基于ASHE和SWT的低对比度自然场景图像文字定位
2023-04-07杨昊东陈盈君汤弘毅
徐 武 杨昊东 陈盈君 汤弘毅
(云南民族大学电气信息工程学院 云南 昆明 650500)
0 引 言
自然场景图像中往往蕴涵着丰富的文本信息,如街道上的标识、商场里的广告牌、货柜上的商品等。这些可以帮助人们理解更深层次的语义信息,提高信息利用率[1]。由于信息提取的关键是定位,因而精准的文字定位具有极大的研究价值。
近年来许多国内外学者开始对自然场景图像中文字定位进行研究,方法主要可以归为三类。(1) 基于滑动窗口的方法[2]。利用文本区域与非文本区域不同的纹理特征,结合边缘信息实现定位,该方法可以获得较高的召回率,但其计算时间复杂度高[3]。(2) 基于连通域的方法[4]。利用文本区域相同的色彩、几何等特性,通过连通域分析法检测文字区域,该方法对光照及噪音敏感,但计算复杂度低。(3) 基于机器学习的方法[5]。利用大量样本在SVM或神经网络中训练,提取出文本特征向量后用于分类,但该方法很难训练出通用的分类器。潘立等[6]将MRSE算法和SWT特征相结合提取文本区域,然后根据规则滤除非文本域并合并连通区。该方法具有良好的文字定位效果,但运算的时间复杂度较高。李东勤等[7]通过提取图像的边缘特征形成候选文本区域,然后利用文字笔画特征区分文本与背景,进而合并文本区域。该方法获得了较低的定位误差率,但对于文本与背景相似的图像难以定位。司飞[8]对图像进行通道分离,分别提取MRSE区域后合并,然后利用神经网络模型提取文本区域。该方法具有较高准确率,但由于训练数据不综合,模型达不到通用的效果。
目前方法大多是针对自然场景中正常亮度的图像,而很多情况下由于拍摄角度、光照强度等影响导致图像对比度低。若直接使用上述方法将导致错检、漏检和时间复杂度高等问题,因而提出一种基于对比度增强的自然场景图像文字定位算法。利用改进自适应子直方图均衡算法提高对比度;在过滤规则中加入角点条件,大范围减少非文本区域;为减少运算耗时、提高检测效率,对SWT算法改进。实验结果表明,该算法对自然场景中低对比度图像的文字定位效果较好。
1 基于改进ASHE的低对比度图像处理
在真实的视觉感知系统中,对比度用来描述图像光照或亮度的差异。低对比度图像是指明暗区域因极亮或极暗而导致前景与背景区分不明显的图像[9]。自然场景中很多拍摄图像由于光照不足或过强导致对比度低,亮度、灰度范围较窄,从而很难从中分离出有用的文字信息[10]。
自适应子直方图均衡算法(ASHE)将原图像的灰度值进行非线性拉伸,重新分配图像像素值[11]。为显示极亮或极暗图像所隐藏信息,采用自适应伽马校正算法改善图像亮度,使图像中信息达到人眼可见;为改善传统ASHE算法作用后大量噪声、信息熵下降的问题,对其子区域分割方式给予改进,有效地降低无用信息。具体步骤为:首先,在直方图中搜索全部极大值,如式(1)所示;然后,根据搜索出的极大值对原直方图区间进行划分,本文采取相邻峰值点的平均数计算出子区间端点,如式(2)所示,利用极大值v=(v1,v2,…,vn,…,vN)、端点值t=(t0,t1,…,tn,…,tN),以及考虑t0=0代表第一个区间左端点,tN=255代表最后一个区间的右端点,将原直方图区间划分成子区间Dn,如式(3)所示;最后,对分割后子图像进行相应的均衡化。
f(vn)≥f(x)x∈[vn-δ,vn+δ]
(1)
式中:vn为所搜索到的极大值;δ为尽可能小的一个实数。
Dn=[tn-1,tn]n=1,2,…,N
(3)
从图1可以看出改进方法在改善对比度的同时减少了大量噪声,适当保护图像亮度,并且充分地保护原图文字信息,为之后的定位打下良好的基础。

