基于Swin Transformer的YOLOv5安全帽佩戴检测方法
2023-04-03郑楚伟
郑楚伟,林 辉
(韶关学院 智能工程学院,广东 韶关 512005)
0 引言
在工地的作业现场,正确佩戴安全帽能有效地防止施工人员在生产过程中遭受坠落物体对头部的伤害。然而在实际生产活动中,尽管每个施工项目都明文要求人员一定要正确佩戴安全帽,但仍杜绝不了个别工人缺少自我安全防范意识,在施工现场不戴或者不规范佩戴安全帽的现象[1]。目前施工现场对安全帽佩戴情况的监控大多仍依赖人工监视[2],这种方式存在成本高、耗时长、容易出错的不足。采用视频自动监控方法有利于实时监控施工现场人员的安全帽佩戴情况,对安全生产环节中的安全隐患进行实时评估。
目前已有学者对安全帽检测方法进行研究。刘晓慧等[3]采用肤色检测的方法定位人脸,再利用支持向量机(SVM)实现安全帽的识别;刘云波等[4]通过统计工人图像的上三分之一区域出现频率最高的像素点色度值并与安全帽颜色相匹配,以此来判断安全帽佩戴情况。但传统的目标检测需要通过手工设计特征,存在准确率低、不具备鲁棒性等问题。
随着深度学习的发展,国内外已有大量学者使用基于卷积神经网络算法对安全帽检测进行了一系列研究。其中有先提取候选框再回归定位的两阶段算法,如R-CNN(regions with convolutional neural network features)[5]、Fast R-CNN(fast region-based convolutional neural network)[6]和Faster R-CNN(faster region-based convolutional neural network)[7]等网络和直接进行一阶段目标检测的SSD(single shot MultiBox detector)[8]和YOLO(you only look once)[9]系列算法。张玉涛等[10]使用轻量化的网络设计减小模型的计算量,使得模型达到137帧每秒的运行速度,但是总体的检测错误率达到7.9%。张明媛等[11]使用Faster RCNN网络检测施工人员的安全帽佩戴情况,但未考虑检测效率的问题,无法实现实时检测。杨莉琼等[12]提出了一种基于机器学习的安全帽检测方法,使得每帧图像的检测时间小于50 ms,满足时效性需求,但在检测图像中的小目标时准确率较低。孙国栋等[13]提出了一种通过融合自注意力机制来改进Faster RCNN的目标检测算法,具有较好的检测效果,但是模型的参数量和计算复杂度高。张锦等[14]在YOLOv5特征提取网络中引入多光谱通道注意力模块,使网络能够自主学习每个通道的权重,提升了模型的平均准确率,但网络模型参数量以及检测速率有待提升。
本文提出一种改进YOLOv5的安全帽检测方法,将Swin Transformer作为YOLOv5的骨干网络,使得模型能够更好地提取图像特征。同时,使用K-means++聚类算法重新设计匹配安全帽数据集的先验锚框尺寸,基于Ghost Bottleneck对YOLOv5的C3模块进行改进从而减少模型参数,提出新型跨尺度特征融合模块,更好地适应不同尺度的目标检测任务。实验结果表明,改进的YOLOv5在安全帽检测任务上的mAP@.5:.95指标提升了2.3%,检测速度达到每秒35.2帧,有效解决施工现场的安全帽检测方法存在遮挡目标检测难度大、误检漏检率高的问题,满足复杂施工场景下安全帽佩戴检测的准确率和实时性要求。
