一种基于深度强化学习的TCP网络拥塞控制协议
2023-04-07卢光全李建波吕志强
卢光全 李建波 吕志强
(青岛大学计算机科学技术学院 山东 青岛 266071)
0 引 言
随着互联网规模和网络应用的不断增加,网络拥塞现象日益显著。尽管高带宽的网络链路能够在一定程度上满足网络服务的需求,提高吞吐量和降低延迟等,但更高端的硬件资源价格昂贵且没有从本质上解决网络拥塞问题。更可行的是对高层的拥塞控制协议进行设计或改进。随着计算机网络路由协议算法的不断创新,许多网络拥塞控制协议被提出[1-3]。其中TCP NewReno拥塞控制协议是业界的主流,但由于其基于规则的设计模式,它在动态变化的网络环境中未能更好地均衡吞吐量和时延。在网络构建的过程中上述规则被定义为“事件-动作”,即在面对丢包或者拥塞时此类网络协议只能根据单一的映射关系选择固定“动作”,尽管这一“动作”会降低网络吞吐量等性能指标。这些网络协议也未能根据网络的过去经验对拥塞窗口做出动态的自适应调整,仅仅是在特定场景和特定假设下达到网络性能的次优化。
基于规则的协议主要存在两个问题:
(1) 当网络环境发生变化时,这些基于规则的协议不能动态地对新的网络环境更好地适应。即不同的网络环境存在不同的带宽、延迟和网络拓扑。因此,适用于特定网络下的TCP拥塞控制协议很难甚至无法在另一个网络中起作用。
(2) 在构建网络的时候,人为地建立标准性的假设,在这些假设之上成立规则。
拥塞控制算法在保证应用数据进行可靠传输中起着重要的作用。但是,网络环境是复杂且动态变化的,链路的信息具有非透明性,这对设计拥塞控制算法提出了更高的挑战。如图1所示,通信双方的通信链路带宽不均衡。当以1 Mbit/s从S向R发送数据时,超过链路所提供的最大带宽,在M处会发生拥塞,导致网络性能变差甚至崩塌。此时S就会减小拥塞窗口,降低其发送速率。NewReno遇到此类问题时执行固定的AIMD规则,在网络出现拥塞时,拥塞窗口的大小默认缩减至原始值的1/2,这种设计浪费了网络资源,从而严重降低了网络的性能。
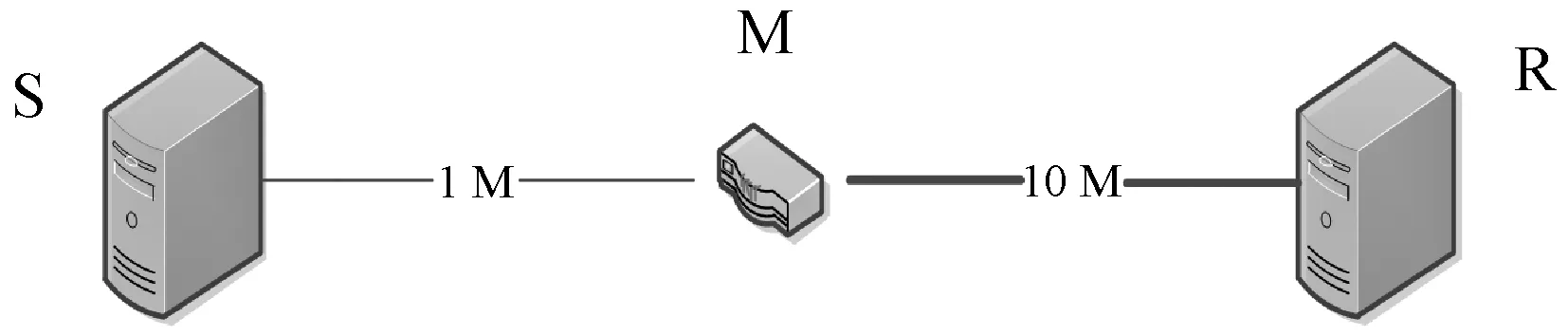
图1 链路带宽不均衡
深度强化学习通过挖掘网络历史经验为处理网络拥塞提供了新模式。TRL-CC可以有效地克服上述问题,从而学习到一个较成功的策略,最终实现智能化拥塞控制。TRL-CC通过利用历史经验实现拥塞控制智能化和摆脱基于规则的模式。在这种情况下,每个发送方作为一个代理,代理与网络环境直接进行交互,代理不需要了解网络的全部信息,它只需要观测网络环境的状态(例如:往返时间(RTT)、吞吐量、拥塞窗口等)。一次TCP会话建立到会话结束称为一个片段。在一个片段内的每个时间步,代理通过接收网络环境的状态选择一个合适的动作,此时的动作会被反馈给环境并且影响环境的下个状态,同时代理将得到执行这一动作带来的回报,目的是最大化未来折扣累积回报。
通过上述对传统TCP拥塞控制问题的描述,本文提出一种基于深度强化学习的智能化拥塞控制方案TRL-CC。尽管没有必要说明,TRL-CC建立在NewReno之上。对TRL-CC研究的主要贡献如下:
(1) TRL-CC利用时序卷积网络对历史经验进行时序上因果关系处理,并结合强化学习选取合适的动作对拥塞窗口进行调整。据我们了解,尽管在这之前存在基于强化学习的拥塞控制方案,同时它们也利用历史经验学习网络环境以达到目标(例如:高吞吐量、低延迟等)。但是,它们仅仅是把过去经验直接作为输入,未考虑历史经验中存在的隐式关系。利用当前的网络状况跟过去一段时间内的网络情况有着密切联系这一隐式条件,TRL-CC可以学习到更优的策略来实现智能化的拥塞控制。所以该方案是首次利用历史经验在时序上的因果关系并结合强化学习实现拥塞控制。
(2) TRL-CC在实现智能化的拥塞控制方案时,对往返时间进行量化。拥塞窗口通过结合量化往返时间进行自适应动态调整。
(3) 本文考虑到环境执行动作到代理收到执行这一动作的回报存在延迟。所以,TRL-CC在学习过程中对Q函数的更新做了修改。代理用t+1时刻的回报代替t时刻的回报。
(4) TRL-CC通过NS-3[4]仿真,并且与TCP NewReno以及基于强化学习的拥塞控制(RL-CC)方案作比较,表明TRL-CC能够更好地学习网络状况,同时在性能方面较NewReno和RL-CC有着显著的提升。
1 相关工作
1.1 回 顾
在有线和无线网络中,TCP是被广泛探讨的话题。同时,拥塞控制是网络中最基本的问题。多年来,许多端到端拥塞控制理论被提出。例如,Reno[5]根据返回的确认字符(ACK)信息调整拥塞窗口,在低带宽、低时延的网络中可以发挥出优势。但是在高带宽延时网络中,RTT很大,拥塞窗口增长慢,导致带宽利用率降低。Cubic[6]使用cubic函数调整拥塞窗口,其优点在于只要没检测到丢包,就不会主动降低发送速率,可以最大程度地利用网络剩余带宽。但这也将会成为其短板。Vegas[7]将时延作为拥塞出现的信号。如果RTT超过了预期的值则开始减小拥塞窗口。还有包括BBR[8]、Compound TCP[9]等端到端的拥塞控制协议。这些协议都有各自独特的设计,它们使用固定的函数或者规则调整拥塞窗口的变化。对于上述传统的拥塞控制协议,固定规则策略限制了它们适应现代网络的复杂性和快速变化。更重要的是,这些拥塞控制协议不能从历史经验中学习。
同时,研究者们已经利用机器学习方法来解决传统TCP协议的局限性。例如,Remy[10]使用机器学习的方式生成拥塞控制算法模型,针对不同网络状态采用不同的方式调整拥塞窗口。它通过离线方式进行训练,通过输入各种参数(如瓶颈链路带宽、时延等),反复调节目标函数使其达到最优,最终会生成一个网络状态到调节方式的映射表。当训练的网络模型假设与实际网络的假设一致时,Remy可以很好地工作。但是当实际网络假设发生改变时,Remy的性能会下降。它的映射表是在训练时计算得出的,与传统的TCP及其变种一样,它无法适应不断变化的网络环境,每当网络环境发生变化时,它必须重新计算映射表。PCC[11]摒弃基于规则的模式,可以快速适应网络中不断变化的条件。它不断地通过“微型实验”积极寻找更优的发送速率。但是,贪婪地寻找更优的发送速率会让其陷入局部最优的地步。并且,它的性能需要依靠准确的时钟。不论是Remy还是PCC,它们都把网络环境视为黑匣子,抛弃了传统的基于规则的设计模式,专注于寻找可以达到最好性能的发送速率改变规则。但是,它们都没有利用先前的经验。
