语音识别在轮机模拟器中的应用
2023-04-07何治斌张永成
冯 涛 何治斌 张永成
(大连海事大学船舶动态仿真与控制国家重点实验室 辽宁 大连 116026)
0 引 言
轮机模拟器是能够模拟船舶机舱中设备操作的系统,能够体现船舶机舱中的实际操作情况。在一定程度上能够克服实际中存在的缺陷,进行针对性的操作训练。近些年在STCW公约马尼拉修正案的标准约束下,轮机模拟器的交互方式也一直在发生着变化[1],而在传统模拟器的实际操作中仍然存在着操作者的分工职能无法体现的缺陷[2],并且在VR技术应用于虚拟船舶机舱后,传统的交互方式会破坏仿真环境下的沉浸感。语音识别技术的应用能够在一定程度上解决这个问题,在训练操作中如果出现超出操作者的职能范围的操作,可以使用语音交互的方式对模拟器发出指令,来模拟合作者的身份,从而更好地体现分工合作的目的。在应用了VR技术后的虚拟船舶机舱中,语音识别可以使操作者摆脱键盘与鼠标的复杂交互方式,在虚拟船舶机舱中的交互更加便捷[3]。本实验工作主要分为两个部分:搭建语音识别系统;展示基于语音交互的发电机操作。
1 语音识别系统搭建
1.1 语音识别基本原理
语音识别系统的任务是在输入为音频信号的情况下,输出最可能的词序列。搭建语音识别系统的核心工作是构建由语音特征矢量至模型词序列之间的关系[4]。语音识别的原理可以用以下公式简单概括:
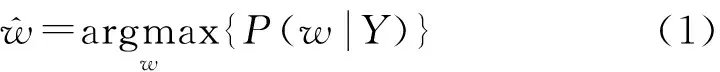
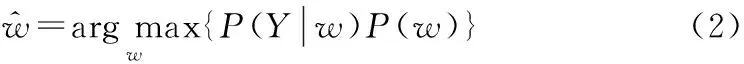
