基于深度学习的文本情感聊天机器人系统的设计与实现
2023-04-07上官鑫吕俊玉张桓宇刘力军
上官鑫 吕俊玉 张桓宇 刘力军

关键词:情感监督;Seq2Seq;注意力机制;深度学习
中图分类号:TP311.1 文献标识码:A
1引言(Introduction)
近年来,随着人工智能技术的不断发展,通过自然语言与人类进行对话的聊天机器人成为研究热点,并因深度学习在自然语言处理、词向量表示、情感分析等领域的广泛应用,使其逐渐成为研究聊天机器人的关键技术[1]。目前,许多商业公司推出了应用深度学习技术的相关产品,如“苹果”的Siri、“微软”的小冰、“百度”的度秘等。虽然现有聊天机器人都可以与人类进行无差错交流,普遍表现出“智商”很高,但是人们在日常交换信息的过程中,传达的信息不仅包含信息语义本身,还包含着情感与情感状态。为了使人机对话更加贴近现实,人们寄希望于聊天机器人具有“智商”的同时也具有“情商”。本文提出基于深度学习的文本情感聊天机器人系统,满足人们进行日常文本聊天中对情感的需求,具有支持中英双语对话、情感分类多元、适用多领域对话的功能,提升了用户在日常闲聊时的使用体验。
2研究现状(Research status)
现有的文本聊天机器人按功能可划分为任务型和非任务型。针对日常聊天应用场景,采用非任务型可以更好地提升用户使用体验,提高用户满意度。非任务型聊天机器人按对话的实现方式可以分为检索式对话系统和生成式对话系统[2]。基于检索式的聊天机器人的回复语句存有单一匹配关键字的问题,其利用信息检索技术为用户会话请求匹配已经事先存储的对话语料作为回复[3]。基于生成式的聊天机器人,在现有的研究基础上其回复语句多使用情感通用性回复语句,情感单一[4]。此类聊天机器人多采用Encoder-Decoder(编码器-解码器)框架中的Seq2Seq模型,其主要应用端到端框架[5],利用大量自然语言训练集学习从问题到答案的关系,从而根据用户输入语句自动生成相应的回复,具备一定的自我学习能力。一些研究表明,基于Seq2Seq模型对于短句子有着较好的表现,但对于长句子则表现力有所下降。注意力机制可以选择性地学习句子中的部分单词或片段[6],从而更好地处理长句子。目前在情感对话领域,许多研究者将各种端到端的神经网络模型作为情感对话生成模型的基础,并通过情感分析、情感嵌入等技术对模型进行改进,实现了在对话生成中的情感表达[7]。周震卿等[8]提出了基于TextCNN(文本卷积神经网络)情感预测器的情感监督聊天机器人,在Seq2Seq模型中引入更准确的情感特征,由问题直接获取回复的情感表示,有效地提高了回复语句的质量,但存在不能区分情感类别和对长文本不敏感的问题。
3系统设计(System design)
