基于深度学习的磁芯表面缺陷检测研究
2023-04-03吴显德陈科宇雷雅彧翁扬凯王宪保
吴显德,陈科宇,周 宝,雷雅彧,翁扬凯,王宪保
(1.浙江华是科技股份有限公司,杭州 311100; 2.浙江工业大学 信息工程学院, 杭州 310023)
0 引言
磁芯是电子设备中变压器和线圈的重要组成部分,其质量的好坏不仅影响磁芯的外观,而且对磁芯的磁导率磁通密度等重要性能参数也有很大影响。
传统的磁芯缺陷检测大多采用人工肉眼的方式进行,但由于磁芯体积小且种类繁多,导致检测工作量大、效率低,而且易受到检测人员的经验、情感、视觉疲劳等因素的影响,检测的质量难以保证,不适于大规模的工业生产。
近年来,使用机器视觉方法进行外观缺陷检测已取得重大进展,广泛应用于钢板[1]、零件[2-3]、玻璃、印刷、焊缝[4]、纺织品、瓷砖、钢轨等多个行业。王猛等[5]人为了检测网络变压器模块缺陷,对图像进行中值滤波,采用阈值分割、Blob分析的办法对图像缺陷特征进行形态学特征识别和提取。郭良[6]等为了检测汽车涂胶缺陷提出了基于方向梯度直方图与Gabor特征结合的特征提取算法[6]。姚明海[7]等将RPCA算法应用于太阳能电池片的缺陷检测,使太阳能电池片的检测精度达到100%。这些传统的基于机器视觉的缺陷检测虽然取得了不错的效果,但是由于自动化产业发展迅猛,产品数量日益猛增,远不能满足工业自动化生产对于缺陷检测精度、速度和泛化能力的需求。
随着卷积神经网络在计算机视觉领域的巨大成功[8-10],深度学习在工业产品的缺陷检测研究领域得到了广泛应用和发展。余永维[11]等提出一种基于深度学习特征匹配的铸件缺陷三维定位方法,模拟选择注意机制的中央-周边查算法,提出以视觉显著为尺度,从射线图像复杂背景中检测缺陷及其区域。Jiang[12]等人根据U-NET模型提出了由编码器和解码器组成的对称卷积神经网络,产生与原始图像相同大小的语义分割,以提高玻璃的检测准确率。
虽然各种深度学习的方法在工业生产的目标定位,目标检测等环节有不错的应用。但是缺陷检测领域还存在诸多的问题,主要集中在两方面。首先是深度学习的良好性基于大量数据,充足的数据可以增强网络的性能,从而提高缺陷的检测效果。但是在实际的工业生产中,大数据集的缺陷库很难获得,且缺陷种类数据量不平衡,使得检测准确率不能达到满意效果。其次是小目标缺陷的检测效率不高,检测时间不迅速,不能满足日益快速的工业化的要求。
