态估计,需要从单个或一组图像中快速获取目标的相对位置和姿态,并且由于空间光照条件复杂、对比度低、明暗变化大,对算法的鲁棒性提出了更高的要求。
非合作目标感知的主要实现功能是针对非合作目标的识别与测量,根据目标航天器相对服务卫星的距离远近,可以划分出远距离辨识、目标航天器位姿测量、近距离目标航天器上结构部件识别与测量等具体任务。文献[4]对非合作航天器识别与姿态估计的不同方法进行了全面综述。目标航天器识别与姿态估计的经典方法通常先从2D图像中提取目标的人工设置特征,典型方法有Harris角点检测算法、Canny边缘检测算法以及通过Hough变换的线检测和尺度不变特征检测(Scale-Invariant Feature Transform,SIFT)。在成功提取所述特征后,采用迭代算法预测当存在异常值和未知特征情况下使某个误差最小化的最佳姿态解。这些关于位姿估计的算法往往依赖于提前获知目标位姿的先验信息,或者假设目标上存在已知特征标记。
近年来,随着卷积神经网络(Conventional Neural Network,CNN)的发展,基于深度学习的图像分类、识别算法在计算机视觉领域取得了重大突破。一方面,已有关于图像识别的R-CNN[5]、YOLO网络[6]及用于位姿估计的Pose-CNN[7]等,但这些地面图像处理算法所需的计算机算力很大,当算力受限时,识别精度将难以满足在轨服务任务要求以及直接应用于在轨情景的需求;另一方面,卫星在轨图像具有光照情况复杂、对比度低、分辨率低等特点,使用CNN的方法相较于传统方法,不依赖人工设置的辅助识别标识,鲁棒性更好。因此,研究空间非合作目标智能感知的深度学习算法具有很好的应用前景。
1 非合作目标发展现状
近年来,各国开展的在轨服务研究项目及其使用的空间相对测量系统如表1所示。现有非合作目标在轨服务项目涵盖广泛,包括对模型已知的非合作目标的视觉监测、辅助废弃卫星离轨、在轨组装、在轨维修和在轨加注等。
在轨任务一般分为4个阶段:远距离交会阶段(>300m);近距离交会阶段,又可进一步细分为接近阶段(300~15m)和最后进近阶段(15~1m);目标抓捕和维修阶段(<1m)。远距离交会阶段主要针对非合作航天器进行辨识,由于距离较远,给测量工作带来了较大难度;在近距离交会阶段,随着距离的接近,非合作航天器的外形特征逐渐清晰,可以识别出非合作航天器上的结构部件,进一步规划在轨任务,由于非合作航天器不具备合作特征,这一阶段的任务重点主要集中在通用特征的识别和动态测量;在目标抓捕和维修阶段,此时距离小于1m,相机由于视场问题无法拍摄到非合作目标航天器的完整图像,此阶段的难点是针对局部图像的特征识别与测量。
在轨任务的每个阶段根据服务卫星与目标卫星之间的距离不同,考虑到任务的工况要求和敏感器的特点,可以采用不同的空间相对测量系统获取故障卫星与服务卫星之间的相对状态信息,并以此设计不同的算法。通过对表1所列项目进行分析,归纳总结出任务阶段的划分以及各阶段使用的敏感器,如表2所示。
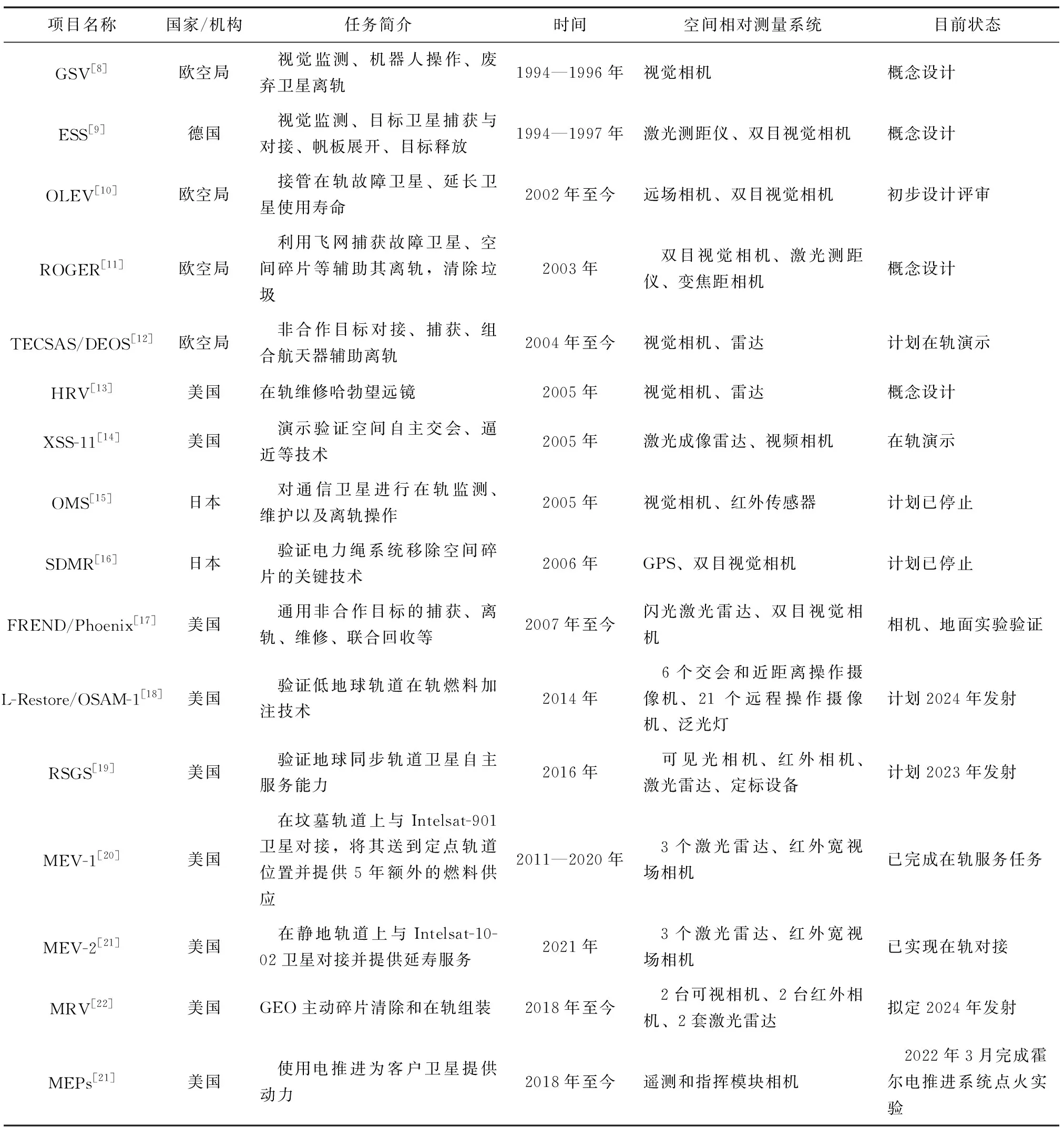
表1 非合作目标在轨服务研究项目汇总
从表2可以看出,最后接近距离操作分为2个阶段(15~5m,5~1m),由于相机视场(Field of View,FOV)的限制,使用了不同的敏感器。最后进近Ⅰ阶段(距离15~5m),一般选择单目相机和激光雷达(Light Detection and Ranging,LiDAR)作为相对姿态测量的敏感器。与激光雷达或雷达测距仪(Radio Detection and Ranging,RADAR)等其他主动传感器相比,使用基于视觉的光学敏感器(如单目相机、双目相机等)由于其质量和功率要求较小,在卫星上搭载更具优势。此外,单目相机因为构造相对简单,更适合在新型的小型航天器如立方体卫星上搭载。但是单目相机只能获取RGB图像,在极近距离(<1m)情景下,单目相机的视角无法拍摄到目标航天器整个场景的完整图像,通常需要采用几个相机共同工作的方式来获取所需的信息。通过几何计算,考虑到一定的余量,单目相机的视角应至少为80°,但是80°的视角会产生很大的镜头失真,这给准确提取特征点带来了困难。换言之,实际中的光学传感器无法在距离较近的情况下拍摄整个目标航天器结构。因此,在5~1m范围内的相对姿态测量是一项具有挑战性的任务,现有空间操作任务相关的非合作目标的识别与测量研究也主要集中在这一距离范围内。