本系统采用Seq2Seq+Attention(序列到序列+注意力机制)模型,解决现有文本聊天机器人存在的单一匹配问题。构建TextCNN-BiLSTM-SlefAttention(文本卷积神经网络-双向长短期记忆网络-自注意力机制)情感分类器,获得具备表示文本情感的情感向量和情感分类向量。为了让聊天机器人具有更好的情感回复表达,将情感向量嵌入基于GRU的Seq2Seq+Attention对话模型中,同时将情感分类向量加入训练模型的损失函数中,实现对话过程中的情感监督,避免产生通用性情感回复语句。运用丰富的数据集进行模型训练,实现中英文对话,满足了文本聊天中的多领域对话需求。使用微信小程序作为系统的前端,实现前后端分离,便于前端优化和功能更新。
3.1系统框架结构
本系統采用分离式前后端部署的方式,前端部署在微信小程序中,与用户进行交互;后端部署在Flask(Web应用程序框架)中,对用户信息进行处理与反馈。系统的整体框架如图1所示。
本系统逻辑结构分为输入模块、预处理模块、对话处理模块、输出模块,系统的逻辑结构如图2所示。
系统逻辑结构流程如下:
①用户在交互界面输入文本;
②输入文本经格式转换后传输到后端服务器;
③后端服务器将接收到的文本进行格式化预处理;
④将预处理后的文本输入对话处理模块中自动生成回复文本;
⑤回复文本经格式转换后返回给用户。
3.2情感分类模型
关于文本情感分类的研究,一般是对情感类别(褒义、中性、贬义)进行情感分类;原福永等[9]提出将BiLSTM(双向长短期记忆网络)与CNN(卷积神经网络)模型结合,与此同时引入Attention(注意力)机制实现对人们的情感进行分类;李辉等[10]提出将CNNGRU-Attention混合,实现二元(消极、积极)分类,并引入Attention机制构建混合神经网络模型学习重要文本信息。
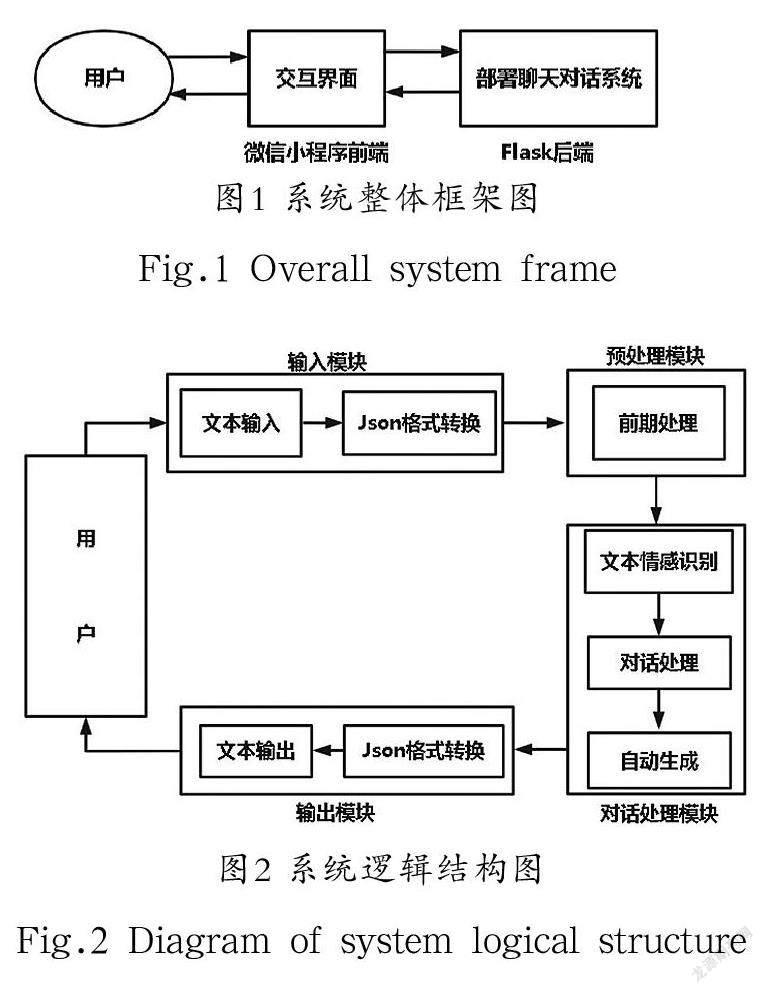
本系统通过构建TextCNN-BiLSTM-SelfAttention情感分类模型,应用于问题情感分类器和答案情感监督器。以愤怒、反感、害怕、内疚、快乐、难过、羞愧7类情感作为情感分类标签,对输入文本进行情感类别预测,其情感分类模型如图3所示。
3.3 对话处理训练模型
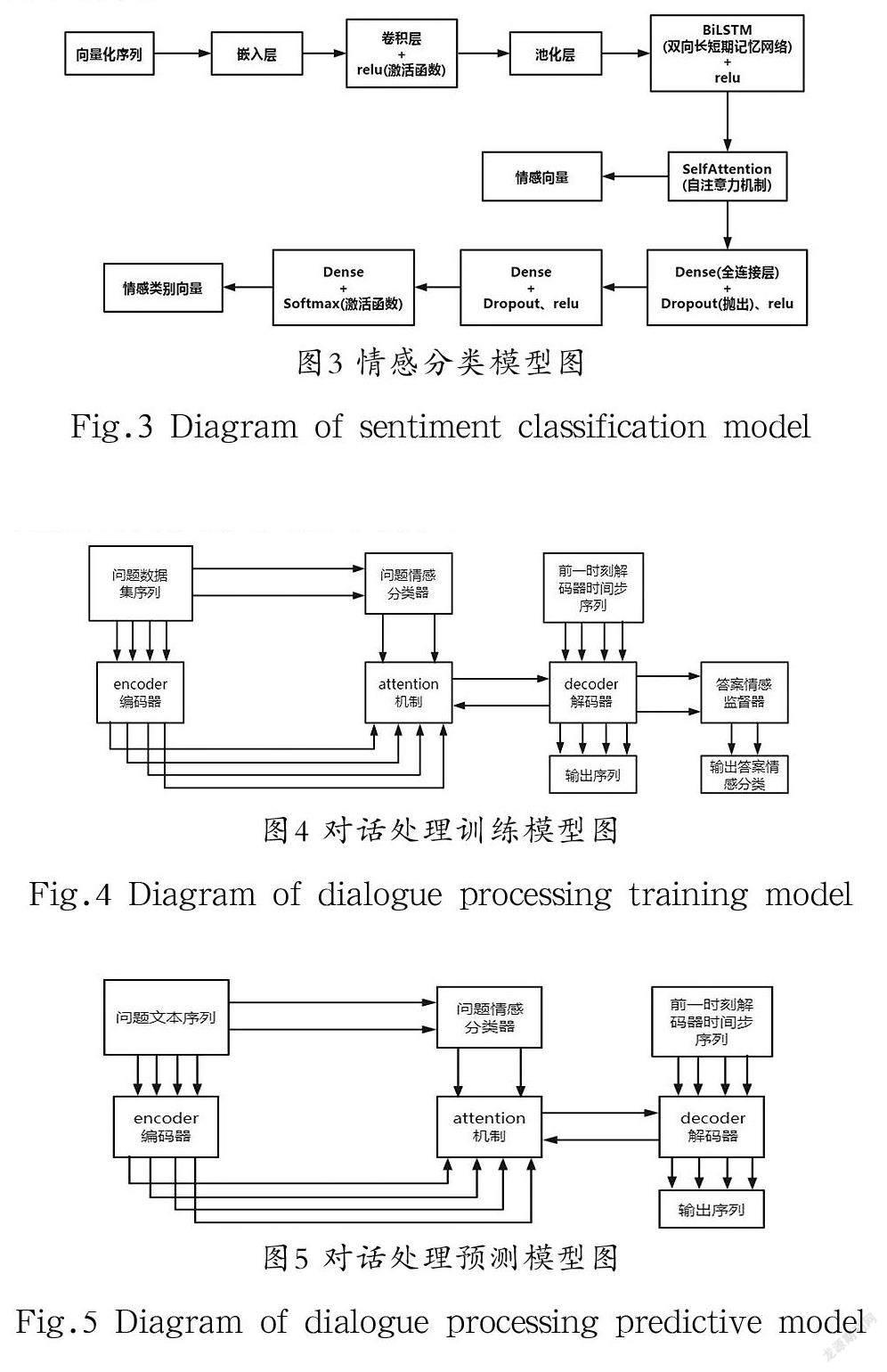
通过Seq2Seq+Attention模型与情感分类模型结合,构建对话处理训练模型,如图4所示。
对话处理的训练流程如下:①将问题数据集序列分别输入编码器和问题情感分类器中,产生编码向量和情感向量;②将上述产生的向量及decoder(解码器)的hidden state(隐藏状态)经过注意力机制产生context vector(上下文张量);③将答案数据集序列及context vector加入解码器中,输出回复向量及hidden state向量;④将hidden state向量输入到答案情感监督器中,输出情感分类向量;⑤将解码器输出的回复向量和答案情感监督器输出的情感分类向量加入对话训练模型的损失函数中,使对话训练模型在训练过程中实现情感监督。
3.4对话处理预测模型