1 系统结构及原理
本文通过改进YOLOv5网络结构以解决安全帽检测过程存在遮挡目标检测难度大、误检漏检率高的问题。改进YOLOv5网络结构如图1所示,分为数据输入、骨干网络、颈部及预测部分。
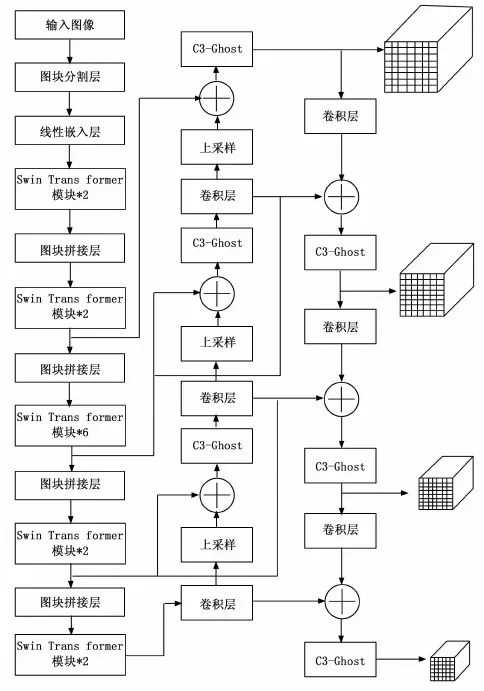
图1 改进YOLOv5网络结构
数据输入部分使用自适应图像填充、Mosaic数据增强来对数据进行处理,提升小目标的检测的精度。骨干网络部分使用Swin Transformer作为YOLOv5的主干特征提取网络。颈部部分借鉴双向特征金字塔网络跨尺度特征融合的结构优势,在FPN + PANet结构进行特征融合的基础上,增添了两条特征融合路线,用较少的成本使得同层级上的特征图能够共享彼此的语义信息;另一方面,为了减少模型参数,提出了基于Ghost Bottleneck对YOLOv5的C3模块进行改进的C3-Ghost模块。预测部分,如图1最右侧所示,从上到下依次是经过特征融合后得到原图的4、8、16、32倍下采样的特征图,在此基础上使用二元交叉熵损失函数计算置信度预测损失和分类预测损失,使用广义交并比(GIoU,generalized intersection over union)计算边界框的损失,同时采用非极大值抑制对多个目标锚框进行筛选来提高对目标识别的准确度。
2 改进YOLOv5网络模型
2.1 Swin Transformer模块
Swin Transformer是基于具有全局信息建模能力的Transformer来构建分层特征图,同时借鉴locality思想将自注意力计算限制在无重叠的窗口区域内并允许移动窗口进行特征交互,对图像大小具有线性计算复杂度[15],可将其作为YOLOv5的骨干网络来更有效的提取图像特征。
Swin transformer网络架构如图2(a)所示。首先将输入的[H,W,3]图像传入图块分割层(patch partition),将每4×4相邻的像素分块为一个Patch,并沿着通道方向展开,使得图像维度变成了[H/4,W/4,48],然后在通过线性嵌入层(linear embeding)对每个像素的通道数据做线性变换,使图像维度变成[H/4,W/4,C],同时将每个样本在特征维度进行归一化处理。
Swin transformer构造图像的层次特征图是通过在每个阶段之间使用图块拼接层(patch merging)对图像进行下采样,图块拼接层的实现类似于YOLOv5的Focus结构对图片进行切片操作,将间隔为2的相邻像素划分为一个个Patch后再进行通道拼接(concat)操作,使得特征图尺度减半。然后在通过一个标准化层(LN,layer normalization)进行归一化操作,最后通过一个全连接层将特征图的通道数线性变换为原来的一半。原特征图经过图块拼接层后,宽和高会减半,通道数翻倍,随着网络层次的加深,节点的感受野也在不断扩大。

