基于动态特征选择的遥感图像目标检测算法
2023-03-31陈超赵巍
陈超,赵巍
(北京航空航天大学 电子信息工程学院,北京 100191)
在遥感图像研究中,目标检测是理解地面信息的重要手段,目的是在遥感图像中自动搜索出感兴趣目标,并标定其位置、判别其类别。近年来,随着深度学习的发展[1],通用图像的目标检测取得了巨大的发展和进步,同时随着高质量的遥感数据集(如DOTA 数据集[2])的建立,遥感图像目标检测也逐渐成为研究热点。与一般图像不同,地理空间图像通常来自鸟瞰视角,这就造成遥感图像中目标尺寸变化巨大,目标姿态不一,目标长宽比变化极端,且遥感成像还受到光照、环境、季节等多种因素影响。上述变化均为遥感图像目标检测带来了额外的挑战。
为实现更好的检测性能,目前大部分先进的遥感图像目标检测算法都基于域卷积神经网络(region-convolutional neural networks, R-CNN)的 系列网络[3-6]。R-CNN 系列网络生成大量的水平检测框(horizontal bounding box,HBB)作为感兴趣区域,通过复杂的感兴趣区域池化操作(如感兴趣区域池化[4]、感兴趣区域对齐[6]、感兴趣区域可变形池化[7])提取感兴趣区域的特征,基于这些区域的特征进行分类与定位。在遥感图像中,水平的感兴趣区域会造成预测边框与旋转物体之间的不匹配问题[8]。例如,遥感图像中的物体通常具有一定的朝向且可能呈密集排列(如在港口停靠的船只与在停车场停放的车辆),导致水平感兴趣区域包含若干个物体。自然的解决方法[9-10]是利用定向检测框(oriented bounding box,OBB)作为锚(anchor)来处理旋转的物体,这些方法需要使用大量不同角度、比例、尺度的锚,导致网络的效率较低。近期,RoI Transformer[8]算法使用将水平感兴趣区域转换为定向感兴趣区域的方式来解决效率低的问题,但仍需要进行复杂的感兴趣区域池化操作。
与基于R-CNN 的网络相比,单阶段网络不进行感兴趣区域池化操作,直接对感兴趣区域进行分类与回归,通常效率较高但精度较差[2]。单阶段网络在遥感图像目标检测上性能较差的原因主要是由于单阶段网络没有感兴趣区域池化操作,单纯依赖卷积提取特征。而卷积神经网络在提取信息时会受制于固定的空间结构,采样的位置始终是固定的,无法实现灵活的特征选择,而遥感目标朝向、尺度、形状不一,采样点无法聚焦于目标。针对卷积神经网络受制于固定空间结构的问题,可变形卷积(deformable convolution)[7]根据特征映射在原本的采样点处学习一个偏移,使采样点聚焦于目标,但其要求堆叠大量的可变形卷积,造成速度的瓶颈;对齐卷积(alignment convolution)[11]根据物体的方向与尺度使采样点跟随旋转目标动态调整,但其采样点仍然维持矩形的形状,无法根据物体的具体形状实现聚焦。
