基于多尺度分割注意力的无人机航拍图像目标检测算法
2023-04-19冒国韬邓天民于楠晶
冒国韬,邓天民,2,*,于楠晶
1.重庆交通大学 交通运输学院,重庆 400074
2.重庆大学 自动化学院,重庆 400044
3.重庆交通大学 航运与船舶工程学院,重庆 400074
随着航空遥感技术的发展,无人机在军事侦查、环境监测及交通规划等领域引起了广泛关注,无人机图像目标检测技术作为无人机图像应用的关键技术之一,能够拓宽无人机的场景理解能力,在军事和民用领域具有重要的应用价值。然而,传统目标检测方法由于手工特征设计繁琐、鲁棒性差及计算冗余等原因,难以满足无人机图像目标检测的需求。近年来,以卷积神经网络(Convolutional Neural Network,CNN)为代表的深度学习方法在计算机视觉领域迎来了迅速发展[1],基于深度学习的目标检测方法凭借其强大的自适应学习能力和特征提取能力,在检测性能上远超传统的目标检测方法,因此越来越多学者开始利用深度学习的方法进行无人机图像目标检测。当前基于深度学习的无人机图像目标检测方法可依据是否需要区域建议分为2 类:
1)基于区域建议的无人机图像目标检测算法,此类方法通过提取若干候选区域的特征信息来对预设的候选目标区域进行分类与回归,进而获取目标的类别与位置,其中较为典型的有Faster R-CNN[2]、Mask R-CNN[3]、Cascade RCNN[4]等。近年来,许多学者基于这类算法提出了针对无人机图像目标的检测方法。例如,Liu 等[5]针对无人机图像小目标可获取特征信息少的问题,基于Faster R-CNN 网络设计了一种多分支并行特征金字塔网络(Multi-branch Parallel Feature Pyramid Networks, MPFPN)以捕获更丰富的小目标特征信息,此外,通过引入监督空间注意力模块(Supervised Spatial Attention Module, SSAM)减弱背景噪声的干扰,有效提升了对无人机图像小目标的检测性能,但对于训练图像中从未标注的物体存在误检的情况。Lin 等[6]在Cascade R-CNN 网络的基础上提出了多尺度特征提取骨干网络Trident-FPN,同时引入注意力机制设计了一种注意力双头检测器,有效改善了由于无人机图像目标尺度差异大对目标检测器带来的不利影响,但区域建议网络较大的计算开销还有待改善。
2)基于回归的无人机图像目标检测算法,该类方法在不进行区域建议的情况下完成端到端的目标检测,直接通过初始锚点框对目标定位并预测类别,典型的有YOLO(You Only Look Once)系列算法[7]、单击多盒检测器(Single Shot MultiBox Detector,SSD)[8]及RetinaNet[9]等。为达到无人机图像目标实时检测的目的,已有研究人员将基于回归的目标检测算法应用于无人机 图 像 领 域。例 如,Zhang 等[10]提 出 一 种 基 于YOLOv3 的深度可分离注意力引导网络,通过引入注意力模块并将部分标准卷积替换为深度可分离卷积,有效提升了对无人机图像中小目标车辆的检测效果。