机器阅读理解研究与进展
2023-04-07王浩畅闫凯峰MariusGabrielPetrescu
王浩畅 闫凯峰 Marius Gabriel Petrescu
1(东北石油大学计算机与信息技术学院 黑龙江 大庆 163318) 2(普罗耶什蒂石油天然气大学 普拉霍瓦 普罗耶什蒂 100680)
0 引 言
随着人工智能时代的到来,自然语言处理(Natural Language Processing, NLP)成为当前一个炙手可热的研究课题。NLP的研究目标就是使得机器能够理解人类语言,而NLP的核心任务之一就是自然语言理解,因此机器阅读理解(Machine Reading Comprehension, MRC)受到了研究人员的极大关注。
MRC现在被应用在各种实际领域(军事、司法、医疗等)中,如中电莱斯信息系统有限公司主办的全国第二届“军事智能机器阅读”挑战赛,从文字情报整编业务面临的实际痛点问题为切入点,旨在由机器筛选出多篇文字情报中用户所关心的活动时间、地点、性能参数等中心内容,这充分说明MRC在实际应用中有着重要的意义。
1 国内外研究现状
20世纪90年代末,MRC的早期研究与NLP很多任务一样都是使用基于规则的方法,其中QUARC[1]就是一个比较有代表性的系统,该系统使用词汇与语义对应关系规则在预测正确答案时达到了40%的准确率;Charniak等[2]使用字符串模式匹配手动生成规则在检索正确答案时可以达到41%的准确率。
随着统计机器学习在NLP领域的快速发展,MRC的性能也得到了进一步的提升。MRC任务要求根据已知信息(文章、问题)生成对应的答案。通常表示为根据已经给定的文章P以及人类根据该文章提出问题Q,再使用MRC技术预测该问题的正确答案A,表示为
2014年Jansen等[3]通过手动提取篇章中的语义特征,使用支持向量机(Support Vector Machine,SVM)分类模型,并且在预测答案时使用答案排序的方法,最终在Yahoo问答语料库上将准确率提高了24%。
2015年Narasimhan等[4]通过提取句子语法和词汇特征,并使用传统的机器学习方法在MCTest数据集[5]MC500上将准确率提升到63.75%。Sachan等[6]手动提取特征并使用改进的SVM方法在相同的数据集上,将MRC任务的准确率提升到67.8%。Wang等[7]将语法、语义、词向量等特征作为输入,使用机器学习分类模型,将准确率提升到69.87%。
实验结果表明,这些传统机器学习方法在很大程度上提升了阅读理解任务的准确率。但使用基于传统机器学习的方法去解决MRC任务,也存在一些缺陷:(1) 使用机器学习方法,需要人工去提取词汇和语义特征,但是一些分散到文本中的语义特征很难通过手工方法提取出来;(2) 传统的机器学习的方法需要大规模的数据集为模型提供更好的数据支撑,但之前提到的MCTest数据集,可用于训练的总数据只有1 480条。因此,受到数据规模的限制,以及手动提取特征的难度,传统的机器学习方法很难再有突破性的进展。
2015年,由Hermann等[8]构建了大规模数据集CNN/Daily Mail,并提出将注意力机制加入长短时记忆网络模型(Long Short-term Memory,LSTM),最终在CNN数据集上得到了63.8%的准确率,在Daily Mail数据集上得到69.0%的准确率。此后陈丹琦等[9]使用改进后的基于注意力的神经网络,在CNN和Daily Mail上分别取得了73.6%和76.6%的准确率,并且通过实验证明CNN/Daily Mail数据集含有较大的数据噪声。
