基于数据对齐的生成性对抗网络轴承剩余寿命预测
2023-04-07陈世红陈荣军
陈世红 陈荣军
1(广东生态工程职业学院信息工程学院 广东 广州 510520) 2(广东技术师范大学计算机科学学院 广东 广州 510665)
0 引 言
旋转机械的预测与健康管理在提高机械可靠性、降低维修成本和提高运行安全性等方面具有重要的意义[1-2]。在过去的几年里,机械设备的监控管理(Prognostics Health Management,PHM)受到了越来越多的重视,特别是在先进制造产业,如汽车制造、航空航天工业等领域[3-4]。作为旋转机械中的关键部件之一,滚动轴承的剩余使用寿命(Remaining Useful Life,RUL)预测更是研究的重中之重[5]。
在过去的几年中,轴承剩余寿命预测方法包括神经网络、支持向量机和神经模糊系统等数据驱动方法,因其易于实现、响应速度快和预测前景好等优点得到了广泛的发展,并取得了一系列研究成果[6-8]。梁昱等[9]提出了一种多方位预测的集成深度学习方法,利用TIR和频域特征来构建轴承的健康指标。Pan等[10]提出了一种有效的机器健康状态估计方法,采用在线动态模糊神经网络,对轴承健康状况进行预测。另外,还有一种基于卷积神经网络的多尺度特征提取方法[11],利用从振动数据中学习到的特征实现了轴承剩余寿命预测。
尽管在数据驱动的预测方面取得了进展,但仍旧存在两个问题未被很好地解决:(1) 首次预测时间(First Predicting Time, FPT)的确定。传统方法中将所收集的数据与剩余寿命值之间进行直接建模,其对应规则往往是时变的,因此失效初始时刻即首次预测时间的确定将对预测精度影响较大,但是该时间的确定仍主要依赖于峰度等常规特征,限制了预测精度的提升。(2) 实体间的数据分布差异数据驱动方法的成功主要依赖于训练和测试数据来自同一分布的假设。由于在轴承RUL预测问题中,训练和测试数据是在不同条件下收集的。当机器的转速等工作条件相同时,轴承的故障往往是不同的。因此,不同轴承的退化行为不尽相同,导致实体间存在显著的数据分布差异。因此,限制了数据驱动模型的泛化能力。
针对上述问题,本文研究并提出一种生成性对抗神经网络模型,用于数据驱动旋转机械轴承的RUL预测。在两个旋转机械数据集进行了实验验证,数值结果表明,该方法相对于传统的数据驱动方法能够有效解决上述问题,并且实现精度较高的预测。
1 理论方法
1.1 问题描述