Swin Transformer 模块中的W-MSA层是使用从左上角像素开始的常规窗口划分策略。如图2(c)所示,其包括窗口分割(window partition)模块、窗口重组(window reverse)模块和MSA模块。其中窗口分割模块用于将输入的特征图分割为多个M×M相邻像素的互不重叠的独立窗口;窗口重组模块用于对每个独立窗口的Multi-head自注意力特征进行还原拼接为完整的Multi-head自注意力特征图;MSA模块用于对每个独立窗口分别进行Multi-head的缩放点积注意力计算,步骤包括:对每个独立窗口的图块向量在通道维度进行线性变换,使通道数增加两倍,同时在特征维度上分割为h个子空间(h为注意力head的个数);通过h个不同的参数矩阵WQ、WK、WV分别在h个子空间中对每个像素的查询Q(Query)、键K(Key)和权重V(Value)进行线性变换,并进行缩放点积注意力计算;将h个计算结果通过可学习的权重矩阵WO进行拼接融合,以联合来自不同子空间中学习到的特征信息,得到Multi-head自注意力特征[18]。其中,第i个注意力头的缩放点积注意力计算结果headi的表达式如式(1)所示:
(1)
(2)
式(2)中,Q,K,V∈M2×d,QKT是不同特征进行信息交互的过程,采用点积来计算不同特征之间的相似度;除以进行缩放操作能保证梯度的稳定性;同时,在每一个headi中添加可学习的相对位置编码B∈M2×M2。Multi-head自注意力特征的拼接融合表达式如式(3)所示。
MultiHead(Q,K,V)=Concat(head1,…,headh)Wo
(3)
为了实现不重叠窗口之间的信息传递,可使用SW-MSA的方式重新计算窗口偏移之后的自注意力,让模型能够学习到跨窗口的信息。如图2(c)所示,SW-MSA中使用了循环移位(Cyclic Shift)的方法,即通过将特征图最上面的M/2行(M是每个划分窗口的尺寸)像素移动到最下面,再将最左边的M/2列像素移动到最右边,再使用W-MSA划分窗口的方法将重组的特征图划分为不重叠的窗口;然后通过掩码机制,将每个窗口内来自不相邻区域的像素点之间的权重系数置为0,隔离原特征图中不相邻区域的像素点之间无效的信息交流,以此将自注意力计算限制在每个子窗口内;最后再通过反向循环移位(reverse cyclic shift)操作还原特征图的相对位置。
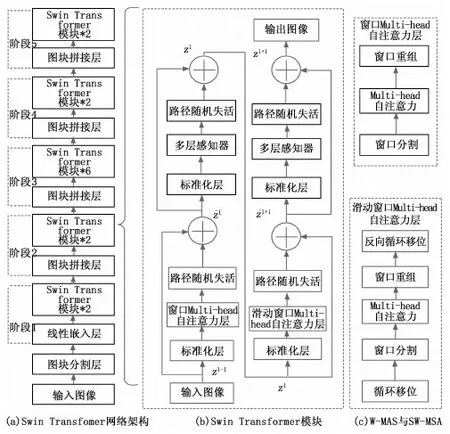
图2 Swin Transformer模块结构图
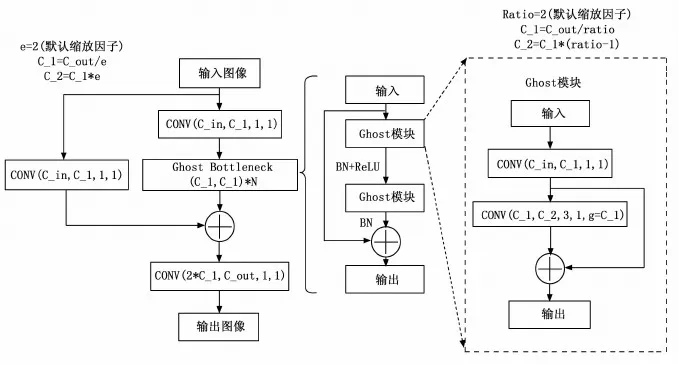
图4 C3-Ghost 模块
2.2 C3-Ghost模块
在深层神经网络的特征映射中,丰富甚至冗余的信息往往保证了对输入数据的全面理解。部分冗余的特征可能是深层神经网络有效的一个重要原因。Ghost模块能以一种高效的方式获得这些冗余的特征[19]。本文提出C3-Ghost模块, 如图3所示,基于Ghost Bottleneck对YOLOv5的C3模块进行改进, 旨在通过低成本的操作生成更多有价值的冗余特征图, 有效的提升网络性能。