Wang 等[11]提出了一种高效的无人机图像目标检测器SPB-YOLO,首先利用设计的条形瓶颈(Strip Bottleneck, SPB)模块来提高对不同尺度目标的检测效果,其次,通过基于路径聚合网络(Path Aggregation Network, PANet)[12]提出的特征图上采样策略,提高了检测器在无人机图像密集检测任务中的表现。裴伟等[13]提出了一种基于特征融合的无人机图像目标检测方法,通过引入不同分类层的特征融合机制以高效的结合网络浅层和深层的特征信息,有效改善了SSD 目标检测算法存在的漏检和重复检测问题,但由于更多的网络层次和深度增加了较大的计算开销,严重影响了目标检测实时性。
由于大视场下的无人机航拍图像目标往往呈现稀疏不均的分布,搜索目标将会花费更高的成本。此外,无人机航拍图像的待检目标具有小尺度、背景复杂、尺度差异大及排列密集等特征,通用场景的目标检测方法很难取得理想的检测效果。基于此,本文提出一种多尺度分割注意力单元(Multi-Scale Split Attention Unit,MSAU),分别从通道和空间2 个维度自适应的挖掘不同尺度特征空间的重要特征信息,抑制干扰特征信息,通过将其嵌入基础骨干网络,使网络更具指向性的提取任务目标区域的关键信息;进一步的,本文结合加权特征融合思想提出一种自适应加权特征融合方法(Adaptive Weighted feature Fusion,AWF),通过动态调节各个特征层的重要性分布权重,实现浅层细节信息与深层语义信息的高效融合。最后,结合以上提出的MSAU 和AWF 两种策略,本文设计了一种基于多尺度分割注意力的无人机航拍图像目标检测算法(Multi-scale Split Attention-You Only Look Once,MSA-YOLO)。
1 本文方法
MSA-YOLO 算法的核心思想是尽可能保证目标检测器实时检测性能的前提下,着重关注如何挖掘有益于无人机图像目标检测的关键特征信息,通过提出的多尺度分割注意力单元MSAU 和自适应加权特征融合AWF 来提升基准模型YOLOv5 在无人机图像目标检测任务中的表现。MSA-YOLO 算法的框架结构如图1所示,嵌入在骨干网络瓶颈层(Bottleneck Layer)中的多尺度分割注意力单元MSAU 主要包括多尺度特征提取模块、通道注意力模块及空间注意力模块3 个部分,首先通过多尺度特征提取模块提取出丰富的多尺度特征信息,随后利用并行组合的混合域注意力为多尺度特征层的不同特征通道和区域赋予不同的注意力权重,从大量多尺度特征信息中筛选出对无人机图像任务目标更重要的信息;自适应加权特征融合AWF利用可学习的权重系数对3 个特征尺度的特征层进行加权处理并实现自适应的特征融合,进而结合丰富的上下文信息强化目标检测器的表征能力。
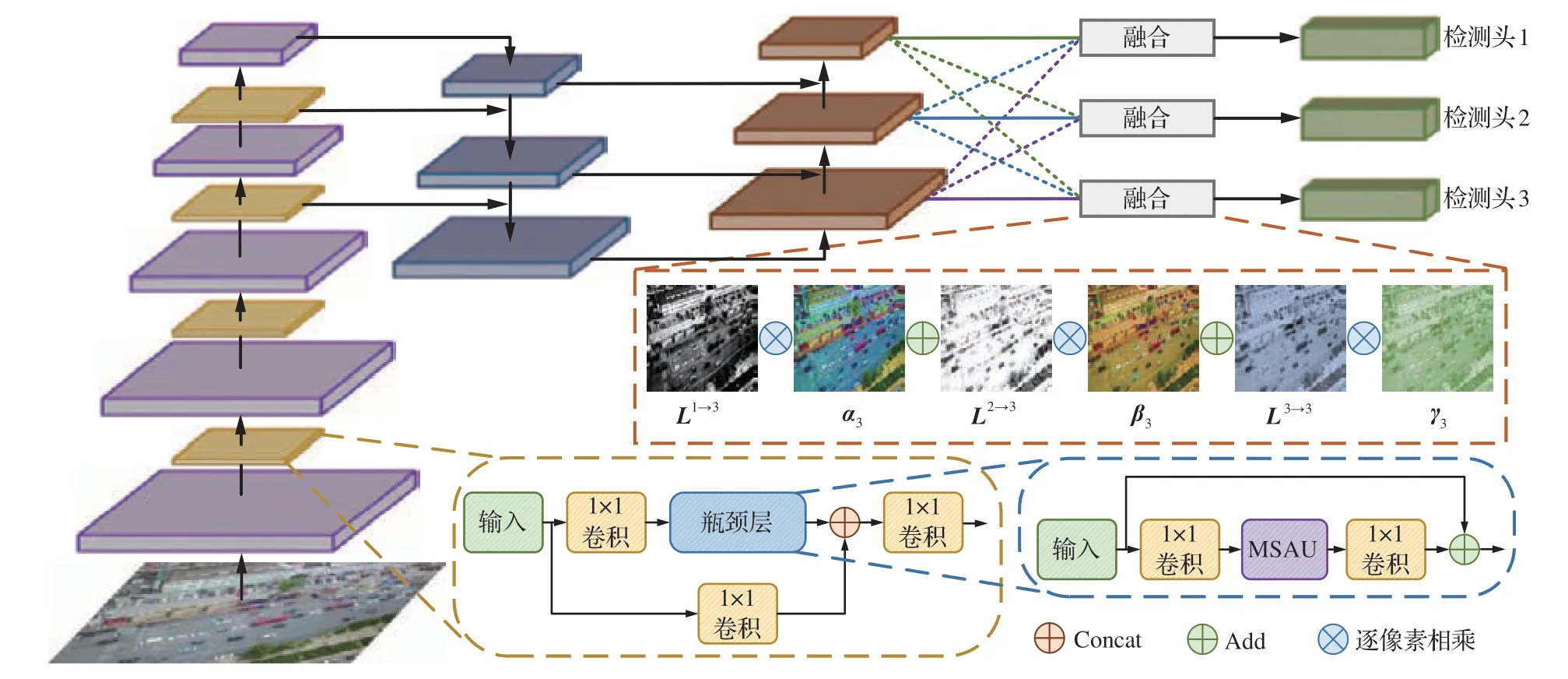
图1 MSA-YOLO 算法框架结构图Fig.1 Architecture of MSA-YOLO algorithm
1.1 多尺度分割注意力单元
