基于民机维修文本数据的故障诊断方法
2023-04-19贾宝惠姜番王玉鑫王杜
贾宝惠,姜番,王玉鑫,*,王杜
1.中国民航大学 交通科学与工程学院,天津 300300
2.中国民航大学 航空工程学院,天津 300300
民用飞机在运营中,不可避免地会发生各类意外事故和系统故障,开展面向民用飞机故障诊断的研究工作,是确保民机安全运行和持续适航的重要前提。故障诊断的目标是当设备检测到故障,维修人员就需要根据具体情况以及相关手册判断故障原因,从而提出故障修复方案[1]。而人工排故会在一定程度上受人的主观因素影响并且浪费维修人员的时间成本。由于对飞机系统进行精准建模十分困难,目前学者们广泛应用基于数据驱动的方法,建立传统机器学习或深度学习模型挖掘数据中的信息,以进行故障诊断[2]。
目前大部分对复杂系统的故障诊断工作都是基于易于分析的结构化数据开展的[3],然而这样忽略了非结构化数据中蕴含的丰富的故障信息。在飞机日常运营中会积累大量的维修记录,以文本的形式保存在数据库中,包含了故障问题信息、故障检修方法及故障原因等关键特征[4]。目前这些维修文本数据由于自身的复杂性还未被充分利用,如果从这些数据中提取知识,能够辅助维修人员依据故障现象快速准确定位设备的故障位置及原因,大大降低了人工依赖度,有利于提高基于知识的故障诊断的自主化程度、可解释性和诊断精度[5],对进一步提升航空安全保障水平具有重要的意义[6]。
中文文本分析技术主要是从中文文本中抽取和挖掘高质量的、有价值的信息。文本分析技术最早起源于1958年,Luhn[7]选择了词频作为特征并融入了词语的位置分布的信息进行文本分析,开创了文本分析研究先河。经过众多学者的不断探索,文本分析出现了一些经典机器学习算法,如朴素贝叶斯[8]、支持向量机(Support Vector Machine,SVM)[9]等。直 到2012年,深 度 学习算法引起了学者们的广泛关注,它可以实现一种端到端的直接分析过程,避免了传统机器学习方法需要复杂的特征工程的问题[10]。Abedin 等[11]使用修改后的Basilisk 框架自动增加基础词典,生成的词典在支持向量机分类中用于识别事件原因。在Andrzejczak 等[12]研 究 中 也 使 用 了 根 据 词 典来识别事件原因的方法,但是该方法难以捕捉文档中存在的非常有用的潜在含义。Tulechki[13]将自然语言处理技术应用在与航空安全相关信息处理框架中,采用SVM 算法构造分类器来预测发生安全事件类别。Zhang 等[14]建立CNNLSTM-Attention 融合模型学习句子的语义和情感信息以及关系,实现对文本的情感分析。郑炜等[15]针对软件安全缺陷报告数量少、特征复杂等特点,采用TextCNN-Attention-TextRNN 模型实现对软件安全问题的预测。田园和马文[16]使用引入注意力机制的双向长短时记忆神经网络(Bidirectional Long Short-Term Memory,BiLSTM)对电网领域运行设备形成的故障日志进行故障识别。李新琴等[17]使用组合权重计算方法将BiGRU 和BiLSTM 的学习结果进行集成,实现对高速铁路信号道岔设备故障数据的分类。上述研究虽然在一些领域上逐渐实现了文本的自动分析,但仍存在以下问题:
1)基于民机维修文本数据的故障诊断还处于人工分析阶段,未实现智能诊断。
2)文本挖掘技术与专业领域知识结合较为困难,在预处理操作时由于专业词语较多很难使用分词技术做到词语的精确划分,这为语义特征的学习带来了难度。
3)当处理的数据量较大时,所建立的分析模型参数量较大,运行时占用内存多,因此导致了分析时间过长,处理速度慢等问题。