近来,许多研究者利用强化学习和网络拥塞控制结合,这一结果能够更好地解决TCP拥塞控制问题。QTCP[12]是把Q-learning与拥塞控制结合得到的在线学习方案。它可以较好地适应新的网络环境,摆脱传统的基于规则的设计原理,从经验中学习网络状况以获得更好的性能(例如,高吞吐量、低时延)。并且提出一种广义的Kanerva编码函数逼近算法。TCP-Drinc[13]与深度强化学习结合,把多个观测状态通过深度卷积网络处理,然后加入LSTM再对特征进行深层次的提取,最终通过一个全连接网络选择动作,来决定如何调整拥塞窗口的大小。它也是一种从过去的经验中学习合适的策略以适应网络环境动态变化的拥塞控制方案。尽管QTCP和TCP-Drinc都是从过去的经验中学习,但都未曾考虑历史经验中的因果关系。
1.2 NewReno存在的问题
拥塞控制的目标是多个发送方可以公平地共享一个瓶颈链路带宽,不会引起网络的崩塌。每个发送方包含一个有限大小的拥塞窗口(cwnd),维持发送数据的多少,以保证注入网络的数据包不会引起网络拥塞。TCP拥塞控制协议及其变种不断地被提出。TCP NewReno通过AIMD规则来维持整拥塞窗口。AIMD主要包含三个步骤:
(1) 慢开始:cwnd=cwnd+1(每个ACK都被发送方收到)。
(2) 拥塞避免:cwnd=cwnd+1/cwnd(每个ACK都被发送方收到)。
(3) 快恢复:cwnd=cwnd/2(收到三次重复ACKs)。
图2为TCP NewReno流的拥塞窗口(包的数量)随时间的变化。它通过AIMD规则控制拥塞窗口变化。一个TCP会话建立时,发送方并不知道拥塞窗口应该取多大的值适合当前的网络状况,所以数据包刚注入网络时拥塞窗口会快速提升到某个值((1) 慢开始),尽管这种策略被称为慢开始,但是拥塞窗口呈指数增长。TCP设置了一个慢开始门限限制拥塞窗口无限增加。发送方根据确认字符判断网络出现拥塞,进入拥塞避免阶段((2) 拥塞避免),拥塞窗口增长缓慢(在接收到每个确认信息ACK)。直到链路发生丢包或发送方收到三个重复冗余ACK,进入第三阶段((3) 快恢复),跳过慢开始阶段直接进入拥塞避免。AIMD原理说明TCP过程将会收敛到一个同时满足效率和公平性的平衡点上,也表明多个流在共享一个链路时最终能得到收敛[14]。
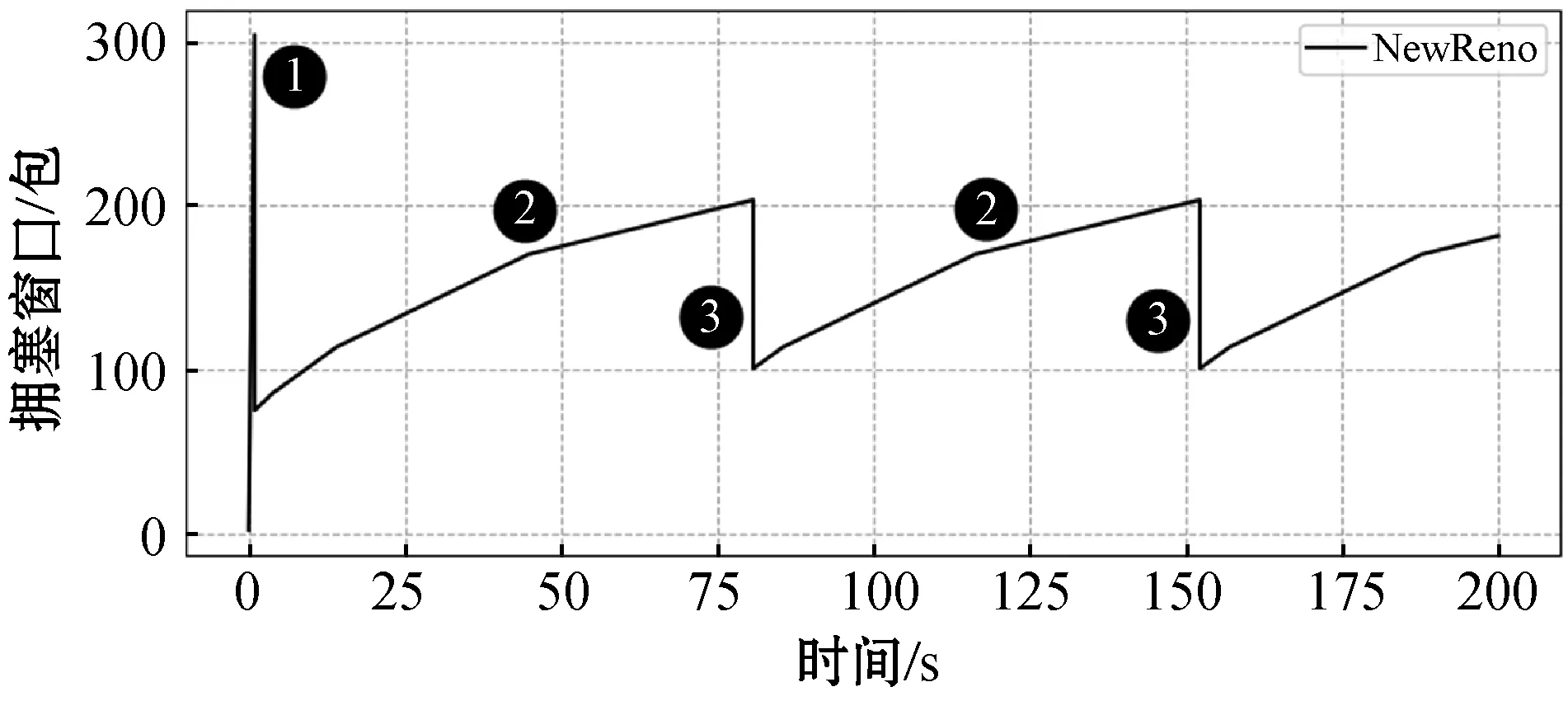
图2 NewReno流拥塞窗口
2 对问题的建模
2.1 问题描述
当一个网络的拓扑和参数发生改变时,网络需要重新被规划以充分利用瓶颈链路带宽和降低往返时间。事实上,在保证充分利用带宽和降低往返时间的前提下,本文提出基于强化学习的TRL-CC通过学习历史经验达到自适应动态规划网络目的。强化学习包含两个实体:代理和环境。通常情况下,深度强化学习用于解决马尔可夫决策问题(MDP)。但在本文中,网络内部信息并不透明,代理不能完全了解网络信息。因此,本文对网络环境建模为部分可观测马尔可夫问题(POMDP)。
没有先验知识的代理通过学习得到最优策略π(a|st),通常情况,策略π(a|st)是通过状态空间S到动作空间A映射,定义为:
π(a|st)S→A
(1)
代理根据当前状态st随机或根据式(1)固定地选取动作at并从环境中获得回报r(st,at),目的是最大化长期累积折扣回报,被定义为:
Rt=r(st,at)+γ·Rt+1
(2)
式中:γ∈[0,1]表示折扣因子。