在特征提取过程中,采用固定尺寸的卷积核只能提取到目标局部的特征信息,无法通过不同感受野挖掘丰富的上下文信息,为有效利用不同尺度的特征空间信息,本文设计了一种多尺度特征提取模 块(Multi-scale Feature Extraction Module,MFEM),通过多尺度卷积的方式来获取不同尺度的特征信息。MFEM 的多尺度特征提取过程如图2 所示,假定多尺度特征提取模块MFEM 的输入特征空间为X=[X1,X2,…,Xc]∈RC×H×W,通过split 切片操作将输入特征空间X的通道平均切分为n个部分,若C表示该输入特征的通道数,则切片后各个部分Xi的通道数为C'=C/n,为了降低模块的参数量,本文采用不同分组数量Gi且不同卷积核尺寸ki×ki的分组卷积提取多尺度的特征信息Fi∈RC'×H×W
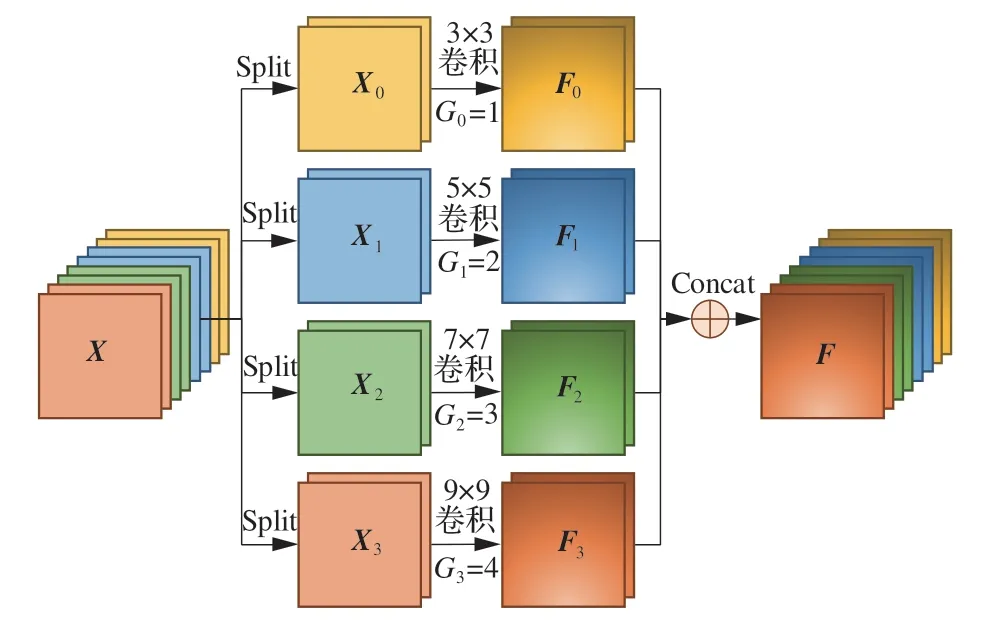
图2 多尺度特征提取模块流程图Fig.2 Flow chart of multi-scale feature extraction module
式中:(Xi,Gi)表示对特征图Xi进行分组数量为Gi且卷积核尺寸为ki×ki的卷积操作,为保证模型较小的计算开销,本文将输入特征空间切分为4 个部分,则设置n=4,分组卷积核尺寸ki分别为3、5、7、9,分组数量Gi分别为1、2、3、4。
各个部分的特征图Xi在分别经过不同尺寸的卷积核后获得了不同尺度的感受野,并提取出不同尺度的特征信息Fi,对Fi进行Concat 操作可以得到最终融合后的特征空间F∈RC×H×W
式中:Cat(·)表示对所有的特征图进行Concat操作。
本文的多尺度特征提取模块在一定程度上弥补了卷积核尺寸单一对网络特征提取能力的不利影响,对输入特征空间进行均匀分割,再分别利用4 种不同感受野的卷积核捕捉不同尺度的特征空间信息,最后将获得的4 种不同尺度的特征信息进行融合,使得融合后的特征空间F具备丰富的多尺度上下文信息,有利于交错复杂的无人机图像检测任务。
注意力机制中,所有特征信息会根据学到的注意力权重进行加权处理,相关性较低的特征信息被赋予较低的权重,反之则被赋予较高的权重,以此弱化不重要信息的干扰,并分离出重要信息。按照注意力域的不同,一般可将注意力机制分为通道域注意力机制、空间域注意力机制及混合域注意力机制。通道注意力机制关注特征图通道之间的远程依赖关系,空间域注意力机制聚焦于特征图中对分类起决定作用的像素区域,混合域注意力机制则同时利用到空间域和通道域的信息,每个通道特征图中的每个元素都对应一个注意力权重。这些即插即用的注意力模型可以无缝集成到各种深度学习网络中用以指导目标检测任务。
为更好地提取无人机图像目标的特征信息,弱化无关背景信息的干扰,本文结合通道域注意力和空间域注意力,提出了一种并行组合的混合域注意力,一方面沿着通道维度获取通道间的远程相互依赖关系,另一方面通过强调空间维度感兴趣的任务相关区域进一步挖掘特征图的上下文信息。本文设计的混合域注意力由挤压激励模 块(Squeeze-and-Excitation Module,SEM)[14]和空间注意力模块(Spatial Attention Module,SAM)[15]并行连接组成。通道注意力旨在通过生成一种可以维持通道间相关性的注意力权重图来挖掘输入与输出特征通道之间的远距离依赖关系,SEM 和SAM 的网络结构如图3 所示。
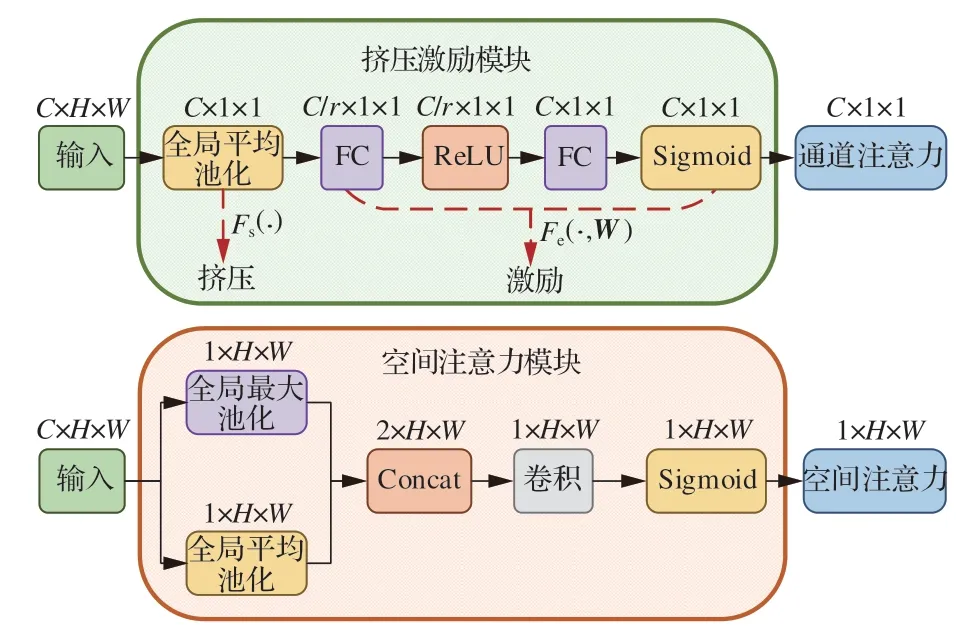
图3 SEM 和SAM 的网络结构图Fig.3 Network structure of SEM and SAM