Ghost模块将普通卷积层拆分为两部分,首先使用若干个1×1的卷积核进行逐点卷积,生成输入特征的固有特征图,然后用逐层卷积进行一系列线性变换来高效地生成冗余特征图,再将冗余特征图和固有特征图进行拼接,得到和普通卷积结果具有相似作用的特征图,如图3所示。与普通卷积操作相比,Ghost模块在不改变输出特征尺寸和维度的情况下能有效减少模型参数和计算复杂度。
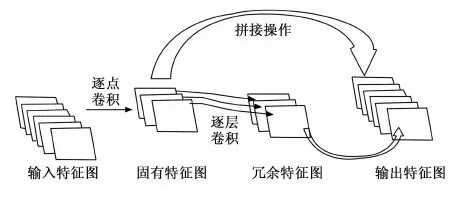
图3 Ghost模块
本文设计的C3-Ghost模块使用Ghost Bottlenecks结构来替代原始C3模块的Bottlenecks结构,Ghost Bottlenecks的本质是用Ghost模块代替Bottlenecks结构里面的普通卷积。如图4所示,第一层Ghost模块用于增加通道数量,从而增加特征维度,第二层Ghost模块用于减少特征维度使其适配残差连接,将输入与输出相加。引入批量归一化(BN,batch normalization)尽可能保证每一层网络的输入具有相同的分布[20],引入具有稀疏性的ReLu激活函数能避免反向传播的梯度消失现象,第二层Ghost模块后没有使用ReLu激活函数是因为ReLU负半轴存在的硬饱和置0会使其输出数据分布不为零均值而导致神经元失活,从而降低网络的性能[21]。
2.3 新型跨尺度特征融合模块
在目标检测任务中,融合不同尺度的特征是提高性能的一个重要手段。目前已有的特征融合网络有PANet[22]、FPN[23]、BiFPN[24]等。YOLOv5使用FPN+PANet结构将高层特征丰富的语义信息和低层特征丰富的细节信息相互融合,如图5(a)所示。
考虑到加权双向特征金字塔网络(BiFPN,bi-directional feature pyramid network)[24]的结构优势,本文提出将BiFPN的思想应用到YOLOv5的多尺度特征融合部分,通过添加横向跳跃连接,即在处于同一层级的原始输入和输出节点之间添加一条新的融合路线,如图5(b)所示,在原始YOLOv5特征跨尺度融合模块基础上添加沿着两条虚线的特征融合路线,用较少的成本使得同层级上的特征图能够共享彼此的语义信息,加强特征融合以提高模型精度。
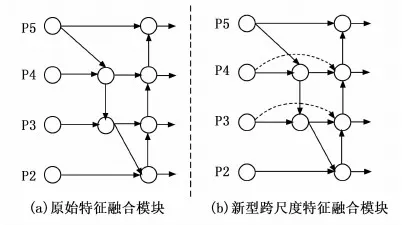
图5 不同特征融合模块的对比
2.4 改进先验锚框尺寸
在模型训练中,先验锚框尺寸越接近真实边界框,模型将会越容易收敛,其预测边界框也会更加接近真实边界框。原始YOLOv5模型中预设了匹配COCO数据集的锚框,但本文使用的安全帽数据集的边界框具有类型单一、边界框尺寸比较集中的特点,预设的锚点不能合理地直接应用。因此本文提出使用K-means++对安全帽数据集的边界框进行聚类分析,找到12个聚类中心的边界框作为先验锚框参数的值,并将其匹配到相应的特征检测层,使模型能够更快收敛。
