基于近红外光谱技术的草莓可溶性固形物与糖度的检测分析*
2023-04-14宋白玉张瑞鑫庄程翔陈少华
宋白玉,张瑞鑫,庄程翔,刘 哲,陈少华
(江苏农林职业技术学院,江苏 镇江 212400)
近红外光谱技术(Near Infrared,NIR)的信息量丰富,可以直接透过样品的内部,波长范围为800~2 500 nm。近红外检测技术具有多种成分同时分析、测量速度快、测试成本低、样品无需预处理且不会遭到破坏、无需化学试剂等突出特点,堪称“绿色检测技术”[1],在水果品质检测中得到了广泛的应用。
近红外光是介于可见光和中红外光之间的电磁波,光谱波长区域为780~2 526 nm,波数为12 820~3 959 cm-1。近红外光谱主要是有机分子的倍频与合频吸收光谱[1],它是由于分子振动的非谐振性使分子振动从基态向高能级跃迁时产生的。它记录了含氢基团(C-H,O-H,N-H,S-H)分子化学键基频振动的倍频和合频信息[2],包含了绝大多数类型化合物及其混合物的质量浓度,或品质参数的丰富信息。可溶性固形物主要的组成基团是C-H 和O-H,因此适合用NIR 技术来分析。根据“朗伯-比尔”吸收定律[3],不同的基团和同一基团在不同化学环境中的吸收波长有明显差别,可以作为获取有机物组成或性质信息的有效载体[4]。因此,NIR 光谱不仅能够反映绝大多数有机化合物的组成和结构性能信息[5],而且对某些无机离子化合物,也能够通过它对共存的本体物质影响引起的光谱变化[6],间接地反映它存在的信息,而且从近红外反射光谱还能得到样品的密度、粒度、高分子物的聚合度及纤维直径等物理状态信息[7]。
由于有机组分的各官能团在近红外区具有多级吸收,且不同官能团之间的谱峰相互叠加[8]和固体样品的散射等因素的影响。因此,近红外光谱在某个波长点的漫反射吸光度[9]与有机组分的质量浓度或性质之间并不是简单的线性关系[3],必须采用化学计量学方法[4]解析复杂的近红外光谱,建立光谱信息与有机组分之间的关系。
1 近红外光谱定量分析中的化学计量算法
目前,光谱分析中定量分析中采用的化学计量学方法[5]主要有多元线性回归、逐步多元线性回归、主成分回归、偏最小二乘法和人工神经网络等[10]。本文采用了主成分回归和偏最小二乘法进行分析,故在此只简单介绍这2 种化学计量算法。
主成分回归法(Principal Component Regression,PCR)[6]包括2 个步骤,首先是把原始数据进行主成分分析(Principal Component Analysis,PCA),它是以因子分析为基础,将光谱数据向协方差最大方向投影,使数目较少的主成分成为原变量的线性组合,主成分最大限度地反映了被测样品的组成和结构信息,而最小限度地包含噪声,通过对主成分个数的合理选取,去掉代表干扰组分和干扰因素的主成分;然后再用其中的几个主成分与物质的化学成分进行多元线性回归,这就是主成分回归分析的主要思想。其优点主要是可充分利用光谱数据的信息,增加了模型抗干扰能力[8]。但在分解光谱矩阵时,未考虑光谱矩阵与样品成分矩阵之间的内在联系,不能保证参与回归的主成分一定与被测组分或性质相关。