假设通道注意力模块SEM 的输入特征空间为X=[X1,X2,…,Xc]∈RC×H×W,C表示该输入特征的通道数,H×W表示输入特征的尺度大小,输入特征空间的第c个通道用Xc∈RH×W表示。Fs(·)表示挤压(Squeeze)映射,Fe(·,W)表示激励(Excitation)映射,Fs(·)通常采用全局平均池化(Global Average Pooling,GAP)实现,对输入空间特征X进行Fs(·)映射后获得全局特征空间Z∈RC×H×W的第c个特征Zc:进一步的,利用Fe(·,W)激励操作来降低计算开销,获得高效的自适应学习注意力图。首先使用参数为W0,降维系数为r的全连接(Fully Connected,FC)层进行降维操作获得维度为C/r×1×1 的特征,通过ReLU 函数对特征进行激励操作δ,经过参数为W1的FC 层后恢复原始的维度C×1×1,最后利用sigmoid 激活函数进行归一化后得到各个通道的注意力权重S,即
空间注意力模块旨在利用输入特征的空间信息生成空间注意力权重图,并对输入特征进行空间域注意力加权,进而增强重要区域的特征表达。空间注意力模块的输入特征空间与通道注意 力 模 块 的 输 入 特 征 空 间X=[X1,X2,…,Xc]∈RC×H×W相同,分别沿着通道维度采用全局最大池化(Global Max Pooling,GMP)和全局平均池化(Global Average Pooling,GAP)压 缩 后 得 到Xavg∈R1×H×W和Xmax∈R1×H×W这2 个特征图,对2 个特征图进行concat操作后采用感受野较大7×7 卷积核进行卷积操作F7×7conv,最后通过sigmoid 激活函数σ进行归一化后得到空间域注意力权重图M∈R1×H×W:
空间注意力模块SAM 将输入特征的每个通道进行相同的空间加权处理,忽视了通道域的信息交互;而通道注意力模块SEM 则忽视了空间域内部的信息交互,将一个通道内的信息进行全局加权处理。因此,本文将通道注意力模块与空间注意力模块通过并行的方式连接,旨在从全局特征信息出发,沿着通道与空间2 个维度深入挖掘输入特征内部的关键信息,进而筛选出任务相关的重要信息,弱化不相关信息的干扰。相比于级联连接的组合方式,这种并行组合的方法无需考虑通道注意力模块与空间注意力模块的先后顺序,2 种注意力模块都直接对初始输入特征空间进行学习,不存在特征学习过程中互相干扰的情况,从而使混合域注意力的效果更稳定[16]。
混合域注意力同时考虑了空间注意力和通道注意力,在一定程度上丰富了特征信息,但无法有效地挖掘和利用不同尺度的特征空间信息。鉴于此,本文设计了一种能够有效地建立多尺度注意力间长期依赖关系的多尺度分割注意力单元MSAU,如图4 所示。MSAU 主要由多尺度特征提取模块MFEM、通道注意力模块SEM 及空间注意力模块SAM 组成,输入特征空间X通过多尺度特征提取模块捕捉不同尺度的特征信息,得到多尺度特征空间F,随后,不同尺度的特征图分别通过通道注意力模块和空间注意力模块得到多尺度注意力权重,最后利用并行组合的通道与空间2 个维度的多尺度注意力进行注意力加权后得到最终输出的特征空间Y。
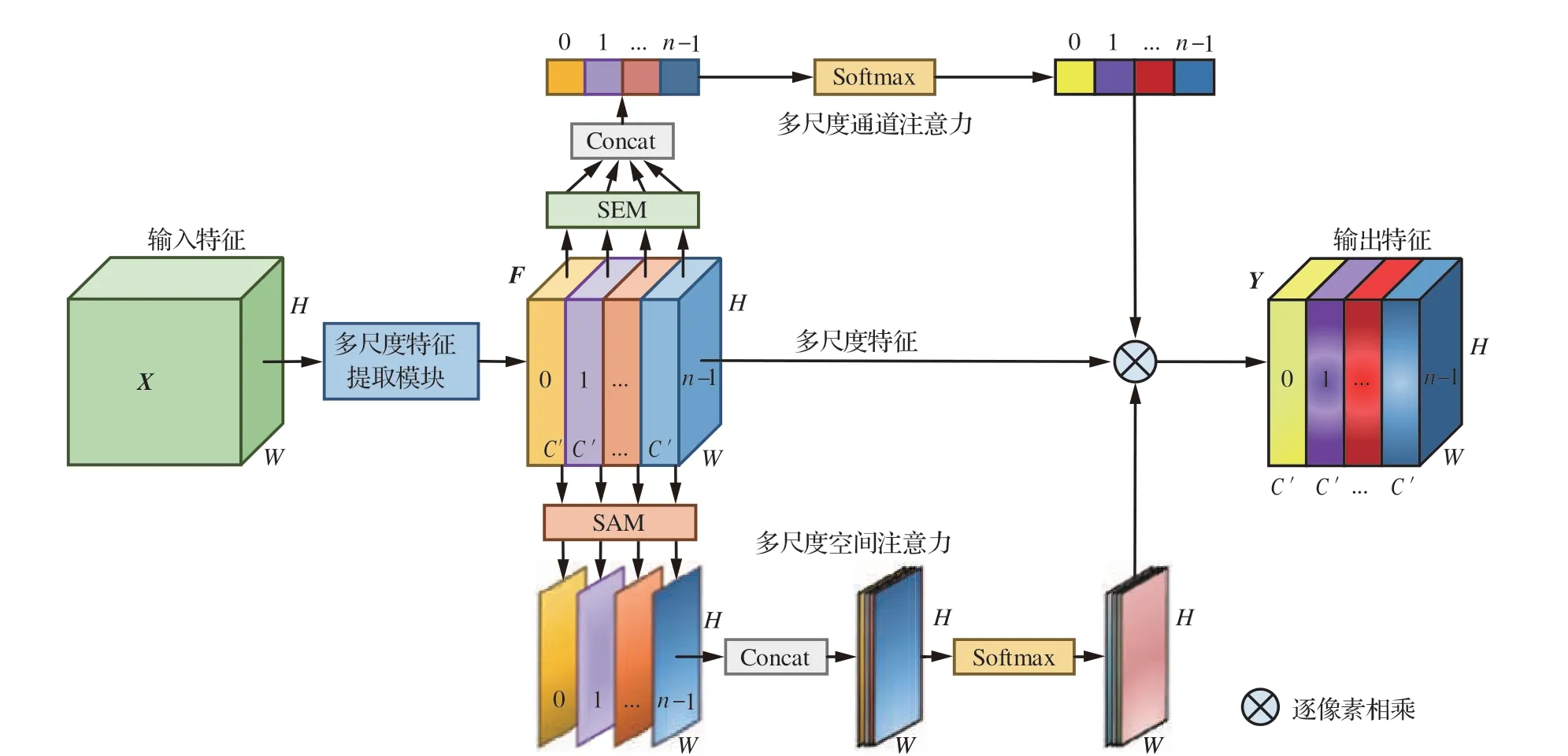