可以看出,ASR(Automatic Speech Recognition)的概率模型分为P(Y|w)和P(w)两个部分,其中:P(Y|w)表示在词序列w一定的情况下获得音频信号Y的概率;P(w)表示在所有的字词所组成的语句中,词序列w的概率。前者在语音识别系统中通常被称为声学模型(Acoustic Model,AM),后者被称为语言模型(Language Model,LM)。由式(2)可以看出语言模型和声学模型对语音识别的结果至关重要,因此搭建语音识别系统的主要工作即在于对语言模型和声学模型的建模[5]。语音识别系统的基本架构如图1所示。
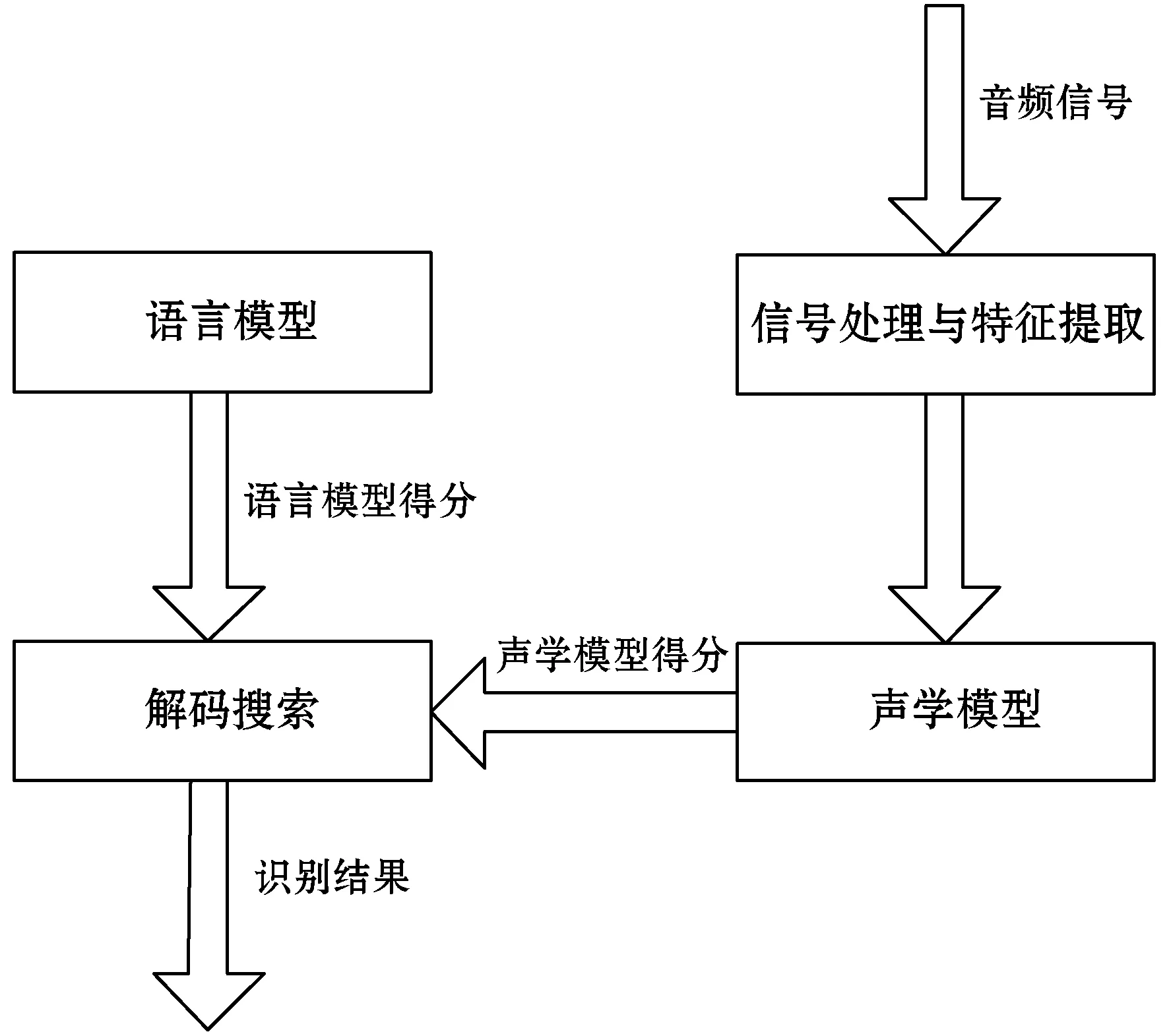
图1 ASR架构
1.2 声学模型建立
1.2.1语音信号处理与特征提取
处理语音信号并提取特征是训练声学模型的准备工作。通过设备采集到的音频有低频段信号能量小、信号不平稳等问题,需要进行信号数字化、预加重、加窗分帧等处理。本实验提取语音信号的梅尔频率倒谱系数(Mel-Frequency Cepstral Coefficients,MFCC)作为声学模型训练的声学特征[6]。MFCC的特征提取流程如图2所示。

图2 MFCC提取流程
在提取特征的流程中,为了提高信号高频部分的能量,使高频信号共振峰更加明显,对采集到的语音信号首先进行预加重。预加重滤波器为一阶高通滤波器。给定时域输入信号x(n),则预加重之后的信号可以表示为:
y(n)=x(n)-α(n-1) 0.9≤α≤1.0
(3)
由于语音信号为非平稳信号且具有短时平稳的特性,因此,对预加重后的语音信号进行分帧加窗来获取短时平稳的语音信号。具体操作为在时域上使用窗函数与原始信号进行相乘,可由式(4)表示。