本系统采用对话处理训练模型去除答案情感监督器构成对话处理预测模型,从而进行对话处理预测,如图5所示。
对话处理的预测流程如下:①将问题数据集序列分别输入编码器和问题情感分类器中,产生编码向量和情感向量;②将上述产生的向量以及decoder的hidden state经过attention机制产生context vector;③将解码时间步序列以及contextvector输入解码器中,输出对话预测序列。
4系统实现(System implementation)
系统实现分为前端设计实现、数据预处理、对话处理和系统部署四个部分。
4.1实现环境
本系统实现环境详见表1。
4.2前端设计实现
本系统的前端设计实现分为界面设计模块,实现用户交互界面;输入模块,实现对话文本更新。
4.2.1界面设计模块
微信小程序框架系统分为逻辑层和视图层。逻辑层使用JavaScript引擎,将数据进行处理后发送给视图层,同时接收视图层的事件反馈。视图层由WXML(页面文件)、WXSS(样式文件)编写,将逻辑层的数据反映到视图层,同时将视图层的事件发送给逻辑层。WXML用于描述页面的结构,WXSS用于描述页面的格式。
本系统实现的前端界面由对话框和输入框构成,对话框实现用户对话内容展示,输入框接收用户输入文本,如图6所示。
在对话框中实现聊天文本更新的流程,如图7所示。
图7中,msg为获得的问题文本/答案文本;msglist为对话过程中产生的问题、答案文本集;wx:for(msglist)为页面循环渲染msglist;scroll-into-view:bottom为将scroll-view窗口滚动到最低端(bottom为msglist的长度)。
该模块流程如下:
①逻辑层在获得输入文本后,将输入文本加入用户对话列表中;
②视图层进行页面的重新渲染,将输入文本信息展现在对话框中。
4.2.2输入模块
本模块通过对用户的输入文本类别进行判断,然后经过json格式转换传输到后端服务器,从而进行相对应语言的对话预测处理,如图8所示。
4.3数据预处理
为了完成本系统语言模型的构建、训练以及生成对话,需要大量的数据集。基于目前已有数据集的基础上,对其进行整理、预处理后加入对话生成模型中。整理数据集时发现,电影字幕文件的对话素材较为丰富,因此采用康奈尔大学电影对话语料作为对话处理训练模型的训练数据集。采用带有情感标注的情感数据集作为问题情感分类器的训练数据集;此外,收集了ai(人工智能)、food(食品)、history(历史)、movies(电影)、literature(文学)等17 种话题领域的数据集实现中文多领域对话。
数据预处理流程如图9所示。
(1)对数据集中的文本进行清洗分割(以电影对话语料库为例)。使用Python的正则库re,其中re.sub()函数对数据集中的问题和答案对进行清洗分割;给问题、答案字符串的前后加上‘\t(开始)、‘\n(结束)标志;得到Question_list,Answer_list;其中,问题格式如‘\t how are you ?\n,答案格式如‘\t i am fine ! \n。