即使在相同的环境中,当策略发生变化时,累计回报也会发生改变。这是因为累计回报取决于选取的动作。此时,需要计算代理在状态st下执行动作at后获得的累计回报,这得以从Q函数体现,被定义为:
Qπ(st,at)=Est+1[rt+γQπ(st+1,at+1)|st,at]
(3)
2.2 状态空间
在一个TCP会话建立时,有许多的状态变量可以描述网络情况,例如往返时间TRT和最小往返时间TRT,min、上次发包的时间、慢开始的阈值、拥塞窗口大小、连续两次发包的拥塞窗口的差值、平均往返时间、收到确认信息的总和、在一个时间间隔内接收到的平均确认信息、网络吞吐量等。选取只与代理目标相关的特征并做预处理是必要的,因为能更好地解释模型。
数据包传输时,通过最小往返时间可以估计出链路的传输时延,但是链路可能会发生动态变化。因此,最小延迟比vRTT=TRT,min/TRT也作为衡量网络状况特征,它表示在动态变化的链路中数据的传播时延所占的比例。同时,数据包的传输过程中需要考虑队列延迟,把dRTT=TRT-TRT,min作为队列延迟的估计。此外,返回确认信息表明在一次数据传输过程,接收方收到数据包还是丢失数据包,一定程度上可以反映网络情况,所以确认信息(ACK)也作为一个特征。
通过上述讨论,下一步定义TRL-CC的状态空间。在一个TCP会话期间,代理对观测状态处理之后,我们考虑以下特征:(1) 拥塞窗口大小,用w表示;(2) 一次发包时间内的吞吐量(tp);(3) 往返时间(TRT);(4)TRT,min和TRT之比υRTT;(5)TRT和TRT,min两者之间的差值dRTT;(6) 发送数据包后返回的确认字符,用τACK表示。因此,状态空间定义为:
S=[s1,s2,…,sk]
(4)
其中st表示为:
st=[w(t),tp(t),RTT(t),υRTT(t),dRTT(t),τACK(t)]
(5)
代理选取式(5)中的s1,s2,…,sk这K个历史经验作为时序卷积网络的输入,提取时序上隐式的因果关系。最终,代理把提取的隐式特征压成一维张量作为DQN的输入。
2.3 动作空间
代理通过在动态变化网络中学习合适的策略,处理每个观测状态后选择合适的动作,构成<状态,动作>对,并将动作映射为拥塞窗口的改变。如表1所示,拥塞窗口调整的状态空间A,共有5个动作。代理结合往返时间的量化对拥塞窗口做动态改变。本文参考文献[15]对往返时间均匀量化为M个区间,如式(6)所示。
Δμ=(TRT,max-TRT,min)/M
(6)
式中:Δμ称为乘性因子,拥塞窗口随乘性因子做不定的改变。代理预测的任何一个动作对改变拥塞窗口满足式(7):
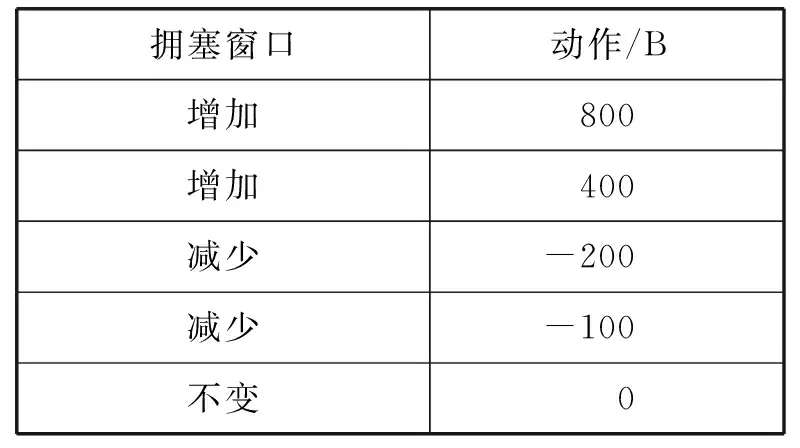
表1 拥塞窗口改变规则
2.4 回报和效用函数
回报是指代理在每个时间步选取动作后作用于环境中,然后从环境中获得的评价性响应。回报取值通过效用函数得到映射。TRL-CC的效用函数目标是最大化吞吐量且最小化延迟。因此,效用函数的定义如下:
Utilityt=α×log(tp(t))-βlog(RTT(t))
(8)
式中:α、β代表吞吐量、往返时间的权重,且α+β=1。式(8)表明应该努力地最大化吞吐量的同时最小化延迟。