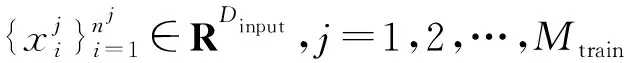
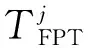
其次,由于可以获得训练实体的FPT,因此可以将每个轴承的运行到故障数据分为健康状态和退化状态。退化期间的剩余使用寿命百分比可计算为:
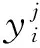

1.2 对抗神经网络
本文引入对抗神经网络进行预测,该模型首先用于生成对抗网络(Generative Adversarial Networks,GAN)[14]。GAN的目标是从随机噪声中生成现实的数据样本,生成器模块G用于将噪声z映射到样本x。为了评估生成的数据G(z)的质量,采用了判别模块D,该模块经过优化以区分真实样本和伪样本。然而,生成器参数的更新影响了判别器的工作,即生成不能被判别器区分的样本。因此通过两个模块之间的对抗训练,生成器逐渐学习噪声和真实样本之间的基础映射函数G。网络模型优化的损失函数可以表示为:
(2)
式中:pdata和pz分别表示实际数据和噪声的分布。
近年来,对抗训练从不同领域提取共享特征方面得到了进一步的发展[15-16]。与GAN方案类似,多个域的数据样本首先经过特征提取器模块以获得高级特征,这些特征通常携带有域偏向信息。随后采用域判别器模块,以高级特征为输入,并输出域分类结果。判别器旨在分离不同域的数据,而特征提取器则试图获得不容易分类的特征。通过对抗训练,特征提取器可以将不同域的数据投影到同一区域,从而获得共享特征。
2 基于数据对齐的生成性对抗网络
2.1 总体介绍
图1给出了本文方法的思路。首先,通过传感器测量机器的瞬时振动加速度数据。具体而言,假设将轴承整个生命周期的振动数据收集为训练数据集。在提出的框架中使用了两个训练阶段,即FPT确定和RUL估计。
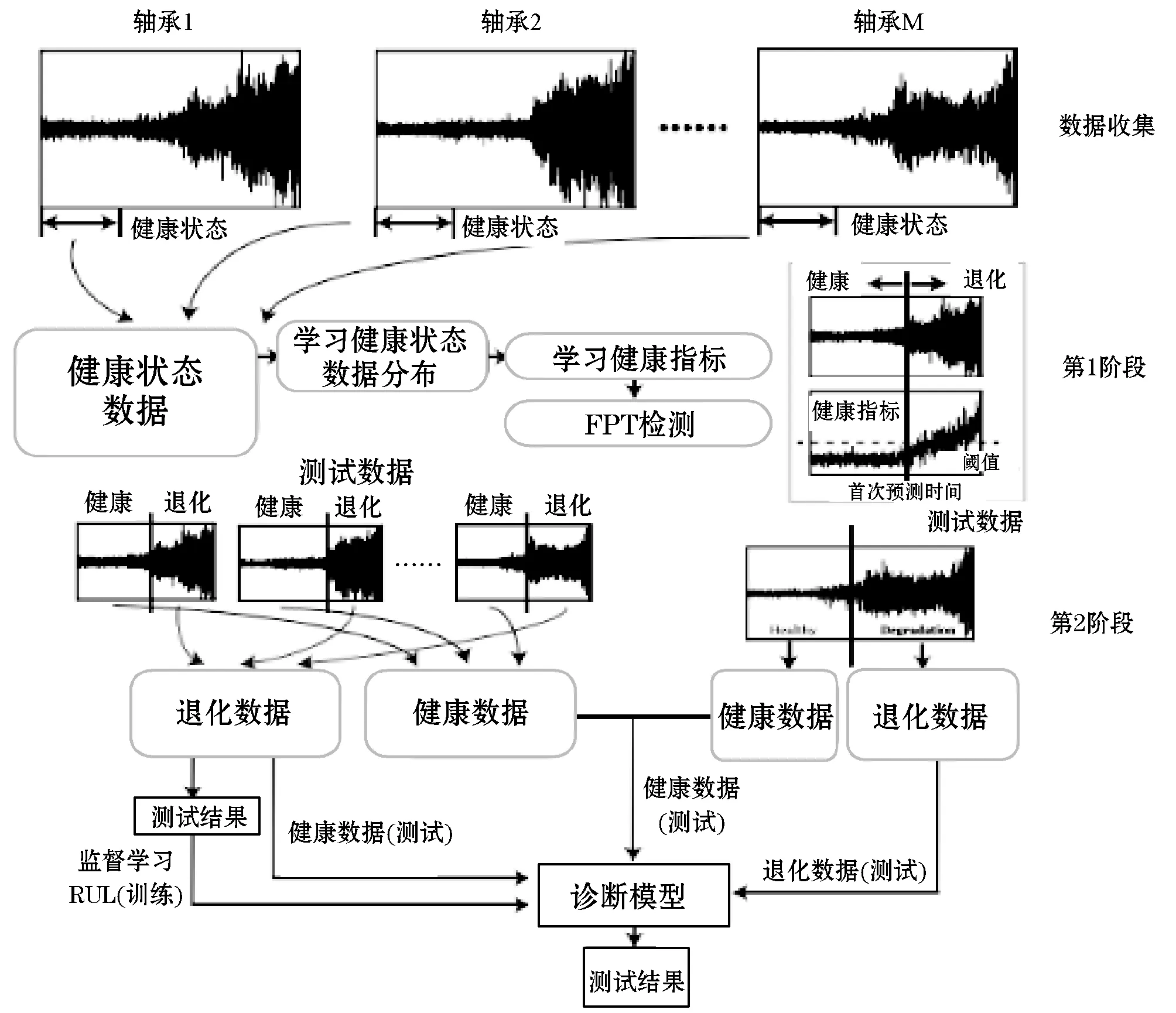
图1 本文预测方法概述
通常,可以将处于早期的轴承视为处于健康状态,并使用深度神经网络模型来学习相应的数据分布。提出性能退化评估指标来显示机器的退化程度,从而可以在阶段1中确定第一个预测时间。然后,获得所有训练轴承的FPT,将生命周期数据分为机器健康状态和退化状态。可以计算出退化状态下轴承的剩余使用寿命,从而可以获取数据样本的RUL标签。