(a) 原图 (b) ASHE算法

(c) 改进 ASHE算法图1 对比度增强效果对比
2 文字定位
本文文字定位算法设计如图2所示。首先采用MSER算法提取文本候选区域,形态学运算连接分离的笔画,通过启发式规则滤除非文字区域实现初步定位;然后采用改进的SWT算法结合汉字笔画特征进行精确定位;最后采用文本聚合算法将单个文字合并成文本行,得到文本区域。
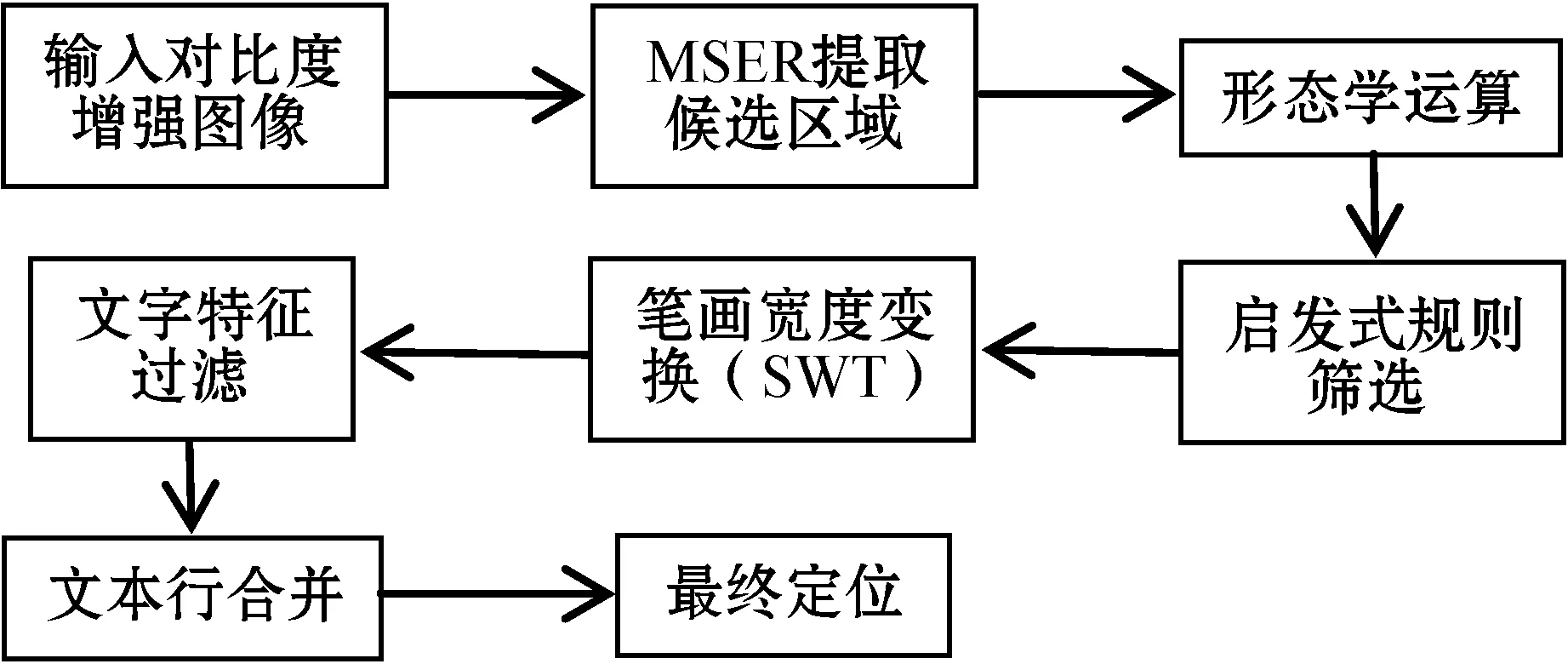
图2 文本定位流程
2.1 最大稳定极值区域
最大稳定极值区域(Maximally Stable Extremal Regions,MSER)是一种区域检测算法[12]。其实质是对图像二值化,随着阈值从小到大变化,部分连通域的面积在一定阈值范围内基本上不发生变化,通过计算|Qi+Δ-Qi-Δ|/|Qi|的局部最小值来获得最大稳定极值区域[13]。
根据自然场景图像中文字与背景的差异,采用MSER处理结果如图3所示,可见该方法能得到完整的文字区域。