由于卷积神经网络具有平移等变性[25],因而只需要通过K-means++对边界框的宽高进行聚类,不用考虑边界框位置的影响。首先通过轮盘赌算法依据概率大小选择初始聚类中心,然后依次计算每个边界框与初始聚类中心的距离,按照距离大小对边界框进行划分聚类,再更新聚类中心,直到在连续迭代中聚类中心位置稳定。在距离度量上,采用式(4)代替标准K-means++中使用的欧氏距离:
(4)
其中:Boxi为第i个真实边界框的面积,Centerj为第j个聚类中心的面积,n为真实边界框总数,k为聚类中心个数,本文YOLOv5有4个不同尺度的特征检测层,每层分配3个先验锚框,故k=12。
由于安全帽边界框尺寸较为集中,为了更好的发挥YOLOv5算法的多尺度目标检测能力,将对K-means++聚类所得的先验锚框尺寸进行线性变换操作[26],如式(5)所示。
(5)
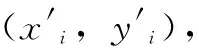
本文使用上述算法所设计的先验锚框尺寸如表1所示。最佳可能召回率(BPR,best possible recalls)是衡量先验锚框和真实边界框匹配程度的指标,定义为一个检测器最多能召回的真实边界框数量与真实边界框总数之比[27]。在训练期间,如果一个真实边界框被分配给至少一个先验锚框,则认为该真实边界框被召回。BRP的最大值为1并且越接近越好。在本文改进的先验锚框下计算所得的BPR值为0.999,表明本文所设的先验锚框和安全帽数据集的真实边界框具有很好的匹配程度。
表1 改进先验锚框尺寸
像素
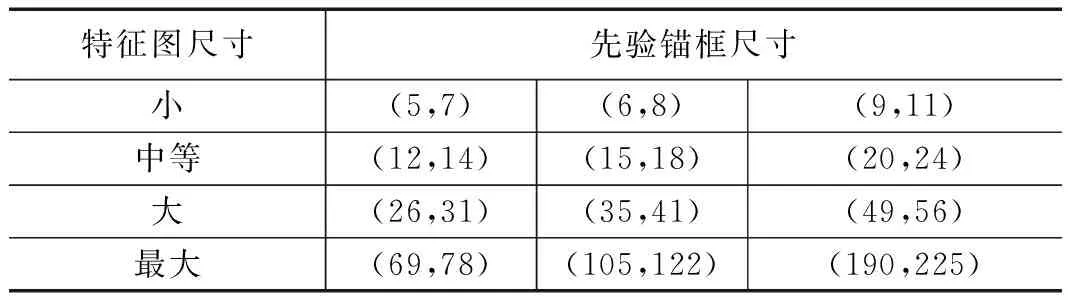
特征图尺寸先验锚框尺寸小(5,7)(6,8)(9,11)中等(12,14)(15,18)(20,24)大(26,31)(35,41)(49,56)最大(69,78)(105,122)(190,225)
3 实验结果与分析
3.1 实验环境
本实验使用Pytorch 1.9.1深度学习框架、python3.6环境,操作系统为Window10,CPU型号为英特尔Core i9-9820X、128 GB内存、24 GB显存的NVIDIA TITAN RTX显卡的设备上完成训练,NVIDIA驱动版本为456.71,并行计算架构CUDA版本为10.0.130,深度学习加速库CUDNN版本为7.6.5。
在训练过程中,设置最大迭代次数为200个epochs,采用SGD优化器,动量因子为0.937,权重衰减系数为0.000 5,初始学习率为0.01,初始阶段使用warmup预热学习率,前3个epochs采用一维线性插值调整学习率,随后使用余弦退火算法更新学习率。
3.2 数据集
为了验证本文改进网络的优越性,实验使用了开源安全帽佩戴检测数据集(SHWD,safety helmet wearing detect dataset)进行验证。SHWD提供7 581张图像,其中包括9 044个佩戴安全帽的正样本人物头像和111 514个未佩戴安全帽的负样本人物头像。本文以训练集:测试集=9:1的比例划分数据集,其中训练集有2 916张正样本图像和3 905张负样本图像,测试集有325张正样本图像和435张负样本图像。