斯坦福大学Rajpurkar等[10]在2016年构建了一个包含107 785个问题的数据集SQuAD1.1。同年Wang等[11]针对该数据集提出Match-LSTM模型并得到了77.1%的F1值。Seo等[12]提出的BiDAF模型,在该数据集上得到77.3%的F1值。2017年,陈丹琦等[13]提出的单模型的Document Reader得到79%的F1值。2018年,Yu等[14]提出的QANET模型进一步将F1值提升至84.6%。随着2018年谷歌的Devlin[15]等BERT模型的提出,并在该数据集上取得93.2%的F1值,深度神经网络模型在此数据集上已经首次超越人类的86.8%的F1值。2019年Yang等[16]提出的XLNet在该数据集上取得95.08%的F1值;同年Lan等[17]提出的ALBERT在此数据集上得到95.5%的F1值。2020年Brown等[18]提出了GPT-3模型,与之前的预训练模型的不同之处是该模型在预训练好模型之后,只需要使用少量的MRC样例去使得模型适应新的MRC任务,而不需要像之前的预训练模型一样进行梯度更新和模型的微调。
国内也有大量研究人员对中文机器阅读理解(Chinese Machine Reading Comprehension, CMRC)进行了深入研究。文献[19-20]提出基于知识库的模式匹配方法;文献[21-22]在CMRC任务上也做出了一些贡献;2016年哈工大讯飞联合实验室构建了CMRC数据集[23];2017年百度公司构建了大规模CMRC数据集Du-reader[24],这是迄今为止最大的CMRC数据集;在2018年“百度机器阅读理解”大赛中,基于多任务的MRC模型[25]、分层答案选择模型[26]、多段落MRC模型[27]、BiDMF[28]都获得了优异的成绩。2019年,哈工大讯飞联合实验室根据BERT[15]模型提出了中文全词覆盖BERT预训练模型[29],该模型改进了BERT模型处理中文文本的能力。
2 相关数据集与评测方法
大规模数据集的出现,使得深度神经网络得以充分发挥其在MRC人物上的优势。与此同时,评测方法也尤为重要。本节将介绍国内外主流的MRC数据集,以及在这些数据集上所使用的评价方法。
2.1 相关数据集
神经MRC的研究必须依靠大规模的数据集作为支撑,它在一定程度上决定了MRC系统的性能。为了降低任务难度,较早出现的MRC数据集都将背景知识排除在外,因此可以通过人工构造简单的数据集去回答一些相对简单的问题。MRC数据集最常见的形式包括完形填空式(Cloze Style, C)、选择题类型(Multiple Choice, M)、段落抽取式(Span Prediction,S)及自由作答方式(Free-form Answer, F)[30]。本节将着重介绍CNN/Daily Mail[8]、SQuAD、Dureader[24]和MS MARCO[32]几个主流MRC数据集。此外还对一些其他MRC数据集在数据规模、发布时间、数据来源等方面做了统计,如表1所示。其中,EN表示英文,ZH表示中文。
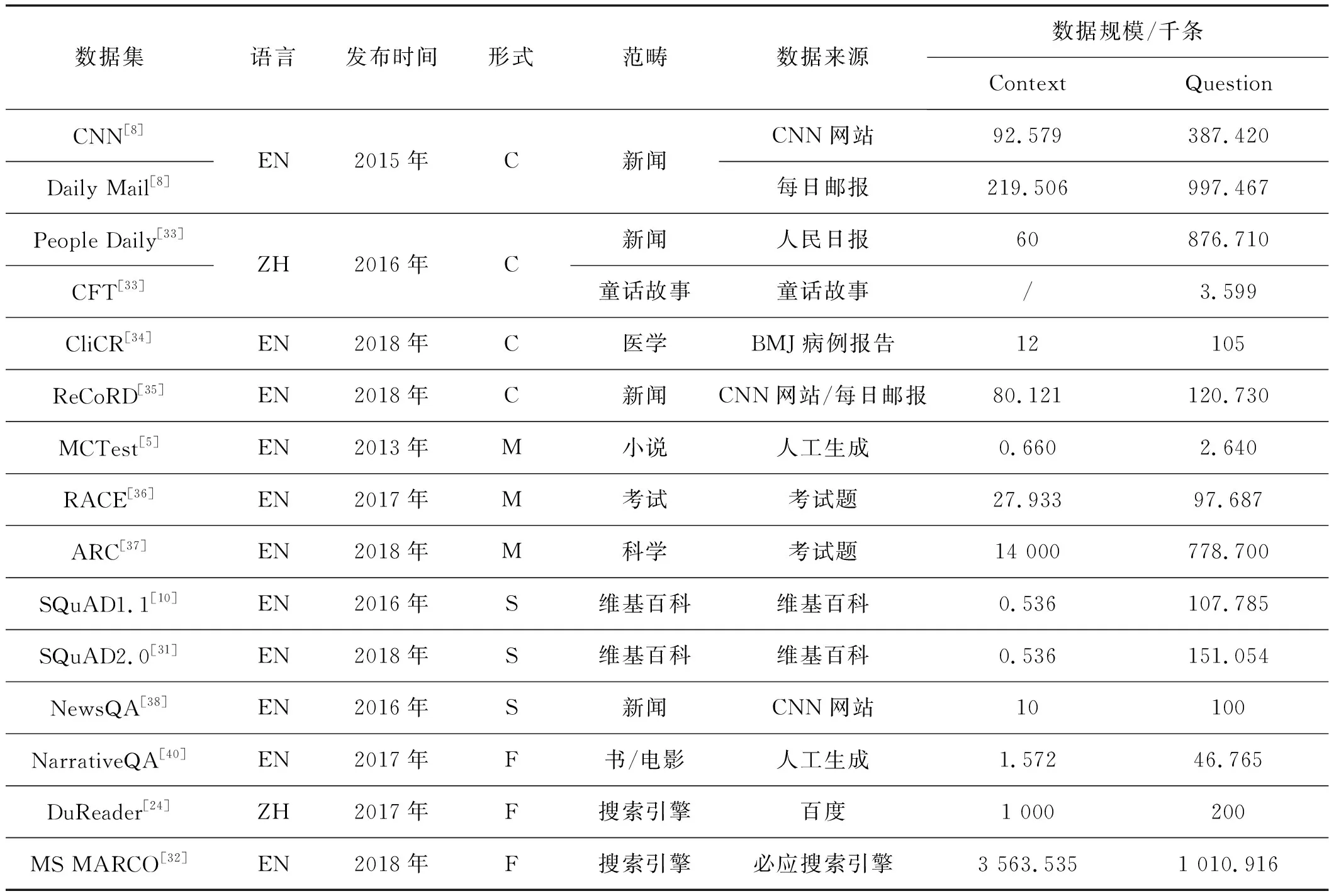
表1 当前主流的MRC数据集比较