图3 MSER算法
2.2 形态学运算
汉字的结构与英文字母有很大不同,各笔画之间往往是互相分离的,因此,首先对图像进行膨胀运算,扩大边缘信息的同时避免文本区域的笔画丢失,然后进行闭运算,既能使文字轮廓光滑,又能填充MSER检测产生的空洞,运算结果如图4所示。

(a) 原图 (b) 形态学操作图4 形态学运算
2.3 基于启发式规则初筛选
自然场景中包含许多与文字极其相似的区域,比如建筑物、树叶、栅栏等。因此需要过滤掉那些非文本区域,缩小文字定位的范围,具体筛选规则如下:
(1) 自然场景图像中文字区域的宽度和高度均不可能太小或太大,太小可能是噪声点,太大可能是背景物体。所以,通过限制连通域高度和宽度,将不满足式(4)的连通域滤除。
h>20,w>20,h<0.3×H,w<0.3×W
(4)
式中:w、h为连通区域的宽、高;W、H为原图像的宽、高。
(2) 自然场景中的文字区域类似于正方形,因此,可以通过式(5)限制连通域的宽高比,滤除掉狭长的非文字区域。
(3) 通常面积太小的连通域是噪声,如网状物、树叶或由光照不均匀引起的黑点等。因此通过式(6)滤除面积小的连通域。
S≥400
(6)
(4) 文字通常具有规则的形状,且较少边缘方向突变,所以具有适当的边缘角点。对于小的噪声点,角点数较少;而对于面积与文字类似的非文本区域,通常会有许多边缘刺尖,角点数较多。因此,对图像进行角点检测,滤除掉不满足式(7)的连通域。
ncorn>4,ncorn<50
(7)
式中:ncorn表示连通域的角点数量。
经过上述规则筛选,滤除大部分非文本区域,完成初步定位,如图5所示。但依然存在部分与文字形状相似的干扰区域,需要结合文字笔画特征进一步过滤。

图5 初步定位
2.4 基于改进的笔画宽度变换精确定位
2.4.1笔画宽度变换
笔画宽度变换(Stroke Width Transform,SWT)是由Epshtein等提出的一种常用于自然场景图像文本检测和定位的算法,因文字具有相似的笔画、边缘和宽度,故与非文字区域有很高的区分度[14]。其核心思想是采用Canny算子检测边缘像素点,然后遍历所有边缘点沿梯度方向搜索对应点,并计算笔画宽度值将其赋予像素点,最后聚合笔画宽度相似的像素点构建文本区域[15]。由于笔画是文字所独有的特征,所以该算法对不同类型的文字都具有普适性。
2.4.2改进SWT算法
使用传统SWT算法可以得到较好的检测效果,但其运算时间复杂度很高。因为该算法主要针对暗字亮底的图像,若图像为亮字暗底,则需要执行两遍,这会使运算时间倍增。其次,在沿梯度方向搜索对应点时,如果笔画太宽,搜索所消耗的时间也会明显增长。同时,SWT算法需要遍历所有边缘点来计算笔画宽度值,但随着图像连通域数量增加,其计算的时间复杂度也会随之成数量级增加。
基于以上算法缺陷,对传统SWT做出改进:
(1) 针对两类图像运算时间的不同,提出一种候选框像素判别法,使得对任何一类图像都只需执行一遍算法。先提取候选框上边缘的平均像素值,然后提取候选框内中间一行和一列的平均像素值,比较二者平均值的大小。若前者大,则判定为暗底亮字,反之亦然,如式(8)所示。
式中:A=1和A=-1分别表示暗字亮底与亮字暗底;Pr.mid.i和Pc.mid.i分别表示中间行列像素值;Pr.edg.i表示上边缘行像素值。
(2) 文字的笔画宽度很大程度影响SWT沿梯度方向的搜索时间。同样,在Canny算子进行边缘检测的过程中,边缘像素宽度也会影响非最大值抑制的作用时间。因此在不丢失文字信息的前提下,采用形态学开运算与腐蚀相结合的方法对图像进行边缘细化,如图6(a)所示,既可以消除边缘的毛刺,又能减小笔画宽度,从而有效地降低沿梯度方向的搜索时间和Canny边缘检测的时间。