针对第一个数据量不足的问题,目前有效的方法是进行数据增强。浙江大学[13]提出一种基于小批量数据集和深度学习算法的晶圆缺陷检测方法,利用微距定焦镜头对图像进行全局扫描;然后将彩色图像进行数据增强,包括添加噪声、裁剪和翻转等,进而扩增数据集;最后将SSD 原始算法与迁移学习相结合,并优化了网络模型参数。李翌昕[14]等针对文档区块图像设计了一组有效的特征,提取了几何、灰度、区域、纹理和内容五方面在内的 32 种特征,以增强特征针对区块类别的分辨能力。
问题二是小目标检测问题,由于小目标物体的像素占比少,难以提取到充分的特征信息,相较于大目标物体的检测,精度难以保障。研究人员对此从多尺度融合、主干网络、特征分辨率等角度进行了研究。其中LIN[15]等人提出了基于FPN的方法来增强底层特征的语义信息。FPN分为两条支路,一条自下而上的支路,可以逐层提取丰富的高层语义信息。另一条自上而下的支路,可以将上层的语义信息融合到底层特征中。通过对小目标的多尺度检测,提高了小目标物体的检测精度。
本文提出了一种基于深度学习的图像增强和检测方法,算法首先基于深度卷积对抗生成网络(deep convolution generative adversarial networks, DCGAN)和图像融合的方法,进行磁芯缺陷图片数据集扩充,提高了生成图片的质量,解决了数据量小的问题。然后使用含有多尺度特征融合结构的YOLO-v3算法,提高了对小目标的检测精度和速度。本文提出的模型整体框架如图1所示。
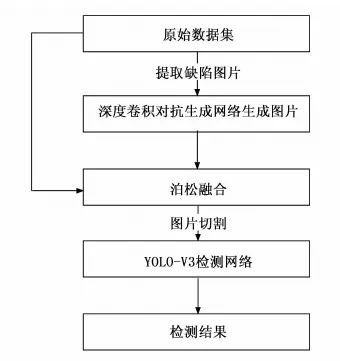
图1 算法整体框架
1 方法
1.1 DCGAN
原始生成对抗网络[16](generative adversarial networks,GAN)由多层感知器作为基础结构,并由多个全连接层组成,其网络结构如上图2所示由生成网络G(Generator)和判别网络D(Discriminator)两个部分构成。
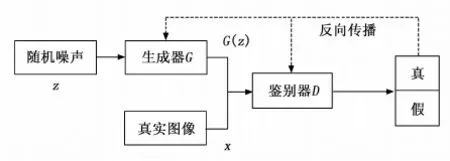
图2 GAN模型
生成网络通过对输入噪声的映射,得到尽可能拟合真实样本的分布的输出图像。判别网络用来判断输入图片的真伪性,即该图片是真实图片还是生成器生成的图片。利用生成对抗互相博弈的思想,对生成网络判别网络交替迭代训练,最终使得生成网络有强大的学习生成能力,能过生成以假乱真的图像。但是,生成对抗网络存在训练不稳定、梯度消失的问题。
生成网络G和判别网络D的目标函数如下所示:
Ez~Pz[log(1-D(G(z)))]
(1)
其中:z是输入噪声,G是生成网络,D是判别网络。G(z)是由生成网络G生成的图像数据,x是G(z)所对应的真实图像数据。
随着近些年来卷积神经网络的巨大发展,2015年,Alec Radford等人[17]在生成对抗网络的基础上,又与卷积神经网络相结合,提出了DCGAN模型,并对其结构做了改进:
1)去掉所有的池化层。在判别器中,使用步幅卷积替代最大池化层进行下采样,在生成器中,采用转置卷积实现上采样,将输入的随机噪声向量转化为二维矩阵,提升图像的尺寸大小。池化层的作用有两方面,一方面是减小特征图,降低网络计算复杂度;另一方面是提取主要特征,抛弃不重要的特征,进行特征压缩,而使用具有较大步长的卷积层来替换池化层可以实现同样的功能并且加快了收敛速度。
2)尽可能的减少全连接层的使用,除去在生成器的第一层和判别器的最后一层,其余地方使用卷积层代替全连接层。在生成器的第一层和判别器的最后一层使用全连接层其目的都是为了维度的转换,在生成器中是为了将输入的随机噪声变量进行维度转换,而在判别器中是为了将前面卷积层的输出转换为一维向量作为sigmoid函数的输入。此操作可以使维持模型的稳定,还可以降低网络训练参数规模。
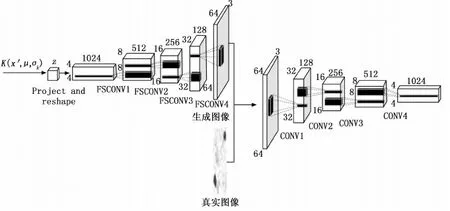
图3 优化后的深度卷积对抗生成网络模型
3)批量归一化(batch normalization,BN)。BN操作将输入都归一化为0均值和单位方差,解决训练过程中间层数据分布发生改变的问题,避免网络训练学习新的数据分布,帮助梯度顺利的向下传播,避免生成器将所有的样本都收敛到一个点。但如果在生成器G和判别器D的所有网络中都应用BN操作会导致样本震荡和模型不稳定,故在生成器的输出层和判别器的输入层不采用BN操作,以防止上述问题的产生。
4)激活函数的变化。在生成器网络中均采用Leaky ReLU作为激活函数,而在判别器网络中使用tanh和ReLU作为激活函数,其中,Tanh仅使用在输出层,ReLU函数运用在其余各层。
1.2 DCGAN优化
DCGAN[18]的生成网络接收一个表示为z的噪声矢量,并将其映射到最后的输出G(z)中。为了提高对抗生成网络对有限训练样本的学习能力,在对抗生成网络的原有结构上,引入高斯混合模型,相比于单高斯分布拥有更好的表征能力。以磁芯为例,磁芯缺陷有不同的形状、颜色、面积等,是多个分布的组合。因此我们潜空间的分布也采用多个高斯分布的组合,使得从潜空间分布更好地映射到真实空间分布。高斯混合模型由多个高斯分布组成,其概率密度函数如下:
(2)
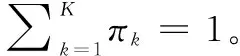
(3)
先随机生成均匀噪声,得到噪声各维均值μ={μ1,μ2,μ3,…,μk}和噪声间协方差对角矩阵σ=[σj1,σj2,σj3,…,σjk],通过均值μ和协方差对角矩阵构建高斯混合模型,并将该高斯混合模型作为生成器的输入部分:
z~K(x;μ,σk)
(4)