表2 空间相对测量系统介绍
近年来,飞行时间(Time-of-Flight,ToF)测距成像相机在商用上得到普及。文献[23]论述了ToF相机在空间应用的可能性,其通过测量光在相机与物体表面之间的飞行时间来测量距离,通常的测量范围为0.3~7m。与单目相机相比,ToF相机可以提供深度信息;与双目视觉相机提供的稀疏深度信息相比,ToF相机可以提供稠密的深度数据;与激光传感器和LiDAR相比,ToF相机的体积小、功耗低。目前,针对宇航空间适用的ToF相机的研制正处于起步阶段[24-26]。
综上,ToF相机具有诸多优点,例如:结构紧凑,功耗低,对光照变化不敏感,可以直接提供深度信息,弥补近距离测量特征信息少的不足,算法相对简单,实时性强。因此,近年来的研究逐渐开始选择ToF相机作为基于深度学习的非合作目标感知光学敏感器。特别是在极近距离下(<1m),可为感知研究提供RGB图像与深度信息两种测量信息,弥补单目相机由于视角问题只能获取局部图像的不足。
2 空间非合作目标特征分析
空间非合作目标由于运动状态不可知,没有先验标识,所以在进行空间操作等任务过程中需要依赖识别非合作目标的几何形状。空间目标的光学特征是非合作目标识别与测量的基础,光学特性包括空间非合作目标的结构特征(几何形状结构)和非合作目标表面的光照特性[27]。
2.1 非合作目标结构特征
图1所示为几种典型结构的卫星,分别为(a)立方体卫星,例如实践五号卫星;(b)球形卫星,典型代表为我国在1970年4月24日成功发射的东方红一号卫星;(c)圆柱体卫星,典型代表为东方红二号卫星;(d)六棱柱卫星,典型代表为美国20世纪80年代发射的中继卫星系统[28](Tracking and Data Relay Satellite System,TDRSS)的中继卫星。从图1可以看出,卫星几何形状中比较常见的是矩形特征和圆形(椭圆形)特征,因此,通过对直线、矩形和椭圆结构的识别进行姿态测量是非合作目标感知的一个重要途径。

(a)立方体卫星:实践五号卫星
可供非合作目标感知的对象主要由以下三部分组成:
1)卫星本体。对于立方体卫星、圆柱体卫星和六棱柱卫星,可以通过识别其直线特征和矩形特征进行测量;对于球形卫星,可以通过识别圆形和椭圆进行测量。
2)太阳帆板及其支架。太阳帆板为卫星提供太阳能供电,通过支架安装在卫星本体上,一般为长方形,可以通过识别其直线特征和矩形特征进行测量;此外,也有特殊的三角形太阳帆板,可以通过三角形识别进行测量。
3)星箭对接环和发动机喷嘴。星箭对接环和发动机喷嘴都是圆环形,可以通过识别其圆面特征或者椭圆特征进行测量。
从非合作目标的主要组成部分可以看出,其主要形状特征为直线特征、矩形特征和圆形特征。
2.2 非合作目标表面光照特性
在在轨环境中,大部分非合作目标可能存在一定的旋转角速度或章动,这导致目标表面光照环境会发生明暗变化。此外,服务卫星上携带的光学传感器拍摄到的非合作目标所处背景也是变化的,有存在杂光的太空背景,也有地球等行星作为背景,还可能出现其他空间飞行器,并且当服务卫星对非合作目标进行在轨操作时,传感器视场内也会出现服务卫星所携带的机械臂或其他操作机构。
3 基于深度学习的非合作目标感知研究现状
基于深度学习的非合作目标感知研究内容主要分为非合作目标数据集构建、非合作目标识别算法与非合作目标位姿检测算法,其中非合作目标数据集是后续研究的基础。