除了考虑局部的特征聚焦外,遥感图像目标尺度变化巨大,还需对网络的多尺度进行更深入的研究。而目前多尺度的研究主要基于特征金字塔结构[12],其在不同层的特征映射检测不同尺度的物体。特征金字塔的出发点是模型对于不同尺度的物体应具有不同的感受野,具有不同尺度感受野的特征映射包含了不同的有效信息,对于同一尺度的不同物体,感受野也需要有细微的差别。
针对上述卷积神经网络在提取目标信息时受制于固定的空间结构,单阶段遥感图像目标检测网络无法实现特征聚焦的问题,本文提出了可变形对齐卷积,根据定向边框的长、宽和角度改变卷积的采样点,根据特征动态给采样点细微的偏移,实现了动态的特征选择,以适应不同尺度、角度、形状的物体;受启发于同一尺度的不同类别物体需要的感受野的细微差异,提出了基于可变形对齐卷积的感受野自适应模块,融合具有不同尺度感受野的特征映射,自适应地改变神经元的感受野。以上述2 个创新点为基础,提出了基于动态特征选择的单阶段遥感图像精确目标检测算法DFSNet。
1 DFSNet
DFSNet 使用RetinaNet[13]作为基础模型,首先使用骨干网络提取多尺度的特征,再使用感兴趣区域转换模块将水平检测框转换为定向检测框,然后使用感受野自适应模块得到包含不同感受野信息的特征映射,感受野自适应模块中使用动态特征选择层实现特征的聚焦,最后经分类与回归子网络得到检测的结果。网络的总体结构如图1 所示。
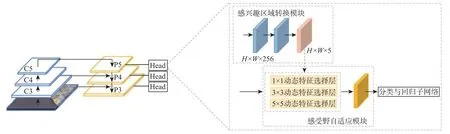
图1 DFSNet 总体结构Fig.1 Overall structure of DFSNet
1.1 基础网络RetinaNet
RetinaNet 的具体结构如图2 所示,主要包括骨干网络和预测分支。骨干网络包括特征提取网络和特征金字塔模块。其中,特征提取网络的作用是提取图像特征,RetinaNet 主要使用ResNet[14]作为特征提取网络;特征金字塔模块[12]的作用是融合多尺度的特征映射。预测分支包括分类子网络与回归子网络,均由1 层卷积构成,分别实现对包围目标的类别识别与边框回归。
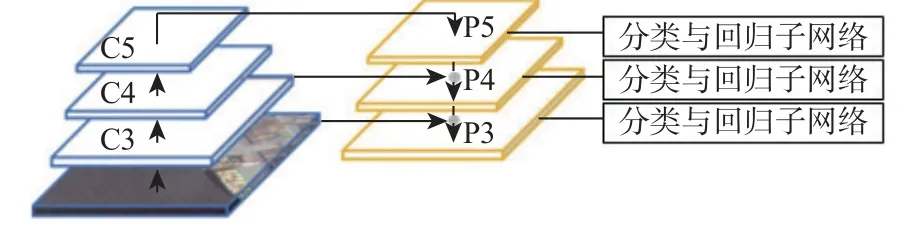
图2 RetinaNet 总体结构Fig.2 Overall structure of RetinaNet
1.2 感兴趣区域转换模块
如图3 所示,图中的实线边框表示一个定向检测框 (x,y,w,h,θ),其中,(x,y)为边框的中心点坐标,w 和 h分 别为边框的宽和长,θ ∈[-π/4,3π/4]为边框与 x轴的夹角。由于设置多个不同角度、比例、尺度的锚将给网络造成极大的计算负担,而不在锚中加入角度参数直接预测角度精度较低,因此DFSNet中的RetinaNet 不直接对定向旋转框进行预测,而是先预测定向旋转框的最小外接水平矩形(见图3虚线矩形),再由感兴趣区域转换模块回归出定向旋转框(见图3 实线矩形),降低了网络的学习难度。