(a) 边缘细化

(b) 原边缘结果 (c) 隔点取边缘结果图6 改进算法示例
(3) 传统SWT遍历所有边缘点进行梯度搜索,若图像中连通域较多,必将消耗大量的计算时间。为降低沿边缘方向的搜索时间,将遍历所有边缘点改为隔点式搜索,这样可以有效地降低一半的搜索时间。从图6(b)、图6(c)可以看出,隔点式搜索保留了完整的文字信息,对后续定位结果不会产生影响。由于隔点搜索会产生许多空洞,导致连通域激增,因此对完成最终梯度搜索的图像进行闭运算填充空洞,确保连通域数量与之前相似。改进SWT流程如图7所示。
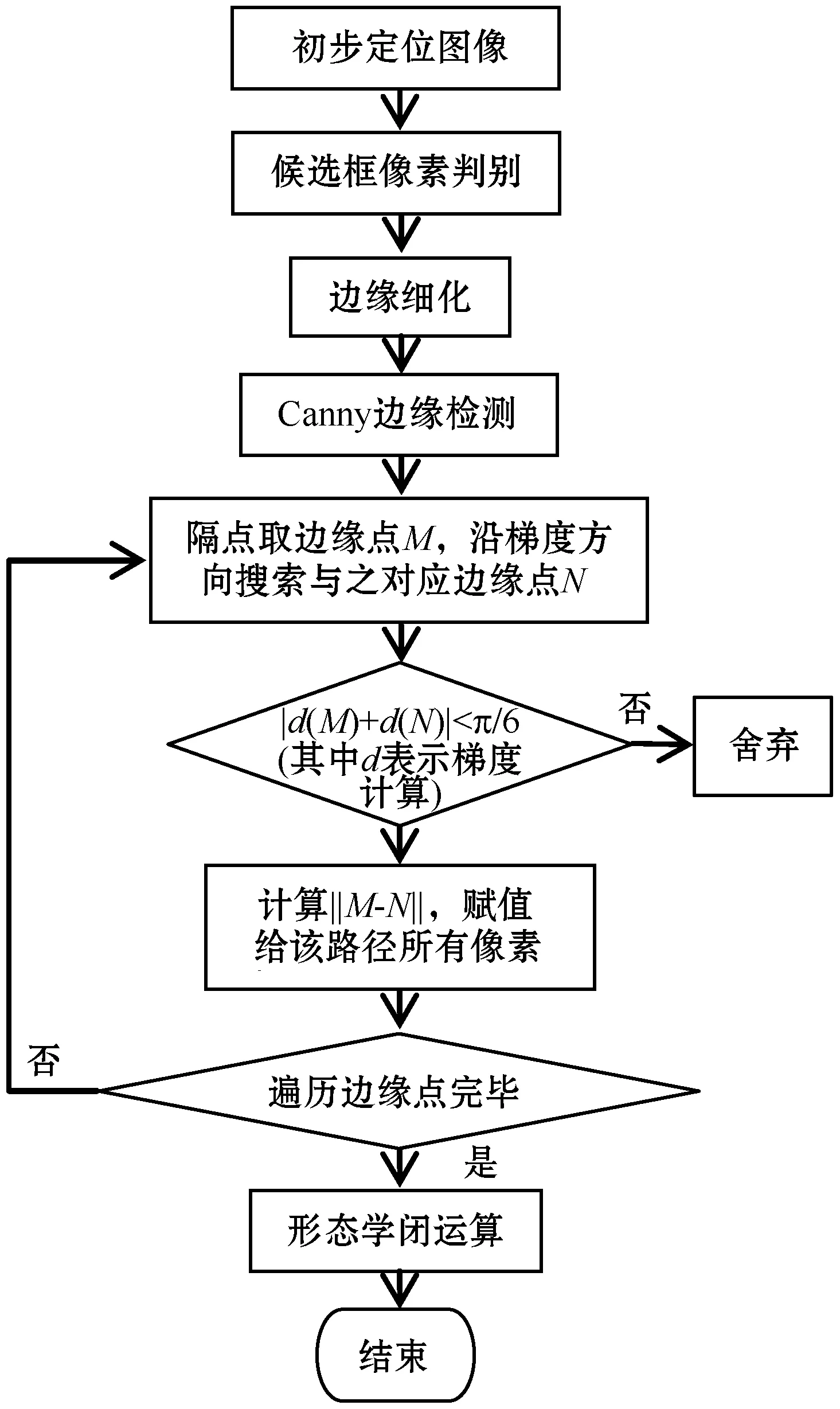
图7 改进SWT流程
2.4.3文字笔画特征过滤
通常情况下,非文字区域的笔画宽度变化幅度较大,并且部分图像区域只是孤立的点集合,没有形成有效的路径,而文字区域的笔画宽度变化比较缓和,且文本像素点占整个文字图像区域的比例适中[3]。因此,利用以上特征对候选区域进一步过滤,通过计算候选区域内笔画宽度的均值和方差过滤掉笔画宽度变化较大的非文字区域,再计算候选区域内文本像素点的占比,将占比太小或太大的区域滤除。如图8所示,大小与文字相似的非文字区域已被滤除,实现文字精确定位。