y(n)=ω(n)x(n)
(4)
式中:x(n)为输入信号;ω(n)为窗函数;y(n)为加窗语音信号。窗函数的选取中较为常用的有:
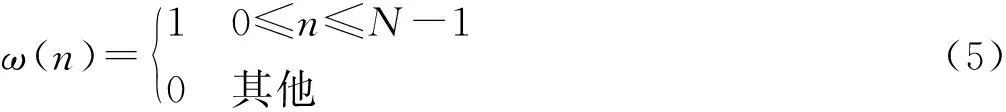
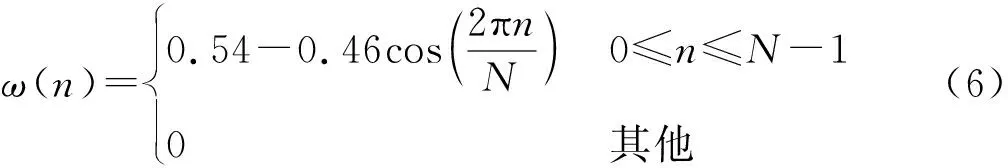
对加窗分帧后的语音信号使用离散傅里叶变换,将时域信号变换到频域,并取离散傅里叶变换系数的模,得到谱特征。对获取的谱特征使用梅尔滤波器组进行滤波,然后对滤波后的结果取对数并进行离散余弦变换,获取MFCC,这一过程的计算可表示为:
(7)
式中:M为梅尔滤波器组的个数;s(m)表示第m个滤波器的输出;L为MFCC的阶数。
为了使声学模型在轮机模拟器的指令识别中表现得更好,采集轮机领域相关的音频作为声学模型的训练语料,以80%、10%、10%的比例将数据划分,分别用于对声学模型的训练、测试与开发。具体提取过程分为以下几个步骤:
(1) 将语音信号通过高通滤波器进行预加重。
(2) 对预加重后的语音信号进行加窗分帧,使用汉明窗,帧长为25 ms,帧移为10 ms。
(3) 对分帧后的每一帧信号做离散傅里叶变换,将信号从时域变换至频域,并计算功率谱。
(4) 使用梅尔滤波器组对功率谱进行滤波,提取每个滤波器内的对数能量。
(5) 对对数能量进行离散余弦变换,输出12维原始MFCC。
(6) 计算原始MFCC的一阶差分与二阶差分、讯框能量、讯框能量的一阶差分与二阶差分,共计39维,作为生成声学模型的MFCC特征。图3为“启动预润滑油泵”的MFCC语谱图展示。
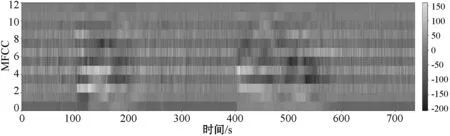