(2)将切割分词后的文本转换为向量化数字序列。将得到的Question_list、Answer_list,经keras_preprocessing.Text.Tokenizer()处理得到Question_list_ids(问题向量化数字序列)、Question_vocab(问题字典)、Answer_list_ids(答案向量化数字序列)、Answer_vocab(答案字典)。keras_preprocessing.Text.Tokenizer:keras中的一个文本标记实用类,将每個文本转化为一个整数序列,其每个整数都是词典中标记的序列。
( 3 ) 将得到的向量化数字序列, 进行p a d d i ng填充。将得到的Question_list_ids、Answer_list_ids,经keras_preprocessing.sequence.pad_sequences()处理,获得定长的问题、答案向量化数字序列。keras_preprocessing.sequence.pad_sequences:将序列转化为经过填充后得到的一个长度相同的新序列。
4.4对话处理
将数据集样本对放入系统构建的模型进行训练,实现对话处理,完成对输入文本的预测回复。系统模型训练可分为问题情感分类器训练和对话处理模型训练。
4.4.1问题情感分类器训练
问题情感分类器的嵌入层采用keras的自定义嵌入层(embedding layer),其embedding layer所有的words(单词序列)被随机初始化,将正整数(单词序号)转换为具有固定大小的向量。通过单层的卷积和池化进行特征提取,同时卷积层使用ReLU激活函数,对特征向量进行非线性处理,避免了梯度消失和爆炸的问题,并提高BiLSTM的训练计算效率。BiLSTM获取抽取后输入特征向量间的相关性,同时关注“头部”和“尾部”的信息,可以更好地学习长序列信息。SelfAttention针对BiLSTM输出的特征向量,捕获远距离的特征,将SelfAttention输出的特征序列作为输入文本的情感向量。使用全连接层、Dropout机制防止过拟合,提升模型训练效率。同时,使用Softmax激活函数对特征向量归一化处理,输出情感类别向量序列。
现有的情感分类一般是简单的二元(消极、积极)或三元分类(消极、积极、中立),然而人的情感更加多元,因此本系统构建的情感分类模型为多分类模型。在实现上,采用分类交叉熵损失函数作为该模型的损失函数,将带有情感标注的情感数据集输入问题情感分类器中,实现模型的训练。
4.4.2对话处理训练模型
对话处理训练模型分为情感分类器模块、编码器模块、解码器模块。模型训练回合数epochs设为50,batch size设为64。
(1)情感分类器模块。加载已经训练好的问题情感分类模型输入问题向量化数字序列,得到情感向量和问题情感分类向量。