(5)
结合高斯混合模型的深度卷积生成对抗结构如图3所示,在生成网络部分,将均匀噪声复杂化,重构为高斯混合模型,增强输入隐空间的语义性和可操作性。生成网络在每次进行迭代生成图像时,随机选取一组高斯混合模型,使模型能够在训练样本数据量有限时更好地学习到真实样本的分布情况,提升生成图像的质量。
在生成网络上的全连接层,使用全局平局池化来代替,提升模型的稳定性。并使用4层反卷积替代原生成网络中的池化层,使模型能够学习自己的空间下采样;使用ReLU激活函数,输出层使用有界激活函数Tanh,使用有界激活函数可以使模型更快收敛。并且都使用批处理Batch Normalization,有利于更深层次网络的训练。
在判别网络部分,同样使用全局平均池化来代替全连接层,各层均采用ReLU激活函数和批处理Batch Normalization,并使用4层步幅卷积取代原判别网络中的池化层。
将生成网络生成的样本数据输入到判别网络中,将判别网络得到的损失误差反向传播到生成网络和判别网络,不断优化性能。
1.3 扩增图像生成
利用DCGAN生成的磁芯缺陷需要与合格的完整磁芯图像进行融合,才能构建最终的扩充样本集,以便于后续目标检测的使用。首先选取原始数据集中合格的磁芯图像ki作为融合图像的背景,并且在图像ki上选取合适的待融合点t,以保证DCGAN生成的磁芯缺陷完整的融合在磁芯上,而不是落于周围导致融合不完整或者无效。其次,从DCGAN生成的缺陷数据集C中获取带融合的生成缺陷。最后将生成缺陷在图像ki上进行融合,从而达到磁芯缺陷特征不丢失、融合边界平滑、效果真实的目的,从而构建完整的扩充数据集。
尽管生成的缺陷数据与真实数据相似,但不能保证其像素与背景图像带融合点周围的像素强度一致,仅仅将生成图像在融合点进行放置会导致生成图像与融合点周围位置不平滑,与原数据集中缺陷图像存在出缺陷不同以外的差异,导致对最终的缺陷检测造成不必要的影响。因此,采用基于泊松方程的融合方法进行生成图像和背景图像间的融合,避免此类问题的产生。
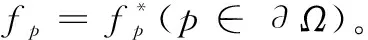
(6)
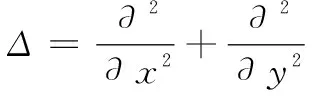
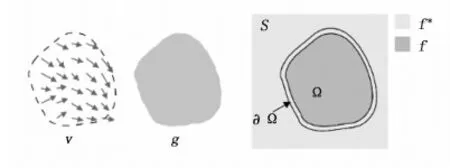
图4 基于泊松方程的图像融合原理图
为了让目标图像覆盖背景图像待融合区域并最终形成无缝拼接,泊松方程引入了由目标图像决定的梯度场。
(7)
(8)
同时,为了保障目标图像能够平滑过渡并且背景图像融合区域与目标图像有相同的轮廓,需要满足融合后图像与原始背景图像有着最相近的梯度信息,即:
(9)