图3 “启动预润滑油泵”的MFCC语谱图
1.2.2声学模型训练
本次实验采用混合高斯隐马尔可夫模型(Gaussianof Mixture Hidden Markov Model)对声学模型进行建模。其中,HMM(Hidden Markov Model)用于对声学特征序列进行建模,HMM是一种双重随机过程的概率模型,通过对有限个状态之间的转换概率进行建模来描述语音信号特征[7]。GMM(Gaussian of Mixture)用于对HMM中的每个状态的输出概率进行建模。GMM-HMM声学模型的示意图如图4所示,其中:Si表示HMM的状态序列;Oi表示观测序列,在语音识别中表现为MFCC特征向量;aij表示从状态i跳转至状态j的转移概率;bi(Ot)表示由状态Si输出观测Ot的概率。图4中语音信号表示的语句为“出口截止阀打开”。
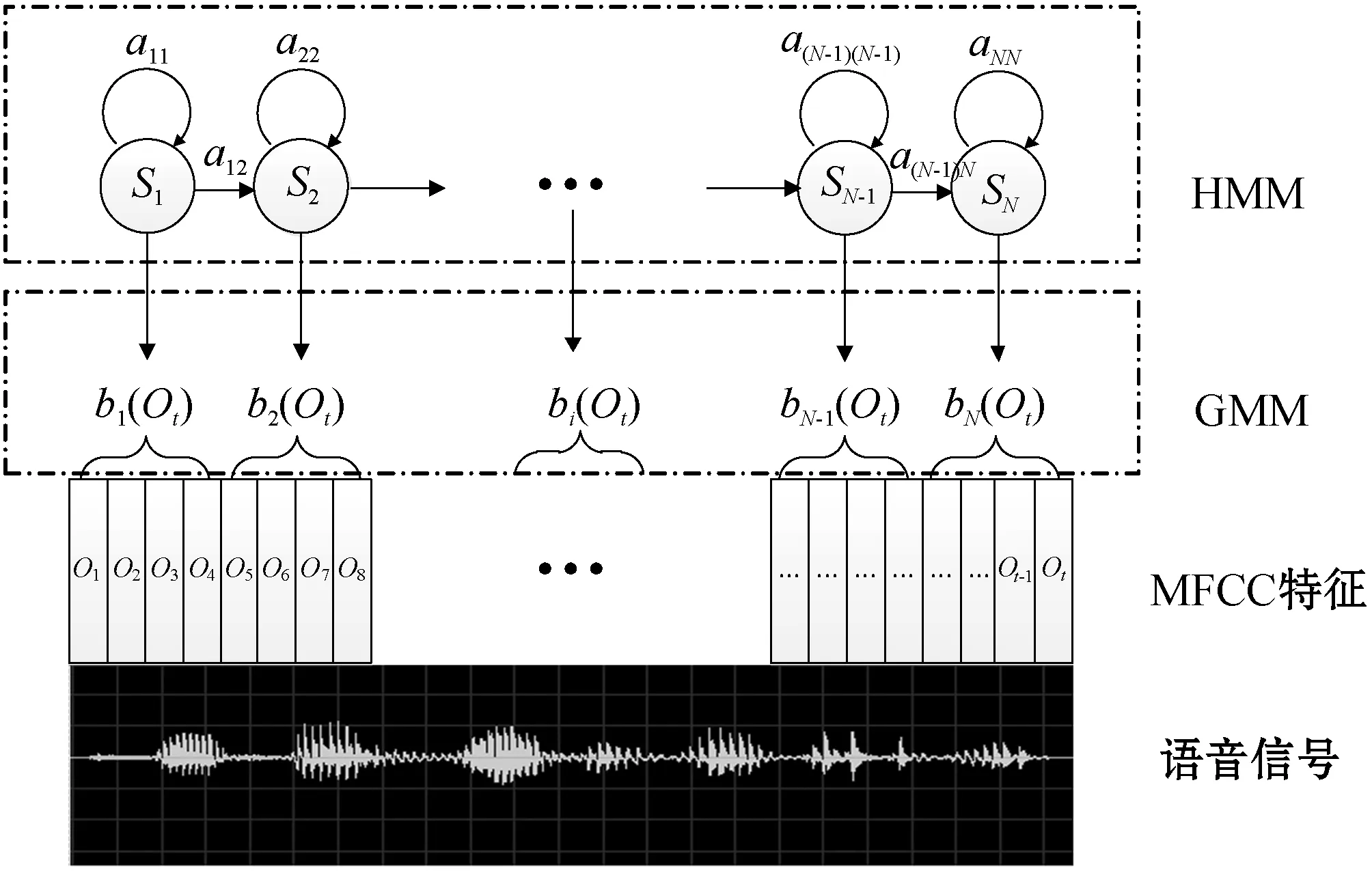
图4 GMM-HMM声学模型示意图
声学模型的训练可表示为在已知观测序列O=(o1,o2,…,oT)的情况下,估计模型λ使得P(O|λ)最大。使用Baum-Welch学习算法对GMM-HMM模型进行训练,其具体步骤如下:
(1) 初始化GMM-HMM参数。
(2) E步(count):估计状态占用概率γ,即给定模型γ与观测O,在时刻t处于状态Si的概率,表示为:
γt(i)=P(it=Si|O,λ)
(8)
(3) M步(normalize):基于估计的状态占用概率,最大化期望,重新估计GMM-HMM的参数。
(4) 重复步骤(2)和步骤(3)直至收敛。