第1阶段的深度神经网络针对RUL预测的回归问题进一步扩展,并使用带有RUL标签的有监督数据进行训练。此外,为了增强模型泛化能力,通过对抗训练将来自不同轴承的数据分布差异最小化。来自不同训练和测试轴承的健康状态数据被投影到学习的子空间中的同一区域中,并且各种训练轴承的退化数据也被映射到相同的区域。这样,可以提取不同轴承实体之间的共享特征,并可以大大提高测试数据的预测性能。
2.2 阶段1:FPT确定
在阶段1中,确定轴承的FPT,这对预测的准确性至关重要。如图2所示,在整个机器生命周期中收集数据之后,通常可以认为处于早期运行状态的轴承处于健康状态。假设在时间t1和t2的健康状况相似。但是,如果将tFPT1不合适地设置为第一个预测时间,则会对它们进行不同的处理,从而导致无效的预测。相反,在这种情况下,tFPT2更适合作为FPT。
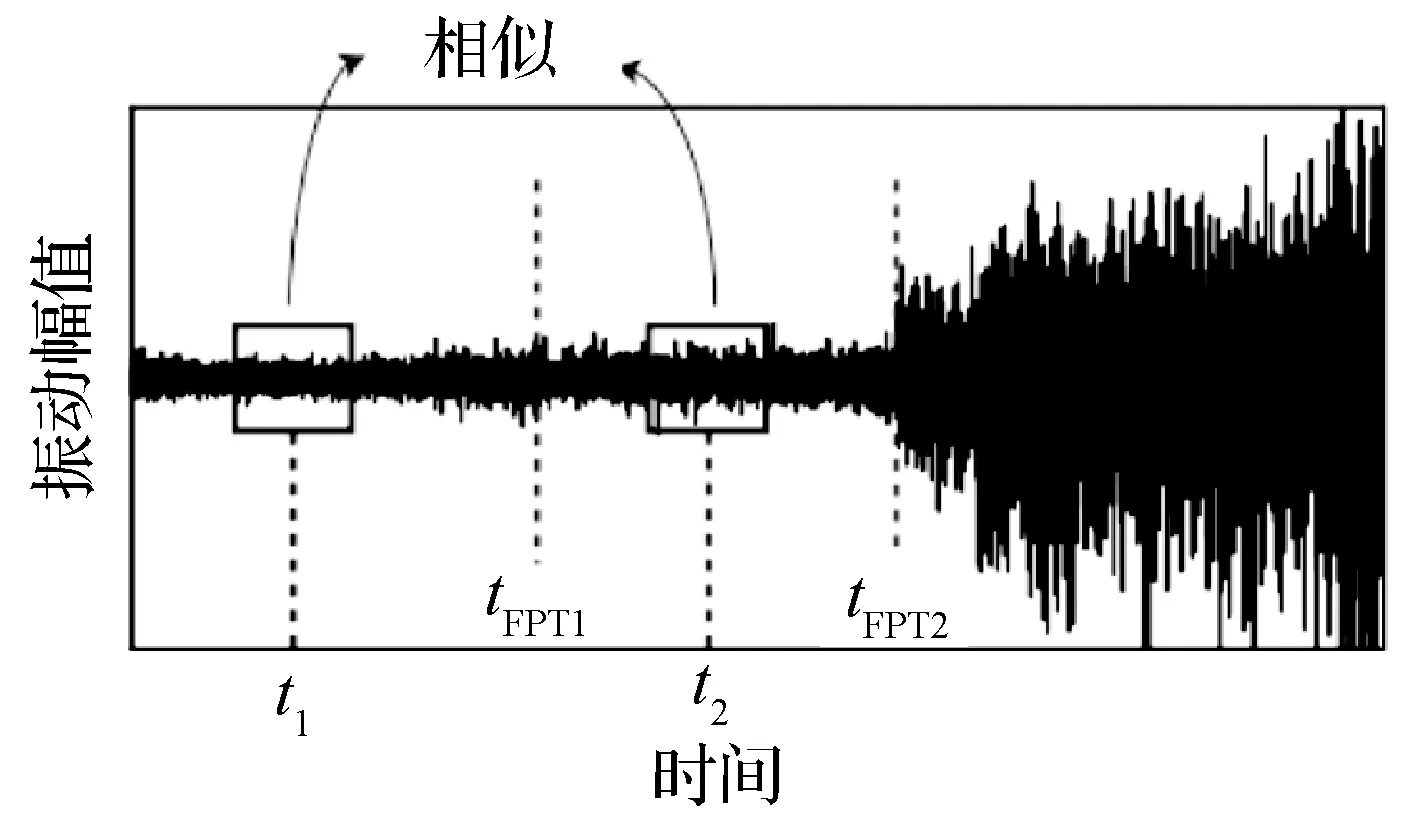
图2 机械振动数据中首次预测时间的图示
采用深度生成对抗网络模型来学习所有训练轴承的健康状态数据的分布。通常,该网络旨在学习噪声向量z∈RDz与实际数据样本x∈RDinput之间的映射函数。这被表示为参数化为神经网络的生成器G。Dz和Dinput分别是噪声向量和数据样本的维数。具体来说,在生成器中使用具有64、32和16个滤波器的三个卷积层。展平后,采用具有512个和Dinput个神经元的两个完全连接的层(Fully Connected layer, FC),因此最后一层中获得的向量就是生成的数据样本。
伪样本表示为G(z;θg),其中θg表示G中的参数。为了测量生成器的性能,特征提取器F使用参数θf处理生成的样本和真实样本。随后将获得的它们的高级表示,即F(G(z;θg);θf)和F(x;θf),以参数θd1馈入判别器D1中。在特征提取器中,使用具有64、32和16个滤波器的三个卷积层,然后是具有512个神经元的平坦层和全连接层。最后,一个神经元附着在判别器D1中,其值表示属于真实数据的输入样本的预测置信度。在整个网络模型中,大多采用渗漏整流线性单元激活函数。
为简单起见,以下将特征提取器和判别器D1的组合表示为判别器。根据GAN中的对抗训练方案,判别器旨在准确分离真实和伪造的数据样本,而生成器则尝试创建无法区分的真实数据。因此,此阶段的参数经过优化可以得到:
z~N(0,I),x∈Strain,h
(3)
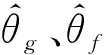