图8 精确定位
2.5 字符区域合并
通过笔画宽度过滤可以得到单个字符区域,但依然存在个别漏检或错检区域。自然场景中文本大都是呈线性存在的,相邻的连通域具有相似的笔画宽度、字符间隔与高度等特性[16]。因此,通过设置相邻区域中笔画宽度中值比小于2、间隔不大于最大字符宽度的2倍、高度比值小于2为条件合并字符区域,最终定位结果如图9所示。

图9 最终定位
3 实验结果分析
为了验证改进ASHE算法的有效性,本文采用对比度和信息熵两个指标对图1进行评价,对比度越大,图像层次清晰度越高;信息熵表示信息量大小,其值越大图像质量越高。与文献[9]中的BPASHE算法对比,由表1可知,本文改进ASHE算法在两个指标上均有所提升,为文字定位提供良好基础。
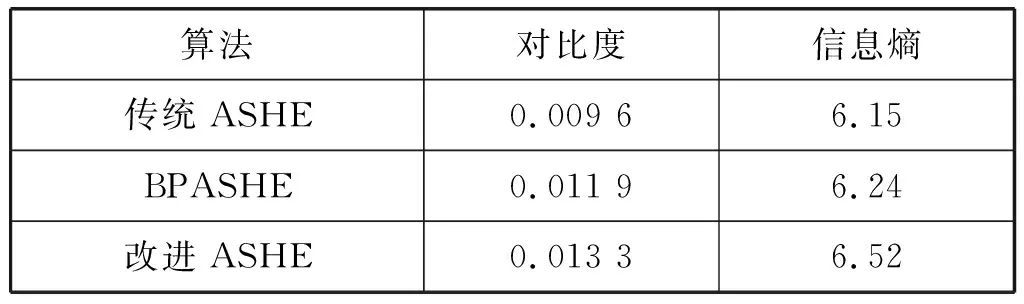
表1 对比度增强算法比较
为了验证改进SWT算法的有效性,本文采用公开发表的ICDAR 2015文本定位竞赛数据集,随机抽取100幅包含不同场景、不同光照及不同像素大小的图片进行实验。由表2可以看出,改进SWT算法有效地改善时间复杂度,降低整体定位时间。