声学模型的训练在Kaldi平台中实现,其部分展示如图5所示。
图5 声学模型片段
1.3 语言模型建立
1.3.1语料收集与处理
语言模型是一种数学模型,用来描述语言之间的规律,决定了语音识别的输出结果是否符合语言逻辑。特定的语言模型能够使语音识别系统在其所使用的领域中识别更准确。因此,本实验从中国船务周刊、现代汉语语料库等报刊与语料库中选取轮机领域相关语料72 910句,并结合清华大学开源语料库THCHS30,共计844 100句,作为本实验训练语言模型的语料。对收集到的生语料使用ICTCLAS工具进行分词,将不同词性的词语进行划分,并对句子起始使用进行标注。语料库部分如图6所示。

图6 语料库片段
1.3.2语言模型生成
语言模型的基本类型分为基于文法规则的语言模型和基于统计的语言模型两种。基于文法规则的语言模型需要设立文法规则并对不同文法使用不同模型,工作量大且无法覆盖所有的语言词句之间的组合。基于统计的语言模型能够使用统计的方法来处理语句之间的前后关系,在处理大型数据时较基于文法的语言模型更快速准确[8]。为实现大词汇量的连续语音识别,本实验采用基于统计的方法对语言模型进行建模。统计语言模型是在提供的语料库中的所有词序列上的一个概率分布,包含有限集合V与函数P(x1,x2,…,xn),且满足以下条件:
对于任意
(9)
本实验使用统计语言模型中的N-gram语言模型作为系统使用的语言模型,也可以称为N元语言模型。N-gram所表示的含义为使用前N-1个词作为历史来估计第N个词(当前词)。一句由n个词组成的句子S可以表示为:
式中:wi表示第i个词。N-gram语言模型可以表示为:
使用SRILM工具训练并测试语言模型。建立语言模型的步骤分为统计词频、生成语言模型、计算困惑度三个步骤。困惑度(Perplexity,ppl)是用来评价一个语言模型性能的指标,合乎逻辑的词序列出现概率与其困惑度成反比。在测试集W=w1w2…wN中,语言模型的困惑度可以表示如下:
为了得到性能更优的语言模型,分别对基于Uni-gram、Bi-gram和Tri-gram的语言模型进行建模并对比三者困惑度。实验结果如表1所示。

表1 三种语言模型的困惑度对比
在对语言模型进行测试的过程中,出现许多频率为零的词序列,这是由语料的稀疏性(sparse data)导致的。为了解决语言模型中出现的这一问题,通常使用平滑算法(Smoothing)处理语言模型,其主要思想是将一部分出现的词序列概率分给未出现的词序列。本次实验采用Kneser-Ney平滑算法对语言模型进行处理。
Kneser-Ney平滑算法的基本思想为绝对折扣(absolute discounting)[9],并在此基础上将绝对折扣与接续概率(continuation probability)进行插值,从而达到对语言模型进行平滑处理的效果。绝对折扣的具体操作是将语言模型中词频的统计计数直接减去一个数值,作为调整计数使用,减去的这个数值被称作折扣系数。以Bi-gram为例,绝对折扣算法可以表示如下:
(14)
式中:wi为第i个词;C(wi)为wi出现的次数;α(wi)为归一化系数;D为折扣系数。
接续概率描述了当给定词序列w1w2…wi-1后,下一个词为wi概率。当一个词在语料库中出现更多种不同上下文时,其接续概率就更大。接续概率定义可以表示如下:
Kneser-Ney平滑算法将绝对折扣算法与接续概率结合并进行插值。以Bi-gram为例,可将Kneser-Ney算法表示如下:
(16)
经过Kneser-Ney平滑算法处理后,将语言模型以ARPA Format形式存储。ARPA Format是N-gram的标准储存模式,列举了所有非零的N元语法概率。每个语法条目中从左至右依次为:折扣后对数概率、词序列和回退权重。图7为生成的语言模型片段。

图7 语言模型片段
1.4 语音识别系统测试
在完成声学模型和语言模型的建模后,使用基于OnlineFasterDecoder的解码器进行解码,用以测试语音识别系统。为了验证使用Kneser-Ney平滑算法处理过语言模型的语音识别系统的性能,使用未处理过语言模型的语音识别系统作为实验对照组。由瘫船启动的流程操作指令构成测试使用的待识别语言,让8个测试者对两个语音识别系统各进行30次语音识别测试实验。实验结果如表2和表3所示。
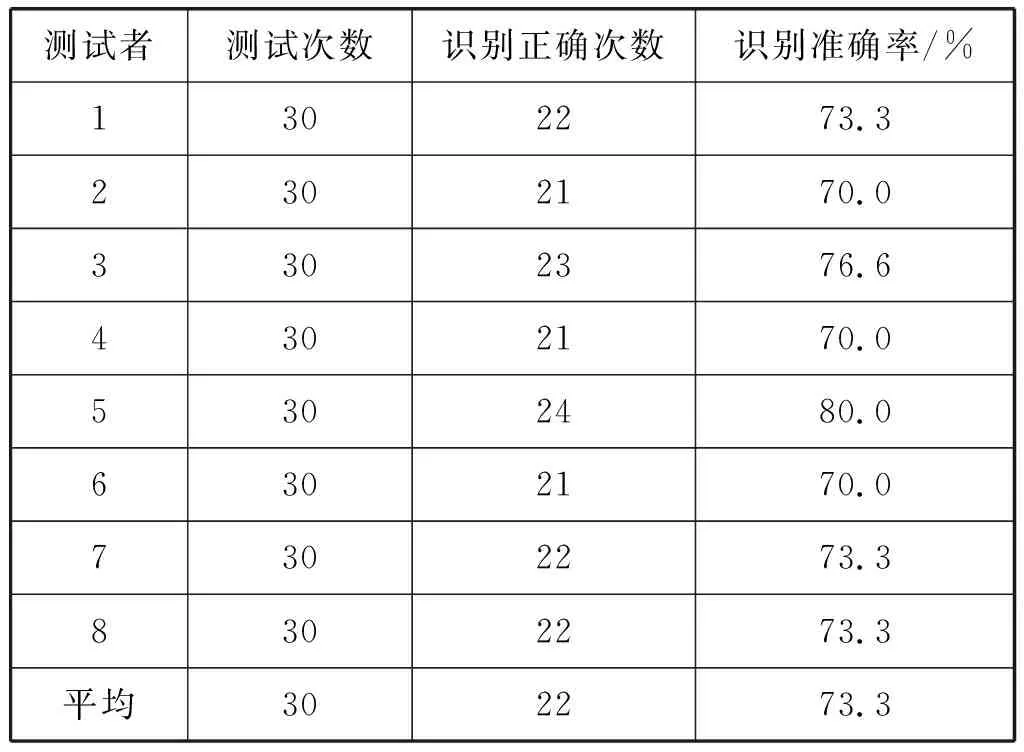
表2 未使用平滑算法的语音识别系统测试结果
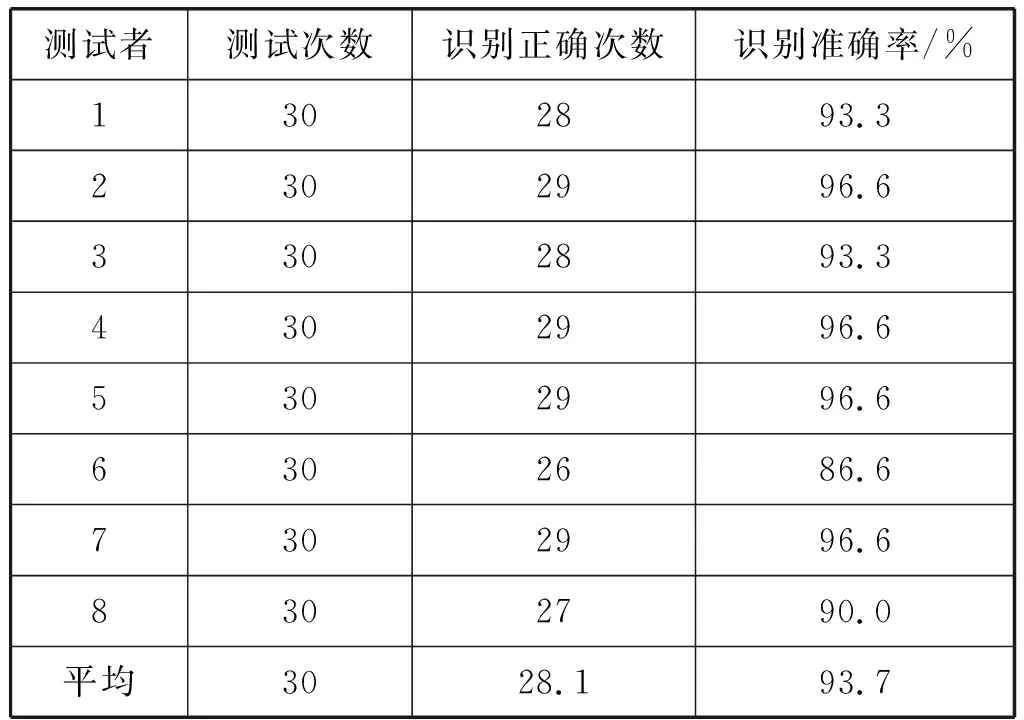
表3 使用Kneser-Ney平滑算法的语音识别系统测试结果
由实验结果可以看出,在使用Kneser-Ney平滑算法处理语言模型后的语音识别系统中,测试平均识别准确率较未使用平滑算法的语音识别系统准确率提升20.4百分点,证明了Kneser-Ney平滑算法的有效性。处理后的语音识别系统的识别准确率可以满足在轮机模拟器中对轮机设备日常操作的使用需求。该语音识别系统的构建也为语音识别系统应用于船舶机舱或无人船中打下了基础。