本文提出了一种修正迭代的基于BERTLightGBM 模型的飞机维修记录故障原因分析流程,实现飞机维修文本数据端到端的智能诊断,提升了维修文本的利用率及使用价值;相比于其他文本分析模型本文所提模型在民机维修文本故障原因分析中准确率较高;在诊断速度上有所优化,提升了方法的实用性。从而能够辅助维修人员依据故障现象快速准确定位设备的故障位置及原因,大大降低了人工依赖度。首先,结合维修案例文本的特点,对文本预处理、文本表示、特征提取模型和特征分类模型的构建做了具体研究;其次,不断增加飞机维修文本数据验证所提出的故障诊断流程的有效性,建立BERT 模型用于构建全局、双向的文本特征提取能力,解决民航维修领域文本分词困难、上下文信息相关性高的问题;并将LightGBM 作为分类器,以实现并行分析减小模型的参数数量,在降低模型复杂度,增强分析效率方面达到良好的效果,提升了方法在工程上的实用性;最后,对比其他分类方法,从准确率及诊断时间方面验证了使用BERT-LightGBM 模型进行民机维修文本故障原因分析的可行性和优越性。
1 民机维修记录文本特点
在民航运营过程中会产生大量的维修记录,维修人员在检查、维修过程中的信息以文本形式保存在故障数据库中,部分维修记录如表1 所示。通过分析大量的飞机维修记录,总结得出如下特点:

表1 维修记录Table 1 Maintenance records
1)长度短,数据量大。经分析飞机维修文本大多数在100 个字符以内,但是数量大。因此存在严重的数据稀疏的问题,对文本处理时形成了高维稀疏的特征空间。
2)文本数据结构不规范。不同书写人员习惯不同导致同一信息可能因为不同人员书写方式存在差异。
3)包含大量的专有名词缩写和代码。例如“刹车组件”会缩写成“刹组”,“发动机”会缩写成“发”。
针对以上特点,使用对短文本分析有较好的效果的BERT 模型进行分析,可以结合上下文进行区分同一词语在不同语句中的不同语义;引入多头自注意力机制可以克服在航空这种特定领域内专业词语较多,难以全部收录在领域词典里的问题;并且还可以解决维修记录口语化严重,难以使用传统分词技术进行语义理解的问题;融合LightGBM 模型能够充分捕捉特征与故障原因标签的关系,从而获得更准确的诊断结果。
2 模型基本理论
2.1 BERT 模型基本理论
基于预训练语言模型双向转换器编码表示(Bidirectional Encoder Representations from Transformers,BERT)[18]预训练模型是谷歌2018年提出的大型多任务语言模型,是一种基于多层双向Transformer 架构[19]的深度学习语言表示模型。其模型基本结构如图1 所示,其中EN为字向量编码表示,TN指输出向量。

图1 BERT 模型基本结构Fig.1 Basic structure of BERT model
BERT 预训练模型与经典的Word2Vec 词向量训练模型不同之处在于,Word2vec 只能表现词的独立语义信息,而BERT 模型不仅在Transformer 的Encoder 中引入多头注意力机制(Multi-head Self-Attention),并且创新性地提出了遮蔽语言模型(Mask Language Model,MLM)和下个句子预测任务(Next Sentence Prediction,NSP)[20],在模型训练时不断根据具体任务调节参数,使得其能更好地捕捉并融合全文语义。在实际预训练中NSP 任务和MLM 任务结合,让模型能够更准确地理解字、词、句子甚至全文的语义信息[21]。
1)遮蔽语言模型:MLM 任务是随机遮蔽每个句子中的15%的词语,用剩下的词语来预测被遮蔽的词。对于被遮蔽的词语,其80% 用[MSAK]代替,10% 用一个随机词代替,剩下10%的被遮蔽的词语保持原词不变。这样就使得当预测一个词语时,模型并不知道输入的是否为正确的词语,因此就会更多的依赖上下文的信息去预测词语,赋予了模型的一定的纠错能力。