图4 多尺度分割注意力单元结构图Fig.4 Architecture of multi-scale split attention unit
假设多尺度分割注意力单元MSAU 的输入特征空间为X=[X1,X2,…,Xc]∈RC×H×W,经过多尺度特征提取模块提取特征后得到多尺度特征空间F∈RC×H×W,随后不同尺度特征图Fi利用通道注意力模块来获得多尺度通道注意力权重Si:
式中:SEM(·)代表利用通道注意力模块SEM 挖掘特征图的通道注意力;Si为Fi的通道注意力权重值,因此整个多尺度通道注意力S可以表示为
式中:⊕表示Concat 操作;S为多尺度通道注意力权重。
为建立通道间的远程依赖关系,实现多尺度通道注意力之间的信息交互,进一步利用Softmax 函数对通道注意力Si进行重新标定得到最终的通道注意力权重Hi:
式中:Softmax(·)表示Softmax 操作,用于获取多尺度通道的重标定权重Hi。
类似的,可以利用空间注意力模块捕捉不同尺度特征图Fi的多尺度空间注意力权重Mi:
式中:SAM(·)代表利用空间注意力模块SAM 捕捉特征图的空间注意力;Mi为Fi的空间注意力权重值,因此整个多尺度空间注意力M可表示为
式中:+表示add 操作;M为多尺度空间注意力权重。
随后,利用Softmax 函数Softmax(·)对空间注意力Mi进行重新标定得到最终的空间注意力权重Pi:
最后,将SEM 和SAM 学习到的多尺度通道注意力权重向量Hi和多尺度空间注意力权重图Pi与多尺度特征空间F∈RC×H×W进行注意力加权Fscale得到输出的多尺度特征空间Yi:
式中:⊗表示特征加权乘法运算符号。Concat 操作能在不破坏原始特征图信息的前提下,完整地维持特征表示,因此,最终得到的多尺度分割注意力单元MSAU 的输出Y可表示为
MSAU 首先利用多尺度特征提取模块有效提取了不同尺度特征空间的多维特征,随后将其分别输入并行组合的混合域注意力,为不同尺度特征空间赋予了不同的重要性权重。这种方法不仅能考虑到多尺度特征信息,同时使网络能够有选择地处理关键信息,对目标区域投入更多注意力资源,以获取更多待检目标的细节信息。同时,不同尺度特征空间的多尺度注意力权重会在模型训练过程中根据每轮输入特征空间的重要性差异进行自适应的、精确的调整更新,通过将其嵌入骨干网络,进而利用丰富的特征空间以指导无人机图像目标检测任务。
1.2 自适应加权特征融合
浅层网络提取目标纹理边缘特征,具有更多的细节内容描述;深层网络则提取目标丰富的语义特征,但同时削弱了对小目标位置信息和细节信息的感知,以致丢失小目标在特征图中的特征信息[17]。PANet 将不同深度特征信息以平等关系跨层融合,忽略了不同特征层之间的关系,直接使用3 个特征尺度的输出特征进行目标预测,但不同深度特征层对任务目标的贡献其实是不同的,浅层网络特征在小目标检测过程中占据着更重要的位置。针对以上问题,本节设计了一种自适应加权特征融合方法AWF,通过为各尺度特征层赋予不同比例权重,有效利用了3 个不同尺度特征层的浅层和深层特征,自适应的强化特征金字塔中对任务目标检测更重要的特征信息,进而融合丰富的特征信息以指导无人机图像小目标检测任务。
