基于图神经网络的推荐系统模型
2023-04-07邵新慧
林 幸 邵新慧
(东北大学理学院 辽宁 沈阳 110819)
0 引 言
随着科学技术的不断进步,用户获得和浏览信息的方式产生了翻天覆地的变化,信息量呈爆炸式增长,带来了信息过载问题,这种问题使人们对有效信息的筛选变得十分困难。为解决以上难题,推荐技术的应用逐步进入了人们的生活,通过利用用户与项目的历史交互数据,对用户未观测到项目的感兴趣度进行预测,并对预测结果进行排序,并推荐给相关用户。
1994年基于商品的协同过滤算法首次由Resnick等[1]提出,其原理简单,效果显著,是目前为止在推荐系统领域应用最广的技术。传统的协同过滤算法主要分为基于用户的协同过滤UserCF、基于物品的协同过滤ItemCF[2]和基于模型的协同过滤和依托于机器学习模型的协同过滤,通过对模型进行离线训练和优化,在线进行推荐。尽管协同过滤算法在应用领域已经取得了巨大的成功,但是对于解决数据冷启动和数据稀疏性问题仍然面临着巨大的挑战。深度学习利用海量的数据,挖掘并学习用户和物品之间的深层交互信息,能够提高推荐的准确率。因此,目前研究基于深度学习的协同过滤方法成为了一个热门的问题。
在2016年召开的ACM学术会议中,成功举行了第一届基于深度学习的推荐系统专题研究讨论会,提出深度学习的重要研究方向。近年来,深度学习与推荐相结合的学术论文在各个领域的顶级学术会议中也逐渐增多[3-5]。由于传统的推荐系统无法挖掘用户与电影之间更深层次之间的关系,同时也无法解决数据稀疏性的问题,图神经网络将用户与物品之间的交互信息作为二部图传入到神经网络中可以更好地解决数据稀疏性的问题,且通过用户与物品之间的连通关系能够让用户与物品的特征表示更加的具体。
因此,本文提出一种结合注意力机制的图神经网络模型来解决推荐算法中存在的问题。通过用户与物品的历史交互行为数据,对用户与物品之间建立二部图,挖掘它们之间的高阶连通性,并且在模型中引入注意力机制,对不同层之间的特征表示赋予不同的重要程度,使得用户的特征表示包含了对不同层物品的偏好程度,而物品的特征表示也包含了对不同层用户行为的偏好,丰富了特征表示,从而改善了模型的性能。
1 相关工作
在20世纪90年代首次在视觉图像领域提出了注意力机制的概念,但是真正让其变得热门是在2014年Mnih等[6]提出了一个新的注意力视觉模型,它能够将视网膜集中在相关的区域上,并且忽略不重要的信息从而进行图像分类。Bahdanau等[7]将注意力机制应用到机器翻译中,是第一次将注意力机制应用在自然语言处理领域中。注意力机制因其具有捕获特征之间不同重要性的能力而被广泛应用在各个领域。