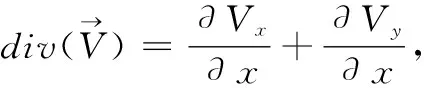
(10)
即求解方程:
(11)
基于泊松方程的图像融合方法伪代码如下:
基于泊松方程的图像融合方法
输入:DCGAN生成的磁芯缺陷数据集C;
原始磁芯数据集合格磁芯图片数据集K;
输出:带有缺陷的磁芯图片数据集。
计算数据集K中的图片数量m
for i=1:m do
从K数据集中顺序读取一张背景图像ki;
抽取出n个来自生成缺陷数据集C的目标图像{C(1),…,C(n)};
设置目标图像的掩膜区域;
通过式(3~12)至(3~17)将掩膜区域的目标图像融入背景图像;
end for
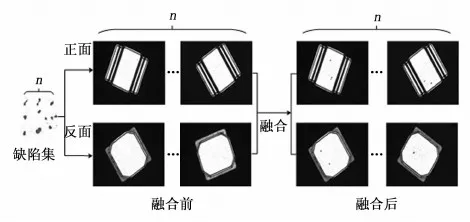
图5 图像融合流程
1.4 基于深度学习的缺陷检测
YOLO算法是最经典的单阶段目标检测网络,其将目标检测问题转化为回归问题,将图片输入后直接得到检测目标的类别和定位,实现了端到端的检测,相较于两阶段检测算法,其在保持高检测精度的前提下,极大提升了检测速度。
其主要思想是首先通过主干网络对输入图像进行特征提取,得到一定大小的特征图,然后将输入图像划分为K×K个单元格,每个单元格都会预测固定数量的边界框,如果目标的中心坐标落在某个单元格中,就由这个单元格预测该目标,每个单元格都会预测固定数量的边界框,其中只有和目标重叠度(IOU)最大的边界框会被选定用来预测该目标。
YOLO-v3算法是在之前两个版本的基础上,融合了多尺度预测、残差网络[20],其网络结构图如图6所示。YOLO-v3的特征提取网络是Darknet-53,包含5个的残差块和大量的层间跳跃连接,解决了网络深度加深带来的梯度爆炸、梯度消失等难以训练的问题,同时一定程度减少了模型的参数,轻量化了模型,加快了模型的训练。
YOLO-v3在预测方面,仿照特征金字塔网络(feature pyramid networks,FPN),采用多尺度融合的方法,总共输出3个尺度的特征图。第一个特征图下采样32倍,第二个特征图是对32倍下采样的特征图进行上采样与下采样16倍的特征图进行张量拼接,同理第三个特张图对16倍下采样的特征图进行上采样与8倍下采样的特征图进行融合。通过多尺度融合的方式,使特征图融合了深层和浅层的特征信息,以此提高检测对小目标的检测精度。
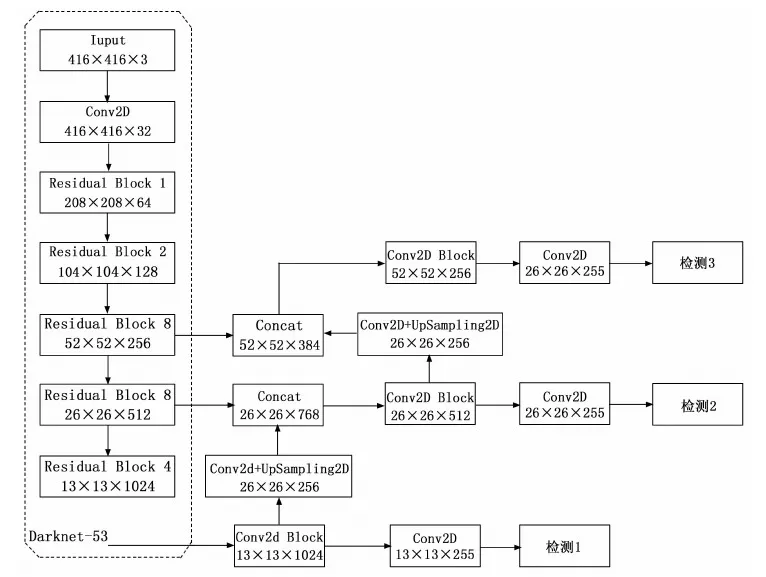
图6 YOLO-v3网络结构图