3.1 非合作目标数据集构建
与智能驾驶、人脸识别等热门方向不同,空间非合作目标识别没有通用的数据集。非合作航天器图像的来源主要有三种:第一种是光学敏感器拍摄的在轨卫星图像,这类图像较为珍贵,数量稀少,一般研究人员难以获得;第二种是利用卫星等比、缩比模型在实验室环境下进行拍照,这种方法比较常见,但是如果数据集采样都是单一背景单一光照条件,训练出的模型鲁棒性较差;第三种是用图像处理软件如3DMAX、OPENGL等渲染生成非合作目标图像,得到非合作目标图像后,对数据库图像进行标注建立数据集。
卫星工具包(Satellite Tool Kit,STK)是美国Analytical Graphics公司开发的一款航天领域商业化分析软件,其中包含了国际空间站、北斗卫星、Artemis卫星等多种卫星的三维模型。文献[29]分别采用STK软件中的北斗卫星模型、Cartosat-2卫星模型与使用SolidWorks软件绘制的北斗卫星模型和Cartosat-2卫星模型采集图片,对非合作目标的卫星本体、太阳帆板、卫星天线、喷管、相机和星敏感器等结构组件进行标注。文献[30]采用STK软件中的北斗卫星、Artemis卫星、国际空间站、小行星探测飞船(Near-Earth Asteroid Rendezvous Spacecraft,NEAR)等92种卫星的外观图像,利用Labelme软件对卫星图像中的太阳帆板和卫星天线进行标注,最终得到1288张图像构成的数据集,数据集示例如图2所示。

图2 非合作目标数据集示例[30]Fig.2 Non-cooperative target dataset example[30]
文献[31-33]采用对非合作目标缩比模型进行拍照的方式采集图像,通过采集不同场景不同姿态的航天器模型图片来制作数据集。文献[34]介绍了斯坦福大学空间交会实验室(Space Rendezvous Laboratory,SLAB)使用C++软件OPENGL库在不同半径的航天器模型周围以球形模式拍摄仿真图像,生成500000张包含卫星姿态标签的数据集。文献[35]在文献[34]的基础上进一步完善,制作了航天器姿态估计数据集(Spacecraft Pose Estimation Dataset,SPEED),SPEED由两部分组成,第一部分是在MATLAB软件和C++软件上使用OPENGL绘制Tango卫星的图像,并以Himawari-8地球静止气象卫星拍摄的地球实际图像作为背景进行渲染,制作了15000张虚拟合成图像,如图3前两行所示;第二部分是使用交会光学导航实验台(Testbed for Rendezvous and Optical Navigation,TRON)摄像机拍摄的300张Tango卫星1∶1模型图像,如图3第三行所示。训练集由来自第一部分中的12000张合成图像组成,其余3000张合成图像和来自第二部分的300张实际相机拍摄图像作为2个单独的测试集。在后续研究中,文献[36-40]采用了SPEED。2021年,文献[41]在SPEED的基础上进一步完善,除了60000张用于训练的合成图像外,还增加了9531张TRON拍摄的航天器模型的半实物图像共同组成了SPEED+数据集,并且用于由SLAB和欧空局共同举办的第二次国际卫星姿态估计挑战赛中。

图3 SPEED示例[35]Fig.3 SPEED example[35]