感兴趣区域转换模块由RoI Transformer[8]提出,是一个有物体分类分支和边框回归分支的轻量级网络,分类分支与回归分支均由2 层卷积构成,完成了从水平检测框到定向检测框的转换。
1.3 可变形对齐卷积
标准的二维卷积(见图4(a))利用一个网格R={(rx,ry)} (如 R={(-1,-1),(-1,0),···,(0,1),(1,1)})在特征映射 X上进行采样,然后将采样的值乘以权重Wweight再 求和,得到特征映射 Y。Y在每一个位置p的特征计算公式为

式中:orn为 偏移量 ODC中在采样点 rn的偏移量。
如图4(c)所示,与标准卷积相比,对齐卷积[11]根据感兴趣区域给采样点增加偏移量 OAC,OAC的计算方式如式(3)所示。Y在每一个位置 p的特征计算公式变为
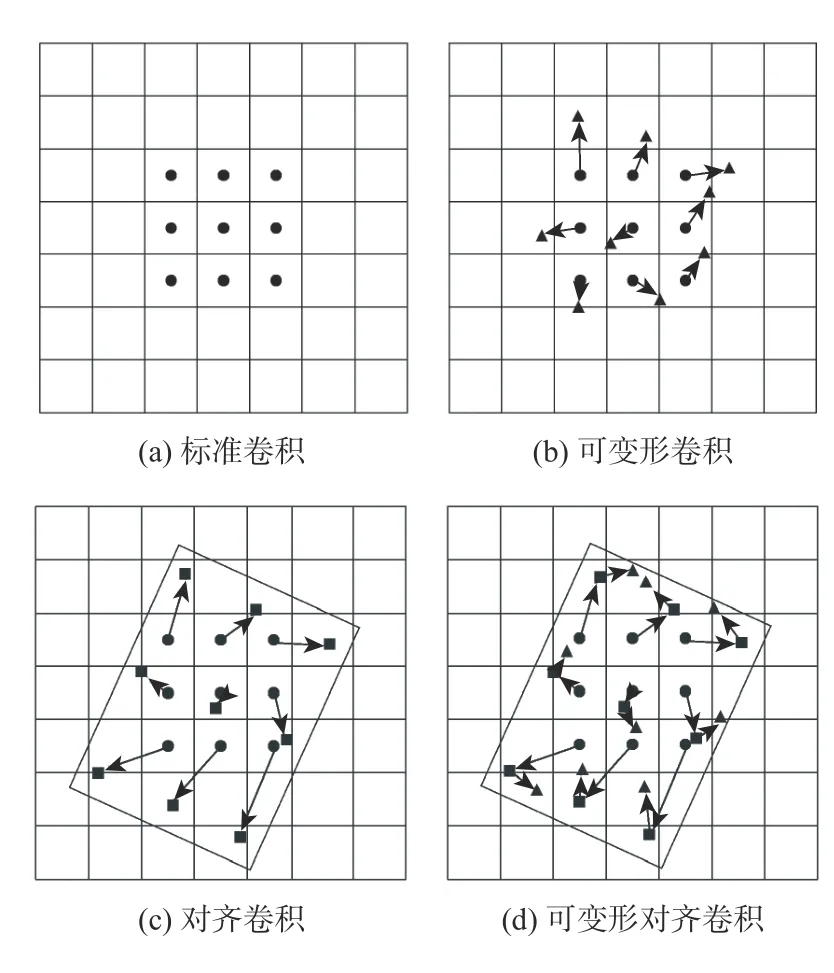
图4 核尺寸为3×3 的不同卷积的采样点对比Fig.4 Comparison of sampling locations of different convolutions with kernel size of 3×3
可变形卷积在提取特征时,可以更多地把注意力放在与目标有关的位置上,更好地处理不同形状的目标;对齐卷积在提取旋转物体的特征时,可以使采样点的分布贴近定向边框的形状,更好地提取旋转物体的特征。因此,将可变形卷积与对齐卷积结合起来,设计了可变形对齐卷积,如图4(d)所示。可变形对齐卷积能够先根据候选边框调整采样点,使采样点的分布(图4(d)中矩形点)贴近定向边框的形状,再通过特征学习偏移,聚集于与目标有关的位置上(图4(d)中三角形点),从而实现更好的特征提取。可变形对齐卷积的采样点偏移量ODAC为
图5 为核尺寸为3×3 的不同卷积的采样点对比,可以更形象地说明不同卷积对于采样点的影响。如图5(a)所示,标准二维卷积受制于固定的空间结构,采样点为图中圆点,即通常的采样点,无法将采样点集中在舰船上;如图5(b)所示,经过可变形卷积,采样点为图中的三角形点,可以集中于舰船之上,但这需要大量的可变形卷积的堆叠,严重影响模型的速度;如图5(c)所示,经过对齐卷积后,采样点为图中的矩形点,呈定向框分布,初步实现对舰船的聚焦;如图5(d)所示,经过可变形对齐卷积后,网络可以先根据舰船的方向、尺度、长宽比大致实现对舰船的聚焦,再根据特征图对采样点进行细微的调整,得到与物体形状更为匹配的三角形采样点。可变形对齐卷积能够改变采样点动态地选择特征,实现对舰船的聚焦。
1.4 动态特征选择层