CNN/Daily Mail是2015年发布的一个完形填空数据集。CNN包含了从2007年到2015年在CNN网站收集的92 579篇文档以及从中提取的387 420个问题;Daily Mail包含了从2010年到2015年在每日邮报(Daily Mail)网站收集的219 506篇文档以及从中提取的997 467个问题。由于这两个网站是通过要点(bullet points)补充文章,并总结文章中包含的信息,因此作者通过替换这些要点的方式创建问题。该数据集的任务目标就是根据文章内容推断出问题中缺失的实体。
SQuAD1.1[10]是斯坦福大学于2016年构建的一个段落抽取式数据集,该数据集采用众包的方式从维基百科的536篇文章中提取了107 785个问题。它定义了一种全新的MRC任务,即问题的答案是文章的一部分,而非一个实体或者一个词;正如之前所介绍的MRC发展现状,现在的一些深度学习模型的表现已经超越了人类,为了增加任务难度,研究人员于2018年在SQuAD1.1基础上加入了53 775个由人类众包者对抗性地设计的没有材料支持的新问题,生成了全新的SQuAD2.0数据集。该任务要求对于这些问题,在作答时不仅要尽可能给出问题的正确答案,还需对没有材料支持的问题拒绝作答。斯坦福大学为SQuAD2.0数据集开放了一个在线评测模型的网站[56]供已提交的模型在该数据集上的评分及排名。
DuReader是当前规模最大的CMRC数据集,该数据集由百度搜索与百度知道的100万篇文档以及从中提取的20万个问题组成,答案是通过众包方式生成。该数据集属于自由作答型,即答案可能并不在给定的文档中,比如观点型、是非判断型。百度开放了一个在线评测网站[57]供已提交的CMRC模型评测及排名。
MS MARCO包含了从Bing搜索引擎检索到的8 841 823篇文章以及从中提取的1 010 916个问题,而每一个问题对应的答案是由人工生成的。微软开放了一个在线评测模型的网站[58]供提交的MRC模型在该数据集上评测及排名。
由于当前百度公司与微软公司开放了较全面的MRC数据集,而且
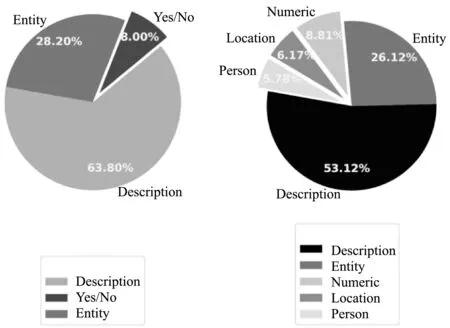
(a) DuReader (b) MS MARCO图1 DuReader与MS MARCO的不同问题类型分布
2.2 相关评测指标
对于段落抽取式MRC数据集,更多使用的是评测SQuAD时所使用的精确匹配(Exact Match,EM)以及F1值。通常将BLEU和ROUGE-L作为自由作答型数据集的评价指标。
首先介绍候选答案和参考答案构成的混淆矩阵,这里的候选答案即预测答案,参考答案即真实答案。该混淆矩阵包括真正例(True Positive,TP)、真负例(True Negative,TN)、假正例(False Positive,FP)、假负例(False Negative,FN),可以表示为如表2所示的混淆矩阵。

表2 重叠词构成的混淆矩阵
那么预测答案的P和R可以表示为:
F1为P与R的调和平均数,可以表示为:
EM表示预测答案与给定答案完全一致的数量占全部问题数量的比率,如式(4)所示。与F1相比,EM更加精确,也更加严格。一般而言,F1都比EM值大。
BLEU(Bilingual Evaluation Understudy)是从机器翻译中引入的评价指标,是一种文本精确度的相似性度量方法。为了度量候选答案与标准答案的相似性,BLEU的计算方法如下:
(5)
式中:n表示n元语法模型,n元语法指的是n个连续的同现词。定义参考答案的长度为r,候选答案长度为c。对于多个参考答案的情况,我们选择最接近c的参考长度,长度惩罚因子(BP)为:
C为候选答案的i元语法模型的集合,式(7)计算整个候选答案的精确度Pi,定义Count(x)表示该词出现在候选答案中的次数。
(7)
假设某个词出现在参考答案中的总次数为Max_Ref_count,则有:
Countclip=min(Count,Max_Ref_Count)
(8)
ROUGE-L计算的是参考答案和候选答案最长公共子序列的精确率(PLCS)和召回率(RLCS):
式中:γ=PLCS/RLCS,如果γ过大,则只需考虑RLCS。
3 神经机器阅读理解模型
根据当前MRC数据集的评测结果可以看出,神经MRC模型是当下解决MRC任务行之有效的方法。本章将介绍神经MRC模型的实现过程,并将对每一个步骤的详细原理进行介绍,此外还介绍了四种解决MRC任务的极有代表性的MRC模型。神经MRC过程总体上包括向量化、编码、注意力机制[42]、答案预测四个步骤,其结构如图2所示。
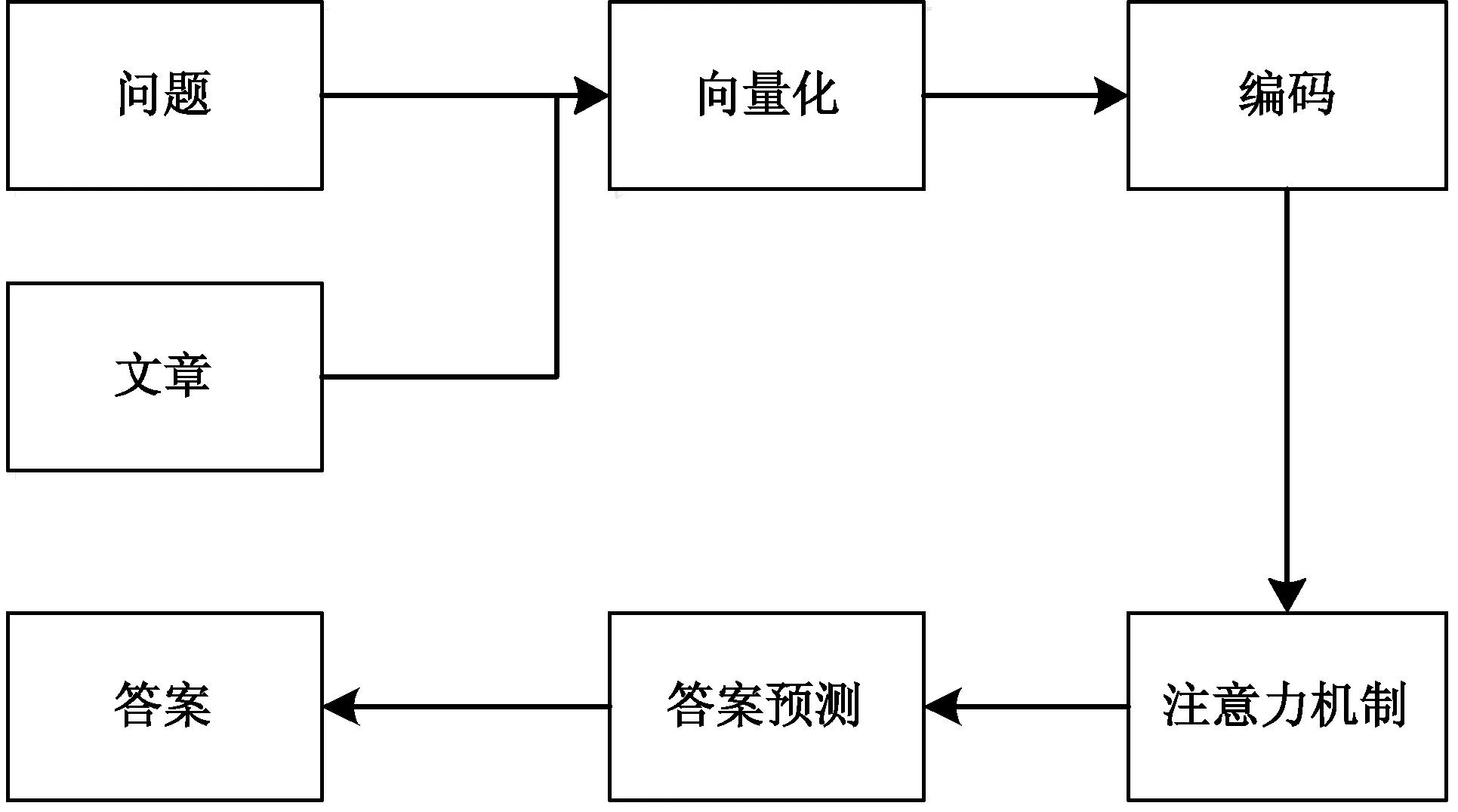
图2 神经MRC整体架构图
3.1 向量化
向量化目的是让计算机可以识别人类语言,在NLP领域,一般是将文字转化为计算机可以识别的定长向量。不同的编码方式所达到的效果也有所不同。在人类语言中语境是尤其重要的信息,因此很多研究人员一直致力于将更多的语境信息传递给计算机。早期自然语言转换为词向量通常使用One-Hot[43]编码,该方法使用二进制向量表示不同的单词,其维度与文本词典大小相同。构造的向量只有该词对应的位置为1,其余位置都是0。但是由于这样的向量比较稀疏,所以这种方法更适合文本量较小的情况,一旦文本增多,就会导致维度灾难。
因此,为了解决传统词向量的不足,Mikolov等[44]提出了Word2Vec词向量,该词向量通过语言模型训练而成,可以充分利用单词之间在向量空间的距离去衡量词之间的相似性。之后Pennington等[45]提出了Glove词向量,它将词汇编码成可以反映词汇之间的相关性的连续低维向量。但是不足之处是以上这些词向量方法只能简单地提取出词汇间的关系,但不能有效挖掘上下文信息。随着NLP技术的发展,2018年Peters等[46]通过双向语言模型为每个词添加了上下文信息,即实现了深层语境的词汇表示,简称ELMo预训练词向量。这种词向量模拟了词汇更加复杂的特征,并且分析了这些用法在不同的语境中如何变化(如一词多义现象)。同年Devlin等[15]发布了BERT预训练词向量,与ELMo不同的是该方法通过在所有层中联合调节每个词的关联上下文来预先训练文本的深层双向表示。近期ALBERT[17]预训练模型以其出色的性能,再一次向我们证明预训练词向量在MRC任务中举足轻重的作用。
3.2 编 码
编码在MRC中是一个极其重要的步骤,目的是提取更多的语境信息。通常使用循环神经网络(Recurrent Neural Network,RNN)、其变体LSTM与门控循环单元(Gated Recurrent Unit, GRU)、卷积神经网络(Convolutional Neural Network,CNN)以及Transformer架构来对输入的词向量进行编码。