文献[42]使用Blender软件包,导入开源的SpaceX飞船的Dragon卫星CAD模型,通过渲染模拟国际空间站上NASA的Raven敏感器组件所看到的在轨环境,其中考虑采用变化太阳角度、变化地球背景和增加敏感器随机噪声的方法来丰富数据集。文献[43]使用3DMAX软件建立了3种非合作目标模型,设置黑色背景和地球背景来模拟太空环境,并设置相机采集非合作目标图像,如图4所示。此外,文献[40]和文献[44-48]也采用了软件渲染的方式建立数据集,在软件中导入CAD模型进行渲染,使用软件包括3DMAX、3DSMAX、Gazebo、Unreal Engine 4及Blender等。文献[49]在不同数据集上验证了CNN的关键点检测性能,实验表明,通过添加随机灯光、变化材质纹理和改变图像背景,可以提高渲染数据集算法鲁棒性。文献[50]针对空间低照度情况下卫星图像成像质量差的问题,提出了一种基于生成对抗网络的图像增强方法。

图4 地球背景下不同航天器数据集[43]Fig.4 The multi class spacecrafts in earth background datasets[43]
3.2 非合作目标识别算法
基于深度学习的目标检测算法主要集中在2个方向:基于One-stage网络的识别算法和基于Two-stage网络的识别算法。基于One-stage网络的识别算法直接在网络中提取特征以预测物体的类别和位置;基于Two-stage网络的识别算法将整个过程分为两步,首先提取候选框(一个可能包含待检物体的预选框,英文名称proposal),然后再进行物体分类与检测框坐标回归。两种算法结构如图5所示。
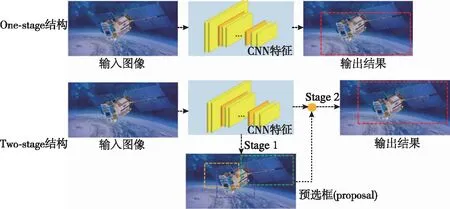
图5 One-stage和Two-stage算法结构Fig.5 One-stage and Two-stage algorithm structure
3.2.1 基于One-stage网络的识别算法
One-stage网络的典型代表是J.Redmon等在2015年提出的YOLO(You Only Look Once)网络[51],能够基于单个神经网络完成目标检测任务,YOLO的网络结构如图6所示。

图6 YOLO算法流程[51]Fig.6 YOLO algorithm flow[51]
YOLO将目标检测问题转化成一个回归问题。给定输入图像,直接在图像的多个位置上回归出目标的位置及其分类类别。YOLO是一个可以一次性预测多个目标位置和类别的CNN,能够实现端到端的目标检测和识别,其最大的优势就是速度快。事实上,目标检测的本质就是回归,因此一个实现回归功能的卷积网络并不需要复杂的设计过程。YOLO没有选择滑动窗口(silding window)或提取候选框(即可能存在物体的区域)的方式训练网络,而是直接选用整图训练模型。这样做的好处在于可以更好地区分目标和背景区域。 如图7所示,YOLO将原图划分为S×S个区域。如果一个物体的中心在某个区域,那么该区域就负责此物体的定位和识别。YOLO最大的优点在于速度快,能很好地满足实时性要求较高的任务。但YOLO方法也存在一些缺陷:1)受限于每个区域对于每个类只预测2个候选框,导致某个区域附近临近的小物体或物体集群无法被检测到;2)因为是在区域中直接预测回归框,因此当物体的长宽比比较特殊且训练中没有出现时,难以进行识别;3)提取的特征过于粗糙,因为经过了很多次降采样,不够精细。loss function对于同样大小的错误在大框和小框上的惩罚应该不同。这些缺陷导致利用其进行物体检测会带来对小物体细粒度检测效果差,以及定位不准的问题。
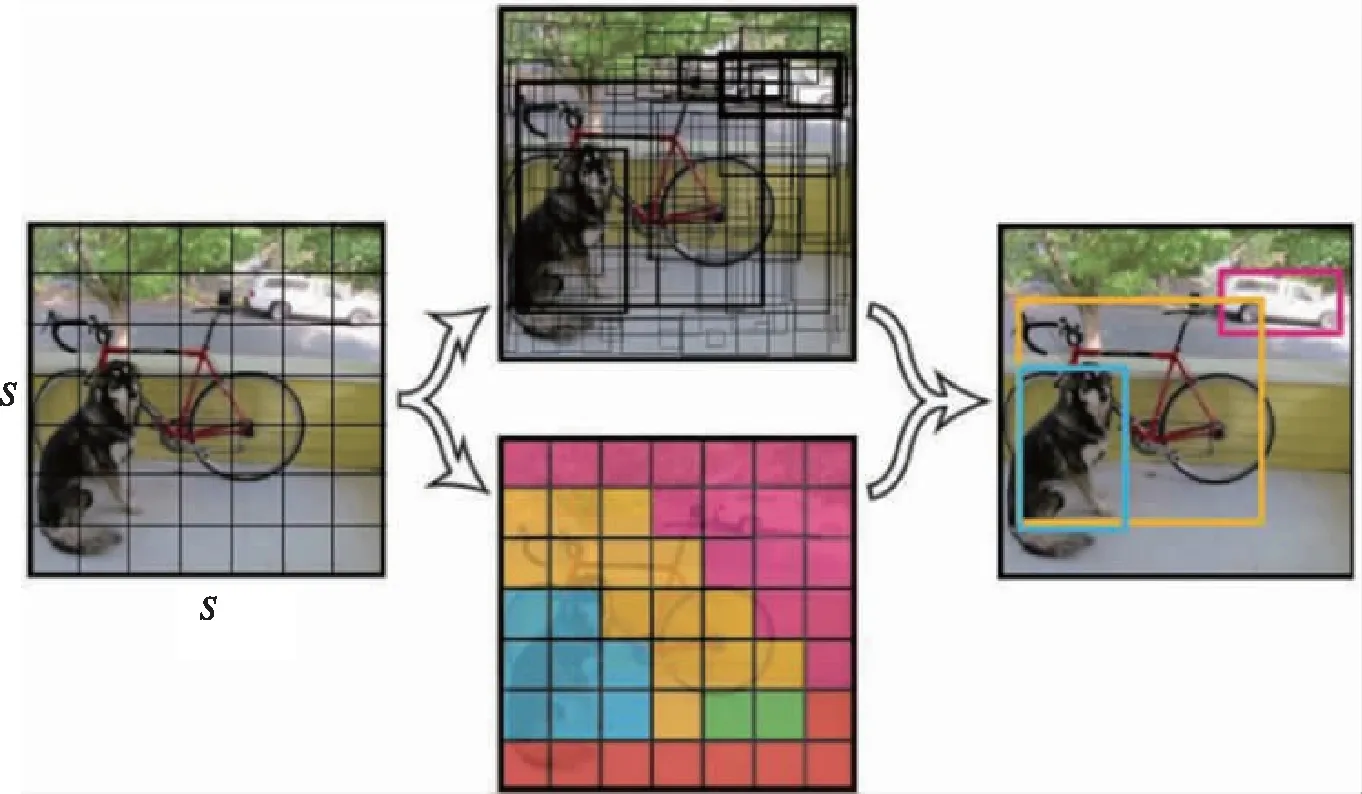
图7 YOLO进行目标检测Fig.7 Object detection by YOLO