通过将梯度反转层(Gradient Reversal Layer, GRL)引入对抗训练架构中,式(3)可以使用流行的随机梯度下降(Stochastic Gradient Descent, SGD)方法求解,并且可以在训练过程中一步同时更新参数[17]。这样,网络逐渐学习样本的分布,即噪声和真实数据之间的投影函数。
在GAN架构中,判别器O1=D1(F(x))的输出用作输入数据与真实样本之间的相似性的指标。考虑到在此阶段学习了健康状态数据分布,因此输出也适合用作健康状况指标。根据实验结果,当机器处于健康状态时,可以获得稳定的O1值,而O1在退化期间会波动。因此,在本文中,其标准偏差H=std(O1)用于表示机器健康状态,并且引入了阈值系数α>1。H(x)超过αH(xhealthy)的时间被认为是第一个预测时间,其中xhealthy代表运行初期的健康状态数据。
2.3 阶段2:RUL预测
2.3.1RUL预测器
确定FPT后,可以将所有数据分为健康状态和退化状态。阶段2旨在确定轴承在退化条件下的剩余使用寿命。基于网络体系结构,在此阶段还利用了在阶段1中学习到的知识。所有样本都直接送入经过训练的特征提取器中,作为真实数据显示在图中。代替判别器1,高级表示由三个模块进一步处理,即RUL预测器、判别器2和判别器3。
具有参数θr的RUL预测器R包括三个卷积层,分别有64、32和16个滤波器,以及两个分别具有512和1个神经元的全连接层。在卷积层之后使用主动丢弃策略以避免过度拟合。 最后一个神经元的值表示预测的RUL。在优化中,将预测误差最小化,并使用了三类损失函数:
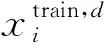
2.3.2条件数据对齐
尽管在RUL预测问题中,监督训练十分有效,但未考虑不同轴承的退化数据差异,这会导致预测性能下降。因此提出一种数据对齐方法,以使用对抗性训练策略提取用于RUL预测的实体不变特征。总体思路在于,应该将来自类似机械健康状况的数据投影到不同实体的学习子空间的相同区域中。
图3显示了提出的条件数据对齐方案的图示。
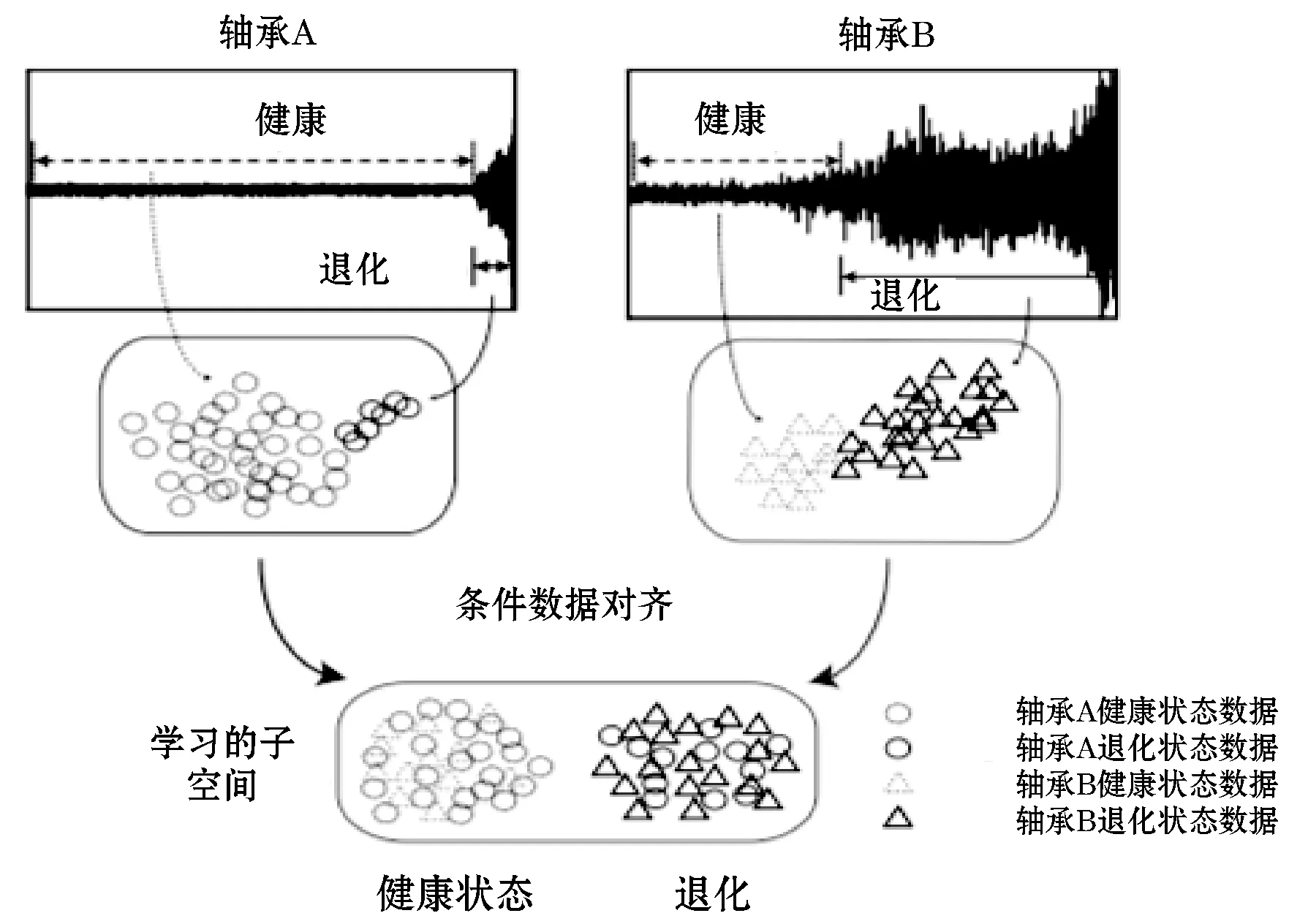
图3 针对不同轴承的数据对齐方案
首先,处理健康状况数据。除训练样本外,机器早期运行期间的测试数据通常也可以使用,可用于更好地进行数据对齐。具体来说,将从特征提取器获得的训练和测试轴承的数据表示都进入具有参数θd2的判别器2中,该参数由两个卷积层和两个全连接层组成。Mtrain+Mtest个神经元附着在最后一个全连接层,每个神经元代表属于不同轴承实体的输入样本的预测置信度。最后,采用Softmax函数进行分类。