2)下个句子预测任务:NSP 任务是从语料库中随机选择50%正确语对和50%错误语对进行训练,根据句子间的语义相关性,判断句子间的正确关系。
BERT 模型实现过程中有预训练和微调两部分:在预训练过程中通过动态调整模型参数,最小化损失,从而使得模型训练得到的特征能够尽可能地表征出语义的本质[22];在微调阶段,根据具体的任务实现对训练好的模型参数不断进行微调。因此BERT 模型不仅能够有效获取航空领域词汇的上下文信息,而且能够充分捕捉语义特征。
2.2 LightGBM 模型基本理论
轻量级梯度提升机(Light Gradient Boosting Machine, LightGBM)[23]是基于梯度提升决策树[24](Gradient Boosting Decision Tree,GBDT)的优化实现。它的原理与GBDT 相似,是将损失函数的负梯度作为当前决策树的残差近似值,去拟合新的决策树,使预测值不断逼近真实值[25]。
相比于传统的GBDT,LightGBM 算法中融合了基于梯度的单边采样(Gradient-based One-Side Sampling,GOSS)和互斥特征捆绑(Exclusive Feature Bundling,EFB)2 种方法,可以减少信息丢失同时节省内存占用加快运行速度,解决了传统提升算法在样本数据量较大的环境下非常耗时的问题,能够有效提高模型的准确率和鲁棒性。因此本文使用LightGBM 模型实现对所提取的语义特征进行分类。
3 故障诊断流程设计
本文基于民机历史维修数据,提出了一种基于BERT-LightGBM 模型的反复迭代的故障诊断流程,诊断模型建立过程如图2 所示,分为4 个步骤。

图2 民机维修文本故障诊断模型建立流程Fig.2 Process of establishing fault diagnosis model for civil aircraft maintenance texts
步骤1构建故障数据库和故障原因数据库
由于已有的维修记录缺少故障原因,因此首先需要将民机原始维修文本根据专家知识及人工经验人工标注故障原因,并将现有的民机维修记录整理到故障案例数据库和故障原因数据库中。
步骤2故障文本预处理
由于民机维修记录是由维修和检查人员手工记录的,会存在一定的不规范。因此在输入故障诊断模型前,需要将其进行处理使模型更好地提取语义特征。
步骤3故障诊断模型的建立
使用现有的维修记录对所建的BERTLightGBM 故障诊断模型进行训练,在测试时对预测结果错误的记录进行原因修正,形成正确的故障原因;并对未标明故障原因的维修数据做出故障原因的预测。
步骤4故障案例数据库和故障原因数据库的更新
将专家修正过的诊断结果更新到故障案例数据库及故障原因数据库中,使用不断积累更新的数据库进行故障诊断模型的训练,提高故障诊断结果的准确率。
在实际应用过程中,将故障数据预处理环节与所建立的BERT-LightGBM 故障诊断模型进行集成,维修人员仅需把初始的维修记录输入到集成模型中,即可得到故障诊断结果,以辅助维修人员做出正确的维修决策,有效提高模型的工程实用性。
4 基于维修记录的民机故障诊断模型
本文提出的基于BERT-LightGBM 维修文本故障诊断模型主要包括两部分:首先,建立基于BERT 模型实现维修文本数据的向量表示及其特征提取;其次,将BERT 模型所提取的文本特征及其对应的故障原因同时输入到所建立的LightGBM 模型中,以实现特征的分类。故障诊断模型框架如图3 所示。

图3 BERT-LightGBM 模型框架Fig.3 BERT-LightgGBM model framework