3.3 评价指标
在目标检测领域常采用精确度(P,precision)、召回率(R,recall)、平均精确度(AP,average precision)、平均精确度均值(mAP,mean Average Precision)、每秒传输帧数(FPS,frames per second)指标来评估模型性能。计算公式如式(6)~(9)所示。
(6)
(7)

(8)
(9)
式(9)中,n表示类别总数。AP用于衡量模型对某一类别的平均精度,mAP是所有类别的平均AP值。其中,真正例(TP,true positive)、假正例(FP,false positive)、真反例(TN,true negative)和假反例(FN,false negative)的混淆矩阵如表2所示。

表2 各指标的混淆矩阵
3.4 实验结果与分析
本实验使用具有4个检测尺度的YOLOv5作为基准模型,其是在标准模型的基础上将更低层级的特征图引入到特征融合网络中,使得特征融合网络能更有效地捕获更丰富的细节信息,从而提高小目标检测精度。实验结果如表3所示,其中mAP@.5是IoU阈值为0.5的情况下每一类别的AP值的平均;mAP@.5:.95表示IoU阈值从0.5开始、以0.05的步长增长到0.95所对应的平均mAP。表3中,“C3-Ghost”是指使用本文所设计的C3-Ghost模块替代基准YOLOv5特征融合网络中的C3模块;“新型跨尺度特征融合”是指使用本文提出的新型跨尺度特征融合模块替代基准YOLOv5的特征融合网络;“Swin Transformer”是指使用Swin Transformer替代基准YOLOv5的骨干网络的模型。
由表3可知,YOLOv5基准模型的参数量为7.17×106,YOLOv5+C3-Ghost模型参数量为6.14×106,在保持mAP@.5:.95值几乎不变的情况下,YOLOv5+C3-Ghost的参数量相比于基准YOLOv5减少了14.4%,证明本文所设计的C3-Ghost模块能有效减少模型参数。YOLOv5+新型跨尺度特征融合在mAP@.5:.95指标上相比基准YOLOv5提高了0.6个百分点。YOLOv5+Swin Transformer相比基准YOLOv5模型,在mAP@.5:.95指标上提升了2.1个百分点。YOLOv5+Swin Transformer+C3-Ghost在mAP@.5:.95指标上相比YOLOv5基准模型提升了1.9个百分点。表3中“本文改进算法”是本文提出的改进YOLOv5网络模型,其具备Swin Transformer强大的特征提取能力外,既有C3-Ghost模块带来的轻便性,又有新型跨尺度特征融合加强特征融合带来的高准确率,从表3中可以看出本文所提出的改进YOLOv5网络模型相比基准YOLOv5网络模型,在mAP@.5:.95指标上提升了2.3个百分点,较基准模型具有显著提升。
为了验证本文改进算法的有效性,本文使用以resnet50为骨干网络的两阶段目标检测网络Faster RCNN和以vgg为骨干网络的单阶段目标检测网络SSD进行对比。从表3可以看出,本文所使用的改进YOLOv5模型在安全帽检测任务上的mAP@.5:.95值55.2%远高于Faster RCNN的mAP@.5:.95值37.2%以及SSD的mAP@.5:.95值37.2%。