在优化中,判别器2旨在精确识别数据源,同时训练特征提取器以获得无法区分的表示。 更新参数以实现。
x∈Sall,h
(5)
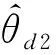
x∈Strain,d
(6)
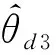
2.3.3网络模型参数优化
式(4)、式(5)和式(6)可以在此阶段集成,并且通过使用GRL,可以在一个训练步骤中更新网络参数,例如:
Ld2=Lce(D2(F(x))),x∈Sall,h
Ld3=Lce(D3(F(x))),x∈Strain,d
(7)
式中:δ是学习率;fAdam,f、fAdam,r、fAdam,d2和fAdam,d3分别表示参数θf、θr、θd2和θd3的Adam优化方法中的计算函数;εr、εd2和εd3分别表示损失Lr、Ld2和Ld3的惩罚系数。
3 实验与结果分析
3.1 数据集描述
3.1.1XJTU-SY数据集
在本文中,利用两组加速滚动轴承退化测试数据集验证了本文方法。XJTU-SY数据集由西安交通大学提供。测试台如图4所示。15台LDK-UER204滚动轴承在两种转速下进行了测试。从运行到故障的振动加速度数据是通过轴承箱上的加速度计获取的。每1分钟以25.6 kHz的采样率收集1.28 s中的32 768个数据点。本文将水平方向的振动数据用于预测。为了安全起见,当振动幅度超过20g时,将停止加速退化轴承测试,并且该时刻被视为轴承的故障时间。表1中提供了数据集信息。

图4 XJTU-SY数据集中的轴承测试台
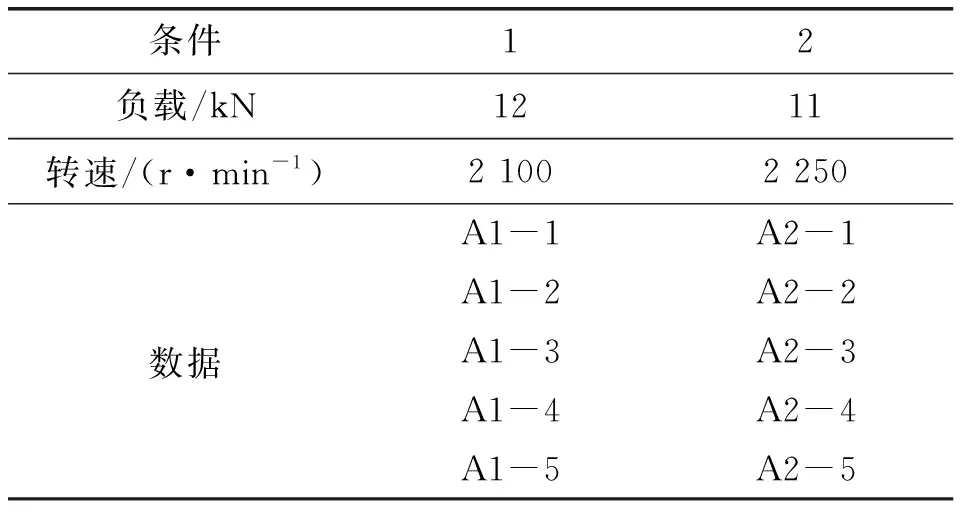
表1 XJTU-SY数据集的信息
3.1.2PHM2012数据集
本文中使用的第二个数据集是在平台PRONOSTIA上收集的,如图5所示。同步电动机、轴、速度控制器和两个滑轮的组件用于改变滚动轴承的速度。同样,研究水平方向的振动数据。具体来说,来自PRONOSTIA平台的PHM 2012 Challenge数据集用于验证,其中包含17个轴承的运行到故障数据。每10 s测量2 560个数据点,即0.1 s,采样频率为25.6 kHz。为了安全起见,当振动数据的振幅超过20g时,停止实验。表2中提供了数据集信息。