(2)编码器模块。将问题向量化数字序列输入编码器中,得到编码输出序列和最后的隐藏状态序列。编码器由嵌入层、GRU(门控循环单元)层构成,其中GRU设置为可返回隐藏状态序列,如图10所示。在选取编码器输入数据集时,首先对问题文本数据集进行抽取后,得到15,838 个规格化的问题文本集,抽取得到问题文本集的90%作为模型训练集,10%作为模型验证集。
(3)解码器模块。将编码器输出的向量序列和注意力机制对输入文本选择性学习得到的向量序列输入到解码器中。解码器由嵌入层、GRU、全连接层组成,如图11所示。在选取解码器输入数据集时,对答案文本数据集进行抽取后,得到15,838 个规格化的答案文本集,单个文本格式如‘\t i amfine !\n;抽取得到答案文本集的90%作为模型训练集,10%作为模型验证集。
4.5系统部署
微信小程序作为前端,实现微信小程序与用户交互;Flask框架作为后端服务器,依载对话模型,并实现与微信小程序的通信。
4.5.1微信小程序
微信小程序的前端代码存储于微信服务器之中,在腾讯云端存放,無须加载,可以直接打开,响应速度较快。使用wx.request API(请求函数接口)与Flask后端服务器进行通信。
wx.request模板:
wx.request({
Url:,
Data:,
Method:'POST',
Header:{
'content-type':'application/x-www-form-urlencoded'
},
})
4.5.2 Flask后端
利用Python的Flask框架搭建后端服务器,可扩展性强,在开发过程中不需要HTTP请求的发送和接收。
app.run(host='127.0.0.1',port=5000,debug=True):设置服务端的IP地址和端口号;
@app.route():设置对话处理函数所绑定的URL;
Request.values:获得Post表单的数据部分;
Return:将对话处理结果以json格式返回给前端。
5 系统展示(System display)
本系统的功能展示如图12所示。
6结论(Conclusion)
本研究提出了一种基于深度学习的文本情感聊天机器人系统,该系统属于生成式聊天机器人系统,解决了单一匹配知识库问题且适用于多领域对话。同时,在对话过程中引入情感监督,实现了对话过程中的情感回复与响应,提高了生成回复语句的情感质量,有效拓展了文本聊天机器人的情感交互功能。此外,在系统部署上使用更加灵活的分离式框架搭建,便于前端优化和功能更新。从整体上看,本系统具有一定的创新性和较好的应用前景。
作者简介:
上官鑫(2000-),男,本科生.研究领域:自然语言处理.
吕俊玉(2001-),女,本科生.研究领域:自然语言处理.
张桓宇(1999-),男,本科生.研究领域:自然语言处理.
刘力军(1979-),男,硕士,讲师.研究领域:网络技术.