表2 SWT平均耗时比较
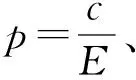
本文将BPASHE、SWT及各自改进算法交叉搭配以验证改进算法的有效性。从表3可知,改进ASHE算法与改进SWT算法实验的综合性能最高,且对结果影响较大的是图像对比度的提升,这也是未来低对比度图像提升文字定位准确率的首要问题。
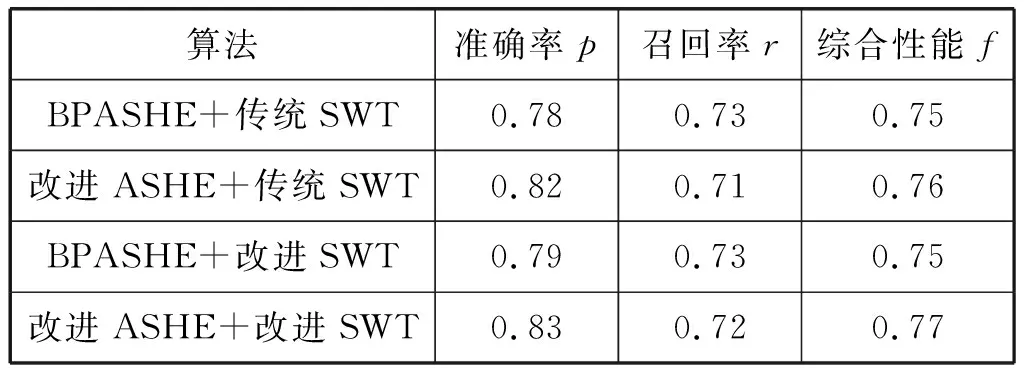
表3 改进算法有效性比较
本文算法还与文献[17-18]进行比较。文献[17]通过评估灰度分布和梯度投影的方法改善对比度,采用多通道的MSER检测,综合使用笔画相关特征结合多通道融合实现定位。文献[18]通过寻找笔画关键点,并根据笔画关键点与领域像素的灰度大小关系,提取文本候选区域,选取凸包面积比、紧密度、孔洞面积比等连通域特征结合AdaBoost分类器对候选区域分类实现定位。
由表4可知,通过增强对比度,结合多种启发式规则和文字笔画特征的定位算法优于文献[17]和文献[18],准确率和综合性能指标均有提升。说明本文改进算法适用于低对比度图像进行文字定位,具有可行性。部分文字定位结果如图10所示。
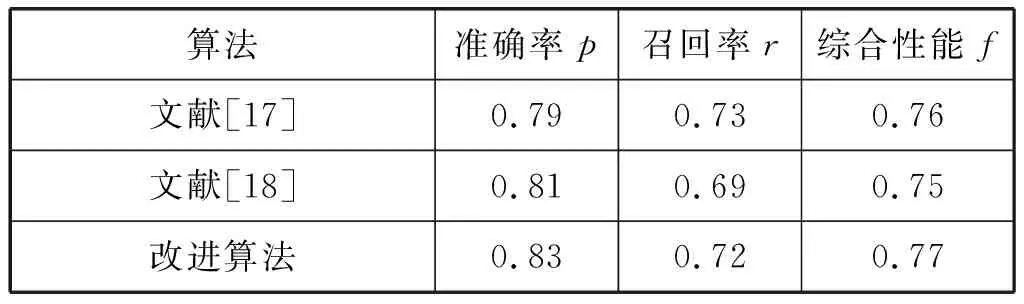
表4 改进算法与其他算法比较

(a)

(b)图10 部分文字定位结果
4 结 语
本文采用改进的ASHE和SWT算法进行自然场景中低对比度图像文字定位。利用改进的自适应子直方图均衡算法提升图像对比度;然后提取MSER候选区域,并结合启发式规则滤除大部分非文本区域;最后应用改进SWT算法配合笔画宽度特征实现最终定位。实验结果表明,本文算法在性能上优于其他算法,准确率和综合性能均有所提高,证实了本文方法的可行性与有效性。