由于飞机维修文本数据量较大,传统的BERT 模型在文本分类中有着较好的实验结果,但消耗资源较大、所需时间较长,在实际工程应用较少。因此本文将BERT 和LightGBM 进行融合,在BERT 模型充分提取全文语义特征的同时,利用LightGBM 可以节省内存并加快运行速度的优点,解决传统BERT 模型在大样本环境下非常耗时的问题,并且在一定程度上提高了故障诊断准确,增强了传统BERT 模型在工程应用中的实用性。
4.1 输入的向量表示
由于文本无法直接被模型识别计算,因此首先需要将其进行向量化表示。对维修文本进行以字为单位的分割,但由于维修文本长度不等,而BERT 采用固定长度序列输入,因此需要首先设定一个最大句子长度的超参数,句子根据其设定进行长截短补。同时为了更好地融合全文语义,将字向量(Token embedding)和句向量(Segment embedding)融合为语义向量,得到向量表示E:
式中:E表示维修文本的融合语义向量;T表示维修文本的字向量;S表示维修文本的句向量。其中,字向量表示每个字的语义信息,句向量用于区分不同的句子。加入CLS 向量表示整篇文本的语义,可以用于之后的分类任务;加入SEP 向量句末分割符,用于将2 个句子分割开。
为了使模型可以捕捉顺序序列,无论句子结构如何变化,该模型都会得到类似的结果。因此在输入特征提取模型前引入位置信息的特征即位置向量(Position Embedding),使得不同位置的字向量有差异,并且这种差异蕴含某种关系,可以从一个位置推断出另外一个位置。编码公式为
式中:PE 是位置编码结果;pos 是字在句子中的位置;i是指编码中每个值的索引,即下标,i=1,2,…,n;dmodel是编码的维度。
最终,BERT 模型的输入的向量为
在预训练阶段,Transformer 模型对输入向量进行训练。其中,CLS 放在句子的首位,经过Transformer 模型中多头注意力机制来获取句子级别的信息表示得到的整句的表征向量,可用于后续的分类任务。
图4 为在做分类任务时输入的向量表示示例,当输入“发现3 号主轮磨平”,将每个字分割得到每个字的字向量、句向量及位置向量,并在句首形成CLS 向量,且由于输入只有一个句子,因此只有一个SEP 句末分隔符。
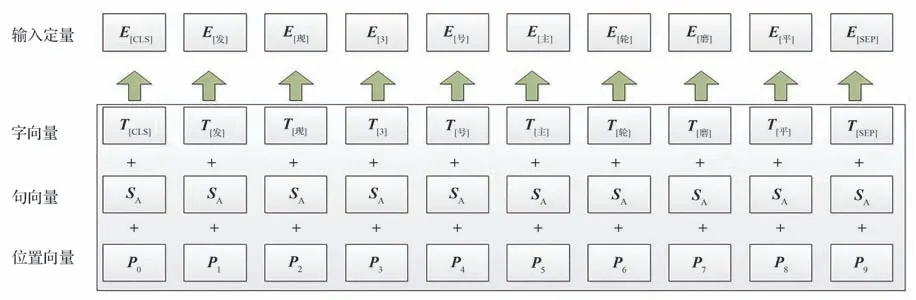
图4 输入的向量表示示例Fig.4 Examples of vector representations of inputs
4.2 民机维修文本的特征提取
在民机维修记录文本中,包含大量的特定领域词汇,为了使模型充分捕捉融合上下文的双向语义、更加关注于重点词汇,因此在模型中引入了12 个双向Transformer 编码层,即隐藏层,用以对文本进行特征提取,Transformer 的编码器也是预训练模型的核心部分,其编码层内部结构如图5 所示。
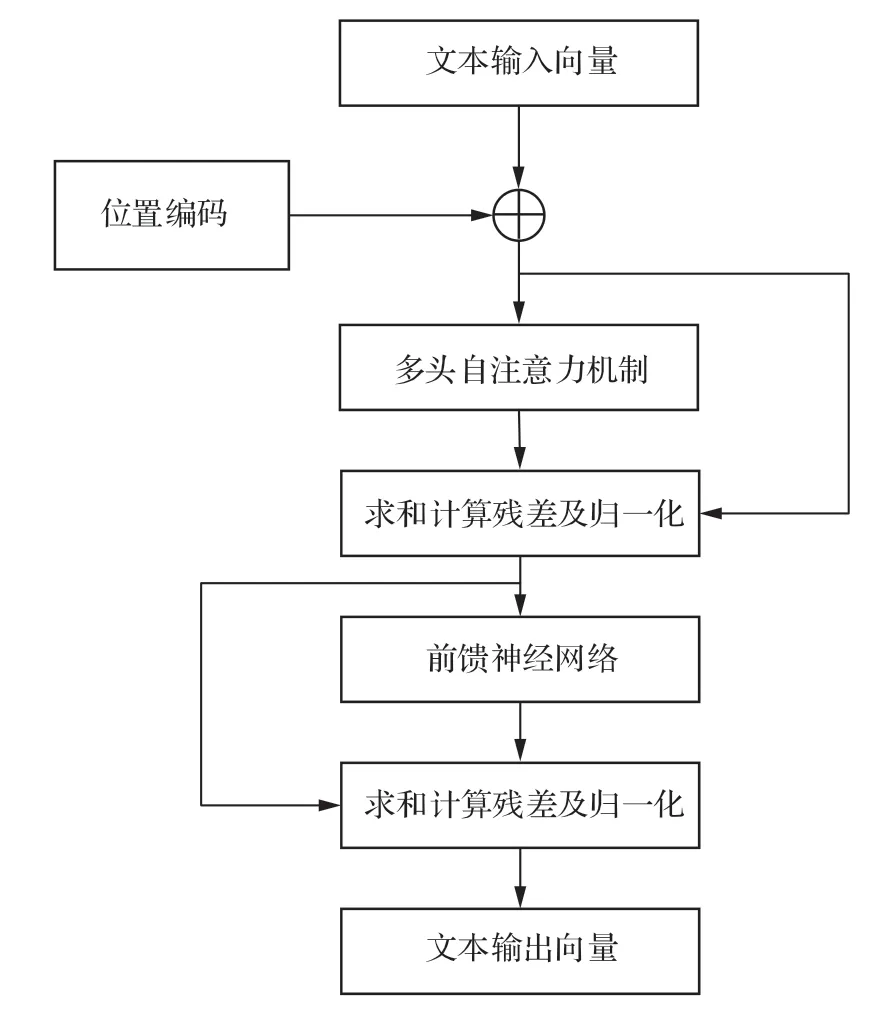
图5 Transformer 编码层内部结构Fig.5 Internal structure of Transformer encode layer
1)本文采用Multi-head Self-Attention 机制进行特征提取:编码向量分别与多个随机初始化的矩阵(分别设为,其 中维度相同)相乘计算出多个新的矩阵Qi、Ki、Vi由于多头注意力可以在不同的空间中学习到相关信息,使模型更加关注重点词汇,但不同的注意力头之间捕捉的信息存在冗余,因此头数过多不仅会增加模型参数量,准确率可能也有所降低。因此经过查找相关文献,本文将向量X分别输入到8 个自注意力机制中,再把输出拼接得到最终的注意力向量。
计算公式为