AWF 在进行最终的特征融合时采用了加权再相加的方式,因此,需要确保参与融合的特征层分辨率相同,且通道数也应相同。对于特征金字塔的输出特征Ln∈RCn×Hn×W n,其中n∈1,2,3,通过上采样或下采样将特征金字塔输出特征Lm∈RCm×Hm×W m的特征图分辨率和通道数都调整为与Ln相同,Lm→n∈RCn×Hn×W n表示调整后的特征。对于上采样,首先使用1×1 卷积层来调整特征的通道数,然后通过双线性插值来提高分辨率;对于下采样,则使用步长为2 的最大池化层和3×3 卷积层同时改变特征的分辨率和通道数。将调整后的特征通过Concat 操作进行整合后可表示为整个特征金字塔的输出特征L∈R3Cn×Hn×W n:
随后,使用Softmax 函数Softmax(·)和1×1卷积层F1×1conv得到权重矩阵W∈R4×Hn×W n:
最后,沿着通道维度将权重矩阵W切割为再沿着通道维度进行扩展后得到特征金字塔调整后特征Lm→n对应的重要性权重参数αn,βn,γn∈RCn×Hn×W n,这些重要性权重参数来自前面特征层经过卷积后的输出,并通过网络的梯度反向传播变为了可自适应学习的参数。将其与对应特征Lm→n加权融合后得到新的融合特征Fn:
由于加权特征融合的权重参数均源自前面3个尺度特征层的输出,因此可学习的权重参数和特征是息息相关的,数据集实例样本的特点则是影响贡献衡量标准的主要因素,针对小目标实例居多的无人机航拍图像,则认为浅层网络中丰富的纹理和边缘特征对无人机航拍目标检测任务具有更大的贡献,更有利于提取小目标的类别及位置信息,因此浅层网络特征层则会被赋予更高的权重值,而这样一个有效的权重系数可以经过不断优化的训练过程产生。在模型训练过程中,AWF 根据各尺度特征层对当前任务目标的贡献大小来动态的调节其权重值,充分挖掘了不同深度特征层的多维特征,可以更好地监督网络的特征融合过程,使融合后的特征兼顾强大的语义信息和丰富的几何细节信息。
值得一提的是,这种自适应加权的特征融合方法并不是能够完全适用于任何目标检测任务,在数据集整体实例的像素大小或各类目标实例的特征未呈现出一种较为显著的趋势时,可能很难达到较为理想的效果。
2 实验结果与分析
2.1 实验数据与参数设置
1)实验平台:本文实验采用的硬件配置为Nvidia RTX3060 GPU 和Intel i5-10400 2.90 GHz CPU,软件环境为Windows10 系统下的Pytorch 深度学习框架。
2)数据集:本文实验所采用的数据来源于VisDrone无人机图像目标检测公开数据集[18]。该数据集包括行人(指具有行走或站立姿势的人)、人(指具有其他姿势的人)、汽车、货车、公共汽车、卡车、摩托车、自行车、遮阳蓬三轮车及三轮车共10 个类别。VisDrone 数据集由288 个视频剪辑而成,分为1 360×765 和960×540 像素2 种不同的图像尺寸,总计提供了由不同高度的无人机捕获的10 209 幅静态图像,其中包括6 471 幅训练集图像、548 幅验证集图像及3 190 幅测试集图像,共计260 万个目标实例样本。