偏最小二乘法(Partial Least-Square Method,PLS)[7]从20 世纪80 年代被开始应用于化学研究,现已成为化学计量学中最常用的多元校正方法,也是近红外光谱分析上应用最多的回归方法。PLS 也是一种基于因子分析的多元校正方法,与主成分回归法的区别是:它不仅将响应矩阵进行分解,提取主因子,还将质量浓度矩阵进行分解提取主因子,具有更强的提供信息的能力,所建立的校正模型[5]更稳定,抗干扰能力更强。如同主成分回归分析,在应用PLS 时,确定参与回归的维数十分重要。
2 材料与方法
2.1 近红外漫反射光谱扫描
本次试验使用的是美国ASD 公司生产的Quality Spec®Pro 光谱仪,各参数设置如下:波长范围为350~1 800 nm,光谱采样间隔为1 nm,扫描次数为10 次,分辨率为3 nm(700 nm)、10 nm(1 400 nm)。近红外波段(350~1 000 nm)选择512 相元阵列硅(Si)检测器,检测距离为3 cm;短红外波段(1 000~1 800 nm)选择铟镓砷(InGaAs)检测器。探头视场角为45°,光源是与光谱仪配套的12 V/30 W 钨卤灯。该NIR 装置示意图如图1 所示。

图1 NIR 测量装置示意图
在光谱采集前,对ASD 光谱仪预热2 h,并稳定光源15 min,以白板作为参比标准,在温度20 ℃及相对湿度55%的条件下,将草莓置于NIR 光谱采集系统上,对每个草莓样品进行1 次光谱测量,扫描点选择表面圆滑部位,然后,换角度再进行1 次光谱扫描。计算机自动计算得到样品漫反射光谱,并取2 次测量的平均光谱。扫描后的谱图如图2 所示。
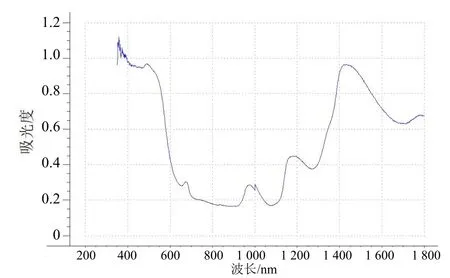
图2 单个草莓样品的近红外漫反射谱图
从图中可以看出,谱线在670 nm、950 nm、1 175 nm 及1 425 nm 附近有明显的特征峰值。
2.2 草莓样品可溶性固形物含量的化学测定
试验样品均采于本课题组位于金华赤松镇的草莓试验基地,采后即用冰盒带回实验室,放置平板上待果实恢复室温后即进行样品的光谱检测和SSC(Soluble Solids Content)测定,试验在当天完成。在对样品进行测量前,首先用半干的毛巾擦干净水果表面,再对样本进行预处理后进行排序标记并确定光谱采样范围。试验样品共150 个,在建模过程中,由软件随机分为2 组,即校正组和验证组,样品分别为112和38 个,样品温度与室温平衡后即进行点对点的光谱采集与SSC 的测定。
本试验采用折射式数字糖度计[2]进行测量。采集完光谱后,挤出草莓果汁,滴到糖度计的小槽中,滴满为止,然后进行可溶性固形物的测量。
2.3 模型的建立与数据处理
应用定量分析软件The uascrambler 9.6 建立草莓可溶性固形物含量校正模型。建模采用2 种多元校正方法,即主成分分析和偏最小二乘法。将可溶性固形物含量的实测值导入该软件,在建模过程中随机选择112 个作为建模样品,38 个作为预测样品。用未参与建模的样品对模型进行验证,评价模型的可行性,比较PCR 和PLS 的预测性能。
2.4 最适谱区的选择
在近红外光谱分析过程中,一般在通用的光谱仪上扫描一个样品会得到上千个数据点。光谱图谱带重叠严重、背景复杂,其信息量非常丰富,这给定性和定量分析带来了巨大困难。传统观点认为主成分分析、偏最小二乘法具有较强的抗干扰能力,可全波长参与多元校正模型的建立。