计算每个注意力机制Attention 矩阵,计算出其他字对于该字的一个分数值Si,即为每个词对于当前位置的词的相关性大小:
式中:Dk表示向量Ki的维度。
使用softmax 函数进行归一化,计算注意力概率:
之后对注意力概率进行随机失活:
得到注意力权重:
把每一个自注意力机制的输出向量串连拼接起来,得到最终的输出向量R:
2)加和及归一化层:首先使用残差网络解决梯度消失问题,并对不同的输出相加;其次进行层归一化,计算公式为
式中:LN 为层归一化后的结果;m为向量的编码维度;n表示加和后第n个位置的字向量;μj=β=(β1,β2,…,βn) 和γ=(γ1,γ2,…,γn) 为 待 定向量。
3)使用全连接层进行前馈神经网络的前向计算,并接一层加和及归一化层,其输出综合了上下文特征的各个词的向量表示,以防止梯度消失;最后使用Gelu 激活函数进行非线性映射。
在模型训练的时候,执行MLM 和NSP 任务让模型尽力去理解上下文关系。预训练好的BERT 模型中每个词都充分融合了上下文信息,CLS 位置包含了句子关系信息。
4.3 模型的输出
在最后一层编码层之后,经池化层和tanh 激励函数做一定的变换,将CLS 标记对应的整句向量表示hi取出来,作为整个序列的表示并返回。模型输出则是输入各字对应的融合全文语义信息后的向量表示,降低矩阵的维度,增加了模型的泛化能力。最终输出特征为
式中:mi为输入序列X的最终特征;W1和W2是权重矩阵;hi是池化层的输入;σ是tanh 激活函数。
4.4 模型参数量优化
BERT 模型在训练过程中会产生O(L×H)个参数,其中L表示词表矩阵维度;H表示隐藏层参数矩阵维度;当数据量较大时,模型参数量多,占用内存较大,训练速度缓慢。为了加快训练速度,在减少参数量做了如下操作[26]:
1)嵌入层参数因式分解。不将独热编码向量直接映射到隐藏层,而是将一个高维词嵌入矩阵分解成2 个低维词嵌入矩阵,即产生的参数个数为O(L×E+E×H),其中E表示嵌入矩阵,当E远小于H时参数量减小的很明显。
2)在不同层的Transformer 编码器之间共享多头自注意力机制以及前馈神经网络中部分参数。
4.5 民机维修文本特征分类
在下游微调任务中,针对本文提出的民机维修文本的故障原因分析问题,是一个多分类的问题。将预训练学习到的语法语义知识迁移到下游任务,利用训练得到网络参数,初始化网络并对其进行微调,将分类操作转移到预训练字向量中,并在BERT 模型的输出端接上分类器,以实现故障原因的分类。
本文使用LightGBM 模型实现语义特征的分类,它是基于梯度提升决策树的优化算法。将BERT 模型提取的维修文本特征以及故障原因标签作为该模型的输入。在训练过程中根据梯度差异计算不同叶子节点不同的权重,以对应于类别的得分,输出得分最高的类别。相较于softmax 分类器,LightGBM 模型可以实现并行学习并且更加充分地学习数据与标签之间的真实联系,利用数据特征拟合,以达到更加高效的分类效果。
LightGBM 算法输入的训练数据集为{(m1,y1),(m2,y2),…,(mn,yn)},其 中mi(i=1,2,…,n)是提取的维修本文的特征向量,yi是对应的故障原因。在模型训练添加决策树时第t步的损失表示形式如式(16),每轮迭代的目标为找到一个弱学习器ht(m),使得本轮损失函数L(y,ft(m))最小。
式中:ft-1(m)为上一轮强学习器学习的结果。
计算第t轮第i个样本的损失函数的负梯度:
每次训练迭代学习rti来拟合残差。
利用mi和rti进行决策树最优节点分裂拟合第k棵回归树。对于所有叶子节点中的数据样本,计算出使得损失函数最小的输出值cti:
从而得到ht(m):
式中:Rtj(j=1,2,…,J)表示第t棵回归树的J个叶子节点的区间;I为示性函数。