同时2017年出现大量注意力机制与推荐系统相结合的论文,Wang等[8]将注意力机制应用到新闻推荐中,将新闻的文本内容作为输入,考虑新闻数据具有的时序特点,应用注意力机制考虑了不同时间对新闻有不同的影响程度,最终的输出为是否会对该新闻进行推荐。Seo等[9]提出基于局部和全局的双层注意力机制的CNN模型,利用商品的评论和评分数据进行建模,最终得到推荐结果。Chen等[10]认为用户的正向反馈数据并不一定是对该项目的喜爱,例如朋友圈点赞数据,可能仅仅是因为大家都点赞所以用户也进行同样的操作。根据上述的现象提出利用对不同层级的反馈分配不同的权重,根据用户的喜好进行建模。Zhou等[11]在阿里的商业广告CTR预测中引入注意力机制来更精准地捕获用户的兴趣点。
近年来图神经网络迅速发展,已经成为了深度学习中最热门的技术之一。Kipf等[12]在2017年的ICLR会议中首次提出GCN的概念,GCN是CNN的变体,用于处理基于图的数据。基于图表示的学习模型,通过堆叠多层卷积聚合运算和非线性激活运算得到最终特征表示。近两年有很多的学者在基于协同过滤的推荐系统中,通过将用户与物品之间的历史交互行为视为二部图,利用GCN捕获了用户与物品之间更高层次的协作信号。这些基于GCN的推荐系统与传统的推荐系统相比,性能更加优越。Rianne等[13]提出了一个图自动编码器,其中包含了一个卷积层,通过在双向用户项上传递消息来构建用户和项目的嵌入。Ying等[14]提出结合图卷积与随机游走的方法,生成了同时包含项目与用户节点特征的信息,进一步改善了模型的鲁棒性和收敛性。Wang等[15]设计了一个新的嵌入传播层可以根据用户与项目之间的高阶连通性,捕获它们之间的高阶协作信号。但在通过卷积进行信息聚合运算后,没有考虑到不同层输出的表示特征之间的相关性。因此,本文引入注意力机制为不同层之间的信息赋予不同的重要性,在进行卷积信息聚合后对不同层之间的特征进行注意力层的操作才可以使节点的最终特征表示更加完善。
2 模型设计
2.1 特征初始化
本文的模型框架如图1所示,分为特征初始化,嵌入传播层和预测层。
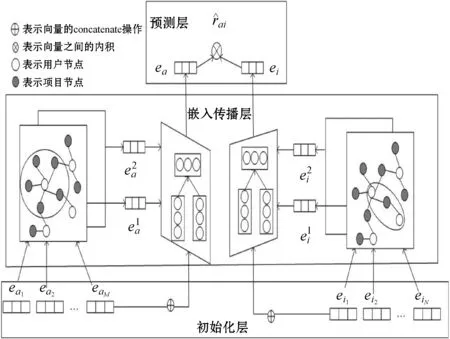
图1 模型整体框架图
在大多数的推荐中直接将初始特征输入到预测层,得到预测评分。而本文将ID信息作为初始特征,通过嵌入传播层,可以更好地捕获协同过滤信号。初始特征表示如下:
E0=[ea1,ea2,…,eaM,ei1,ei2,…,eiN]
(1)
式中:M表示用户的数量;N表示项目的数量。
2.2 嵌入传播层
我们将设计一种嵌入传播层,用以捕获在图结构中的协同过滤信号,首先介绍单层嵌入传播层,对于用户-项目之间的信息传递表示为:
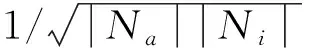
用户对用户本身之间的信息传递表示为:
通过汇总所有邻居节点的特征表示完成最终的表示学习,信息聚合的公式如下:
式中:ea为用户a汇总邻居节点的信息之后的特征表示,LeakyReLU为激活函数,在信息传递过程中通过拉普拉斯范数,使得不同的节点对同一用户具有不同的重要程度,也使得信息传递过程中增强了模型的表示能力,使得模型性能得到提升。用矩阵的形式表示各层之间的信息传递,公式如下:
式中:El表示第l层的特征表示;El-1表示上一层的特征表示;L表示拉普拉斯矩阵;I为单位矩阵;A是邻接矩阵;D是度矩阵。
本文设计一个注意力层,在模型中每一个嵌入传播层都会输出一个新的节点的表示特征,我们利用注意力机制对不同层之间的特征进行加权,然后再与原始特征进行串联操作。由实验结果可以看出进行加权后的模型效果更好,可以学习到更好的表示特征。具体公式如下:
式中:
式中:
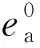
2.3 评分预测
对于推荐模型,最终用户对电影的预测偏好由用户-项目之间的交互特征表示。具体公式如下:
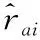
2.4 模型学习
由于数据是隐式数据,对于同时出现的两个项目,需要知道用户会更倾向于哪个项目,也就是学习用户对不同项目的偏好。对不同的项目一定存在不同的优先级,对于用户有历史交互行为的项目应该比没有历史交互行为的项目得到的预测值要高。BPR是目前在推荐系统领域广泛使用的基于成对数据的损失函数[16]。通过损失函数最小化的方法更新模型的参数。其表达式如下:
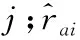
3 实验与结果分析
3.1 数据预处理
数据采用的是在推荐领域十分常见的公开数据集,即由UCI开发的MovieLens 1M用户电影评分数据集,并且保证了每个用户对不同电影进行评分的数据至少有20条。原始的数据中包含了用户和电影编号,用户对电影的评分以及时间戳字段,其中评分数据为1-5分,其中包含了3 952部电影,6 040个用户和1 000209条评分数据,并且数据存放在csv文件中。由于本文只需考虑用户对电影的历史交互行为,所以对原始数据进行处理,仅保留用户编号、电影编号和评分数据,并且原始的评分数据为显式数据,需要将评分数据全部转换为隐式数据。将所有评分为1-5分的电影评分转换为1,而未进行电影评分的数据记为0。其中0代表用户没有观看过该电影,1代表用户对电影进行过评分。并且将数据的80%作为训练集,20%作为测试集。