随着多组分混合物光谱定量分析研究的日趋活跃和深入,发现选取一定范围的光谱甚至是几个特定的波长点处的吸收值进行定标不但可以简化计算,还可以提高模型的稳定性和预测能力。当采用全谱区进行计算建模时,不仅计算量大,而且在某些光谱区域样品的光谱信息很弱或与样品的组成或性质缺乏相关关系,引入这样的变量会造成多元校正模型的精度降低甚至错误。如果对建模的光谱谱区进行选择,将有利于简化模型、减少噪声影响,提高运算效率和模型的稳定性。
本研究选择不同的谱区采用PLS 和PCR 这2 种方法分别建立不同谱区的校正模型,根据它们的预测效果,得到建立校正模型的最适谱区。
2.5 光谱预处理
由于仪器、样品背景或其他因素影响,近红外光谱分析中经常出现谱图漂移或偏移现象,如不加处理,同样会影响校正模型建立的质量和未知样品预测结果的准确性。可以采用扯平峰谷点、偏置扣减、微分处理和基线倾斜等方法。基线校正最常用的解决方法是对光谱进行一阶微分或二阶微分处理,前者主要解决基线的偏移,后者则解决基线的漂移。采用微分可以较好地净化图谱信息。本试验比较了原始光谱及一阶和二阶微分光谱所建模型的预测效果。
2.6 数学模型预测效果的评价指标
在对未知样本进行测定时,根据测定的光谱和校正模型的实用性判断,确定建立的校正模型能否对未知样本进行测定。一般在实际建模过程中把交叉验证的决定系数R2和校正标准差(RMSEC)作为评价标准。在外部检验中,用决定系数R2和预测标准差(RMSEP)作为评价标准。决定系数R2越大,而校正标准差(RMSEC)和预测标差(RMSEP)越小,说明模型越可靠。
校正标准差的计算公式如下:
式(1)中:IRMSEC为校正标准差值;M为定标集的样品数;iy^ 为第i个样品的预测值;yi为第i个样品的化学分析值。
预测标准差值的计算公式如下:
式(2)中:JRMSEP为预测标准差值;n为验证集的样品数。
决定系数R2给出了真实组分值中出现的变量百分数,预测含量值越接近真值,R2越接近100%,其计算公式如下:
式(3)中:yn为M个样品真值的平均值。
3 结果与分析
3.1 草莓样品可溶性固形物与糖度测定结果
草莓样品可溶性固形物含量分析结果如表1所示。由表可知,校正集样品中可溶性固形物范围为9.1~17.3,标准偏差为1.857 4,平均值为11.514 6;验证集样品的可溶性固形物范围为9.6~17.1,平均值为12.235 4,标准偏差为1.498 2。测定值呈典型的“钟”形的正态分布,这表明样品值具有较广泛的代表性,并保证方差分析、回归分析等统计方法所对应的样本值服从正态分布。草莓糖度的分析结果如表2 所示。

表1 草莓样品可溶性固形物含量分析结果

表2 草莓糖度的分析结果
3.2 不同谱区对结果的影响
在运用偏最小二乘法建立模型的过程中,选择不同的谱区,对结果具有一定的影响。运用The uascrambler 9.6定量分析软件将全光谱波段分成11 个交叉的波段,表3 和表4 只列举了部分谱区,即选择了预测效果最佳的谱区,并按效果由好到差依次列于表中。
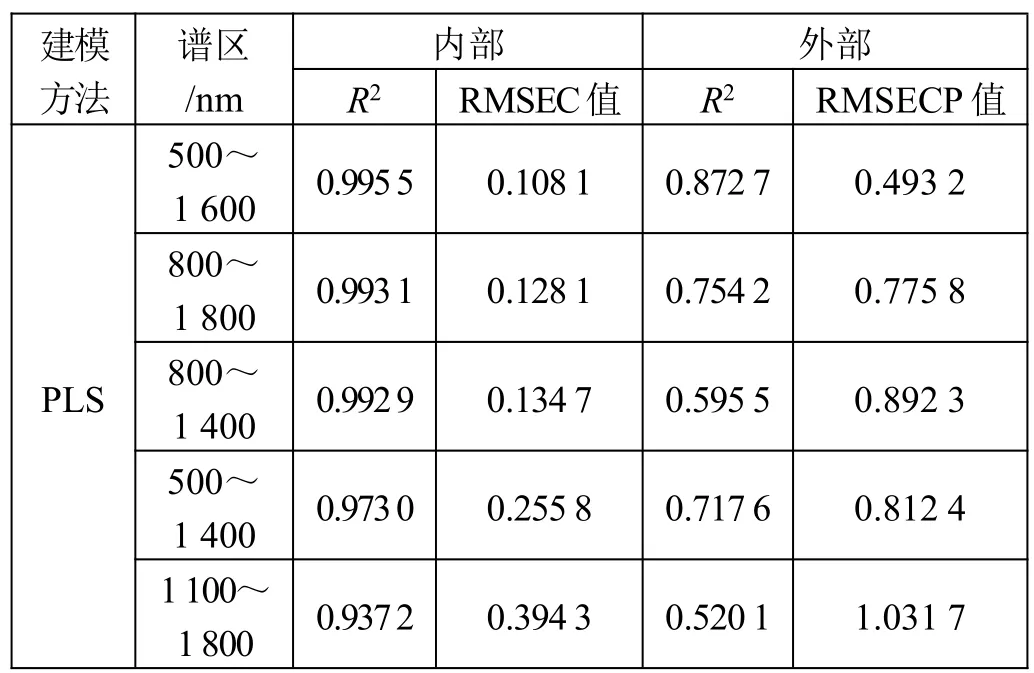
表3 不同谱区对PLS 模型效果的影响