则强学习器表示为
由于决策树在计算分割节点的信息增益时会对每个特征遍历所有数据点,为了快速找到一个最优特征分割点作为叶子节点,使得在分割之后整棵树的增益值最大,在上述步骤中融合了GOSS 和EFB2 种 方 法。
1)GOSS 使用梯度作为样本权重,本文在采样时重点关注梯度较大的特征,对于梯度小的特征进行进一步学习。之后遍历样本并计算信息增益,信息增益越大,样本梯度就越大,即特征重要度就越高。在节点d上特征j的信息增益计算公式为[27]
式中:n为使用样本总数;gi为损失;Hl、Hr、Bl和Br为集合H和B划分在节点d左边(下标l)、右边(下 标r)的 特 征 集 合,njl和njr分 别 为Hl∪Bl和Hr∪Br的集合个数;按梯度对特征进行排序,选取前a%个特征形成集合H,从剩下的小梯度特征中选取b%个特征形成集合为小梯度特征的采样权重。
2)EFB 使用直方图算法将特征空间中相互独立的特征进行合并来减少特征的数量,当特征以独热编码的形式表示时,特征之间是不完全互斥的,因此设置冲突比对不互斥程度进行衡量,当冲突比较小时进行特征合并,此时合并特征不会丢失信息,并且形成了低维特征空间[28]。从而既降低内存占用以及时间复杂度,并且防止了过拟合的问题。
5 实验分析
5.1 实验数据
本文所采用的数据集来自某航空公司某型号飞机的历史维修记录,该数据集包含了33 562条维修记录,其中22 000 条作为训练集,4 781 条作为验证集,4 781 条作为测试集。实验环境为:操作系统Windows10、处理器Intel(R) Xeon(R) Gold 6226R CPU @2.90GHz、Python3.6、Tensorflow1.14。由于原始训练数据集缺少故障原因,因此首先需要根据经验对其故障原因进行诊断标注。故障原因及其数量如图6 所示,将故障原因分为111 类。维修记录中主要包括机型、机号、发生日期、ATA 章节、故障描述、故障处理及故障原因等信息,其中机型、机号、发生日期等信息与故障原因的诊断相关性不大,因此为了降低数据的维度本文把这几列删除。表2 为标注故障原因后的某航空公司飞机部分维修记录。表中故障原因则为本文分析预测的目标,它主要通过使用本文所用方法对故障描述及故障处理两列进行分析获得。

表2 标注后的某航空公司飞机维修记录(部分)Table 2 Aircraft maintenance records of an airline after marking (part)
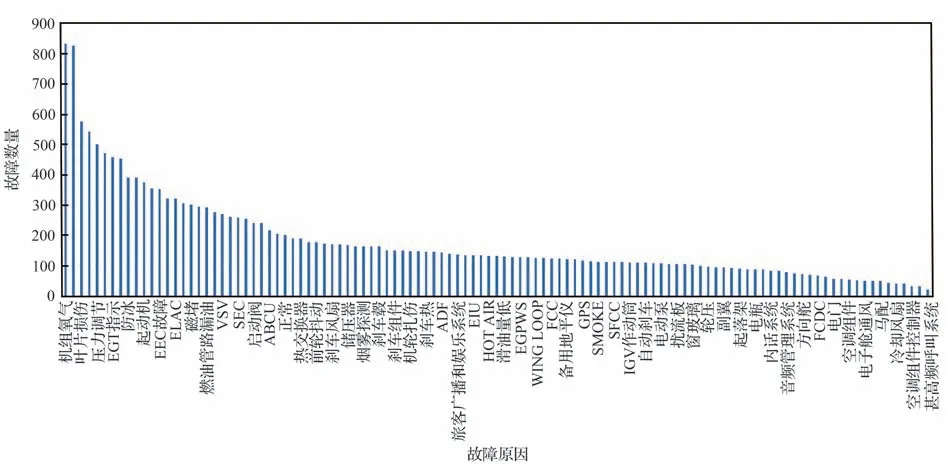
图6 故障原因及数量Fig.6 Causes and numbers of faults
5.2 文本数据预处理
由于维修文本的表述与故障映射存在一定关系,对故障位置及原因表述明确的维修文本数据,可直接使用文本中的关键字和词与故障案例数据库进行比对匹配从而实现故障判定和维修决策的生成,使故障原因判别更为直接。如:“3#主轮见线,更换主轮后测试正常”,可通过数据库匹配直接诊断为:“机轮磨损、见线”,以减少资源的占用。
针对存在歧义及表述具有不确定性的维修文本,如:“空中巡航时垂直导航指引消失,自动驾驶B 脱开.几十分钟后,PFD 上速度带出现黄色SPD LIMIT 标志.”,可根据前文总结的民机维修文本的特点首先文本进行预处理操作,将其整理为规范文本,用其进行模型的训练及测试,以提升模型对有用信息的关注能力,主要进行的处理如下:
1)文本整合
在进行飞机维修文本故障原因分析时,主要使用维修记录中故障描述及故障处理两列,因此本文将这两列数据合并成一列,以便进行后续整体分析。
2)文本随机化