图5 用于轴承加速退化测试的PRONOSTIA平台
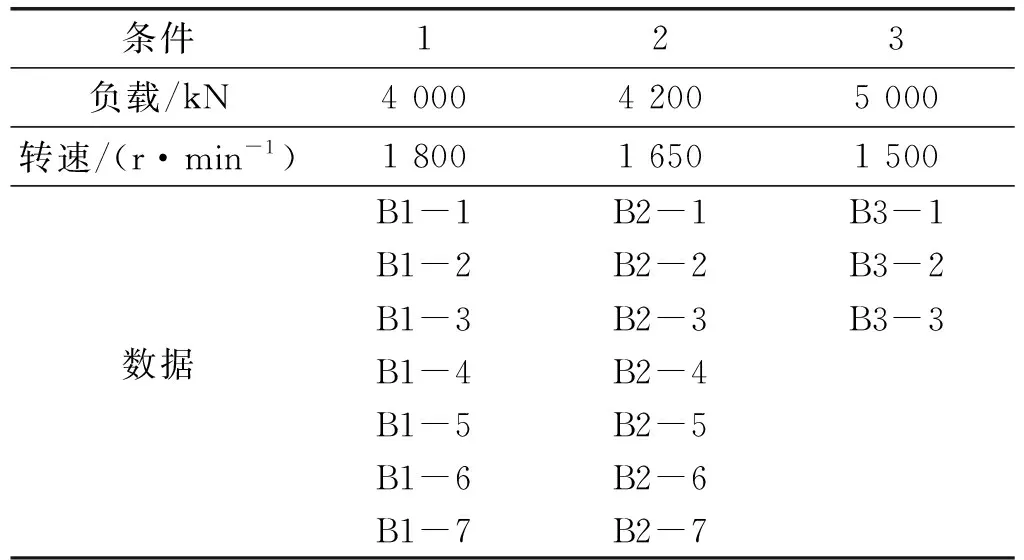
表2 PHM 2012数据集的信息
3.2 比较方法
以下方法与本文方法具有相似的实验设置和网络体系结构。
(1) Basic:利用TIR和频域特征来构建轴承的健康指标,即文献[9]中提到的方法。该方法遵循数据驱动预测的传统模式。没有使用FPT,并且RUL标签是在轴承的整个生命周期中确定的。在RUL预测问题中进行了简单的监督学习,这表明在优化中仅考虑了损失Lr,并删除了数据对齐方案。
(2) NoAlign:在所提出的方法中没有考虑数据对齐方案的情况下,实现了NoAlign方法,包括健康状态和退化状态数据对齐。在第2阶段中,仅执行损失Lr。
(3) NoHealthyAlign:健康状态数据的对齐未在NoHealthyAlign方法中实现,即删除了判别器2。
(4) NoDegradeAlign:该方法忽略判别器3,并且不考虑退化数据的对齐。
在执行预测方法时,首先准备输入数据样本。即考虑从机器定期收集数据的两个数据集的信息,每个样本中包含NC个连续的测量数据片段,并且在每个片段中使用Np个连续振动加速度数据点。这导致每个样本中包含NC×Np个数据点。数据准备方案如图6所示。当测试某个轴承时,将使用相同工作条件下其他轴承的数据进行训练。
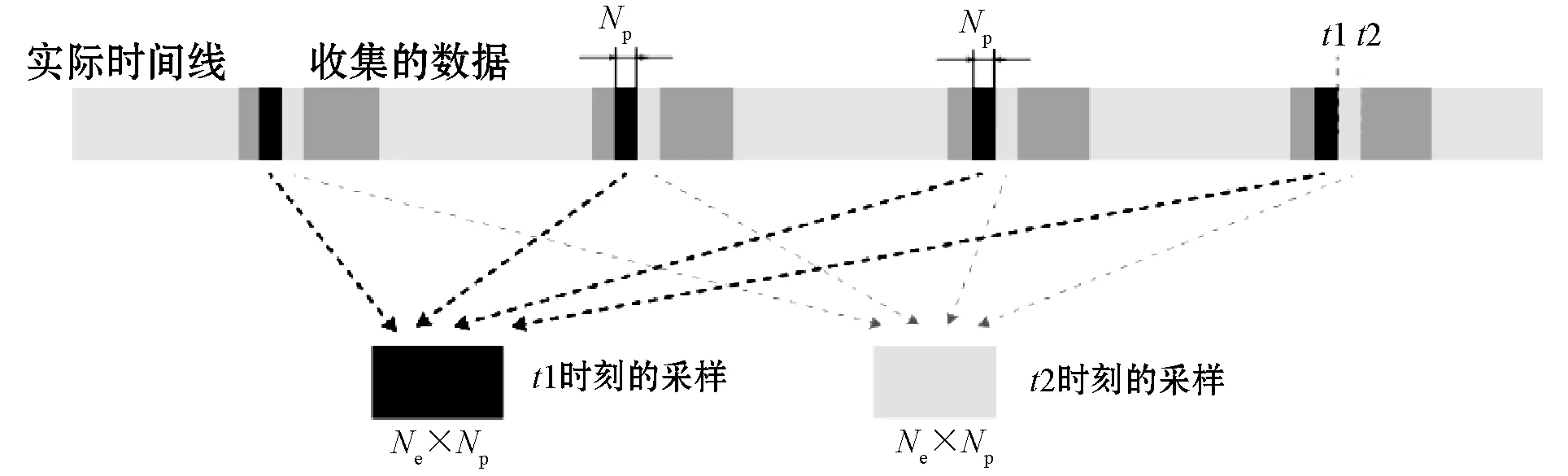
图6 本文的数据准备方案
在网络模型优化中,采用反向传播学习对模型参数进行更新,采用Adam优化算法。已为初始化部署Xavier标准初始化器。详细的模型参数和实验设置见表3。通常根据验证任务确定它们,在该任务中对轴承A1-1进行测试,并在相同的工作条件下使用其他轴承进行训练。在这项研究中,使用三个指标来评估预测性能,即平均绝对误差(MAE)、平均绝对百分比误差(MAPE)和均方根误差(RMSE)。
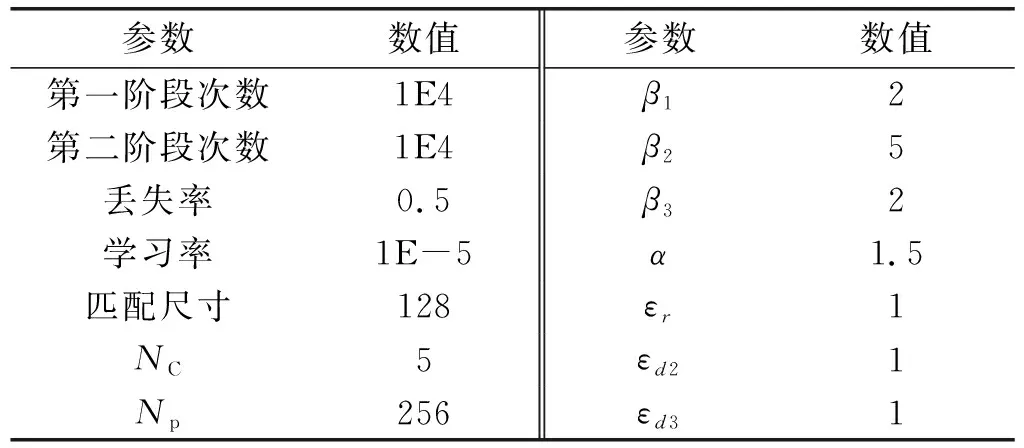
表3 本文使用的参数
3.3 实验结果