尽管效用函数是模型要实现的目标,但值得注意的是,代理仅仅采用式(8)作为回报函数,代理可能持续选择相同的动作,使得效用函数一直是最大化,但网络的性能并不一直是最优的。为了能够更好地均衡吞吐量和往返时间。本文采用时间步t和t+TRT连续时间的效用函数值之差来定义效用函数,如下:
U=Ut+TRT-Ut
(9)
表2中,ε表示两个连续效用值差值的容忍度。当连续的两个效用函数值的差大于ε,代理会得到一个正的回报值,反之亦然。
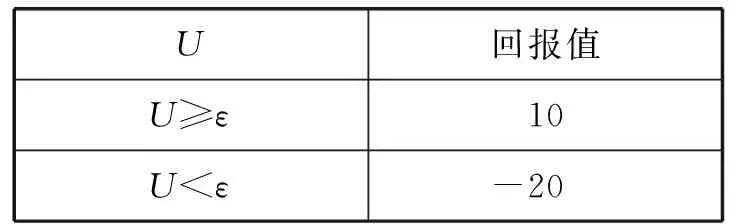
表2 效用函数回报
3 拥塞控制方案
3.1 TRL-CC
随着机器学习和深度学习在视频流[16-18]、流量预测[19-20]等方面的成功发展,这促使本文利用深度学习对拥塞控制做进一步研究,寻找一个智能化的拥塞控制方案。TRL-CC的设计如图3所示,它可以从历史经验中隐式学习和预测未来网络情况。它大致可以分为三部分:(1) 对网络实行控制和决策的代理;(2) 执行代理选择的动作并对这些动作做出标准性评价的环境;(3) 存放历史经验的缓冲区。
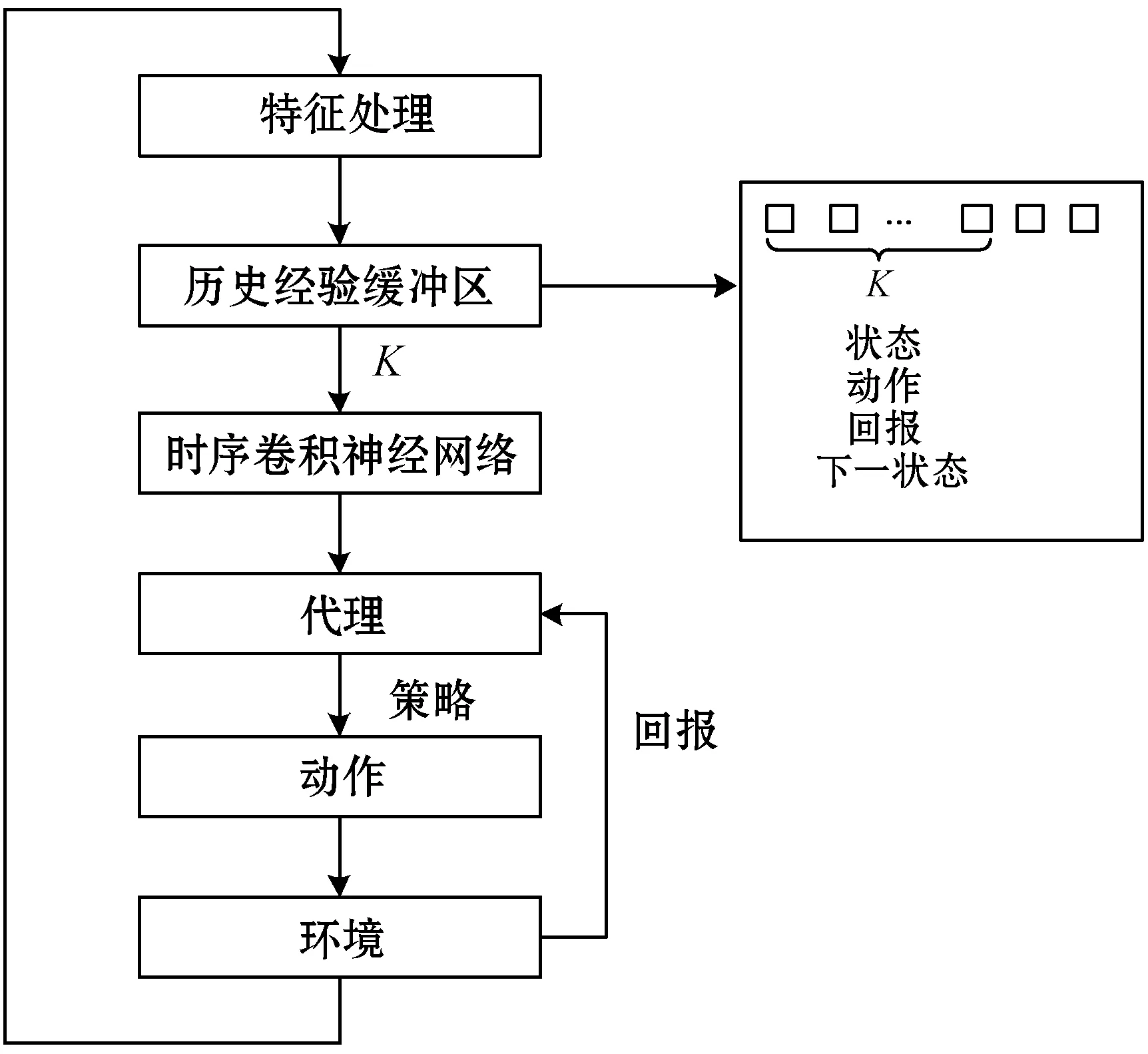
图3 TRL-CC模型
本文对传统的强化学习策略做了改进。首先,每过一个往返时间,缓冲区更新一次。数据以元组(st,at,rt,st+TRT)的形式存放在缓冲区中。TRL-CC利用时序卷积网络提取历史经验中隐式的关系作为输入,每次选取K个历史经验。最后,t时刻的回报经过TRT才会被代理收到。本文考虑这一延迟,改变了Q函数的更新方式。通过这些改进,DQN可以从历史经验中更好地学习。
3.2 代 理
在定义了状态、动作空间、回报函数和TRL-CC方案设计之后,现在介绍代理的设计如图4所示。代理将时序上连续的K个历史经验作为输入,并且输出是动作空间中的下一个动作。
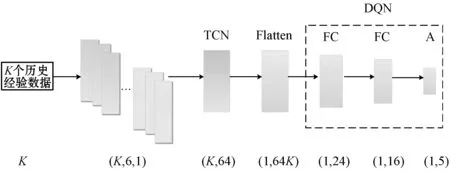
图4 代理设计(FC:全连接层;A:动作空间)
在单独使用强化学习实现拥塞控制时,仅仅是把过去经验直接作为输入。尽管可以得到比传统模型好的效果,但RL-CC却忽略了历史经验中隐式的因果关系。文献[21]中提到时序卷积网络(TCN)在处理时序上的序列时是一个非常有前景的方法。在t时刻,代理从缓冲区中选取t时刻之前的K个连续的历史经验作为TCN的输入。TCN的卷积网络层层之间是有因果关系的,意味着不会“遗漏”历史信息的情况发生。而且它使用大量的空洞卷积扩大感受野,可获得更长的历史信息。网络参数的丢弃概率是0.3。最后,代理通过两个全连接网络来计算最合适的动作的Q函数值。
在图4中,代理使用全连接层网络计算每个动作的Q函数值时,采用的是Softmax激活函数,定义如下:
代理选取最大概率的动作Ai计算对应的Q函数值。
3.3 DQN训练过程
在实现拥塞控制时,在每个时间步t,代理会接收到来自环境的状态向量st,基于策略π(st)选择动作at。并且在下一个时间t+TRT,代理收到标量值回报r(st,at),表示在时间步t执行动作at的回报。但是,环境执行动作at的回报被代理在时间t+TRT收到,这表明在学习中存在延迟τ。在强化学习中,像这样的延迟大多都被忽略掉。然而,对于拥塞控制来说,它对维持网络稳定有着重要的作用。出于此原因,TRL-CC在学习过程中对Q函数(式(3))的更新做了修改。代理把rt+1作为动作at的回报。因此,在时间t+1开始时,修改Q函数的更新方式为:
Qπ(st,at)←rt+1+γQπ(st+2,at+2)
(10)
式中:Q函数利用神经网络进行近似。
式中:ω表示神经网络权重,将代理得到的观测状态通过时序神经网络进行处理后和权重作为神经网络的输入,然后通过迭代和学习得到近似的Q函数。
在神经网络进行训练时,假设式(11)成立,由此定义损失函数为:
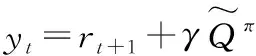
4 实验结果与分析
4.1 网络环境
本文利用NS-3仿真网络环境,如图5所示,在路由器1和路由器2之间有着大小为B的颈链路带宽,设置最小往返时间为80 ms,这是一种典型的哑铃状网络模型。有N个发送方和N个接收方,多个发送方共同竞争一个瓶颈链路,每个发送方都是一个独立的代理。代理每次训练50个片段,每个片段为800 s。如果代理在TRT时间间隔内没有接收到确认字符,则会用上一时刻的观测状态。
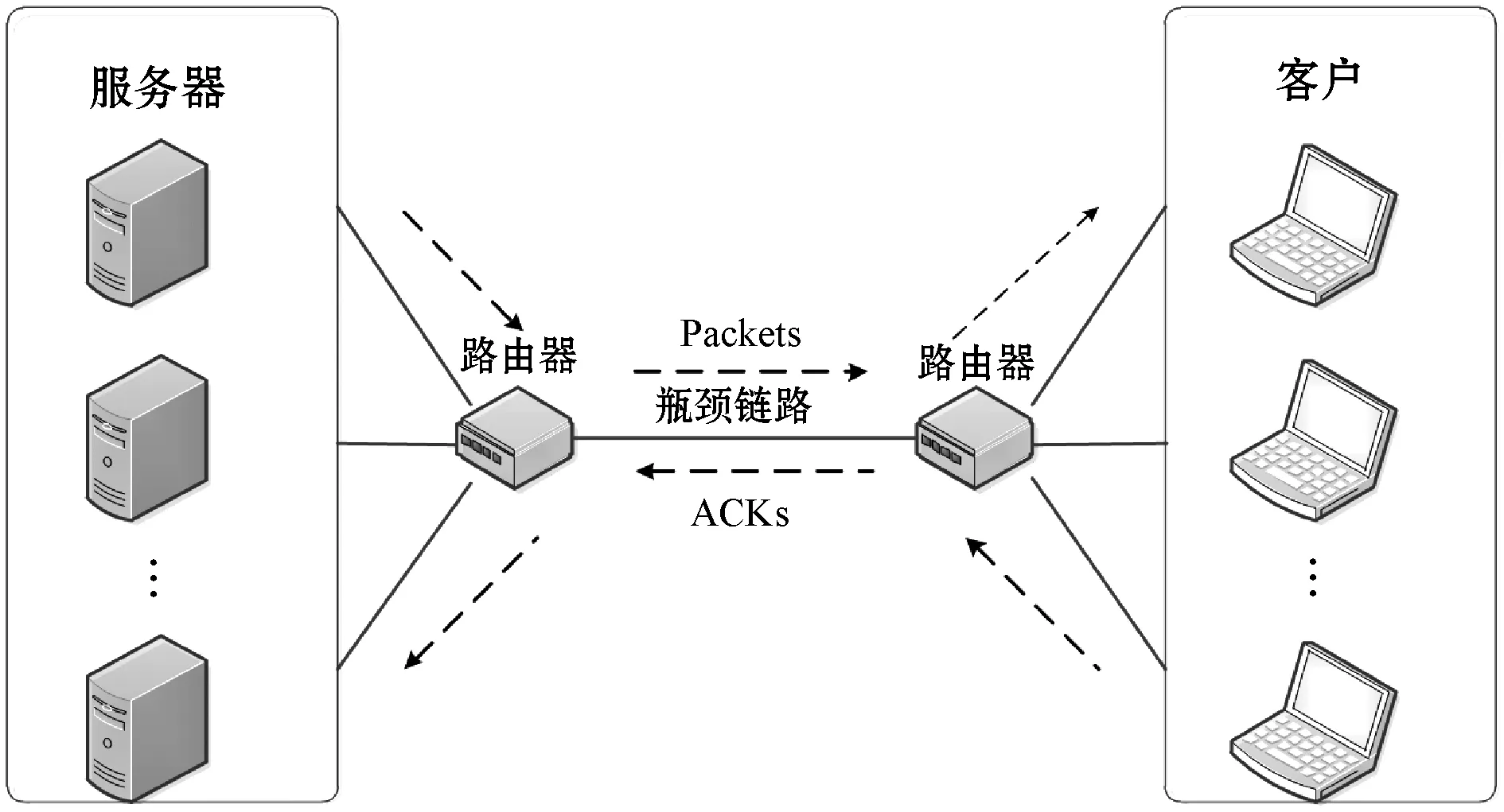
图5 网络拓扑
为了验证TRL-CC的性能,选择两个基准方案NewReno、RL-CC进行对比。本文主要专注于吞吐量和往返时间两方面的性能。
4.2 评 估
本节评估本文提出的TRL-CC方案的性能。首先它与传统的拥塞控制算法NewReno、未考虑时序特征的基于强化学习的拥塞控制方案进行对比。随后通过实验分析历史经验K的取值。最后,TRL-CC不做任何改变的部署在高带宽网络进行实验分析。
4.2.1TRL-CC性能
图6是代理在进行20个片段的训练后得到的拥塞窗口和往返时延以及吞吐量的变化曲线。它包含代理学习的三个过程:(1) 随机探索;(2) 随机学习;(3) 收敛阶段。拥塞窗口的变化符合式(7),在图6(a)和图6(b)中可以看出拥塞窗口是通过往返时延量化的。标注①之间是随机探索过程,代理以一定概率随机选取动作,随机选择动作的概率为0.1。在代理学习的过程中随机选择概率会减小,但是最终它不会为零,因为面对动态变化的网络保持一定的概率探索环境是有必要的。标注②之间是随机学习过程,代理通过学习到的策略选择合适的动作,然后结合效用函数确保代理达到收敛阶段(标注③),最终往返时延收敛到最小往返时延附近波动。
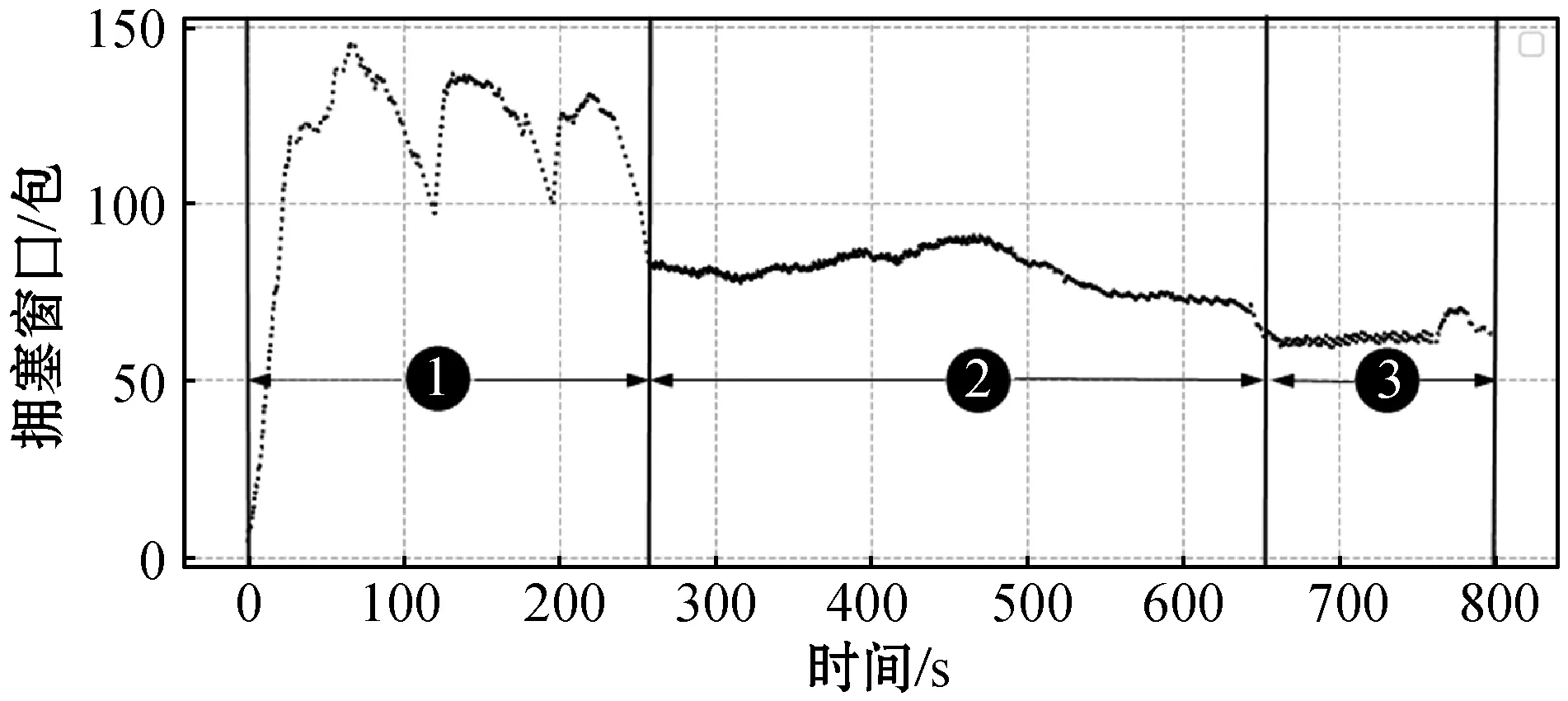
(a) 拥塞窗口的变化
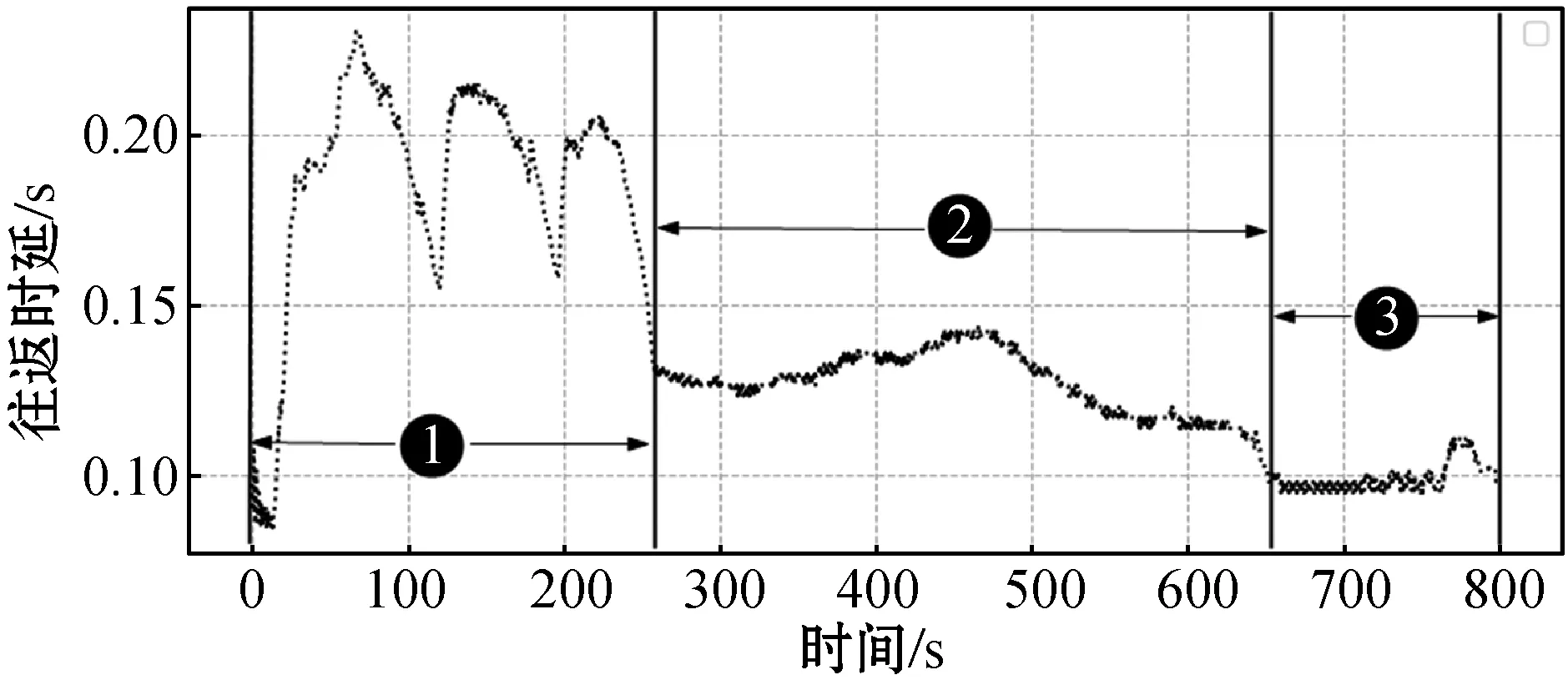
(b) 往返时延的变化
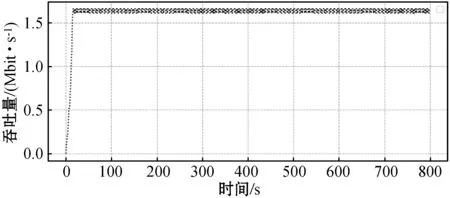
(c) 吞吐量的变化图6 TRL-CC方案性能
通过图6(c)可以看出,尽管代理在学习过程中使得拥塞窗口自适应减小(发包数量减少),但是吞吐量却一直保持稳定。这也进一步说明TRL-CC在减小延迟的同时也能充分利用瓶颈链路带宽,提高链路利用率。
4.2.2对比实验
此节主要通过从吞吐量和延迟方面进行比较,展示TRL-CC在吞吐量和延迟方面具有良好的性能。主要以下面三个拥塞控制方法进行比较:
(1) TCP NewReno:如今广泛应用的经典拥塞控制算法之一。
(2) RL-CC:基于强化学习的拥塞控制方案,没有利用历史经验在时序上的关系。将其作为TRL-CC的对比实验。