在构建维修文本数据集时,如果按类别进行数据的存储,在模型训练在过程中的一段时间内会只关注某一类别的数据,可能会造成模型过拟合,泛化能力很差,因此本文将维修文本乱序输入。
3)文本清洗
由于民机维修文本是由维修检查人员人工进行记录,常常会存在记录不规范的问题。为了使模型更加关注于字词本身和语句,因此对文本进行清洗操作。主要包括去除文本中特殊的符号,如:“()”“!”“…”等符号,去除多余的空格及中英文符号统一等步骤。
4)停用词过滤
在人工描述的维修文本中通常会存在“的”“并且”“和”等出现频率高但是却无实际含义的词,去除这些词可以在一定程度上降低文本的特征维度。预处理后的结果如表3 所示。

表3 部分飞机维修文本预处理结果Table 3 Partial results of aircraft maintenance text preprocessing results
5.3 实验结果分析
将测试集数据输入到用训练集训练好的预训练模型中,得到最终分类结果如表4 所示,其中故障原因这一列为诊断模型输出结果。为了验证提出的不断修正的故障诊断流程可以提高故障诊断结果的准确率,逐渐递增历史维修记录并将其输入到 BERT-LightGBM 模型中,采用准确率(Accuracy)、精确度(Precision)、召回率(Recall)及 F1 值作为评价指标,观察模型输出评价指标的变化情况,最终实验情况如图7 所示。

表4 故障诊断结果Table 4 Fault diagnosis results
由图7 中的数据可以明显观察到,当故障样本较少时,可能会使模型欠拟合模型准确率很低;随着故障样本迭代式地增多,准确率不断增长,直至维修文本数据量达到20 000 时,准确率达到最大值98.93%,精确度、召回率和 F1 值也达到了较高的值,分别达到了99.98%、99.98%、99.98%。由此可以说明,所建立的故障诊断模型的准确率随着维修记录数据库中故障样本的增加而提高,但当维修文本达到一定数量时,若继续增加样本数量准确率基本保持不变,并且还可能会造成计算资源的浪费,因此本文选用数据量为20 000 的维修文本数据进行后续研究。
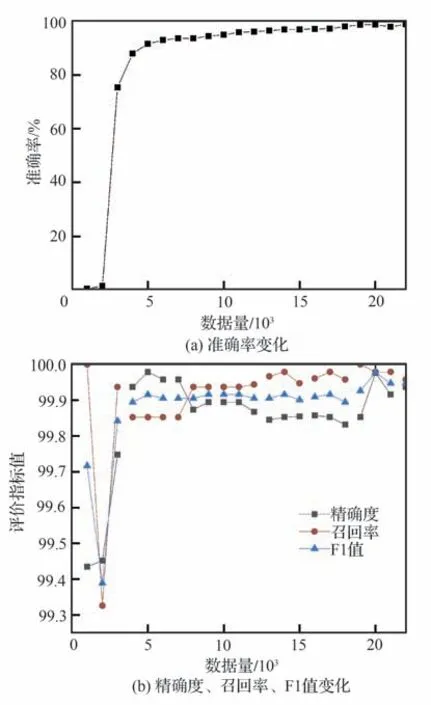
图7 迭代训练结果Fig.7 Iterative training results
基于BERT-LightGBM 的故障诊断模型在训练时,选择的批处理大小(Batch Size)即一次训练所选取的样本数和遍历次数(Epoch)都会影响故障诊断的准确率。因此不断调整这2 个参数以实现最优的准确率,实验结果如图8所示。
由图8 可知,在Batch Size 相同时,准确率随着遍历次数的增大而增大;由于在遍历次数相同时,Batch Size=16 时准确率最大。当Batch Size=8时,由于模型欠拟合导致模型的准确率无法随着遍历次数的增大而持续升高;当Batch Size=32时,由于一次训练所选取的样本数过大,可能会导致模型过拟合,使其在局部形成最优值,因此无法得到最优的准确率。因此本文选择Epoch=5,Batch Size=16 进行后续研究。

图8 不同Epoch 和Batch Size 的准确率Fig.8 Accuracy of different Epochs and Batch Sizes
为了研究本文所提出的基于BERTLightGBM 方法在民机维修文本故障原因分析的有效性和优越性,选择了文本分类常用模型TextCNN、LSTM 以及BiLSTM 作为对照实验。基于BERT-LightGBM 模型的训练参数如表5所示。BERT-LightGBM 模型训练损失如图9 所示。由图9 可知,BERT-LightGBM 模型在迭代超过4 500 轮后,训练集上的损失波动幅度变小,逐渐趋于稳定,训练集的准确率基本保持不变,说明模型训练拟合效果已达最优。