现有文献研究多采用YOLO网络作为One-stage直接检测目标。文献[29]利用YOLO网络对非合作目标的卫星本体、太阳帆板、卫星天线、喷管、相机和星敏感器进行识别,识别准确率达到了90%以上。文献[36]提出了一种轻量化特征融合网络,即NCDN(Non-cooperative Detection Network)模型,以MobileNetV2为基础网络检测Tango卫星组件,包括GPS天线、FFRF天线和敏感器,在SPEED 上平均AP值(mean Average Precision,mAP)可达0.898。文献[37]采用YOLO网络检测非合作目标,然后利用Landmark回归网络在YOLO网络识别出的二维边界框中检测非合作目标角点。上述方法多在单幅图片上进行验证,难以满足在轨识别精度要求,且距离实时测量存在较大差距。
3.2.2 基于Two-stage网络的识别算法
基于Two-stage网络算法的核心是利用目标建议(Object Proposal)方法先提取候选框,再对候选框内区域进行分类和检测,即“候选框+分类” 的方法。2014年,加州大学伯克利分校的R.B. Girshick等提出了R-CNN算法[52],其算法结构也成为后续Two-stage的经典结构,R-CNN的算法流程如图8所示。通过选择性搜索(selective search)在原图中得到所有候选框,然后对这些区域依次提取特征,将得到的特征用支持向量机进行分类。

图8 R-CNN基本流程Fig.8 Basic process of R-CNN
虽然R-CNN算法相较于传统目标检测算法取得了50%的性能提升,但也存在很多缺陷:1)重复计算造成计算量大;2)训练测试不简洁,中间数据需要单独保存,耗费空间;3)速度慢:重复计算与串行训练的特点最终导致R-CNN速度很慢,GPU上处理一张图片需要十几秒,CPU上则需要更长时间;4)输入的图片必须强制缩放成固定大小,造成物体形变,导致检测性能下降。后续的Two-stage算法实际上都是针对这些缺陷进行改进,典型算法有SPP-Net、Fast R-CNN、Faster R-CNN、R-FCN和Mask R-CNN等[53-57]。
采用Two-stage网络的非合作目标识别算法主要基于现有网络进行设计。文献[58]在Mask R-CNN的基础上,融合ResNet-FPN结构、Dense Block和区域建议网络(Region Proposal Network,RPN)改进特征提取结构,对非合作目标的太阳帆板进行识别。文献[45]同样以Mask R-CNN框架为基础,使用Light-head R-CNN(头部轻量化CNN)取代Mask R-CNN的头部结构(作用是对划定区域的识别),提升了检测速度。文献[59]通过引入迁移学习的方法,利用COCO数据集进行预训练,设计改进的CenterMask网络检测卫星的太阳帆板和天线。文献[44]则以高分辨率目标检测网络HRNet为基础,首先在单目相机拍摄的图片中检测包含整个卫星轮廓的二维边界框,再根据检测到的二维边界框对原始图像进行裁剪,然后通过关键点回归网络输出卫星外轮廓关键角点。这种基于Two-stage网络的算法检测精度高于One-stage网络,但算法检测速度慢,难以满足实时测量的要求。
文献[47]和文献[60]对不同CNN间的性能差距进行了定量研究,其中,文献[47]对Inception-ResNet-V2网络和ResNet-101网络进行非合作目标检测对比,实验表明,Inception-ResNet-V2网络检测结果更为精确,但ResNet-101网络的训练时间可以节省50%以上,且处理过程比Inception-ResNet-V2网络快了4倍。文献[60]对比了Faster R-CNN和YOLO v3网络检测太阳帆板的效果,实验表明,Faster R-CNN检测准确度要高于YOLO v3网络,但处理时间为YOLO v3网络的2.5倍。目前,整体研究处于初步阶段,对CNN的定量研究较少。综上,对One-stage网络和Two-stage网络进行对比,如表3所示。
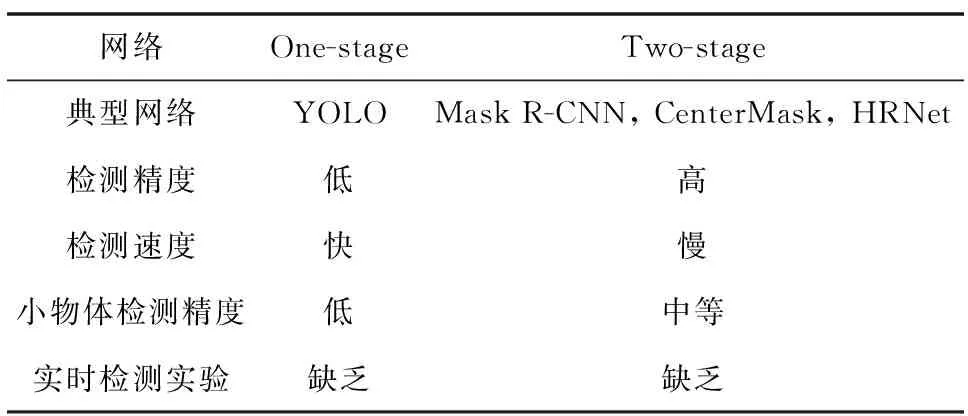
表3 One-stage网络和Two-stage网络对比