RNN是NLP领域应用极其广泛的模型,该网络有很强的序列信息提取能力。其变体LSTM和GRU利用其门结构更加擅长捕获序列的长期依赖,而且这二者有利于缓解梯度爆炸和梯度消失问题。由于在理解给定的单词时,其上下文具有相同的重要性,因此通常使用双向RNN对MRC系统中的上下文及问题进行编码和特征提取。虽然RNNs在序列信息上表现很好,但是由于不能并行处理,所以使用这种网络结构非常耗时,而且极易出现梯度消失和梯度爆炸的问题,因此通常使用其改进模型LSTM或者GRU。相较而言,一般认为GRU可以节省大量的训练时间,其原因是GRU有更少的模型参数。
CNN是从计算机视觉中引入的一种深度学习方法。一维的CNN应用于NLP任务时,利用滑动窗口挖掘局部上下文信息非常有效,首先在CNN中每个卷积层应用不同比例的特征映射来提取不同窗口大小的局部特征,之后将输出反馈到池化层降低维数的同时最大程度上保留最重要的信息。另外,在每个筛选器结果上取最大值和取平均是池化层最常用的方法。
Transformer是Vaswani等[47]在2017年提出的一种新型神经网络模型。与RNN和CNN不同的是,Transformer主要使用注意力机制,由于加入了多个方向的注意力,使得这种结构在对齐方面表现突出,而且与RNN的不同之处是可以并行运行,因此运行时间更短。与CNN最大的区别是,它更加关注全局特征。但是如果没有CNN与RNN,Transformer就不能更好地利用序列信息,为了整合位置信息,作者添加了正弦和余弦函数去计算位置信息。Transformer的模型输入是词汇的编码以及每个词的位置信息,通过对输入进行编码提取上下文信息,最后输出解码后的新序列。
3.3 注意力机制
MRC系统中,注意力机制一般可以分为三种,单向注意力机制(Unidirectional Attention)、双向注意力机制(Bidirectional Attention)和自匹配注意力机制[47](Self-Attention)。
添加单向注意力是为了突出问题与上下文文本最相关的部分,这种方法对于强调重要的语境词很有效果。通常情况下,我们认为问题与文本中词或者句子越相似,越有可能是答案。但是,其弊端在于太强调语境词从而忽略了预测答案的一个关键因素——问题关键词。因此又有研究者提出使用双向注意力机制来克服单向注意力机制的这一局限性。如图3所示,在MRC中首次加入双向注意力机制的是BiDAF[12]模型,该模型既关注了文本到问题,同时也关注了问题到文本两个方向的信息交互。之后Wang等[48]提出自匹配注意力机制,即通过文本段落与其自身匹配来完善信息交互,并取得了很好的效果。
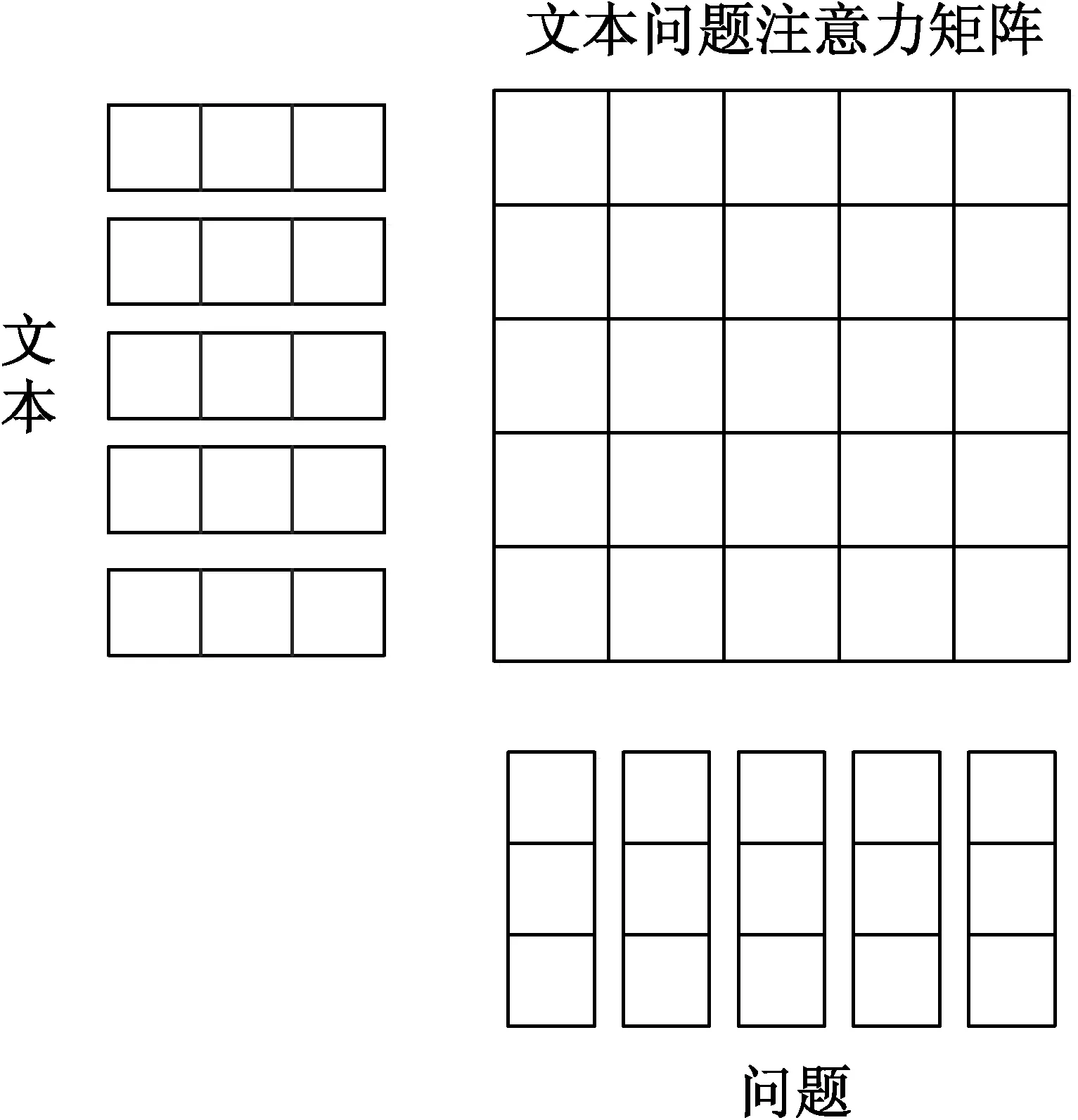
图3 问题文档的双向注意力机制
3.4 答案预测
不同的MRC数据集,预测答案的方法也不相同。整体上可以划分为三种,第一种是从文本中提取答案,以CNN/Daily Mail为代表,它们都有一个共同的特点,就是从给定文本中预测一个词或者一个实体作为答案。另外一种以SQuAD数据集为代表,答案都是段落中的某句话。最后一种就是根据对应文本生成答案,最终答案分布在多个段落中或者答案不一定在给定的文本中,主要以DuReader和MS MARCO为代表。