值得说明的是,YOLOv5单独融合Swin Transformer模块和融合Swin Transformer+C3-Ghost模块的算法相比于本文改进算法,在mAP@.5:.95指标上分别减少了0.2%和0.4%。本文认为,Swin Transformer模块作为骨干网络能有效提取图像初步抽象的、细节性的特征,而本文设计的新型跨尺度特征融合模块能更有效的融合来自Swin Transformer浅层特征丰富的纹理信息和深层特征丰富的语义信息,使得网络更深层的颈部以及预测模块的特征图具有更丰富的高级语义信息,从而提高目标检测精度。
FPS指标用于评估模型每秒处理的图像帧数。本文在施工现场监控中截取一段视频进行检测,如表3所示,可以看出,本文改进算法检测速度达到每秒35.2帧,能够达到实时检测的效果。由于Swin Transformer网络较高的计算复杂度而导致其FPS低于基准YOLOv5,但仍高于Faster RCNN和SSD每秒能处理的图像帧数。
为了更直观地展示出改进YOLOv5模型的优势,本文使用改进前后的YOLOv5模型进行检测,如图6所示,其中正确佩戴安全帽的施工人员上方显示“hat”标签,未佩戴安全帽的施工人员上方显示“no-hat”标签。图6(a)中,原始YOLOv5模型漏检了一个被施工设备遮挡的未佩戴安全帽的施工人员,而改进后的YOLOv5模型则可以正确检测出来,如图6(b)所示。图6(c)中,原始YOLOv5模型错误地将控制施工设备的圆形控制器判断为未佩戴安全帽的施工人员,而改进后的YOLOv5模型则可以得到正确的结果,如图6(d)所示。图6(e)是在弱光照下的检测效果,可以看出原始YOLOv5模型漏检了一个佩戴安全帽的施工人员,而改进后的YOLOv5模型则具有较好的表现,如图6(f)所示,能正确检测出光照不充足的图像中的目标。由上述检测对比可知,本文改进后的YOLOv5模型能有效解决施工现场安全帽佩戴检测存在的遮挡目标检测难度大、误检漏检率高的问题,满足复杂施工场景下安全帽佩戴检测的准确率要求。

图6 不同场景下原始模型和本文改进模型的检测结果对比
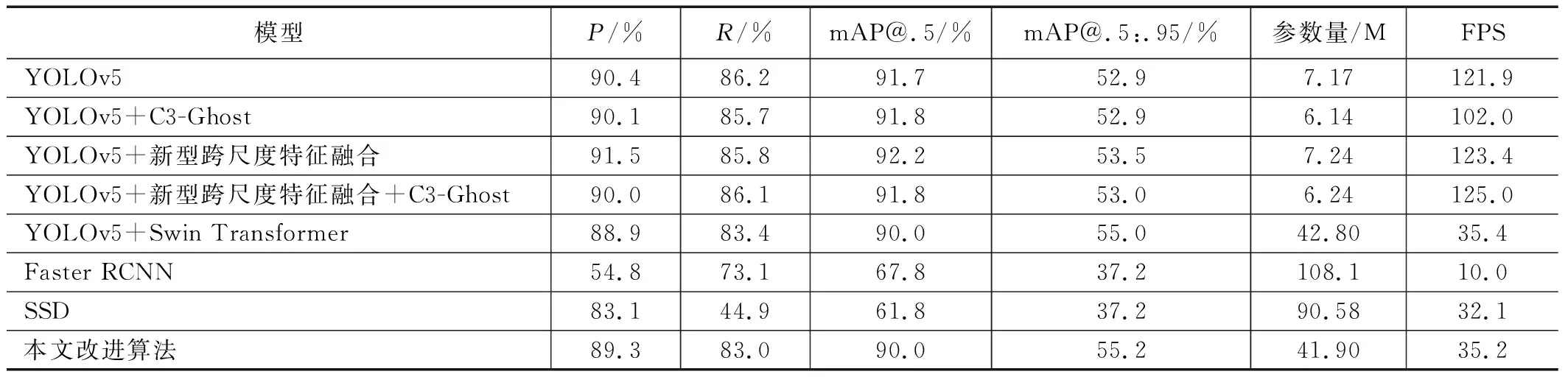
表3 多种模型实验结果对比
4 结束语
针对目前施工现场的安全帽检测方法存在遮挡目标检测难度大、误检漏检率高的问题,本文提出一种改进YOLOv5的安全帽佩戴检测方法。通过将Swin Transformer作为YOLOv5的骨干网络,能够有效结合Swin Transformer强大的特征提取能力和YOLOv5单阶段目标检测算法高效推理速度的优势。实验结果表明本文改进算法在安全帽检测任务上的mAP@.5:.95指标提升了2.3%,每秒检测图片的帧数达到35.2帧,能够达到实时检测的效果,满足复杂施工场景下安全帽佩戴检测的准确率和实时性要求。下一步的工作是继续研究如何在保持精准度的情况下,减少网络模型参数量以及提升检测速率。