3.2 实验环境
此次实验采用Linux操作系统,PyTorch 1.1.0框架。平台硬件参数如下:Intel Core i7- 8550处理器,内存大小为16 GB,主频2.0 GHz。
3.3 实验参数
在本文的实验中,采用小批量adam算法优化模型[17],对于参数初始化使用的是Xavier,它具有计算效率高,能较好处理稀疏梯度等优点。为了防止模型发生过拟合现象,在神经网络中添加了Batch Normalization和dropout。BN是指使在模型训练过程中,使得每一层的输入均服从标准正态分布。dropout是指在训练神经网络的过程中,按照指定的比例从神经网络中将部分神经元暂时舍弃。本文的batch size为4 096,embed size为64。超参数根据网格搜索的方法选取最优值。dropout值在[0.1,0,2,0,3]之间进行调整,取0.1时为最优;学习率在[0.000 1,0.000 5,0.001]中进行调整,0.000 1为最优选择;L2正则化的系数在[10-5,10-4,10-3]之间进行取值,为10-5时为最优值。
3.4 结果评估指标
对于实验结果评价,采用三个评价指标进行模型效果评估。准确率(Precision)和召回率(Recall)可以用来评判模型整体推荐结果的质量。NDCG表示归一化的折损累积增益,可以用来衡量推荐顺序的质量。三个指标均是值越大代表推荐的效果越好。
(1) 准确率的计算公式如下:
式中:K表示根据用户a做出的推荐列表中有K项,N表示用户的总数,d表示在给用户a推荐的K个电影中,用户对其有过观看记录的数量。
(2) 召回率表示在最终的推荐列表中存在评分行为的比例。计算公式如下:
式中:r表示测试集中用户a有过观看行为的数量,N表示用户的总数,d表示在给用户a推荐的K个电影中,用户对其有过观看记录的数量。
(3) NDCG可以用于衡量推荐结果顺序的质量,对于最终的推荐结果,考虑到进行排序推荐时不同顺序会对最终的推荐效果产生不同的影响,希望达到相关性大的结果排在前面,相关性小的结果排在后面,计算公式如下:
式中:K是推荐列表的长度,DCG是指推荐列表位置结果的相关性,DCG值越大代表相关性越高。由于我们需要对整个测试集中的用户的推荐列表进行评估,但DCG仅表示单个用户的推荐列表的质量,则需要进行归一化处理。
式中:IDCG表示用户得到的按照相关性倒序排序后的最优的推荐列表,其中DCG∈(0,IDCG]。
3.5 实验结果