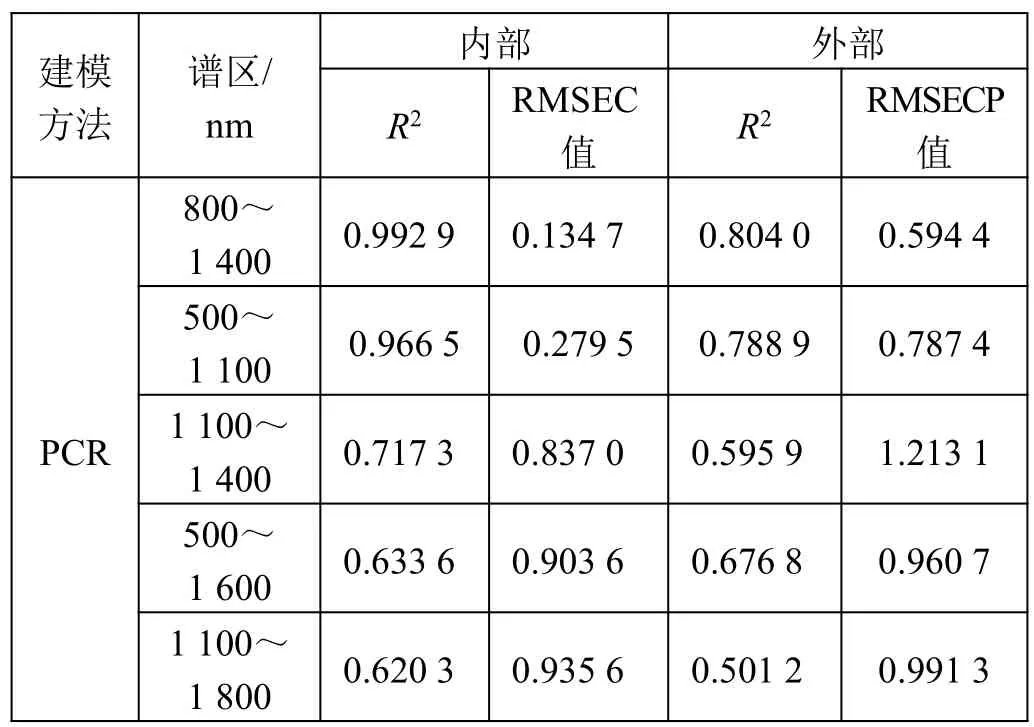
表4 不同谱区对PCR 模型效果的影响
结合表3 和表4,从交叉验证后预测值和实际值的决定系数R2、校正标准差(RMSEC)以及模型预测后的决定系数R2、预测标准差(RMSEP)可以看出,总的来说PLS 对原始光谱的建模要优于PCR 对原始光谱的建模。由表3 可知,通过偏最小二乘法所得的模型,在波段为500~1 600 nm 范围内,交叉验证得到最大的R2和最小的RMSEC值,分别为0.995 5和0.108 1;并且用这个模型预测验证集,所得到的R2和RMSEP值也最理想,分别为0.872 7 和0.493 2。
因此,500~1 600 nm 为PLS 建模的最适谱区。而由表4 可知,通过PCR 所得模型的最适谱区为800~1 400 nm。产生这个差异的原因尚未弄清有待进一步研究,本文不做讨论。
3.3 不同光谱预处理方法对结果的影响
本试验采用一阶微分和二阶微分这2 种常用的光谱预处理方法,并且比较原始光谱、一阶微分光谱和二阶微分光谱所建模型的预测能力。对可溶性固形物进行建模时,采用偏最小二乘法、主成分回归法2 种不同的数学校正法,并分别在其最适谱区内建模,最后对2 种模型进行比较讨论。
利用PLS 和PCR 对不同预处理光谱进行建模,预测模型结果如表5 所示,由表可知,PCR 和PLS 的预测能力有明显差别。比较PLS 和PCR 分别基于原始光谱、一阶微分光谱和二阶微分光谱的模型,PLS 普遍具有较高的R2值及较小的RMSEC 值和RSMEP 值,表明PLS 法更适于草莓的建模分析。

表5 建模和预测模型结果
从分析结果来看,对样品的原始光谱采用一阶、二阶微分处理后的PLS 预测模型的拟和度及预测效果有一定的差异,由好到差依次是:原始光谱、一阶光谱、二阶光谱。单看PLS 模型,一阶光谱与二阶光谱所建立的校正模型,其决定系数R2相差不大,分别为0.943 2、0.943 1,而与原始光谱相比,其决定系数R2为0.995 5,都有相对较大的差距。
再比较各种不同光谱预处理后的PCR 模型,也可以发现,基于原始光谱建立的模型效果最好,其决定系数R2为0.992 9。而一阶微分、二阶微分处理后预测效果大大降低,决定系数分别为0.491 1、0.216 9。
以上结果说明,原始光谱所建模型的性能最好,一阶微分和二阶微分处理并没有提高模型的预测能力。对于草莓可溶性固形物的近红外光谱检测,原始光谱比微分光谱更适合于建模。
进行综合比较后发现,3 种不同光谱预处理方法所得到的验证决定系数R2、校正标准差(RMSEC)以及模型预测后的决定系数R2、预测标准差(RMSEP)都存在比较大的差别。因此,在建模过程中,要反复比较、慎重选择,力求选择的谱区、光谱预处理方法和建模方法为最佳搭配。
4 结论
随着仪器和光谱处理化学计量学软件及相应各类应用模型的开发,近红外光谱技术作为一种快速及绿色的分析技术将会被应用在越来越多领域中。
目前,在仪器的研发方面,更加注重高信噪比、高稳定性、低检测极限、便携、价廉等要求;在应用方面,突出在线、实时、远程、结果可靠等概念。因此,笔者认为在未来的研究工作中应以这些为导向,完善仪器、优化软件,使近红外光谱技术发挥更大的作用。