3)评价指标:为评估本文所提算法的有效性,选取模型规模、参数数量及每秒浮点运算次数(Floating Point Operations,FLOPs)来评价模型的复杂程度,选取平均均值精度(mean Average Precision,mAP)作为模型对多个目标类别综合检测性能的评价指标,采用平均精度(Average Precision,AP)来评价模型对单个目标类别的检测性能。
2.2 消融实验
为了验证所提的多尺度分割注意力单元MSAU 和自适应加权特征融合AWF 在无人机图像目标检测任务中的有效性,本文在VisDrone测试集上进行了一系列的消融实验,以YOLOv5为基线算法,mAP、模型规模、参数量及浮点运算次数为评价指标,最终结果如表1 所示。

表1 VisDrone 测试集上的消融实验结果Table 1 Results of ablation experiment on VisDrone test set
消融实验的结果表明,将提出的多尺度分割注意力单元MSAU 嵌入基线算法的骨干网络后,算法的模型规模和参数量分别增加了15 MB 和7.53M(1M=106),同时浮点运算次数增加到140.9G(1G=109),取得了34.1%的mAP,检测精度的提升也从侧面反映出了MSAU 捕获不同尺度特征信息的能力,正是由于其精准高效的挖掘了特征空间在多尺度上的特征信息,因此能在确保模型较小计算复杂度的同时有效提升对无人机航拍图像目标的检测效果;进一步的,在基线算法基础上采用所提的自适应加权特征融合AWF 方法,相比基线算法仅增加了2.21M 的参数量和5.4G 的浮点运算次数,并取得了32.8%的mAP,AWF 在自适应地融合了网络深层与浅层的丰富语义信息和几何信息后,能够较为充分的捕获无人机图像目标的特征信息。同时,由于AWF 添加了3 个特征融合层,且每个特征融合层都利用到前面各个特征尺度的输出特征,给网络带来了一定的计算开销,但相比于基线算法采用Concat 的特征融合操作,加权再相加的特征融合方式可使融合后的特征空间维持在更低的通道数,因此保持了良好的实时性能;与基线算法相比较,本文所提MSA-YOLO 算法的参数量和浮点运算次数分别增加了9.6 M 和31.7 G,模型规模由于参数量的增高而上升到108 MB,mAP 则比基线算法提高了2.8%,达到34.7%。综上所述,MSA-YOLO 算法在维持较小计算开销的前提下获得了更好的检测性能,可以有效地指导无人机图像目标检测任务。
2.3 各算法在VisDrone 测试集上的检测性能
为证明MSA-YOLO 算法对无人机图像各类目标检测的有效性,本文在VisDrone 测试集上与各种先进的无人机图像目标检测算法进行对比 分 析,表2[19-24]为 各 算 法 对VisDrone 测 试 集10 类目标的AP 值与mAP 值。从表2 中可以看出,MSA-YOLO 算法与其他先进算法相比取得了最优的综合性能,比次优的CDNet 高出0.5%的mAP。对于汽车、卡车及公共汽车等目标类别取得了最优的检测性能,分别达到了76.8%、41.4%及60.9%的AP 值,对于行人、货车、及摩托车等纵横比较大且实例个数较少的目标类别则分别达到了33.4%、41.5%及31.0%的较优AP 值,在目标实例个数较少的情况下能够较为充分的挖掘其特征信息,由此可见本文提出的MSA-YOLO 算法在处理无人机图像目标检测任务时具有较大优势,其检测效果是十分可观的。