从上述文献可以看出,One-stage网络识别速度快,但算法精度低;Two-stage网络精度高、识别错误率低,但是检测速度慢,难以满足空间非合作目标检测的实时性需求。
3.3 非合作目标位姿检测算法
空间非合作目标的测量主要包括位置和姿态的实时测量,通过对非合作目标进行跟踪并获取目标表面特征,求解目标的运动状态,基于视觉的空间目标测量技术是在轨感知的一个研究热点。根据算法的不同,将现有基于深度学习的非合作目标测量研究分为间接测量方法和端到端测量方法。
3.3.1 间接测量方法
间接测量方法首先通过CNN识别出非合作目标的特征,如非合作目标结构部件关键角点、长宽比等,然后通过n点透视(Perspective-n-Point,PnP)算法和EPnP(Efficient Perspective-n-Point)算法等解算位姿。
文献[31]在YOLO网络的基础上,提出了YOLO-GhostECA 算法来检测非合作目标,再根据检测出非合作目标的长宽比来粗略估算位姿,该方法估计的位姿误差较大,无法满足实际在轨测量精度要求。文献[44]基于单目相机拍摄的图像,首先利用目标检测网络HRNet检测卫星,再利用关键点回归网络预测二维关键点坐标,并结合多视图三角剖分重建三维模型,最后采用非线性最小二乘法最小化2D-3D对应坐标,预测位置和姿态,该方法只在特定渲染图片上进行实验,距离连续测量动态目标具有较大差距。与文献[44]类似,文献[37]采用YOLO网络检测非合作目标,然后利用Landmark回归网络检测非合作目标角点,最后使用EPnP算法解算位姿。文献[40]采用SSD MobileNetV2网络检测卫星所在回归框,再利用改进后的MobilePose网络检测关键点,最后用EPnP算法解算位姿。文献[61]和文献[62]先使用CNN检测特征,再通过CEPPnP解算器和卡尔曼滤波估计位姿。这种基于2D-3D关键点对应的方式严重依赖于关键点识别的精度,由于空间光照条件变化复杂,传统关键点检测算法因鲁棒性差难以使用,而基于CNN的方法可以在一定程度上弥补传统方法的劣势,但这种先采用两级CNN识别非合作目标角点的方式对算力要求较高,处理时间长,难以满足在轨实时测量的要求。为解决实时动态测量问题,文献[63]提出了一种基于卷积位姿机网络的测量方法,通过设计卷积位姿机网络识别非合作目标关键点,再通过PnP算法解算位姿,并完成了实时物理实验,相对位置测量误差小于2mm。
除了通过PnP算法解算位姿外,文献[32]在通过VGG19网络识别卫星关键点后,采用搭建的双目相机系统解算位姿,但该方法存在关键点识别精度低、位姿解算算法误差大的问题,后续还需继续优化。文献[39]提出了LSPNet结构,它由3个互相连接的CNN组成,分别为位置CNN、定位CNN和方向CNN。其中位置CNN和定位CNN组成转化模块,由UNet和ResNet融合而成;转化模块连接到由ResNet修改成的方向CNN,输出实时位姿。但是上述研究仅在仿真图片上进行验证,缺乏物理实验来验证算法的泛化性,并且缺乏实时性指标论证。文献[64]使用PointNet++网络从点云数据中识别捕获区域,从而输出分割后的对接环位姿,并在V-rep仿真软件中进行了实验。这种通过深度学习处理点云数据的方法在非合作目标感知领域的研究较少,后续会是一个可以开发的方向。
此外,针对近距离(<1m)非合作目标测量,由于相机视角问题无法获得整体图像,文献[65]使用ToF相机实时采集RGB图像和深度图像,将RGB图像通过改进的BiseNet对非合作目标进行语义分割,提取卫星结构部件,再通过将RGB图像与深度图像相匹配的方法,获得对接环的位姿,确定抓捕点。该方法完成了地面物理实验,后续还需要在模拟太空光照条件下进行测试,对模型占用内存进行评估,为真正在轨应用提供支撑。
3.3.2 端到端测量方法