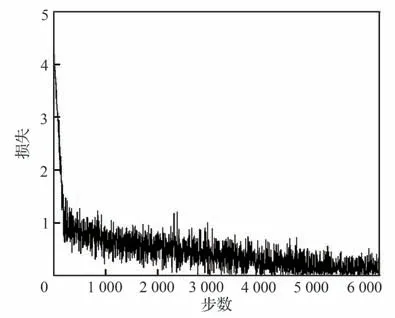
图9 BERT-LightGBM 模型训练损失Fig.9 BERT-LightGBM model training loss
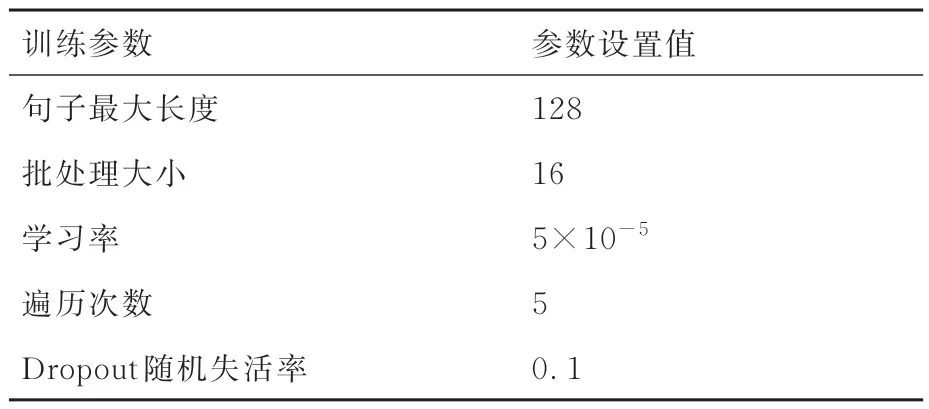
表5 BERT-LightGBM 模型训练参数Table 5 BERT-LightGBM model training parameters
几种文本分类模型的对比实验结果如表6 所示。BERT-LightGBM 模型(隐藏层维度为768)最后在测试集上进行10 次测试实验,取其平均值作为模型在测试集上的平均准确率,约为 98.03%,相较于本文的所采用的对比模型TextCNN 准确率提高了38.99%,比LSTM 模型(隐藏层维度为768)准确率提高了22.98%,比BiLSTM 模型(隐藏层维度为768)准确率提高了18.16%,比BERT 模型(隐藏层维度为768)准确率提高了0.91%;并且原BERT 模型在表5 的参数设置下训练20 000 数据集需要12 h,而BERT-LightGBM 模型训练只需要9.8 h,说明BERT-LightGBM 模型对于提高飞机维修文本故障诊断的效果更好,并且训练速度有了很大的提升,因此本文所建立的BERT-LightGBM 模型能够在一定程度上提高对飞机维修文本故障诊断的效率。
从 表6 可 知,BERT-LightGBM 模 型 与TextCNN、LSTM 和BiLSTM 相比,平均准确率相差较大,这是因为TextCNN 利用局部卷积的思想只能捕获相邻词之间的语义关系,缺乏对全局信息的捕获能力;LSTM 模型只可以融合单向的上下文信息得到特征信息并且会存在记忆退化;BiLSTM 模型在双向提取语义特征时,能关注一部分句子的前后信息,然而这些信息是递归而来的,可能会丢失某个位置的局部信息,只是在一定程度上解决了长程依赖问题。而本文所建立的BERT-LightGBM 模型可以结合上下文进行区分同一词语在不同语句中的不同语义,直接捕捉上下文信息,使模型充分融合全文的双向语义、更加关注于重点词汇,拥有强大的语义表征能力,因此在飞机维修文本故障原因分析中的表现更优。

表6 不同模型的对比实验结果Table 6 Comparison of experimental results of different models
6 结 论
在大数据背景下,针对目前飞机维修文本中蕴含的丰富的信息但无法充分被利用的问题,本文以真实的民机维修文本数据为例,提出了一种不断修正迭代的故障诊断方法,建立了基于飞机维修文本数据的BERT-LightGBM 故障诊断模型。在建立故障诊断模型时,针对飞机维修文本的数据特点,提出了以字和整句为单位的理解方式,为了更好地融合理解维修文本的全文语义,在模型中引入了多头注意力机制,并且针对当数据量较大时诊断速度慢的问题,采用参数因式分解及共享的方法减小参数量。实验结果表明:①将不断递增的维修文本数据输入到BERTLightGBM 诊断模型并修正,可以提高所提出故障诊断方法的准确率;②将本文所建立的BERT-LightGBM 模 型 与 原 BERT 模 型、TextCNN 模 型、LSTM 模 型 和BiLSTM 模 型 在相同数据集上进行准确率对比,可以看出本文所建立的模型在维修文本数据集上有很好的表现;③将改进的BERT-LightGBM 模型与原BERT模型的诊断速度相比,所提出的故障诊断模型可以在一定程度上提高诊断速度。因此本文所提出的方法可以实现飞机维修文本故障原因的智能诊断,辅助维修人员定位故障,便于更快做出正确的维修决策。