对于从文本中提取单个词汇的MRC类型,受到指针网络[49]的启发,Kadlec等[42]提出使用注意力机制直接从文本中寻找问题答案。对于段落抽取型数据集,答案预测的关键在于找到答案的开头和结尾。考虑到可能存在多个候选答案的情况,Xiong等[50]提出了DCN迭代技术筛选最终答案。
对于自由作答式数据集,候选答案并不要求与参考答案完全一致。这类问题有一个共同之处,就是每一个候选答案分布在不同段落中。解决这类问题的思想就是,从每一个相关段落中提取候选答案的一个小片段,最后将选取出来的小片段组合作为最终的预测答案。Tan等[51]提出S-Net方法,使用基于注意力的GRUs将与答案相关的每一个片段的起止点找到,最后综合这些小片段形成预测答案。
3.5 常见的MRC模型
表3所呈现的是按照以上四个步骤对当前主流的方法做的总结和概括,主要介绍了当前主流的MRC方法的结构及其实验针对的数据集。接下来将介绍几种解决MRC任务中极具代表性的MRC模型。
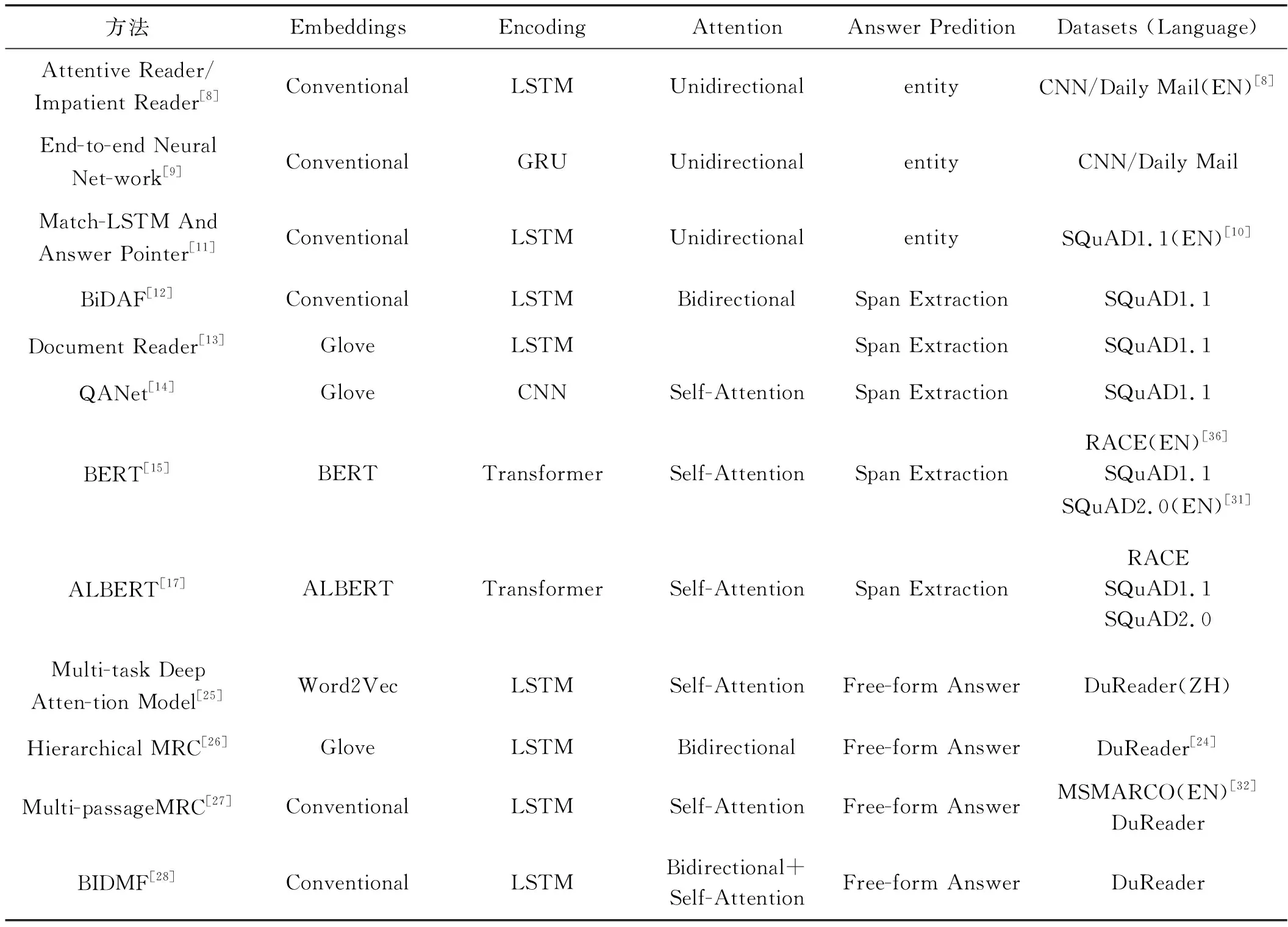
表3 当前解决MRC任务的主流方法
Hermann等[8]为评测完型阅读理解型数据集CNN/Daily Mail,同时发布了两个基线模型Attentive Reader[8]和Impatitent Reader[8]。它们都使用的双向LSTM词嵌入的方法,并且都加入了注意力机制,但是二者不同之处在于对给定的文本段落和问题的处理方式不同。Attentive Reader更加注重将查询作为一个整体,与给定的文本做交互,以达到查询答案的目的;相较而言,Impatitent Reader更加复杂,它把查询中的每一个词与给定文本做交互,以此达到更加全面详尽的目的。如图4所示,Attentive Reader模型(作者原图)为了预测单词x,使用双向LSTM作为嵌入层,并在其输出上加入注意力机制,从而使得给定文本与对应查询进行交互。如图5所示,为Impatitent Reader模型(作者原图),不同之处是对查询中每个词与给定文本进行注意力交互。
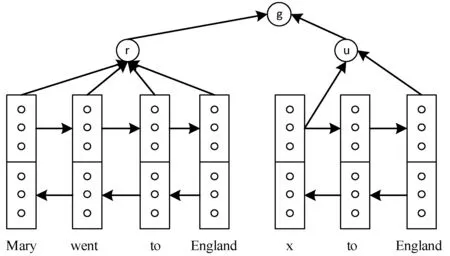
图4 Attentive Reader模型框架
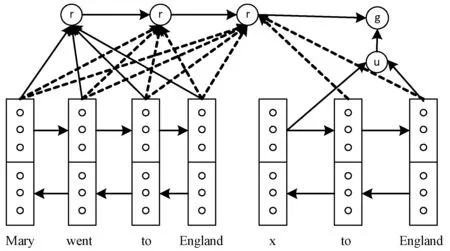
图5 Impatitent Reader模型框架
之后的改进大多数是以这两个模型为基础。随着注意力机制在NLP领域的应用逐渐深入,在MRC中应用也极其广泛。下面介绍一种在MRC任务中有着极其重要地位的BiDAF模型,如图6所示,该模型首次提出在MRC模型中加入了双向注意力流机制,模型共划分为六层。
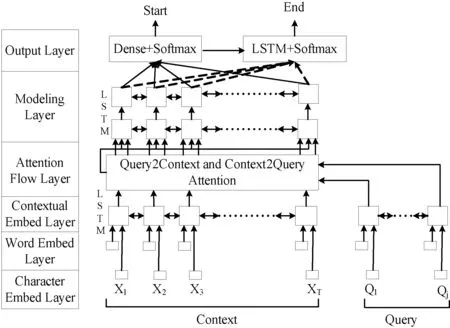
图6 BiDAF模型
字符嵌入层(Character Embed Layer),该层是将输入文本转化为以字符为单位的字符向量。
词嵌入层(Word Embed Layer),该层主要将输入文本表示为词向量的形式,并与上一层一起作为下一层的输入,该层使用Glove[44]词向量。
上下文嵌入层(Contextual Embed Layer)使用双向LSTM对上层输入的词向量进行编码,目的是使得上下文进行充分交互。
注意力流层(Attention Flow Layer),该层是该模型的主要改进之处,模型通过加入双向注意力流,也就是文本到问题的注意力流和问题到文本的注意力流两个方向,主要目的是考虑到模型中文本与问题的交互不够充分。