(3) TRL-CC:在RL-CC的基础之上,考虑过去经验在时序上的因果关系。即此刻的网络情况与之前某段时间内的网络情况是有联的。利用时序卷积网络提取网络中潜在的关系,对未来网络情况做更好的规划。
从图7(a)可以看出,NewReno的时延上下浮动剧烈且时延较其他两者相对较高。在图7(b)中,NewReno的吞吐量存在波动且不能保持稳定。这主要是因为NewReno中固定的AIMD规则,当代理观测到有包丢失时,拥塞窗口减半。而另一方面,在TCP连接刚建立时,RL-CC方案随机探索阶段时延波动大、收敛较慢,同时吞吐量的稳定性比较差。TRL-CC较RL-CC可以学习到控制网络行为更优的策略,时延可以快速收敛且在最小往返时间附近波动,吞吐量保持相对稳定。主要原因是,历史经验中存在时序上隐式关系,这种关系一旦被提取利用,代理就可以更好地结合过去经验和现在的网络情况,并对未来网络情况做好规划。
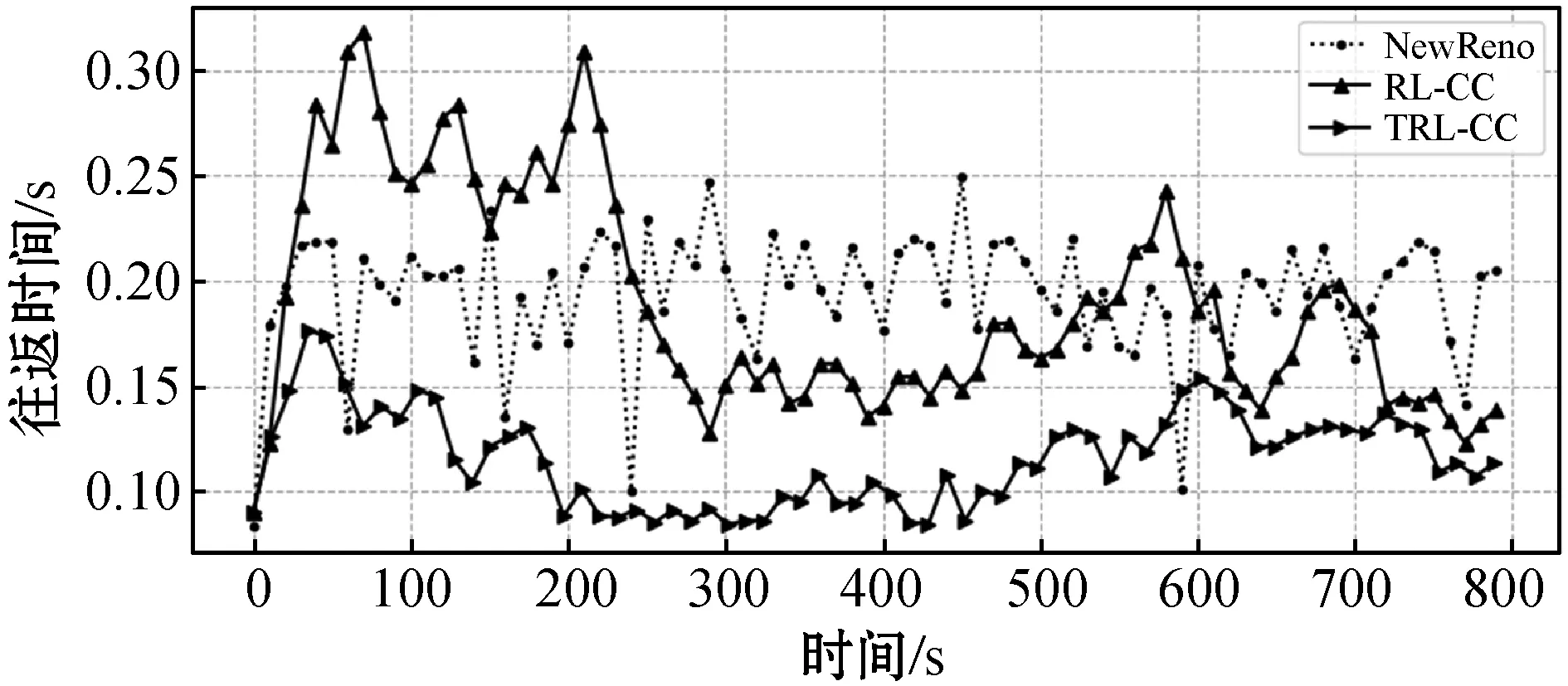
(a) 三个算法的往返时间
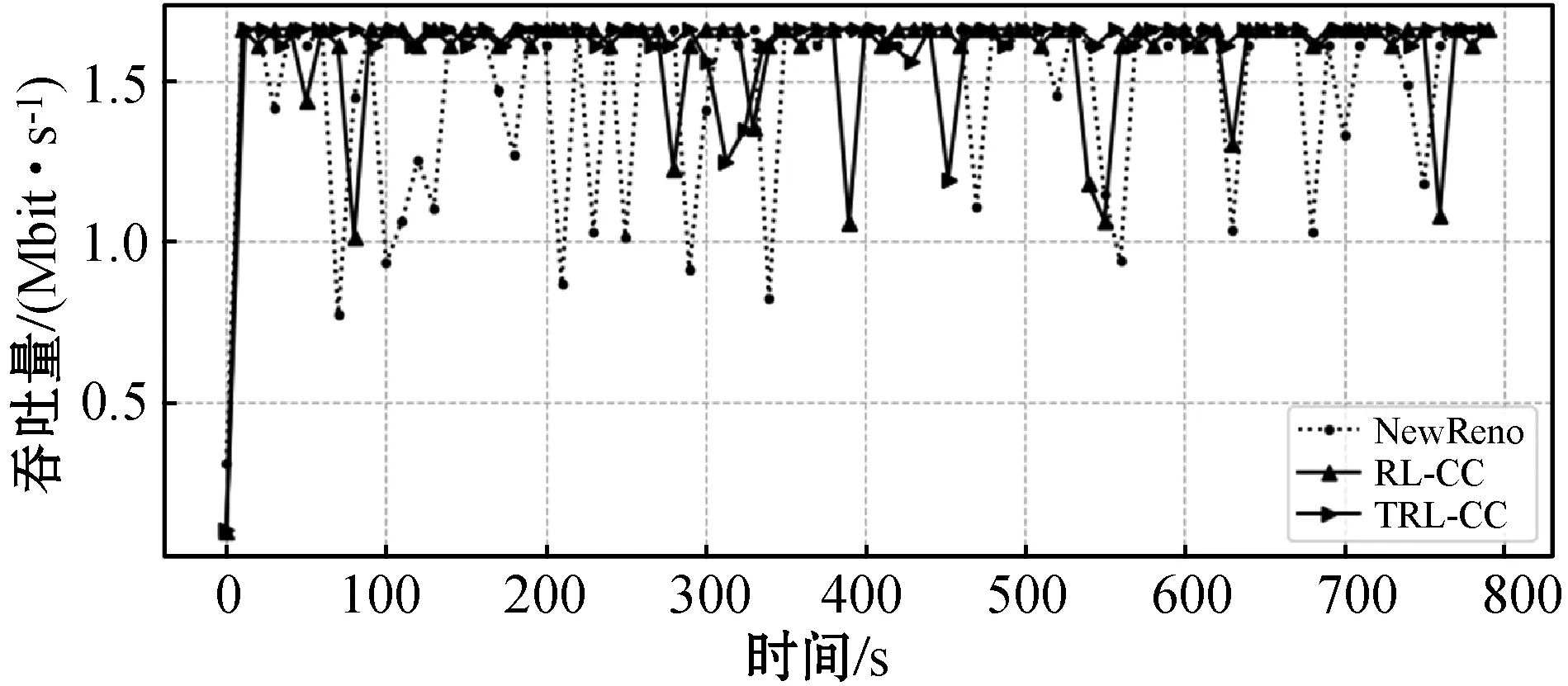
(b) 三个算法的吞吐量
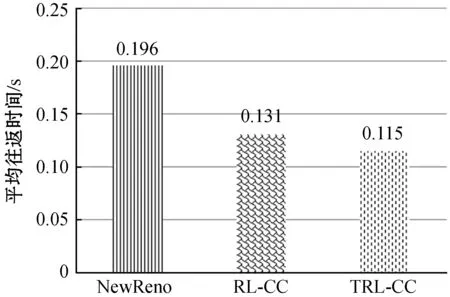
(c) 平均往返时间
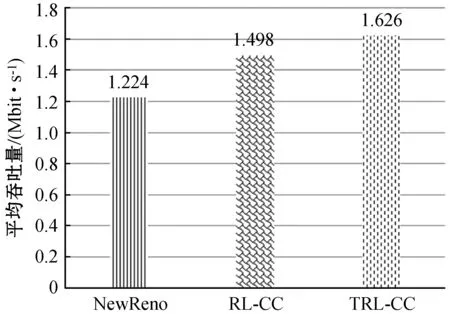
(d) 平均吞吐量图7 TRL-CC、NewReno、RL-CC比较
通过图7(a)和图7(b),得到了图7(c)和图7(d)。可以进一步看出,TRL-CC无论在时延还是吞吐量方面,它的性能较于前两者都是最好的。这是因为它利用历史经验中潜在的因果关系,并且得以从效用函数中体现。TRL-CC在吞吐量方面较NewReno提升32.8%,较RL-CC提升8.5%,瓶颈带宽链路得到了充分利用;较NewReno时延降低41.3%,较RL-CC时延降低12%。
TRL-CC不仅在吞吐量和延迟方面达到了较高的性能,而且相较于其他两个方案更均衡吞吐量和时延,更加具有鲁棒性。
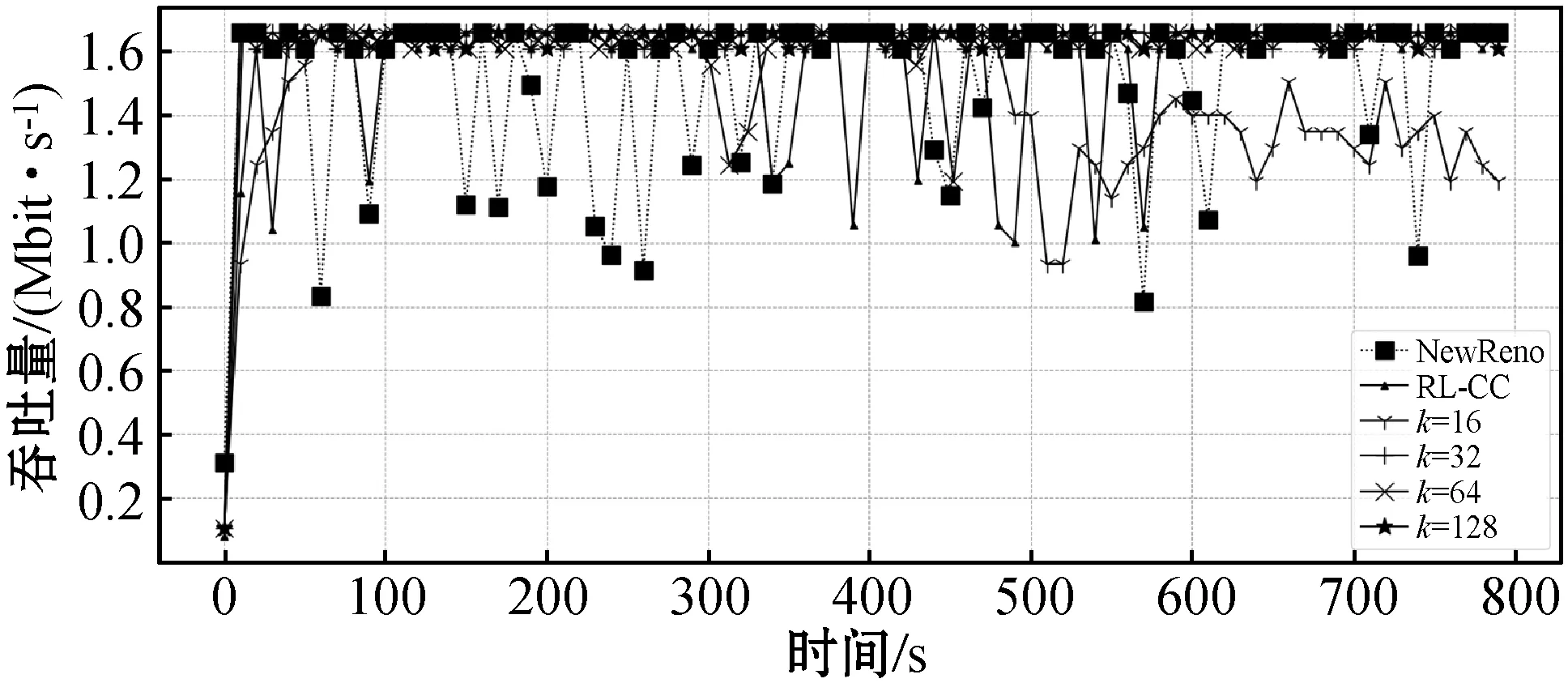
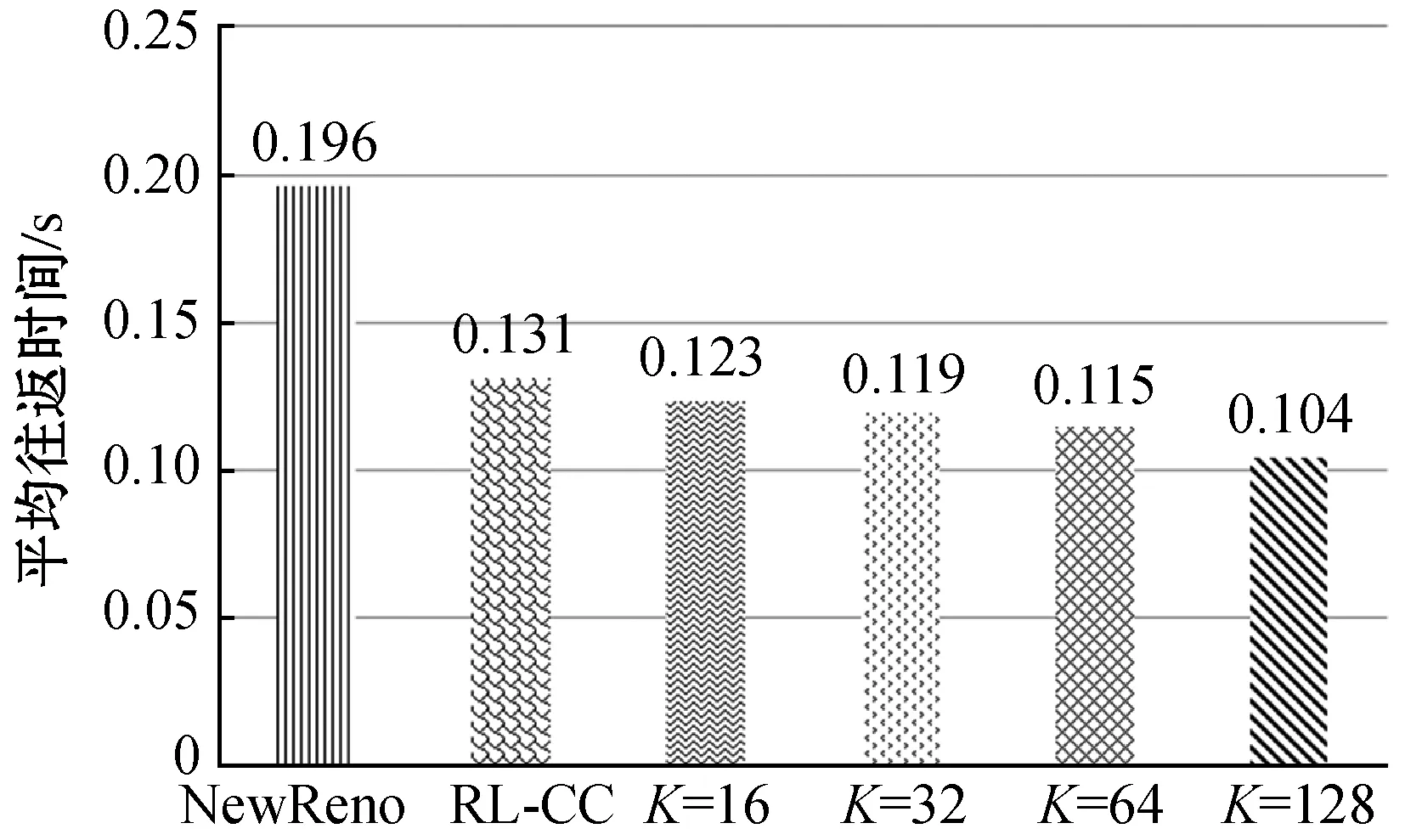
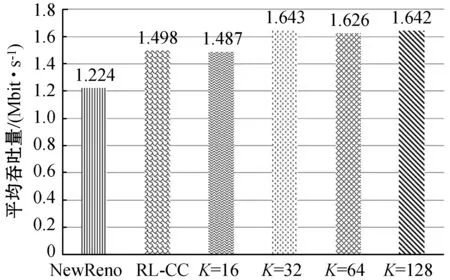
4.2.3K取值分析
在考虑过去经验时,过去经验选取数量(K)对拥塞控制有着很大影响。此节对历史经验K取值进行比较,同时取不同K值的方案也与NewReno以及RL-CC作对比,结果如图8所示。
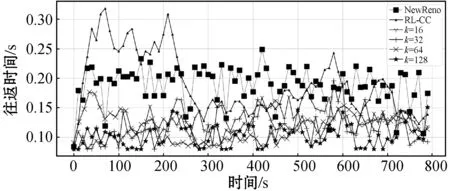
(a) K取不同值的往返时间对比
(b) K取不同值的吞吐量对比
(c) 平均往返时间
(d) 平均吞吐量图8 K取值不同对网络影响
正如图8(a)所示,当K=64和K=128时,延迟波动较小且在最小往返时间附近,相对较小。反观K=16和K=32时,尽管时延在NewReno和RL-CC下面浮动,但却几乎没有收敛到最小往返时间附近。这种原因有两种:(1) 在定义状态空间时,代理加入了队列延迟这一特征;(2) 关键是时序卷积网络处理较长时间的历史经验,它能够存储更长时间的信息,代理可以从更丰富的信息中学习,使队列延迟一直保持较小值。另一方面,图8(b)表示吞吐量的变化,K取值大(K=64 128),吞吐量变化保持稳定。结果表明,历史经验K越大时,TRL-CC方案的性能越优。同时,通过图8(a)和图8(b),TRL-CC通过效用函数均衡了吞吐量和往返时间。最后,柱状图(图8(c)、图8(d))进一步诠释了上述结论。