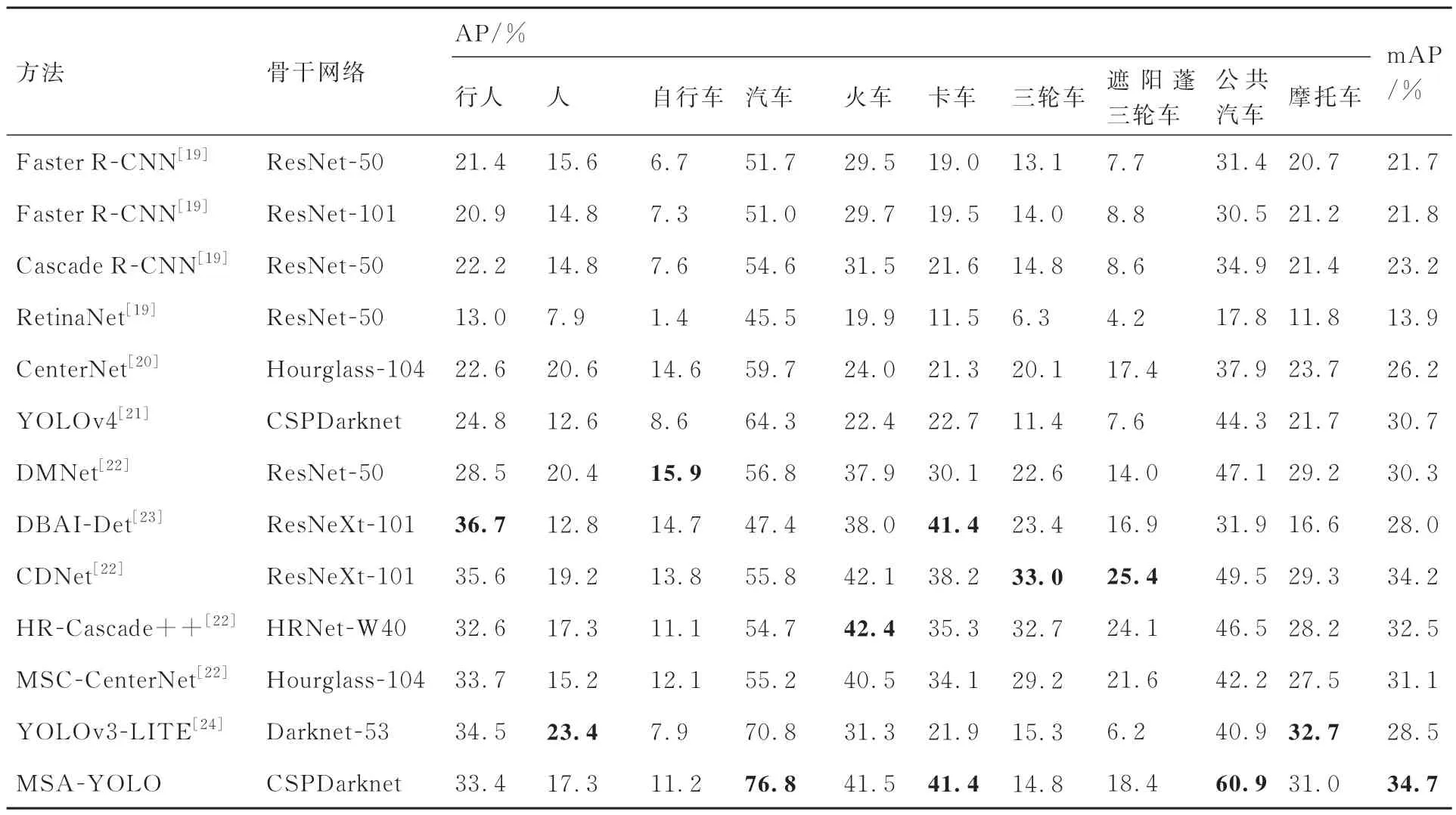
表2 不同算法在VisDrone 测试集上的AP 与mAP 对比Table 2 Comparison of AP and mAP of different algorithms on VisDrone test set
为了验证MSA-YOLO 算法在实际场景中的检测效果,选取VisDrone 测试集中实际检测较为困难的图像进行测试,部分检测结果如图5 所示,可以看出,本文方法对不同拍摄角度下背景复杂且分布密集的无人机图像展现出了较为优异的检测性能,能够有效地抑制图像背景噪声信息的干扰,更具选择性的挖掘有利于无人机图像目标检测任务的重要特征信息。为进一步评价基线算法和MSA-YOLO 算法在处理无人机图像目标检测任务时的性能差异,本文在VisDrone测试集中随机选取了小目标样例图片进行测试,并可视化对比分析,如图6 所示。

图5 MSA-YOLO 在VisDrone 测试集上的部分检测结果Fig.5 Partial detection results of MSA-YOLO on VisDrone test set
本文分别抽取了晴天和夜间的小目标样例并对比了2 种算法的检测结果,可以看出,MSAYOLO 算法有效提升了基线算法对小尺度目标的检测效果。通过图6(a)与图6(b)的对比发现,基线算法错将站立的行人检测为人,且存在大量行人目标漏警的情况,而MSA-YOLO 算法则能够精准的进行识别。对比图6(c)和图6(d)可以看出,在夜间低照度的情况下,基线算法受到背景噪声信息的干扰出现了部分漏警,MSA-YOLO算法则通过弱化噪声干扰、强化网络感兴趣的多尺度特征,从大量多尺度特征信息中分离出了有利于无人机图像目标检测的信息,在面对复杂的背景信息时表现出了较强的抗干扰能力,有效改善了夜间的漏警情况。总体而言,在处理无人机图像目标检测任务时,MSA-YOLO 算法相比于基线算法有更明显的优势,对于小尺度、背景复杂及排列密集的无人机图像目标具备更强的辨识能力,有效避免了出现虚警、漏警等现象。

图6 VisDrone 测试集上的小目标检测效果对比Fig.6 Comparison of small object detection effect on VisDrone test set
3 结 论
本文提出一种基于多尺度分割注意力的无人机图像目标检测算法MSA-YOLO。针对无人机图像背景复杂混乱的特点,提出了多尺度分割注意力单元MSAU,在多个尺度上沿着空间和通道维度提取无人机图像目标的关键特征信息,同时弱化不相关的背景噪声信息,有益于提高无人机图像目标检测性能。针对无人机图像小尺度目标实例多,缺乏有效特征信息的问题,提出了自适应加权特征融合AWF 方法,通过自适应学习的方式动态调节各输入特征层的权重,充分强调浅层细粒度特征信息在特征融合过程中的重要性,有效改善目标检测器对小目标细节位置信息的感知能力。在VisDrone 数据集上的实验结果表明,相比于现有的先进无人机图像目标检测方法,MSA-YOLO 算法在行人、货车及摩托车类别上分别取得了第五、第三及第二的检测效果,而在汽车、卡车及公共汽车这3 种目标类别则上取得了最优的检测效果,能很好的应对无人机图像目标检测任务。