本节将在不同情况下评估本文方法的预测性能。通常将实验结果平均5次,以减少模型随机性的影响。表4显示了通过不同方法对XJTU-SY数据集进行的数值预测结果。可以观察到,本文方法通常在包括MAE、RMSE和MAPE这三个指标的不同预测任务中实现最低的预测误差。当MAE和RMSE测量预测值与基本事实之间的距离时,MAPE度量通过不同的方法评估比例估计误差。Basic方法会获得较大的预测误差,这表明简单的监督学习方案在RUL预测问题中的有效性较低。应当指出,Basic方法是本文的基础方法,它遵循常规的监督学习模式。结果表明,本文方法明显优于Basic方法,证明了本文算法的优越性。NoAlign方法的结果明显优于Basic方法,但仍然没有竞争力。使用提出的数据对齐方案,NoHealthyAlign和NoDegradeAlign方法都可以实现可观的预测结果。但是,在大多数情况下,结果仍不如本文方法好。
表5给出了PHM 2012数据集的数值预测结果。该方法在不同情况下也取得了可观的结果,并且观察到的模式与表4中的XJTU-SY数据集相似。因此,在两个数据集上验证了本文方法的有效性。
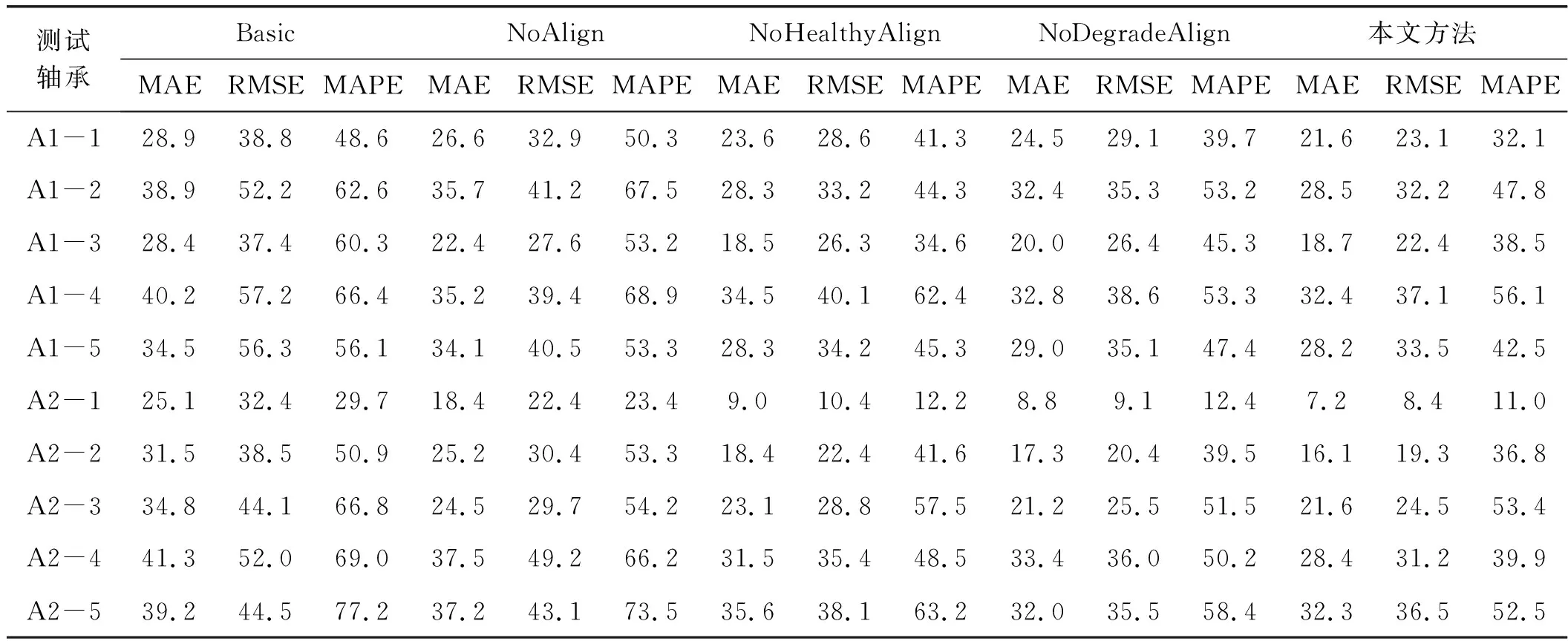
表4 XJTU-SY数据集上不同方法的数值预测性能比较

表5 PHM 2012数据集上数值预测性能比较
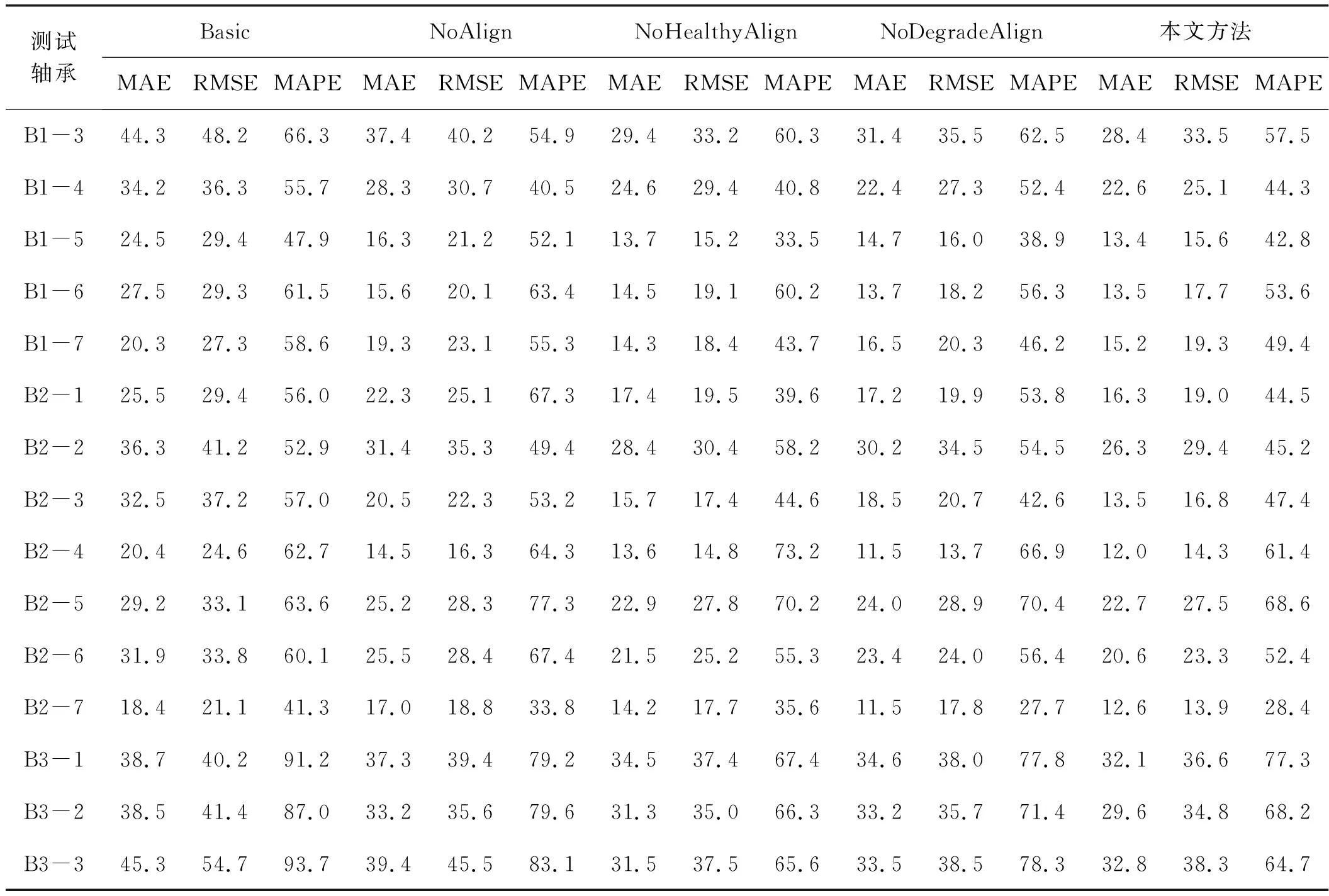
续表5
3.3.1健康指标和FPT结果
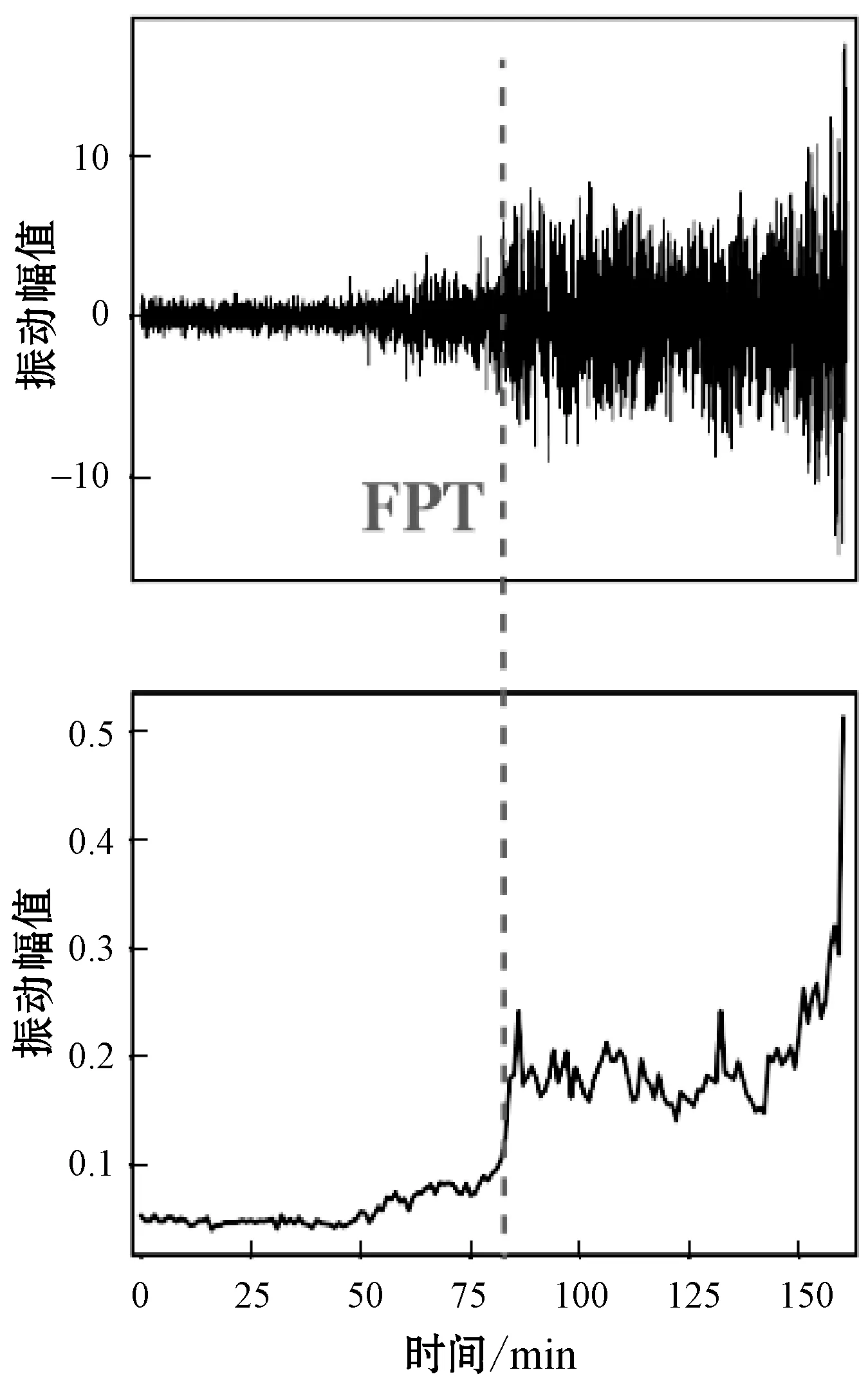
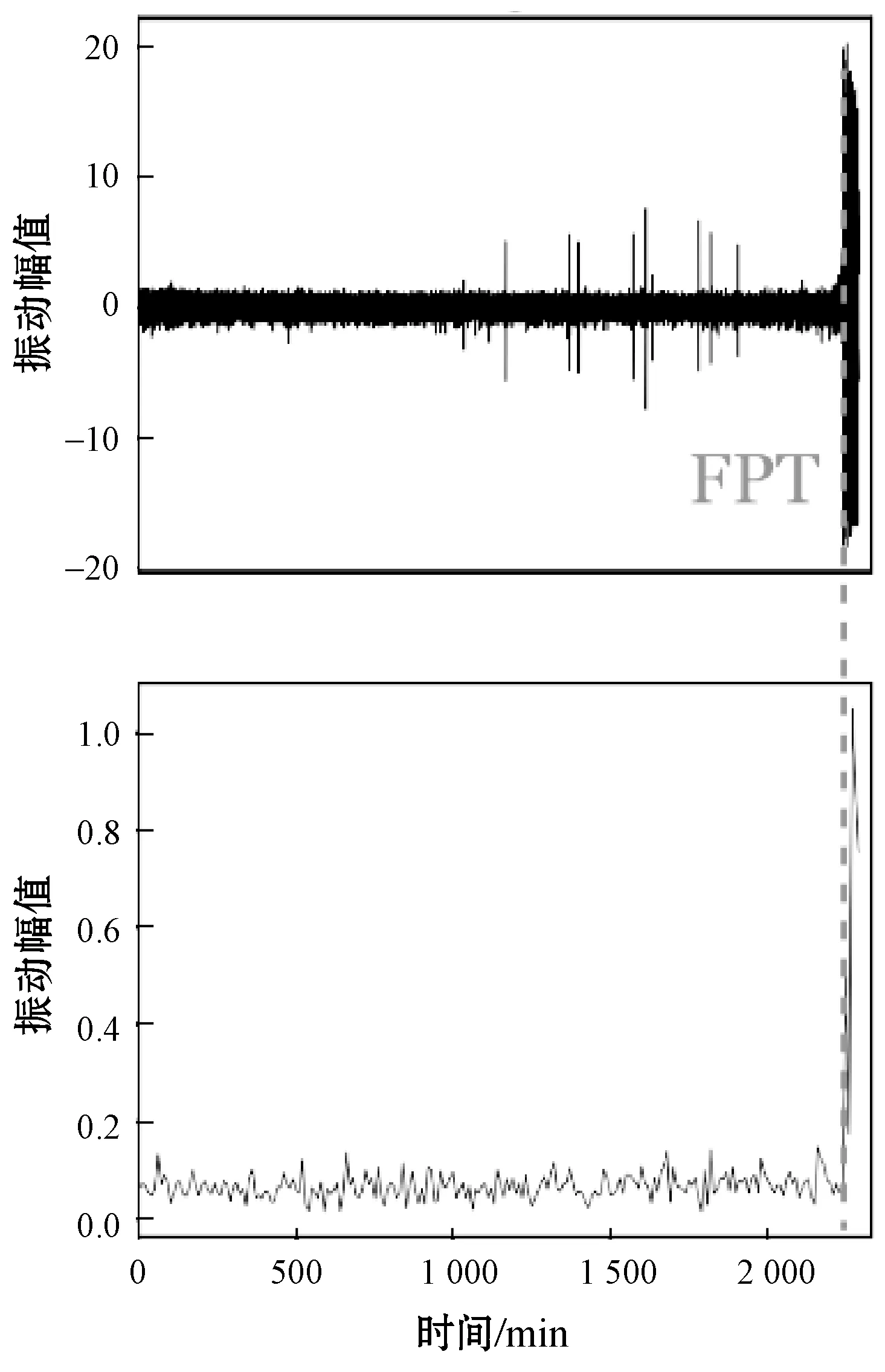
在本节中,提出振动幅值的健康指标以及获得的不同轴承的首次预测时间。图7和图8显示了两个数据集上的四个示例。可以观察到,在早期运行阶段,健康指标通常保持在较低水平,且波动很小。当轴承开始退化时,随着振动的加剧,健康指标会显著增加。结果表明,所提出的健康指标非常适合用于监测机械的健康状况,并且相应的FPT能够很好地指示退化时间。
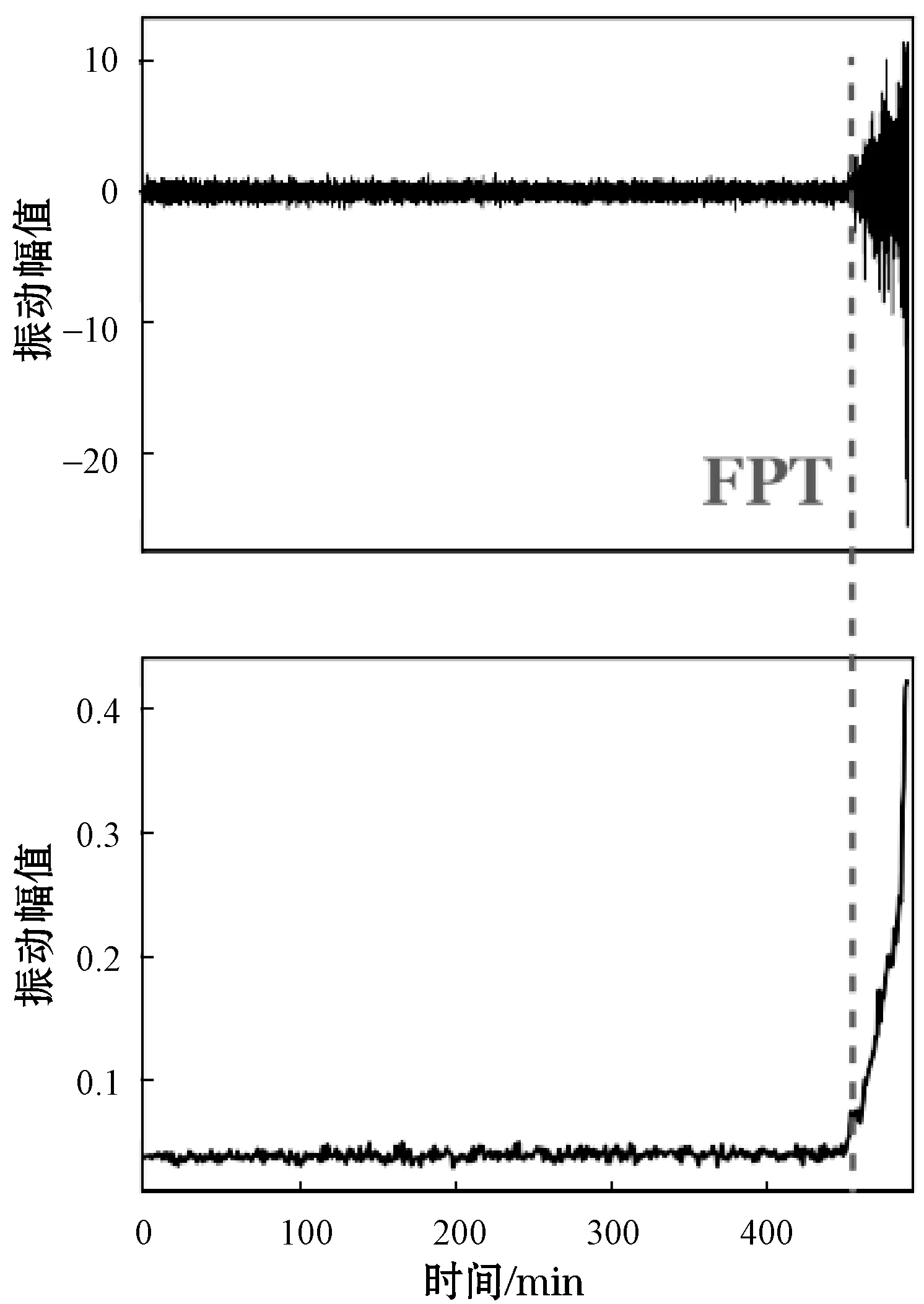
(a) 轴承A2-1
(b) 轴承A2-2图7 XJTU-SY数据集的首次预测时间和健康指标
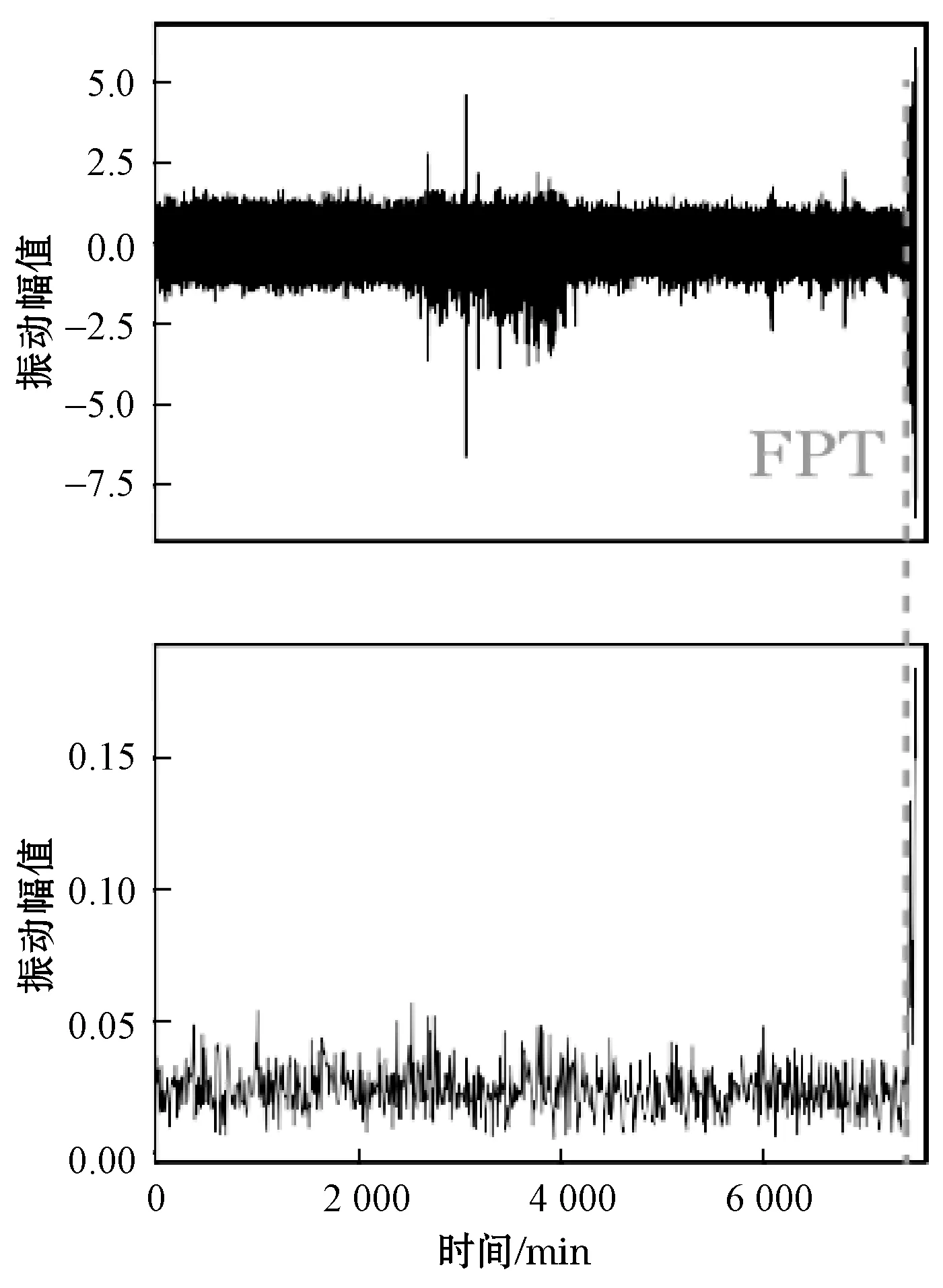
(a) 轴承A2-1
(b) 轴承A2-1图8 PHM 2012数据集的首次预测时间和健康指标
应该指出的是,所提出的健康指标是使用特征提取器模块构建的,该模块也将在随后的阶段2中使用。因此,阶段1所学的知识不仅支持FPT确定,而且对RUL预测有利。
3.3.2RUL预测结果