NMF模型为一个由MLP和GMF组成的神经网络框架,它可以得到用户与物品之间的非线性特征表示。GCMC模型是在二部图结构中应用图自动编码器。捕获一阶邻居节点的特征。NGCF模型提出了利用用户与项目之间的高阶联通性捕获用户和项目的嵌入信息,使得用户和项目的特征表示更加的完整。实验采用Recall、Precision和NDCG三个指标对模型进行评估,其中推荐列表的长度为20个。由表1可以看出与NMF、GCMC和NGCF模型相比,提出的AttGCF的模型评估效果始终优于其他的模型,其中召回率比NGCF模型提高了3.8%,准确率提高了3%,NDCG提高了1.2%。这说明提出的AttGCF模型能够更好地学习到用户与项目之间的行为偏好,得到更好的推荐效果。
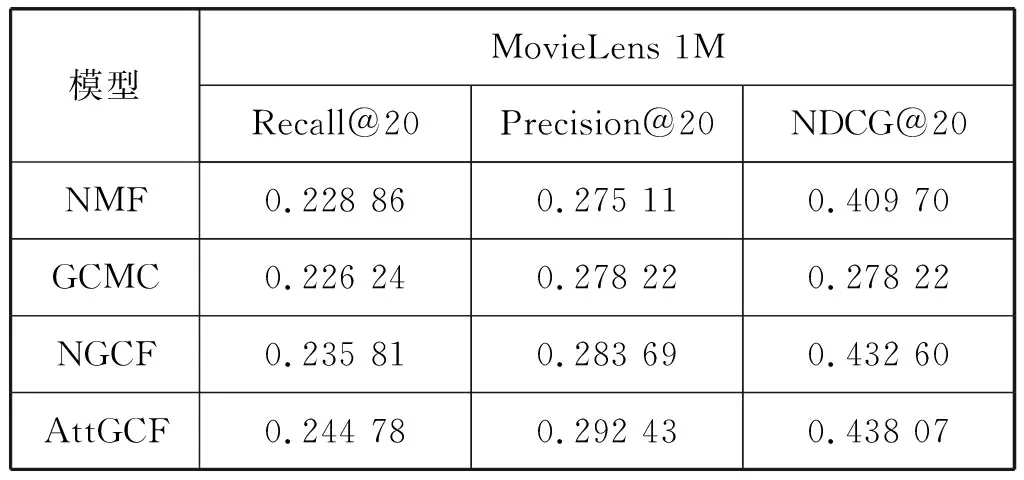
表1 模型效果对标
对于推荐列表长度的评估,实验分别选取了推荐列表分别为20、40、60、80和100个项目时各个模型的评估结果。由图2-图4可以看出随着推荐列表长度的增加,各个模型的召回率和NDCG值均有所增加,但是准确率却有所下降,所以最终选择推荐列表长度为20时作为最优的结果。
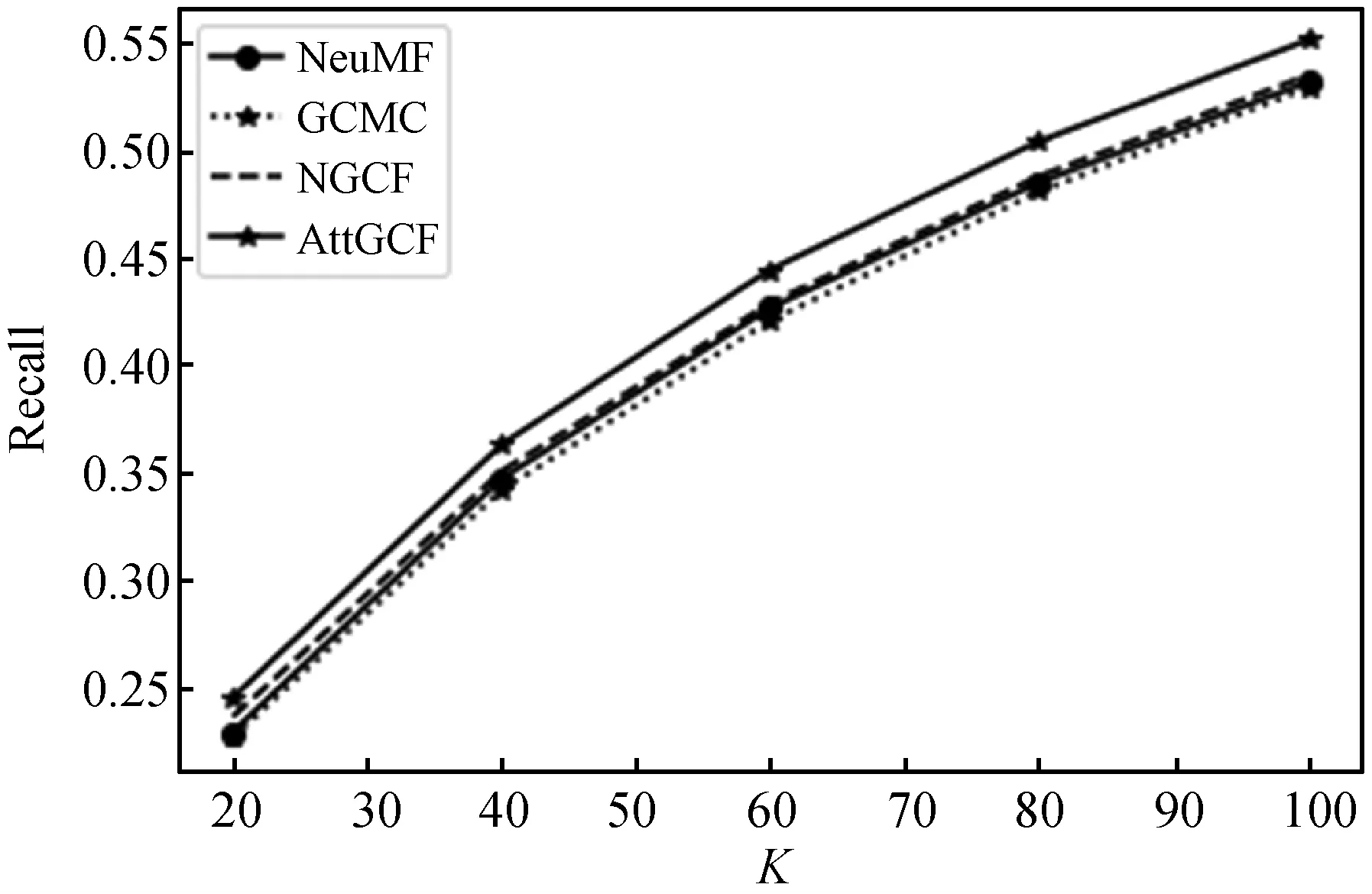
图2 不同K的Recall比较
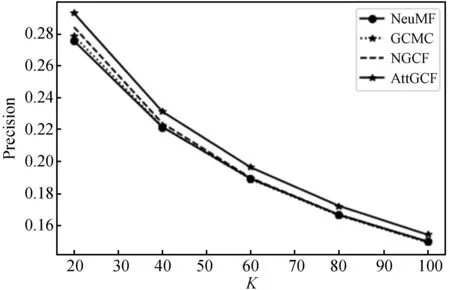
图3 不同K的Precision比较
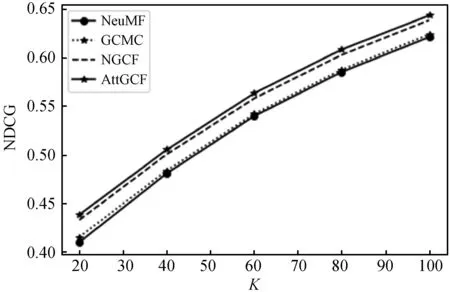
图4 不同K的NDCG比较
下面分析嵌入传播层的深度对模型的影响。从表2可以看出当嵌入传播层的深度为2时,模型取得最优的效果。结合多层邻居信息的模型效果比仅考虑一阶邻居信息的推荐效果更好,当改变嵌入传播层数时,AttGCF的结果均优于NGCF模型。说明引入注意力机制的图神经网络模型可以更好地学习到用户和项目的特征表示,使得最终的推荐结果更好。
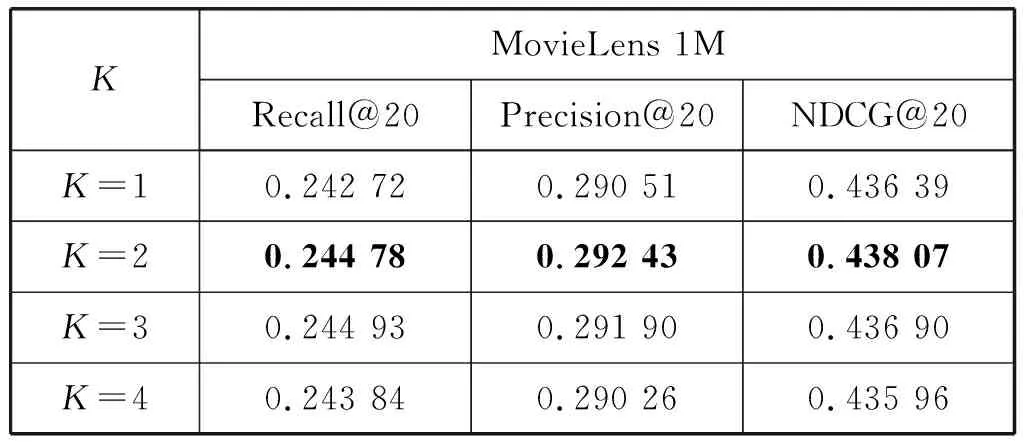
表2 传播层层数对模型的影响
4 结 语
用户和物品之间存在的协作信号问题是不能忽略的问题。从传统的协同过滤算法到最近出现的基于深度学习的方法,现有的研究通常是通过用户的编号等附加属性来获得用户的嵌入。传统的协同过滤算法只考虑物品之间和用户之间的关系,从而忽略了用户与物品之间存在的协作信号对协同过滤效果的影响。因此本文设计了一个结合注意力机制的图神经网络模型来捕获用户与物品之间的协作信号。通过对用户与物品之间建立二部图,设计嵌入传播层,并引入注意力机制对不同层输出的表示特征赋予不同的权重,经过实验验证本文提出的AttGCF模型的推荐效果更好。但实验也存在不足之处,将用户与物品之间的内积作为预测评分的方式,不能充分挖掘出两者之间的关系。所以在接下来的工作中考虑使用非线性神经网络的方法进行预测评分。