基于可变形对齐卷积,构建了动态特征选择层,如图6 所示。对于感兴趣区域转换模块输出的H×W×5的特征映射,首先将其解码为定向边框(x,y,w,h,θ)的形式,然后利用式(3)得到对齐的偏移量;同时特征映射经过卷积得到进一步的偏移量。2 种偏移量输入到可变形对齐卷积,特征映射经可变形对齐卷积后得到采样点聚焦于目标的特征映射,实现了特征的动态选择。
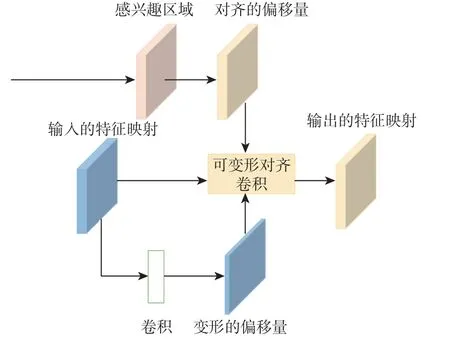
图6 动态特征选择层Fig.6 Dynamic feature selection layer
1.5 感受野自适应模块
具有同一尺度的不同类别的物体,所需要的感受野也应有细微的差别。例如,同一个尺度的车辆与足球场,足球场的边缘、纹理特征不明显,需要的感受野应更大以便提取更多背景信息,而车辆的边缘、纹理特征明显,感受野可以相对稍小。可变形卷积层输出的特征映射的感受野受到感兴趣区域边框参数与核大小控制,为了融合不同尺度感受野的信息,受TridentNet[15]与DRN[16]启发,提出了基于可变形对齐卷积的感受野自适应模块,融合不同核尺寸的可变形卷积层输出的特征映射。如图7所示,输入的特征映射 X经过具有不同核尺寸(1×1、3×3、5×5)的动态特征选择层,分别得到特征映射Xi∈RH×W×C(i ∈1,2,3),经过1×1 卷积、Batch Normalization[17]和ReLU 激 活 函 数 得 到 特 征 映 射Ai∈RH×W×1(i ∈1,2,3),如式(6)所示,通过fast normalization[18]得到不同特征映射的权重 Wi∈RH×W×1(i ∈1,2,3),最终如式(7)所示得到融合的特征 Y。
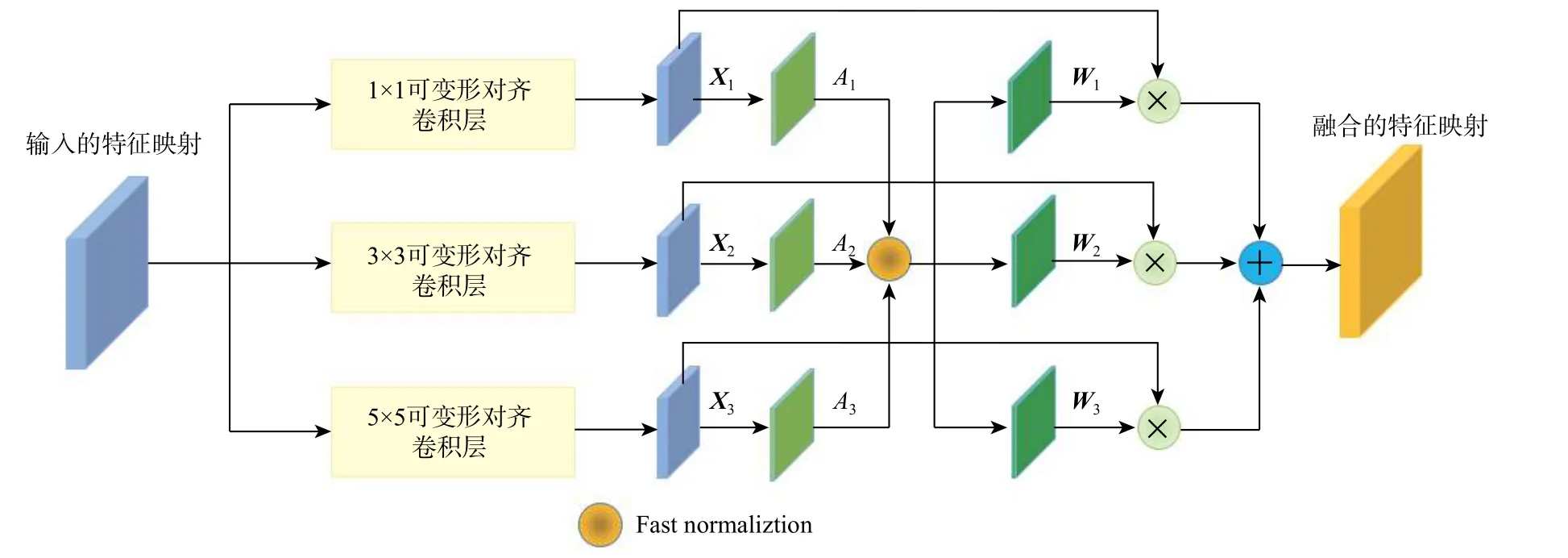
图7 感受野自适应模块Fig.7 Receptive field adaptive module
1.6 网络损失函数
1.6.1 基本的回归目标
针对旋转检测框,回归的目标主要有
式中:(xg,yg,wg,hg,θg)和 (x,y,w,h,θ)分别代 表真实边框和锚;k 为一个确保 (θg-θ+kπ)∈[-π/4,3π/4]的整数。在DFSNet 的动态特征选择层中,锚是提前设置的水平边框,θ设为0;在感受野自适应模块块中,锚是动态特征选择层输出的旋转边框结果。
1.6.2 匹配策略
使用交并比(intersection over union,IoU)作为边框匹配的指标,如图8 所示,IoU 代表2 个边框(在训练阶段匹配正负样本时,使用锚与真实边框计算 IoU,在推理阶段使用不同的预测边框计算IoU)的重叠程度,计算公式为

图8 IoU 的解释Fig.8 Explanation of IoU

将与真实框的IoU 大于0.5 的锚设为正样本,小于0.4 的设为负样本。动态特征选择层中,锚是水平框,真实边框是旋转边框,此时根据锚与旋转边框的最小外接矩形计算IoU。感受野自适应模块中,直接计算动态特征选择层输出的旋转边框与真实的旋转边框的IoU。