端到端测量方法主要通过CNN直接输出非合作目标的位姿,2018年开始有基于CNN的非合作目标端到端姿态估计研究成果发表。文献[46]在Google研发的Google Inception NetV3模型的基础上进行修改,输入是将渲染出的非合作目标模型图像处理为99×299 像素的单通道灰度图像,输出是一个1×3 的三轴位姿向量,并利用线性回归输出角速度向量值。
文献[34]在使用基于AlexNet的迁移学习将图像分类到正确的姿态标签后,在未经训练的PRISMA任务卫星图像上进行测试。该方法生成图像主要变化量来自4个自由度(3个自由度与姿态有关,1个自由度与相机视轴位置有关),误差大于10°。基于CNN的航天器姿态估计在文献[35]中得到了改进,在文献[34]的基础上,使用合成的PRISMA图像作为数据集,设计了离散标签之间的回归姿态估计算法,通过分类框架估计姿态,缓解了离散姿态标签的问题,同时仍然保持分类网络的鲁棒性,基于在实验室环境中创建的合成图像和真实图像的测试,该方法误差小于10°。
文献[42]沿用文献[34-35]的分类网络,通过设定特定级别的姿态标签离散化的方式,增强了算法的鲁棒性,并对实现姿态精度目标所需的训练集大小以及不同的在轨变量如何影响CNN精度进行了定量分析。文献[43]以ResNet-50为主干网络,将ResNet-50的最后一个全连接层改为3个全连接层分支输出位置、方向和类别,在一定姿态范围内的卫星仿真图片上进行了实验验证。文献[61]采用AlexNet和ResNet作为主干网络,将AlexNet末端的全连接层改为3个并联的全连接层以输出卫星的三轴位姿角,并设计了姿态分类损失函数和姿态回归损失函数进一步提高检测精度,实验结果表明,标准差均在0.9°以内。此方法的一个突破点是采用迁移学习的方法,利用ImageNet数据集进行预训练初始化网络参数,后续没有人工设计特征,实现了对非合作目标的端对端估计。文献[33]基于ResNet101设计了端到端检测网络,并与ResNet50、ResNet18和MobileNet_V2 进行对比,实验证明,ResNet101检测精度高,但网络大小和检测速度明显高于ResNet50、ResNet18和MobileNet_V2。文献[48]基于VGG19设计了两种CNN,分别为分支网络和并行网络,分支网络将一些特征位置信息直接连接到模型末端的全连接层,避免被最大池化层消除;并行网络将用于测量相对距离的VGG网络和用于测量卫星姿态的VGG网络并行连接。文献[66]基于修改后的GoogleLeNet检测Soyuz卫星渲染图片的位姿,输出为三轴位置和四元数。
由于应用于目标识别模型的低级特征对姿态估计具有通用的效果,因此可以基于迁移学习初始化前几层网络参数而构建CNN,避免产生过大的数据集模型。此外,与当前基于模型的姿态初始化方法相比,经过训练的深度学习网络可以快速识别姿态信息。然而,由于姿态分类标签是离散的,很难获得高精度的姿态测量结果,因此,后续的研究中可通过实验验证提供达到所需测量精度的训练数据量和标签离散化水平之间的定量结果。此外,虽然已知CNN算法在可变光照条件和复杂背景场景的测量中鲁棒性较好,但是在后续研究中完善空间操作各种光学条件下的定量方法对非合作目标检测仍然具有重要意义。
目前,针对非合作目标感知的深度学习网络轻量化研究较少,文献[36]设计了轻量化非合作目标组件检测网络,通过在MobileNet结构中对所有卷积层中的卷积核数量乘以缩小因子α(其中α∈(0,1]) 来压缩网络,在不过分降低网络整体检测精度的情况下优化卷积核参数冗余,压缩后模型存储空间仅为2.2Mbit,节省了约88%的空间。在采用25%计算量时,距离非合作目标15m内检测mAP>0.9,整体精度牺牲约为5%。