模型层(Modeling Layer),该层使用两层双向LSTM查找问题在文本中的详细位置。
输出层(Output Layer),该层预测答案的开头与结束位置,开头位置使用全连接层与Softmax函数进行预测,结束位置使用LSTM与Softmax进行预测。
随着预训练模型的发展,预训练词向量逐渐在MRC任务中崭露头角,它也正逐步取代传统的词向量,特别是在BERT预训练模型的发布之后,MRC任务的表现也得到了极大的提升。如图7所示,BERT模型分为预训练和微调两个阶段,预训练阶段使用掩码语言模型、下一句预测任务进行训练,之后在微调阶段对其进行微调。掩码语言模型是BERT预训练词向量的核心思想,它通过双向Transformer对给定语句的15%词汇进行随机掩码的方式来达到深度训练的目的,它将句子长度限定为512个词;为了深度理解句子与句内词汇的语义关系,它使用了下一句预测任务对BERT进行预训练。由于预训练出的参数已经确定,因此并不能很好地支持下游任务,因此模型的微调是为了适应下游任务而对其数据集进行的调整参数的训练。
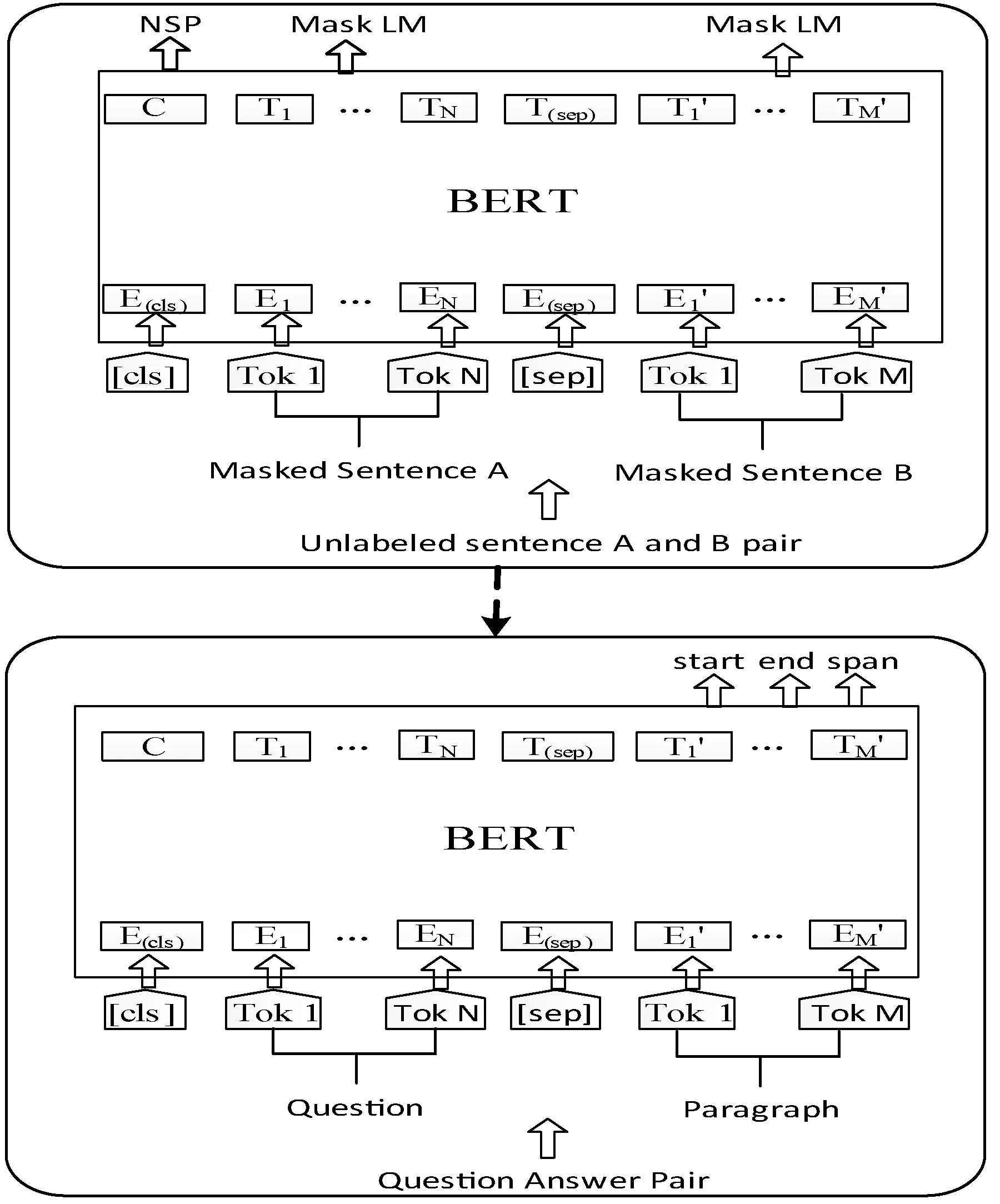
图7 BERT模型框架
4 MRC面临的问题
MRC技术不断地迭代更新,推动着MRC任务的向前发展,同时也促进了整个NLP领域的进步。在某些特定情境下,MRC模型的性能已经超越了人类的表现(如SQuAD1.1数据集),但仍然存在一些问题。
1) 资源耗费巨大。正如本文之前讨论过的,词向量层是MRC模型中不可或缺的输入层,该层的目的是将给定的文本与问题信息最大化地输入模型中,以期问题与文本之间的最大信息交互。但是通常会遇到难以均衡资源耗费与充分的上下文信息的问题:(1) MRC早期通常使用较为简单的词向量(如Word2Vec、Glove),但其不足之处在于难以有充分的上下文信息,这导致在数据输入模型的过程会产生一定的损耗,以致文本与问题之间的信息交互不够完全。(2) 预训练词向量(如ELMo、BERT、XLNet、ALBERT、GPT3)的出现解决了这一难题,这些词向量加入了更全面的上下文信息,使得文本与问题的完全交互成为了可能,但是它们的应用又引发了新的问题,那就是资源耗费过大。例如当下性能最好且资源消耗相对较少的ALBERT预训练词向量,它使用谷歌公司的TPU集群训练125 000步拥有23.3亿个参数的ALBERT预训练模型总共花费32小时,更有GPT-3将参数量提升至1 750亿,显然普通科研团队或机构的硬件很难达到这种要求。因此如何在拥有充分的文本与问题上下文信息的同时最大限度降低MRC模型训练时的资源耗费,这是MRC当前遇到的一大挑战。
2) 模型缺乏推理能力。大多数现有的MRC系统主要基于上下文和问题之间的语义匹配来给出答案,这导致MRC模型难以推理。推理能力其实是一种更高层次抽象信息的提取能力,这要求模型按照人类的逻辑推理能力提取抽象信息。虽然预训练模型可以生成较全面的上下文信息,但是事实上将其应用在MRC任务中,对于模型的推理能力仍然没有太大的改进。但不可否认的是推理能力会极大地改进模型的性能并有助于提升其他NLP子任务的表现,因此如何使MRC模型具有推理能力仍需进一步研究。