1.6.3 损失函数
DFSNet 的损失函数由动态特征选择层的损失与感受野自适应模块的损失构成,每一部分损失由分类的损失与回归的损失构成,总的损失函数如下:

2 实验结果
实验采用的硬件环境为:CPU 配置为Intel(R)Xeon(R) E5-2680 V3@2.50 GHz,GPU 配置为NVIDIA 1080 Ti。实验的软件环境为:Ubuntu16.04.6 LTS、CUDA10.0、PyTorch[19]1.3.1 和Python3.6.9。
2.1 数 据 集
DOTA 数据集[2]是目前最通用的遥感图像目标检测数据集,包含2 806 张图片,图片的大小在800×800 到4 000×4 000 像 素 范 围 内,包 含188 282个不同尺度、不同方向、不同形状的实例。DOTA数据集包含15 个类别的物体,分别为飞机 (PL)、棒球场(BD)、桥梁(BG)、田径场(GTF)、小型车辆(SV)、大型车辆(LV)、船只(SH)、网球场(TC)、篮球场(BC)、油罐(ST)、足球场(SBF)、环岛(RA)、港口(HA)、游泳池(SP)及直升机(HC)。
2.2 实验细节
采用ResNet50 FPN 作为骨干网络。对于特征金字塔(如P3~P7)的每一层特征映射,只在一个点上生成一个正方形的锚,锚的尺度是特征映射步长的4 倍(如32、64、128、256、512)。实验均在DOTA数据集上训练24 个轮次,使用SGD 作为优化器,初始学习率设置为0.01,在第18 和第22 个轮次学习率下降10 倍。实验输入图片尺寸为1 024×1 024,使用4 张1080 Ti 显卡进行单尺度的训练,每次迭代处理16 张图片,数据增强仅使用随机的镜像翻转,测试时使用一张显卡,非极大值抑制(nonmaximum suppression, NMS)的阈值为0.1。
2.3 评价指标
平均精度(average precision, AP)是精度-召回曲线下的面积,DOTA 数据集使用IoU=0.5 时的AP 作为评估指标。mAP 代表对不同类别AP 求平均的结果。
2.4 实验结果及分析
2.4.1 基础模型RetinaNet 结果
在基础模型RetinaNet 中,将锚的长宽比分别设置为0.5、1、1.5,尺度设置为特征映射步长的2、4、8 倍,在特征映射的一个点设置9 个锚。最终可以在DOTA 数据集上达到68.05%的mAP,验证了基础模型的可靠性。
2.4.2 可变形对齐卷积的作用
为验证可变形对齐卷积的有效性,将可变形对齐卷积与其他卷积进行对比。实验中,将DFSNet的可变形对齐卷积替换为其他卷积,并且不使用感受野自适应模块,而是在感受野转换模块后经过3×3 的不同卷积得到修正的特征映射,再进行类别识别与边框回归,其他网络结构与设置维持不变。特别的,可变形卷积需要一定的堆叠才会起作用,因此实验中使用了2 层可变形卷积。