综上,对间接测量方法和端到端测量方法进行对比,如表4所示。间接测量方法的精度要高于端到端测量方法,但端到端测量方法检测速度快,未来研究将着重于以下三点:1)检测精度和检测速度的平衡;2)针对星载计算机进行算力的优化;3)针对非合作目标所处的在轨光照变化环境也要进行相应的实验验证。

表4 间接测量方法和端到端测量方法对比
4 关键问题与发展趋势
近年来,针对非合作目标感知的深度学习方法研究逐渐增多,但距离在轨应用还有一定差距。针对目前的研究现状,本文总结以下关键问题与发展趋势:
1)非合作目标数据集样本少:目前针对非合作目标建立的数据集的图片数据量少且种类单一,只针对特定卫星,但实际在轨卫星形状丰富,如立方体卫星、圆柱体卫星等。针对这一问题,一方面是采用UE4等更先进的渲染软件进行精细渲染仿真,同时综合考虑太阳光照变化、空间点光源线光源、噪声、空间机械臂遮挡、其他卫星背景干扰等多方面因素,建立包含更多种类、更丰富细节的空间非合作目标的数据集;另一方面是考虑引入区域随机化的概念,建立基于域随机化的非合作目标数据集,不依赖于模拟环境,而是通过随机化生成数据集增强算法泛化能力,这也是非合作目标数据集未来的研究方向之一。
2)基于小样本的CNN设计:在现有数据集并不完备的情况下,基于小样本的CNN设计也是一个方向。针对这一问题,可以采用:①基于生成对抗网络生成高质量的样本并实现数据增扩;②设计更具泛化能力的特征提取器;③采用迁移学习的方式,从其他图像分类与识别任务中挖掘判别信息,通过更改初始化网络参数的方式优化网络;④采用元学习方式学习一个具有较好泛化能力的图像到嵌入特征空间的映射,然后在嵌入特征空间中直接求解最近邻达到预测分类的目的。
3)近距离局部组件测量难:在服务卫星与非合作目标距离小于1m时,相机由于视场问题无法拍摄到非合作目标的完整图像,给基于局部组件的测量带来极大难度,目前基于深度学习针对这一部分的研究较少。为解决这一问题,一个思路是从传感器入手,以近年来视觉应用研究较多的ToF相机为一个研究方向[25],ToF相机通过红外激光发射器可以同时获得彩色RGB图像和深度图像,很好地弥补了近距离非合作目标局部部件测量光学信息少的问题;第二个思路是引入深度学习图像处理的分类学习方法,通过标注相机采集图片中的不完整部件进行学习训练,以规避传统图像检测方法对异形物体识别困难的问题。
4)高精度实时测量:不同于地面深度学习图像识别测量网络,空间情景对于非合作目标实时检测的精度要求更高,目前针对非合作目标测量研究的实时性评价数据较少。后续研究主要聚焦于实时性算法的完善与地面物理实验验证,提出通用的实时性指标要求。
5)轻量化网络设计:空间星载计算机由于算力有限,无法直接应用地面图像识别算法,现有测量算法的轻量化网络设计也是实现在轨应用的一个关键问题,目前针对空间非合作目标的应用研究处于初步阶段。相较于Two-Stage网络,One-Stage网络结构简单、更具有轻量化优势,在后续研究中可以通过融合多尺度特征、优化网络结构、减少模型参数量、减少最大池化、保留更多有用特征信息等方式对网络进行进一步优化。
5 结 论
近年来,随着深度学习技术的飞速发展,在图像识别领域取得了较大突破,这也给空间在轨测量提供了新思路。本文分析总结了近年来基于深度学习的空间非合作目标感知技术的国内外研究现状,从基于深度学习的非合作目标数据集、非合作目标识别、非合作目标位姿检测几个方面对国内外学者的相关研究进行了综合分析。通过深度CNN进行非合作目标测量可以弥补传统图像检测算法泛化能力差的缺点,通过学习训练的方式可以一次分类多种结构特征的非合作目标,通过端到端训练在输入非合作目标图像后可以直接测量出非合作目标的姿态。综合来看,深度学习算法对光的变化鲁棒性更强,具有很高的空间应用价值。目前,国内外针对采用深度学习的非合作目标智能感知技术研究均处于起步阶段,有必要对基于深度学习的非合作目标算法进行深入研究,完善实时性、准确性和轻量性这3个重要指标,进一步建立针对空间非合作目标的智能感知平台。