3) 模型通用性有待提升。如果模型是通用的,则其也可能适用于其他任务,此外该机器是否真的通过利用神经网络方法“理解”了人类的语言,而不仅仅是充当了“文档级”语言模型。这对于其他的NLP任务也是至关重要的,即并非由给定的文档解决MRC任务,而是模型真正在“理解”人类语言的基础上进行解答。如何设计一个通用而非专门针对某一特定领域或特定数据集的MRC模型也须进行深入的研究。
4) 模型缺乏健壮性。现实生活中,遇到的更多阅读理解问题与自由作答型数据集更加接近,但是现有模型在这解决这些问题时效果仍旧不理想。对于SQuAD2.0,通过在给定的上下文中添加了分散注意力的句子,并且这些句子与问题的语义重叠可能引起混乱,但不会与正确答案相矛盾,通过此类对抗性示例,MRC模型的性能急剧下降,这反映出机器无法真正理解自然语言,此外已有的MRC模型在DuReader与MSMARCO数据集上的表现相对来说也是比较差的。尽管可以通过引入答案验证组件在某种程度上减少合理答案的副作用,但增强MRC系统的健壮性以应对对抗性环境仍然是一个挑战。
5 MRC发展前景
事实上,日新月异的MRC技术也在推动NLP领域的飞速发展。通过整理近年来经典的MRC模型以及参考其他在经典模型上的改进工作,下面将给出MRC技术的几个可能的发展方向。
1) 改进预训练模型速度与效率。预训练模型在改进MRC输入上下文信息的同时也带来了训练资源耗费巨大的问题。在未来可以通过稀疏注意力(sparse attention)[52]和块注意力(block attention)[53]之类的方法来加快预训练模型的训练速度,以此应对预训练模型资源损耗的挑战。
2) 如何提升MRC模型的推理能力。其实MRC模型的推理能力一直有待提升,这就像就是像人类推理某一个问题一样,并不依靠外部的知识,而只依据已有知识对问题进行推理,从而得出更加正确的预测答案。Chen等[54]提出将知识图谱这种新型的知识表示形式应用于知识推理中,因此MRC模型的推理能力也可以借助知识图谱去改善,当问题复杂且知识库不完整时,知识图谱能够利用现有的三元组推断出更加合理的答案。通过知识图谱中的现有事实中推断出许多有效事实,这是将知识图谱用于推理的目标之一,其目的是将实体和关系表示到低维的向量空间[55]。
3) 如何改进MRC模型的通用性。实验表明,MRC模型或者只在特定的数据集上表现良好,但是更换多个不同的数据集后性能却会受到影响,甚至是性能急剧下降。在很大程度上,这其实也是由于深度学习模型的可解释性较差,模型本身是一个“黑盒”,在对其进行研究的实验的过程中,难以从细节处做根本性的改进。但是,未来可通过增广数据的方式对已有数据进行扩增,庞大的数据量有助于提升模型的通用性,此外,从文中的四个模块改进MRC模型性能也有利于提升其通用性。
4) 如何提升MRC模型的健壮性。可以考虑加入新的特征(如词性标注、命名实体识别、依存句法分析、语义依存分析等)以改进模型的健壮性,另外可以通过在数据中添加额外的噪声或者像SQuAD2.0一样增加对抗性语料,以改进MRC模型的健壮性。
6 结 语
本文介绍了国内外MRC技术的发展历史及其现状,内容主要包含MRC数据集、MRC主要模型方法以及一些自然语言处理界通用的评价方法。由于深度学习技术的飞速发展,基于深度学习方法的应用解决了MRC中遇到的很多难题,因此本文主要从应对MRC任务最有效的深度学习方法的角度进行了研究讨论,首先总结了神经MRC任务的一般步骤,紧接着阐述了每一个步骤中所涉及的开创性技术,最后对MRC面临的问题做了详尽的概括,并针对性地提出了行之有效的解决方案。