如表1 所示,可变形卷积与对齐卷积都能使网络的识别精度得以提高,可变形对齐卷积能够结合两者的优点,实现对目标的聚焦,在标准卷积的基础上mAP 提升了2.01%。

表1 可变形对齐卷积与其他卷积对比Table 1 Comparison between deformable alignment convolution and other convolutions
2.4.3 感兴趣区域转换模块、动态特征选择层、感受野自适应模块的作用
为了验证感兴趣区域转换模块、动态特征选择层、感受野自适应模块的作用,对其进行了消融实验,逐步添加感兴趣区域转换模块、动态特征选择层与感受野自适应模块。如表2 所示,通过添加感兴趣区域转换模块、动态特征选择层、感受野自适应模块,模型的性能持续提高,表明了三者可以相互兼容,并且可以联合使用来获得最佳性能。

表2 DFSNet 的消融实验对比Table 2 Ablation studies of DFSNet
2.4.4 与其他模型对比及可视化
如表3 所示,DFSNet 在使用ResNet50 FPN 作骨干网络时,在DOTA 数据集上可以达到74.04%的mAP,远远优于其他单阶段或双阶段模型,有着优异的性能,说明DFSNet 能够有效提高不同尺度、不同类别物体的检测精度。与基础模型Retina-Net 相比,DFSNet 在小型车辆(SV)、大型车辆(LV)、船只(SH)、油罐(ST)提升很大,证明DFSNet 能够对密集排列的物体实现聚焦。DFSNet 在DOTA 数据集的可视化结果如图9 所示。可以看到,DFSNet相比基础模型有着优异的检测效果。

表3 DFSNet 与其他模型在DOTA 数据集上的对比结果Table 3 Comparison of DFSNet and other methods on DOTA
3 结 论
在RetinaNet 的基础上,增加了感兴趣区域转换模块、动态特征选择层、感受野自适应模块,提出了基于动态特征选择的遥感图像目标检测算法DFSNet。
1)引入感兴趣区域转换模块,使得DFSNet 算法在定向框检测过程中不需要使用大量不同角度、比例、尺度的锚,算法在DOTA 数据集上mAP 达到71.17%,比基础模型RetinaNet 提高了3.12%。
2)使用可变形对齐卷积解决了卷积神经网络受制于固定的空间结构的问题,使得DSFNet 算法可以针对不同尺度、不同长宽比、不同形状的物体动态的选择特征,实现了对物体的聚焦。使用可变形对齐卷积,算法在DOTA 数据集上mAP 达到73.18%,性能进一步提高了2.01%。
3)使用感受野自适应模块,动态调整神经元的感受野,算法在DOTA 数据集上mAP 达到74.04%,性能进一步提高了0.86%。