下面分析在测试轴承的退化状态下的RUL预测结果。图9显示了两个数据集中的四个预测实例。可以看出,本文方法能够准确预测在不同情况下轴承的剩余使用寿命。有效地捕获了一般的退化模式,并且预测误差很小,尤其是在后期运行期间。这在实际行业中对于后期维护至关重要。
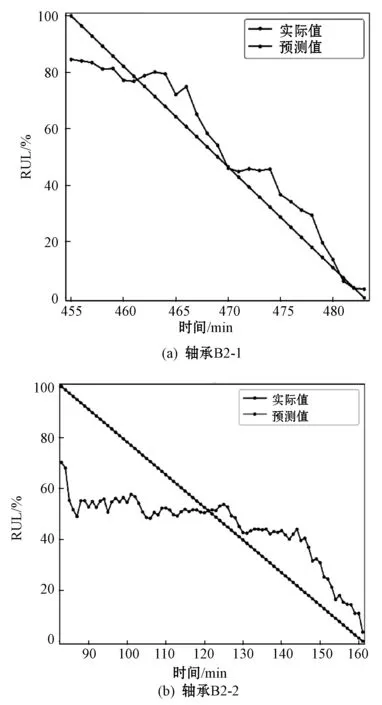
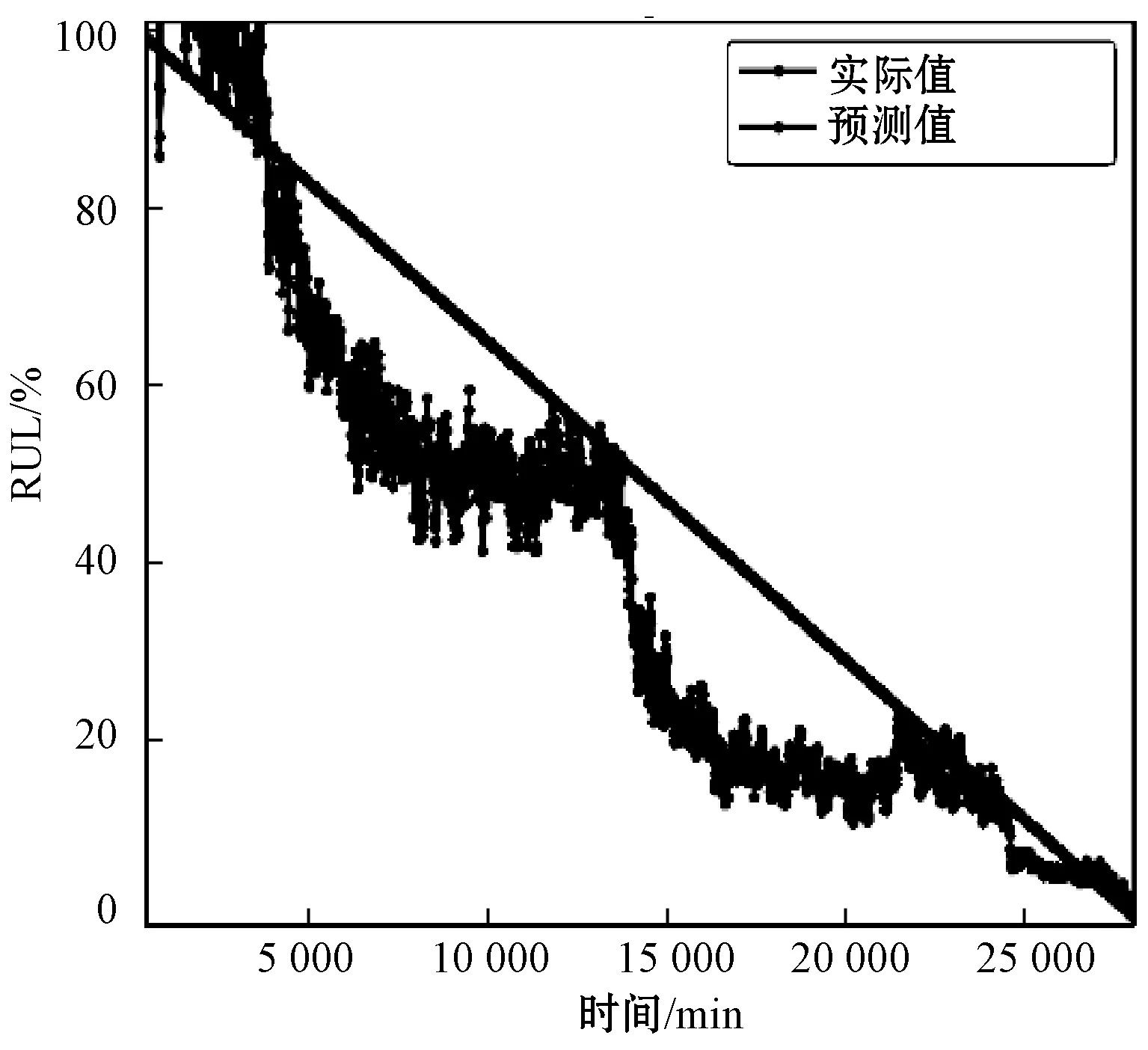
(c) 轴承B1-1
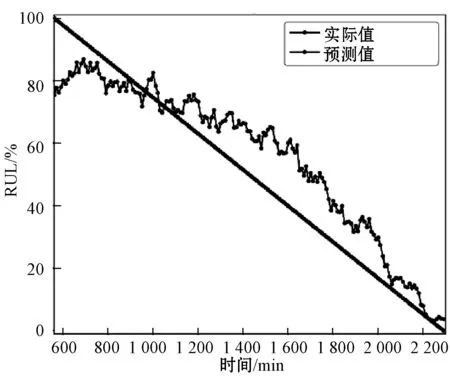
(d) 轴承B2-7图9 四个测试轴承的剩余使用寿命预测
3.3.3特征可视化
本节将可视化分析所提出的网络模型学习表示,以显示特征学习的结果。具体而言,研究了特征提取器学习到的表示,并使用t-SNE方法将高维数据转换为二维以进行可视化。
图10显示了两个RUL预测情况的可视化结果,分别测试了轴承A2-2和A2-3。可以看出,使用提出的数据对齐方法,将健康状态下的训练和测试数据投影到学习的子空间的相同区域中,并且训练轴承的退化数据也实现了良好的聚类性能。尽管在模型训练期间没有测试退化数据,但是它们也被投影到与训练退化数据相似的区域中。这样,获得了较好的数据对齐效果,有助于新测试轴承的预测知识概括。
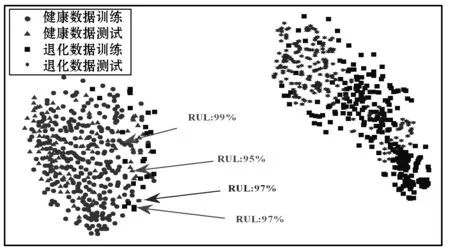
(a) 测试轴承A2-2

(b) 测试轴承A2-3图10 两种预测情况下学习数据表示的可视化
此外,在可视化中只能观察到有限数量的数据未对齐。一些退化数据样本被投影到健康状态数据区域中。但是通过样本跟踪,可以发现未对齐样本的RUL标签通常接近100%,这表明它们与健康状态数据本质上相似。因此,未对齐仍然符合实际的退化方案。
4 结 语
针对传统智能数据驱动轴承剩余寿命预测中存在的首次预测时间确定难度大以及模型泛化能力差等问题,提出一种基于数据对齐的生成性对抗网络轴承剩余寿命预测方法。基于两个轴承退化实验分析可得如下结论:
(1) 首次预测时间的精确定位会提升最终的剩余寿命预测精度,进一步说明了首次预测时间的重要性。
(2) 数据对齐的引入不仅有利于提升预测性能,而且提高了预测模型的泛化能力,使得模型能够充分利用各种类型的实验数据,对数据实现了良好的聚类性能。
(3) 本文方法能够有效地反映退化过程,并较好地实现轴承的剩余寿命预测,该模型可以很好地推广到测试数据,提升了方法的泛化性能。