针对本文研究的磁芯数据集,其缺陷多为小目标。由于多次卷积后小目标的特征容易消失,因此用52×52的网格来检测小物体。由图6所示,在YOLO-v3网络中进行多次卷积操作,将尺寸为13×13的特征层经过上采样扩张成26×26的大小,同时与26×26的特征层进行融合,将融合的结果输入到下一特征层,直到3个检测尺度相融合。利用具有较强位置信息的浅层特征和具有较强语义信息的深层特征,增加网络结构的表征能力,能够提高对小目标的检测率。
最后的输出有2个维度的特征图;选取一个置信度阈值,过滤掉低阈值box,再经过非极大值抑制,输出整个网络的预测结果。输出特征图的其中一个维度是特征图尺寸,另外一个维度是深度,即B(5+C),其中B为每个网格检测得到的边框数量,C为磁芯的缺陷类别数,包括磁芯缺陷的4个位置(Ix,Iy,Iw,Ih)和1个置信度。
2 实验与结果分析
2.1 磁芯图像及预处理
本文所使用的产品来自浙江某公司实际生产产品,所有的图像均在高清工业摄像机下拍摄所得,该数据集提供了2 763张磁芯的图像,其中包含正反面正常图片、斑点图片、破损图片,共六类图片。对该数据集分析发现,数据集中斑点图片仅占总数据集的10.89%,而其余类型图像数量均匀,是典型的不平衡数据集。磁芯整体材质一致,正反面是在同一光照方案和工业摄像机下拍摄所得,故正面缺陷与反面缺陷一致,且存在一个磁芯表面可能出现多个斑点缺陷的情况。将原始数据集中所有的斑点缺陷提取出来,共获得348张斑点缺陷图像作为生成对抗网络的输入,如图8所示,训练生成对抗网络生成新的斑点缺陷图像,再与合格磁芯图像融合获得新的磁芯斑点缺陷数据集。

图7 磁芯数据集部分图像
图8 部分提取的斑点缺陷图
训练前,将数据集中的缺陷部位提取出来,缺陷图像的分辨率为64×64×3。将获取的缺陷图像作为此次DCGAN网络的真实数据输入。
2.2 实验环境及网络参数配置
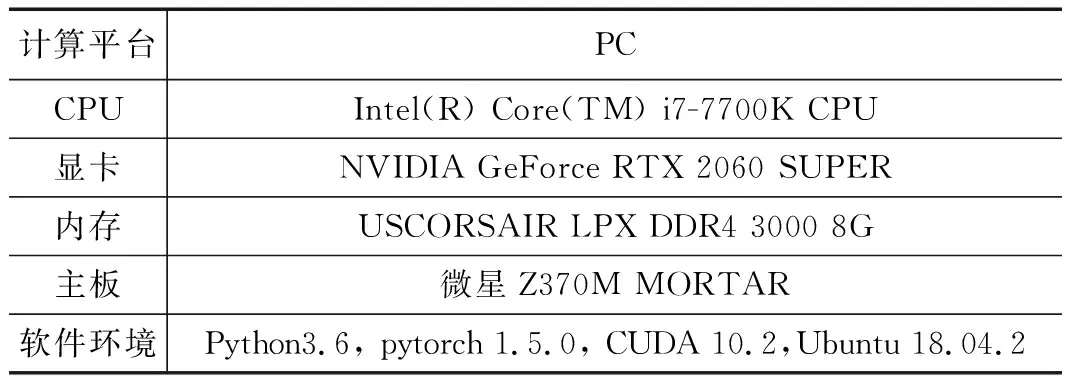
表1 软硬件配置环境
经过多次实验和微调之后,优化后的DCGAN的网络参数如下:输入图像的大小为64×64×3;输出缺陷图像大小为64×64×3;优化器采用Adam[21],生成网络和判别网络的学习率均为0.000 2,动量为0.5;训练epoch为600。
2.3 扩增图像结果与分析
为研究优化后的卷积对抗生成网络对提高缺陷图像质量的有效性,使用从原数据集中提取的斑点图像进行生成实验。模型在训练中的损失函数如图9所示。图9(a)为生成器损失函数变化情况;图9(b)为判别器的损失函数。
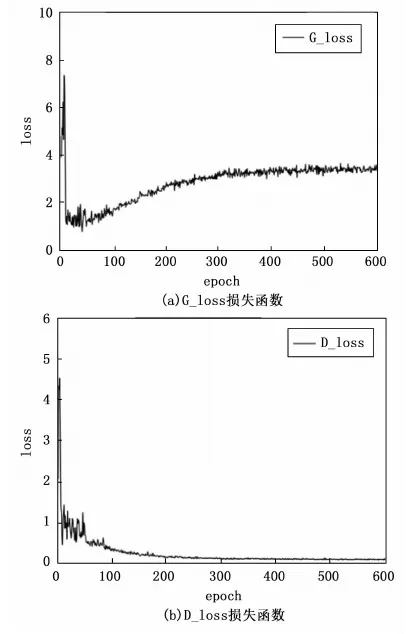
图9 优化DCGAN损失函数曲线