2 基于语音交互的发电机操作模拟
为了在现有轮机模拟器中展示语音交互的效果,使用讯飞SDK提供的接口进行封装调用,完成语音合成功能。在Windows平台下设计船舶发电机启动的语音交互流程。交互流程如下:
(1) 启动语音识别程序,语音识别系统进入监听状态,如图8所示。
图8 发电机关闭状态
(2) 通过麦克风讲话,识别指令“启动预润滑油泵”,轮机模拟器启动预润滑油泵并通过语音播报“预润滑油泵已开启”。
(3) 识别“启动轻油泵”指令,轮机模拟器启动轻油泵并播报“轻油泵已启动”。
(4) 识别“打开空气截止阀”指令,轮机模拟器打开空气截止阀并播报“空气截止阀已打开”。
(5) 识别“启动发电机”指令,轮机模拟器启动发电机并播报“发电机已启动”,如图9所示。
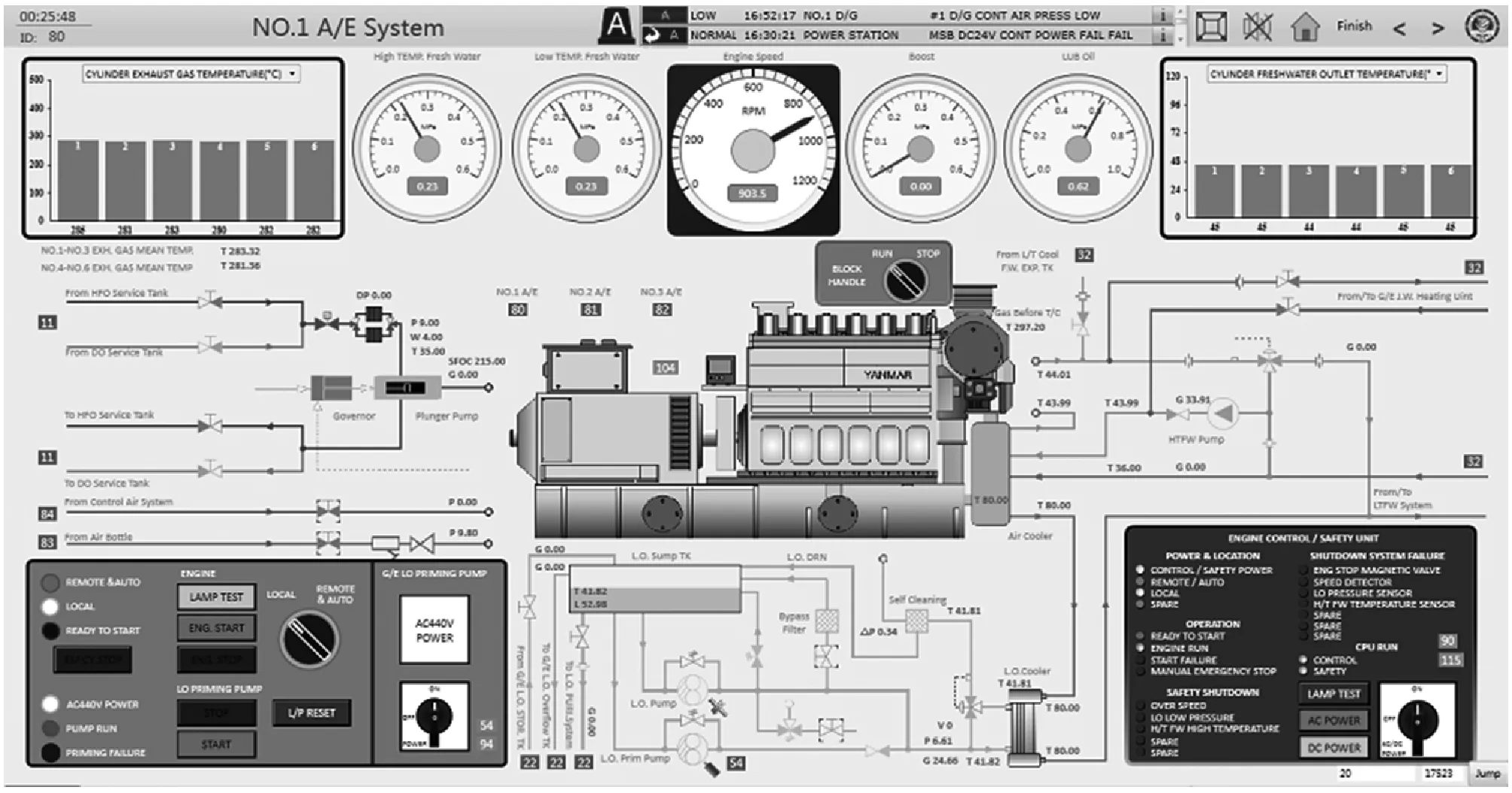
图9 发电机启动状态
通过测试表明,该交互系统表现良好,识别率高,行动执行准确。
3 结 语
作为最自然的交互方式,语音识别在智能家居的语音控制系统以及车载语音识别系统中已经十分成熟,但在轮机模拟器以及船舶机舱仿真中却仍未有人实践。语音识别在轮机模拟器中的应用不仅可以减少对轮机员培训时的人力消耗,并且可以提升轮机员操作体验。本实验通过对语音信号的特征提取、声学模型的建模、多元语言模型的对比实验,最终完成用于轮机模拟器的语音识别系统,并在轮机模拟器的发电机操作上应用语音交互系统。实验表明语音识别系统的识别率能够满足应用,解决了在培训轮机员时一人身兼多职和在虚拟环境下的交互问题,为在实际船舶机舱与无人船中应用语音识别打下了基础,对船舶轮机仿真系统的智能化具有促进意义。