4.2.4高带宽网络
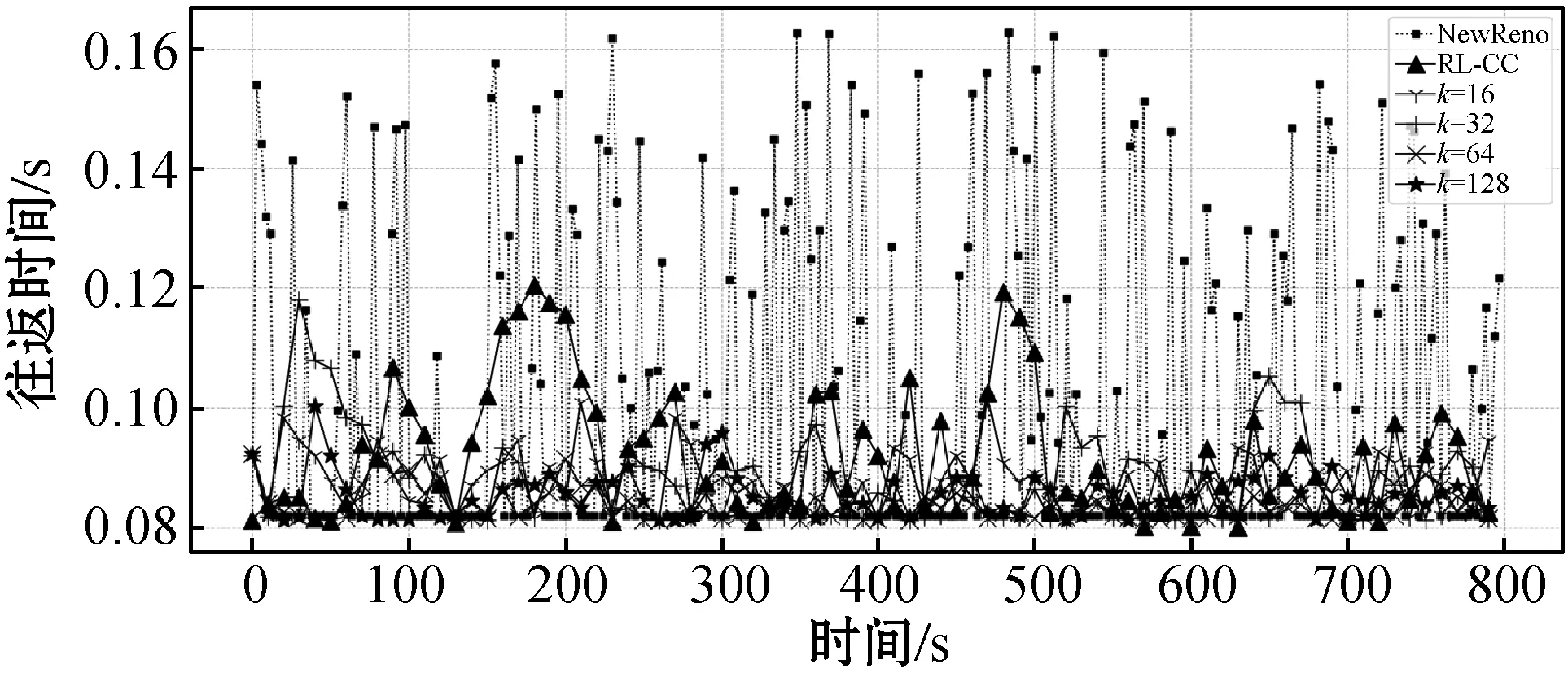
本节把在瓶颈链路带宽2 Mbit/s、最小往返时间为80 ms训练好的模型直接部署到网络瓶颈链路带宽为20 Mbit/s、最小往返时间为80 ms的网络中。每个片段的训练时间仍然是800 s。
在网络发生变化时,图9表示三种拥塞控制方案的自适应性。NewReno因基于规则的设计,不能从历史经验中学习,导致它在面对网络变化时表现出很差的性能甚至使网络出现崩塌。TRL-CC在面对网络变化时仍然可以从历史经验中学习到最优策略,具有更好的鲁棒性。如图9(a)所示,随着瓶颈链路带宽的增大(与2 Mbit/s相比),往返时间变小。这是由于带宽变大时队列延迟降低,这显然是合理的。图9(b)是相应的吞吐量随模拟时间的变化,当历史经验K取值较大时,代理在学习过程中会谨慎。这是因为代理综合“考虑”历史经验,避免出现网络性能下降。历史经验K取值越大、延迟越小且在最小往返时间附近波动;吞吐量也越稳定。
(a) 链路带宽为20 Mbit/s的往返时间
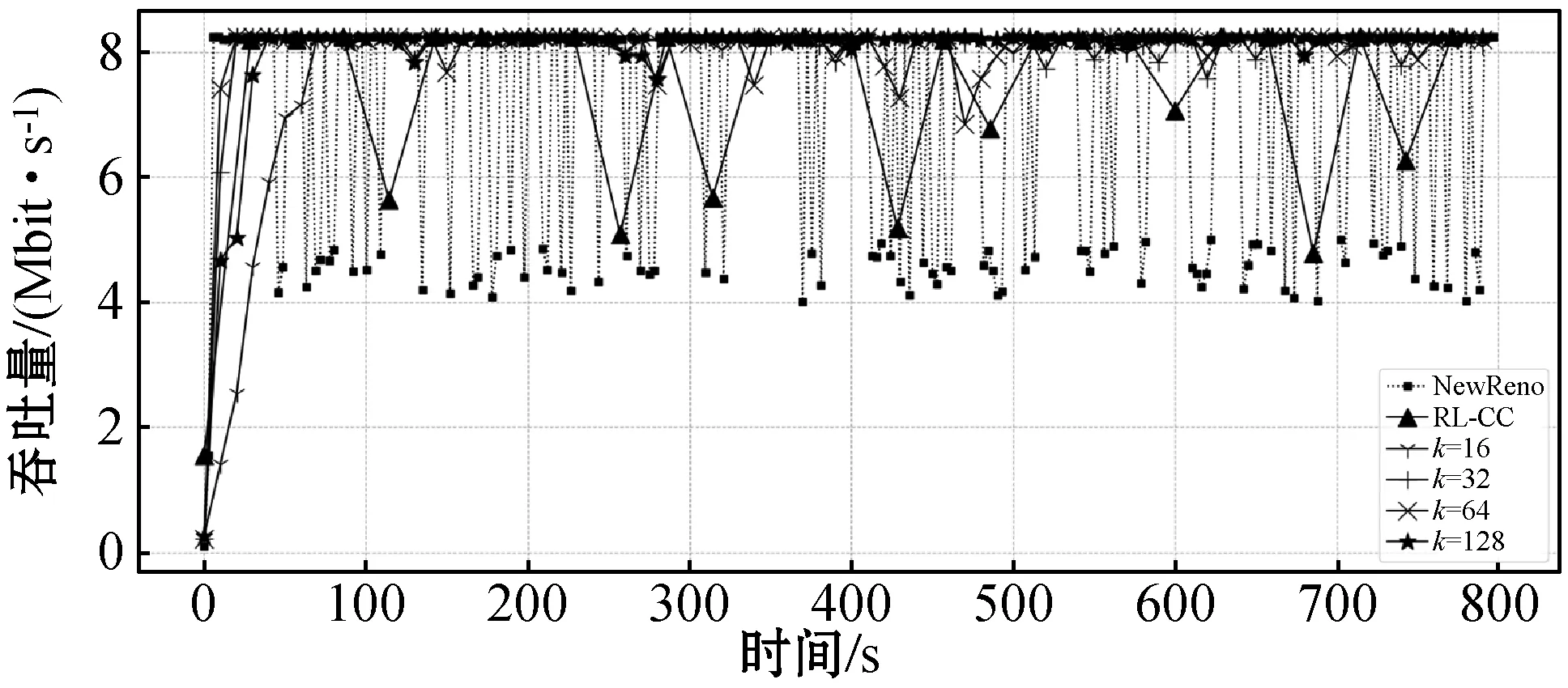
(b) 链路带宽为20 Mbit/s的吞吐量
(c) 平均往返时间
(d) 平均吞吐量图9 链路带宽发生变化时性能对比
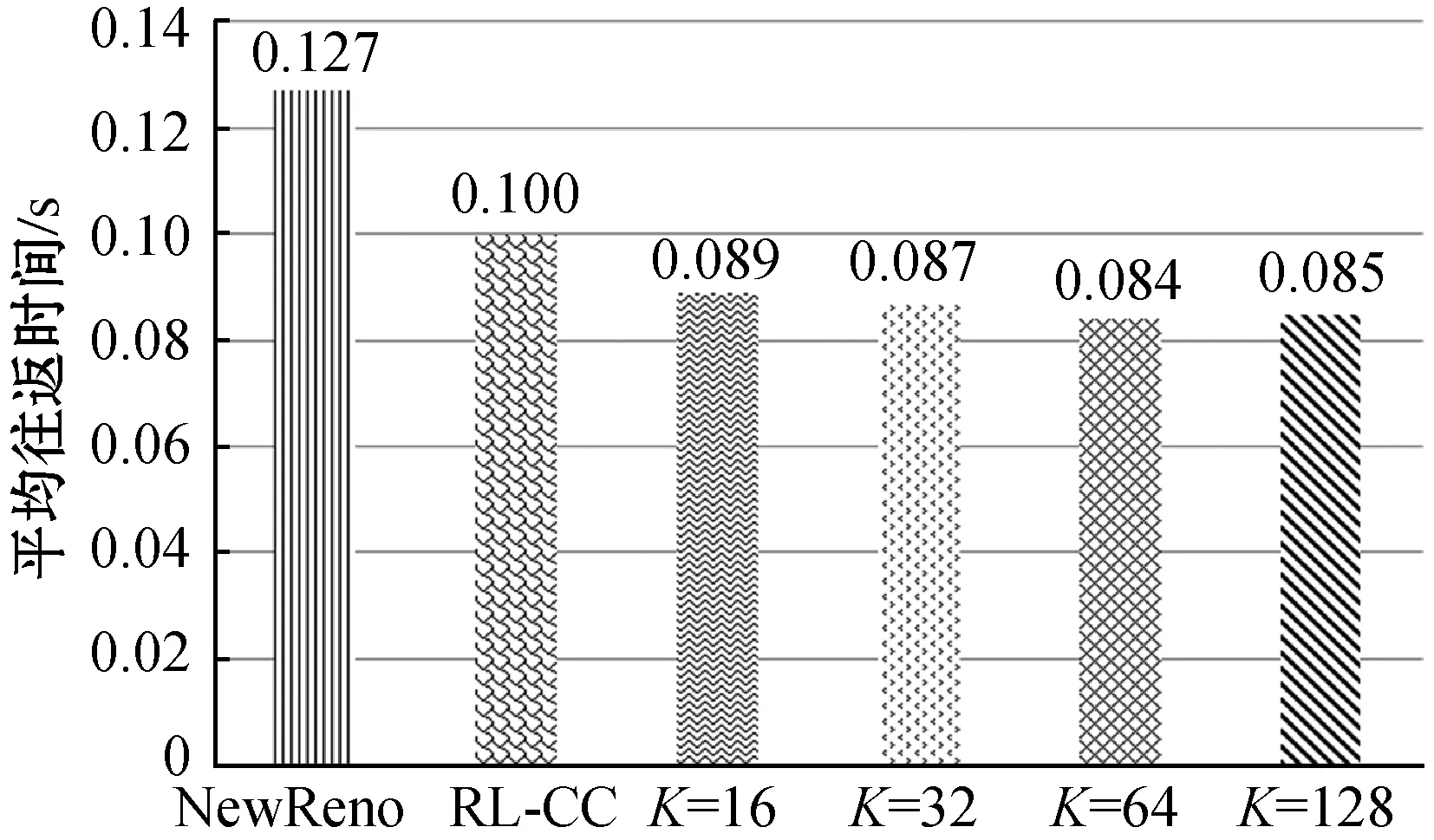
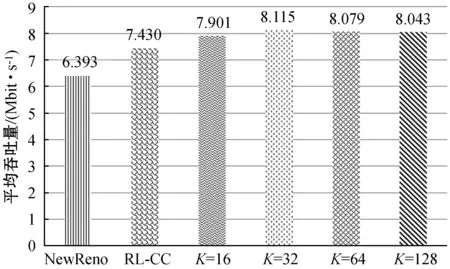
图9(c)和图9(d)表明,TRL-CC较NewReno吞吐量提升25.8%,较RL-CC吞吐量提升8.3%。另一方面,TRL-CC较NewReno延迟降低33%,比RL-CC降低15%。最终,在变化的网络中,TRL-CC的自适应性更好,仍然能保持最优性能。
5 结 语
本文提出智能化的拥塞控制方案。不像传统的基于规则的拥塞控制协议,它通过量化往返时间控制拥塞窗口自适应动态变化。虽然RL-CC通过学习过去经验对未来网络进行规划,取得了较好的效果。但TRL-CC通过时序卷积网络处理过去经验在时序上存在的因果关系,这使得该方案较RL-CC更具有鲁棒性,在吞吐量和往返时间方面取得更好的性能。
首先,本文在瓶颈链路带宽较小的网络中部署TRL-CC。TRL-CC较NewReno和RL-CC(未考虑过去经验在时序上存在的因果关系)在吞吐量和延迟方面达到了更好的性能。在平均吞吐量方面,TRL-CC比NewReno提升32.8%,比RL-CC提升8.5%。同时TRL-CC的时延比NewReno降低41.3%,比RL-CC降低了12%。然后,把训练好的TRL-CC迁移到高带宽网络环境中,不需要再次训练。通过实验分析,TRL-CC的吞吐量比NewReno和RL-CC分别提升25.8%和8.3%;延迟降低33%和15%。最终,本文对历史经验K取值进行探讨,发现代理“考虑”历史经验越多时,TRL-CC越可以更好地均衡吞吐量和时延。