由图9所示,生成网络在前300次迭代中,初期损失函数极具震荡,随后缓慢增长,到后其逐渐平稳,在小范围内波动,此时随着迭代次数的增加,生成的图像也越来越清晰。生成网络在300次迭代以后,损失稳定在一个非常低的值。总体来看,两个函数在经历过前期的震荡变化以后,其值都趋于平稳,这是生成网络和判别网络两个结构在相互平衡、制约。
优化后的卷积对抗生成网络生成的缺陷图像如图10所示。在训练迭代了500次以后,基本满足了生成缺陷的需要,相比于优化前的卷积对抗生成网络生成的图像,改进后的生成图像在同等条件下缺陷部位颜色更深,缺陷边缘更清楚,缺陷更为凝实,生成的有效缺陷更多,可以作为目标图像来进行识别。
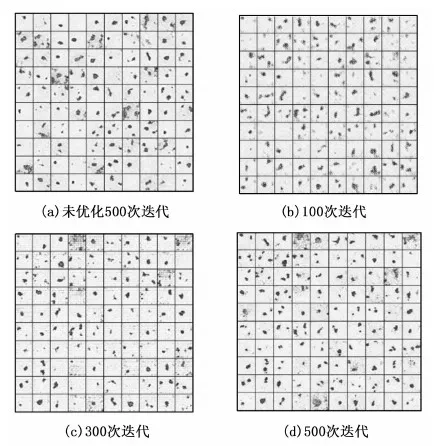
图10 优化和未优化生成图像
2.4 缺陷检测结果与分析
为了将扩增图像应用于后续检测网络,将其与背景图像进行融合,生成2 000张可以用于训练的数据,然后基于YOLO-v3目标检测算法,分别对未扩增和使用优化DCGAN扩增后的数据集进行训练,其结果见表2。
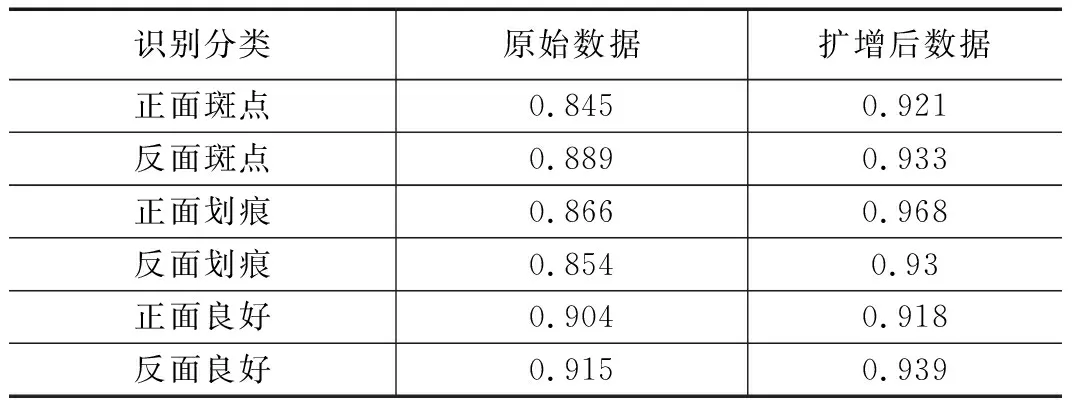
表2 不同数据集检测正确率 %
由表2可知,扩增数据集后各种类别的检测精度较未扩增前有所提高,其中正面斑点检测准确率提升了7.6%,反面斑点检测准确率提升了4.4%,正面划痕检测准确率提升了10.2%,反面划痕检测准确率提升了7.6%,平均准确率提高了5.6%。
3 结束语
缺陷识别是工业产品实现自动化生产的前提之一,随着计算机技术的发展和深度学习技术的不断向前推进,各种检测模型百花齐放,但是在使用深度学习方法实现工业化检测方面容易遇到由于产品制造中的不确定性,导致采集的磁芯数据集出现类间不平衡问题且难以获取大量满足训练要求的磁芯缺陷数据。
针对上述问题,本文提出了一种基于生成对抗网络和图像融合的小样本集类间不平衡处理的方法,并在磁芯数据集上进行验证对比,本文的研究工作包括以下几个方面:
1)针对磁芯数据集数量少及类间不平衡问题,通过截取数据中数量少的斑点目标图像,通过生成对抗网络生成大量类别相同信息各异的目标图像,解决小样本问题。并对原有的卷积对抗生成网络进行了优化,引入了高斯混合模型,改善生成网络的输入,提高了生成缺陷的图像质量。实验表明本文提出的算法生成的目标图像质量更高,利用此方法进行数据扩充能够增强检测模型的泛化能力,提高磁芯表面缺陷检测准确率。
2)针对DCGAN生成的缺陷图像,提出一种基于泊松方程的图像融合方法,将缺陷目标图像与良好的背景图像进行融合,在背景图像上融合一到多个缺陷目标图像,构建趋于真实生产中包含缺陷的磁芯图像,并且达到自然融合的效果,实现目标图像边缘与背景图像融合区域平滑过渡,扩充了数据集,为后续神经网络的训练和识别做准备。
